 网硕互联帮助中心
网硕互联帮助中心💖💖作者:计算机毕业设计小途 💙💙个人简介:曾长期从事计算机专业培训教学,本人也热爱上课教学,语言擅长Java、微信小程序、Python、Golang、安卓Android等,开发项目包括大数据、深度学习、网站、小程序、安卓、算法。平常会做一些项目定制化开发、代码讲解、答辩教学、文档编写、也懂一些降重方面的技巧。平常喜欢分享一些自己开发中遇到的问题的解决办法,也喜欢交流技术,大家有技术代码这一块的问题可以问我! 💛💛想说的话:感谢大家的关注与支持! 💜💜 网站实战项目 安卓/小程序实战项目 大数据实战项目 深度学习实战项目
目录
- 医学生健康程度数据可视化分析系统介绍
- 医学生健康程度数据可视化分析系统演示视频
- 医学生健康程度数据可视化分析系统演示图片
- 医学生健康程度数据可视化分析系统代码展示
- 医学生健康程度数据可视化分析系统文档展示
医学生健康程度数据可视化分析系统介绍
基于大数据的医学生健康程度数据可视化分析系统是一套采用先进大数据技术栈开发的综合性健康数据分析平台,该系统以Hadoop分布式存储框架和Spark大数据处理引擎为核心技术支撑,结合Python数据科学库Pandas、NumPy进行深度数据挖掘与分析处理。系统后端采用Django框架构建稳定的数据服务层,前端运用Vue.js结合ElementUI组件库和Echarts可视化图表库打造直观友好的用户交互界面,数据持久化存储基于MySQL关系型数据库实现。系统功能涵盖完整的用户管理体系,包括个人信息维护、密码修改等基础功能模块,核心业务聚焦于医学生健康程度数据的全方位分析,具体实现了医学生健康程度数据管理、倦怠共情能力深度分析、人口学特征统计分析、重点群体精准画像分析、心理健康科学评估分析以及学业健康关联性研究分析等六大专业分析模块。系统还配备了大屏可视化展示功能,通过丰富的图表形式直观呈现分析结果,利用Hadoop HDFS分布式文件系统确保海量健康数据的安全存储,通过Spark SQL实现高效的数据查询与统计分析,为医学院校提供科学的学生健康状况监测与评估解决方案。
医学生健康程度数据可视化分析系统演示视频
基于大数据的医学生健康程度数据可视化分析系统
医学生健康程度数据可视化分析系统演示图片
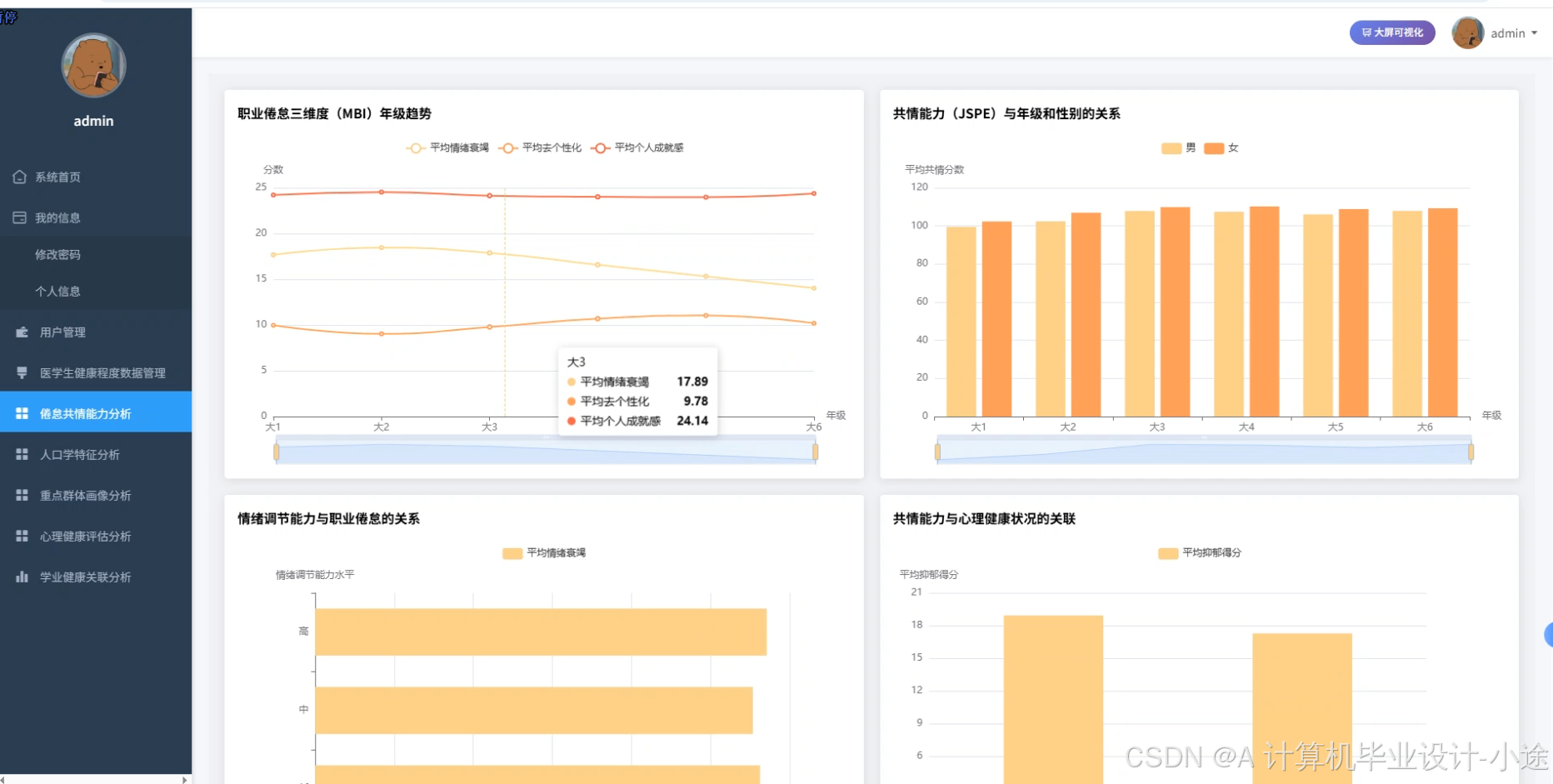
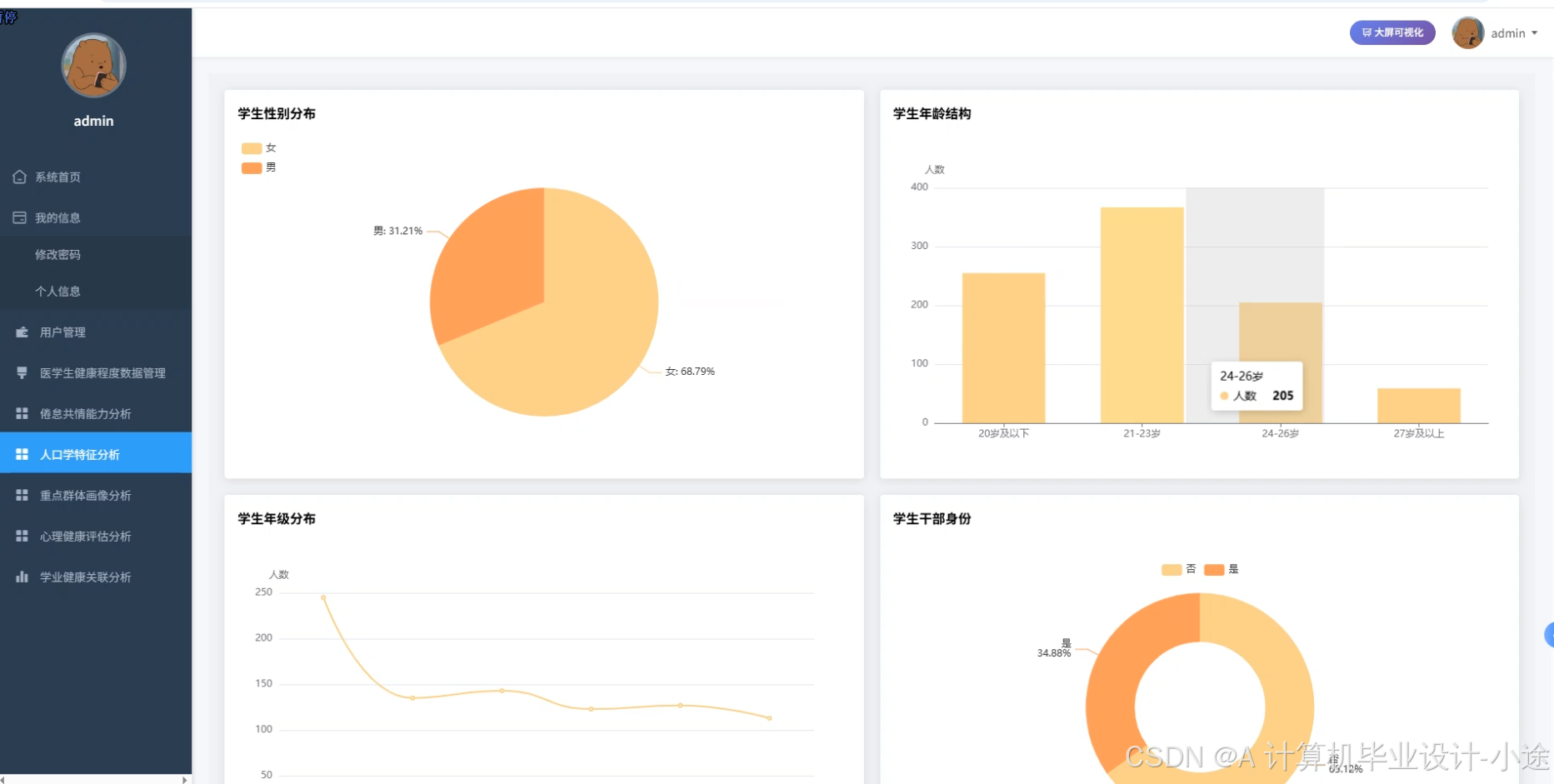

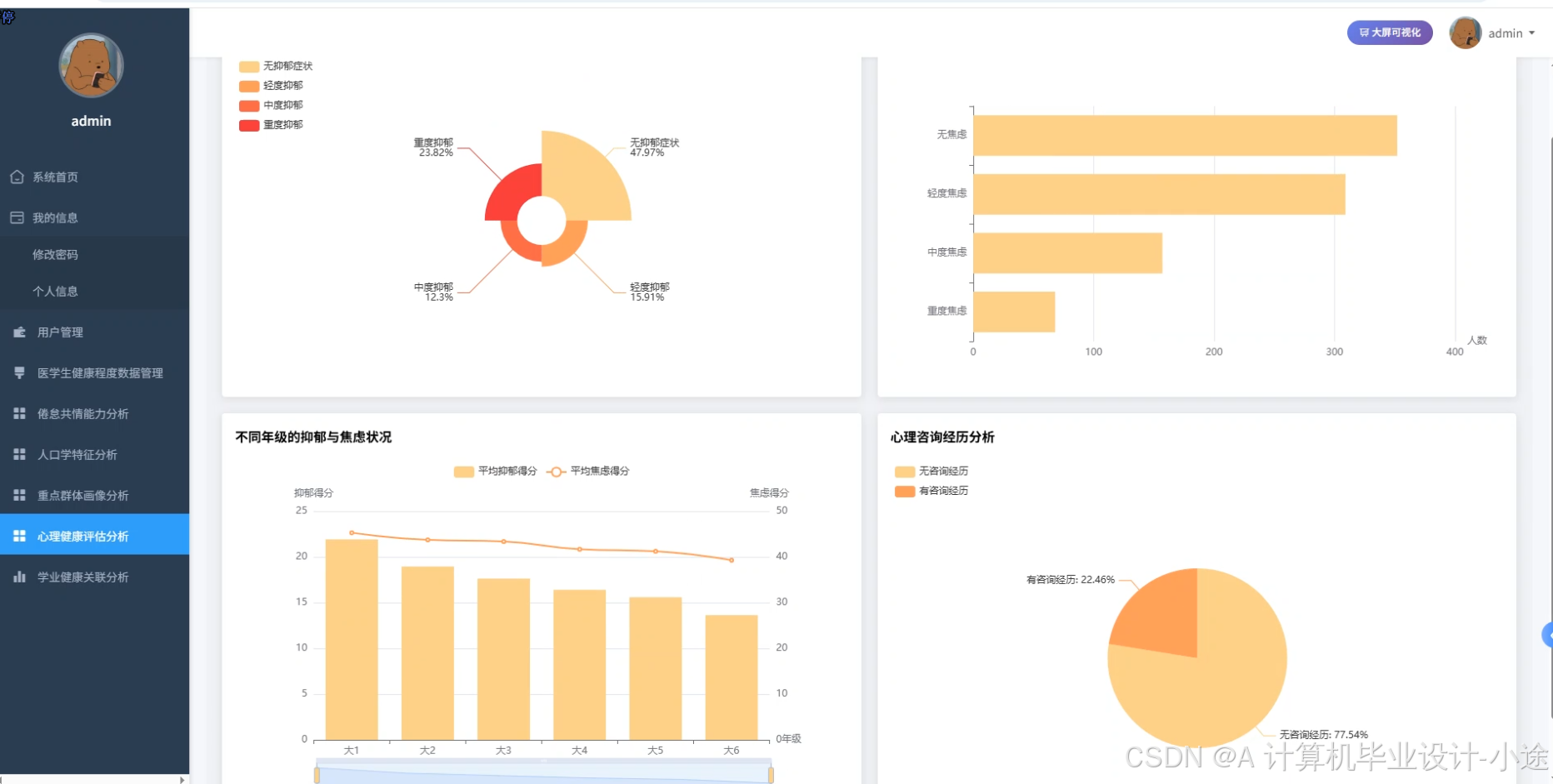
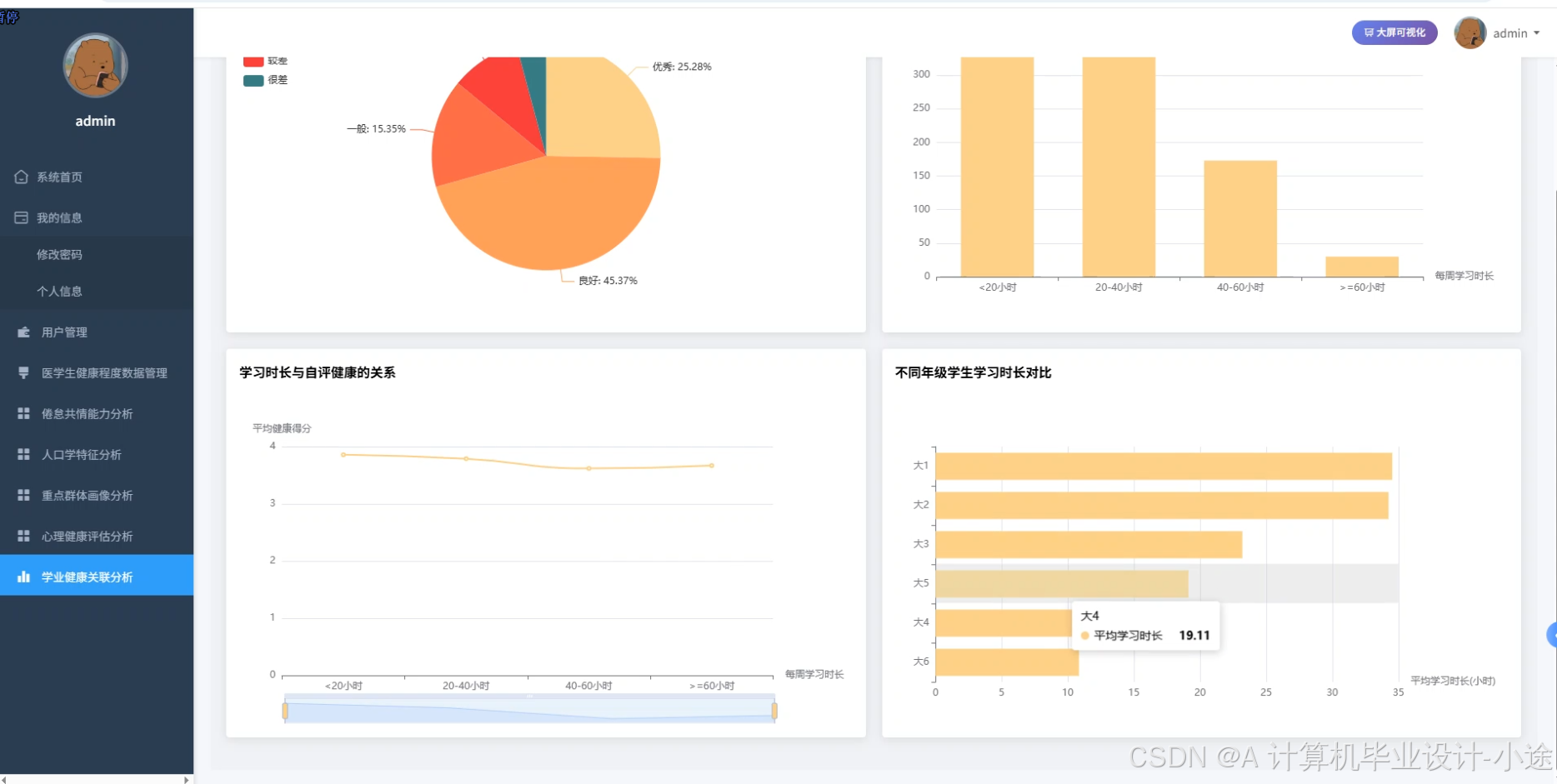
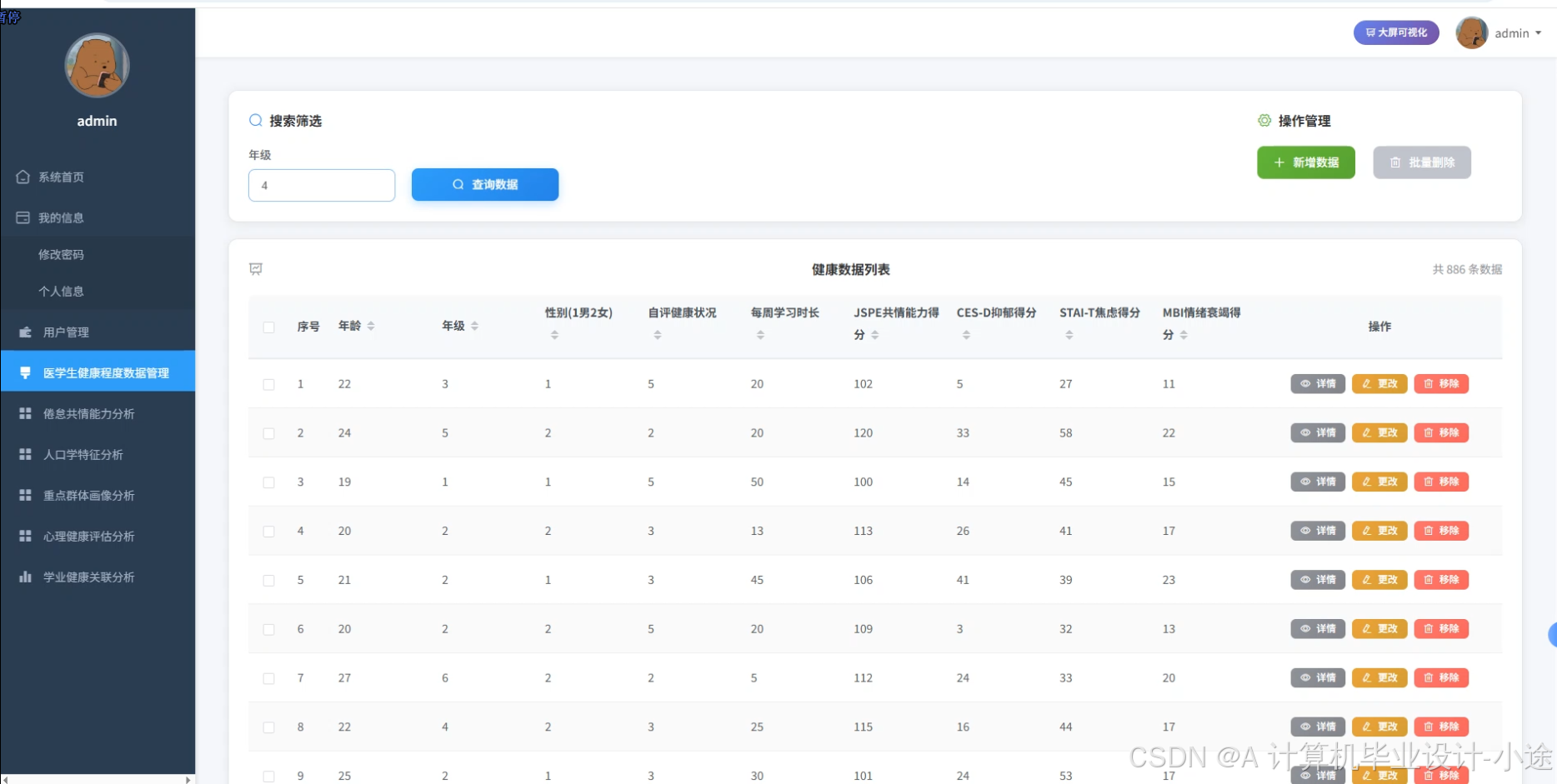
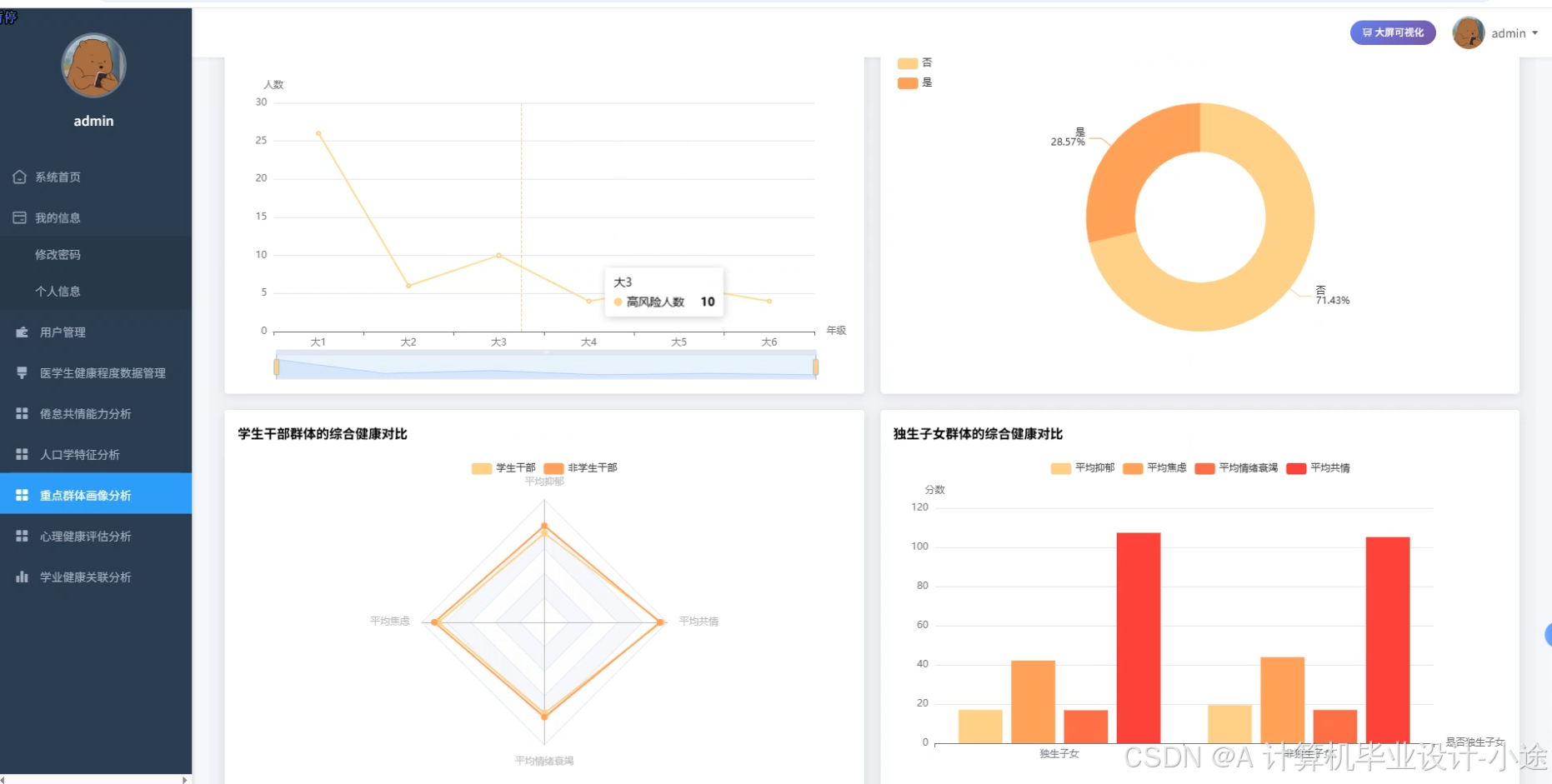
医学生健康程度数据可视化分析系统代码展示
# 医学生健康程度数据管理核心功能
def manage_health_data(request):
health_data = request.POST.get('health_data')
student_id = request.POST.get('student_id')
assessment_date = request.POST.get('assessment_date')
# 数据预处理和清洗
df = pd.DataFrame(json.loads(health_data))
df['bmi'] = df['weight'] / (df['height'] / 100) ** 2
df['health_score'] = (df['physical_score'] * 0.4 + df['mental_score'] * 0.6)
df = df.dropna()
# 使用Spark SQL进行数据分析
spark_df = spark.createDataFrame(df)
spark_df.createOrReplaceTempView("health_records")
analysis_result = spark.sql("""
SELECT student_id,
AVG(health_score) as avg_health_score,
MAX(health_score) as max_health_score,
MIN(health_score) as min_health_score,
COUNT(*) as record_count
FROM health_records
WHERE assessment_date >= date_sub(current_date(), 90)
GROUP BY student_id
""").collect()
# 健康等级评估算法
for record in analysis_result:
if record.avg_health_score >= 80:
health_level = "优秀"
elif record.avg_health_score >= 70:
health_level = "良好"
elif record.avg_health_score >= 60:
health_level = "一般"
else:
health_level = "需关注"
# 数据存储到HDFS
hdfs_path = f"/health_data/{student_id}_{assessment_date}.json"
health_record = {
'student_id': student_id,
'health_data': df.to_dict('records'),
'analysis_result': [row.asDict() for row in analysis_result],
'health_level': health_level,
'created_at': datetime.now().isoformat()
}
# 保存到MySQL数据库
HealthRecord.objects.create(
student_id=student_id,
health_score=record.avg_health_score,
health_level=health_level,
assessment_date=assessment_date,
data_path=hdfs_path
)
# 心理健康评估分析核心功能
def psychological_health_analysis(request):
student_ids = request.POST.getlist('student_ids')
analysis_period = request.POST.get('period', 30)
# 从数据库获取心理健康数据
psychological_data = PsychologicalRecord.objects.filter(
student_id__in=student_ids,
created_at__gte=timezone.now() – timedelta(days=int(analysis_period))
).values()
df = pd.DataFrame(psychological_data)
# 心理健康指标计算
df['anxiety_index'] = (df['anxiety_score'] – df['anxiety_score'].mean()) / df['anxiety_score'].std()
df['depression_index'] = (df['depression_score'] – df['depression_score'].mean()) / df['depression_score'].std()
df['stress_index'] = (df['stress_score'] – df['stress_score'].mean()) / df['stress_score'].std()
df['comprehensive_index'] = (df['anxiety_index'] + df['depression_index'] + df['stress_index']) / 3
# 使用Spark进行深度分析
spark_df = spark.createDataFrame(df)
spark_df.createOrReplaceTempView("psychological_records")
correlation_analysis = spark.sql("""
SELECT
corr(anxiety_score, depression_score) as anxiety_depression_corr,
corr(stress_score, academic_performance) as stress_performance_corr,
corr(sleep_quality, comprehensive_index) as sleep_mental_corr,
percentile_approx(comprehensive_index, 0.25) as q1_index,
percentile_approx(comprehensive_index, 0.75) as q3_index
FROM psychological_records
""").collect()[0]
# 风险等级评估
risk_assessment = spark.sql("""
SELECT student_id,
CASE
WHEN comprehensive_index > 1.5 THEN '高风险'
WHEN comprehensive_index > 0.5 THEN '中等风险'
WHEN comprehensive_index > -0.5 THEN '轻微风险'
ELSE '正常'
END as risk_level,
comprehensive_index
FROM psychological_records
ORDER BY comprehensive_index DESC
""").collect()
# 预警机制
high_risk_students = []
for student in risk_assessment:
if student.risk_level == '高风险':
high_risk_students.append({
'student_id': student.student_id,
'risk_score': student.comprehensive_index,
'alert_time': datetime.now()
})
# 触发预警通知
PsychologicalAlert.objects.create(
student_id=student.student_id,
alert_type='心理健康高风险',
risk_score=student.comprehensive_index,
alert_status='待处理'
)
# 大屏可视化数据处理核心功能
def dashboard_visualization_data(request):
time_range = request.GET.get('time_range', '30')
# 获取总体健康数据统计
total_students = HealthRecord.objects.filter(
created_at__gte=timezone.now() – timedelta(days=int(time_range))
).values('student_id').distinct().count()
health_distribution = HealthRecord.objects.filter(
created_at__gte=timezone.now() – timedelta(days=int(time_range))
).values('health_level').annotate(count=Count('id'))
# 使用Spark进行复杂数据聚合
health_df = pd.DataFrame(HealthRecord.objects.all().values())
spark_health_df = spark.createDataFrame(health_df)
spark_health_df.createOrReplaceTempView("all_health_records")
# 健康趋势分析
trend_analysis = spark.sql("""
SELECT
date_format(assessment_date, 'yyyy-MM') as month,
AVG(health_score) as avg_score,
COUNT(*) as record_count,
COUNT(DISTINCT student_id) as student_count
FROM all_health_records
WHERE assessment_date >= date_sub(current_date(), 365)
GROUP BY date_format(assessment_date, 'yyyy-MM')
ORDER BY month
""").collect()
# 专业维度健康分析
major_analysis = spark.sql("""
SELECT
major,
AVG(health_score) as avg_health_score,
AVG(physical_score) as avg_physical_score,
AVG(mental_score) as avg_mental_score,
COUNT(*) as total_records
FROM all_health_records hr
JOIN students s ON hr.student_id = s.id
GROUP BY major
ORDER BY avg_health_score DESC
""").collect()
# 年级对比分析
grade_comparison = spark.sql("""
SELECT
grade,
health_level,
COUNT(*) as count,
ROUND(COUNT(*) * 100.0 / SUM(COUNT(*)) OVER (PARTITION BY grade), 2) as percentage
FROM all_health_records hr
JOIN students s ON hr.student_id = s.id
GROUP BY grade, health_level
ORDER BY grade, health_level
""").collect()
# 实时数据更新
real_time_stats = {
'total_assessments_today': HealthRecord.objects.filter(
created_at__date=timezone.now().date()
).count(),
'high_risk_alerts': PsychologicalAlert.objects.filter(
alert_status='待处理',
created_at__gte=timezone.now() – timedelta(hours=24)
).count(),
'system_health_score': np.random.uniform(85, 95)
}
# 构建可视化数据结构
visualization_data = {
'health_distribution': [{'name': item['health_level'], 'value': item['count']}
for item in health_distribution],
'trend_data': [{'month': row.month, 'score': float(row.avg_score), 'count': row.student_count}
for row in trend_analysis],
'major_ranking': [{'major': row.major, 'score': float(row.avg_health_score)}
for row in major_analysis],
'grade_stats': [{'grade': row.grade, 'level': row.health_level,
'count': row.count, 'percentage': float(row.percentage)}
for row in grade_comparison],
'real_time': real_time_stats
}
return JsonResponse(visualization_data)
医学生健康程度数据可视化分析系统文档展示

💖💖作者:计算机毕业设计小途 💙💙个人简介:曾长期从事计算机专业培训教学,本人也热爱上课教学,语言擅长Java、微信小程序、Python、Golang、安卓Android等,开发项目包括大数据、深度学习、网站、小程序、安卓、算法。平常会做一些项目定制化开发、代码讲解、答辩教学、文档编写、也懂一些降重方面的技巧。平常喜欢分享一些自己开发中遇到的问题的解决办法,也喜欢交流技术,大家有技术代码这一块的问题可以问我! 💛💛想说的话:感谢大家的关注与支持! 💜💜 网站实战项目 安卓/小程序实战项目 大数据实战项目 深度学习实战项目


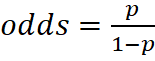



评论前必须登录!
注册