 网硕互联帮助中心
网硕互联帮助中心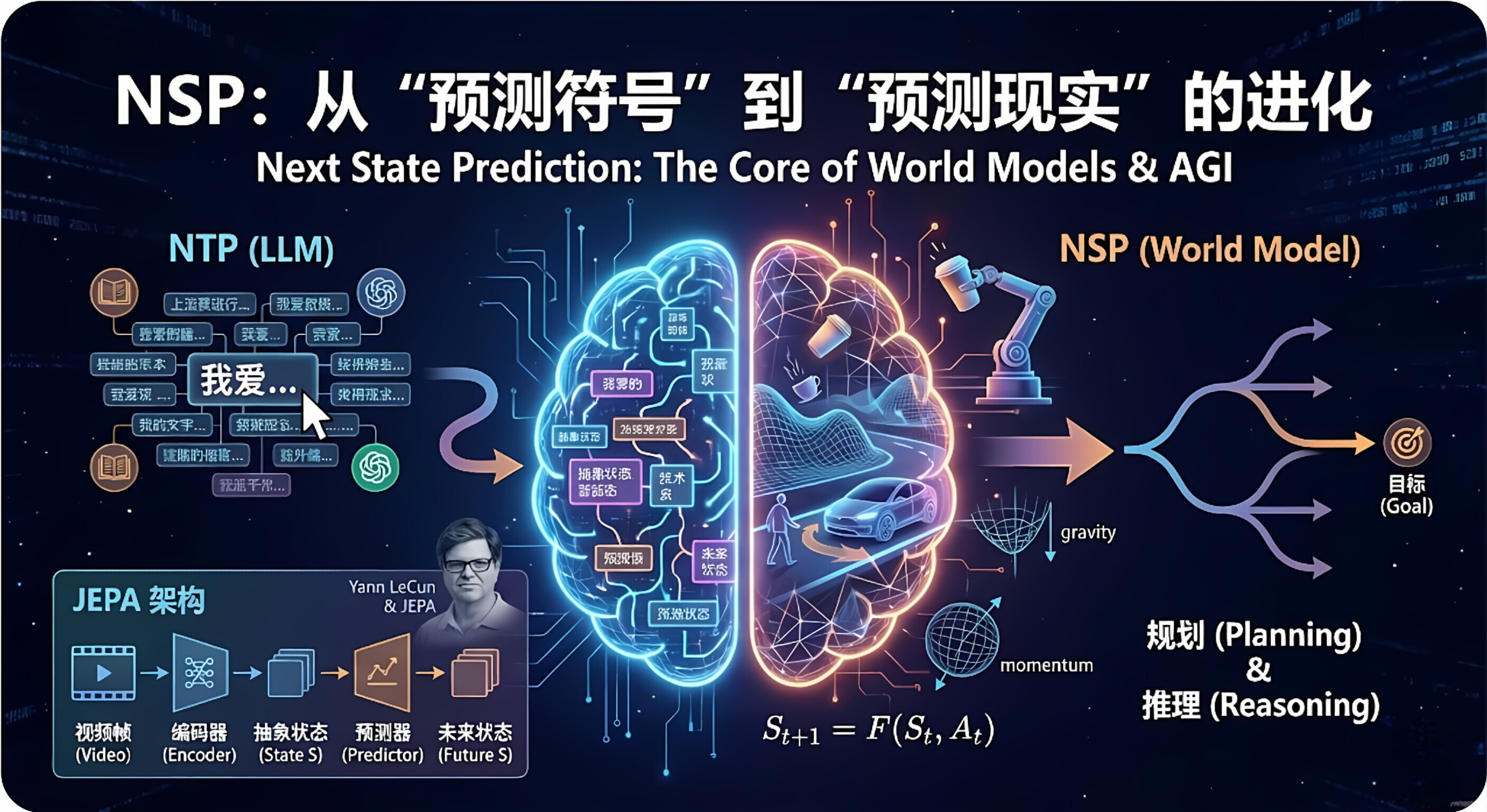
下一状态预测 (NSP,Next State Prediction) 是从 大语言模型 (LLM) 向 世界模型 (World Model) 进化时的一个核心概念。
如果说 NTP (下一个词预测) 是让 AI 学会像人类一样说话;
那么 NSP 就是让 AI 学会像人类一样思考物理规律和因果关系。
这通常与 Yann LeCun (图灵奖得主、Meta 首席 AI 科学家) 提出的 JEPA 架构 以及 具身智能 (Robotics) 紧密相关。
1.🌍 核心定义:从“预测符号”到“预测现实”
要理解这个概念,我们需要对比 LLM 和 World Model 的根本区别:
-
LLM (大语言模型) —— Next Token Prediction
-
对象:文本符号。
-
逻辑:根据“我爱”,预测下一个字是“你”。
-
局限:它只懂概率,不懂物理。它不知道为什么杯子松手会掉下去,它只知道“杯子”后面常跟“摔碎”。
-
-
World Model (世界模型) —— Next State Prediction
-
对象:环境的状态 (State)。
-
逻辑:根据“我现在手里的杯子 (S_t)” + “我松开手 (A_t)”,预测“下一秒杯子的位置和状态 (S_{t+1})”。
-
核心:S_{t+1} = F(S_t, A_t)。即:未来状态 = 当前状态 + 动作。
-
2.🧠 什么是“状态 (State)”?为什么不预测“像素”?
这是 Yann LeCun 最著名的理论。
在视频生成或自动驾驶中,如果让 AI 预测“下一帧的每一个像素点是什么颜色” (Genrative Model),太难了,因为现实世界充满了随机的噪音(树叶的抖动、光影的变化)。
下一状态预测 的精髓在于:不预测细节,只预测本质。
-
例子:一辆车在路上跑。
-
像素预测:AI 试图画出车轮上每一粒灰尘。
-
状态预测:AI 把画面压缩成一个抽象的“特征向量” (Latent State) 。它只在乎:“这辆车的位置变了,它向左转了。”
-
-
优势:通过忽略无关紧要的细节(噪音),AI 能更精准地掌握核心的物理规律和因果链条。
3.🏗️ 典型架构:JEPA (联合嵌入预测架构)
这是实现下一状态预测的主流架构(不同于 GPT 的 Transformer 架构):
编码 (Encoder):把现实画面(视频/图片)变成抽象的数学状态 (S)。
预测 (Predictor):在抽象空间里,推演如果不加干预,或者施加动作后,状态 S 会变成什么样。
对比:把预测出来的状态,和真实的未来状态进行对比,修正模型。
这就像人类的直觉: 当你扔出一个篮球,你脑子里不会计算篮球表面的纹路怎么旋转(像素),但你会预判它的抛物线轨迹(状态)。
4.🚀 为什么它比 NTP 更高级?
下一状态预测被认为是通往 AGI (通用人工智能) 的必经之路,因为它带来了 “规划 (Planning)” 能力。
-
NTP (GPT-4):也是一种“走一步看一步”的思维。写代码时,它不知道写到第 100 行会发生什么,它只知道第 1 行写完写第 2 行。
-
NSP (World Model):具备推演未来的能力。
-
思考:“如果我做动作 A,状态会变成 S1;如果做动作 B,状态会变成 S2。S2 离我的目标更近,所以我选 B。”
-
结果:这就是推理 (Reasoning) 和 规划 的本质。
-
总结
NSP 是 AI 从 “文科生”(只会写文章)进化为 “理科生”(理解物理世界因果律)的关键技术。
它是自动驾驶汽车预判行人动作的核心,也是机器人学会不撞墙的核心。在未来,最强的 AI 可能是 NTP (负责交流) + NSP (负责思考) 的结合体。


评论前必须登录!
注册