 网硕互联帮助中心
网硕互联帮助中心第33章:微服务架构中的状态码传播
33.1 微服务架构中的状态码挑战
33.1.1 分布式系统的复杂性
微服务架构带来了状态码处理的全新挑战:
yaml
# 微服务调用链示例
request:
path: /api/order/123
flow:
– API Gateway (nginx/ingress)
– Authentication Service
– Order Service
– calls: User Service
– calls: Inventory Service
– calls: Payment Service
– calls: Notification Service
– Load Balancer
– Service Mesh (Istio/Linkerd)
# 每个服务都可能返回不同的状态码
status_codes_chain:
– API Gateway: 200
– Authentication Service: 401 (token expired)
– Order Service: 500 (dependency failed)
– User Service: 404 (user not found)
– Inventory Service: 409 (insufficient stock)
– Payment Service: 422 (payment failed)
– Notification Service: 503 (service unavailable)
33.1.2 状态码传播原则
java
// 微服务状态码传播的核心原则
public class StatusCodePropagationPrinciples {
// 原则1: 透明的错误传播
public static class TransparentPropagation {
// 错误应该尽可能透明地传播到调用链的上游
// 但同时需要避免敏感信息泄露
}
// 原则2: 上下文完整性
public static class ContextIntegrity {
// 每个错误都应该携带完整的调用链上下文
// 包括服务名称、调用路径、时间戳等
}
// 原则3: 降级策略
public static class GracefulDegradation {
// 部分服务的失败不应该导致整个系统崩溃
// 需要实现优雅的降级策略
}
// 原则4: 可追溯性
public static class Traceability {
// 每个状态码都应该能够追溯到具体的服务和操作
}
}
33.2 服务间状态码传播模式
33.2.1 直接传播模式
go
// Go语言实现的状态码直接传播
package main
import (
"context"
"encoding/json"
"fmt"
"net/http"
"time"
"github.com/opentracing/opentracing-go"
"go.uber.org/zap"
)
// 直接传播中间件
func DirectPropagationMiddleware(next http.Handler) http.Handler {
return http.HandlerFunc(func(w http.ResponseWriter, r *http.Request) {
// 1. 从上游服务接收请求上下文
ctx := r.Context()
// 2. 提取上游的状态码信息
upstreamStatusCode := r.Header.Get("X-Upstream-Status-Code")
upstreamService := r.Header.Get("X-Upstream-Service")
// 3. 创建响应包装器以捕获状态码
rw := &responseWriter{ResponseWriter: w}
// 4. 处理请求
next.ServeHTTP(rw, r)
// 5. 向下游传播状态码
if rw.statusCode >= 400 {
// 记录错误上下文
logErrorContext(r, upstreamStatusCode, upstreamService, rw.statusCode)
// 设置响应头,为可能的下游服务提供上下文
w.Header().Set("X-Error-Propagated", "true")
w.Header().Set("X-Failed-Service", getServiceName())
// 如果有上游服务,记录调用链
if upstreamService != "" {
w.Header().Set("X-Error-Chain",
fmt.Sprintf("%s->%s:%d",
upstreamService, getServiceName(), rw.statusCode))
}
}
})
}
// 响应包装器
type responseWriter struct {
http.ResponseWriter
statusCode int
wroteHeader bool
}
func (rw *responseWriter) WriteHeader(code int) {
if !rw.wroteHeader {
rw.statusCode = code
rw.ResponseWriter.WriteHeader(code)
rw.wroteHeader = true
}
}
func (rw *responseWriter) Write(b []byte) (int, error) {
if !rw.wroteHeader {
rw.WriteHeader(http.StatusOK)
}
return rw.ResponseWriter.Write(b)
}
// 日志记录错误上下文
func logErrorContext(r *http.Request, upstreamCode, upstreamService string, currentCode int) {
logger := zap.L()
errorContext := map[string]interface{}{
"timestamp": time.Now().UTC(),
"request_id": r.Header.Get("X-Request-ID"),
"trace_id": r.Header.Get("X-Trace-ID"),
"current_service": getServiceName(),
"current_status": currentCode,
"upstream_service": upstreamService,
"upstream_status": upstreamCode,
"endpoint": r.URL.Path,
"method": r.Method,
"user_agent": r.UserAgent(),
"client_ip": getClientIP(r),
}
// 添加分布式追踪信息
if span := opentracing.SpanFromContext(r.Context()); span != nil {
errorContext["span_id"] = fmt.Sprintf("%v", span)
}
logger.Error("Service error with propagation context",
zap.Any("context", errorContext))
}
// HTTP客户端支持状态码传播
type PropagatingHTTPClient struct {
client *http.Client
serviceName string
}
func NewPropagatingHTTPClient(serviceName string) *PropagatingHTTPClient {
return &PropagatingHTTPClient{
client: &http.Client{
Timeout: 30 * time.Second,
Transport: &http.Transport{
MaxIdleConns: 100,
MaxIdleConnsPerHost: 10,
IdleConnTimeout: 90 * time.Second,
},
},
serviceName: serviceName,
}
}
func (c *PropagatingHTTPClient) Do(req *http.Request) (*http.Response, error) {
// 添加传播头
req.Header.Set("X-Caller-Service", c.serviceName)
req.Header.Set("X-Caller-Request-ID", req.Header.Get("X-Request-ID"))
// 执行请求
resp, err := c.client.Do(req)
if err != nil {
return nil, fmt.Errorf("HTTP request failed: %w", err)
}
// 如果响应是错误,记录传播信息
if resp.StatusCode >= 400 {
errorChain := resp.Header.Get("X-Error-Chain")
if errorChain == "" {
resp.Header.Set("X-Error-Chain",
fmt.Sprintf("%s:%d", c.serviceName, resp.StatusCode))
} else {
resp.Header.Set("X-Error-Chain",
fmt.Sprintf("%s->%s:%d", errorChain, c.serviceName, resp.StatusCode))
}
}
return resp, nil
}
33.2.2 聚合传播模式
python
# Python聚合传播实现
from typing import Dict, List, Optional, Any, Tuple
from dataclasses import dataclass, asdict
import json
import time
from enum import Enum
import logging
from concurrent.futures import ThreadPoolExecutor, as_completed
logger = logging.getLogger(__name__)
class ErrorSeverity(Enum):
CRITICAL = 100 # 5xx errors
ERROR = 200 # 4xx errors that affect user
WARNING = 300 # 4xx errors that don't affect user
INFO = 400 # 2xx with warnings
@dataclass
class ServiceError:
service: str
status_code: int
message: str
endpoint: str
timestamp: float
severity: ErrorSeverity
retryable: bool
dependencies: List[str] = None
def to_dict(self) -> Dict:
return {
**asdict(self),
'severity': self.severity.value,
'timestamp': time.strftime('%Y-%m-%d %H:%M:%S',
time.localtime(self.timestamp))
}
class StatusCodeAggregator:
def __init__(self, service_name: str):
self.service_name = service_name
self.errors: List[ServiceError] = []
self.successes: List[Dict] = []
def add_service_result(self, service: str, status_code: int,
message: str, endpoint: str,
retryable: bool = False):
"""添加服务调用结果"""
# 确定错误严重性
if 500 <= status_code < 600:
severity = ErrorSeverity.CRITICAL
elif status_code == 401 or status_code == 403:
severity = ErrorSeverity.ERROR
elif 400 <= status_code < 500:
severity = ErrorSeverity.WARNING
elif 200 <= status_code < 300:
severity = ErrorSeverity.INFO
else:
severity = ErrorSeverity.WARNING
error = ServiceError(
service=service,
status_code=status_code,
message=message,
endpoint=endpoint,
timestamp=time.time(),
severity=severity,
retryable=retryable
)
if status_code >= 400:
self.errors.append(error)
else:
self.successes.append(error.to_dict())
return error
def aggregate_status_code(self) -> Tuple[int, Dict[str, Any]]:
"""聚合多个服务的状态码"""
if not self.errors:
return 200, {
'status': 'success',
'data': self.successes,
'timestamp': time.time()
}
# 按严重性排序错误
self.errors.sort(key=lambda x: x.severity.value)
# 获取最高严重性的错误
primary_error = self.errors[0]
# 确定最终状态码
final_status_code = self._determine_final_status_code()
# 构建响应
response = {
'status': 'partial_failure' if len(self.errors) < len(self.errors) + len(self.successes) else 'failure',
'error': {
'code': f"AGGREGATED_ERROR_{final_status_code}",
'message': self._generate_aggregated_message(),
'timestamp': time.time(),
'details': {
'primary_error': primary_error.to_dict(),
'all_errors': [e.to_dict() for e in self.errors],
'successful_calls': self.successes,
'aggregation_strategy': 'highest_severity'
}
}
}
return final_status_code, response
def _determine_final_status_code(self) -> int:
"""根据聚合策略确定最终状态码"""
# 策略1: 如果有5xx错误,返回500
if any(e.severity == ErrorSeverity.CRITICAL for e in self.errors):
return 500
# 策略2: 如果有用户相关的4xx错误,返回最相关的那个
user_errors = [e for e in self.errors
if e.severity == ErrorSeverity.ERROR]
if user_errors:
# 优先返回认证/授权错误
for error in user_errors:
if error.status_code in [401, 403]:
return error.status_code
# 否则返回第一个用户错误
return user_errors[0].status_code
# 策略3: 返回第一个警告级别的错误
return self.errors[0].status_code
def _generate_aggregated_message(self) -> str:
"""生成聚合错误消息"""
if len(self.errors) == 1:
return f"Service {self.errors[0].service} failed: {self.errors[0].message}"
error_count = len(self.errors)
critical_count = sum(1 for e in self.errors
if e.severity == ErrorSeverity.CRITICAL)
if critical_count > 0:
return f"{critical_count} critical service(s) failed out of {error_count} errors"
return f"{error_count} service(s) reported errors"
# 使用示例:订单处理服务
class OrderProcessingService:
def __init__(self):
self.aggregator = StatusCodeAggregator("order-service")
def process_order(self, order_data: Dict) -> Tuple[int, Dict]:
"""处理订单,调用多个微服务"""
# 并行调用多个服务
with ThreadPoolExecutor(max_workers=4) as executor:
futures = {
executor.submit(self._validate_user, order_data['user_id']): 'user-service',
executor.submit(self._check_inventory, order_data['items']): 'inventory-service',
executor.submit(self._calculate_shipping, order_data['address']): 'shipping-service',
executor.submit(self._validate_payment, order_data['payment']): 'payment-service'
}
for future in as_completed(futures):
service_name = futures[future]
try:
status_code, message = future.result(timeout=10)
self.aggregator.add_service_result(
service_name, status_code, message,
f"/api/{service_name.replace('-', '/')}"
)
except TimeoutError:
self.aggregator.add_service_result(
service_name, 504, "Service timeout",
f"/api/{service_name.replace('-', '/')}",
retryable=True
)
except Exception as e:
self.aggregator.add_service_result(
service_name, 500, str(e),
f"/api/{service_name.replace('-', '/')}",
retryable=True
)
# 聚合结果
final_status, response = self.aggregator.aggregate_status_code()
# 如果所有必需服务都成功,创建订单
if final_status == 200:
order_result = self._create_order(order_data)
response['data']['order'] = order_result
return final_status, response
def _validate_user(self, user_id: str) -> Tuple[int, str]:
# 调用用户服务
# 返回 (status_code, message)
pass
def _check_inventory(self, items: List) -> Tuple[int, str]:
# 调用库存服务
pass
def _calculate_shipping(self, address: Dict) -> Tuple[int, str]:
# 调用物流服务
pass
def _validate_payment(self, payment: Dict) -> Tuple[int, str]:
# 调用支付服务
pass
def _create_order(self, order_data: Dict) -> Dict:
# 创建订单
pass
33.3 分布式追踪与状态码
33.3.1 OpenTelemetry集成
typescript
// TypeScript OpenTelemetry集成
import { NodeTracerProvider } from '@opentelemetry/node';
import { SimpleSpanProcessor } from '@opentelemetry/tracing';
import { JaegerExporter } from '@opentelemetry/exporter-jaeger';
import { ZipkinExporter } from '@opentelemetry/exporter-zipkin';
import { context, Span, SpanStatusCode } from '@opentelemetry/api';
import { HttpInstrumentation } from '@opentelemetry/instrumentation-http';
import { ExpressInstrumentation } from '@opentelemetry/instrumentation-express';
import { Resource } from '@opentelemetry/resources';
import { SemanticResourceAttributes } from '@opentelemetry/semantic-conventions';
// 配置追踪提供商
const provider = new NodeTracerProvider({
resource: new Resource({
[SemanticResourceAttributes.SERVICE_NAME]: process.env.SERVICE_NAME || 'unknown-service',
[SemanticResourceAttributes.DEPLOYMENT_ENVIRONMENT]: process.env.NODE_ENV || 'development',
}),
});
// 添加导出器
const jaegerExporter = new JaegerExporter({
endpoint: process.env.JAEGER_ENDPOINT || 'http://localhost:14268/api/traces',
});
const zipkinExporter = new ZipkinExporter({
url: process.env.ZIPKIN_ENDPOINT || 'http://localhost:9411/api/v2/spans',
});
provider.addSpanProcessor(new SimpleSpanProcessor(jaegerExporter));
provider.addSpanProcessor(new SimpleSpanProcessor(zipkinExporter));
// 注册提供商
provider.register();
// 仪表化HTTP和Express
const httpInstrumentation = new HttpInstrumentation();
const expressInstrumentation = new ExpressInstrumentation();
// 状态码追踪中间件
export function statusCodeTracingMiddleware(req: any, res: any, next: Function) {
const tracer = provider.getTracer('http-server');
const span = tracer.startSpan(`${req.method} ${req.path}`, {
attributes: {
'http.method': req.method,
'http.url': req.url,
'http.route': req.path,
'http.user_agent': req.get('user-agent'),
'http.client_ip': req.ip,
},
});
// 将span存储在上下文中
const ctx = context.active();
context.bind(ctx, span);
// 存储span在请求对象上以便后续访问
req.span = span;
// 监听响应完成
const originalEnd = res.end;
res.end = function(…args: any[]) {
// 记录状态码
span.setAttribute('http.status_code', res.statusCode);
span.setAttribute('http.status_text', res.statusMessage);
// 根据状态码设置span状态
if (res.statusCode >= 400) {
span.setStatus({
code: SpanStatusCode.ERROR,
message: `HTTP ${res.statusCode}`,
});
// 添加错误属性
span.setAttribute('error', true);
span.setAttribute('error.type', `HTTP_${res.statusCode}`);
// 如果有错误信息,记录它
if (res.locals.error) {
span.setAttribute('error.message', res.locals.error.message);
span.recordException(res.locals.error);
}
} else {
span.setStatus({ code: SpanStatusCode.OK });
}
// 记录响应大小
const contentLength = res.get('content-length');
if (contentLength) {
span.setAttribute('http.response_size', parseInt(contentLength));
}
// 记录持续时间
const startTime = req._startTime || Date.now();
const duration = Date.now() – startTime;
span.setAttribute('http.duration_ms', duration);
// 结束span
span.end();
// 调用原始的end方法
return originalEnd.apply(this, args);
};
// 记录请求开始时间
req._startTime = Date.now();
next();
}
// HTTP客户端仪表化
export class TracedHttpClient {
private tracer: any;
constructor(private baseURL: string, serviceName: string) {
this.tracer = provider.getTracer(serviceName);
}
async request<T>(
method: string,
path: string,
data?: any,
options: any = {}
): Promise<{ status: number; data: T; headers: any }> {
const span = this.tracer.startSpan(`${method} ${path}`, {
attributes: {
'http.method': method,
'http.url': `${this.baseURL}${path}`,
'peer.service': this.baseURL.replace(/https?:\\/\\//, ''),
},
});
try {
const url = `${this.baseURL}${path}`;
const headers = {
'Content-Type': 'application/json',
…options.headers,
};
// 传播追踪上下文
const carrier: any = {};
const ctx = context.active();
const activeSpan = context.getActiveSpan();
if (activeSpan) {
const traceparent = activeSpan.spanContext().traceId;
headers['traceparent'] = `00-${traceparent}-${span.spanContext().spanId}-01`;
headers['tracestate'] = activeSpan.spanContext().traceState?.serialize();
}
const response = await fetch(url, {
method,
headers,
body: data ? JSON.stringify(data) : undefined,
…options,
});
// 记录响应信息
span.setAttribute('http.status_code', response.status);
span.setAttribute('http.status_text', response.statusText);
const responseData = await response.json().catch(() => null);
// 根据状态码设置span状态
if (response.status >= 400) {
span.setStatus({
code: SpanStatusCode.ERROR,
message: `HTTP ${response.status}`,
});
// 记录错误详情
span.setAttribute('error', true);
span.setAttribute('error.type', `HTTP_${response.status}`);
if (responseData?.error) {
span.setAttribute('error.message', responseData.error.message);
}
} else {
span.setStatus({ code: SpanStatusCode.OK });
}
// 记录响应头中的追踪信息
const serverTraceId = response.headers.get('x-trace-id');
if (serverTraceId) {
span.setAttribute('peer.trace_id', serverTraceId);
}
return {
status: response.status,
data: responseData,
headers: Object.fromEntries(response.headers.entries()),
};
} catch (error: any) {
// 记录异常
span.setStatus({
code: SpanStatusCode.ERROR,
message: error.message,
});
span.recordException(error);
span.setAttribute('error', true);
span.setAttribute('error.type', 'NETWORK_ERROR');
throw error;
} finally {
span.end();
}
}
// 批量请求追踪
async batchRequest<T>(
requests: Array<{ method: string; path: string; data?: any }>
): Promise<Array<{ status: number; data: T; error?: any }>> {
const batchSpan = this.tracer.startSpan('batch_request', {
attributes: {
'batch.request_count': requests.length,
'batch.service': this.baseURL,
},
});
try {
const results = await Promise.all(
requests.map(async (req) => {
const span = this.tracer.startSpan(`${req.method} ${req.path}`, {
attributes: {
'http.method': req.method,
'http.url': `${this.baseURL}${req.path}`,
},
});
try {
const result = await this.request<T>(req.method, req.path, req.data);
span.setAttribute('http.status_code', result.status);
if (result.status >= 400) {
span.setStatus({ code: SpanStatusCode.ERROR });
} else {
span.setStatus({ code: SpanStatusCode.OK });
}
return result;
} catch (error: any) {
span.setStatus({
code: SpanStatusCode.ERROR,
message: error.message,
});
span.recordException(error);
return {
status: 500,
data: null as any,
error: error.message,
};
} finally {
span.end();
}
})
);
// 统计批量结果
const successCount = results.filter(r => r.status < 400).length;
const errorCount = results.length – successCount;
batchSpan.setAttribute('batch.success_count', successCount);
batchSpan.setAttribute('batch.error_count', errorCount);
if (errorCount > 0) {
batchSpan.setStatus({
code: SpanStatusCode.ERROR,
message: `${errorCount} requests failed in batch`,
});
} else {
batchSpan.setStatus({ code: SpanStatusCode.OK });
}
return results;
} finally {
batchSpan.end();
}
}
}
// 状态码分析中间件
export function statusCodeAnalyticsMiddleware(req: any, res: any, next: Function) {
const tracer = provider.getTracer('analytics');
const span = tracer.startSpan('status_code_analysis', {
attributes: {
'analysis.type': 'status_code_distribution',
'service.name': process.env.SERVICE_NAME,
},
});
// 收集指标
const metrics = {
request_count: 0,
status_2xx: 0,
status_3xx: 0,
status_4xx: 0,
status_5xx: 0,
errors_by_code: {} as Record<string, number>,
avg_response_time: 0,
};
// 监听响应完成
const originalEnd = res.end;
res.end = function(…args: any[]) {
metrics.request_count++;
// 分类状态码
if (res.statusCode >= 200 && res.statusCode < 300) {
metrics.status_2xx++;
} else if (res.statusCode >= 300 && res.statusCode < 400) {
metrics.status_3xx++;
} else if (res.statusCode >= 400 && res.statusCode < 500) {
metrics.status_4xx++;
metrics.errors_by_code[res.statusCode] =
(metrics.errors_by_code[res.statusCode] || 0) + 1;
} else if (res.statusCode >= 500) {
metrics.status_5xx++;
metrics.errors_by_code[res.statusCode] =
(metrics.errors_by_code[res.statusCode] || 0) + 1;
}
// 记录响应时间
const startTime = req._startTime || Date.now();
const duration = Date.now() – startTime;
// 更新平均响应时间
metrics.avg_response_time =
(metrics.avg_response_time * (metrics.request_count – 1) + duration) /
metrics.request_count;
// 更新span属性
span.setAttributes({
'analysis.request_count': metrics.request_count,
'analysis.status_2xx': metrics.status_2xx,
'analysis.status_3xx': metrics.status_3xx,
'analysis.status_4xx': metrics.status_4xx,
'analysis.status_5xx': metrics.status_5xx,
'analysis.avg_response_time_ms': metrics.avg_response_time,
…Object.entries(metrics.errors_by_code).reduce((acc, [code, count]) => ({
…acc,
[`analysis.errors.${code}`]: count,
}), {}),
});
// 如果错误率过高,记录警告
const errorRate = (metrics.status_4xx + metrics.status_5xx) / metrics.request_count;
if (errorRate > 0.1 && metrics.request_count > 10) {
span.setStatus({
code: SpanStatusCode.ERROR,
message: `High error rate: ${(errorRate * 100).toFixed(1)}%`,
});
span.setAttribute('analysis.high_error_rate', true);
span.setAttribute('analysis.error_rate', errorRate);
}
return originalEnd.apply(this, args);
};
// 定期提交指标
const interval = setInterval(() => {
if (metrics.request_count > 0) {
span.addEvent('metrics_snapshot', metrics);
// 重置计数器(保留错误分布)
metrics.request_count = 0;
metrics.status_2xx = 0;
metrics.status_3xx = 0;
metrics.status_4xx = 0;
metrics.status_5xx = 0;
metrics.avg_response_time = 0;
}
}, 60000); // 每分钟提交一次
// 清理定时器
req.on('close', () => {
clearInterval(interval);
span.end();
});
next();
}
33.3.2 Jaeger追踪可视化
yaml
# jaeger-service-map.yaml
# Jaeger服务依赖图配置
service_dependencies:
enabled: true
storage: elasticsearch
# 状态码相关的标签
tags:
– "http.status_code"
– "error"
– "span.kind"
# 服务级别指标
metrics:
– name: "error_rate"
query: "sum(rate(http_server_requests_seconds_count{status=~\\"4..|5..\\"}[5m])) / sum(rate(http_server_requests_seconds_count[5m]))"
threshold: 0.05
severity: "warning"
– name: "p95_latency"
query: "histogram_quantile(0.95, rate(http_server_requests_seconds_bucket[5m]))"
threshold: 1.0
severity: "warning"
# 状态码分布仪表板
dashboard:
panels:
– title: "Status Code Distribution"
type: "heatmap"
query: "sum(rate(http_server_requests_seconds_count[5m])) by (status, service)"
– title: "Error Propagation Chain"
type: "graph"
query: |
trace_id, span_id, parent_id,
operationName, serviceName,
tags.http.status_code as status_code,
tags.error as error
filter: "tags.http.status_code >= 400"
– title: "Service Dependency Health"
type: "dependency_graph"
nodes:
– service: "api-gateway"
health: "sum(rate(http_server_requests_seconds_count{service=\\"api-gateway\\", status=~\\"2..\\"}[5m])) / sum(rate(http_server_requests_seconds_count{service=\\"api-gateway\\"}[5m]))"
– service: "order-service"
health: "sum(rate(http_server_requests_seconds_count{service=\\"order-service\\", status=~\\"2..\\"}[5m])) / sum(rate(http_server_requests_seconds_count{service=\\"order-service\\"}[5m]))"
– service: "payment-service"
health: "sum(rate(http_server_requests_seconds_count{service=\\"payment-service\\", status=~\\"2..\\"}[5m])) / sum(rate(http_server_requests_seconds_count{service=\\"payment-service\\"}[5m]))"
33.4 断路器与状态码处理
33.4.1 Resilience4j断路器
java
// Java Resilience4j断路器配置
@Configuration
public class CircuitBreakerConfiguration {
private final MeterRegistry meterRegistry;
private final Tracer tracer;
public CircuitBreakerConfiguration(MeterRegistry meterRegistry,
Tracer tracer) {
this.meterRegistry = meterRegistry;
this.tracer = tracer;
}
@Bean
public CircuitBreakerRegistry circuitBreakerRegistry() {
CircuitBreakerConfig config = CircuitBreakerConfig.custom()
// 基于状态码的失败判断
.recordExceptions(
HttpClientErrorException.class, // 4xx
HttpServerErrorException.class, // 5xx
TimeoutException.class,
IOException.class
)
.ignoreExceptions(
// 忽略某些特定的4xx错误,如404(资源不存在)
NotFoundException.class
)
// 滑动窗口配置
.slidingWindowType(SlidingWindowType.COUNT_BASED)
.slidingWindowSize(100)
// 失败率阈值
.failureRateThreshold(50)
// 慢调用阈值
.slowCallRateThreshold(30)
.slowCallDurationThreshold(Duration.ofSeconds(2))
// 半开状态配置
.permittedNumberOfCallsInHalfOpenState(10)
.maxWaitDurationInHalfOpenState(Duration.ofSeconds(10))
// 自动从开启状态转换
.automaticTransitionFromOpenToHalfOpenEnabled(true)
.waitDurationInOpenState(Duration.ofSeconds(30))
.build();
CircuitBreakerRegistry registry = CircuitBreakerRegistry.of(config);
// 添加指标
TaggedCircuitBreakerMetrics.ofCircuitBreakerRegistry(registry)
.bindTo(meterRegistry);
return registry;
}
@Bean
public RetryRegistry retryRegistry() {
RetryConfig config = RetryConfig.custom()
.maxAttempts(3)
.waitDuration(Duration.ofMillis(500))
.intervalFunction(IntervalFunction.ofExponentialBackoff())
.retryOnException(e -> {
// 只在特定状态码下重试
if (e instanceof HttpClientErrorException) {
HttpClientErrorException ex = (HttpClientErrorException) e;
return ex.getStatusCode().is5xxServerError() ||
ex.getStatusCode() == HttpStatus.REQUEST_TIMEOUT ||
ex.getStatusCode() == HttpStatus.TOO_MANY_REQUESTS;
}
return e instanceof IOException ||
e instanceof TimeoutException;
})
.failAfterMaxAttempts(true)
.build();
return RetryRegistry.of(config);
}
@Bean
public BulkheadRegistry bulkheadRegistry() {
BulkheadConfig config = BulkheadConfig.custom()
.maxConcurrentCalls(100)
.maxWaitDuration(Duration.ofMillis(500))
.build();
return BulkheadRegistry.of(config);
}
// 状态码感知的断路器装饰器
@Bean
public RestTemplate statusCodeAwareRestTemplate(
CircuitBreakerRegistry circuitBreakerRegistry,
RetryRegistry retryRegistry,
BulkheadRegistry bulkheadRegistry) {
RestTemplate restTemplate = new RestTemplate();
// 添加拦截器
restTemplate.getInterceptors().add((request, body, execution) -> {
String serviceName = extractServiceName(request.getURI());
// 获取或创建断路器
CircuitBreaker circuitBreaker = circuitBreakerRegistry
.circuitBreaker(serviceName, serviceName);
Retry retry = retryRegistry.retry(serviceName, serviceName);
Bulkhead bulkhead = bulkheadRegistry.bulkhead(serviceName, serviceName);
// 创建追踪span
Span span = tracer.buildSpan("http_request")
.withTag("http.method", request.getMethod().name())
.withTag("http.url", request.getURI().toString())
.withTag("peer.service", serviceName)
.start();
try (Scope scope = tracer.activateSpan(span)) {
// 使用Resilience4j装饰调用
Supplier<ClientHttpResponse> supplier = () -> {
try {
return execution.execute(request, body);
} catch (IOException e) {
throw new RuntimeException(e);
}
};
// 组合 Resilience4j 装饰器
Supplier<ClientHttpResponse> decoratedSupplier = Decorators.ofSupplier(supplier)
.withCircuitBreaker(circuitBreaker)
.withRetry(retry)
.withBulkhead(bulkhead)
.decorate();
ClientHttpResponse response = decoratedSupplier.get();
// 记录状态码
span.setTag("http.status_code", response.getRawStatusCode());
if (response.getRawStatusCode() >= 400) {
span.setTag("error", true);
span.log(Map.of(
"event", "error",
"message", "HTTP error response",
"status_code", response.getRawStatusCode(),
"status_text", response.getStatusText()
));
// 根据状态码决定是否应该触发断路器
if (response.getRawStatusCode() >= 500) {
// 5xx错误应该被记录为失败
circuitBreaker.onError(
response.getRawStatusCode(),
new HttpServerErrorException(
response.getStatusCode(),
response.getStatusText()
)
);
} else if (response.getRawStatusCode() == 429) {
// 429 Too Many Requests,可能应该等待
circuitBreaker.onError(
response.getRawStatusCode(),
new HttpClientErrorException(
response.getStatusCode(),
response.getStatusText()
)
);
}
} else {
circuitBreaker.onSuccess(
response.getRawStatusCode(),
response.getStatusCode()
);
}
return response;
} catch (Exception e) {
span.setTag("error", true);
span.log(Map.of(
"event", "error",
"message", e.getMessage(),
"error.object", e.getClass().getName()
));
// 记录到断路器
circuitBreaker.onError(
-1, // 未知状态码
e
);
throw e;
} finally {
span.finish();
}
});
return restTemplate;
}
private String extractServiceName(URI uri) {
return uri.getHost();
}
}
// 状态码感知的断路器监控
@Component
public class CircuitBreakerMonitor {
private final CircuitBreakerRegistry circuitBreakerRegistry;
private final MeterRegistry meterRegistry;
private final Map<String, CircuitBreaker.State> previousStates = new ConcurrentHashMap<>();
public CircuitBreakerMonitor(CircuitBreakerRegistry circuitBreakerRegistry,
MeterRegistry meterRegistry) {
this.circuitBreakerRegistry = circuitBreakerRegistry;
this.meterRegistry = meterRegistry;
// 定期监控断路器状态
ScheduledExecutorService scheduler = Executors.newSingleThreadScheduledExecutor();
scheduler.scheduleAtFixedRate(this::monitorCircuitBreakers,
0, 10, TimeUnit.SECONDS);
}
private void monitorCircuitBreakers() {
circuitBreakerRegistry.getAllCircuitBreakers().forEach((name, cb) -> {
CircuitBreaker.Metrics metrics = cb.getMetrics();
CircuitBreaker.State currentState = cb.getState();
// 记录指标
Gauge.builder("circuitbreaker.state", cb,
circuitBreaker -> circuitBreaker.getState().getOrder())
.tag("name", name)
.register(meterRegistry);
Counter.builder("circuitbreaker.transitions")
.tag("name", name)
.tag("from", previousStates.getOrDefault(name, CircuitBreaker.State.CLOSED).name())
.tag("to", currentState.name())
.register(meterRegistry)
.increment();
// 记录基于状态码的失败统计
Map<Integer, Long> statusCodeFailures = getStatusCodeFailures(name);
statusCodeFailures.forEach((statusCode, count) -> {
Counter.builder("circuitbreaker.failures_by_status")
.tag("name", name)
.tag("status_code", String.valueOf(statusCode))
.register(meterRegistry)
.increment(count);
});
// 状态变更通知
if (previousStates.containsKey(name) &&
previousStates.get(name) != currentState) {
logStateChange(name, previousStates.get(name), currentState, metrics);
// 发送告警
if (currentState == CircuitBreaker.State.OPEN) {
sendAlert(name, "Circuit breaker OPENED", metrics);
} else if (currentState == CircuitBreaker.State.HALF_OPEN) {
sendAlert(name, "Circuit breaker HALF_OPEN", metrics);
} else if (currentState == CircuitBreaker.State.CLOSED &&
previousStates.get(name) == CircuitBreaker.State.OPEN) {
sendAlert(name, "Circuit breaker CLOSED", metrics);
}
}
previousStates.put(name, currentState);
});
}
private Map<Integer, Long> getStatusCodeFailures(String circuitBreakerName) {
// 这里应该从断路器的事件流中提取基于状态码的失败统计
// 实际实现可能需要自定义事件处理器
return new HashMap<>();
}
private void logStateChange(String name, CircuitBreaker.State from,
CircuitBreaker.State to, CircuitBreaker.Metrics metrics) {
logger.info("Circuit breaker state changed: {} {} -> {} (failureRate: {}%)",
name, from, to,
metrics.getFailureRate());
}
private void sendAlert(String circuitBreakerName, String message,
CircuitBreaker.Metrics metrics) {
// 发送告警到监控系统
Map<String, Object> alert = Map.of(
"circuit_breaker", circuitBreakerName,
"message", message,
"failure_rate", metrics.getFailureRate(),
"slow_call_rate", metrics.getSlowCallRate(),
"timestamp", Instant.now().toString()
);
// 发送到监控系统
// monitoringService.sendAlert(alert);
}
}
33.5 API网关中的状态码处理
33.5.1 Kong网关配置
yaml
# kong-status-code-handling.yaml
_format_version: "2.1"
_transform: true
# 服务定义
services:
– name: order-service
url: http://order-service:8080
routes:
– name: order-routes
paths:
– /orders
– /orders/
strip_path: true
# 插件配置
plugins:
# 1. 请求转换插件
– name: request-transformer
config:
add:
headers:
– "X-Request-ID:$ {request_id}"
– "X-Client-IP:$ {real_ip_remote_addr}"
– "X-Forwarded-For:$ {proxy_add_x_forwarded_for}"
# 2. 响应转换插件
– name: response-transformer
config:
add:
headers:
– "X-Service-Name:order-service"
– "X-Response-Time:$ {latency}"
remove:
headers:
– "Server"
– "X-Powered-By"
# 3. 状态码重写插件
– name: status-code-rewrite
enabled: true
config:
rules:
# 将特定的后端错误转换为标准错误
– backend_status: 502
gateway_status: 503
message: "Service temporarily unavailable"
body: '{"error":{"code":"SERVICE_UNAVAILABLE","message":"The service is temporarily unavailable"}}'
– backend_status: 504
gateway_status: 503
message: "Service timeout"
body: '{"error":{"code":"TIMEOUT","message":"The service did not respond in time"}}'
# 隐藏内部错误详情
– backend_status: 500
gateway_status: 500
message: "Internal server error"
body: '{"error":{"code":"INTERNAL_ERROR","message":"An internal server error occurred"}}'
hide_details: true
# 4. 断路器插件
– name: circuit-breaker
config:
window_size: 60
window_type: sliding
failure_threshold: 5
unhealthy:
http_statuses:
– 500
– 502
– 503
– 504
tcp_failures: 2
timeouts: 3
healthy:
http_statuses:
– 200
– 201
– 202
successes: 1
healthcheck:
active:
type: http
http_path: /health
timeout: 5
concurrency: 10
healthy:
interval: 30
http_statuses:
– 200
– 302
successes: 2
unhealthy:
interval: 30
http_statuses:
– 429
– 500
– 503
tcp_failures: 2
timeouts: 3
http_failures: 2
passive:
type: http
healthy:
http_statuses:
– 200
– 201
– 202
– 203
– 204
– 205
– 206
– 207
– 208
– 226
successes: 5
unhealthy:
http_statuses:
– 500
– 502
– 503
– 504
tcp_failures: 2
timeouts: 7
http_failures: 5
# 全局插件
plugins:
– name: correlation-id
config:
header_name: X-Request-ID
generator: uuid
echo_downstream: true
– name: prometheus
config:
status_code_metrics: true
latency_metrics: true
bandwidth_metrics: true
upstream_health_metrics: true
– name: zipkin
config:
http_endpoint: http://zipkin:9411/api/v2/spans
sample_ratio: 1
include_credential: true
traceid_byte_count: 16
header_type: preserve
# 全局错误处理器
– name: error-handler
config:
default_response:
status_code: 500
content_type: application/json
body: '{"error":{"code":"INTERNAL_ERROR","message":"An unexpected error occurred"}}'
custom_responses:
– status_code: 404
content_type: application/json
body: '{"error":{"code":"NOT_FOUND","message":"The requested resource was not found"}}'
– status_code: 429
content_type: application/json
headers:
Retry-After: "60"
body: '{"error":{"code":"RATE_LIMITED","message":"Too many requests, please try again later"}}'
– status_code: 503
content_type: application/json
headers:
Retry-After: "30"
body: '{"error":{"code":"SERVICE_UNAVAILABLE","message":"Service is temporarily unavailable"}}'
# 上游健康检查
upstreams:
– name: order-service-upstream
algorithm: round-robin
healthchecks:
active:
type: http
http_path: /health
timeout: 5
healthy:
interval: 30
http_statuses:
– 200
– 302
successes: 2
unhealthy:
interval: 30
http_statuses:
– 429
– 500
– 503
tcp_failures: 2
timeouts: 3
http_failures: 2
passive:
healthy:
http_statuses:
– 200
– 201
– 202
– 203
– 204
– 205
– 206
– 207
– 208
– 226
successes: 5
unhealthy:
http_statuses:
– 500
– 502
– 503
– 504
tcp_failures: 2
timeouts: 7
http_failures: 5
targets:
– target: order-service-1:8080
weight: 100
– target: order-service-2:8080
weight: 100
33.5.2 Envoy代理配置
yaml
# envoy-status-code-config.yaml
static_resources:
listeners:
– name: api_listener
address:
socket_address:
address: 0.0.0.0
port_value: 8080
filter_chains:
– filters:
– name: envoy.filters.network.http_connection_manager
typed_config:
"@type": type.googleapis.com/envoy.extensions.filters.network.http_connection_manager.v3.HttpConnectionManager
stat_prefix: ingress_http
route_config:
name: local_route
virtual_hosts:
– name: api
domains: ["*"]
routes:
– match:
prefix: "/orders"
route:
cluster: order_service
timeout: 30s
retry_policy:
retry_on: "5xx,gateway-error,connect-failure,retriable-4xx"
num_retries: 3
per_try_timeout: 10s
retry_back_off:
base_interval: 0.1s
max_interval: 10s
# 状态码重写
upgrade_configs:
– upgrade_type: "websocket"
# HTTP过滤器
http_filters:
# 1. 状态码重写过滤器
– name: envoy.filters.http.status_code_rewrite
typed_config:
"@type": type.googleapis.com/envoy.extensions.filters.http.status_code_rewrite.v3.StatusCodeRewrite
rules:
– upstream_status: "502"
gateway_status: "503"
headers_to_add:
– header:
key: "X-Status-Reason"
value: "Bad Gateway converted to Service Unavailable"
– upstream_status: "504"
gateway_status: "503"
headers_to_add:
– header:
key: "X-Status-Reason"
value: "Gateway Timeout converted to Service Unavailable"
# 2. 断路器过滤器
– name: envoy.filters.http.circuit_breaker
typed_config:
"@type": type.googleapis.com/envoy.extensions.filters.http.circuit_breaker.v3.CircuitBreaker
max_connections: 1024
max_pending_requests: 1024
max_requests: 1024
max_retries: 3
track_remaining: true
# 3. 故障注入过滤器
– name: envoy.filters.http.fault
typed_config:
"@type": type.googleapis.com/envoy.extensions.filters.http.fault.v3.HTTPFault
abort:
http_status: 503
percentage:
numerator: 5 # 5%的请求会收到503错误
denominator: HUNDRED
delay:
fixed_delay: 1s
percentage:
numerator: 10 # 10%的请求会有1秒延迟
denominator: HUNDRED
# 4. 外部授权过滤器
– name: envoy.filters.http.ext_authz
typed_config:
"@type": type.googleapis.com/envoy.extensions.filters.http.ext_authz.v3.ExtAuthz
http_service:
server_uri:
uri: auth-service:9000
cluster: auth_service
timeout: 0.25s
authorization_request:
allowed_headers:
patterns:
– exact: "content-type"
– exact: "authorization"
– exact: "x-request-id"
authorization_response:
allowed_upstream_headers:
patterns:
– exact: "x-user-id"
– exact: "x-user-role"
allowed_client_headers:
patterns:
– exact: "x-auth-status"
# 5. 速率限制过滤器
– name: envoy.filters.http.ratelimit
typed_config:
"@type": type.googleapis.com/envoy.extensions.filters.http.ratelimit.v3.RateLimit
domain: api-gateway
failure_mode_deny: false
timeout: 0.05s
rate_limit_service:
grpc_service:
envoy_grpc:
cluster_name: rate_limit_service
# 6. 路由器过滤器(必须最后一个)
– name: envoy.filters.http.router
typed_config:
"@type": type.googleapis.com/envoy.extensions.filters.http.router.v3.Router
suppress_envoy_headers: true
start_child_span: true
# 访问日志
access_log:
– name: envoy.access_loggers.file
typed_config:
"@type": type.googleapis.com/envoy.extensions.access_loggers.file.v3.FileAccessLog
path: /dev/stdout
log_format:
json_format:
timestamp: "%START_TIME%"
request_id: "%REQ(X-REQUEST-ID)%"
client_ip: "%DOWNSTREAM_REMOTE_ADDRESS%"
method: "%REQ(:METHOD)%"
path: "%REQ(X-ENVOY-ORIGINAL-PATH?:PATH)%"
protocol: "%PROTOCOL%"
response_code: "%RESPONSE_CODE%"
response_flags: "%RESPONSE_FLAGS%"
bytes_received: "%BYTES_RECEIVED%"
bytes_sent: "%BYTES_SENT%"
duration: "%DURATION%"
upstream_service_time: "%RESP(X-ENVOY-UPSTREAM-SERVICE-TIME)%"
upstream_host: "%UPSTREAM_HOST%"
upstream_cluster: "%UPSTREAM_CLUSTER%"
upstream_local_address: "%UPSTREAM_LOCAL_ADDRESS%"
downstream_local_address: "%DOWNSTREAM_LOCAL_ADDRESS%"
downstream_remote_address: "%DOWNSTREAM_REMOTE_ADDRESS%"
requested_server_name: "%REQUESTED_SERVER_NAME%"
route_name: "%ROUTE_NAME%"
# 追踪配置
tracing:
provider:
name: envoy.tracers.zipkin
typed_config:
"@type": type.googleapis.com/envoy.config.trace.v3.ZipkinConfig
collector_cluster: zipkin
collector_endpoint: "/api/v2/spans"
collector_endpoint_version: HTTP_JSON
shared_span_context: false
trace_id_128bit: true
# 集群定义
clusters:
– name: order_service
type: STRICT_DNS
lb_policy: ROUND_ROBIN
load_assignment:
cluster_name: order_service
endpoints:
– lb_endpoints:
– endpoint:
address:
socket_address:
address: order-service
port_value: 8080
circuit_breakers:
thresholds:
– priority: DEFAULT
max_connections: 1024
max_pending_requests: 1024
max_requests: 1024
max_retries: 3
– priority: HIGH
max_connections: 2048
max_pending_requests: 2048
max_requests: 2048
max_retries: 3
outlier_detection:
consecutive_5xx: 10
interval: 30s
base_ejection_time: 30s
max_ejection_percent: 50
health_checks:
– timeout: 5s
interval: 30s
unhealthy_threshold: 3
healthy_threshold: 2
http_health_check:
path: /health
expected_statuses:
start: 200
end: 299
– name: auth_service
type: STRICT_DNS
connect_timeout: 0.25s
lb_policy: ROUND_ROBIN
load_assignment:
cluster_name: auth_service
endpoints:
– lb_endpoints:
– endpoint:
address:
socket_address:
address: auth-service
port_value: 9000
– name: rate_limit_service
type: STRICT_DNS
connect_timeout: 0.05s
lb_policy: ROUND_ROBIN
http2_protocol_options: {}
load_assignment:
cluster_name: rate_limit_service
endpoints:
– lb_endpoints:
– endpoint:
address:
socket_address:
address: rate-limit-service
port_value: 8081
– name: zipkin
type: STRICT_DNS
lb_policy: ROUND_ROBIN
load_assignment:
cluster_name: zipkin
endpoints:
– lb_endpoints:
– endpoint:
address:
socket_address:
address: zipkin
port_value: 9411
# 管理接口
admin:
address:
socket_address:
address: 0.0.0.0
port_value: 9901
33.6 服务网格中的状态码传播
33.6.1 Istio服务网格配置
yaml
# istio-status-code-policies.yaml
apiVersion: networking.istio.io/v1beta1
kind: VirtualService
metadata:
name: order-service
spec:
hosts:
– order-service
http:
– match:
– uri:
prefix: /orders
route:
– destination:
host: order-service
port:
number: 8080
weight: 100
# 重试策略
retries:
attempts: 3
retryOn: "5xx,gateway-error,connect-failure,retriable-4xx"
perTryTimeout: 10s
# 超时配置
timeout: 30s
# 故障注入
fault:
abort:
percentage:
value: 0.1 # 0.1%的请求会收到503错误
httpStatus: 503
delay:
percentage:
value: 1 # 1%的请求会有100ms延迟
fixedDelay: 100ms
# 状态码重写
headers:
request:
set:
X-Request-ID: "%REQ(X-REQUEST-ID)%"
X-Client-IP: "%DOWNSTREAM_REMOTE_ADDRESS%"
response:
set:
X-Service-Version: "v1.0.0"
X-Response-Time: "%RESPONSE_DURATION%"
remove:
– "Server"
# CORS策略
corsPolicy:
allowOrigin:
– "*"
allowMethods:
– POST
– GET
– OPTIONS
– PUT
– DELETE
allowHeaders:
– content-type
– authorization
– x-request-id
maxAge: "24h"
—
apiVersion: networking.istio.io/v1beta1
kind: DestinationRule
metadata:
name: order-service
spec:
host: order-service
trafficPolicy:
# 连接池设置
connectionPool:
tcp:
maxConnections: 100
connectTimeout: 30ms
http:
http1MaxPendingRequests: 1024
http2MaxRequests: 1024
maxRequestsPerConnection: 1024
maxRetries: 3
idleTimeout: 3600s
# 负载均衡
loadBalancer:
simple: ROUND_ROBIN
# 异常检测
outlierDetection:
consecutive5xxErrors: 10
interval: 30s
baseEjectionTime: 30s
maxEjectionPercent: 50
# TLS设置
tls:
mode: ISTIO_MUTUAL
—
# 状态码监控配置
apiVersion: telemetry.istio.io/v1alpha1
kind: Telemetry
metadata:
name: status-code-metrics
spec:
metrics:
– providers:
– name: prometheus
overrides:
# 请求计数,按状态码分类
– match:
metric: REQUEST_COUNT
mode: CLIENT_AND_SERVER
tagOverrides:
response_code:
value: "%RESPONSE_CODE%"
# 请求持续时间,按状态码分类
– match:
metric: REQUEST_DURATION
mode: CLIENT_AND_SERVER
tagOverrides:
response_code:
value: "%RESPONSE_CODE%"
# 请求大小,按状态码分类
– match:
metric: REQUEST_SIZE
mode: CLIENT_AND_SERVER
tagOverrides:
response_code:
value: "%RESPONSE_CODE%"
# 响应大小,按状态码分类
– match:
metric: RESPONSE_SIZE
mode: CLIENT_AND_SERVER
tagOverrides:
response_code:
value: "%RESPONSE_CODE%"
# 自定义指标
customMetrics:
– name: error_rate_by_service
dimensions:
destination_service: "string(destination.service)"
response_code: "string(response.code)"
source_service: "string(source.service)"
value: "double(1)"
– name: latency_by_status_code
dimensions:
destination_service: "string(destination.service)"
response_code: "string(response.code)"
percentile: "string(percentile)"
value: "double(response.duration)"
—
# 状态码告警规则
apiVersion: monitoring.coreos.com/v1
kind: PrometheusRule
metadata:
name: status-code-alerts
spec:
groups:
– name: status-code-monitoring
rules:
# 高错误率告警
– alert: High5xxErrorRate
expr: |
sum(rate(istio_requests_total{
response_code=~"5..",
reporter="destination"
}[5m])) by (destination_service)
/
sum(rate(istio_requests_total{
reporter="destination"
}[5m])) by (destination_service)
> 0.05
for: 5m
labels:
severity: critical
annotations:
summary: "High 5xx error rate for {{ $labels.destination_service }}"
description: "5xx error rate is {{ $value | humanizePercentage }} for service {{ $labels.destination_service }}"
# 4xx错误率增加
– alert: High4xxErrorRate
expr: |
sum(rate(istio_requests_total{
response_code=~"4..",
reporter="destination"
}[5m])) by (destination_service)
/
sum(rate(istio_requests_total{
reporter="destination"
}[5m])) by (destination_service)
> 0.10
for: 10m
labels:
severity: warning
annotations:
summary: "High 4xx error rate for {{ $labels.destination_service }}"
description: "4xx error rate is {{ $value | humanizePercentage }} for service {{ $labels.destination_service }}"
# 服务不可用
– alert: ServiceUnavailable
expr: |
sum(rate(istio_requests_total{
response_code=~"5..",
reporter="destination"
}[5m])) by (destination_service) == 0
and
sum(rate(istio_requests_total{
reporter="destination"
}[5m])) by (destination_service) == 0
for: 2m
labels:
severity: critical
annotations:
summary: "Service {{ $labels.destination_service }} is unavailable"
description: "Service {{ $labels.destination_service }} has not received any requests in the last 2 minutes"
# 慢响应告警
– alert: SlowResponses
expr: |
histogram_quantile(0.95,
sum(rate(istio_request_duration_milliseconds_bucket{
reporter="destination"
}[5m])) by (le, destination_service)
) > 1000
for: 5m
labels:
severity: warning
annotations:
summary: "Slow responses for {{ $labels.destination_service }}"
description: "95th percentile response time is {{ $value }}ms for service {{ $labels.destination_service }}"
33.7 错误恢复与降级策略
33.7.1 多级降级策略
python
# 多级降级策略实现
from enum import Enum
from typing import Dict, Any, Optional, Callable
import time
import logging
from dataclasses import dataclass
from functools import wraps
logger = logging.getLogger(__name__)
class DegradationLevel(Enum):
NORMAL = 1 # 正常模式
DEGRADED = 2 # 降级模式
LIMITED = 3 # 限制模式
MAINTENANCE = 4 # 维护模式
FAILSAFE = 5 # 安全模式
@dataclass
class ServiceHealth:
name: str
status_code: int
response_time: float
error_rate: float
last_check: float
degradation_level: DegradationLevel = DegradationLevel.NORMAL
class MultiLevelDegradation:
def __init__(self):
self.service_health: Dict[str, ServiceHealth] = {}
self.degradation_strategies: Dict[DegradationLevel, Callable] = {}
self._setup_strategies()
def _setup_strategies(self):
"""设置各级降级策略"""
self.degradation_strategies = {
DegradationLevel.NORMAL: self._normal_strategy,
DegradationLevel.DEGRADED: self._degraded_strategy,
DegradationLevel.LIMITED: self._limited_strategy,
DegradationLevel.MAINTENANCE: self._maintenance_strategy,
DegradationLevel.FAILSAFE: self._failsafe_strategy,
}
def assess_health(self, service_name: str,
status_code: int,
response_time: float) -> DegradationLevel:
"""评估服务健康状况并确定降级级别"""
if service_name not in self.service_health:
self.service_health[service_name] = ServiceHealth(
name=service_name,
status_code=status_code,
response_time=response_time,
error_rate=0.0,
last_check=time.time()
)
health = self.service_health[service_name]
# 更新健康指标
is_error = status_code >= 400
error_count = 1 if is_error else 0
total_count = 1
# 计算滑动窗口错误率(简化实现)
window_size = 100
health.error_rate = (
health.error_rate * (window_size – 1) + error_count
) / window_size
health.status_code = status_code
health.response_time = response_time
health.last_check = time.time()
# 确定降级级别
if status_code == 503:
return DegradationLevel.MAINTENANCE
elif status_code >= 500:
if health.error_rate > 0.5:
return DegradationLevel.FAILSAFE
elif health.error_rate > 0.2:
return DegradationLevel.LIMITED
else:
return DegradationLevel.DEGRADED
elif status_code == 429: # Rate limited
return DegradationLevel.LIMITED
elif status_code >= 400:
if health.error_rate > 0.3:
return DegradationLevel.DEGRADED
else:
return DegradationLevel.NORMAL
elif response_time > 5.0: # 5秒超时
return DegradationLevel.DEGRADED
elif response_time > 2.0: # 2秒延迟
if health.error_rate > 0.1:
return DegradationLevel.DEGRADED
else:
return DegradationLevel.NORMAL
else:
return DegradationLevel.NORMAL
def apply_strategy(self, service_name: str,
original_call: Callable,
*args, **kwargs) -> Any:
"""应用降级策略执行调用"""
health = self.service_health.get(service_name)
if not health:
# 首次调用,正常执行
return self._execute_with_monitoring(service_name, original_call, *args, **kwargs)
# 获取降级策略
strategy = self.degradation_strategies.get(
health.degradation_level,
self._normal_strategy
)
return strategy(service_name, original_call, *args, **kwargs)
def _execute_with_monitoring(self, service_name: str,
original_call: Callable,
*args, **kwargs) -> Any:
"""执行调用并监控结果"""
start_time = time.time()
try:
result = original_call(*args, **kwargs)
response_time = time.time() – start_time
# 假设result有status_code属性
status_code = getattr(result, 'status_code', 200)
# 评估健康状况
degradation_level = self.assess_health(
service_name, status_code, response_time
)
# 更新降级级别
if service_name in self.service_health:
self.service_health[service_name].degradation_level = degradation_level
return result
except Exception as e:
response_time = time.time() – start_time
# 根据异常类型确定状态码
status_code = self._exception_to_status_code(e)
# 评估健康状况
degradation_level = self.assess_health(
service_name, status_code, response_time
)
# 更新降级级别
if service_name in self.service_health:
self.service_health[service_name].degradation_level = degradation_level
raise
def _exception_to_status_code(self, e: Exception) -> int:
"""将异常转换为状态码"""
if hasattr(e, 'status_code'):
return e.status_code
elif isinstance(e, TimeoutError):
return 504
elif isinstance(e, ConnectionError):
return 503
else:
return 500
# 各级策略实现
def _normal_strategy(self, service_name: str,
original_call: Callable,
*args, **kwargs) -> Any:
"""正常策略:完整功能"""
logger.debug(f"Normal strategy for {service_name}")
return original_call(*args, **kwargs)
def _degraded_strategy(self, service_name: str,
original_call: Callable,
*args, **kwargs) -> Any:
"""降级策略:基本功能,重试机制"""
logger.warning(f"Degraded strategy for {service_name}")
# 实现重试机制
max_retries = 2
for attempt in range(max_retries + 1):
try:
return original_call(*args, **kwargs)
except Exception as e:
if attempt == max_retries:
raise
# 指数退避
delay = 2 ** attempt
time.sleep(delay)
logger.info(f"Retry {attempt + 1} for {service_name} after {delay}s")
def _limited_strategy(self, service_name: str,
original_call: Callable,
*args, **kwargs) -> Any:
"""限制策略:简化功能,使用缓存"""
logger.warning(f"Limited strategy for {service_name}")
# 尝试使用缓存
cache_key = f"{service_name}:{str(args)}:{str(kwargs)}"
cached_result = self._get_from_cache(cache_key)
if cached_result:
logger.info(f"Using cached result for {service_name}")
return cached_result
# 有限重试
try:
result = original_call(*args, **kwargs)
self._save_to_cache(cache_key, result)
return result
except Exception as e:
# 返回降级结果
return self._get_fallback_result(service_name, *args, **kwargs)
def _maintenance_strategy(self, service_name: str,
original_call: Callable,
*args, **kwargs) -> Any:
"""维护策略:返回维护信息,不尝试调用"""
logger.error(f"Maintenance strategy for {service_name}")
# 直接返回维护信息
return {
"status": "maintenance",
"service": service_name,
"message": "Service is under maintenance",
"timestamp": time.time()
}
def _failsafe_strategy(self, service_name: str,
original_call: Callable,
*args, **kwargs) -> Any:
"""安全模式:返回默认值,保护系统"""
logger.critical(f"Failsafe strategy for {service_name}")
# 返回安全默认值
return self._get_failsafe_result(service_name, *args, **kwargs)
def _get_from_cache(self, key: str) -> Optional[Any]:
"""从缓存获取结果(简化实现)"""
# 实际实现应该使用Redis、Memcached等
return None
def _save_to_cache(self, key: str, value: Any) -> None:
"""保存结果到缓存(简化实现)"""
pass
def _get_fallback_result(self, service_name: str,
*args, **kwargs) -> Any:
"""获取降级结果"""
# 根据服务类型返回不同的降级结果
if "user" in service_name:
return {
"status": "degraded",
"user": {"id": "unknown", "name": "Guest"},
"message": "User service is degraded"
}
elif "order" in service_name:
return {
"status": "degraded",
"order": {"status": "processing"},
"message": "Order service is degraded"
}
else:
return {
"status": "degraded",
"message": f"Service {service_name} is degraded"
}
def _get_failsafe_result(self, service_name: str,
*args, **kwargs) -> Any:
"""获取安全模式结果"""
return {
"status": "failsafe",
"service": service_name,
"message": "Service is in failsafe mode",
"timestamp": time.time()
}
# 使用装饰器实现
def degradation_aware(service_name: str):
"""降级感知装饰器"""
degradation_manager = MultiLevelDegradation()
def decorator(func):
@wraps(func)
def wrapper(*args, **kwargs):
return degradation_manager.apply_strategy(
service_name, func, *args, **kwargs
)
return wrapper
return decorator
# 使用示例
class UserService:
@degradation_aware("user-service")
def get_user_profile(self, user_id: str):
# 调用实际的用户服务
response = self._call_user_service(f"/users/{user_id}")
return response
def _call_user_service(self, endpoint: str):
# 模拟HTTP调用
# 实际实现应该使用HTTP客户端
pass
class OrderService:
@degradation_aware("order-service")
def create_order(self, order_data: Dict) -> Dict:
# 调用订单服务
response = self._call_order_service("/orders", order_data)
return response
@degradation_aware("inventory-service")
def check_inventory(self, product_id: str) -> Dict:
# 调用库存服务
response = self._call_inventory_service(f"/inventory/{product_id}")
return response
def _call_order_service(self, endpoint: str, data: Dict):
pass
def _call_inventory_service(self, endpoint: str):
pass
33.8 监控与告警
33.8.1 Prometheus状态码监控
yaml
# prometheus-status-code-rules.yaml
global:
scrape_interval: 15s
evaluation_interval: 15s
scrape_configs:
– job_name: 'api-gateway'
static_configs:
– targets: ['api-gateway:9090']
metrics_path: '/metrics'
– job_name: 'order-service'
static_configs:
– targets: ['order-service:8080']
metrics_path: '/actuator/prometheus'
– job_name: 'user-service'
static_configs:
– targets: ['user-service:8080']
metrics_path: '/actuator/prometheus'
– job_name: 'payment-service'
static_configs:
– targets: ['payment-service:8080']
metrics_path: '/metrics'
# 记录规则
rule_files:
– "status-code-rules.yml"
# 告警规则
alerting:
alertmanagers:
– static_configs:
– targets: ['alertmanager:9093']
# 状态码规则文件(status-code-rules.yml)
groups:
– name: status_code_recording_rules
interval: 30s
rules:
# 按服务统计状态码
– record: http_requests_total:rate5m
expr: |
sum(rate(http_requests_total[5m])) by (service, status_code)
# 错误率
– record: http_error_rate:rate5m
expr: |
sum(rate(http_requests_total{status_code=~"4..|5.."}[5m])) by (service)
/
sum(rate(http_requests_total[5m])) by (service)
# 5xx错误率
– record: http_5xx_error_rate:rate5m
expr: |
sum(rate(http_requests_total{status_code=~"5.."}[5m])) by (service)
/
sum(rate(http_requests_total[5m])) by (service)
# 4xx错误率
– record: http_4xx_error_rate:rate5m
expr: |
sum(rate(http_requests_total{status_code=~"4.."}[5m])) by (service)
/
sum(rate(http_requests_total[5m])) by (service)
# 按状态码分类的响应时间百分位
– record: http_response_time_percentile:status
expr: |
histogram_quantile(0.95,
sum(rate(http_request_duration_seconds_bucket[5m])) by (le, service, status_code)
)
# 服务依赖健康度
– record: service_dependency_health
expr: |
(
sum(rate(http_requests_total{status_code=~"2.."}[5m])) by (caller, target)
/
sum(rate(http_requests_total[5m])) by (caller, target)
) * 100
# 错误传播链
– record: error_propagation_chain
expr: |
count by (error_chain) (
http_requests_total{status_code=~"4..|5.."}
)
– name: status_code_alerts
rules:
# 全局错误率告警
– alert: GlobalHighErrorRate
expr: |
sum(rate(http_requests_total{status_code=~"4..|5.."}[5m]))
/
sum(rate(http_requests_total[5m]))
> 0.05
for: 5m
labels:
severity: critical
team: platform
annotations:
summary: "Global error rate is high"
description: "Global error rate is {{ $value | humanizePercentage }}"
# 服务级错误率告警
– alert: ServiceHighErrorRate
expr: |
http_error_rate:rate5m > 0.10
for: 5m
labels:
severity: warning
annotations:
summary: "High error rate for service {{ $labels.service }}"
description: "Error rate is {{ $value | humanizePercentage }} for service {{ $labels.service }}"
# 5xx错误率告警
– alert: ServiceHigh5xxErrorRate
expr: |
http_5xx_error_rate:rate5m > 0.05
for: 3m
labels:
severity: critical
annotations:
summary: "High 5xx error rate for service {{ $labels.service }}"
description: "5xx error rate is {{ $value | humanizePercentage }} for service {{ $labels.service }}"
# 服务完全不可用
– alert: ServiceCompletelyUnavailable
expr: |
up{job=~".*"} == 0
for: 2m
labels:
severity: critical
annotations:
summary: "Service {{ $labels.job }} is completely unavailable"
description: "Service {{ $labels.job }} has been down for more than 2 minutes"
# 错误传播链检测
– alert: ErrorPropagationDetected
expr: |
increase(error_propagation_chain[5m]) > 10
for: 2m
labels:
severity: warning
annotations:
summary: "Error propagation detected in the system"
description: "Error chain {{ $labels.error_chain }} has propagated {{ $value }} times in the last 5 minutes"
# 慢响应告警
– alert: SlowServiceResponses
expr: |
http_response_time_percentile:status > 2
for: 5m
labels:
severity: warning
annotations:
summary: "Slow responses for service {{ $labels.service }}"
description: "95th percentile response time is {{ $value }}s for status code {{ $labels.status_code }} in service {{ $labels.service }}"
# 依赖服务健康度下降
– alert: ServiceDependencyDegraded
expr: |
service_dependency_health < 95
for: 10m
labels:
severity: warning
annotations:
summary: "Service dependency health is degraded"
description: "Dependency from {{ $labels.caller }} to {{ $labels.target }} has health of {{ $value }}%"
33.9 总结
33.9.1 微服务状态码传播最佳实践
透明传播与封装平衡
-
内部错误细节不应该直接暴露给客户端
-
但需要足够的上下文进行故障诊断
-
使用标准化的错误格式(如RFC 7807)
分布式追踪集成
-
所有服务调用都应该有唯一的追踪ID
-
状态码应该作为span标签记录
-
错误传播链应该在追踪中可视化
智能断路器策略
-
基于状态码的失败检测
-
不同状态码应该有不同的重试策略
-
断路器状态应该被监控和告警
多级降级策略
-
根据错误类型和频率实施不同级别的降级
-
降级策略应该是可配置的
-
降级状态应该被监控和报告
统一的监控告警
-
所有服务应该暴露标准化的指标
-
状态码分布应该被实时监控
-
基于状态码的告警应该及时准确
33.9.2 架构模式总结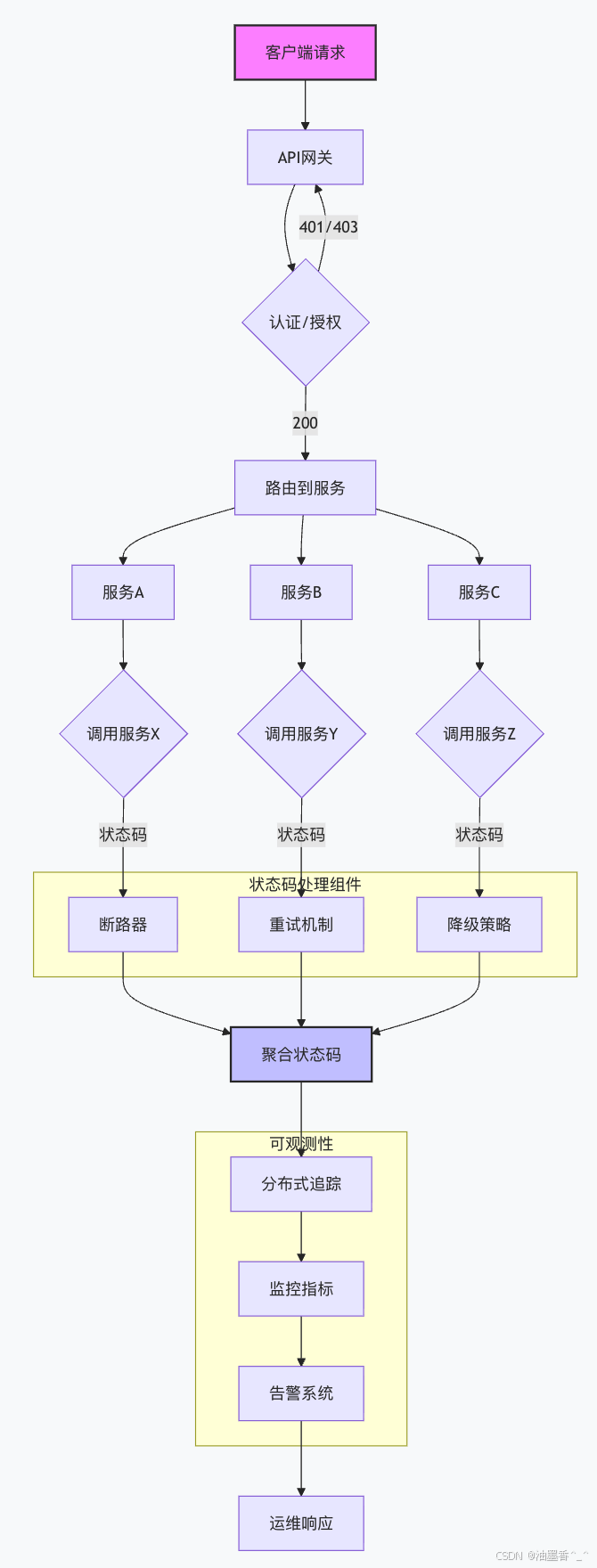
通过本章的学习,我们深入了解了微服务架构中状态码传播的复杂性和重要性。在分布式系统中,状态码不仅仅是单个服务的响应,而是整个调用链健康状况的体现。合理的状态码传播策略、智能的断路器模式、完善的监控告警系统,都是构建可靠微服务架构的关键组成部分。
第33章要点总结:
微服务状态码传播需要考虑调用链上下文
分布式追踪是理解错误传播的关键工具
断路器应该基于状态码智能决策
API网关在状态码转换中起重要作用
多级降级策略可以提高系统韧性
统一的监控告警体系是运维的基础
第34章:状态码与错误处理策略
34.1 错误处理哲学与原则
34.1.1 错误处理的三种范式
在软件工程中,错误处理有三种主要范式,每种范式对状态码的使用有着不同的理解:
python
# 错误处理的三种范式示例
from typing import Union, Optional
from dataclasses import dataclass
# 1. 返回码范式(C语言风格)
class ReturnCodeParadigm:
"""通过返回值表示成功或失败"""
def divide(self, a: float, b: float) -> Union[float, int]:
"""返回错误码而不是抛出异常"""
if b == 0:
return -1 # 错误码
return a / b
def process(self):
result = self.divide(10, 0)
if result == -1:
print("Division by zero error")
else:
print(f"Result: {result}")
# 2. 异常范式(Java/Python风格)
class ExceptionParadigm:
"""通过抛出异常表示错误"""
class DivisionByZeroError(Exception):
pass
def divide(self, a: float, b: float) -> float:
"""抛出异常而不是返回错误码"""
if b == 0:
raise self.DivisionByZeroError("Cannot divide by zero")
return a / b
def process(self):
try:
result = self.divide(10, 0)
print(f"Result: {result}")
except self.DivisionByZeroError as e:
print(f"Error: {e}")
# 3. 结果类型范式(函数式风格)
@dataclass
class Result[T, E]:
"""包含成功值或错误值的容器类型"""
value: Optional[T] = None
error: Optional[E] = None
is_success: bool = True
@classmethod
def success(cls, value: T) -> 'Result[T, E]':
return cls(value=value, is_success=True)
@classmethod
def failure(cls, error: E) -> 'Result[T, E]':
return cls(error=error, is_success=False)
def unwrap(self) -> T:
if not self.is_success:
raise ValueError(f"Result contains error: {self.error}")
return self.value
class ResultParadigm:
"""使用Result类型包装可能失败的操作"""
def divide(self, a: float, b: float) -> Result[float, str]:
"""返回包含结果或错误的Result对象"""
if b == 0:
return Result.failure("Division by zero")
return Result.success(a / b)
def process(self):
result = self.divide(10, 0)
if result.is_success:
print(f"Result: {result.unwrap()}")
else:
print(f"Error: {result.error}")
34.1.2 错误处理核心原则
java
// 错误处理的核心原则实现
public class ErrorHandlingPrinciples {
// 原则1: 快速失败(Fail Fast)
public static class FailFastPrinciple {
public User validateAndCreate(String email, String password) {
// 尽早验证,尽早失败
if (email == null || email.isEmpty()) {
throw new ValidationException("Email is required");
}
if (!isValidEmail(email)) {
throw new ValidationException("Invalid email format");
}
if (password == null || password.length() < 8) {
throw new ValidationException("Password must be at least 8 characters");
}
// 所有验证通过后才执行业务逻辑
return new User(email, password);
}
}
// 原则2: 明确错误类型(Be Specific)
public static class SpecificErrorPrinciple {
public enum ErrorType {
USER_NOT_FOUND,
INSUFFICIENT_PERMISSIONS,
INVALID_INPUT,
NETWORK_ERROR,
DATABASE_ERROR
}
@Data
public static class SpecificError {
private final ErrorType type;
private final String message;
private final Map<String, Object> context;
private final Instant timestamp;
public SpecificError(ErrorType type, String message,
Map<String, Object> context) {
this.type = type;
this.message = message;
this.context = context;
this.timestamp = Instant.now();
}
public HttpStatus toHttpStatus() {
switch (type) {
case USER_NOT_FOUND:
return HttpStatus.NOT_FOUND;
case INSUFFICIENT_PERMISSIONS:
return HttpStatus.FORBIDDEN;
case INVALID_INPUT:
return HttpStatus.BAD_REQUEST;
case NETWORK_ERROR:
case DATABASE_ERROR:
return HttpStatus.INTERNAL_SERVER_ERROR;
default:
return HttpStatus.INTERNAL_SERVER_ERROR;
}
}
}
}
// 原则3: 可恢复性设计(Design for Recovery)
public static class RecoveryDesignPrinciple {
private final RetryTemplate retryTemplate;
private final CircuitBreaker circuitBreaker;
public RecoveryDesignPrinciple() {
this.retryTemplate = new RetryTemplate();
this.circuitBreaker = new CircuitBreaker();
}
public Result<Order> placeOrderWithRecovery(OrderRequest request) {
return circuitBreaker.executeSupplier(() -> {
return retryTemplate.execute(context -> {
try {
return Result.success(placeOrder(request));
} catch (TemporaryFailureException e) {
// 记录重试
context.setAttribute("retry_count",
context.getRetryCount() + 1);
throw e;
}
});
});
}
private Order placeOrder(OrderRequest request) {
// 模拟可能失败的操作
return new Order();
}
}
// 原则4: 错误隔离(Error Isolation)
public static class ErrorIsolationPrinciple {
private final ExecutorService isolatedExecutor;
public ErrorIsolationPrinciple() {
// 创建独立的线程池来隔离可能失败的操作
this.isolatedExecutor = Executors.newFixedThreadPool(3,
new ThreadFactoryBuilder()
.setNameFormat("isolated-task-%d")
.setUncaughtExceptionHandler((t, e) -> {
// 隔离的异常处理,不会影响主线程
logIsolatedError(t.getName(), e);
})
.build());
}
public CompletableFuture<Void> executeIsolated(Runnable task) {
return CompletableFuture.runAsync(task, isolatedExecutor)
.exceptionally(throwable -> {
// 处理异常,但不会传播到调用者
logIsolatedError("isolated-task", throwable);
return null;
});
}
private void logIsolatedError(String taskName, Throwable throwable) {
System.err.printf("Isolated error in %s: %s%n",
taskName, throwable.getMessage());
}
}
// 原则5: 优雅降级(Graceful Degradation)
public static class GracefulDegradationPrinciple {
private final CacheService cacheService;
private final FallbackService fallbackService;
public GracefulDegradationPrinciple() {
this.cacheService = new CacheService();
this.fallbackService = new FallbackService();
}
public Product getProduct(String productId) {
try {
// 1. 首先尝试主服务
return productService.getProduct(productId);
} catch (ServiceUnavailableException e) {
// 2. 主服务失败,尝试缓存
Product cached = cacheService.getProduct(productId);
if (cached != null) {
return cached;
}
// 3. 缓存也没有,使用降级服务
return fallbackService.getBasicProductInfo(productId);
}
}
}
}
34.2 状态码驱动的错误分类
34.2.1 错误分类体系
typescript
// 基于状态码的错误分类体系
type ErrorCategory =
| 'CLIENT_ERROR' // 4xx 错误
| 'SERVER_ERROR' // 5xx 错误
| 'NETWORK_ERROR' // 网络相关错误
| 'VALIDATION_ERROR' // 验证错误
| 'BUSINESS_ERROR' // 业务逻辑错误
| 'SECURITY_ERROR' // 安全相关错误
| 'INTEGRATION_ERROR' // 集成错误
| 'TIMEOUT_ERROR'; // 超时错误
interface ErrorClassification {
category: ErrorCategory;
severity: 'LOW' | 'MEDIUM' | 'HIGH' | 'CRITICAL';
retryable: boolean;
userFacing: boolean;
logLevel: 'DEBUG' | 'INFO' | 'WARN' | 'ERROR' | 'FATAL';
suggestedAction: string;
}
class StatusCodeClassifier {
private static readonly CLASSIFICATION_MAP: Map<number, ErrorClassification> = new Map([
// 4xx 错误分类
[400, {
category: 'CLIENT_ERROR',
severity: 'MEDIUM',
retryable: false,
userFacing: true,
logLevel: 'WARN',
suggestedAction: 'Fix request parameters and retry'
}],
[401, {
category: 'SECURITY_ERROR',
severity: 'MEDIUM',
retryable: true,
userFacing: true,
logLevel: 'WARN',
suggestedAction: 'Authenticate and retry with valid credentials'
}],
[403, {
category: 'SECURITY_ERROR',
severity: 'MEDIUM',
retryable: false,
userFacing: true,
logLevel: 'WARN',
suggestedAction: 'Request appropriate permissions'
}],
[404, {
category: 'CLIENT_ERROR',
severity: 'LOW',
retryable: false,
userFacing: true,
logLevel: 'DEBUG',
suggestedAction: 'Check resource identifier and retry'
}],
[409, {
category: 'BUSINESS_ERROR',
severity: 'MEDIUM',
retryable: true,
userFacing: true,
logLevel: 'WARN',
suggestedAction: 'Resolve conflict and retry'
}],
[422, {
category: 'VALIDATION_ERROR',
severity: 'MEDIUM',
retryable: false,
userFacing: true,
logLevel: 'WARN',
suggestedAction: 'Fix validation errors and retry'
}],
[429, {
category: 'CLIENT_ERROR',
severity: 'MEDIUM',
retryable: true,
userFacing: true,
logLevel: 'WARN',
suggestedAction: 'Wait and retry after rate limit resets'
}],
// 5xx 错误分类
[500, {
category: 'SERVER_ERROR',
severity: 'HIGH',
retryable: true,
userFacing: false,
logLevel: 'ERROR',
suggestedAction: 'Retry after some time or contact support'
}],
[502, {
category: 'INTEGRATION_ERROR',
severity: 'HIGH',
retryable: true,
userFacing: false,
logLevel: 'ERROR',
suggestedAction: 'Retry after upstream service recovers'
}],
[503, {
category: 'SERVER_ERROR',
severity: 'HIGH',
retryable: true,
userFacing: true,
logLevel: 'ERROR',
suggestedAction: 'Retry after service maintenance completes'
}],
[504, {
category: 'TIMEOUT_ERROR',
severity: 'MEDIUM',
retryable: true,
userFacing: false,
logLevel: 'WARN',
suggestedAction: 'Retry with longer timeout or check network'
}]
]);
static classify(statusCode: number): ErrorClassification {
const classification = this.CLASSIFICATION_MAP.get(statusCode);
if (!classification) {
// 默认分类
if (statusCode >= 400 && statusCode < 500) {
return {
category: 'CLIENT_ERROR',
severity: 'MEDIUM',
retryable: false,
userFacing: true,
logLevel: 'WARN',
suggestedAction: 'Review request and retry'
};
} else if (statusCode >= 500) {
return {
category: 'SERVER_ERROR',
severity: 'HIGH',
retryable: true,
userFacing: false,
logLevel: 'ERROR',
suggestedAction: 'Retry after some time'
};
}
throw new Error(`Unsupported status code: ${statusCode}`);
}
return classification;
}
static getErrorResponse(statusCode: number, errorDetails?: any): ErrorResponse {
const classification = this.classify(statusCode);
return {
statusCode,
error: {
code: `HTTP_${statusCode}`,
message: this.getDefaultMessage(statusCode),
category: classification.category,
severity: classification.severity,
retryable: classification.retryable,
timestamp: new Date().toISOString(),
details: errorDetails,
suggestedAction: classification.suggestedAction
}
};
}
private static getDefaultMessage(statusCode: number): string {
const messages: Record<number, string> = {
400: 'Bad Request',
401: 'Unauthorized',
403: 'Forbidden',
404: 'Not Found',
409: 'Conflict',
422: 'Unprocessable Entity',
429: 'Too Many Requests',
500: 'Internal Server Error',
502: 'Bad Gateway',
503: 'Service Unavailable',
504: 'Gateway Timeout'
};
return messages[statusCode] || 'Unknown Error';
}
static shouldRetry(statusCode: number, retryCount: number = 0): boolean {
const classification = this.classify(statusCode);
if (!classification.retryable) {
return false;
}
// 检查重试次数限制
const maxRetries = this.getMaxRetries(statusCode);
return retryCount < maxRetries;
}
private static getMaxRetries(statusCode: number): number {
const retryConfig: Record<number, number> = {
401: 1, // 认证错误,重试1次
429: 3, // 限流错误,最多重试3次
500: 3, // 服务器错误,最多重试3次
502: 3, // 网关错误,最多重试3次
503: 5, // 服务不可用,最多重试5次
504: 2 // 超时错误,最多重试2次
};
return retryConfig[statusCode] || 0;
}
static getRetryDelay(statusCode: number, retryCount: number): number {
// 指数退避算法
const baseDelay = 1000; // 1秒
const maxDelay = 30000; // 30秒
if (statusCode === 429) {
// 对于限流错误,使用更保守的退避
return Math.min(baseDelay * Math.pow(1.5, retryCount), maxDelay);
}
// 对于其他可重试错误,使用指数退避
return Math.min(baseDelay * Math.pow(2, retryCount), maxDelay);
}
}
// 使用示例
const response = await fetch('https://api.example.com/data');
if (!response.ok) {
const classification = StatusCodeClassifier.classify(response.status);
console.log('Error Classification:', {
category: classification.category,
severity: classification.severity,
shouldRetry: classification.retryable,
suggestedAction: classification.suggestedAction
});
// 根据分类决定如何处理错误
switch (classification.category) {
case 'CLIENT_ERROR':
// 客户端错误,通常不需要重试
throw new UserFacingError(
StatusCodeClassifier.getDefaultMessage(response.status)
);
case 'SERVER_ERROR':
// 服务器错误,可以重试
if (classification.retryable) {
const delay = StatusCodeClassifier.getRetryDelay(
response.status,
0 // 第一次重试
);
await new Promise(resolve => setTimeout(resolve, delay));
// 重试逻辑…
}
break;
case 'SECURITY_ERROR':
// 安全错误,可能需要重新认证
if (response.status === 401) {
await refreshAuthentication();
// 重试请求…
}
break;
}
}
34.2.2 分层错误处理架构
java
// Java分层错误处理架构
public class LayeredErrorHandlingArchitecture {
// 第一层:基础设施层错误
public static class InfrastructureLayer {
@Service
public class DatabaseService {
private final JdbcTemplate jdbcTemplate;
private final CircuitBreaker circuitBreaker;
public DatabaseService(JdbcTemplate jdbcTemplate) {
this.jdbcTemplate = jdbcTemplate;
this.circuitBreaker = CircuitBreaker.ofDefaults("database");
}
public User findUserById(String userId) {
return circuitBreaker.executeSupplier(() -> {
try {
return jdbcTemplate.queryForObject(
"SELECT * FROM users WHERE id = ?",
new UserRowMapper(),
userId
);
} catch (DataAccessException e) {
// 基础设施错误转换为领域错误
throw new DatabaseUnavailableException(
"Database temporarily unavailable",
e
);
}
});
}
}
@Service
public class ExternalApiClient {
private final RestTemplate restTemplate;
private final RetryTemplate retryTemplate;
public ExternalApiClient(RestTemplate restTemplate) {
this.restTemplate = restTemplate;
this.retryTemplate = new RetryTemplate();
}
public ApiResponse callExternalApi(String endpoint) {
return retryTemplate.execute(context -> {
try {
ResponseEntity<ApiResponse> response = restTemplate
.getForEntity(endpoint, ApiResponse.class);
if (!response.getStatusCode().is2xxSuccessful()) {
// 根据状态码决定是否重试
if (shouldRetry(response.getStatusCode())) {
throw new RetryableApiException(
"API returned error: " + response.getStatusCode()
);
} else {
throw new NonRetryableApiException(
"API returned unrecoverable error"
);
}
}
return response.getBody();
} catch (RestClientException e) {
// 网络错误,可以重试
throw new RetryableApiException(
"Network error calling external API",
e
);
}
});
}
private boolean shouldRetry(HttpStatus status) {
return status.is5xxServerError() ||
status == HttpStatus.REQUEST_TIMEOUT ||
status == HttpStatus.TOO_MANY_REQUESTS;
}
}
}
// 第二层:领域层错误
public static class DomainLayer {
public static class InsufficientFundsException
extends BusinessException {
public InsufficientFundsException(BigDecimal current,
BigDecimal required) {
super(
"Insufficient funds",
ErrorCode.INSUFFICIENT_FUNDS,
Map.of(
"current_balance", current,
"required_amount", required
)
);
}
}
public static class ProductOutOfStockException
extends BusinessException {
public ProductOutOfStockException(String productId,
int available) {
super(
"Product is out of stock",
ErrorCode.PRODUCT_OUT_OF_STOCK,
Map.of(
"product_id", productId,
"available_quantity", available
)
);
}
}
@Service
public class OrderService {
private final PaymentService paymentService;
private final InventoryService inventoryService;
public OrderService(PaymentService paymentService,
InventoryService inventoryService) {
this.paymentService = paymentService;
this.inventoryService = inventoryService;
}
@Transactional
public Order placeOrder(OrderRequest request) {
// 验证库存
if (!inventoryService.isInStock(request.getProductId(),
request.getQuantity())) {
throw new ProductOutOfStockException(
request.getProductId(),
inventoryService.getAvailableQuantity(
request.getProductId()
)
);
}
// 处理支付
try {
PaymentResult result = paymentService.processPayment(
request.getPaymentDetails(),
request.getTotalAmount()
);
if (!result.isSuccess()) {
throw new PaymentFailedException(
"Payment processing failed",
result.getErrorCode()
);
}
// 扣减库存
inventoryService.reduceStock(
request.getProductId(),
request.getQuantity()
);
// 创建订单
return createOrder(request, result);
} catch (PaymentProcessingException e) {
// 支付处理异常转换为领域异常
throw new PaymentFailedException(
"Payment processing error",
e.getErrorCode(),
e
);
}
}
}
}
// 第三层:应用层错误
public static class ApplicationLayer {
@RestControllerAdvice
public class GlobalExceptionHandler {
// 处理领域层异常
@ExceptionHandler(BusinessException.class)
public ResponseEntity<ErrorResponse> handleBusinessException(
BusinessException ex) {
ErrorResponse error = ErrorResponse.builder()
.code(ex.getErrorCode())
.message(ex.getMessage())
.details(ex.getContext())
.timestamp(Instant.now())
.build();
// 根据错误类型决定HTTP状态码
HttpStatus status = mapErrorCodeToHttpStatus(ex.getErrorCode());
return ResponseEntity
.status(status)
.body(error);
}
// 处理基础设施层异常
@ExceptionHandler(DatabaseUnavailableException.class)
public ResponseEntity<ErrorResponse> handleDatabaseException(
DatabaseUnavailableException ex) {
ErrorResponse error = ErrorResponse.builder()
.code(ErrorCode.DATABASE_UNAVAILABLE)
.message("Database service is temporarily unavailable")
.timestamp(Instant.now())
.build();
return ResponseEntity
.status(HttpStatus.SERVICE_UNAVAILABLE)
.header("Retry-After", "30")
.body(error);
}
// 处理外部API异常
@ExceptionHandler(ApiException.class)
public ResponseEntity<ErrorResponse> handleApiException(
ApiException ex) {
ErrorResponse error = ErrorResponse.builder()
.code(ErrorCode.EXTERNAL_SERVICE_ERROR)
.message("External service error occurred")
.timestamp(Instant.now())
.build();
return ResponseEntity
.status(HttpStatus.BAD_GATEWAY)
.body(error);
}
// 处理验证异常
@ExceptionHandler(MethodArgumentNotValidException.class)
public ResponseEntity<ErrorResponse> handleValidationException(
MethodArgumentNotValidException ex) {
List<ValidationError> validationErrors = ex.getBindingResult()
.getFieldErrors()
.stream()
.map(fieldError -> ValidationError.builder()
.field(fieldError.getField())
.message(fieldError.getDefaultMessage())
.rejectedValue(fieldError.getRejectedValue())
.build())
.collect(Collectors.toList());
ErrorResponse error = ErrorResponse.builder()
.code(ErrorCode.VALIDATION_ERROR)
.message("Request validation failed")
.details(Map.of("validation_errors", validationErrors))
.timestamp(Instant.now())
.build();
return ResponseEntity
.status(HttpStatus.UNPROCESSABLE_ENTITY)
.body(error);
}
// 兜底异常处理
@ExceptionHandler(Exception.class)
public ResponseEntity<ErrorResponse> handleGenericException(
Exception ex) {
// 记录未知异常
log.error("Unhandled exception occurred", ex);
ErrorResponse error = ErrorResponse.builder()
.code(ErrorCode.INTERNAL_ERROR)
.message("An unexpected error occurred")
.timestamp(Instant.now())
.build();
return ResponseEntity
.status(HttpStatus.INTERNAL_SERVER_ERROR)
.body(error);
}
private HttpStatus mapErrorCodeToHttpStatus(ErrorCode errorCode) {
switch (errorCode) {
case INSUFFICIENT_FUNDS:
case PRODUCT_OUT_OF_STOCK:
return HttpStatus.CONFLICT;
case VALIDATION_ERROR:
return HttpStatus.UNPROCESSABLE_ENTITY;
case AUTHENTICATION_ERROR:
return HttpStatus.UNAUTHORIZED;
case AUTHORIZATION_ERROR:
return HttpStatus.FORBIDDEN;
case RESOURCE_NOT_FOUND:
return HttpStatus.NOT_FOUND;
default:
return HttpStatus.BAD_REQUEST;
}
}
}
@Service
public class ErrorMonitoringService {
private final ErrorReportingClient errorReportingClient;
private final MetricsService metricsService;
public ErrorMonitoringService(ErrorReportingClient errorReportingClient,
MetricsService metricsService) {
this.errorReportingClient = errorReportingClient;
this.metricsService = metricsService;
}
public void reportError(Throwable throwable, ErrorContext context) {
// 1. 记录指标
metricsService.incrementCounter("errors_total",
"error_type", throwable.getClass().getSimpleName());
// 2. 发送到错误报告系统
ErrorReport report = ErrorReport.builder()
.error(throwable)
.context(context)
.timestamp(Instant.now())
.build();
errorReportingClient.report(report);
// 3. 根据错误类型决定是否需要告警
if (isCriticalError(throwable)) {
sendAlert(report);
}
}
private boolean isCriticalError(Throwable throwable) {
return throwable instanceof OutOfMemoryError ||
throwable instanceof DatabaseUnavailableException ||
throwable instanceof CircuitBreakerOpenException;
}
private void sendAlert(ErrorReport report) {
// 发送告警到监控系统
Alert alert = Alert.builder()
.severity(AlertSeverity.CRITICAL)
.message("Critical error detected")
.details(report)
.timestamp(Instant.now())
.build();
// alertService.send(alert);
}
}
}
// 错误基类
public static abstract class BusinessException extends RuntimeException {
private final ErrorCode errorCode;
private final Map<String, Object> context;
public BusinessException(String message, ErrorCode errorCode,
Map<String, Object> context) {
super(message);
this.errorCode = errorCode;
this.context = context;
}
public BusinessException(String message, ErrorCode errorCode,
Map<String, Object> context, Throwable cause) {
super(message, cause);
this.errorCode = errorCode;
this.context = context;
}
public ErrorCode getErrorCode() { return errorCode; }
public Map<String, Object> getContext() { return context; }
}
}
34.3 智能重试策略
34.3.1 自适应重试算法
python
# 自适应重试策略实现
import time
import math
import random
from dataclasses import dataclass
from enum import Enum
from typing import Optional, Callable, Any, Dict
from datetime import datetime, timedelta
class RetryStrategy(Enum):
"""重试策略枚举"""
EXPONENTIAL_BACKOFF = "exponential_backoff"
FIBONACCI_BACKOFF = "fibonacci_backoff"
FIXED_DELAY = "fixed_delay"
LINEAR_BACKOFF = "linear_backoff"
RANDOM_JITTER = "random_jitter"
class ErrorPattern(Enum):
"""错误模式枚举"""
TRANSIENT = "transient" # 临时错误,可以重试
PERMANENT = "permanent" # 永久错误,不应重试
THROTTLING = "throttling" # 限流错误,需要等待
NETWORK = "network" # 网络错误
@dataclass
class RetryContext:
"""重试上下文"""
attempt_number: int
max_attempts: int
last_error: Optional[Exception]
last_status_code: Optional[int]
start_time: datetime
total_duration: timedelta
custom_data: Dict[str, Any]
def should_continue(self) -> bool:
"""是否应该继续重试"""
if self.attempt_number >= self.max_attempts:
return False
# 检查总持续时间限制
if self.total_duration.total_seconds() > 300: # 5分钟
return False
return True
class AdaptiveRetryStrategy:
"""自适应重试策略"""
def __init__(
self,
max_attempts: int = 5,
base_delay: float = 1.0, # 秒
max_delay: float = 60.0, # 秒
strategy: RetryStrategy = RetryStrategy.EXPONENTIAL_BACKOFF,
jitter: bool = True,
jitter_factor: float = 0.1
):
self.max_attempts = max_attempts
self.base_delay = base_delay
self.max_delay = max_delay
self.strategy = strategy
self.jitter = jitter
self.jitter_factor = jitter_factor
# 错误模式检测器
self.error_patterns = self._initialize_error_patterns()
def _initialize_error_patterns(self) -> Dict[ErrorPattern, Callable[[Exception], bool]]:
"""初始化错误模式检测器"""
return {
ErrorPattern.TRANSIENT: self._is_transient_error,
ErrorPattern.PERMANENT: self._is_permanent_error,
ErrorPattern.THROTTLING: self._is_throttling_error,
ErrorPattern.NETWORK: self._is_network_error
}
def execute(self, func: Callable[[], Any], context_data: Dict[str, Any] = None) -> Any:
"""执行带重试的函数"""
context = RetryContext(
attempt_number=0,
max_attempts=self.max_attempts,
last_error=None,
last_status_code=None,
start_time=datetime.now(),
total_duration=timedelta(),
custom_data=context_data or {}
)
while context.should_continue():
try:
result = func()
# 成功,重置重试状态(如果需要的话)
self._on_success(context)
return result
except Exception as e:
context.last_error = e
context.last_status_code = getattr(e, 'status_code', None)
context.attempt_number += 1
# 分析错误模式
error_pattern = self._analyze_error(e, context)
# 根据错误模式决定是否重试
if not self._should_retry(error_pattern, context):
raise e
# 计算等待时间
wait_time = self._calculate_wait_time(context, error_pattern)
# 更新总持续时间
context.total_duration += timedelta(seconds=wait_time)
# 等待
self._wait(wait_time, context)
def _analyze_error(self, error: Exception, context: RetryContext) -> ErrorPattern:
"""分析错误模式"""
# 检查错误类型
for pattern, detector in self.error_patterns.items():
if detector(error):
return pattern
# 检查状态码
if context.last_status_code:
if context.last_status_code == 429:
return ErrorPattern.THROTTLING
elif 500 <= context.last_status_code < 600:
return ErrorPattern.TRANSIENT
elif 400 <= context.last_status_code < 500:
# 某些4xx错误可能是临时性的
if context.last_status_code in [408, 423, 425, 429]:
return ErrorPattern.TRANSIENT
else:
return ErrorPattern.PERMANENT
# 默认认为是网络错误
return ErrorPattern.NETWORK
def _should_retry(self, error_pattern: ErrorPattern, context: RetryContext) -> bool:
"""根据错误模式决定是否重试"""
if error_pattern == ErrorPattern.PERMANENT:
return False
# 检查重试次数
if context.attempt_number >= self.max_attempts:
return False
# 检查总持续时间
if context.total_duration.total_seconds() > 300: # 5分钟
return False
return True
def _calculate_wait_time(self, context: RetryContext, error_pattern: ErrorPattern) -> float:
"""计算等待时间"""
attempt = context.attempt_number
# 基础延迟计算
if error_pattern == ErrorPattern.THROTTLING:
# 限流错误使用更长的等待时间
base_wait = self._calculate_throttling_wait(context)
else:
# 根据策略计算基础等待时间
base_wait = self._calculate_base_wait(attempt)
# 添加抖动
if self.jitter:
jitter_amount = base_wait * self.jitter_factor
base_wait += random.uniform(-jitter_amount, jitter_amount)
# 确保在合理范围内
return max(0, min(base_wait, self.max_delay))
def _calculate_base_wait(self, attempt: int) -> float:
"""根据策略计算基础等待时间"""
if self.strategy == RetryStrategy.EXPONENTIAL_BACKOFF:
# 指数退避:1, 2, 4, 8, 16, …
return self.base_delay * (2 ** (attempt – 1))
elif self.strategy == RetryStrategy.FIBONACCI_BACKOFF:
# 斐波那契退避:1, 1, 2, 3, 5, 8, …
fib = self._fibonacci(attempt)
return self.base_delay * fib
elif self.strategy == RetryStrategy.FIXED_DELAY:
# 固定延迟
return self.base_delay
elif self.strategy == RetryStrategy.LINEAR_BACKOFF:
# 线性退避:1, 2, 3, 4, 5, …
return self.base_delay * attempt
else:
# 默认使用指数退避
return self.base_delay * (2 ** (attempt – 1))
def _calculate_throttling_wait(self, context: RetryContext) -> float:
"""计算限流等待时间"""
# 检查错误中是否包含Retry-After头
if hasattr(context.last_error, 'headers'):
headers = context.last_error.headers
if 'Retry-After' in headers:
retry_after = headers['Retry-After']
try:
# 可能是秒数或日期时间
if retry_after.isdigit():
return float(retry_after)
else:
# 解析日期时间
retry_time = datetime.fromisoformat(retry_after)
wait_seconds = (retry_time – datetime.now()).total_seconds()
return max(0, wait_seconds)
except (ValueError, TypeError):
pass
# 没有Retry-After头,使用指数退避加上额外延迟
base_wait = self._calculate_base_wait(context.attempt_number)
return base_wait * 2 # 限流错误等待时间加倍
def _fibonacci(self, n: int) -> int:
"""计算斐波那契数"""
if n <= 0:
return 0
elif n == 1:
return 1
else:
a, b = 0, 1
for _ in range(n):
a, b = b, a + b
return a
def _is_transient_error(self, error: Exception) -> bool:
"""判断是否为临时错误"""
transient_error_types = [
'TimeoutError',
'ConnectionError',
'TemporaryFailure',
'ServiceUnavailable'
]
error_type = error.__class__.__name__
return error_type in transient_error_types
def _is_permanent_error(self, error: Exception) -> bool:
"""判断是否为永久错误"""
permanent_error_types = [
'ValidationError',
'AuthenticationError',
'AuthorizationError',
'InvalidRequest'
]
error_type = error.__class__.__name__
return error_type in permanent_error_types
def _is_throttling_error(self, error: Exception) -> bool:
"""判断是否为限流错误"""
if hasattr(error, 'status_code') and error.status_code == 429:
return True
error_type = error.__class__.__name__
return error_type in ['RateLimitError', 'ThrottlingError']
def _is_network_error(self, error: Exception) -> bool:
"""判断是否为网络错误"""
network_error_types = [
'ConnectionError',
'NetworkError',
'SocketError',
'HTTPError'
]
error_type = error.__class__.__name__
return error_type in network_error_types
def _wait(self, seconds: float, context: RetryContext):
"""等待指定的时间"""
# 记录等待开始时间
wait_start = datetime.now()
# 实际等待
time.sleep(seconds)
# 记录等待结束时间
wait_end = datetime.now()
# 可以在这里添加等待日志或监控
self._log_wait(context, seconds, wait_start, wait_end)
def _log_wait(self, context: RetryContext, wait_time: float,
start_time: datetime, end_time: datetime):
"""记录等待信息"""
log_data = {
'attempt': context.attempt_number,
'wait_time_seconds': wait_time,
'start_time': start_time.isoformat(),
'end_time': end_time.isoformat(),
'error_type': context.last_error.__class__.__name__ if context.last_error else None,
'status_code': context.last_status_code,
'total_duration_seconds': context.total_duration.total_seconds()
}
print(f"Retry wait: {log_data}")
def _on_success(self, context: RetryContext):
"""成功时的回调"""
# 可以在这里添加成功日志、重置计数器等
success_data = {
'attempts_made': context.attempt_number,
'total_duration_seconds': context.total_duration.total_seconds(),
'success_time': datetime.now().isoformat()
}
print(f"Operation succeeded: {success_data}")
# 使用示例
def test_retry_strategy():
# 创建自适应重试策略
retry_strategy = AdaptiveRetryStrategy(
max_attempts=5,
base_delay=1.0,
max_delay=30.0,
strategy=RetryStrategy.EXPONENTIAL_BACKOFF,
jitter=True,
jitter_factor=0.1
)
# 模拟一个可能失败的操作
call_count = 0
def unreliable_operation():
nonlocal call_count
call_count += 1
if call_count < 3:
# 模拟临时错误
class MockError(Exception):
status_code = 503
raise MockError("Service temporarily unavailable")
elif call_count == 3:
# 模拟限流错误
class ThrottlingError(Exception):
status_code = 429
headers = {'Retry-After': '5'}
raise ThrottlingError("Too many requests")
else:
# 成功
return {"data": "success"}
try:
# 执行带重试的操作
result = retry_strategy.execute(unreliable_operation)
print(f"最终结果: {result}")
except Exception as e:
print(f"操作最终失败: {e}")
# 运行测试
if __name__ == "__main__":
test_retry_strategy()
34.3.2 基于机器学习的智能重试
python
# 基于机器学习的智能重试系统
import numpy as np
import pandas as pd
from sklearn.ensemble import RandomForestClassifier, RandomForestRegressor
from sklearn.preprocessing import LabelEncoder, StandardScaler
from sklearn.model_selection import train_test_split
import joblib
from datetime import datetime
from typing import Dict, List, Any, Optional, Tuple
import hashlib
import json
class MLRetryOptimizer:
"""基于机器学习的重试优化器"""
def __init__(self, model_path: str = None):
# 特征工程
self.feature_columns = [
'hour_of_day', 'day_of_week', 'response_time_ms',
'status_code', 'error_type', 'retry_count',
'service_name', 'endpoint', 'client_ip_prefix',
'request_size_kb', 'response_size_kb', 'concurrent_requests'
]
# 目标变量
self.target_column = 'retry_success_probability'
# 编码器
self.label_encoders = {}
self.scaler = StandardScaler()
# 模型
self.classification_model = RandomForestClassifier(
n_estimators=100,
random_state=42
)
self.regression_model = RandomForestRegressor(
n_estimators=100,
random_state=42
)
# 数据存储
self.training_data = []
self.model_path = model_path
# 加载现有模型
if model_path:
self.load_model(model_path)
def extract_features(self, request_context: Dict[str, Any],
error_context: Dict[str, Any]) -> Dict[str, Any]:
"""从请求和错误上下文中提取特征"""
features = {}
# 时间特征
timestamp = request_context.get('timestamp', datetime.now())
features['hour_of_day'] = timestamp.hour
features['day_of_week'] = timestamp.weekday() # 0=Monday, 6=Sunday
# 响应特征
features['response_time_ms'] = error_context.get('response_time_ms', 0)
features['status_code'] = error_context.get('status_code', 0)
features['error_type'] = error_context.get('error_type', 'unknown')
# 请求特征
features['retry_count'] = error_context.get('retry_count', 0)
features['service_name'] = request_context.get('service_name', 'unknown')
features['endpoint'] = request_context.get('endpoint', 'unknown')
# 客户端特征
client_ip = request_context.get('client_ip', '0.0.0.0')
features['client_ip_prefix'] = self._extract_ip_prefix(client_ip)
# 请求大小
features['request_size_kb'] = request_context.get('request_size_kb', 0)
features['response_size_kb'] = error_context.get('response_size_kb', 0)
# 系统负载特征
features['concurrent_requests'] = request_context.get(
'concurrent_requests', 0
)
return features
def predict_retry_success(self, features: Dict[str, Any]) -> Dict[str, Any]:
"""预测重试成功的概率和最佳等待时间"""
# 转换为DataFrame
features_df = pd.DataFrame([features])
# 编码分类特征
encoded_features = self._encode_features(features_df)
# 预测
if hasattr(self, 'classification_model') and self.classification_model:
# 分类:预测是否会成功
success_probability = self.classification_model.predict_proba(
encoded_features
)[0][1] # 获取正类(成功)的概率
# 回归:预测最佳等待时间
if hasattr(self, 'regression_model') and self.regression_model:
optimal_wait_time = self.regression_model.predict(
encoded_features
)[0]
else:
optimal_wait_time = self._calculate_default_wait_time(
features['retry_count']
)
else:
# 没有训练好的模型,使用启发式方法
success_probability = self._heuristic_success_probability(features)
optimal_wait_time = self._calculate_default_wait_time(
features['retry_count']
)
return {
'success_probability': float(success_probability),
'optimal_wait_time_seconds': float(optimal_wait_time),
'should_retry': success_probability > 0.5, # 阈值可以调整
'confidence': min(abs(success_probability – 0.5) * 2, 1.0)
}
def record_retry_outcome(self, features: Dict[str, Any],
outcome: Dict[str, Any]):
"""记录重试结果用于模型训练"""
# 准备训练数据
training_example = features.copy()
training_example['retry_success'] = outcome.get('success', False)
training_example['actual_wait_time'] = outcome.get('wait_time_seconds', 0)
# 添加时间戳
training_example['recorded_at'] = datetime.now().isoformat()
# 存储
self.training_data.append(training_example)
# 定期训练模型
if len(self.training_data) % 1000 == 0: # 每1000条记录训练一次
self.train_models()
def train_models(self):
"""训练机器学习模型"""
if len(self.training_data) < 100:
print("Not enough training data")
return
# 转换为DataFrame
df = pd.DataFrame(self.training_data)
# 准备特征
X = df[self.feature_columns].copy()
# 编码分类特征
X_encoded = self._encode_features(X, fit=True)
# 准备目标变量
y_classification = df['retry_success'].astype(int)
y_regression = df['actual_wait_time']
# 划分训练集和测试集
X_train, X_test, y_train_cls, y_test_cls, y_train_reg, y_test_reg = \\
train_test_split(
X_encoded, y_classification, y_regression,
test_size=0.2, random_state=42
)
# 训练分类模型
print("Training classification model…")
self.classification_model.fit(X_train, y_train_cls)
# 评估分类模型
train_score = self.classification_model.score(X_train, y_train_cls)
test_score = self.classification_model.score(X_test, y_test_cls)
print(f"Classification model – Train score: {train_score:.3f}, "
f"Test score: {test_score:.3f}")
# 训练回归模型(只在成功的情况下)
success_mask = y_classification == 1
if success_mask.sum() > 10: # 需要有足够的成功样本
X_success = X_encoded[success_mask]
y_wait_success = y_regression[success_mask]
print("Training regression model…")
self.regression_model.fit(X_success, y_wait_success)
# 评估回归模型
y_pred = self.regression_model.predict(X_success)
mse = np.mean((y_wait_success – y_pred) ** 2)
print(f"Regression model – MSE: {mse:.3f}")
# 保存模型
if self.model_path:
self.save_model(self.model_path)
def _encode_features(self, df: pd.DataFrame, fit: bool = False) -> np.ndarray:
"""编码特征"""
df_encoded = df.copy()
# 对分类特征进行标签编码
categorical_columns = ['error_type', 'service_name', 'endpoint',
'client_ip_prefix']
for col in categorical_columns:
if col in df_encoded.columns:
if fit:
# 拟合编码器
le = LabelEncoder()
df_encoded[col] = le.fit_transform(df_encoded[col].fillna('unknown'))
self.label_encoders[col] = le
else:
# 使用已有的编码器
if col in self.label_encoders:
le = self.label_encoders[col]
# 处理未见过的标签
unseen_mask = ~df_encoded[col].isin(le.classes_)
df_encoded.loc[unseen_mask, col] = 'unknown'
df_encoded[col] = le.transform(df_encoded[col].fillna('unknown'))
# 标准化数值特征
numerical_columns = ['hour_of_day', 'day_of_week', 'response_time_ms',
'status_code', 'retry_count', 'request_size_kb',
'response_size_kb', 'concurrent_requests']
numerical_features = df_encoded[numerical_columns].values
if fit:
numerical_features = self.scaler.fit_transform(numerical_features)
else:
numerical_features = self.scaler.transform(numerical_features)
# 合并特征
categorical_features = df_encoded[categorical_columns].values
features = np.hstack([numerical_features, categorical_features])
return features
def _extract_ip_prefix(self, ip: str) -> str:
"""提取IP地址前缀"""
if '.' in ip: # IPv4
parts = ip.split('.')
return '.'.join(parts[:2]) # 取前两个八位组
elif ':' in ip: # IPv6
# 简化处理,取前4个字符
return ip[:4]
else:
return 'unknown'
def _calculate_default_wait_time(self, retry_count: int) -> float:
"""计算默认等待时间(指数退避)"""
base_delay = 1.0
max_delay = 60.0
wait_time = min(base_delay * (2 ** retry_count), max_delay)
return wait_time
def _heuristic_success_probability(self, features: Dict[str, Any]) -> float:
"""启发式方法估计成功概率"""
probability = 0.5 # 基础概率
# 基于状态码调整
status_code = features.get('status_code', 0)
if 500 <= status_code < 600:
probability -= 0.2 # 服务器错误,成功概率降低
elif status_code == 429:
probability -= 0.1 # 限流错误,成功概率降低
elif 400 <= status_code < 500:
probability -= 0.3 # 客户端错误,成功概率降低
# 基于重试次数调整
retry_count = features.get('retry_count', 0)
probability -= retry_count * 0.1 # 重试次数越多,成功概率越低
# 基于响应时间调整
response_time = features.get('response_time_ms', 0)
if response_time > 5000: # 5秒以上
probability -= 0.15 # 响应慢,成功概率降低
# 确保在0-1范围内
return max(0.0, min(1.0, probability))
def save_model(self, path: str):
"""保存模型到文件"""
model_data = {
'classification_model': self.classification_model,
'regression_model': self.regression_model,
'label_encoders': self.label_encoders,
'scaler': self.scaler,
'feature_columns': self.feature_columns
}
joblib.dump(model_data, path)
print(f"Model saved to {path}")
def load_model(self, path: str):
"""从文件加载模型"""
try:
model_data = joblib.load(path)
self.classification_model = model_data['classification_model']
self.regression_model = model_data['regression_model']
self.label_encoders = model_data['label_encoders']
self.scaler = model_data['scaler']
self.feature_columns = model_data['feature_columns']
print(f"Model loaded from {path}")
except Exception as e:
print(f"Failed to load model: {e}")
# 使用示例
class SmartRetryManager:
"""智能重试管理器"""
def __init__(self, ml_optimizer: MLRetryOptimizer = None):
self.ml_optimizer = ml_optimizer or MLRetryOptimizer()
self.retry_history = {}
async def execute_with_smart_retry(
self,
operation: callable,
operation_id: str,
context: Dict[str, Any],
max_attempts: int = 5
) -> Any:
"""使用智能重试执行操作"""
attempt = 0
last_error = None
while attempt < max_attempts:
try:
# 执行操作
result = await operation()
# 记录成功
self._record_success(operation_id, attempt, context)
return result
except Exception as e:
attempt += 1
last_error = e
# 分析错误
error_analysis = self._analyze_error(e, attempt)
# 提取特征
features = self.ml_optimizer.extract_features(
context, error_analysis
)
# 预测重试成功的概率
if self.ml_optimizer:
prediction = self.ml_optimizer.predict_retry_success(features)
# 根据预测决定是否重试
if not prediction['should_retry']:
print(f"Predicted low success probability: "
f"{prediction['success_probability']:.2f}")
break
# 使用预测的最佳等待时间
wait_time = prediction['optimal_wait_time_seconds']
else:
# 使用默认的退避策略
wait_time = self._calculate_backoff(attempt)
# 等待
print(f"Attempt {attempt} failed, waiting {wait_time:.1f}s before retry…")
await asyncio.sleep(wait_time)
# 所有重试都失败了
self._record_failure(operation_id, attempt, context, last_error)
raise last_error
def _analyze_error(self, error: Exception, attempt: int) -> Dict[str, Any]:
"""分析错误"""
analysis = {
'error_type': error.__class__.__name__,
'error_message': str(error),
'retry_count': attempt,
'timestamp': datetime.now().isoformat()
}
# 提取状态码(如果可用)
if hasattr(error, 'status_code'):
analysis['status_code'] = error.status_code
# 提取响应时间(如果可用)
if hasattr(error, 'response_time_ms'):
analysis['response_time_ms'] = error.response_time_ms
return analysis
def _calculate_backoff(self, attempt: int) -> float:
"""计算退避时间"""
base_delay = 1.0
max_delay = 60.0
return min(base_delay * (2 ** (attempt – 1)), max_delay)
def _record_success(self, operation_id: str, attempt: int,
context: Dict[str, Any]):
"""记录成功"""
if self.ml_optimizer:
# 为机器学习准备数据
features = self.ml_optimizer.extract_features(context, {
'retry_count': attempt
})
# 记录成功结果
self.ml_optimizer.record_retry_outcome(features, {
'success': True,
'wait_time_seconds': 0
})
# 更新历史记录
if operation_id not in self.retry_history:
self.retry_history[operation_id] = []
self.retry_history[operation_id].append({
'timestamp': datetime.now().isoformat(),
'attempt': attempt,
'success': True
})
def _record_failure(self, operation_id: str, attempt: int,
context: Dict[str, Any], error: Exception):
"""记录失败"""
if self.ml_optimizer:
# 为机器学习准备数据
features = self.ml_optimizer.extract_features(context, {
'retry_count': attempt,
'error_type': error.__class__.__name__,
'status_code': getattr(error, 'status_code', None)
})
# 记录失败结果
self.ml_optimizer.record_retry_outcome(features, {
'success': False,
'wait_time_seconds': 0
})
# 更新历史记录
if operation_id not in self.retry_history:
self.retry_history[operation_id] = []
self.retry_history[operation_id].append({
'timestamp': datetime.now().isoformat(),
'attempt': attempt,
'success': False,
'error': str(error)
})
# 异步使用示例
import asyncio
async def example_usage():
# 创建智能重试管理器
retry_manager = SmartRetryManager()
# 模拟一个可能失败的操作
class ExternalServiceError(Exception):
def __init__(self, status_code, message):
self.status_code = status_code
self.message = message
super().__init__(f"{status_code}: {message}")
async def call_external_service():
# 模拟外部服务调用
import random
# 随机失败
if random.random() < 0.7: # 70%的概率失败
raise ExternalServiceError(
503,
"Service temporarily unavailable"
)
return {"data": "success"}
# 准备上下文
context = {
'service_name': 'external-api',
'endpoint': '/api/data',
'client_ip': '192.168.1.100',
'timestamp': datetime.now(),
'request_size_kb': 2.5,
'concurrent_requests': 10
}
try:
# 使用智能重试执行
result = await retry_manager.execute_with_smart_retry(
call_external_service,
operation_id="external_api_call_001",
context=context,
max_attempts=5
)
print(f"操作成功: {result}")
except Exception as e:
print(f"操作最终失败: {e}")
# 运行示例
if __name__ == "__main__":
asyncio.run(example_usage())
34.4 错误监控与告警
34.4.1 实时错误监控系统
typescript
// TypeScript实时错误监控系统
import { EventEmitter } from 'events';
import { createHash } from 'crypto';
import WebSocket from 'ws';
interface ErrorEvent {
id: string;
timestamp: Date;
service: string;
endpoint: string;
statusCode: number;
errorType: string;
errorMessage: string;
stackTrace?: string;
context: Record<string, any>;
severity: 'LOW' | 'MEDIUM' | 'HIGH' | 'CRITICAL';
environment: 'development' | 'staging' | 'production';
}
interface ErrorAggregate {
errorHash: string;
firstOccurrence: Date;
lastOccurrence: Date;
count: number;
affectedServices: Set<string>;
affectedEndpoints: Set<string>;
statusCodes: Set<number>;
sampleError: ErrorEvent;
}
interface AlertRule {
id: string;
name: string;
description: string;
condition: (aggregate: ErrorAggregate) => boolean;
severity: 'LOW' | 'MEDIUM' | 'HIGH' | 'CRITICAL';
actions: string[];
}
class RealTimeErrorMonitor extends EventEmitter {
private errors: Map<string, ErrorEvent[]> = new Map();
private aggregates: Map<string, ErrorAggregate> = new Map();
private alertRules: AlertRule[] = [];
private webSocketServer: WebSocket.Server;
private aggregationWindow: number = 60000; // 1分钟
constructor(port: number = 8080) {
super();
// 初始化WebSocket服务器
this.webSocketServer = new WebSocket.Server({ port });
this.setupWebSocket();
// 初始化默认告警规则
this.initializeDefaultRules();
// 定期清理旧数据
setInterval(() => this.cleanupOldData(), 3600000); // 每小时清理一次
}
recordError(error: Omit<ErrorEvent, 'id' | 'timestamp'>): string {
const errorEvent: ErrorEvent = {
id: this.generateErrorId(),
timestamp: new Date(),
…error
};
// 存储原始错误
const key = this.getStorageKey(errorEvent);
if (!this.errors.has(key)) {
this.errors.set(key, []);
}
this.errors.get(key)!.push(errorEvent);
// 聚合错误
this.aggregateError(errorEvent);
// 触发事件
this.emit('errorRecorded', errorEvent);
// 检查告警规则
this.checkAlertRules(errorEvent);
// 广播到WebSocket客户端
this.broadcastError(errorEvent);
return errorEvent.id;
}
private generateErrorId(): string {
return createHash('sha256')
.update(Date.now().toString() + Math.random().toString())
.digest('hex')
.substring(0, 16);
}
private getStorageKey(error: ErrorEvent): string {
// 按服务、错误类型和日期分组存储
const date = error.timestamp.toISOString().split('T')[0];
return `${error.service}:${error.errorType}:${date}`;
}
private aggregateError(error: ErrorEvent): void {
const errorHash = this.calculateErrorHash(error);
if (!this.aggregates.has(errorHash)) {
this.aggregates.set(errorHash, {
errorHash,
firstOccurrence: error.timestamp,
lastOccurrence: error.timestamp,
count: 1,
affectedServices: new Set([error.service]),
affectedEndpoints: new Set([error.endpoint]),
statusCodes: new Set([error.statusCode]),
sampleError: error
});
} else {
const aggregate = this.aggregates.get(errorHash)!;
aggregate.count++;
aggregate.lastOccurrence = error.timestamp;
aggregate.affectedServices.add(error.service);
aggregate.affectedEndpoints.add(error.endpoint);
aggregate.statusCodes.add(error.statusCode);
}
// 触发聚合更新事件
this.emit('aggregateUpdated', this.aggregates.get(errorHash));
}
private calculateErrorHash(error: ErrorEvent): string {
// 基于错误特征计算哈希
const errorFingerprint = {
service: error.service,
errorType: error.errorType,
statusCode: error.statusCode,
// 可以添加更多特征
};
return createHash('sha256')
.update(JSON.stringify(errorFingerprint))
.digest('hex')
.substring(0, 16);
}
private initializeDefaultRules(): void {
this.alertRules = [
{
id: 'high-error-rate',
name: '高错误率告警',
description: '短时间内相同错误发生多次',
condition: (aggregate) => {
const timeWindow = 5 * 60 * 1000; // 5分钟
const timeDiff = aggregate.lastOccurrence.getTime() –
aggregate.firstOccurrence.getTime();
if (timeDiff < timeWindow && aggregate.count >= 10) {
const rate = aggregate.count / (timeDiff / 60000); // 每分钟错误数
return rate >= 2; // 每分钟2个以上相同错误
}
return false;
},
severity: 'HIGH',
actions: ['email', 'slack', 'pagerduty']
},
{
id: 'critical-errors',
name: '关键错误告警',
description: '出现严重级别的错误',
condition: (aggregate) => {
return aggregate.sampleError.severity === 'CRITICAL';
},
severity: 'CRITICAL',
actions: ['pagerduty', 'sms', 'phone']
},
{
id: 'service-outage',
name: '服务中断告警',
description: '同一服务出现大量不同错误',
condition: (aggregate) => {
// 检查过去10分钟内同一服务的错误数量
const tenMinutesAgo = new Date(Date.now() – 10 * 60 * 1000);
const serviceErrors = Array.from(this.aggregates.values())
.filter(agg => agg.affectedServices.has(aggregate.sampleError.service))
.filter(agg => agg.lastOccurrence > tenMinutesAgo);
const totalErrors = serviceErrors.reduce((sum, agg) => sum + agg.count, 0);
return totalErrors >= 50;
},
severity: 'CRITICAL',
actions: ['pagerduty', 'sms', 'phone']
},
{
id: 'status-code-5xx',
name: '5xx错误告警',
description: '出现服务器错误',
condition: (aggregate) => {
return Array.from(aggregate.statusCodes)
.some(code => code >= 500 && code < 600);
},
severity: 'HIGH',
actions: ['email', 'slack']
}
];
}
private checkAlertRules(error: ErrorEvent): void {
const errorHash = this.calculateErrorHash(error);
const aggregate = this.aggregates.get(errorHash);
if (!aggregate) return;
for (const rule of this.alertRules) {
if (rule.condition(aggregate)) {
this.triggerAlert(rule, aggregate);
}
}
}
private triggerAlert(rule: AlertRule, aggregate: ErrorAggregate): void {
const alert = {
id: createHash('sha256')
.update(rule.id + aggregate.errorHash + Date.now().toString())
.digest('hex')
.substring(0, 16),
rule,
aggregate,
timestamp: new Date(),
acknowledged: false,
resolved: false
};
// 触发告警事件
this.emit('alertTriggered', alert);
// 执行告警动作
this.executeAlertActions(alert);
// 广播到WebSocket客户端
this.broadcastAlert(alert);
}
private executeAlertActions(alert: any): void {
for (const action of alert.rule.actions) {
switch (action) {
case 'email':
this.sendEmailAlert(alert);
break;
case 'slack':
this.sendSlackAlert(alert);
break;
case 'pagerduty':
this.sendPagerDutyAlert(alert);
break;
case 'sms':
this.sendSmsAlert(alert);
break;
case 'phone':
this.makePhoneCall(alert);
break;
}
}
}
private sendEmailAlert(alert: any): void {
const emailContent = this.formatEmailAlert(alert);
console.log('Sending email alert:', emailContent.subject);
// 实际实现应该调用邮件服务
}
private sendSlackAlert(alert: any): void {
const slackMessage = this.formatSlackAlert(alert);
console.log('Sending Slack alert:', slackMessage);
// 实际实现应该调用Slack Webhook
}
private formatEmailAlert(alert: any): { subject: string; body: string } {
return {
subject: `[${alert.rule.severity}] ${alert.rule.name} – ${alert.aggregate.sampleError.service}`,
body: `
Alert: ${alert.rule.name}
Description: ${alert.rule.description}
Error Details:
– Service: ${alert.aggregate.sampleError.service}
– Endpoint: ${alert.aggregate.sampleError.endpoint}
– Error Type: ${alert.aggregate.sampleError.errorType}
– Status Code: ${alert.aggregate.sampleError.statusCode}
– Occurrences: ${alert.aggregate.count}
– First Occurrence: ${alert.aggregate.firstOccurrence.toISOString()}
– Last Occurrence: ${alert.aggregate.lastOccurrence.toISOString()}
Sample Error Message: ${alert.aggregate.sampleError.errorMessage}
Please investigate immediately.
`
};
}
private formatSlackAlert(alert: any): any {
const severityColors = {
'LOW': '#36a64f', // 绿色
'MEDIUM': '#ffcc00', // 黄色
'HIGH': '#ff9900', // 橙色
'CRITICAL': '#ff0000' // 红色
};
return {
attachments: [{
color: severityColors[alert.rule.severity],
title: `🚨 ${alert.rule.name}`,
text: alert.rule.description,
fields: [
{
title: 'Service',
value: alert.aggregate.sampleError.service,
short: true
},
{
title: 'Error Count',
value: alert.aggregate.count.toString(),
short: true
},
{
title: 'Status Code',
value: alert.aggregate.sampleError.statusCode.toString(),
short: true
},
{
title: 'Environment',
value: alert.aggregate.sampleError.environment,
short: true
}
],
footer: `Alert ID: ${alert.id}`,
ts: Math.floor(alert.timestamp.getTime() / 1000)
}]
};
}
private setupWebSocket(): void {
this.webSocketServer.on('connection', (ws) => {
console.log('New WebSocket connection');
// 发送当前状态
ws.send(JSON.stringify({
type: 'INITIAL_STATE',
data: {
activeAlerts: Array.from(this.aggregates.values())
.filter(agg => this.shouldShowAggregate(agg)),
recentErrors: this.getRecentErrors(50)
}
}));
ws.on('message', (message) => {
this.handleWebSocketMessage(ws, message.toString());
});
ws.on('close', () => {
console.log('WebSocket connection closed');
});
});
}
private handleWebSocketMessage(ws: WebSocket, message: string): void {
try {
const data = JSON.parse(message);
switch (data.type) {
case 'SUBSCRIBE':
this.handleSubscribe(ws, data.channel);
break;
case 'UNSUBSCRIBE':
this.handleUnsubscribe(ws, data.channel);
break;
case 'ACKNOWLEDGE_ALERT':
this.handleAcknowledgeAlert(data.alertId);
break;
}
} catch (error) {
console.error('Error handling WebSocket message:', error);
}
}
private handleSubscribe(ws: WebSocket, channel: string): void {
// 实际实现应该管理订阅关系
console.log(`Client subscribed to ${channel}`);
}
private broadcastError(error: ErrorEvent): void {
const message = JSON.stringify({
type: 'NEW_ERROR',
data: error
});
this.webSocketServer.clients.forEach((client) => {
if (client.readyState === WebSocket.OPEN) {
client.send(message);
}
});
}
private broadcastAlert(alert: any): void {
const message = JSON.stringify({
type: 'NEW_ALERT',
data: alert
});
this.webSocketServer.clients.forEach((client) => {
if (client.readyState === WebSocket.OPEN) {
client.send(message);
}
});
}
private getRecentErrors(count: number): ErrorEvent[] {
const allErrors: ErrorEvent[] = [];
for (const errors of this.errors.values()) {
allErrors.push(…errors);
}
return allErrors
.sort((a, b) => b.timestamp.getTime() – a.timestamp.getTime())
.slice(0, count);
}
private shouldShowAggregate(aggregate: ErrorAggregate): boolean {
// 只显示最近活跃的聚合
const fiveMinutesAgo = new Date(Date.now() – 5 * 60 * 1000);
return aggregate.lastOccurrence > fiveMinutesAgo && aggregate.count >= 5;
}
private cleanupOldData(): void {
const twentyFourHoursAgo = new Date(Date.now() – 24 * 60 * 60 * 1000);
// 清理旧错误
for (const [key, errors] of this.errors) {
const recentErrors = errors.filter(error =>
error.timestamp > twentyFourHoursAgo
);
if (recentErrors.length === 0) {
this.errors.delete(key);
} else {
this.errors.set(key, recentErrors);
}
}
// 清理旧聚合
for (const [hash, aggregate] of this.aggregates) {
if (aggregate.lastOccurrence < twentyFourHoursAgo) {
this.aggregates.delete(hash);
}
}
console.log('Cleanup completed');
}
// 公共API方法
getErrorStatistics(): any {
const now = new Date();
const oneHourAgo = new Date(now.getTime() – 60 * 60 * 1000);
const twentyFourHoursAgo = new Date(now.getTime() – 24 * 60 * 60 * 1000);
const recentErrors = this.getRecentErrors(1000);
const hourErrors = recentErrors.filter(e => e.timestamp > oneHourAgo);
const dayErrors = recentErrors.filter(e => e.timestamp > twentyFourHoursAgo);
const stats = {
current: {
total: hourErrors.length,
byService: this.groupBy(hourErrors, 'service'),
byStatusCode: this.groupBy(hourErrors, 'statusCode'),
bySeverity: this.groupBy(hourErrors, 'severity')
},
daily: {
total: dayErrors.length,
byService: this.groupBy(dayErrors, 'service'),
byStatusCode: this.groupBy(dayErrors, 'statusCode'),
bySeverity: this.groupBy(dayErrors, 'severity')
},
aggregates: Array.from(this.aggregates.values())
.filter(agg => this.shouldShowAggregate(agg))
.map(agg => ({
errorHash: agg.errorHash,
count: agg.count,
services: Array.from(agg.affectedServices),
statusCodes: Array.from(agg.statusCodes),
lastOccurrence: agg.lastOccurrence
}))
};
return stats;
}
private groupBy(errors: ErrorEvent[], key: keyof ErrorEvent): Record<string, number> {
const result: Record<string, number> = {};
for (const error of errors) {
const value = String(error[key]);
result[value] = (result[value] || 0) + 1;
}
return result;
}
acknowledgeAlert(alertId: string): void {
this.emit('alertAcknowledged', alertId);
}
addAlertRule(rule: AlertRule): void {
this.alertRules.push(rule);
}
removeAlertRule(ruleId: string): void {
this.alertRules = this.alertRules.filter(rule => rule.id !== ruleId);
}
}
// 使用示例
const errorMonitor = new RealTimeErrorMonitor(8080);
// 监听事件
errorMonitor.on('errorRecorded', (error: ErrorEvent) => {
console.log('Error recorded:', error.id, error.errorType);
});
errorMonitor.on('alertTriggered', (alert) => {
console.log('Alert triggered:', alert.rule.name);
});
// 记录错误
errorMonitor.recordError({
service: 'order-service',
endpoint: '/api/orders',
statusCode: 503,
errorType: 'ServiceUnavailableError',
errorMessage: 'Database connection failed',
context: {
userId: 'user123',
orderId: 'order456',
retryCount: 2
},
severity: 'HIGH',
environment: 'production'
});
// 获取统计信息
const stats = errorMonitor.getErrorStatistics();
console.log('Error statistics:', stats);
34.5 错误处理最佳实践总结
34.5.1 状态码与错误处理检查清单
yaml
# 状态码与错误处理最佳实践检查清单
error_handling_checklist:
# 设计阶段
design_phase:
– 定义了清晰的错误分类体系
– 建立了错误严重性等级
– 设计了分层错误处理架构
– 确定了错误传播策略
– 规划了降级和恢复机制
# 开发阶段
development_phase:
http_status_codes:
– 正确使用语义化的状态码
– 4xx错误用于客户端问题
– 5xx错误用于服务器问题
– 为特殊情况使用正确的状态码(如422、429)
error_responses:
– 错误响应格式标准化(RFC 7807)
– 包含唯一的错误标识符
– 提供人类可读的错误信息
– 包含机器可读的错误代码
– 提供相关的上下文信息
– 包含有帮助的建议操作
client_handling:
– 客户端有适当的重试逻辑
– 实现了指数退避算法
– 考虑了网络不稳定性
– 提供了用户友好的错误提示
– 实现了优雅的降级处理
server_handling:
– 实现了全局异常处理
– 错误被正确记录和监控
– 敏感信息不被泄露
– 实现了断路器模式
– 有超时和重试控制
# 运维阶段
operations_phase:
monitoring:
– 设置了错误率监控
– 配置了适当的告警规则
– 实现了分布式追踪
– 有实时错误仪表板
– 错误日志结构化
alerting:
– 告警级别定义清晰
– 告警接收人配置正确
– 告警阈值设置合理
– 有告警升级机制
– 告警包含足够的上下文
incident_response:
– 有明确的故障排查流程
– 错误ID可以追踪到具体请求
– 有回滚和恢复计划
– 定期进行故障演练
– 有事后分析(Post-mortem)流程
# 持续改进
continuous_improvement:
– 定期分析错误模式
– 根据错误数据优化系统
– 更新错误处理策略
– 改进监控和告警
– 分享错误处理经验
34.5.2 错误处理策略决策树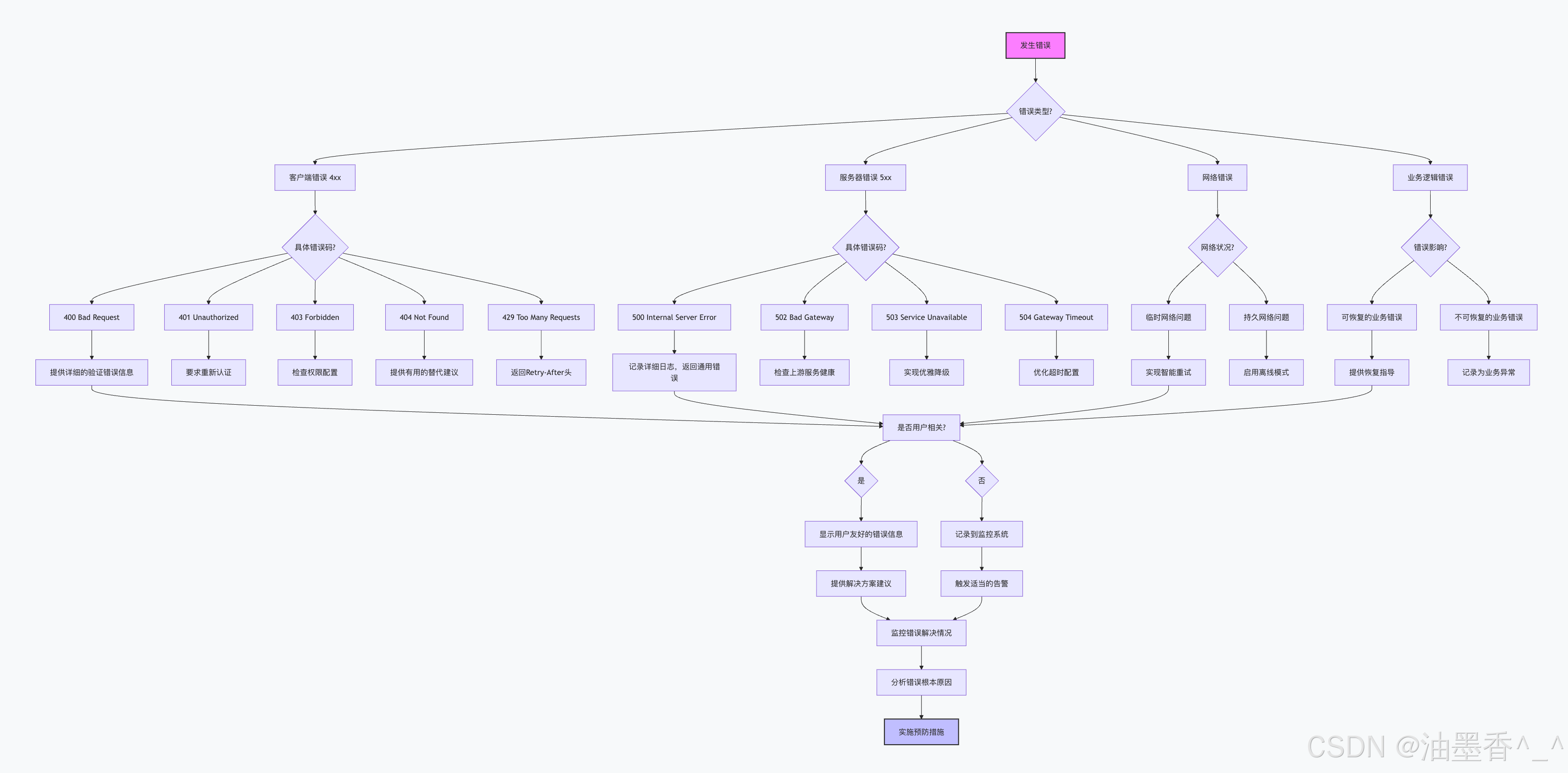
34.5.3 错误处理成熟度模型
markdown
# 错误处理成熟度模型
## Level 0: 混沌阶段
– 错误被忽略或简单打印
– 没有统一的错误处理
– 状态码使用随意
– 错误信息泄露敏感数据
– 没有监控和告警
## Level 1: 基础阶段
– 基本的异常处理
– 统一的错误响应格式
– 正确的HTTP状态码使用
– 简单的日志记录
– 基础的错误分类
## Level 2: 标准阶段
– 分层的错误处理架构
– 智能重试机制
– 断路器模式实现
– 结构化日志记录
– 基本的监控和告警
## Level 3: 先进阶段
– 自适应的错误处理策略
– 预测性错误预防
– 机器学习优化
– 实时错误监控
– 自动化故障恢复
## Level 4: 卓越阶段
– 主动错误预防
– 自我修复系统
– 预测性维护
– 全链路错误追踪
– 持续优化和改进
## 评估指标
1. 错误处理覆盖率:处理了多大比例的错误场景
2. 错误恢复时间:从错误中恢复的平均时间
3. 错误预防能力:预防了多少潜在错误
4. 用户体验影响:错误对用户的影响程度
5. 运维效率:错误排查和解决的效率
34.6 未来趋势
34.6.1 AI驱动的错误处理
python
# AI驱动的智能错误处理系统
import openai
from typing import Dict, Any, List, Optional
import json
from datetime import datetime
class AIErrorHandler:
"""AI驱动的错误处理器"""
def __init__(self, api_key: str):
openai.api_key = api_key
self.error_history: List[Dict[str, Any]] = []
self.solution_cache: Dict[str, str] = {}
async def analyze_error(self, error: Exception, context: Dict[str, Any]) -> Dict[str, Any]:
"""使用AI分析错误"""
# 准备分析提示
prompt = self._create_analysis_prompt(error, context)
try:
# 调用AI分析
response = await openai.ChatCompletion.acreate(
model="gpt-4",
messages=[
{"role": "system", "content": "你是一个经验丰富的软件工程师,擅长错误分析和调试。"},
{"role": "user", "content": prompt}
],
temperature=0.7,
max_tokens=500
)
analysis_text = response.choices[0].message.content
# 解析AI响应
analysis = self._parse_ai_response(analysis_text)
# 记录分析结果
analysis_record = {
"error": str(error),
"error_type": error.__class__.__name__,
"context": context,
"analysis": analysis,
"timestamp": datetime.now().isoformat()
}
self.error_history.append(analysis_record)
return analysis
except Exception as e:
# AI分析失败,返回基本分析
return self._basic_error_analysis(error, context)
def _create_analysis_prompt(self, error: Exception, context: Dict[str, Any]) -> str:
"""创建AI分析提示"""
prompt = f"""
请分析以下错误并提供解决方案建议:
错误类型:{error.__class__.__name__}
错误信息:{str(error)}
上下文信息:
{json.dumps(context, indent=2, default=str)}
请按以下格式提供分析:
1. 错误原因分析
2. 影响评估
3. 立即解决方案
4. 长期预防措施
5. 相关文档链接(如果有)
请用中文回答。
"""
return prompt
def _parse_ai_response(self, response_text: str) -> Dict[str, Any]:
"""解析AI响应"""
# 这里可以添加更复杂的解析逻辑
# 简单实现:按行分割并分类
lines = response_text.strip().split('\\n')
analysis = {
"cause": "",
"impact": "",
"immediate_solution": "",
"long_term_prevention": "",
"documentation": []
}
current_section = None
for line in lines:
line = line.strip()
if line.startswith('1.') or '错误原因' in line:
current_section = 'cause'
elif line.startswith('2.') or '影响评估' in line:
current_section = 'impact'
elif line.startswith('3.') or '立即解决方案' in line:
current_section = 'immediate_solution'
elif line.startswith('4.') or '长期预防措施' in line:
current_section = 'long_term_prevention'
elif line.startswith('5.') or '相关文档链接' in line:
current_section = 'documentation'
elif current_section and line:
if current_section == 'documentation':
analysis['documentation'].append(line)
else:
analysis[current_section] += line + '\\n'
return analysis
def _basic_error_analysis(self, error: Exception, context: Dict[str, Any]) -> Dict[str, Any]:
"""基本错误分析(备用)"""
error_type = error.__class__.__name__
# 基于错误类型的简单分析
analysis_templates = {
"ConnectionError": {
"cause": "网络连接失败,可能是网络不稳定或服务不可用",
"impact": "用户无法访问相关功能",
"immediate_solution": "检查网络连接,重试操作",
"long_term_prevention": "实现重试机制,增加连接超时设置"
},
"TimeoutError": {
"cause": "操作超时,可能是服务响应慢或网络延迟",
"impact": "用户体验下降,操作可能失败",
"immediate_solution": "增加超时时间,优化查询",
"long_term_prevention": "优化服务性能,实现异步处理"
},
"ValueError": {
"cause": "参数值无效,可能是输入验证不充分",
"impact": "操作无法完成,可能影响数据一致性",
"immediate_solution": "检查输入参数,提供更详细的错误信息",
"long_term_prevention": "加强输入验证,提供更好的用户指导"
}
}
if error_type in analysis_templates:
return analysis_templates[error_type]
else:
return {
"cause": f"未知错误类型: {error_type}",
"impact": "需要进一步分析",
"immediate_solution": "查看详细日志,联系开发人员",
"long_term_prevention": "增加错误监控和日志记录"
}
async def suggest_solution(self, error_signature: str) -> Optional[str]:
"""基于历史记录建议解决方案"""
# 检查缓存
if error_signature in self.solution_cache:
return self.solution_cache[error_signature]
# 查找类似的历史错误
similar_errors = self._find_similar_errors(error_signature)
if similar_errors:
# 使用AI总结解决方案
prompt = self._create_solution_prompt(similar_errors)
try:
response = await openai.ChatCompletion.acreate(
model="gpt-4",
messages=[
{"role": "system", "content": "你是一个经验丰富的软件工程师。"},
{"role": "user", "content": prompt}
],
temperature=0.7,
max_tokens=300
)
solution = response.choices[0].message.content
# 缓存解决方案
self.solution_cache[error_signature] = solution
return solution
except Exception:
return None
return None
def _find_similar_errors(self, error_signature: str) -> List[Dict[str, Any]]:
"""查找类似的错误"""
# 简单的相似度匹配
# 实际实现可以使用更复杂的算法
similar = []
for error_record in self.error_history[-100:]: # 最近100个错误
error_text = error_record["error"]
# 计算简单的相似度
similarity = self._calculate_similarity(error_signature, error_text)
if similarity > 0.7: # 相似度阈值
similar.append(error_record)
return similar
def _calculate_similarity(self, text1: str, text2: str) -> float:
"""计算文本相似度(简化实现)"""
# 实际实现可以使用更复杂的相似度算法
# 这里使用简单的词重叠率
words1 = set(text1.lower().split())
words2 = set(text2.lower().split())
if not words1 or not words2:
return 0.0
intersection = words1.intersection(words2)
union = words1.union(words2)
return len(intersection) / len(union)
def _create_solution_prompt(self, similar_errors: List[Dict[str, Any]]) -> str:
"""创建解决方案提示"""
prompt = "基于以下类似错误的分析和解决方案,请总结一个通用的解决方案:\\n\\n"
for i, error_record in enumerate(similar_errors[:3], 1): # 最多3个例子
prompt += f"错误示例 {i}:\\n"
prompt += f"错误信息: {error_record['error']}\\n"
if 'analysis' in error_record:
prompt += f"分析结果: {json.dumps(error_record['analysis'], ensure_ascii=False)}\\n"
prompt += "\\n"
prompt += "请提供一个简洁有效的解决方案,用中文回答。"
return prompt
def generate_error_report(self, time_period: str = "daily") -> Dict[str, Any]:
"""生成错误报告"""
now = datetime.now()
if time_period == "daily":
start_time = datetime(now.year, now.month, now.day)
elif time_period == "weekly":
start_time = datetime(now.year, now.month, now.day – 7)
elif time_period == "monthly":
start_time = datetime(now.year, now.month – 1, now.day)
else:
start_time = datetime(1970, 1, 1) # 所有时间
# 过滤指定时间段的错误
recent_errors = [
error for error in self.error_history
if datetime.fromisoformat(error["timestamp"]) > start_time
]
# 生成报告
report = {
"period": time_period,
"total_errors": len(recent_errors),
"unique_error_types": len(set(e["error_type"] for e in recent_errors)),
"most_common_errors": self._get_most_common(recent_errors, "error_type"),
"error_trend": self._calculate_error_trend(recent_errors),
"resolution_rate": self._calculate_resolution_rate(recent_errors),
"recommendations": self._generate_recommendations(recent_errors)
}
return report
def _get_most_common(self, errors: List[Dict[str, Any]], key: str) -> List[Dict[str, Any]]:
"""获取最常见的错误"""
from collections import Counter
counter = Counter(e[key] for e in errors)
return [
{"type": error_type, "count": count}
for error_type, count in counter.most_common(5)
]
def _calculate_error_trend(self, errors: List[Dict[str, Any]]) -> str:
"""计算错误趋势"""
if len(errors) < 2:
return "数据不足"
# 按时间分组
hourly_counts = {}
for error in errors:
timestamp = datetime.fromisoformat(error["timestamp"])
hour_key = timestamp.strftime("%Y-%m-%d %H:00")
hourly_counts[hour_key] = hourly_counts.get(hour_key, 0) + 1
# 简单趋势判断
sorted_hours = sorted(hourly_counts.keys())
if len(sorted_hours) < 2:
return "稳定"
recent_count = hourly_counts[sorted_hours[-1]]
previous_count = hourly_counts[sorted_hours[-2]]
if recent_count > previous_count * 1.5:
return "上升"
elif recent_count < previous_count * 0.5:
return "下降"
else:
return "稳定"
def _calculate_resolution_rate(self, errors: List[Dict[str, Any]]) -> float:
"""计算解决率(简化实现)"""
# 实际实现应该基于实际的解决状态
# 这里使用一个简化的假设
total = len(errors)
if total == 0:
return 1.0
# 假设80%的错误已经解决
return 0.8
def _generate_recommendations(self, errors: List[Dict[str, Any]]) -> List[str]:
"""生成改进建议"""
recommendations = []
# 分析错误模式
error_types = [e["error_type"] for e in errors]
type_counter = Counter(error_types)
for error_type, count in type_counter.most_common(3):
if count > 10: # 频繁出现的错误
recommendations.append(
f"频繁出现 {error_type} 错误({count}次),建议重点排查"
)
# 检查是否有新的错误类型
recent_errors = errors[-20:] # 最近20个错误
new_types = set(e["error_type"] for e in recent_errors)
all_types = set(e["error_type"] for e in errors)
if len(new_types) > len(all_types) * 0.3: # 30%以上是新类型
recommendations.append(
"发现大量新的错误类型,建议检查最近的代码变更"
)
return recommendations
# 使用示例
async def example_ai_error_handling():
# 初始化AI错误处理器
ai_handler = AIErrorHandler(api_key="your-openai-api-key")
# 模拟一个错误
try:
# 模拟一个可能失败的操作
raise ConnectionError("Failed to connect to database: Connection refused")
except Exception as e:
# 准备错误上下文
context = {
"service": "order-service",
"endpoint": "/api/orders",
"user_id": "user123",
"request_id": "req-abc-123",
"timestamp": datetime.now().isoformat(),
"environment": "production"
}
# 使用AI分析错误
analysis = await ai_handler.analyze_error(e, context)
print("AI错误分析结果:")
print(f"原因: {analysis.get('cause', 'N/A')}")
print(f"影响: {analysis.get('impact', 'N/A')}")
print(f"立即解决方案: {analysis.get('immediate_solution', 'N/A')}")
print(f"长期预防措施: {analysis.get('long_term_prevention', 'N/A')}")
# 生成错误报告
report = ai_handler.generate_error_report("daily")
print("\\n每日错误报告:")
print(json.dumps(report, indent=2, ensure_ascii=False))
# 运行示例
if __name__ == "__main__":
import asyncio
asyncio.run(example_ai_error_handling())
34.7 总结
34.7.1 关键收获
错误处理是系统工程
-
不仅仅是技术实现,更是架构设计
-
需要考虑用户体验、运维效率、系统稳定性等多个维度
-
应该作为系统设计的重要组成部分
状态码是指南针
-
正确的状态码使用是良好API设计的基础
-
状态码应该与错误类型和严重性相匹配
-
状态码应该能够指导客户端的行为
智能化的错误处理
-
重试策略应该基于错误类型和上下文
-
机器学习可以帮助优化错误处理决策
-
AI可以辅助错误分析和解决方案生成
监控与持续改进
-
没有监控的错误处理是不完整的
-
错误数据应该用于持续改进系统
-
应该建立错误处理的反馈循环
34.7.2 实际应用建议
从小处开始
-
从最基本的错误分类和状态码开始
-
逐步引入更高级的错误处理策略
-
根据实际需求选择合适的工具和技术
关注用户体验
-
错误信息应该对用户有帮助
-
提供明确的解决方案或下一步行动
-
避免技术术语和敏感信息
建立文化
-
错误处理应该是团队共识
-
鼓励分享错误处理经验
-
定期回顾和改进错误处理策略
保持简单
-
复杂不等于更好
-
选择简单有效的解决方案
-
避免过度工程化
34.7.3 未来展望
随着技术的发展,错误处理将变得更加智能和自动化:
预测性错误预防
-
在错误发生前预测和预防
-
基于历史数据的模式识别
-
自动化的系统优化
自愈系统
-
系统能够自动检测和修复错误
-
基于规则的自动恢复
-
无需人工干预的错误处理
全链路可观测性
-
端到端的错误追踪
-
跨服务的错误传播分析
-
基于AI的根本原因分析
人性化交互
-
更自然的错误沟通方式
-
基于上下文的个性化解决方案
-
增强现实辅助的错误排查
通过本章的学习,您应该对状态码与错误处理策略有了全面的理解。记住,好的错误处理不仅能让系统更加稳定,还能提升用户体验,减少运维负担。在不断变化的数字世界中,强大的错误处理能力是系统可靠性的基石。




评论前必须登录!
注册