 网硕互联帮助中心
网硕互联帮助中心
一、系统与硬件环境说明
| CPU | 鲲鹏 920 / 930 系列(ARM64架构) |
| GPU/NPU | 华为昇腾 910B2 × 2(支持BF16、INT8量化) |
| 内存 | ≥ 256GB |
| 存储 | ≥ 2TB SSD |
| 操作系统 | openEuler / 麒麟 / 统信UOS(国产信创OS) |
| 驱动 | CANN ≥ 8.0;Ascend Toolkit ≥ 8.0 |
| 框架环境 | MindSpore ≥ 2.3;torch-npu ≥ 2.1(兼容PyTorch 2.1) |
| 部署工具 | XInference ≥ 0.12,Ascend ATC 工具 |
二、模型来源与基本结构
| Qwen3-32B-Base | 从阿里巴巴官方 / Hugging Face 下载 | 32B | PyTorch | .bin / .safetensors | FP16 / BF16 | 原始预训练模型 |
| Qwen3-32B-Finetuned | 在昇腾910B2上进行微调(使用MindSpore框架) | 32B | MindSpore | .ckpt | INT8 / BF16 | 行业定制微调模型 |
三、模型格式转换流程
模型部署前需统一格式,昇腾平台推荐使用 MindIR 或 OM 格式。
1️⃣ 从 PyTorch 格式转换到 MindIR 格式
方法 1:通过 MindConverter
MindConverter 是昇腾官方提供的跨框架模型转换工具。
mindconverter –in_framework pytorch \\
–model_file /models/qwen32b/pytorch_model.bin \\
–input_shape '[1,1024]' \\
–output_file /models/qwen32b/qwen32b.mindir
方法 2:通过 ONNX 中转
如果MindConverter转换失败,可通过ONNX作为中间层:
# PyTorch -> ONNX
import torch
dummy_input = torch.ones(1, 1024, dtype=torch.int64)
torch.onnx.export(model, dummy_input, "qwen32b.onnx", opset_version=17)
# ONNX -> MindIR
atc –model=qwen32b.onnx \\
–framework=5 \\
–output=qwen32b_mindir \\
–soc_version=Ascend910B2
2️⃣ MindIR → OM(部署优化格式)
OM(Offline Model)是昇腾芯片的离线执行优化格式,部署时加载性能更优。
atc –model=qwen32b.mindir \\
–framework=1 \\
–output=qwen32b_om \\
–input_format=ND \\
–input_shape="input_ids:1,1024" \\
–soc_version=Ascend910B2 \\
–precision_mode=allow_mix_precision
⚙️ 注意:
- soc_version 必须与昇腾芯片型号一致。
- MindIR 格式支持训练和部署;OM 格式仅支持推理。
四、模型部署方式
我们希望部署两个模型(Base 与 Finetuned),并可在 XInference 中动态切换。
1️⃣ 环境目录结构
/models/
│
├── qwen32b_base/
│ ├── qwen32b_om.om
│ └── config.json
│
└── qwen32b_finetune/
├── qwen32b_finetune_om.om
└── config.json
2️⃣ 启动 XInference 服务
# 启动 Base 模型
xinf start –model Qwen3-32B-Base \\
–model-path /models/qwen32b_base \\
–device ascend \\
–precision bf16 \\
–port 8081
# 启动 Finetuned 模型
xinf start –model Qwen3-32B-Finetuned \\
–model-path /models/qwen32b_finetune \\
–device ascend \\
–precision int8 \\
–port 8082
✅ 支持使用 Docker 容器化部署(xinf ascend-runtime 官方镜像)
3️⃣ 模型注册配置(xinf.json)
{
"models": [
{
"name": "Qwen3-32B-Base",
"path": "/models/qwen32b_base/qwen32b_om.om",
"device": "ascend",
"port": 8081,
"precision": "bf16"
},
{
"name": "Qwen3-32B-Finetuned",
"path": "/models/qwen32b_finetune/qwen32b_finetune_om.om",
"device": "ascend",
"port": 8082,
"precision": "int8"
}
]
}
五、XInference 模型切换与调用
1️⃣ 模型动态切换(REST API)
curl -X POST http://localhost:8000/api/models/select \\
-H "Content-Type: application/json" \\
-d '{"model_name": "Qwen3-32B-Finetuned"}'
切换回原始模型:
curl -X POST http://localhost:8000/api/models/select \\
-d '{"model_name": "Qwen3-32B-Base"}'
2️⃣ 推理调用示例(Python)
import requests
def query_model(port, prompt):
url = f"http://localhost:{port}/v1/completions"
payload = {
"prompt": prompt,
"max_tokens": 256,
"temperature": 0.8
}
headers = {"Content-Type": "application/json"}
response = requests.post(url, headers=headers, json=payload)
return response.json()["choices"][0]["text"]
print("Base模型回答:")
print(query_model(8081, "介绍一下鲲鹏920的CPU架构优势"))
print("\\nFinetuned模型回答:")
print(query_model(8082, "解释一下信创生态下AI算法的优势"))
六、模型推理性能与优化
| INT8量化 | 微调模型在导出时使用量化感知训练(QAT) | 显存降低约 50%,速度提升约 1.6× |
| 双卡并行推理 | 使用两张910B2卡分别部署两个模型 | 实现模型并行调用 |
| Pipeline切分 | 模型前向传播分段执行 | 适合显存不足情况 |
| XInference异步队列 | 支持多请求并发分发 | 提升吞吐量 2~3倍 |
七、常见问题与解决建议
| CANN不支持该算子 | 转换时ONNX算子不兼容 | 在atc命令中加–customize_op 或使用MindSpore原生模型 |
| 内存不足 | 模型显存开销大 | 开启INT8量化或分层加载 |
| XInference无法加载 | 模型路径或格式不匹配 | 确认.om文件路径与配置文件一致 |
| 请求延迟高 | 同步阻塞 | 使用异步调用API或多进程部署 |
八、总结
| 模型训练框架 | MindSpore(昇腾原生) | 微调阶段效率高 |
| 模型部署格式 | MindIR / OM | 原生支持昇腾推理 |
| 多模型调用 | XInference 动态注册切换 | 快速在Base与Finetune模型间切换 |
| 性能优化 | INT8量化 + 双卡并发 + 异步推理 | 满足信创硬件约束 |
| 兼容性 | 支持PyTorch、MindSpore、ONNX统一部署 | 适配灵活 |

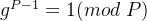

评论前必须登录!
注册