 网硕互联帮助中心
网硕互联帮助中心原文:Anthropic 官方揭秘:让 Agent 调用上千工具却不爆上下文的秘诀
想象一下这样的场景:你的 AI 助手同时连接了 GitHub、Slack、Jira、Google Drive,还有公司内部的十几个 MCP 服务器。
听起来很美好对吧?
但现实是——光是这些工具的定义,就能吃掉 10 万个 Token。对话还没开始,上下文窗口已经所剩无几。
这就是当前 Agent 开发的核心困境:工具越多,能力越强,但上下文也越容易被撑爆。
Anthropic 最近放出了三个大招,正是为了解决这个问题。我研究了一番,发现这套组合拳的思路非常值得借鉴。
一、问题到底有多严重?
先看一组真实数据。假设你的系统接入了五个常见服务:
| GitHub | 35 个 | ~26K |
| Slack | 11 个 | ~21K |
| Sentry | 5 个 | ~3K |
| Grafana | 5 个 | ~3K |
| Splunk | 2 个 | ~2K |
58 个工具,55K Token,对话还没开始。
再加个 Jira(17K Token),轻松突破 100K。Anthropic 内部优化前,工具定义甚至吃掉了 134K Token。
Token 消耗还不是唯一的问题。
当工具太多时,模型容易选错工具、填错参数。尤其是名字相似的工具,比如 notification-send-user 和 notification-send-channel,一不小心就发错地方了。
二、工具搜索工具:用"搜索"代替"全加载"
这名字有点绕——工具搜索工具,本质上是一个用来搜索其他工具的工具。
核心思路
传统做法是把所有工具定义预先塞进上下文。新方案是:只加载一个搜索工具,其他工具按需发现。
Claude 需要什么能力,就搜什么工具。搜到了再加载完整定义。
效果有多明显?直接看对比:
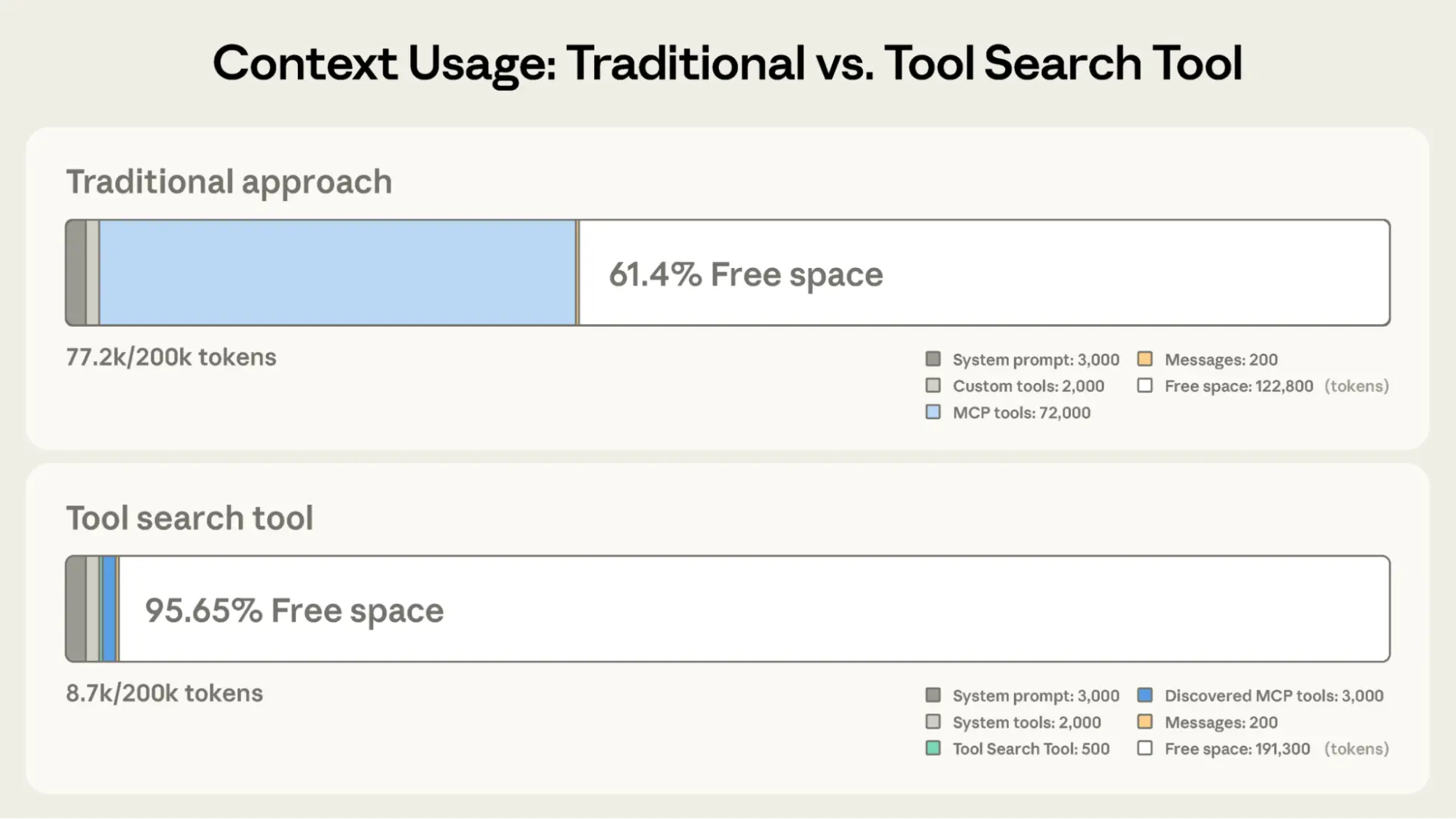
| 预加载消耗 | ~72K Token | ~500 Token |
| 实际工作时 | ~77K Token | ~8.7K Token |
| 可用上下文 | 剩余 ~60% | 剩余 ~95% |
Token 使用量减少了 85%,同时保留完整的工具库访问权限。
更惊喜的是准确率提升:Opus 4 从 49% 提升到 74%,Opus 4.5 从 79.5% 提升至 88.1%。
怎么用?
给工具加一个标记 defer_loading: true,表示"延迟加载":
{
"tools": [
{"type": "tool_search_tool_regex_20251119", "name": "tool_search_tool_regex"},
{
"name": "github.createPullRequest",
"description": "Create a pull request",
"input_schema": {…},
"defer_loading": true // 按需加载
}
]
}
对于 MCP 服务,可以整个服务延迟加载,但保留最常用的那几个:
{
"type": "mcp_toolset",
"mcp_server_name": "google-drive",
"default_config": {"defer_loading": true},
"configs": {
"search_files": {"defer_loading": false} // 高频工具保持加载
}
}
提示词缓存不受影响——延迟加载的工具本来就不在初始提示词里,只有被搜到才会加入上下文。
什么时候该用?
推荐使用:
- 工具定义超过 10K Token
- 工具选择准确率不高
- 接入多个 MCP 服务
- 工具数量超过 10 个
可以不用:
- 工具少于 10 个
- 所有工具都高频使用
- 工具定义本身就很精简
三、程序化工具调用:让 Claude 写代码来编排工具
传统工具调用有两个痛点:
痛点一:中间结果污染上下文
分析一个 10MB 的日志文件,Claude 只需要"错误频率统计",但传统方式会把整个文件塞进上下文。跨表查询客户数据?每条记录都会累积进来。
痛点二:推理开销太大
每次工具调用都要走一遍完整的模型推理。五个工具串联,就是五次推理,还要用自然语言来"对账"和"汇总"。又慢又容易出错。
解决方案:用 Python 编排,而不是自然语言推理
程序化工具调用让 Claude 写一段 Python 脚本,在沙箱环境中执行。中间结果在代码里处理,只有最终结果进入上下文。
举个例子:查询哪些员工超出了 Q3 差旅预算。
传统方法:
程序化工具调用:
team = await get_team_members("engineering")
# 并行获取每个级别的预算
levels = list(set(m["level"] for m in team))
budget_results = await asyncio.gather(*[
get_budget_by_level(level) for level in levels
])
budgets = {level: budget for level, budget in zip(levels, budget_results)}
# 并行获取所有人的开销
expenses = await asyncio.gather(*[
get_expenses(m["id"], "Q3") for m in team
])
# 筛选超预算的员工
exceeded = []
for member, exp in zip(team, expenses):
budget = budgets[member["level"]]
total = sum(e["amount"] for e in exp)
if total > budget["travel_limit"]:
exceeded.append({
"name": member["name"],
"spent": total,
"limit": budget["travel_limit"]
})
print(json.dumps(exceeded))
Claude 最终只看到几个超预算员工的名字和数字,200KB 数据压缩到 1KB。
效果数据
| Token 消耗 | 降低 37%(43588 → 27297) |
| 延迟 | 消除 19+ 次推理开销 |
| 准确率 | 知识检索 25.6% → 28.5%,GIA 基准 46.5% → 51.2% |
适用场景
推荐使用:
- 处理大数据集,只需要聚合结果
- 多步骤工作流(3 个以上依赖调用)
- 需要对工具结果进行筛选、排序、转换
- 中间数据不应影响 Claude 的推理判断
- 多任务并行执行
可以不用:
- 简单的单工具调用
- Claude 需要看到并推理所有中间结果
- 快速查询,响应数据量小
四、工具使用示例:Schema 定义结构,示例教会用法
JSON Schema 很擅长定义"什么是合法的",但不擅长表达"怎么用才对"。
看这个工单 API 的 Schema:
{
"name": "create_ticket",
"input_schema": {
"properties": {
"title": {"type": "string"},
"priority": {"enum": ["low", "medium", "high", "critical"]},
"due_date": {"type": "string"},
"reporter": {
"type": "object",
"properties": {
"id": {"type": "string"},
"contact": {"type": "object", "properties": {…}}
}
},
"escalation": {"type": "object", "properties": {…}}
},
"required": ["title"]
}
}
Schema 没告诉你:
- due_date 该用 2026-01-23 还是 Jan 23, 2026?
- reporter.id 是 UUID 还是 USR-12345 格式?
- 什么时候需要填 contact 信息?
- escalation 参数和 priority 有什么关联?
解决方案:直接给示例
{
"name": "create_ticket",
"input_schema": {…},
"input_examples": [
{
"title": "Login page returns 500 error",
"priority": "critical",
"labels": ["bug", "authentication", "production"],
"reporter": {"id": "USR-12345", "name": "Jane Smith", "contact": {…}},
"due_date": "2026-01-23",
"escalation": {"level": 2, "notify_manager": true, "sla_hours": 4}
},
{
"title": "Add dark mode support",
"labels": ["feature-request", "ui"],
"reporter": {"id": "USR-67890", "name": "Alex Chen"}
},
{
"title": "Update API documentation"
}
]
}
三个示例教会了 Claude:
- 格式规范:日期用 YYYY-MM-DD,用户 ID 用 USR-XXXXX,标签用短横线命名
- 嵌套结构:reporter 里面有 contact,怎么构建
- 参数关联:
- critical 级别的 bug → 完整联系信息 + 严格 SLA
- feature-request → 有提交者,但不需要联系信息和升级机制
- 内部任务 → 只填标题就够了
内部测试显示,复杂参数处理的准确率从 72% 提升到 90%。
五、最佳实践:按需组合,分层使用
这三个功能不是非此即彼,而是互补的工具链:
| 工具定义撑爆上下文 | 工具搜索工具 |
| 中间结果污染推理 | 程序化工具调用 |
| 参数格式总出错 | 工具使用示例 |
它们的关系是:
几个实操建议
优化工具搜索:工具名称和描述要清晰,搜索靠的就是匹配这两项。
// 好
{"name": "search_customer_orders", "description": "Search for customer orders by date range, status, or total amount…"}
// 差
{"name": "query_db_orders", "description": "Execute order query"}
在系统提示词里告诉 Claude 有哪些能力可用:
你具备 Slack 消息收发、Google Drive 文件管理、Jira 工单跟踪、GitHub 仓库操作的工具权限。
可使用工具搜索功能查找具体操作能力。
优化程序化调用:清晰地文档化返回格式,方便 Claude 写解析代码。
{
"name": "get_orders",
"description": "Retrieve orders for a customer.\\nReturns:\\n- id (str): Order identifier\\n- total (float): Order total in USD\\n- status (str): One of 'pending', 'shipped', 'delivered'…"
}
优化工具示例:
- 用真实数据,不是 "string" 或 "value"
- 最小、部分、完整三种规格分层展示
- 每个工具 1-5 个示例足矣
- 只为 Schema 表达不清的地方加示例
写在最后
这三个功能,本质上是在回答同一个问题:当 Agent 的能力边界不断扩展,如何让它在"无限工具库"中依然保持高效和精准?
答案是:从"全塞进去"走向"智能编排"。
- 工具太多?按需搜索,用到再加载
- 数据太杂?代码处理,只返回结论
- 参数复杂?示例教学,比文档管用
这套思路不止适用于 Claude 平台。任何涉及大规模工具调用的 Agent 系统,都可以借鉴这种"发现 – 执行 – 精准"的分层设计。
工具使用的终极形态,不是让模型记住所有工具,而是让它学会"按需取用、智能编排"。





评论前必须登录!
注册