 网硕互联帮助中心
网硕互联帮助中心面向想转行 AI 的软件工程师:这一期我们聚焦「检索增强生成」(RAG,Retrieval-Augmented Generation),为什么它比微调更适合知识问答场景,RAG 的完整技术链路长什么样,以及如何用一份自己的文档在本地快速搭一个可用、可解释、可扩展的企业知识助手。
一、为啥几乎所有「企业知识问答」现在都在用 RAG?
回想这两类典型需求:
很多团队上来就说:「要不要微调一个大模型?」
但真实落地时,你会发现:
- 文档经常变:制度更新、版本变更、接口调整
- 内容较长:手册动辄几十页 PDF
- 对可控性和可解释性要求高:要能追溯「回答来自哪条文档」
这正是 RAG 擅长的场景,一句话概括:
RAG:不改模型参数,而是给模型接一个「外部知识库」,让它先查再答。
从工程视角看,相比微调:
-
成本更低
不用大规模训练,只需做向量化和检索
-
更新更快
文档一改、向量库重建 / 增量更新,当天就生效
-
更安全
理论上知识不「烤进」模型参数,更方便做权限与脱敏
-
更可解释
可以把引用的片段一起返回,方便人工审查
接下来我们按「一个完整项目」的路径来拆解 RAG。
二、RAG 的五个关键环节:从文档到答案的数据流
先用一张「数据流图」帮你建立整体心智模型:
原始文档
↓ 文档加载(Load)
纯文本
↓ 文本切分(Chunking)
较短片段
↓ 向量化(Embedding)
向量 + 元数据
↓ 向量库(Vector Store)
检索到的相关片段
↓ 提示工程 + LLM 生成
最终回答
1. 文档加载(Load)
-
目标:
从各种格式(PDF、Word、Markdown、网页)读出纯文本 + 元数据
-
元数据包括:
- 来源文件名
- 页码 / 章节
- 创建时间、版本号等
2. 文本切分(Chunking)
- 为什么要切?
- 文档太长,整篇放进 context 会超 token 限制
- 检索时需要更细粒度匹配
- 常见策略:
- 按字符数:比如每 300–800 字一片
- 带重叠:每片之间重叠 50–200 字,避免「一句话被劈开」
- 按结构:标题、段落、代码块为单位
3. 向量化(Embedding)
- 把每个文本片段编码成一个向量(高维浮点数组)
- 距离 / 夹角越小,语义越相近
- 本质:用一个预训练的 encoder 模型(Embedding 模型)
4. 向量库(Vector Store)
- 把「向量 + 原始文本 + 元数据」存进去
- 支持相似度检索:
- 输入一个问题 → 编码成向量 → 查最近的 K 个片段
- 常见实现:
- FAISS(轻量、单机)
- Chroma(开源、带简单服务)
- Milvus / Pinecone(企业级)
5. 检索 + 生成(Retrieve & Generate)
- 给定用户问题:
三、RAG vs 微调:到底什么时候选哪个?
你可以用下面这张简单对比来辅助决策:
| 需要统一口吻 / 品牌风格 | ✅ | ❌ |
| 需要学习新业务规则 / 输出格式 | ✅ | ✅(Prompt + 模板) |
| 知识量大且经常变 | ❌ | ✅ |
| 对「可解释性」要求高(要能看到引用文档) | 一般 | ✅ |
| 数据极难脱敏(不能进入训练集) | 风险较高 | 相对安全 |
| GPU 资源有限 | 吃力 | 友好 |
大部分「企业知识问答 / 文档助手 / 政策解读」项目,第一步应该是:
先用 RAG 做起来,效果确实不够、再考虑配合微调。
四、技术选型建议:Embedding、向量库、LLM 怎么选?
1. Embedding 模型
- 本地开源(推荐开发环境使用):
-
sentence-transformers/all-MiniLM-L6-v2
体积小、效果不错、非常适合作为默认 Embedding 模型
- 云 API:
- OpenAI:text-embedding-3-small / text-embedding-3-large
- 国产:通义、智谱、百川等也有各自的 embedding API
建议:
- 开发 / POC 阶段:优先用本地 MiniLM(不用花钱,不受限)
- 正式环境:按成本 + 精度 + 合规,综合选择云端或自部署模型
2. 向量库
- 小团队 / 单机:
- FAISS:无服务依赖,嵌入代码里就行
- Chroma:简单易用,持久化方便
- 企业级:
- Milvus:国产成熟方案,支持分布式
- Pinecone:SaaS,简单但费用较高
3. LLM 模型
- PoC 阶段
- GPT‑4o / GPT‑4o-mini:效果好,集成简单
- 内部应用
- 通义 Qwen、智谱 GLM、百川 Baichuan 等国产模型
- 或开源 LLaMA / Qwen 开源版本地部署
你可以把「Embedding + Vector Store」这层设计成可插拔,后面换模型时代价就很低。
五、从 0 到 1:用 LangChain 搭一个企业文档助手
下面这套代码,你可以稍做调整,就能变成你们公司的「知识问答机器人」。
1. 项目目录建议
rag_demo/
├── docs/ # 放企业文档(pdf/docx/md/txt)
│ ├── policy.md
│ ├── tech_manual.pdf
│ └── code_guidelines.docx
├── .env # API 密钥配置
├── rag_demo.py # 主程序(本期给出的示例)
└── requirements.txt
requirements.txt 大致包含:
langchain
langchain-community
langchain-openai
sentence-transformers
faiss-cpu
python-dotenv
tqdm
2. .env 示例(以 OpenAI 为例)
OPENAI_API_KEY=sk-xxxxxx
如果你用国产模型 / 自部署 API,只要在 LangChain 中切换对应的 LLM 类 & base_url/密钥即可。
3. 核心代码结构说明 (示例代码不在这里粘贴,感兴趣的话可以在公众号回复"ragdemo"获取)
代码主要划分为 5 块:
我在示例里已经用 LangChain 写了一版,你只需要:
- 把文档放到 docs/
- 填好 .env
- 运行 python rag_demo.py
就可以在终端看到:
- AI 回答
- 模型引用的文档片段和来源文件名(方便你验证)
六、如何把这个 Demo 改成你自己的「企业知识助手」?
1. 改 Prompt:让它说出你想要的风格
在 build_rag_chain 里有一段模板:
template = """你是一个企业技术文档助手,请根据以下上下文回答用户问题。
上下文可能包含多个相关片段,请综合所有信息给出准确、简洁的回答。
如果上下文不足以回答,请说'我不知道'。
问题: {question}
上下文: {context}
你的回答:"""
你可以改成更贴合你业务的风格,比如「严肃法律顾问」「互联网客服」「资深后端架构师」等,并加入一些规则:
- 不要编造政策
- 回答中必须附上出处章节
- 不懂就说不知道,而不是瞎编
2. 优化 Chunk 策略
不同类型文档,用不同切分方式会更好:
-
技术文档
按标题 / 小节分
-
代码规范
按「章节 + 小标题」切
-
接口文档
按「接口为单位」切(一个接口一个 chunk)
可以通过调整:
- chunk_size(每块长度)
- chunk_overlap(重叠部分长度)
- separators(切分优先级)
逐步找到适合你数据的组合。
3. 多轮对话与记忆
当前 Demo 是「单问单答」,你可以进一步:
- 把历史对话作为额外上下文传入
或 - 用 LangChain 的 Memory 组件维护简化的历史对话摘要
注意:当历史较长时,仍要控制 token 数,可以让 LLM 先为历史对话做总结,再带进 Prompt。
七、常见坑与优化建议
1. 「模型乱回答、不按文档来」怎么办?
- 在 Prompt 中反复强调:
- 必须严格依据上下文
- 不知道就说不知道
- 不要凭常识编造
- 同时:
- 尝试把 temperature 调低(如 0~0.3)
- 适当增加检索片段数 k(但不要太大,以免上下文太杂)
2. 「检索不准」怎么办?
可能原因:
- 太碎:单个 chunk 信息不完整
- 太整:很多不相关内容混在一起,影响匹配
优化方向:
- 调整 chunk_size(从 300–800 字试起)
- 使用专门的中文 Embedding 模型
- 尝试 MMR 检索,减少冗余
3. 文档频繁更新怎么办?
- 小规模:
- 定期重新向量化 & 构建向量库
- 中大型:
- 为每条文档保存唯一 ID
- 对变化的文档做增量更新(删除旧向量、插入新向量)
- 可以配合简单的「文档版本号」策略,避免错用旧内容
八、给你的行动建议
- 比如:入职手册、团队项目 Wiki、接口文档、技术规范
- 至少凑够 10–20 个文档文件,格式随意(PDF/Docx/MD/TXT)
- 先只用一个 LLM(GPT 或任意国产 API)
- 先跑通「能问能答」,再调 chunk / 检索参数
-
让对方用自然语言随便问,记录哪些问题答得不好
-
对每个「失败案例」判断是:
检索不到(说明索引 / 切分有问题),还是
检索到了但 LLM 没用好(说明 Prompt / LLM 能力不足)
普通人如何抓住AI大模型的风口?
领取方式在文末
为什么要学习大模型?
目前AI大模型的技术岗位与能力培养随着人工智能技术的迅速发展和应用 , 大模型作为其中的重要组成部分 , 正逐渐成为推动人工智能发展的重要引擎 。大模型以其强大的数据处理和模式识别能力, 广泛应用于自然语言处理 、计算机视觉 、 智能推荐等领域 ,为各行各业带来了革命性的改变和机遇 。
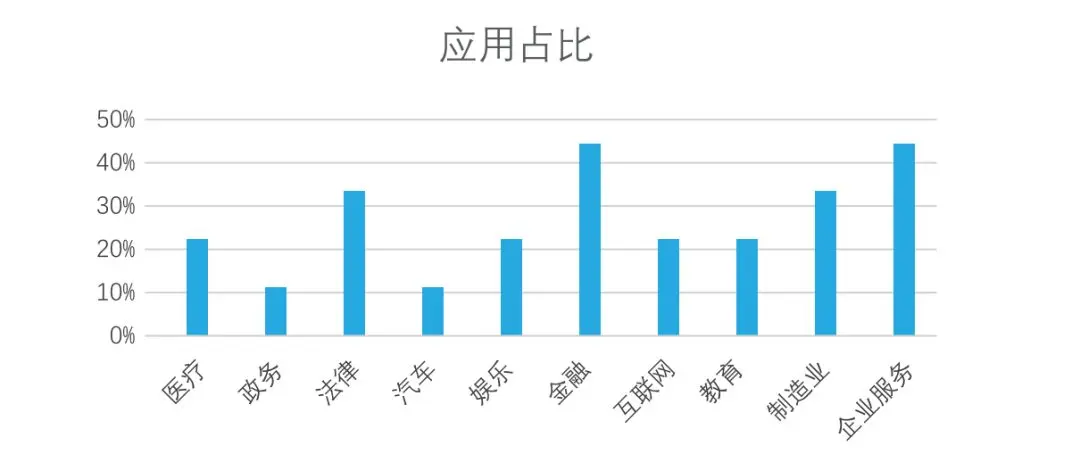
目前,开源人工智能大模型已应用于医疗、政务、法律、汽车、娱乐、金融、互联网、教育、制造业、企业服务等多个场景,其中,应用于金融、企业服务、制造业和法律领域的大模型在本次调研中占比超过 30%。
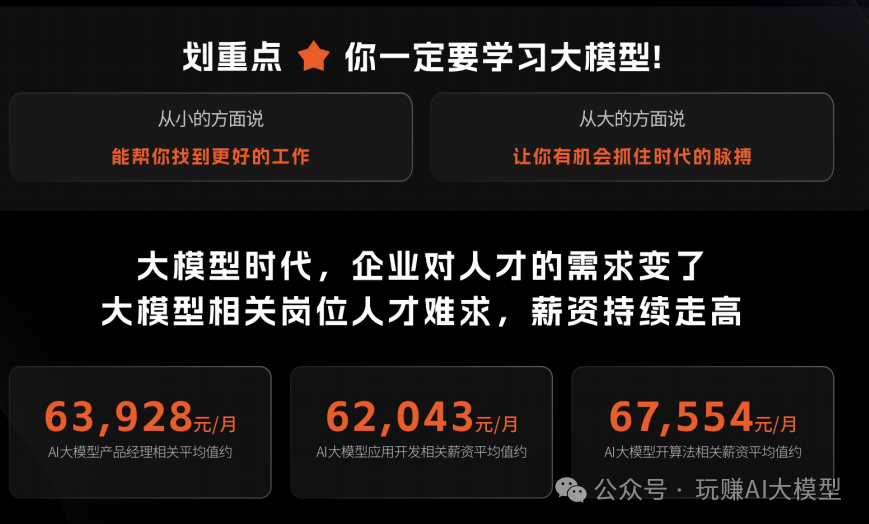
随着AI大模型技术的迅速发展,相关岗位的需求也日益增加。大模型产业链催生了一批高薪新职业:
人工智能大潮已来,不加入就可能被淘汰。如果你是技术人,尤其是互联网从业者,现在就开始学习AI大模型技术,真的是给你的人生一个重要建议!
最后
只要你真心想学习AI大模型技术,这份精心整理的学习资料我愿意无偿分享给你,但是想学技术去乱搞的人别来找我!
在当前这个人工智能高速发展的时代,AI大模型正在深刻改变各行各业。我国对高水平AI人才的需求也日益增长,真正懂技术、能落地的人才依旧紧缺。我也希望通过这份资料,能够帮助更多有志于AI领域的朋友入门并深入学习。
真诚无偿分享!!!
vx扫描下方二维码即可
加上后会一个个给大家发
【附赠一节免费的直播讲座,技术大佬带你学习大模型的相关知识、学习思路、就业前景以及怎么结合当前的工作发展方向等,欢迎大家~】

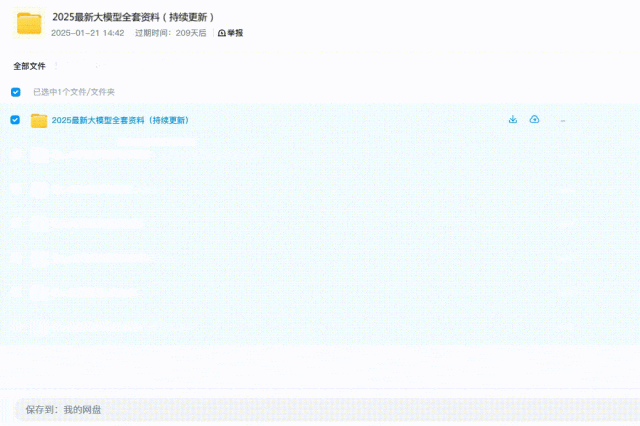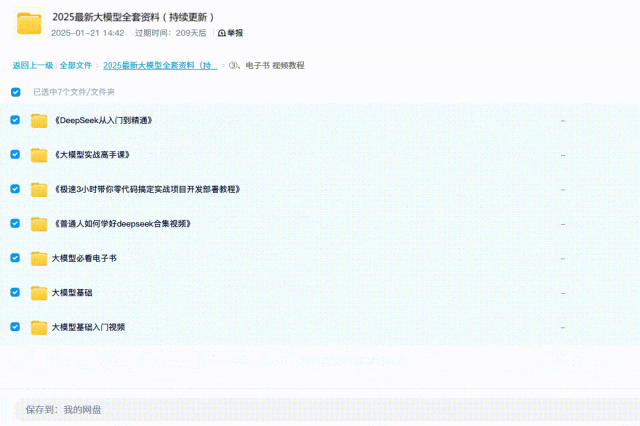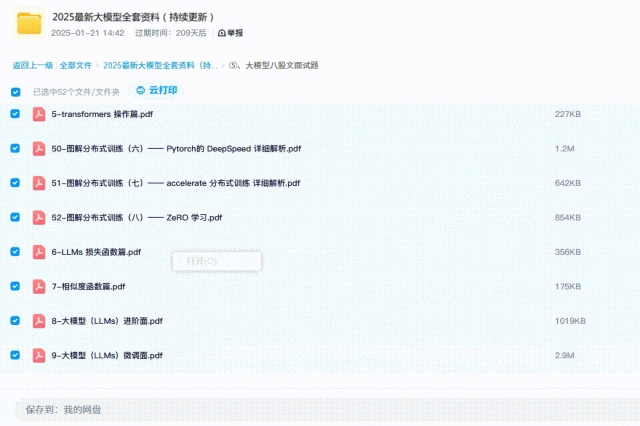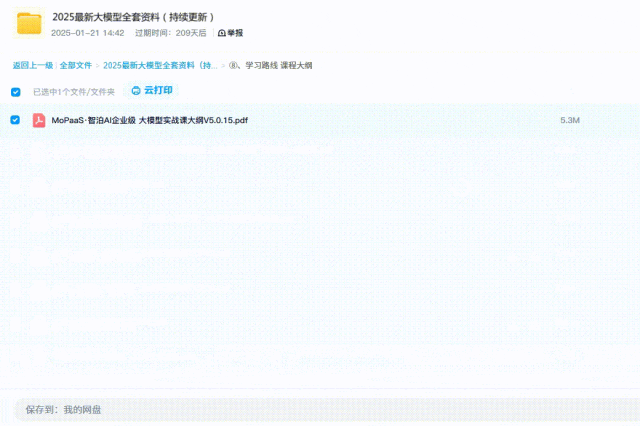
大模型全套学习资料展示
自我们与MoPaaS魔泊云合作以来,我们不断打磨课程体系与技术内容,在细节上精益求精,同时在技术层面也新增了许多前沿且实用的内容,力求为大家带来更系统、更实战、更落地的大模型学习体验。
希望这份系统、实用的大模型学习路径,能够帮助你从零入门,进阶到实战,真正掌握AI时代的核心技能!
01 教学内容
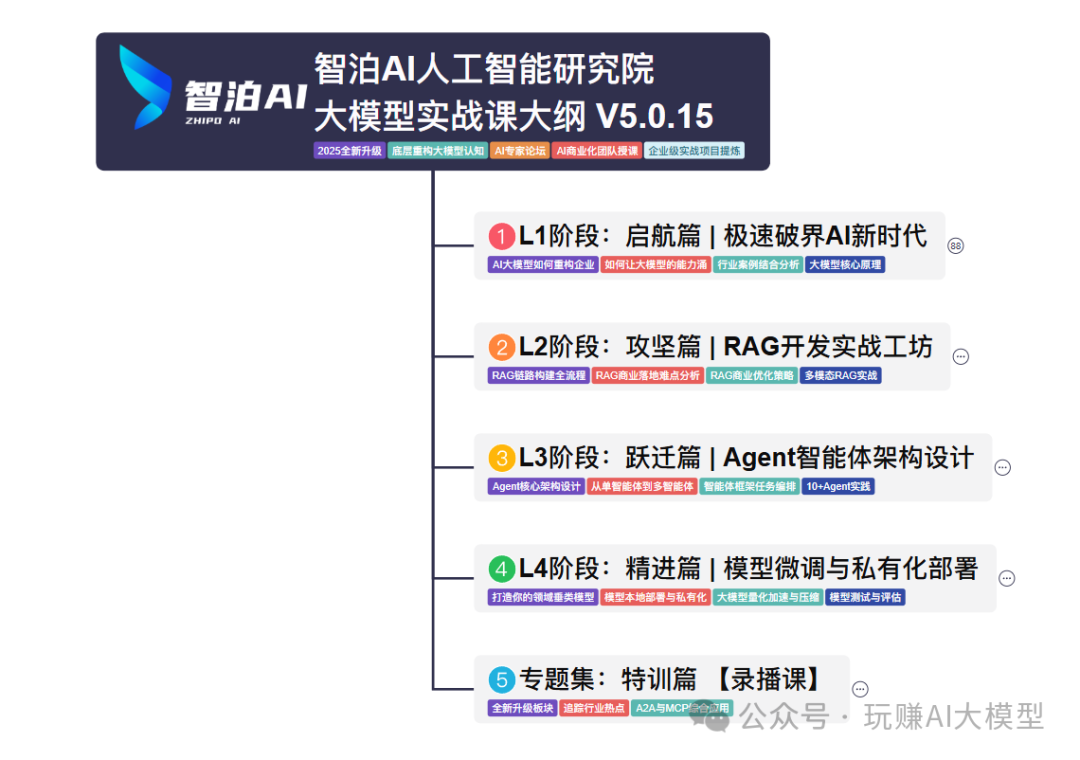
-
从零到精通完整闭环:【基础理论 →RAG开发 → Agent设计 → 模型微调与私有化部署调→热门技术】5大模块,内容比传统教材更贴近企业实战!
-
大量真实项目案例: 带你亲自上手搞数据清洗、模型调优这些硬核操作,把课本知识变成真本事!
02适学人群
应届毕业生: 无工作经验但想要系统学习AI大模型技术,期待通过实战项目掌握核心技术。
零基础转型: 非技术背景但关注AI应用场景,计划通过低代码工具实现“AI+行业”跨界。
业务赋能突破瓶颈: 传统开发者(Java/前端等)学习Transformer架构与LangChain框架,向AI全栈工程师转型。

vx扫描下方二维码即可
【附赠一节免费的直播讲座,技术大佬带你学习大模型的相关知识、学习思路、就业前景以及怎么结合当前的工作发展方向等,欢迎大家~】

本教程比较珍贵,仅限大家自行学习,不要传播!更严禁商用!
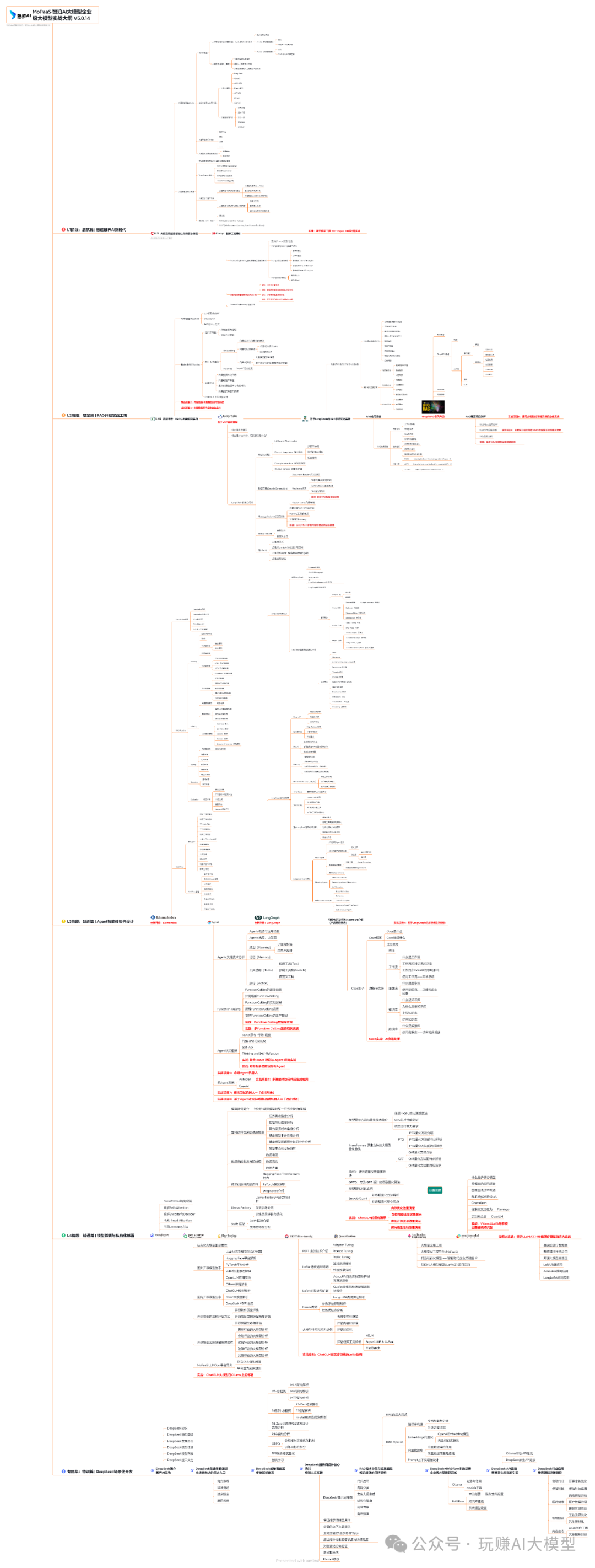
03 入门到进阶学习路线图
大模型学习路线图,整体分为5个大的阶段:
04 视频和书籍PDF合集

从0到掌握主流大模型技术视频教程(涵盖模型训练、微调、RAG、LangChain、Agent开发等实战方向)
新手必备的大模型学习PDF书单来了!全是硬核知识,帮你少走弯路(不吹牛,真有用)
05 行业报告+白皮书合集
收集70+报告与白皮书,了解行业最新动态!
06 90+份面试题/经验
AI大模型岗位面试经验总结(谁学技术不是为了赚$呢,找个好的岗位很重要)

07 deepseek部署包+技巧大全

由于篇幅有限
只展示部分资料
并且还在持续更新中…
真诚无偿分享!!!
vx扫描下方二维码即可
加上后会一个个给大家发
【附赠一节免费的直播讲座,技术大佬带你学习大模型的相关知识、学习思路、就业前景以及怎么结合当前的工作发展方向等,欢迎大家~】









评论前必须登录!
注册