 网硕互联帮助中心
网硕互联帮助中心一、前言
在求职或行业调研过程中,我们常常需要批量获取招聘平台的岗位信息,手动复制粘贴效率极低。本文将通过 DrissionPage 框架实现BOSS 直聘大数据开发岗位的批量爬取,无需分析复杂的页面元素,直接监听接口数据包获取 JSON 数据,最终将结果存入 CSV 文件,全程代码简洁易懂,新手也能快速上手。
本次实战目标
二、环境准备
1. 所需 Python 库
本次实战核心使用 DrissionPage 框架(集 Selenium 和 Requests 优势于一体,支持接口监听、页面操作),另外使用 Python 内置的 csv 模块处理文件,pprint 用于格式化输出。
安装核心库
打开终端 / 命令提示符,执行以下安装命令:
pip install DrissionPage
2. 环境说明
- Python 版本:3.9 及以上(推荐 3.9~3.11)
- 操作系统:Windows/macOS/Linux 均兼容
- 无需额外配置浏览器:DrissionPage 会自动适配本地 Chrome 浏览器,若未安装 Chrome,框架会提示自动下载
三、完整实战代码
直接复制以下代码,运行即可实现爬取(无需修改核心内容,可根据需求调整岗位关键词和爬取页数)。
# 导入自动化模块(核心:页面操作+接口监听)
from DrissionPage import ChromiumPage
# 格式化输出(方便调试,查看数据结构)
from pprint import pprint
# 导入csv模块(处理CSV文件写入)
import csv
def crawl_boss_zhipin():
# 1. 初始化CSV文件,配置表头和写入对象
with open('boss.csv', mode='w', encoding='utf-8', newline='') as f:
# 定义CSV文件表头字段
csv_fieldnames = [
'岗位名称',
'公司',
'规模',
'公司领域',
'学历要求',
'经验要求',
'技能需求',
'福利待遇',
'薪资',
'市',
'区',
'商圈',
'经度',
'纬度'
]
# 初始化DictWriter对象(用于字典格式数据写入)
csv_writer = csv.DictWriter(f, fieldnames=csv_fieldnames)
# 写入CSV表头
csv_writer.writeheader()
# 2. 初始化浏览器对象,开启接口监听
dp = ChromiumPage()
# 监听接口关键词:joblist(匹配BOSS直聘岗位列表接口)
dp.listen.start('joblist')
# 访问BOSS直聘大数据开发岗位页面(city=101280600 对应深圳,可修改城市编码)
target_url = 'https://www.zhipin.com/web/geek/jobs?query=%E5%A4%A7%E6%95%B0%E6%8D%AE%E5%BC%80%E5%8F%91&city=101280600'
dp.get(target_url)
# 3. 循环翻页,爬取前20页数据
total_pages = 20
for page in range(1, total_pages + 1):
print(f'========== 正在采集第{page}页数据内容 ==========')
try:
# 等待接口数据包返回(超时时间默认30秒,可调整)
resp = dp.listen.wait()
# 获取接口返回的JSON数据
json_data = resp.response.body
# 4. 提取岗位列表数据,解析并写入CSV
# 从JSON数据中提取岗位列表(核心数据节点)
job_list = json_data['zpData']['jobList']
for job in job_list:
# 构造单条岗位数据字典
job_info = {
'岗位名称': job.get('jobName', ''), # 使用get方法避免键不存在报错
'公司': job.get('brandName', ''),
'规模': job.get('brandScaleName', ''),
'公司领域': job.get('brandIndustry', ''),
'学历要求': job.get('jobDegree', ''),
'经验要求': job.get('jobExperience', ''),
'技能需求': job.get('skills', []),
'福利待遇': job.get('welfareList', []),
'薪资': job.get('salaryDesc', ''),
'市': job.get('cityName', ''),
'区': job.get('areaDistrict', ''),
'商圈': job.get('businessDistrict', ''),
'经度': job.get('gps', {}).get('longitude', ''), # 嵌套字典安全取值
'纬度': job.get('gps', {}).get('latitude', '')
}
# 写入单条岗位数据到CSV
csv_writer.writerow(job_info)
# 格式化输出当前爬取的岗位信息(方便查看进度)
pprint(job_info)
# 5. 页面下滑到底部,触发下一页数据加载(核心翻页逻辑)
dp.scroll.to_bottom()
except Exception as e:
print(f'第{page}页数据采集失败,错误信息:{str(e)}')
continue
# 6. 爬取完成,关闭浏览器
dp.quit()
print(f'========== 全部{total_pages}页数据采集完成,结果已存入boss.csv ==========')
if __name__ == '__main__':
crawl_boss_zhipin()
四、核心代码解析
1. CSV 文件初始化
- 使用 open() 函数创建 CSV 文件,指定 mode='w'(写入模式)、encoding='utf-8'(防止中文乱码)、newline=''(避免 CSV 文件出现空行)
- csv.DictWriter() 支持直接写入字典格式数据,fieldnames 定义 CSV 表头,与后续提取的字段一一对应
- writeheader() 写入表头,为后续数据写入做准备
2. 浏览器初始化与接口监听
- ChromiumPage() 实例化浏览器对象,自动启动本地 Chrome 浏览器
- dp.listen.start('joblist'):开启接口监听,关键词 joblist 用于匹配 BOSS 直聘的岗位列表接口,无需手动分析完整接口 URL,简化开发
- dp.get() 访问目标岗位页面,自动加载页面并触发接口请求
3. 循环翻页与数据提取
- 循环 range(1, 21) 实现前 20 页数据爬取,可修改 total_pages 调整爬取页数
- dp.listen.wait():等待接口数据包返回,直到获取到匹配 joblist 的接口响应,超时默认 30 秒
- json_data = resp.response.body:直接获取接口返回的 JSON 数据,无需手动解析 JSON 字符串,DrissionPage 已自动处理
- 从 json_data['zpData']['jobList'] 提取岗位列表,这是接口返回数据的核心节点,可通过浏览器 F12 开发者工具分析确认
4. 数据安全提取与写入
- 使用 job.get(key, 默认值) 替代 job[key]:避免因接口返回数据缺失某个字段导致程序报错终止,提高代码健壮性
- 嵌套字典(如 gps)使用 job.get('gps', {}).get('longitude', '') 实现安全取值,即使 gps 字段不存在也不会报错
- csv_writer.writerow(job_info):将单条岗位字典数据写入 CSV 文件,自动对应表头字段
5. 翻页逻辑与资源释放
- dp.scroll.to_bottom():将页面下滑到底部,触发 BOSS 直聘的懒加载机制,加载下一页岗位数据(这是本次实战的核心翻页技巧,无需点击分页按钮)
- dp.quit():爬取完成后关闭浏览器,释放系统资源
五、运行结果展示
1. 终端运行日志
运行代码后,终端会输出每一页的爬取进度,以及单条岗位的格式化信息,如下所示:
========== 正在采集第1页数据内容 ==========
{'公司': '某科技有限公司',
'公司领域': '大数据/人工智能',
'商圈': '科技园',
'学历要求': '本科',
'经度': '113.94xxx',
'纬度': '22.54xxx',
'经验要求': '3-5年',
'福利待遇': ['五险一金', '年终奖金', '定期体检'],
'技能需求': ['Hadoop', 'Spark', 'Hive'],
'薪资': '25-35K·13薪',
'市': '深圳市',
'区': '南山区',
'规模': '500-999人',
'岗位名称': '大数据开发工程师'}
2. CSV 文件结果
爬取完成后,在代码同级目录下会生成 boss.csv 文件,可用 Excel、WPS 或记事本打开,数据格式规整,无中文乱码,如下所示(部分截图):
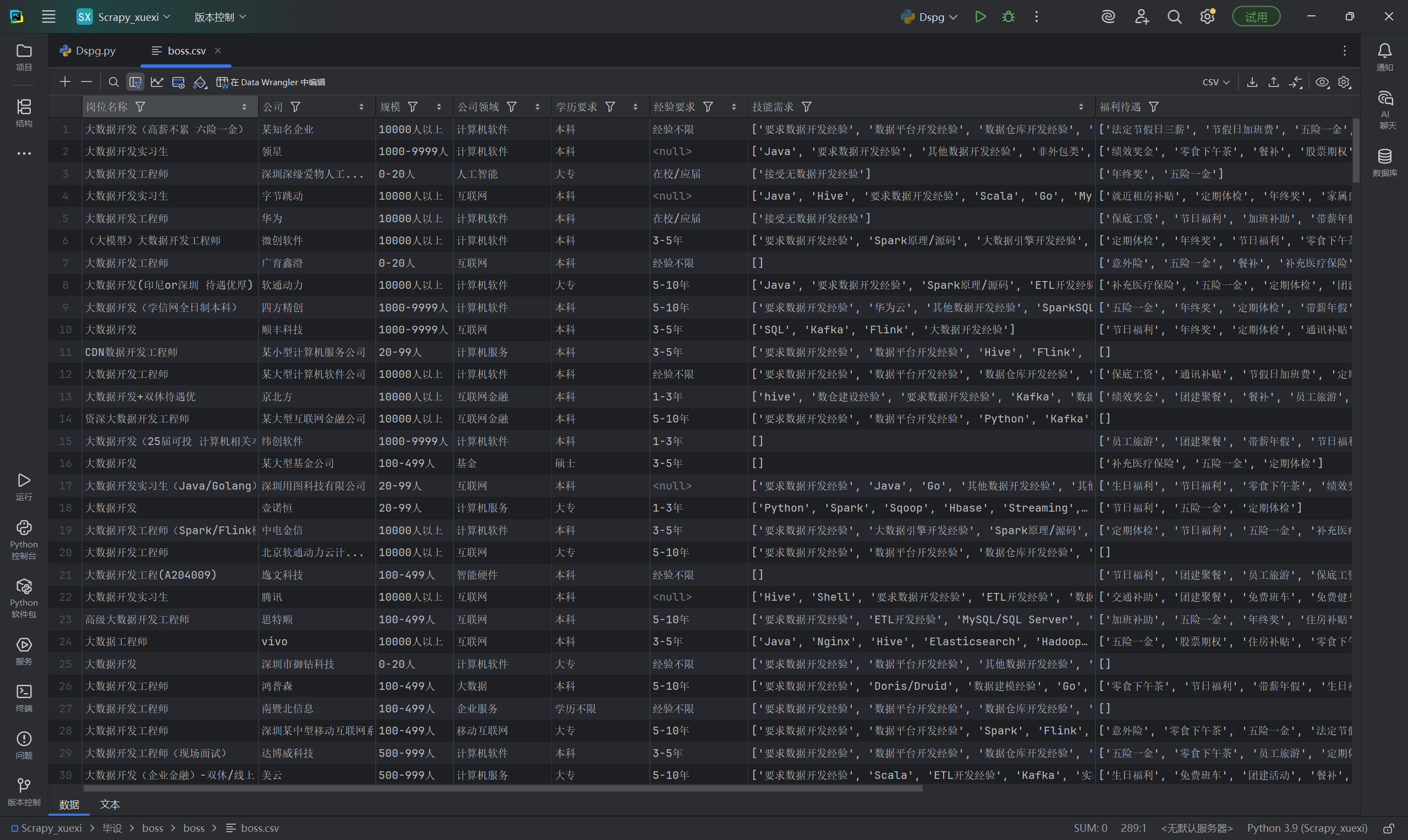
六、注意事项与优化建议
1. 注意事项
- 反爬机制:BOSS 直聘有反爬限制,请勿频繁运行代码,建议爬取间隔适当延长(可添加 time.sleep(2) 避免被封禁 IP)
- 城市编码修改:目标 URL 中的 city=101280600 对应深圳,如需爬取其他城市,可在 BOSS 直聘官网切换城市后,复制 URL 中的城市编码替换
- 中文乱码问题:CSV 文件打开若出现乱码,可选择用 Excel 打开,选择「数据」→「自文本 / CSV」,编码选择「UTF-8」
- 接口关键词验证:若无法获取数据,可打开浏览器 F12→「网络」→「XHR」,查看岗位列表接口的 URL 中是否包含 joblist,若不包含,需修改监听关键词
2. 优化建议
- 添加延时控制:在翻页逻辑中添加 time.sleep(3),避免请求过快触发反爬,代码如下:
import time
# 下滑后添加延时
dp.scroll.to_bottom()
time.sleep(3)
- 异常数据过滤:可添加判断条件,过滤掉薪资为空、学历要求为空的无效岗位数据
- 多线程爬取:对于大批量数据爬取,可结合 threading 实现多线程爬取,提高效率
- 数据去重:爬取完成后,可对 CSV 文件进行去重处理,避免重复岗位数据
七、总结
本次实战通过 DrissionPage 框架实现了 BOSS 直聘岗位数据的批量爬取,核心亮点是接口监听,无需分析复杂的页面 DOM 结构,直接获取结构化 JSON 数据,相比传统的页面元素解析,效率更高、稳定性更强。
通过本文的学习,你不仅掌握了招聘平台数据爬取的方法,还能举一反三,将该思路应用到其他支持懒加载的网站数据爬取中。同时,csv 模块的使用也为后续数据分析打下了基础,爬取的 boss.csv 文件可进一步用 pandas 进行数据清洗、可视化分析。
如果运行过程中遇到问题,欢迎在评论区留言讨论,喜欢本文的话,记得点赞 + 收藏哦!






评论前必须登录!
注册