 网硕互联帮助中心
网硕互联帮助中心protobuf介绍
根据google官方的介绍:
Protocol Buffers是Google的一种语言无关,平台无关,可扩展的序列化数据结构的方法,它可用于数据通信协议,数据存储等.
Protocol Buffer类比XML/JSON,是一种灵活,高效,自动化机制的结构数据序列方法,但是比XML/JSON更小,更快,更简单.
你可以定义数据结构,然后使用特殊生成的源代码轻松的在各种数据流中使用各种语言编写和读取数据结构.你甚至可以更新数据结构,而不破坏旧数据结构编译的以部署程序.
概念补充
序列化概念:
常见的实现序话的方式有:XML,JSON,protobuf
序列化是指: 把对象转化为字节序列的过程,称为对象的序列化.
反序列化是指: 把字节序列恢复为对象的过程称为对象的反序列化
在什么情况下需要序列化
存储数据: 需要把内存中的数据存储到文件或者数据库中时.
网络传输: 网络直接传输数据,但是无法传输对象,所以要在传输前进行序列化完成传输后再进行反序列化.
Protobuf使用流程
编写".ptoto"文件,确定结构对象以及属性内容.
使用protoc编译器编译".proto"文件,编译过后会自动生成接口代码
依赖生成的接口,将编译生成的头文件包含进我们的代码中,实现对".proto"文件中定义的字段进行设置和获取,和对"message"对象进行序列化和反序列化.
使用流程小结:
protobuf是需要依赖编译生成的头文件和源文件使用的.有了这种代码生成机制,程序🐒就不需要在吃力的编写序列化和反序列化的代码了.
暂时无法在飞书文档外展示此内容
快速上手Protobuf
通过上面的使用流程来快速上手Protobuf,下面我会通过一个最简单的个人信息对象来演示protobuf的使用.
编写.proto文件,确定对象结构
//文件名为contacts.proto
syntax = "proto3";
package contacts;
message PeopleInfo {
string name = 1;
int32 age = 2;
}
解析:
-
syntax = "proto3";
-
表示使用的语法版本为"proto3",这是protobuf的最新语法版本,更易于使用,同时支持的语言也更多了.
-
-
package contacts;
-
package 是一个可选的声明符,表示".proto"文件的命名空间.可以类比与C++的namespace
-
-
message PeopleInfo
-
定义的结构化对象
-
命名规范为大驼峰命名法
-
-
string name = 1
-
定义消息字段,格式为:字段类型 字段名 = 字段唯一编号.
-
命名规范:全小写字母,多个字母之间用 _ 连接
-
字段类型分为:标量数据类型 和 特殊类型(包括枚举、其他消息类型等)。
-
字段唯一编号:用来标识字段,一旦开始使用就不能够再改变
-
protobuf支持的标量数据类型与其对应的C++类型见附录
使用protoc编译器编译".proto"文件,编译过后会自动生成接口代码
在终端输入:
protoc –cpp_out=. contacts.proto
解析:
-
–cpp_out=.
-
"–cpp_out"表示编译后的文件为C++文件,"=."表示生成的文件存储在当前目录下
-
-
contacts.proto
-
要被编译的".proto"文件
-
执行指令后对于目录下面会生成对应的声明文件和实现文件:
root@instance-5a74bdri:~/protobuf/fast_start# ls
contacts.pb.cc contacts.pb.h contacts.proto main.cc
对于编译生成的C++代码,包含了以下内容:
-
对于每个message,都会生成一个对应的消息类.
-
在消息类中,编译器为每个字段提供了获取和设置方法,以及一下其他能够操作字段的方法。
-
编译器会针对每个".proto"文件生成".h"和".cc"文件,分别存储类的声明和类的实现.
"contacts.pb.h"文件(局部)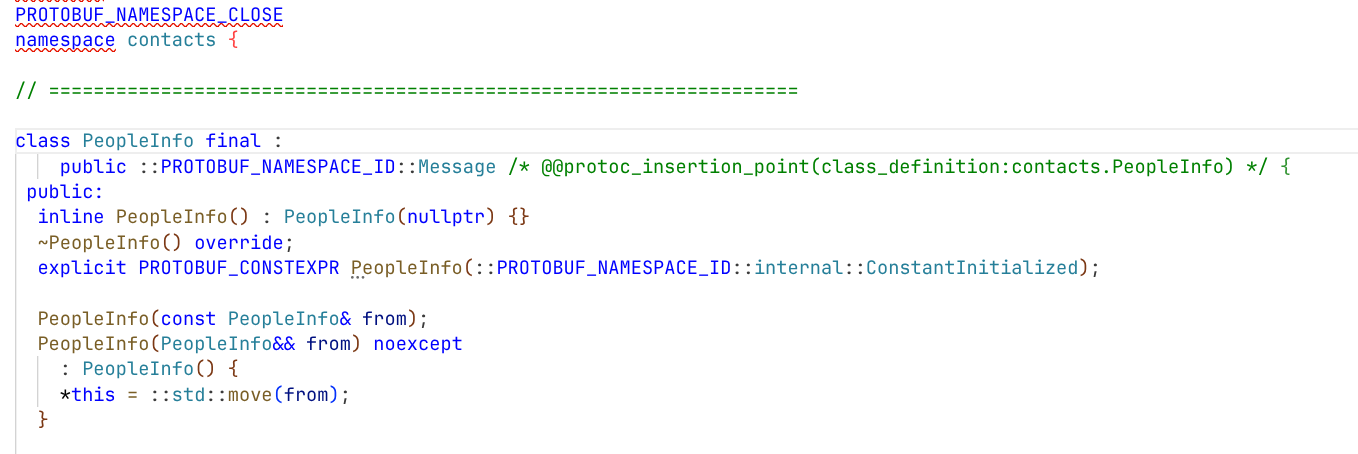
可以看到proto编译器为我们生成的命名空间"contacts"和类"PeopleInfo"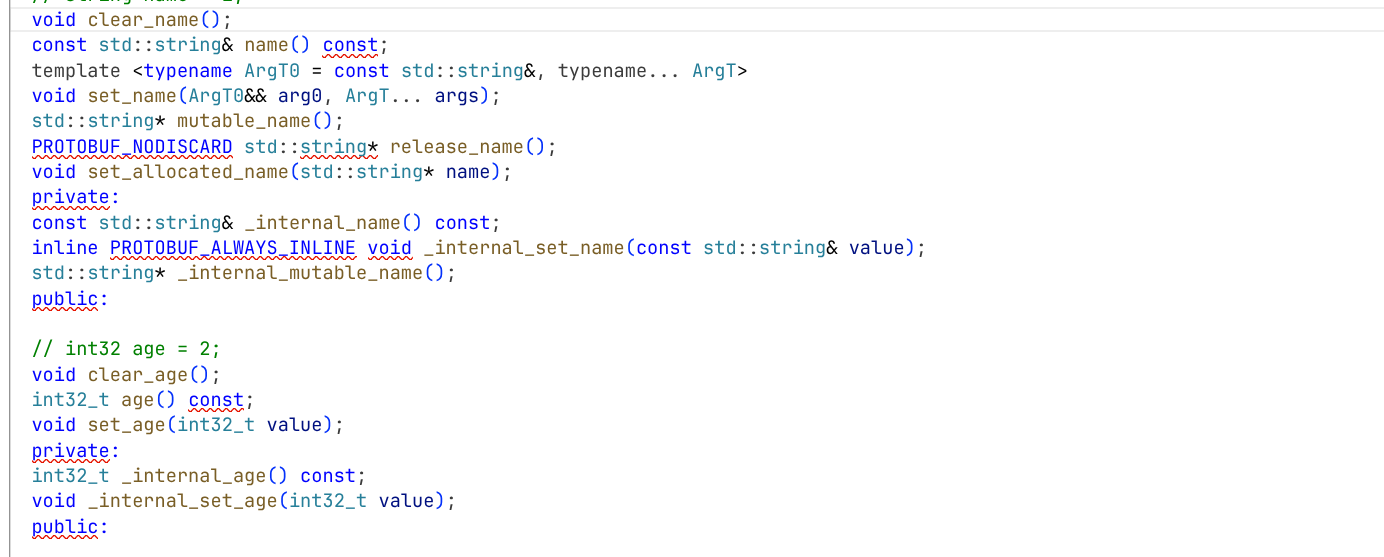
-
每个字段都有设置和获取的方法,getter和名称与小写字段完全相同,setter方法以set_开头
-
每个字段都有clear_方法,可以将字段重新设置回empty状态
仔细观察"contacts.pb.h"文件,并没有发现有关序列化和反序列化的函数,这是因为它们在消息类的父类"MessageLite"中.
class MessageLite{
public:
//序列化
bool SerializeToOstream(ostream* output) const; //将序列化后的数据写入文件
bool SerializeToArray(void *data, int size) const;//序列化后的数据写入指定的内存数组,size表示最大可用字节数。
bool SerializeToString(string* output) const;//将序列化后的数据写入字符串
//反序列化
bool ParseFromIstream(istream* input);//从流中读取数据,再进行反序列化
bool ParseFromArray(const void* data, int size);
bool ParseFromString(const string& data);//从字符串中读取数据,再进行反序列化
}
依赖生成的接口,将编译生成的头文件包含进我们的代码中,实现对".proto"文件中定义的字段进行设置和获取,和对"message"对象进行序列化和反序列化.
//文件名: main.cc
#include <iostream>
#include "contacts.pb.h"
int main()
{
std::string data;
{
contacts::PeopleInfo peopleInfo;
peopleInfo.set_name("yui");
peopleInfo.set_age(17);
peopleInfo.SerializeToString(&data);
}
{
contacts::PeopleInfo peopleInfo;
peopleInfo.ParseFromString(data);
std::cout<<peopleInfo.name()<<std::endl;
std::cout<<peopleInfo.age()<<std::endl;
}
return 0;
}
编写makefile
main:main.cc g++ -o $@ $^ contacts.pb.cc -std=c++11 -lprotobuf
运行结果:
root@instance-5a74bdri:~/protobuf/fast_start# make
g++ -o main main.cc contacts.pb.cc -std=c++11 -lprotobuf
root@instance-5a74bdri:~/protobuf/fast_start# ./main
yui
17
附录
标量数据类型
|
.proto Type |
Notes |
C++ Type |
|
double |
double |
|
|
float |
float |
|
|
int32 |
使用变长编码。负数的编码效率较低——若字段可能为负值,应使用 sint32 代替。 |
int32 |
|
int64 |
使用变长编码。负数的编码效率较低——若字段可能为负值,应使用 sint64 代替。 |
int64 |
|
uint32 |
使用变长编码。 |
uint32 |
|
uint64 |
使用变长编码。 |
uint64 |
|
sint32 |
使用变长编码。符号整型。负值的编码效率高于常规的 int32 类型。 |
int32 |
|
sint64 |
使用变长编码。符号整型。负值的编码效率高于常规的 int64 类型。 |
int64 |
|
fixed32 |
定长 4 字节。若值常大于 2^28 则会比 uint32 更高效。 |
uint32 |
|
fixed64 |
定长 8 字节。若值常大于 2^56 则会比 uint64 更高效。 |
uint64 |
|
sfixed32 |
定长 4 字节。 |
int32 |
|
sfixed64 |
定长 8 字节。 |
int64 |
|
bool |
bool |
|
|
string |
包含 UTF-8 和 ASCII 编码的字符串,长度不能超过 2^32。 |
string |
|
bytes |
可包含任意的字节序列但长度不能超过 2^32。 |
string |



评论前必须登录!
注册