 网硕互联帮助中心
网硕互联帮助中心引言:NLP领域的范式转移
2017年,谷歌的研究团队在论文《Attention is All You Need》中提出了一种全新的神经网络架构——Transformer,这标志着自然语言处理领域的一次重大范式转移。在Transformer出现之前,循环神经网络(RNN)及其变体(如LSTM、GRU)长期统治着序列建模任务,但Transformer以其独特的架构设计和卓越的性能表现,迅速成为NLP领域的新标准。
本文将深入剖析Transformer的核心原理、架构细节、变体演进以及实际应用,为您呈现这一划时代技术的完整图景。
一、Transformer诞生的背景与动机
1.1 传统序列建模的瓶颈
在Transformer出现之前,处理序列数据的主流方法是RNN系列模型。虽然LSTM和GRU通过引入门控机制部分解决了长序列训练中的梯度消失问题,但本质上仍然存在以下限制:
-
顺序依赖性:RNN必须按时间步顺序处理序列,难以并行化
-
长距离依赖捕捉能力有限:尽管有门控机制,但信息在长序列中传递仍会衰减
-
计算效率低下:处理长序列时内存和计算需求呈线性或平方增长
1.2 注意力机制的兴起
注意力机制最早在神经机器翻译任务中被提出,其核心思想是让模型能够\”关注\”输入序列中与当前输出最相关的部分。最初的注意力机制作为RNN的补充组件出现,但研究者很快发现,注意力本身可能比循环结构更强大。
二、Transformer核心架构深度解析
2.1 整体架构概览
Transformer采用典型的编码器-解码器架构,但完全摒弃了循环结构,仅依赖注意力机制和前馈神经网络。
# Transformer架构的伪代码示意
class Transformer(nn.Module):
def __init__(self, encoder, decoder):
super().__init__()
self.encoder = encoder # 编码器堆叠
self.decoder = decoder # 解码器堆叠
def forward(self, src, tgt):
# 编码器处理源序列
memory = self.encoder(src)
# 解码器基于编码结果生成目标序列
output = self.decoder(tgt, memory)
return output
2.2 自注意力机制:Transformer的灵魂
2.2.1 缩放点积注意力
自注意力机制是Transformer最核心的创新,其数学形式如下:
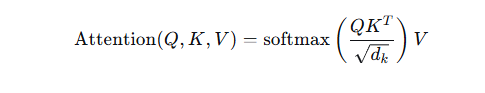
其中:
-
$Q$ (Query):查询矩阵,表示当前需要关注的焦点
-
$K$




评论前必须登录!
注册