 网硕互联帮助中心
网硕互联帮助中心26年1月来自中科院自动化所、中科院大学和美团的论文“MobileDreamer: Generative Sketch World Model for GUI Agent”。
移动GUI智体在现实世界的自动化和实际应用中展现出巨大的潜力。然而,大多数现有智体仍然是被动的,主要基于当前屏幕做出决策,这限制了它们在处理长期任务时的性能。通过重复交互构建世界模型能够预测动作结果,并支持移动GUI智体做出更优的决策。这极具挑战性,因为该模型必须具备空间-觉察能力来预测后动作的状态,同时还要保持足够的效率以满足实际部署的需求。
本文提出一种高效基于世界模型的预测框架MobileDreamer,该框架利用世界模型提供的未来想象来增强GUI智体能力。它由文本草图世界模型和GUI智体的展开想象组成。文本草图世界模型通过学习过程将数字图像转换为关键任务相关的草图,从而预测后动作的状态,并设计一种顺序不变学习策略来保留GUI元素的空间信息。GUI智体的展开想象策略,利用世界模型的预测能力来优化动作选择过程。在 Android World 上的实验表明,MobileDreamer 达到最先进的性能,并将任务成功率提高 5.25%。世界模型评估进一步验证文本草图建模能够准确预测关键的 GUI 元素。
MobileDreamer如图所示:
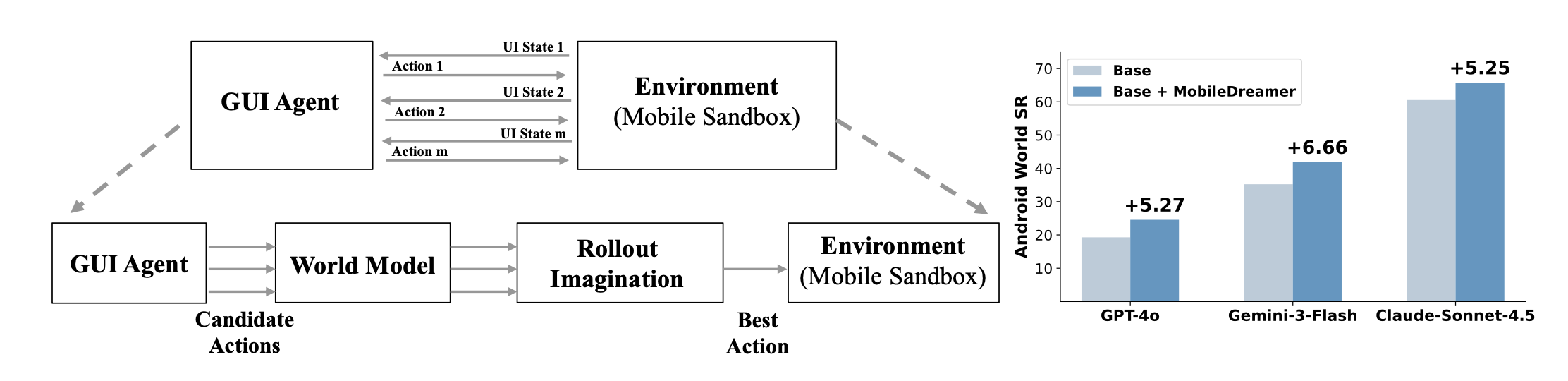
MobileDreamer 框架,该框架旨在赋予 GUI 智体在执行操作前预测长期结果的能力。如图所示,该框架包含两个阶段。第一阶段,构建一个文本草图世界模型 (TSWM),这是一个基于动作的世界模型,能够以轻量级、结构化的文本格式预测后动作的 GUI 状态。第二阶段,为 GUI 智体提出一种展开想象策略。该策略将 TSWM 封装成一个函数,使智体能够通过函数调用来预测操作结果。预测过程分多个步骤进行,构建一个涵盖候选操作的预测树,最终智体根据预期结果选择操作。
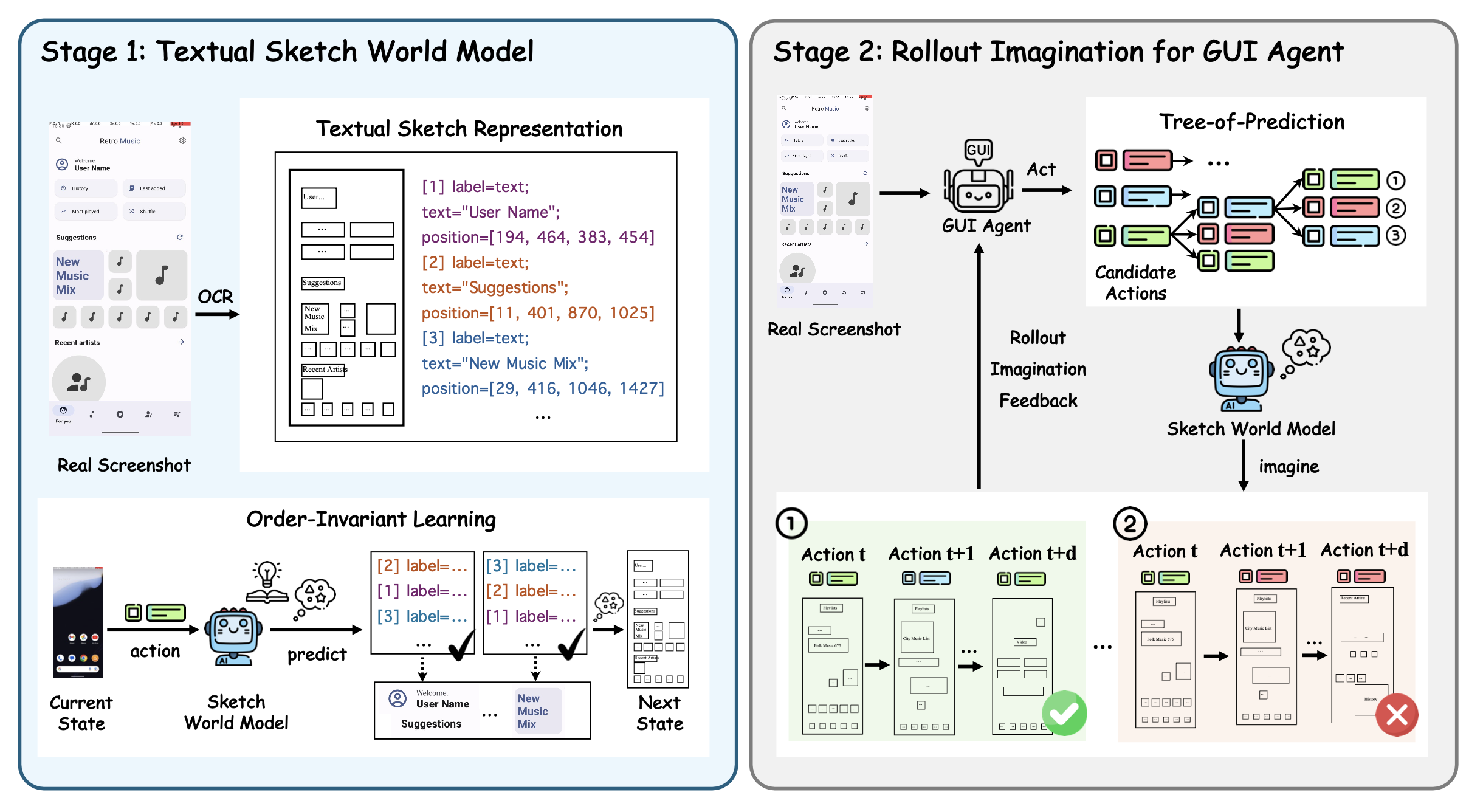
文本草图世界模型
虽然以往的研究尝试使用世界模型预测进行动作选择(Gu et al., 2024; Chae et al., 2024; Li et al., 2025; Luo et al., 2025),但依赖扩散模型重建 GUI 页面会增加大量计算成本,并引入与预测无关的细节,例如纹理和装饰。这些细节会分散智体的注意,并影响其决策。为了解决这个问题,提出一种文本草图世界模型(TSWM),该模型仅预测 GUI 智体规划所需的最小信息。
文本草图表示。首先使用 PaddleOCR-VL(Cui et al., 2025)从 GUI 页面中提取关键元素。提取完成后,每个图标都以结构化格式表示。为了在计算效率和布局描述清晰度之间取得平衡,保留三个关键属性:标签、图标内的文本以及在页面上的位置。因此,当前状态 s_t 表示为元素集 E (s_t ) = {e_n},其中每个元素 e_n = (l_n, τ_n, b_n) 包含标签 l_n、文本 τ_n 和位置(边框)b_n。
基于文本草图表示,GUI状态被编码为结构化文本。因此,一种直接的方法是采用监督式方法训练文本草图世界模型。具体来说,下一个状态s_t+1是通过对当前状态s_t执行动作a_t得到的,并且可以通过基于词元级交叉熵的监督式微调(SFT)来训练世界模型。
然而,由于世界模型和LLM的目标不匹配,单独使用SFT可能会导致性能欠佳。特别是,在以下两种情况下,预测结果可能足以满足世界模型的使用需求,但仍会造成较大的SFT损失:1)元素顺序改变,2)位置微移。
由于朴素的SFT算法不太适合世界模型预训练,引入元素级匹配损失。直观地说,将TSWM目标函数视为一个目标检测问题。对于每个预测的图标,用最优传输将其与真实图标进行匹配,然后对齐其属性。
设定的目标鼓励文本草图世界模型在动作条件转换下保持元素级结构,使其预测结果对元素重排以及文本或边框的微小扰动更具鲁棒性。由此产生的预测结果为比较候选动作提供更清晰的信号,并支持在展开想象中更可靠的前瞻规划。
面向 GUI 智体的展开想象
在获得强大的 TSWM 之后,提出一种利用其预测能力来改进动作选择过程的展开想象策略。
给定任务目标 g、当前状态 s_t 和步骤指令 u_t,GUI 智体提出一组 M 个候选动作 A_t = {a(1)_t,…,a(M)_t}。MobileDreamer 将这些候选动作视为备选分支,并通过前瞻过程进行评估。
对于每个候选动作 a(m)_t,世界模型预测下一个状态。这些预测构成一组与每个候选动作对应的未来状态,为 GUI 智体提供额外的上下文信息,以帮助其根据预期的未来状态选择最佳动作。
为了模拟长期影响,将单步预测扩展为深度为 d 的预测树,递归地基于预测状态提出后续候选动作,并预测它们的未来状态。在第一个预测步骤之后,MobileDreamer 将预测状态 Sˆ_t+1 和候选动作 A_t 反馈给 GUI 智体,智体使用预测轨迹来选择下一个预测动作 Aˆ_t+1。这里,A_t = {a(1)_t,…,a(M)_t} 包含 M 个候选动作,其中 M 作为一个剪枝参数,控制预测树的分支因子。此过程持续进行,直到树达到指定的深度 d。每条从根到叶的路径代表一条短的预测轨迹。这些轨迹被汇总成深度为 d 的预测树,其中包括每个步骤的候选动作及其预测的后续状态。
世界模型反馈至 GUI 智体。预测完成后,MobileDreamer 会将预测树反馈给 GUI 智体,作为操作选择的附加上下文。具体来说,GUI 智体会收到用于定位的真实当前状态截图,以及预测树的文本摘要,其中描述每个候选操作执行后的预测未来状态。然后,GUI 智体根据反馈选择最佳操作并在环境中执行。预测树允许 GUI 智体根据预期状态显式地比较备选操作。这对于需要长期规划的复杂 GUI 导航任务尤为重要。






评论前必须登录!
注册