 网硕互联帮助中心
网硕互联帮助中心你有没有遇到这样一刻:警报骤响,负载曲线飙升至令人惊恐的209。你远程登录,却发现系统响应如常,top显示CPU竟有88.7%在偷懒,磁盘更是清闲得发慌。
这诡异的场景,是监控误报,还是系统即将崩溃的宁静前夜?
在日常运维中,我们常常会依赖一些经典指标来判断服务器健康状况——比如 CPU 使用率、内存占用、磁盘 IO、网络流量,以及 CPU Load(负载)。但有时候,这些指标也会“骗人”。
今天要分享的,就是一个真实发生在线上环境的案例一台 8核服务器,load average 高达 209.41,但用户操作流畅如常。更诡异的是——top 显示 CPU 使用率只有 1.4%(us) + 7.1%(sy)= 8.5%,内存充足,磁盘 I/O 也无明显等待等异常。当时的top命令的现象如下:
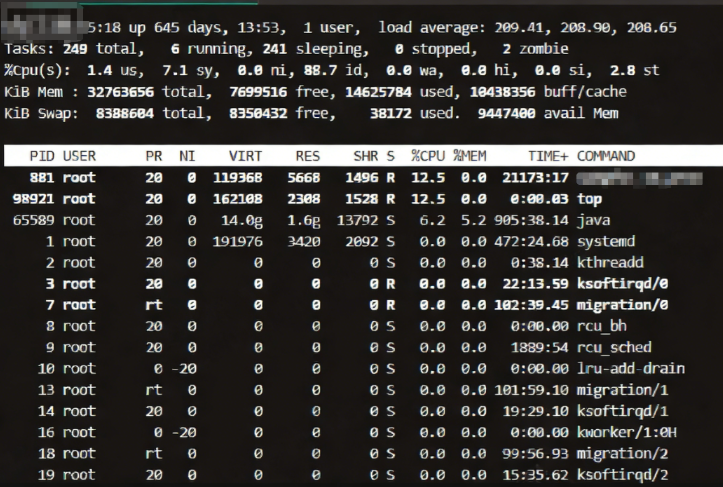
这到底是怎么回事?毫无卡顿。这究竟是怎么回事?让我们一起揭开这个“高负载”背后的真相。
1. 现象解读
1.1 每行指标解读
先让我们逐行解读,还原这场“高负载幻象”的真相。
-
第一行:系统状态
**15:18 up 645 days, 13:53, 1 user, load average: 209.41, 208.90, 208.65
系统运行了 645 天,稳定性极强;当前负载高达 209.41,远超 8 核理论值(理想情况下最大为 8);负载持续高位,说明不是瞬时波动。
⚠️ 重点来了:Load 并不等于 CPU 占用率!
Load 表示的是“正在运行或等待资源的进程数”,包括那些因 I/O 阻塞而进入 D 状态 的进程。
-
第二行:任务统计
Tasks: 249 total, 6 running, 241 sleeping, 0 stopped, 2 zombie
总共 249 个进程;其中 241个处于sleeping 状态,意味着它们在“等待”;只有 6 个在运行,说明 CPU 没有被压垮。这就解释了为什么CPU使用率低 —— 大多数进程都“睡着了”(sleeping 状态)。
-
第三行:CPU 使用情况
%Cpu(s): 1.4 us, 7.1 sy, 0.0 ni, 88.7 id, 0.0 wa, 0.0 hi, 0.0 si, 2.8 st
-
us = 1.4%:用户态 CPU 使用率很低;
-
sy = 7.1%:内核态也未过高;
-
id = 88.7%:空闲时间占比极高 → CPU 几乎没干活;
-
wa = 0.0%:等待 I/O 的 CPU 时间为 0 → 但这并不准确!
这里有个常见误解:wa 是指“CPU 在等待 I/O 完成的时间”,但它只反映 CPU 等待队列中的 I/O,而不包含那些“卡死在 D 状态”的进程。换句话说便是虽然wa是0,但大量进程其实正在等I/O,只是它们已经“不可中断”了,不会计入 wa。
-
第四行:内存使用
KiB Mem : 32763656 total, 7699516 free, 14625784 used, 10438356 buff/cache
内存总容量约 32GB;可用内存 >7GB,缓冲/缓存占用合理;没有内存不足导致的 swap 或 OOM,也就是说内存完全没问题。
-
第五行:Swap
KiB Swap: 8388604 total, 8350432 free, 38172 used. 9447400 avail Mem
Swap 使用量极少(仅 38MB),且可用内存充足;不会因内存压力导致性能下降。
-
进程列表:谁在“拖后腿”?
PID USER PR NI VIRT RES SHR S %CPU %MEM TIME+ COMMAND881 root 20 0 119368 5668 1496 R 12.5 0.0 21:17:17 java98921 root 20 0 162108 2308 1528 R 12.5 0.0 0:00.03 top65589 root 20 0 14.0g 1.6g 13792 S 6.2 5.2 905:38.14 java…
最耗 CPU 的是两个 Java 进程(12.5% 和 6.2%),合计不到 20%;其他进程几乎不占 CPU;所有进程状态均为 R(Running)或S(Sleeping),没有D状态!
⚠️ 但等等!top 不显示 D 状态进程,除非你主动查看!
所以,我们需要执行:
ps aux | grep 'D'
结果发现:几十个进程卡在 D 状态,全部与 /data 挂载点相关!
1.2 CPU LOAD怎么计算的
以上的情况也验证了我们之前说的CPU Load ≠ CPU 使用率。
CPU 使用率:表示 CPU 正在干活的时间占比。
Load Average:表示正在运行或等待资源(主要是 CPU 或不可中断状态)的进程平均数。
关键点来了:Load 包含处于 “不可中断睡眠状态(D 状态)” 的进程!这类进程通常是在等待 I/O 完成(比如磁盘读写、NFS 请求等),它们不占用CPU,但会计入Load。
2. 深挖根源:一块坏盘引发的“负载风暴”
通过以上现象及进一步的排查,最终定位问题:
2.1 查看磁盘 I/O 状态
iostat -x 1
输出显示:
-
/dev/sdb(对应 /data)的 await 达 12000ms,严重超时;
-
%util 接近 100%,但实际吞吐量极低;
-
rsec/s 和 wsec/s 都接近0,说明磁盘已“瘫痪”。
2.2 查看系统日志
dmesg | grep -i error
发现大量类似错误:
Buffer I/O error on dev sdb1, logical block 12345678sd 2:0:0:0: [sdb] FAILED Result: hostbyte=DID_OK driverbyte=DRIVER_TIMEOUT
此错误已明确指出:物理磁盘或控制器故障!
2.3 检查挂载点
df -h /data
执行以上命令时直接卡了,结果显示 /data 已经无法读写,然后发现负载进一步+1。但因为是非核心业务目录(原应用已迁移),所以不影响主流程。
2.4 为什么业务不卡?
尽管 Load 超 200,但业务依然流畅,原因如下:
| 核心服务 | 运行在系统盘/上,I/O正常 |
| 用户请求路径 | 不经过故障磁盘 |
| 故障磁盘用途 | 用于日志归档、备份、冷数据存储等非实时任务 |
| 卡住的进程 | 多为后台监控脚本、定时任务,不参与主线程 |
因此,虽然系统整体负载虚高,但真正影响用户体验的部分毫发无损。
3. 如何应对?三步解决
3.1 立即尝试卸载故障设备
umount /data
通常会失败,显示设备正忙。此时如果失败,可尝试:
echo 1 > /sys/block/sdb/device/delete
如果还是失败,则需要重启服务器。
3.2 更换硬盘并恢复数据
部分情况下磁盘坏块引起的异常重启后磁盘可能会可用,但是还是建议进行更换。如果无法使用则必须更换硬盘,大概更换及恢复的步骤如下:
更换物理磁盘
重新挂载并修复文件系统
若有备份,同步数据
关于如何挂载新盘,可以查看历史文章
圣诞快乐!学点Linux小技能
手把手教你用fdisk为硬盘分区
3.3 加强监控与告警
这种情况我已经经历过多次,大部分都是因为磁盘故障导致;也有一种情况是挂在了NFS硬盘,但是因某个时间段内网络抖动引起。因此为了提前感知异常及快速定位问题,建议做好以下工作:
-
监控各磁盘的 await、%util
-
设置D状态进程数量阈值告警
-
对非核心存储设置超时熔断机制
4. 结语
运维的本质,是透过现象看本质。就像本次的现象,看似“灾难级”的负载告警,可能只是一个坏掉的磁盘在背后搞鬼。下次当你看到“8核机器负载 200+”,别急着扩容、重启、报警,先问一句:“有没有哪个磁盘,正在默默‘卡死’所有进程?”
关于LOAD的技术再次小结一下,核心记住如下列表内容:
| Load Average | 等待或运行的进程总数 | ⚠️ 易受 D 状态影响 |
| CPU 使用率 | 实际消耗 CPU 的百分比 | ✅ 可靠 |
| IO Wait | CPU等待I/O的时间 | ❌ 不完整(忽略 D 状态) |
|
D 状态进程 |
不可中断睡眠,通常在等 I/O | ✅ 关键线索 |
记住一句话:当 Load 异常高,但 CPU 使用率低时,优先检查磁盘和 I/O 状态!
#Linux #运维 #性能分析 #LoadAverage #磁盘故障 #SRE #top命令 #D状态 #数据库服务器
关于数据库、服务器及日常运维中你有没有遇到相关的“诡异”的问题,可以在留言区留言交流,也欢迎点赞、转发,给更多需要的朋友们看到此文章。
如果有关于数据库、运维、大数据相关问题,欢迎关注我的微信公众号“数据库干货铺”进行交流。



评论前必须登录!
注册