 网硕互联帮助中心
网硕互联帮助中心一、文本处理工具
1.grep(global regular expression print):行处理工具,可以匹配关键字或正则表达式,并默认把整行内容输出到终端上,时日常查找文本最常用的工具。
2.sed(stream editor):流式编辑器,核心作用是流式编辑文本(替换、删除、插入、追加等),默认仅输出处理结果,而不修改原文件。
3.awk:文本“分析处理”工具,核心作用是按分隔符拆分字段,再按列 / 字段处理文本,擅长数据提取、统计、格式化输出。
各文本处理工具的常用选项
1.grep:
- 测试文本如下:
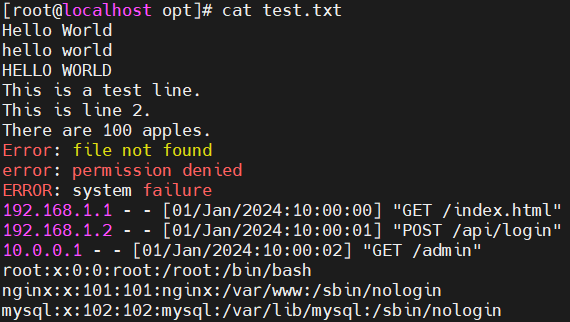
- -i —— 忽略大小写
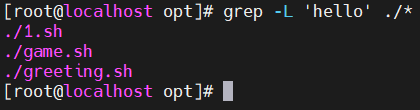
- -v —— 反向匹配

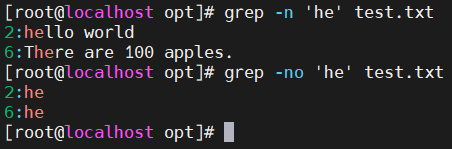
- -n —— 显示行号

- -c —— 只统计匹配行数

- -l ——只显示匹配的文件名

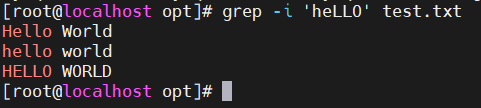
- -L —— 只显示不匹配的文件名
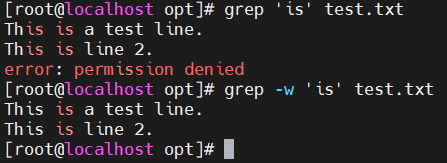
- -w —— 匹配整个单词,区分单词中包含关键字的情况
- -x —— 匹配整行,以关键字作为整行内容进行匹配
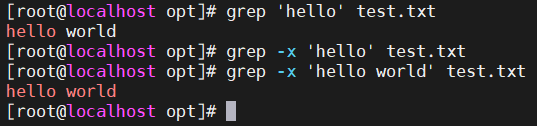
- -o —— 只输出匹配部分
- -E —— 使用扩展正则
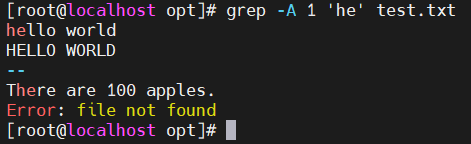
- -A n —— 显示匹配行及后n行
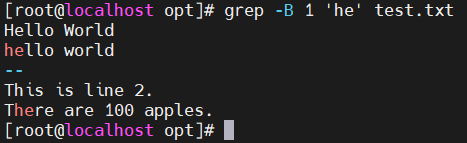
- -B n —— 显示匹配行及前n行
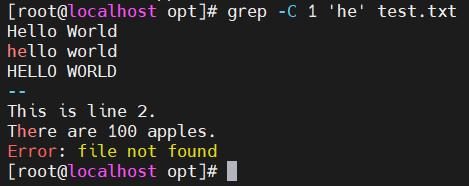
- -C n —— 显示匹配行及前后各n行
- -r —— 递归搜索目录
- -q —— 静默模式,不输出

2.sed
- -i —— sed的处理动作同步生效与原文件
- -n —— 进行print动作时需要添加
- -n '3p' filename —— 打印第三行

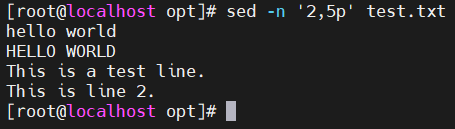
- -n '2,5p' filename —— 打印二到五行
- -n '$p' filename —— 打印最后一行

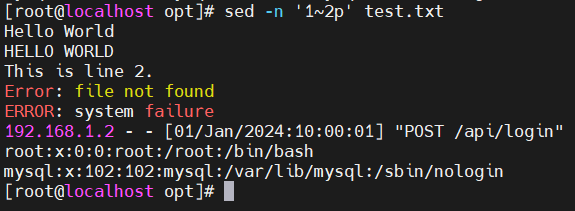
- -n '1~2p' filename —— 打印奇数行(从第1行开始每隔2行打印)
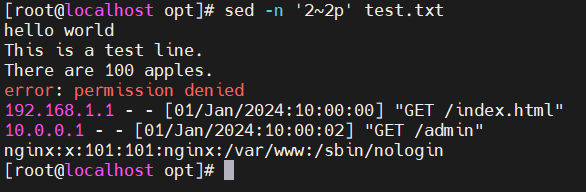
- -n '2~2p' filename —— 打印偶数行(从第2行开始每隔2行打印)
- -n '/a/p' filename —— 打印包含a的行
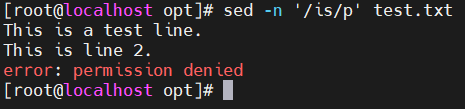
- 's/old/new/g' —— s表示替换,g表示全局

- 's/old/new/g; s/old1/new1/g' —— 同时执行多个指令用“; ”隔开

3.awk
- 测试文本如下

- -F——指定分隔符

- 指定条件过滤

二、基本正则表达式
( ) : 小括号,表示分组
[ ] :表示匹配1个字符串
{ } :表示匹配出现的频次
字符匹配
|
元字符 |
含义 |
示例 |
匹配 |
|
. |
匹配任意单个字符 |
a.c |
abc,adc,a1c,a c |
|
[ ] |
匹配括号内任意一个字符 |
[abc] |
a或b或c |
|
[^ ] |
匹配不在括号内的字符 |
[^abc] |
除a,bc外的任意字符 |
|
[a-z] |
匹配范围内的字符 |
[a-z] |
任意小写字母 |
|
[0-9] |
匹配数字 |
[0-9] |
任意数字 |
位置锚定
|
元字符 |
含义 |
示例 |
匹配 |
|
^ |
行首 |
^hello |
以hello开头的行 |
|
$ |
行尾 |
world$ |
以world结尾的行 |
|
^$ |
空行 |
^$ |
空白行 |
|
\\< |
词首 |
\\<the |
the,them,theatre |
|
\\> |
词尾 |
the\\> |
the,bathe |
|
\\b |
词边界 |
\\bthe\\b |
只匹配独立的the |
次数匹配
|
元字符 |
含义 |
示例 |
匹配 |
|
* |
前一个字符出现0次或多次 |
ab*c |
ac,abc,abbc,abbbc |
|
\\+ |
前一个字符出现1次或多次 |
ab\\+c |
abc,abbc,abbbc |
|
\\? |
前一个字符出现0次或1次 |
ab\\?c |
ac,abc |
|
\\{n\\} |
前一个字符恰好出现n次 |
a\\{3\\} |
aaa |
|
\\{n,\\} |
前一个字符至少出现n次 |
a\\{3,\\} |
aaa,aaaa,aaaaa |
|
\\{n,m\\} |
前一个字符出现n到m次 |
a\\{2,4\\} |
aa,aaa,aaaa |
分组与引用
|
元字符 |
含义 |
示例 |
匹配 |
|
\\(\\) |
分组 |
\\(ab\\)* |
ab整体重复0次或多次 |
|
\\1 |
反向引用第1个分组 |
\\(.\\)\\1 |
匹配连续两个相同字符 |
常用字符类
|
字符类 |
等价于 |
含义 |
|
[[:alpha:]] |
[a-zA-Z] |
字母 |
|
[[:digit:]] |
[0-9] |
数字 |
|
[[:alnum:]] |
[a-zA-Z0-9] |
字母和数字 |
|
[[:space:]] |
空白字符 |
空格、制表符、换行等 |
|
[[:upper:]] |
[A-Z] |
大写字母 |
|
[[:lower:]] |
[a-z] |
小写字母 |
|
[[:punct:]] |
标点符号 |
标点符号 |
三、其他文本处理的命令
wc
- 用于统计文件的行数、单词数和字节数。
- -l —— 统计行数
- -w —— 统计单词数
- -c —— 统计字节数
- -m —— 统计字符数
sort
- 用于对文本行进行排序,默认按ASCⅡ码顺序升序排列。
- -n —— 按数值排序
- -r —— 降序(逆序)排序
- -k —— 按指定列排序 —— sort -k2 filename
- -t —— 指定字段分隔符 —— sort -t: -k3 filename
- -u —— 排序并去重
- -f —— 忽略大小写
- -h —— 按人类可读数值排序
- -o —— 输出到指定文件 —— sort filename -o sorted_file
- -c —— 检查是否已排序
- -s —— 稳定排序
- -M —— 按月份排序
uniq
用于去除或统计相邻的重复行。特点是只处理相邻的重复行,故通常需要先sort排序。
- -c —— 统计重复次数
- -d —— 只显示重复的行
- -u —— 只显示不重复的行
- -i —— 忽略大小写
- -f N —— 跳过前N个字段
- -s N —— 跳过前N个字符
- -w N —— 只比较前N个字符





评论前必须登录!
注册