 网硕互联帮助中心
网硕互联帮助中心26年1月来自军事科学研究院、南昌大学、西安交大和中科院计算所的论文“A Vision–Language–Action Model with Visual Prompt for OFF-Road Trajectory Prediction”。
在越野地形中进行高效的轨迹规划对自动驾驶车辆而言是一项艰巨的挑战,通常需要复杂的多步骤流程。然而,传统方法在动态环境中的适应性有限。为了克服这些局限性,本文提出一种名为OffEMMA的端到端多模态框架,旨在克服视觉-语言-动作(VLA)模型在越野自动驾驶场景中空间感知不足和推理不稳定的缺陷。该框架通过设计视觉提示模块对输入图像进行显式标注,并引入自洽的思维链(COT-SC)推理策略来提高轨迹规划的准确性和鲁棒性。视觉提示模块利用语义分割掩码作为视觉提示,增强预训练视觉-语言模型在复杂地形中的空间理解能力。COT-SC策略通过多路径推理机制有效地降低异常值对规划性能的误差影响。在 RELLIS-3D 越野数据集上的实验结果表明,OffEMMA 的性能明显优于现有方法,将 Qwen 骨干模型的平均 L2 误差降低 13.3%,并将故障率从 16.52% 降低到 6.56%。
如图展示 OffEMMA 的整体架构,OffEMMA 是一个端到端的越野自动驾驶框架,它利用开源的预训练VLM 来实现轨迹规划和场景感知功能。OffEMMA 以历史驾驶状态和预处理图像作为输入来预测未来的运动轨迹。

在每个推理周期中,首先使用视觉提示模块 (VP-Block) 处理来自 RELLIS-3D 数据集的前置摄像头图像,得到一个带标签的掩码图像,然后将其与车辆的历史驾驶数据一起输入到 VLM 中。为了提高预测结果的可解释性和稳定性,采用 COT-SC 策略。在后续阶段,VLM 会显式输出一系列预测的未来驾驶状态。这些预测结果经过数值积分后生成预测轨迹,并将其与真实轨迹进行比较。最后,经过插值处理,得到可视化结果。
为了在复杂的越野环境中实现更高效的轨迹规划,引入COT-SC策略,该策略是对基于CoT推理传统方法的改进。COT-SC通过多路径推理生成答案,有效降低异常值对推理结果的影响,从而提高预测的准确性和鲁棒性。具体而言,在轨迹规划过程中,首先进行多路径推理以获得若干候选结果,然后去除异常值并对剩余的预测结果取平均值,从而获得更稳定、更符合实际的规划轨迹。
本研究旨在提升预训练视觉-语言模型(VLM)在复杂越野环境下的轨迹规划和推理能力,为此提出一种视觉提示标注模块。尽管现有VLM在语言理解和简单的视觉推理任务中表现出色,但其有限的空间理解能力使其在处理复杂的空间推理问题时难以生成高质量的推理结果。尤其是在复杂的越野驾驶场景中,模型的空间感知能力不足,严重影响其在轨迹规划和决策生成方面的性能。
为了解决存在的局限性,并在无需进一步微调预训练骨干网络的情况下提升 LLM 在越野任务中的性能,借鉴 MPDrive [14] 和 SoM 方法,引入一个专为越野任务定制的外部开源语义分割模型 OFFSEG [15],并将其集成到 OffEMMA 系统中。该模块对输入的 RGB 图像进行高效的语义分割,并为不同的类别分配独特的颜色标签,从而为 VLM 提供清晰的场景级提示。
OFFSEG 的工作流程分为两步,其概览如图所示。第一步,将各种标签整合为四大类,并应用语义分割网络。第二步,将分割出的感兴趣区域传递给基于颜色的分割模块,该模块进一步将其细分为更精细的子类(例如草地、泥地或水坑),并将这些详细的标签作为最终输出。这样,原始图像就被转换成具有清晰空间语义的场景特征图,使 VLM 能够更准确地理解不同区域的通行性和障碍物信息。
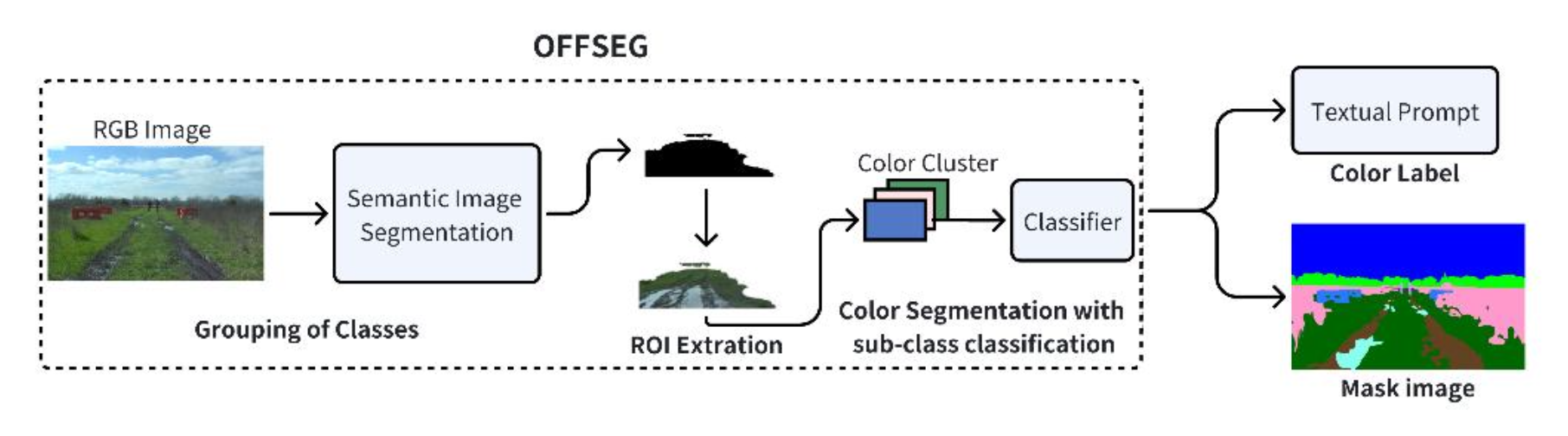
此外,将视觉提示模块生成的颜色标签与传统的文本提示相结合,进一步增强VLM的空间感知能力。具体而言,在构建提示时为每个颜色标签引入语义描述,引导模型在推理过程中将视觉区域与语义关联起来。通过融合丰富的空间语义信息,原本依赖语言和简单视觉输入的VLM能够实现更深层次的空间推理,显著提升其在复杂越野环境中的性能。
总之,VP-Block的引入增强OffEMMA模型在越野场景下的空间推理能力。尤其是在面对复杂障碍物和动态环境时,该模型能够基于空间提示信息做出更精准、更安全的决策。这种创新方法不仅显著提升系统性能,而且避免对预训练模型进行微调,极大地增强模型的适应性和应用灵活性。




评论前必须登录!
注册