 网硕互联帮助中心
网硕互联帮助中心概述
Ultralytics YOLO26是YOLO系列实时目标检测器的最新进化版本,从头开始为边缘和低功耗设备设计。它引入了流线型设计,去除了不必要的复杂性,同时集成了针对性的创新,以提供更快、更轻量、更易于部署的解决方案。

YOLO26的架构遵循三个核心原则:
- 简洁性:YOLO26是原生端到端模型,直接生成预测结果,无需非最大值抑制(NMS)。通过消除这一后处理步骤,推理变得更快、更轻量,并且在实际系统中更容易部署。这种突破性方法最早由清华大学的王傲在YOLOv10中首创,并在YOLO26中得到进一步发展。
- 部署效率:端到端设计消除了整个处理流程中的一个阶段,大大简化了集成,降低了延迟,并使跨不同环境的部署更加稳健。
- 训练创新:YOLO26引入了MuSGD优化器,这是SGD和Muon的混合体——受到Moonshot AI的Kimi K2在大语言模型训练中突破的启发。该优化器将来自语言模型的优化进展带入计算机视觉领域,带来增强的稳定性和更快的收敛速度。
- 任务特定优化:YOLO26为专门任务引入了针对性改进,包括用于分割的语义分割损失和多尺度proto模块,用于高精度姿态估计的残差对数似然估计(RLE),以及优化的解码和角度损失以解决OBB中的边界问题。
这些创新共同提供了一个模型系列,可在小物体上实现更高的准确度,提供无缝部署,并在CPU上运行速度提升高达43%——使YOLO26成为迄今为止最适合资源受限环境部署的最实用、最易部署的YOLO模型之一。
关键特性
-
DFL移除 分布焦点损失(DFL)模块虽然有效,但常常使导出复杂化并限制硬件兼容性。YOLO26完全移除了DFL,简化了推理并扩大了对边缘和低功耗设备的支持。
-
端到端无NMS推理 与依赖NMS作为单独后处理步骤的传统检测器不同,YOLO26是原生端到端的。预测直接生成,降低了延迟,使集成到生产系统中更快、更轻量、更可靠。
-
ProgLoss + STAL 改进的损失函数提高了检测准确度,在小物体识别方面有显著改进,这对物联网、机器人、航空图像和其他边缘应用至关重要。
-
MuSGD优化器 一种新的混合优化器,结合了SGD和Muon。受Moonshot AI的Kimi K2启发,MuSGD将大语言模型训练中的高级优化方法引入计算机视觉,实现更稳定的训练和更快的收敛。
-
CPU推理速度提升高达43% 专为边缘计算优化,YOLO26提供显著更快的CPU推理,确保在没有GPU的设备上实现实时性能。
-
实例分割增强 引入语义分割损失以改进模型收敛,并升级了proto模块,利用多尺度信息提供更优质的掩码。
-
精确姿态估计 集成残差对数似然估计(RLE)以实现更准确的关键点定位,并优化了解码过程以提高推理速度。
-
优化的OBB解码 引入专门的角度损失以提高对方形物体的检测准确度,并优化OBB解码以解决边界不连续问题。
支持的任务和模式
YOLO26建立在早期Ultralytics YOLO版本建立的多功能模型范围之上,提供对各种计算机视觉任务的增强支持:
| YOLO26 | yolo26n.pt yolo26s.pt yolo26m.pt yolo26l.pt yolo26x.pt | 检测 | ✅ | ✅ | ✅ | ✅ |
| YOLO26-seg | yolo26n-seg.pt yolo26s-seg.pt yolo26m-seg.pt yolo26l-seg.pt yolo26x-seg.pt | 实例分割 | ✅ | ✅ | ✅ | ✅ |
| YOLO26-pose | yolo26n-pose.pt yolo26s-pose.pt yolo26m-pose.pt yolo26l-pose.pt yolo26x-pose.pt | 姿态/关键点 | ✅ | ✅ | ✅ | ✅ |
| YOLO26-obb | yolo26n-obb.pt yolo26s-obb.pt yolo26m-obb.pt yolo26l-obb.pt yolo26x-obb.pt | 定向检测 | ✅ | ✅ | ✅ | ✅ |
| YOLO26-cls | yolo26n-cls.pt yolo26s-cls.pt yolo26m-cls.pt yolo26l-cls.pt yolo26x-cls.pt | 分类 | ✅ | ✅ | ✅ | ✅ |
这个统一框架确保YOLO26适用于实时检测、分割、分类、姿态估计和定向目标检测——全部支持训练、验证、推理和导出。
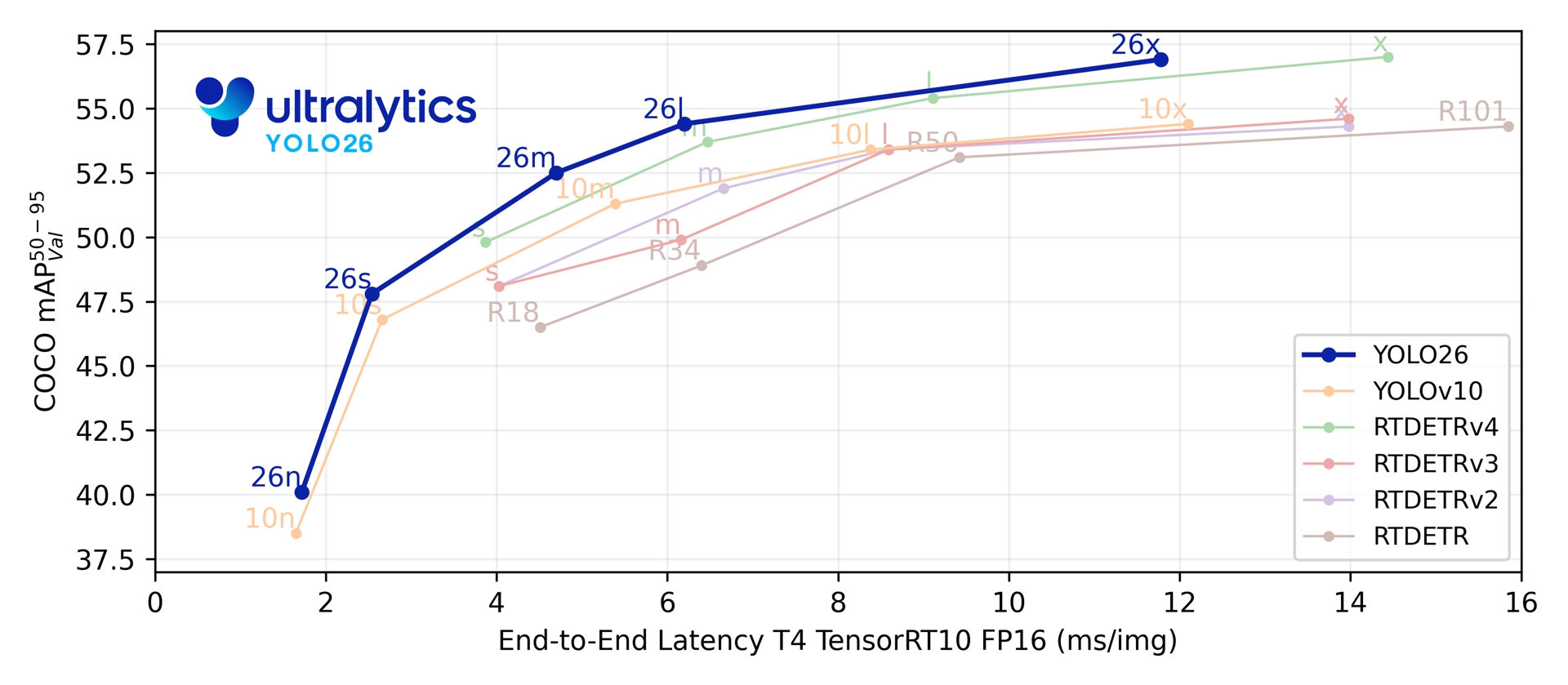
性能指标
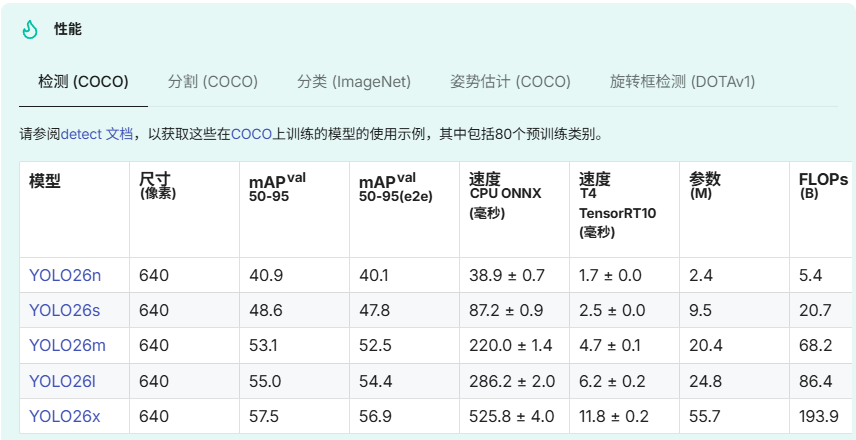
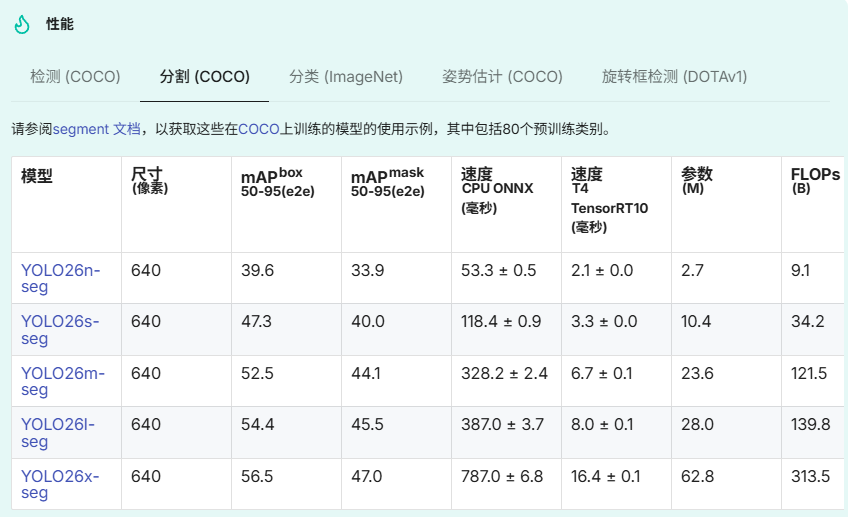
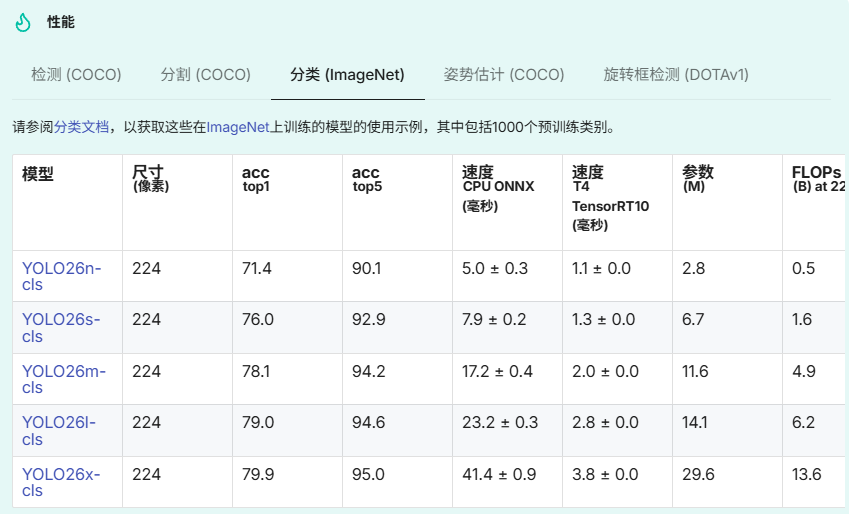

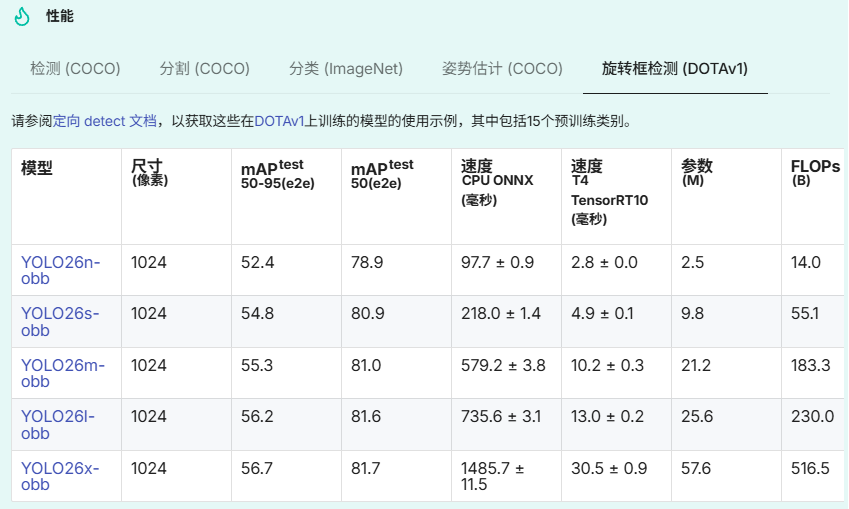
使用示例
本节提供了简单的YOLO26训练和推理示例。有关这些和其他模式的完整文档,请参阅预测、训练、验证和导出文档页面。
请注意,以下示例适用于YOLO26 检测模型,用于目标检测。有关其他支持任务的详细信息,请参阅分割、分类、OBB和姿态文档。
from ultralytics import YOLO
# Load a COCO–pretrained YOLO26n model
model = YOLO("yolo26n.pt")
# Train the model on the COCO8 example dataset for 100 epochs
results = model.train(data="coco8.yaml", epochs=100, imgsz=640)
# Run inference with the YOLO26n model on the 'bus.jpg' image
results = model("path/to/bus.jpg")
YOLOE-26:开放词汇实例分割
YOLOE-26将高性能的YOLO26架构与YOLOE系列的开放词汇能力集成在一起。它使用文本提示、视觉提示或无提示模式进行零样本推理,实现对任何物体类别的实时检测和分割,有效消除了固定类别训练的限制。
通过利用YOLO26的无NMS、端到端设计,YOLOE-26提供快速的开放世界推理。这使其成为动态环境中边缘应用的强大解决方案,其中感兴趣的对象代表广泛且不断发展的词汇。
文本/视觉提示
| YOLOE-26n-seg | 640 | Text/Visual | 23.7 / 20.9 | 24.7 / 21.9 | 20.5 / 17.6 | 24.1 / 22.3 | 26.1 / 22.4 | 4.8 | 6.0 |
| YOLOE-26s-seg | 640 | Text/Visual | 29.9 / 27.1 | 30.8 / 28.6 | 23.9 / 25.1 | 29.6 / 27.8 | 33.0 / 29.9 | 13.1 | 21.7 |
| YOLOE-26m-seg | 640 | Text/Visual | 35.4 / 31.3 | 35.4 / 33.9 | 31.1 / 33.4 | 34.7 / 34.0 | 36.9 / 33.8 | 27.9 | 70.1 |
| YOLOE-26l-seg | 640 | Text/Visual | 36.8 / 33.7 | 37.8 / 36.3 | 35.1 / 37.6 | 37.6 / 36.2 | 38.5 / 36.1 | 32.3 | 88.3 |
| YOLOE-26x-seg | 640 | Text/Visual | 39.5 / 36.2 | 40.6 / 38.5 | 37.4 / 35.3 | 40.9 / 38.8 | 41.0 / 38.8 | 69.9 | 196.7 |
没有提示
| YOLOE-26n-seg-pf | 640 | 16.6 | 22.7 | 6.5 | 15.8 |
| YOLOE-26s-seg-pf | 640 | 21.4 | 28.6 | 16.2 | 35.5 |
| YOLOE-26m-seg-pf | 640 | 25.7 | 33.6 | 36.2 | 122.1 |
| YOLOE-26l-seg-pf | 640 | 27.2 | 35.4 | 40.6 | 140.4 |
| YOLOE-26x-seg-pf | 640 | 29.9 | 38.7 | 86.3 | 314.4 |
使用示例
YOLOE-26支持文本提示和视觉提示。使用提示非常简单——只需通过predict方法传递它们,如下所示:
!!! 示例
“文本提示”
文本提示允许您通过文本描述指定要检测的类别。以下代码展示了如何使用YOLOE-26在图像中检测人和公交车:
from ultralytics import YOLO
# Initialize model
model = YOLO("yoloe-26l-seg.pt") # or select yoloe–26s/m–seg.pt for different sizes
# Set text prompt to detect person and bus. You only need to do this once after you load the model.
names = ["person", "bus"]
model.set_classes(names, model.get_text_pe(names))
# Run detection on the given image
results = model.predict("path/to/image.jpg")
# Show results
results[0].show()
“视觉提示”
import numpy as np
from ultralytics import YOLO
from ultralytics.models.yolo.yoloe import YOLOEVPSegPredictor
# Initialize model
model = YOLO("yoloe-26l-seg.pt")
# Define visual prompts using bounding boxes and their corresponding class IDs.
# Each box highlights an example of the object you want the model to detect.
visual_prompts = dict(
bboxes=np.array(
[
[221.52, 405.8, 344.98, 857.54], # Box enclosing person
[120, 425, 160, 445], # Box enclosing glasses
],
),
cls=np.array(
[
0, # ID to be assigned for person
1, # ID to be assigned for glassses
]
),
)
# Run inference on an image, using the provided visual prompts as guidance
results = model.predict(
"ultralytics/assets/bus.jpg",
visual_prompts=visual_prompts,
predictor=YOLOEVPSegPredictor,
)
# Show results
results[0].show()
“无提示”
YOLOE-26包括具有内置词汇表的无提示变体。这些模型不需要任何提示,像传统YOLO模型一样工作。它们不依赖用户提供的标签或视觉示例,而是从预定义的4,585个类别列表中检测对象,该列表基于识别任何事物模型Plus (RAM++)使用的标签集。
from ultralytics import YOLO
# Initialize model
model = YOLO("yoloe-26l-seg-pf.pt")
# Run prediction. No prompts required.
results = model.predict("path/to/image.jpg")
# Show results
results[0].show()
要深入了解提示技术、从头开始训练和完整使用示例,请访问**YOLOE文档**。
引用和致谢
!!! 提示 “Ultralytics YOLO26出版物”
Ultralytics尚未为YOLO26发表正式研究论文,因为模型正在快速演进。相反,我们专注于提供尖端模型并使它们易于使用。有关YOLO特性、架构和使用的最新更新,请访问我们的[GitHub仓库](https://github.com/ultralytics/ultralytics)和[文档](https://docs.ultralytics.com/)。
如果您在工作中使用YOLO26或其他Ultralytics软件,请引用如下:
!!! 引用 “”
=== "BibTeX"
```bibtex
@software{yolo26_ultralytics,
author = {Glenn Jocher and Jing Qiu},
title = {Ultralytics YOLO26},
version = {26.0.0},
year = {2026},
url = {https://github.com/ultralytics/ultralytics},
orcid = {0000-0001-5950-6979, 0000-0003-3783-7069},
license = {AGPL-3.0}
}
```
DOI待定。YOLO26在AGPL-3.0和企业许可证下提供。


评论前必须登录!
注册