 网硕互联帮助中心
网硕互联帮助中心深度学习笔记:从ANN到CNN+DNN的图像分类实践
一、深度学习基础:ANN、CNN与DNN的核心原理
1.1 人工神经网络(ANN):深度学习的起点
1.1.1 什么是人工神经网络?
人工神经网络(Artificial Neural Network, ANN)是一种模仿生物神经网络结构和功能的数学模型,由大量的神经元相互连接而成。
1.1.2 神经元的数学模型
最基本的神经元模型是感知器(Perceptron):
y
=
f
(
w
T
x
+
b
)
y = f(w^T x + b)
y=f(wTx+b)
其中:
-
x
x
x:输入向量,x
=
[
x
1
,
x
2
,
.
.
.
,
x
n
]
T
x = [x_1, x_2, …, x_n]^T
x=[x1,x2,…,xn]T -
w
w
w:权重向量,w
=
[
w
1
,
w
2
,
.
.
.
,
w
n
]
T
w = [w_1, w_2, …, w_n]^T
w=[w1,w2,…,wn]T -
b
b
b:偏置项 -
f
(
⋅
)
f(\\cdot)
f(⋅):激活函数 -
y
y
y:输出
1.1.3 激活函数:引入非线性的关键
常见的激活函数:
Sigmoid函数:
f
(
z
)
=
1
1
+
e
−
z
f(z) = \\frac{1}{1 + e^{-z}}
f(z)=1+e−z1 导数:
f
′
(
z
)
=
f
(
z
)
(
1
−
f
(
z
)
)
f'(z) = f(z)(1 – f(z))
f′(z)=f(z)(1−f(z))
ReLU函数(Rectified Linear Unit):
f
(
z
)
=
m
a
x
(
0
,
z
)
f(z) = max(0, z)
f(z)=max(0,z) 导数:
f
′
(
z
)
=
{
1
,
z
>
0
0
,
z
≤
0
f'(z) = \\begin{cases} 1, & z > 0 \\\\ 0, & z \\leq 0 \\end{cases}
f′(z)={1,0,z>0z≤0
Tanh函数:
f
(
z
)
=
e
z
−
e
−
z
e
z
+
e
−
z
f(z) = \\frac{e^z – e^{-z}}{e^z + e^{-z}}
f(z)=ez+e−zez−e−z 导数:
f
′
(
z
)
=
1
−
f
(
z
)
2
f'(z) = 1 – f(z)^2
f′(z)=1−f(z)2
1.1.4 神经网络的基本结构
ANN通常由输入层、隐藏层和输出层组成:
- 输入层:接收外部输入数据
- 隐藏层:学习输入数据的特征表示
- 输出层:产生最终的预测结果
1.1.5 反向传播算法:神经网络的学习方式
反向传播算法(Backpropagation)是训练ANN的核心算法,基于梯度下降法:
损失函数(交叉熵损失):
L
=
−
∑
i
=
1
C
y
i
log
(
y
^
i
)
L = -\\sum_{i=1}^{C} y_i \\log(\\hat{y}_i)
L=−i=1∑Cyilog(y^i)
其中:
-
C
C
C:类别数 -
y
i
y_i
yi:真实标签的独热编码 -
y
^
i
\\hat{y}_i
y^i:网络预测的概率
参数更新:
w
=
w
−
η
∂
L
∂
w
w = w – \\eta \\frac{\\partial L}{\\partial w}
w=w−η∂w∂L
b
=
b
−
η
∂
L
∂
b
b = b – \\eta \\frac{\\partial L}{\\partial b}
b=b−η∂b∂L
其中:
-
η
\\eta
η:学习率 -
∂
L
∂
w
\\frac{\\partial L}{\\partial w}
∂w∂L:损失对权重的梯度 -
∂
L
∂
b
\\frac{\\partial L}{\\partial b}
∂b∂L:损失对偏置的梯度
1.2 深度神经网络(DNN):探索更深层次的特征
1.2.1 深度网络的定义与特点
深度神经网络(Deep Neural Network, DNN)是具有多个隐藏层的神经网络,能够学习更复杂的特征表示。
1.2.2 深度网络的数学表达
DNN的结构与ANN类似,但包含更多的隐藏层:
y
=
f
L
(
f
L
−
1
(
.
.
.
f
2
(
f
1
(
w
1
T
x
+
b
1
)
w
2
T
+
b
2
)
.
.
.
)
w
L
T
+
b
L
)
y = f_L( f_{L-1}( … f_2( f_1(w_1^T x + b_1) w_2^T + b_2 ) … ) w_L^T + b_L )
y=fL(fL−1(…f2(f1(w1Tx+b1)w2T+b2)…)wLT+bL)
其中:
-
L
L
L:网络层数 -
f
l
(
⋅
)
f_l(\\cdot)
fl(⋅):第l
l
l层的激活函数 -
w
l
w_l
wl:第l
l
l层的权重矩阵 -
b
l
b_l
bl:第l
l
l层的偏置向量
1.2.3 深度网络的训练挑战与解决方案
深度网络训练面临的挑战:
梯度消失/爆炸:深度网络中,梯度在反向传播过程中容易消失或爆炸
- 解决方法:使用ReLU激活函数、批标准化、残差连接等
过拟合:深度网络容易在训练数据上过度拟合
- 解决方法:正则化、Dropout、数据增强等
计算复杂度高:深度网络需要大量的计算资源和训练数据
1.3 卷积神经网络(CNN)
1.3.1 CNN的基本思想
卷积神经网络(Convolutional Neural Network, CNN)是一种专门用于处理具有网格结构数据(如图像、音频)的神经网络,通过卷积操作提取局部特征。
1.3.2 CNN的核心组件解析
卷积层
- 卷积操作:
(
f
∗
g
)
(
i
,
j
)
=
∑
m
=
−
M
M
∑
n
=
−
N
N
f
(
m
,
n
)
g
(
i
+
m
,
j
+
n
)
(f * g)(i, j) = \\sum_{m=-M}^{M} \\sum_{n=-N}^{N} f(m, n) g(i+m, j+n)
(f∗g)(i,j)=m=−M∑Mn=−N∑Nf(m,n)g(i+m,j+n) 其中,f
f
f是卷积核,g
g
g是输入特征图 - 参数共享:同一卷积核在整个输入上共享参数
- 局部连接:每个神经元只连接输入的局部区域
池化层
- 最大池化(Max Pooling):
(
P
m
a
x
g
)
(
i
,
j
)
=
m
a
x
m
=
0
k
−
1
m
a
x
n
=
0
k
−
1
g
(
i
∗
k
+
m
,
j
∗
k
+
n
)
(P_{max} g)(i, j) = max_{m=0}^{k-1} max_{n=0}^{k-1} g(i*k+m, j*k+n)
(Pmaxg)(i,j)=maxm=0k−1maxn=0k−1g(i∗k+m,j∗k+n) - 平均池化(Average Pooling):
(
P
a
v
g
g
)
(
i
,
j
)
=
1
k
2
∑
m
=
0
k
−
1
∑
n
=
0
k
−
1
g
(
i
∗
k
+
m
,
j
∗
k
+
n
)
(P_{avg} g)(i, j) = \\frac{1}{k^2} \\sum_{m=0}^{k-1} \\sum_{n=0}^{k-1} g(i*k+m, j*k+n)
(Pavgg)(i,j)=k21m=0∑k−1n=0∑k−1g(i∗k+m,j∗k+n) - 作用:降维、提取主要特征、增强不变性
全连接层:将卷积层提取的特征映射到输出类别
激活函数:通常使用ReLU
1.3.3 经典CNN架构一览
- LeNet-5:最早的CNN架构之一,用于手写数字识别
- AlexNet:2012年ImageNet冠军,引入了ReLU、Dropout、数据增强等技术
- VGGNet:使用更小的卷积核和更深的网络结构
- ResNet:引入残差连接,解决深度网络训练问题
- Inception:使用多尺度卷积核并行处理
二、深度学习模型对比:ANN、CNN与DNN的优劣势
2.1 三者的关系:从基础到专业
- ANN:是所有神经网络的基础框架,包括了所有具有神经元结构的网络
- DNN:是ANN的深度版本,通过增加隐藏层深度提升表达能力
- CNN:是DNN的特殊变体,针对网格结构数据优化设计
2.2 核心特性对比
| 结构 | 单隐藏层或多隐藏层 | 多层隐藏层 | 卷积层+池化层+全连接层 |
| 数据类型 | 通用 | 通用 | 网格结构(图像、音频等) |
| 参数数量 | 较少 | 较多 | 相对较少(参数共享) |
| 特征提取 | 人工或自动 | 自动 | 自动(局部特征) |
| 主要应用 | 简单分类、回归 | 复杂分类、回归 | 图像识别、语音识别 |
| 训练难度 | 较低 | 较高(梯度消失/爆炸) | 中等(卷积操作简化训练) |
2.3 适用场景分析
ANN:
- 适用于简单的模式识别任务
- 输入数据维度较低的情况
- 资源受限的环境
DNN:
- 适用于复杂的非线性问题
- 需要学习深层特征表示的任务
- 有大量训练数据的情况
CNN:
- 图像处理:图像分类、目标检测、图像分割
- 音频处理:语音识别、音频分类
- 视频处理:视频分类、动作识别
- 其他网格结构数据:文本处理(1D CNN)、时间序列分析
三、项目实践:CNN与DNN结合的图像分类方案
3.1 项目背景与目标
本项目旨在使用CNN与DNN结合的架构,实现CIFAR10数据集的高效图像分类,探索两种网络结构的优势互补。
3.2 为什么选择CNN+DNN的组合?
优势互补:
- CNN:擅长提取图像的局部特征,保留空间信息,参数共享减少计算量
- DNN:擅长对提取的特征进行复杂的非线性变换和分类
特征层次化:
- CNN层从底层到高层提取越来越抽象的特征
- DNN层对这些层次化的特征进行综合和分类
提高泛化能力:
- CNN的局部连接和参数共享减少了过拟合风险
- DNN的深度结构能够学习更复杂的模式
高效处理图像数据:
- CNN专门针对图像数据的结构设计
- 避免了全连接网络处理图像时的参数爆炸问题
四、代码实现与设计思路解析
4.1 项目代码结构概览
CNN_DNN.py
├── 项目说明文档
├── 核心库导入
├── 数据预处理模块
│ ├── 数据增强策略
│ ├── 数据归一化处理
│ ├── 数据集加载与拆分
├── 模型定义(CNN_DNN_Model类)
│ ├── CNN特征提取模块
│ ├── DNN分类决策模块
│ ├── 前向传播流程
├── 辅助工具函数
│ ├── 训练进度条
├── 核心功能函数
│ ├── 模型训练函数
│ ├── 模型测试函数
├── 可视化模块
│ ├── 训练损失曲线绘制
│ ├── 混淆矩阵生成
│ ├── 错误分类样本展示
│ ├── 正确分类样本展示
│ ├── 预测概率分布可视化
└── 主程序入口
4.2 模型设计与实现思路
4.2.1 网络架构设计:从特征提取到分类决策
CNN特征提取部分:捕捉图像局部信息
-
3个卷积块的设计依据:
- CIFAR10图像尺寸为32×32×3,属于小尺寸图像,3个卷积块足以提取从低级到高级的特征
- 第一层(低级特征):提取边缘、纹理等基础特征
- 第二层(中级特征):组合低级特征,形成形状、轮廓等
- 第三层(高级特征):学习更复杂的语义特征,如物体部件
-
每个卷积块的结构:
卷积块 = 卷积层 + ReLU激活函数 + 最大池化层
- 卷积层:使用3×3卷积核,这是CNN中最有效的卷积核尺寸,在保持较小感受野的同时平衡了计算效率
- 通道数设计:3→32→64→128,呈指数增长,符合特征表示的层次化需求
- 池化层:每层使用2×2最大池化,步长2,使特征图尺寸减半
-
维度演化过程:
输入:32×32×3
卷积块1:32×32×3 → 32×32×32 → 16×16×32
卷积块2:16×16×32 → 16×16×64 → 8×8×64
卷积块3:8×8×64 → 8×8×128 → 4×4×128
DNN分类决策部分:学习复杂非线性映射
-
4个全连接层的设计依据:
- 多层全连接层可以学习复杂的非线性映射关系
- 采用"漏斗"形状(2048→512→256→128→10),逐步减少特征维度,压缩信息
- 最后一层为10个神经元,对应CIFAR10的10个类别
-
Dropout层的设计:
- 在每个全连接层后添加Dropout层,dropout率为0.2
- 较小的dropout率在防止过拟合的同时保留了大部分特征信息
- 仅在训练时使用,测试时关闭
维度匹配设计
-
卷积层输出计算:
# 卷积层输出尺寸计算
output_height = (input_height – kernel_size + 2 * padding) // stride + 1
output_width = (input_width – kernel_size + 2 * padding) // stride + 1对于最后一个卷积块:
输入:8×8×64
卷积:3×3卷积,步长1,填充1 → 输出8×8×128
池化:2×2最大池化,步长2 → 输出4×4×128 -
展平与全连接层输入:
# 展平操作
flattened_size = 128 * 4 * 4 = 2048
# 第一个全连接层输入维度为2048
2. 训练策略:
优化器选择
-
Adam优化器的优势:
- 结合了动量法和RMSProp的优点
- 自适应学习率,对不同参数使用不同的学习率
- 对超参数不敏感,训练稳定性好
- 适合非凸优化问题和大规模数据训练
-
学习率设置:
- 初始学习率1e-3,这是Adam优化器的常用初始值
- 考虑到模型规模适中,未使用学习率衰减策略
- 可进一步优化:使用学习率衰减或余弦退火策略
损失函数选择
- 交叉熵损失的适用性:
- 适合多分类问题,直接优化分类概率
- 对错误分类的惩罚更重,加速模型收敛
- PyTorch的nn.CrossEntropyLoss结合了softmax和交叉熵,使用方便
数据增强技术
-
具体增强方法:
transforms.Compose([
transforms.RandomHorizontalFlip(), # 随机水平翻转
transforms.RandomCrop(32, padding=4), # 随机裁剪
transforms.ToTensor(), # 转换为张量
transforms.Normalize(mean=[0.5, 0.5, 0.5], std=[0.5, 0.5, 0.5]) # 标准化
]) -
增强效果:
- 增加训练数据多样性,减少过拟合
- 提高模型的泛化能力和鲁棒性
- 模拟真实世界中的图像变化
验证集监控
-
验证集划分:
- 从训练集中划分10%作为验证集
- 使用torch.utils.data.random_split实现
-
监控指标:
- 训练损失和验证损失
- 训练准确率和验证准确率
- 训练准确率(Training Accuracy)
- 定义:模型在用于训练的数据集上正确分类的样本数占总训练样本数的比例。
- 数据来源:来自训练集(即代码中trainloader加载的数据),这些数据用于更新模型的参数。
- 作用:反映模型对训练数据的学习程度。训练准确率高表明模型能很好地记忆和拟合训练样本。
- 验证准确率(Validation Accuracy)
- 定义:模型在验证数据集上正确分类的样本数占总验证样本数的比例。
- 数据来源:来自验证集(即代码中valloader加载的数据),这些数据在训练过程中不参与参数更新。
- 作用:反映模型的泛化能力,即模型对未见过的数据的预测能力。验证准确率能帮助检测模型是否过拟合(训练准确率很高但验证准确率低的情况)。
- 两者的关系与意义
- 在理想情况下,训练准确率和验证准确率应该都较高且差距较小,这表明模型既学习了训练数据的规律,又能很好地泛化到新数据。
- 如果训练准确率远高于验证准确率,可能发生了过拟合,模型过度记忆了训练数据的细节,而忽略了数据的普遍规律。
- 如果两者都很低,可能发生了欠拟合,模型没有充分学习到数据的规律。
- 训练准确率(Training Accuracy)
- 可进一步添加其他指标,如精确率、召回率等
-
早停策略:
- 可实现早停策略,当验证损失连续多轮不下降时停止训练
- 保存验证损失最低的模型
3. 可视化设计:
训练损失曲线
-
实现方法:
- 训练过程中记录每轮的训练损失和验证损失
- 使用matplotlib绘制损失曲线
-
技术细节:
plt.figure(figsize=(10, 5))
plt.plot(range(epochs), train_losses, label='Training Loss')
plt.plot(range(epochs), val_losses, label='Validation Loss')
plt.xlabel('Epochs')
plt.ylabel('Loss')
plt.legend()
plt.grid(True)
plt.savefig('training_loss_curve.png') -
结果解读:
- 理想曲线:训练损失和验证损失都逐渐下降,最终趋于稳定
- 过拟合:训练损失持续下降,验证损失先降后升
- 欠拟合:训练损失和验证损失都很高
混淆矩阵
-
实现方法:
- 使用sklearn的confusion_matrix函数计算
- 使用seaborn的heatmap函数可视化
-
技术细节:
from sklearn.metrics import confusion_matrix
import seaborn as snscm = confusion_matrix(true_labels, predicted_labels)
plt.figure(figsize=(12, 10))
sns.heatmap(cm, annot=True, fmt='d', cmap='Blues')
plt.xlabel('Predicted Label')
plt.ylabel('True Label')
plt.savefig('confusion_matrix.png') -
结果解读:
- 对角线元素表示正确分类的样本数
- 非对角线元素表示错误分类的样本数
- 可直观看出哪些类别容易混淆
样本展示
-
错误分类样本:
- 展示模型分类错误的样本,帮助分析模型的弱点
- 显示真实标签和预测标签
-
正确分类样本:
- 展示模型分类正确的样本,特别是置信度较低的样本
- 帮助了解模型的优势
-
技术细节:
# 显示前25个错误分类样本
plt.figure(figsize=(10, 10))
for i in range(25):
plt.subplot(5, 5, i+1)
plt.imshow(misclassified_images[i].permute(1, 2, 0))
plt.title(f'True: {true_label}, Pred: {pred_label}')
plt.axis('off')
plt.tight_layout()
plt.savefig('misclassified_samples.png')
预测概率分布
-
实现方法:
- 使用模型的softmax输出获取预测概率
- 绘制概率分布直方图或条形图
-
技术细节:
# 获取预测概率
probabilities = F.softmax(model(inputs), dim=1)
# 绘制前5个样本的概率分布
plt.figure(figsize=(15, 5))
for i in range(5):
plt.subplot(1, 5, i+1)
plt.bar(range(10), probabilities[i].detach().numpy())
plt.title(f'Sample {i+1}')
plt.xlabel('Class')
plt.ylabel('Probability')
plt.tight_layout()
plt.savefig('prediction_probabilities.png') -
结果解读:
- 观察模型对正确类别的置信度
- 分析模型是否对错误类别有较高的置信度
- 了解模型的决策边界
4.3 结合知识点与公式的代码分析
4.3.1 卷积操作:图像特征提取的数学原理
nn.Conv2d(3, 32, 3, 1, 1) # 3通道输入,32通道输出,3×3卷积核,步长1,填充1
数学原理与推导:
卷积像操作的本质是在输入特征图上滑动卷积核,计算局部区域的加权和。对于多通道输入,每个通道都有独立的卷积核,输出是所有通道结果的总和。
多通道卷积公式:
(
f
∗
g
)
(
i
,
j
,
k
)
=
∑
c
=
1
C
∑
m
=
−
1
1
∑
n
=
−
1
1
f
(
c
,
m
,
n
,
k
)
g
(
i
+
m
,
j
+
n
,
c
)
(f * g)(i, j, k) = \\sum_{c=1}^{C} \\sum_{m=-1}^{1} \\sum_{n=-1}^{1} f(c, m, n, k) g(i+m, j+n, c)
(f∗g)(i,j,k)=c=1∑Cm=−1∑1n=−1∑1f(c,m,n,k)g(i+m,j+n,c)
其中:
-
C
C
C:输入通道数(此处为3) -
k
k
k:输出通道数(此处为32) -
f
(
c
,
m
,
n
,
k
)
f(c, m, n, k)
f(c,m,n,k):第k
k
k个输出通道对应的第c
c
c个输入通道的卷积核权重 -
g
(
i
+
m
,
j
+
n
,
c
)
g(i+m, j+n, c)
g(i+m,j+n,c):输入特征图在位置(
i
+
m
,
j
+
n
)
(i+m, j+n)
(i+m,j+n)处的第c
c
c个通道值
输出特征图尺寸计算:
O
u
t
p
u
t
_
s
i
z
e
=
I
n
p
u
t
_
s
i
z
e
+
2
∗
P
a
d
d
i
n
g
−
K
e
r
n
e
l
_
s
i
z
e
S
t
r
i
d
e
+
1
Output\\_size = \\frac{Input\\_size + 2*Padding – Kernel\\_size}{Stride} + 1
Output_size=StrideInput_size+2∗Padding−Kernel_size+1
对于本项目:
O
u
t
p
u
t
_
s
i
z
e
=
32
+
2
∗
1
−
3
1
+
1
=
32
Output\\_size = \\frac{32 + 2*1 – 3}{1} + 1 = 32
Output_size=132+2∗1−3+1=32" 保持了输入输出尺寸不变(same卷积)。
代码设计思路:
- 3×3卷积核:平衡了计算效率和特征提取能力,是CNN中最常用的卷积核尺寸
- 32个输出通道:第一层卷积使用较少的通道数,避免参数爆炸
- 步长1:保留更多空间信息
- 填充1:保持输出尺寸与输入相同,避免边缘信息丢失
2. 池化操作:
nn.MaxPool2d(2, 2) # 2×2最大池化,步长2
数学原理与推导:
池化操作是一种下采样技术,用于减少特征图的空间尺寸和参数数量,同时增强特征的不变性。
最大池化公式:
(
P
m
a
x
g
)
(
i
,
j
,
c
)
=
m
a
x
m
=
0
1
m
a
x
n
=
0
1
g
(
i
∗
2
+
m
,
j
∗
2
+
n
,
c
)
(P_{max} g)(i, j, c) = max_{m=0}^{1} max_{n=0}^{1} g(i*2+m, j*2+n, c)
(Pmaxg)(i,j,c)=maxm=01maxn=01g(i∗2+m,j∗2+n,c)
平均池化公式:
(
P
a
v
g
g
)
(
i
,
j
,
c
)
=
1
4
∑
m
=
0
1
∑
n
=
0
1
g
(
i
∗
2
+
m
,
j
∗
2
+
n
,
c
)
(P_{avg} g)(i, j, c) = \\frac{1}{4} \\sum_{m=0}^{1} \\sum_{n=0}^{1} g(i*2+m, j*2+n, c)
(Pavgg)(i,j,c)=41m=0∑1n=0∑1g(i∗2+m,j∗2+n,c)
代码设计思路:
- 选择最大池化:更好地保留纹理和边缘特征,适合图像分类任务
- 2×2池化核:常用的池化尺寸,在降维和信息保留之间取得平衡
- 步长2:使特征图尺寸减半,有效减少计算量
与项目的结合:
连续3次池化操作将输入32×32的图像逐步降维为4×4:
- 第1次池化:32×32 → 16×16
- 第2次池化:16×16 → 8×8
- 第3次池化:8×8 → 4×4
4.3.3 全连接层:从特征到分类的映射
nn.Linear(128 * 4 * 4, 512) # 输入维度2048,输出维度512
数学原理与推导:
全连接层实现了线性变换,将卷积层提取的特征映射到类别空间。
线性变换公式:
y
=
W
x
+
b
y = Wx + b
y=Wx+b
其中:
-
x
x
x:输入向量,维度为128
∗
4
∗
4
=
2048
128*4*4=2048
128∗4∗4=2048 -
W
W
W:权重矩阵,维度为512
×
2048
512×2048
512×2048 -
b
b
b:偏置向量,维度为512
512
512 -
y
y
y:输出向量,维度为512
512
512
参数数量计算:
P
a
r
a
m
e
t
e
r
s
=
(
I
n
p
u
t
_
d
i
m
∗
O
u
t
p
u
t
_
d
i
m
)
+
O
u
t
p
u
t
_
d
i
m
Parameters = (Input\\_dim * Output\\_dim) + Output\\_dim
Parameters=(Input_dim∗Output_dim)+Output_dim
对于第一个全连接层:
P
a
r
a
m
e
t
e
r
s
=
(
2048
∗
512
)
+
512
=
1
,
049
,
088
Parameters = (2048 * 512) + 512 = 1,049,088
Parameters=(2048∗512)+512=1,049,088
代码设计思路:
- 逐步减少维度:2048 → 512 → 256 → 128 → 10,形成"漏斗"形状
- 深度结构:多层全连接层能够学习更复杂的非线性映射
- 维度匹配:确保卷积层输出的特征图展平后与全连接层输入维度一致
4. 激活函数:
nn.ReLU() # ReLU激活函数
数学原理与推导:
激活函数引入非线性,使网络能够学习复杂的非线性函数。
ReLU函数公式:
f
(
z
)
=
m
a
x
(
0
,
z
)
f(z) = max(0, z)
f(z)=max(0,z)
导数:
f
′
(
z
)
=
{
1
,
z
>
0
0
,
z
≤
0
f'(z) = \\begin{cases} 1, & z > 0 \\\\ 0, & z \\leq 0 \\end{cases}
f′(z)={1,0,z>0z≤0
代码设计思路:
- 选择ReLU:解决了sigmoid和tanh的梯度消失问题,计算效率高
- 每一层后使用:在卷积层和全连接层后都使用ReLU,引入非线性
- 避免死亡神经元:通过合理的权重初始化(如He初始化)减少ReLU神经元死亡的概率
与项目的结合:
在本项目中,ReLU激活函数应用于:
- 每个卷积层之后
- 每个全连接层之后(除了输出层)
4.3.5 损失与优化:模型学习的核心机制
criterion = nn.CrossEntropyLoss() # 交叉熵损失
optimizer = optim.Adam(model.parameters(), lr=1e-3) # Adam优化器
交叉熵损失的数学推导:
对于多分类问题,假设模型输出为
z
1
,
z
2
,
.
.
.
,
z
C
z_1, z_2, …, z_C
z1,z2,…,zC(
C
C
C为类别数),首先使用softmax函数将其转换为概率:
y
^
i
=
s
o
f
t
m
a
x
(
z
i
)
=
e
z
i
∑
j
=
1
C
e
z
j
\\hat{y}_i = softmax(z_i) = \\frac{e^{z_i}}{\\sum_{j=1}^{C} e^{z_j}}
y^i=softmax(zi)=∑j=1Cezjezi
交叉熵损失定义为:
L
=
−
∑
i
=
1
C
y
i
log
(
y
^
i
)
L = -\\sum_{i=1}^{C} y_i \\log(\\hat{y}_i)
L=−i=1∑Cyilog(y^i)
其中
y
i
y_i
yi是真实标签的独热编码(本项目中CIFAR10的C=10)。
PyTorch中的nn.CrossEntropyLoss实际上结合了softmax和交叉熵损失,直接接受模型的原始输出。
Adam优化器的原理:
Adam优化器结合了动量法和RMSProp的优点,使用自适应学习率:
计算梯度的一阶矩估计(动量):
m
t
=
β
1
m
t
−
1
+
(
1
−
β
1
)
g
t
m_t = \\beta_1 m_{t-1} + (1 – \\beta_1) g_t
mt=β1mt−1+(1−β1)gt
计算梯度的二阶矩估计(RMSProp):
v
t
=
β
2
v
t
−
1
+
(
1
−
β
2
)
g
t
2
v_t = \\beta_2 v_{t-1} + (1 – \\beta_2) g_t^2
vt=β2vt−1+(1−β2)gt2
偏差修正:
m
^
t
=
m
t
1
−
β
1
t
\\hat{m}_t = \\frac{m_t}{1 – \\beta_1^t}
m^t=1−β1tmt
v
^
t
=
v
t
1
−
β
2
t
\\hat{v}_t = \\frac{v_t}{1 – \\beta_2^t}
v^t=1−β2tvt
参数更新:
w
t
=
w
t
−
1
−
η
m
^
t
v
^
t
+
ϵ
w_t = w_{t-1} – \\eta \\frac{\\hat{m}_t}{\\sqrt{\\hat{v}_t} + \\epsilon}
wt=wt−1−ηv^t
+ϵm^t
其中:
-
β
1
=
0.9
\\beta_1=0.9
β1=0.9,β
2
=
0.999
\\beta_2=0.999
β2=0.999,ϵ
=
1
e
−
8
\\epsilon=1e-8
ϵ=1e−8(PyTorch默认值) -
η
=
1
e
−
3
\\eta=1e-3
η=1e−3(学习率,本项目选择)
代码设计思路:
- 交叉熵损失:适合分类任务,对错误分类的惩罚更重
- Adam优化器:自适应学习率,训练稳定性好,收敛速度快
- 学习率1e-3:常用的初始学习率,平衡了收敛速度和稳定性
4.3.6 Dropout:防止过拟合的正则化技术
nn.Dropout(0.2) # Dropout率为0.2
数学原理与推导:
Dropout是一种正则化技术,用于防止过拟合,在训练过程中随机将部分神经元的输出置为0:
y
i
=
{
0
,
with probability
p
x
i
1
−
p
,
otherwise
y_i = \\begin{cases} 0, & \\text{with probability } p \\\\ \\frac{x_i}{1-p}, & \\text{otherwise} \\end{cases}
yi={0,1−pxi,with probability potherwise
其中
p
=
0.2
p=0.2
p=0.2是dropout率。
代码设计思路:
- dropout率0.2:较小的dropout率,在防止过拟合的同时保留大部分信息
- 全连接层后使用:全连接层参数多,容易过拟合,是dropout的主要应用位置
- 测试时不使用:PyTorch的model.eval()会自动关闭dropout
与项目的结合:
在本项目中,dropout层应用于:
- 512→256全连接层之后
- 256→128全连接层之后
- 128→10全连接层之后(输出层之前)
五、项目使用指南
5.1 环境搭建
安装必要的依赖:
pip install torch torchvision matplotlib seaborn scikit-learn tqdm
确保有足够的计算资源(GPU推荐)
5.2 数据准备
5.3 运行代码
直接运行主程序:
python CNN_DNN.py
代码执行流程:
- 加载并预处理数据
- 初始化模型
- 训练模型(10轮)
- 绘制训练损失曲线
- 测试模型
- 生成混淆矩阵
- 展示错误分类和正确分类的样本
- 展示预测概率分布
5.4 结果查看
终端输出:
- 训练过程中的损失信息
- 测试准确率
生成的可视化文件:
- training_loss_curve.png:训练损失曲线
- confusion_matrix.png:混淆矩阵
- misclassified_samples.png:错误分类样本
- correctly_classified_samples.png:正确分类样本
- prediction_probabilities.png:预测概率分布
5.5 参数调整
6. 运行效果
🚀 开始训练模型…
✅ Epoch [1/50] 完成 | 本轮平均损失: 1.7453 | 训练准确率: 47.41% | 验证准确率: 48.15%
💾 验证准确率提升至 48.15%,已保存最佳模型到 best_model.pth
( 此 处 省 略 一 部 分 )
✅ Epoch [35/50] 完成 | 本轮平均损失: 0.5103 | 训练准确率: 84.67% | 验证准确率: 81.49%
✅ Epoch [36/50] 完成 | 本轮平均损失: 0.5094 | 训练准确率: 84.18% | 验证准确率: 81.59%
💾 验证准确率提升至 81.59%,已保存最佳模型到 best_model.pth
✅ Epoch [37/50] 完成 | 本轮平均损失: 0.5086 | 训练准确率: 85.60% | 验证准确率: 81.82%
💾 验证准确率提升至 81.82%,已保存最佳模型到 best_model.pth
✅ Epoch [38/50] 完成 | 本轮平均损失: 0.5008 | 训练准确率: 86.28% | 验证准确率: 82.10%
💾 验证准确率提升至 82.10%,已保存最佳模型到 best_model.pth
✅ Epoch [39/50] 完成 | 本轮平均损失: 0.4955 | 训练准确率: 84.67% | 验证准确率: 81.71%
✅ Epoch [40/50] 完成 | 本轮平均损失: 0.5008 | 训练准确率: 85.01% | 验证准确率: 82.41%
💾 验证准确率提升至 82.41%,已保存最佳模型到 best_model.pth
✅ Epoch [41/50] 完成 | 本轮平均损失: 0.4960 | 训练准确率: 84.86% | 验证准确率: 81.71%
✅ Epoch [42/50] 完成 | 本轮平均损失: 0.4955 | 训练准确率: 86.08% | 验证准确率: 81.99%
✅ Epoch [43/50] 完成 | 本轮平均损失: 0.4778 | 训练准确率: 85.60% | 验证准确率: 80.98%
✅ Epoch [44/50] 完成 | 本轮平均损失: 0.4862 | 训练准确率: 85.60% | 验证准确率: 82.59%
💾 验证准确率提升至 82.59%,已保存最佳模型到 best_model.pth
✅ Epoch [45/50] 完成 | 本轮平均损失: 0.4764 | 训练准确率: 85.45% | 验证准确率: 82.34%
✅ Epoch [46/50] 完成 | 本轮平均损失: 0.4776 | 训练准确率: 84.77% | 验证准确率: 81.36%
✅ Epoch [47/50] 完成 | 本轮平均损失: 0.4796 | 训练准确率: 84.18% | 验证准确率: 81.78%
✅ Epoch [48/50] 完成 | 本轮平均损失: 0.4672 | 训练准确率: 86.23% | 验证准确率: 82.07%
✅ Epoch [49/50] 完成 | 本轮平均损失: 0.4719 | 训练准确率: 85.84% | 验证准确率: 82.10%
✅ Epoch [50/50] 完成 | 本轮平均损失: 0.4669 | 训练准确率: 86.28% | 验证准确率: 82.79%
💾 验证准确率提升至 82.79%,已保存最佳模型到 best_model.pth
🎉 所有训练轮数完成!
🏆 最佳验证准确率: 82.79%
📁 最佳模型已保存到: best_model.pth
📈 绘制训练损失曲线…
✅ 训练损失曲线已保存并显示
📊 绘制准确率对比曲线…
✅ 训练和验证准确率对比已保存并显示
🧪 测试模型性能…
📊 测试集准确率: 82.29%
🔍 生成混淆矩阵…
✅ 混淆矩阵已保存并显示
❌ 展示错误分类样本…
✅ 错误分类样本已保存并显示
✅ 展示正确分类样本…
✅ 正确分类样本已保存并显示
📊 展示预测概率分布…
✅ 预测概率分布已保存并显示
7. 项目源码
https://download.csdn.net/download/qq_68716132/92561378?spm=1001.2014.3001.5501
8. 总结
- 总训练轮数: 50
- 最终训练损失: 0.4669
- 最终训练准确率: 86.28%
- 最终验证准确率: 82.79%
- 最佳验证准确率: 82.79%
本项目结合了CNN和DNN的优势,利用CNN提取图像的局部特征,再通过DNN进行分类。这种架构在图像分类任务中表现出色,特别是对于CIFAR10这样的小型图像数据集。通过详细的注释和可视化功能,项目代码具有良好的可读性和可维护性,适合作为深度学习初学者的学习示例。


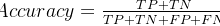



评论前必须登录!
注册