 网硕互联帮助中心
网硕互联帮助中心引言
大家好。最近在项目中使用YOLOv11进行实例分割任务,代码主要用于批量处理图像目录中的图片,进行模型推理、掩码提取和结果保存。原代码有一些条件判断,用于过滤保存掩码坐标,但实际使用中发现可以进一步简化,以提高代码的通用性和效率。
本文记录了代码的修改过程,包括修改前后的对比、修改原因和实际效果。如果您也在使用YOLOv11或类似模型,这篇文章可能会对您有所帮助。代码基于OpenCV和C++实现,模型文件为ONNX格式。
修改背景
原代码的功能:
- 从指定目录加载图像。
- 使用YOLOv11模型进行实例分割(segmentation)。
- 测量纯推理时间,并记录到文件中。
- 对于每个检测到的对象,如果满足一定条件(例如置信度>0.5且掩码非空),提取掩码坐标并可选保存到TXT文件(代码中已注释)。
- 绘制分割结果并保存图像。
- 计算平均推理时间。
修改点主要集中在掩码保存的条件判断上:原代码有额外的置信度过滤(seg.conf > 0.5),但在我的场景中,所有非空掩码都需要处理,因此简化了这一部分。
修改前代码
修改前的关键部分(遍历检测结果的循环):
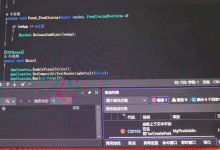
// 遍历每个检测结果(这部分不计时)
for (size_t i = 0; i < results.size(); ++i) {
const auto& seg = results[i];
std::cout << \”类别 ID: \” << seg.classId << \”, 置信度: \” << seg.conf << std::endl;
std::cout << \”边界框: (\” << seg.box.x << \”, \” << seg.box.y << \”)\”



评论前必须登录!
注册