 网硕互联帮助中心
网硕互联帮助中心BEVFormer: Learning Bird’s-Eye-ViewRepresentation from Multi-Camera Images via Spatiotemporal Transformers|Temporal Self-Attention、Spatial Cross-Attention注意力机制详解
BEVFormer(Bird’s-Eye-View Former)是一种先进的计算机视觉模型,旨在从多摄像头图像序列中生成鸟瞰图(BEV)表示。它通过时空变换器融合多视角和时间信息,实现高效的3D场景理解。广泛应用于自动驾驶等领域。以下从模型结构、创新点、训练方法和模型实验四个方面进行详细总结。
一. 模型结构
BEVFormer的整体架构分为输入层、特征提取层、时空变换器层和输出层,处理多摄像头图像序列(如6个摄像头)以生成BEV特征图。
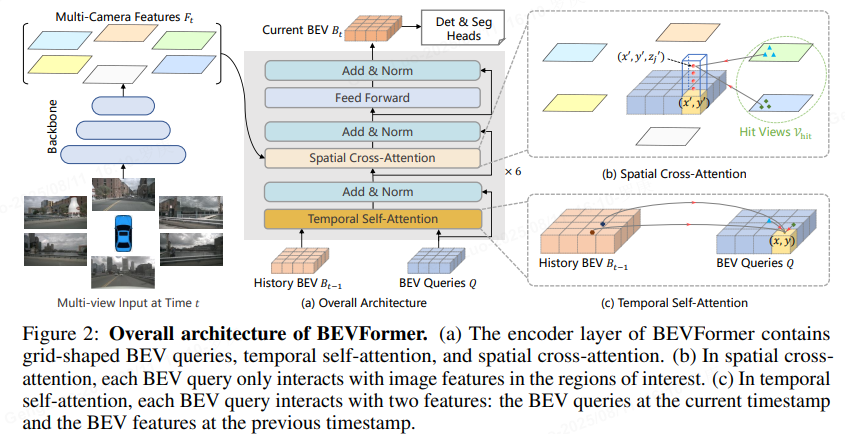
- 输入层:输入为多摄像头图像序列,记为I={Itc∣c∈{1,2,…,C},t∈{1,2,…,T}}I = \\{I_t^c | c \\in \\{1, 2, \\dots, C\\}, t \\in \\{1, 2, \\dots, T\\}\\}I={Itc∣c∈{1,2,…,C},t∈{1,2,…,T}},其中CCC是摄像头数量,TTT是时间步长。例如,在nuScenes数据集中,C=6C=6C=6,TTT通常取3-5帧。
- 特征提取层:使用卷积神经网络(CNN)backbone(如ResNet或EfficientNet)提取每帧图像的2D特征。特征图记为F2DcF_{2D}^cF2Dc,维度为H×W×DH \\times W \\times DH×W×D,其中DDD是特征维度。
- 时空变换器层:这是核心模块,包括空间交叉注意力和时间自注意力机制。空间交叉注意力融合多摄像头视角,时间自注意力建模时间依赖性。公式如下:
- 空间交叉注意力:对于每个BEV网格点qqq,查询所有摄像头特征:
Attention(Q,K,V)=softmax(QKTdk)V
\\text{Attention}(Q, K, V) = \\text{softmax}\\left(\\frac{QK^T}{\\sqrt{d_k}}\\right)V
Attention(Q,K,V)=softmax(dkQKT)V
其中QQQ是BEV查询,KKK和VVV是2D特征图的键和值。 - 时间自注意力:在时间维度上聚合信息:
Attention(Qt,Kt−1,Vt−1)=softmax(QtKt−1Tdk)Vt−1
\\text{Attention}(Q_t, K_{t-1}, V_{t-1}) = \\text{softmax}\\left(\\frac{Q_t K_{t-1}^T}{\\sqrt{d_k}}\\right)V_{t-1}
Attention(Qt,Kt−1,Vt−1)=softmax(dkQtKt−1T)Vt−1
这允许模型从历史帧中学习运动信息。
- 空间交叉注意力:对于每个BEV网格点qqq,查询所有摄像头特征:
- 输出层:生成BEV特征图FbevF_{bev}Fbev,维度为Hbev×Wbev×DbevH_{bev} \\times W_{bev} \\times D_{bev}Hbev×Wbev×Dbev。该特征图可直接用于下游任务,如3D目标检测或分割。
整个模型是端到端的,输入图像序列,输出BEV表示,中间通过多层变换器堆叠实现高效融合。
二. 创新点详解:Temporal Self-Attention 与 Spatial Cross-Attention 注意力机制
注意力机制是深度学习中处理序列数据的关键技术,通过计算输入元素之间的相关性权重,实现动态特征聚焦。逐步解释 Temporal Self-Attention 和 Spatial Cross-Attention 的原理、数学表达和应用场景。
1) 注意力机制基础
注意力机制的核心是计算查询(Query)、键(Key)和值(Value)之间的相似度,生成加权输出。通用公式为:
Attention(Q,K,V)=softmax(QKTdk)V
\\text{Attention}(Q, K, V) = \\text{softmax}\\left(\\frac{QK^T}{\\sqrt{d_k}}\\right)V
Attention(Q,K,V)=softmax(dkQKT)V
其中:
- Q∈Rn×dkQ \\in \\mathbb{R}^{n \\times d_k}Q∈Rn×dk 是查询矩阵。
- K∈Rm×dkK \\in \\mathbb{R}^{m \\times d_k}K∈Rm×dk 是键矩阵。
- V∈Rm×dvV \\in \\mathbb{R}^{m \\times d_v}V∈Rm×dv 是值矩阵。
- dkd_kdk 是键的维度,用于缩放点积防止梯度爆炸。
- softmax\\text{softmax}softmax 函数确保权重和为 1。
Temporal Self-Attention 和 Spatial Cross-Attention 是该机制的变体,分别针对时间和空间维度优化。
2) Temporal Self-Attention 详解
定义:Temporal Self-Attention 是一种自注意力机制,专注于时间序列数据(如视频帧、传感器读数)。它在同一序列的时间步之间计算注意力,捕捉长期依赖关系,忽略空间位置信息。
数学原理:
- 输入序列:X∈RT×dX \\in \\mathbb{R}^{T \\times d}X∈RT×d,其中 TTT 为时间步数,ddd 为特征维度。
- 通过可学习权重矩阵生成 Q,K,VQ, K, VQ,K,V:
Q=XWQ,K=XWK,V=XWV
Q = X W^Q, \\quad K = X W^K, \\quad V = X W^V
Q=XWQ,K=XWK,V=XWV
其中 WQ,WK∈Rd×dkW^Q, W^K \\in \\mathbb{R}^{d \\times d_k}WQ,WK∈Rd×dk, WV∈Rd×dvW^V \\in \\mathbb{R}^{d \\times d_v}WV∈Rd×dv。 - 注意力计算:
Attention(Q,K,V)=softmax(QKTdk)V
\\text{Attention}(Q, K, V) = \\text{softmax}\\left(\\frac{QK^T}{\\sqrt{d_k}}\\right)V
Attention(Q,K,V)=softmax(dkQKT)V
输出 O∈RT×dvO \\in \\mathbb{R}^{T \\times d_v}O∈RT×dv,每个时间步的值为其他时间步的加权和。 - 示例:对于时间步 ttt,输出 oto_tot 计算为:
ot=∑j=1Tαtjvj,αtj=exp(qt⋅kjdk)∑k=1Texp(qt⋅kkdk)
o_t = \\sum_{j=1}^{T} \\alpha_{tj} v_j, \\quad \\alpha_{tj} = \\frac{\\exp\\left(\\frac{q_t \\cdot k_j}{\\sqrt{d_k}}\\right)}{\\sum_{k=1}^{T} \\exp\\left(\\frac{q_t \\cdot k_k}{\\sqrt{d_k}}\\right)}
ot=j=1∑Tαtjvj,αtj=∑k=1Texp(dkqt⋅kk)exp(dkqt⋅kj)
其中 αtj\\alpha_{tj}αtj 是时间步 ttt 对 jjj 的注意力权重,qtq_tqt 和 kjk_jkj 是 QQQ 和 KKK 的行向量。
特点:
- 优点:高效处理长序列,捕捉时间动态(如视频中的运动模式)。
- 缺点:计算复杂度为 O(T2)O(T^2)O(T2),对长序列可能昂贵。
- 应用场景:视频动作识别(分析帧间关系)、时间序列预测(如股票数据)、语音处理(建模音频时序)。
简单代码示例(Python):
以下是一个简化实现,展示 Temporal Self-Attention 的核心逻辑:
import torch
import torch.nn.functional as F
def temporal_self_attention(X):
# X: 输入序列, shape [batch_size, T, d]
d_k = X.size(–1) # 键维度
Q = torch.matmul(X, W_Q) # W_Q 是可学习权重
K = torch.matmul(X, W_K)
V = torch.matmul(X, W_V)
# 计算注意力分数
scores = torch.matmul(Q, K.transpose(–2, –1)) / (d_k ** 0.5)
attn_weights = F.softmax(scores, dim=–1)
# 加权输出
output = torch.matmul(attn_weights, V)
return output
# 示例使用
batch_size, T, d = 2, 10, 64 # 批大小、时间步、特征维度
X = torch.randn(batch_size, T, d)
W_Q = torch.randn(d, d)
W_K = torch.randn(d, d)
W_V = torch.randn(d, d)
output = temporal_self_attention(X)
print(output.shape) # 输出: torch.Size([2, 10, 64])
3) Spatial Cross-Attention 详解
定义:Spatial Cross-Attention 是一种交叉注意力机制,专注于空间数据(如图像、特征图)。它在不同序列的空间位置之间计算注意力,例如查询序列来自一个模态(如文本),键值序列来自另一个模态(如图像),实现跨模态信息融合。
数学原理:
- 输入:两个独立序列,查询序列 Qseq∈RN×dqQ_{\\text{seq}} \\in \\mathbb{R}^{N \\times d_q}Qseq∈RN×dq 和键值序列 KVseq∈RM×dkvKV_{\\text{seq}} \\in \\mathbb{R}^{M \\times d_{kv}}KVseq∈RM×dkv,其中 NNN 和 MMM 为空间位置数(如图像像素或区域)。
- 生成 Q,K,VQ, K, VQ,K,V:
Q=QseqWQ,K=KVseqWK,V=KVseqWV
Q = Q_{\\text{seq}} W^Q, \\quad K = KV_{\\text{seq}} W^K, \\quad V = KV_{\\text{seq}} W^V
Q=QseqWQ,K=KVseqWK,V=KVseqWV
其中 WQ∈Rdq×dkW^Q \\in \\mathbb{R}^{d_q \\times d_k}WQ∈Rdq×dk, WK,WV∈Rdkv×dkW^K, W^V \\in \\mathbb{R}^{d_{kv} \\times d_k}WK,WV∈Rdkv×dk。 - 注意力计算:
Attention(Q,K,V)=softmax(QKTdk)V
\\text{Attention}(Q, K, V) = \\text{softmax}\\left(\\frac{QK^T}{\\sqrt{d_k}}\\right)V
Attention(Q,K,V)=softmax(dkQKT)V
输出 O∈RN×dvO \\in \\mathbb{R}^{N \\times d_v}O∈RN×dv,每个查询位置的值是键值序列位置的加权和。 - 示例:对于查询位置 iii,输出 oio_ioi 计算为:
oi=∑j=1Mβijvj,βij=exp(qi⋅kjdk)∑k=1Mexp(qi⋅kkdk)
o_i = \\sum_{j=1}^{M} \\beta_{ij} v_j, \\quad \\beta_{ij} = \\frac{\\exp\\left(\\frac{q_i \\cdot k_j}{\\sqrt{d_k}}\\right)}{\\sum_{k=1}^{M} \\exp\\left(\\frac{q_i \\cdot k_k}{\\sqrt{d_k}}\\right)}
oi=j=1∑Mβijvj,βij=∑k=1Mexp(dkqi⋅kk)exp(dkqi⋅kj)
其中 βij\\beta_{ij}βij 是查询位置 iii 对键值位置 jjj 的注意力权重。
特点:
- 优点:支持异构数据交互,增强空间上下文理解(如物体定位)。
- 缺点:需对齐不同序列的空间维度,计算复杂度 O(N×M)O(N \\times M)O(N×M)。
- 应用场景:视觉问答(文本查询关注图像区域)、图像生成(草图到照片的转换)、多模态融合(视频和音频的空间对齐)。
简单代码示例(Python):
以下是一个简化实现,展示 Spatial Cross-Attention 的核心逻辑:
import torch
import torch.nn.functional as F
def spatial_cross_attention(query_seq, kv_seq):
# query_seq: 查询序列, shape [batch_size, N, d_q]
# kv_seq: 键值序列, shape [batch_size, M, d_kv]
d_k = query_seq.size(–1) # 键维度
Q = torch.matmul(query_seq, W_Q) # W_Q 是可学习权重
K = torch.matmul(kv_seq, W_K)
V = torch.matmul(kv_seq, W_V)
# 计算注意力分数
scores = torch.matmul(Q, K.transpose(–2, –1)) / (d_k ** 0.5)
attn_weights = F.softmax(scores, dim=–1)
# 加权输出
output = torch.matmul(attn_weights, V)
return output
# 示例使用
batch_size, N, M, d_q, d_kv = 2, 16, 32, 64, 128 # N: 查询位置数, M: 键值位置数
query_seq = torch.randn(batch_size, N, d_q)
kv_seq = torch.randn(batch_size, M, d_kv)
W_Q = torch.randn(d_q, d_k)
W_K = torch.randn(d_kv, d_k)
W_V = torch.randn(d_kv, d_k)
output = spatial_cross_attention(query_seq, kv_seq)
print(output.shape) # 输出: torch.Size([2, 16, d_k])
整体原版代码推理结构,将此2种结构重复叠加并执行6次进行encoder操作:
operation_order=(‘self_attn’, ‘norm’, ‘cross_attn’, ‘norm’, ‘ffn’, ‘norm’)
def attn_bev_encode(
self,
mlvl_feats,
bev_queries,
bev_h,
bev_w,
grid_length=[0.512, 0.512],
bev_pos=None,
prev_bev=None,
**kwargs):
bs = mlvl_feats[0].size(0)
bev_queries = bev_queries.unsqueeze(1).repeat(1, bs, 1)
bev_pos = bev_pos.flatten(2).permute(2, 0, 1)
#[4,256,3200]->[3200,4,256]
# obtain rotation angle and shift with ego motion
delta_x = np.array([each['can_bus'][0]
for each in kwargs['img_metas']])
delta_y = np.array([each['can_bus'][1]
for each in kwargs['img_metas']])
ego_angle = np.array(
[each['can_bus'][–2] / np.pi * 180 for each in kwargs['img_metas']])
grid_length_y = grid_length[0]
grid_length_x = grid_length[1]
translation_length = np.sqrt(delta_x ** 2 + delta_y ** 2)
translation_angle = np.arctan2(delta_y, delta_x) / np.pi * 180
bev_angle = ego_angle – translation_angle
shift_y = translation_length * \\
np.cos(bev_angle / 180 * np.pi) / grid_length_y / bev_h
shift_x = translation_length * \\
np.sin(bev_angle / 180 * np.pi) / grid_length_x / bev_w
shift_y = shift_y * self.use_shift
shift_x = shift_x * self.use_shift
shift = bev_queries.new_tensor(
[shift_x, shift_y]).permute(1, 0) # xy, bs -> bs, xy
# 通过`旋转`和`平移`变换实现 BEV 特征的对齐,对于平移部分是通过对参考点加上偏移量`shift`体现的
if prev_bev is not None:
if prev_bev.shape[1] == bev_h * bev_w:
prev_bev = prev_bev.permute(1, 0, 2)
if self.rotate_prev_bev:
for i in range(bs):
# num_prev_bev = prev_bev.size(1)
rotation_angle = kwargs['img_metas'][i]['can_bus'][–1]
tmp_prev_bev = prev_bev[:, i].reshape(
bev_h, bev_w, –1).permute(2, 0, 1)
tmp_prev_bev = rotate(tmp_prev_bev, rotation_angle,
center=self.rotate_center)
tmp_prev_bev = tmp_prev_bev.permute(1, 2, 0).reshape(
bev_h * bev_w, 1, –1)
prev_bev[:, i] = tmp_prev_bev[:, 0]
# add can bus signals
can_bus = bev_queries.new_tensor(
[each['can_bus'] for each in kwargs['img_metas']])
can_bus = self.can_bus_mlp(can_bus)[None, :, :] #编码为高维特征
bev_queries = bev_queries + can_bus * self.use_can_bus
feat_flatten = []
spatial_shapes = []
for lvl, feat in enumerate(mlvl_feats):
bs, num_cam, c, h, w = feat.shape
spatial_shape = (h, w)
feat = feat.flatten(3).permute(1, 0, 3, 2)
if self.use_cams_embeds:
feat = feat + self.cams_embeds[:, None, None, :].to(feat.dtype) #self.cams_embeds摄像头位置编码
feat = feat + self.level_embeds[None,
None, lvl:lvl + 1, :].to(feat.dtype)
spatial_shapes.append(spatial_shape)
feat_flatten.append(feat)
feat_flatten = torch.cat(feat_flatten, 2)
spatial_shapes = torch.as_tensor(
spatial_shapes, dtype=torch.long, device=bev_pos.device)
level_start_index = torch.cat((spatial_shapes.new_zeros(
(1,)), spatial_shapes.prod(1).cumsum(0)[:–1]))
feat_flatten = feat_flatten.permute(
0, 2, 1, 3) # (num_cam, H*W, bs, embed_dims)
ret_dict = self.encoder(
bev_queries,
feat_flatten,
feat_flatten,
mlvl_feats=mlvl_feats,
bev_h=bev_h,
bev_w=bev_w,
bev_pos=bev_pos,
spatial_shapes=spatial_shapes,
level_start_index=level_start_index,
prev_bev=prev_bev,
shift=shift,
**kwargs
)
return ret_dict
def forward(self,
query,
key=None,
value=None,
bev_pos=None,
query_pos=None,
key_pos=None,
attn_masks=None,
query_key_padding_mask=None,
key_padding_mask=None,
ref_2d=None,
ref_3d=None,
bev_h=None,
bev_w=None,
reference_points_cam=None,
mask=None,
spatial_shapes=None,
level_start_index=None,
prev_bev=None,
**kwargs):
"""Forward function for `TransformerDecoderLayer`.
**kwargs contains some specific arguments of attentions.
Args:
query (Tensor): The input query with shape
[num_queries, bs, embed_dims] if
self.batch_first is False, else
[bs, num_queries embed_dims].
key (Tensor): The key tensor with shape [num_keys, bs,
embed_dims] if self.batch_first is False, else
[bs, num_keys, embed_dims] .
value (Tensor): The value tensor with same shape as `key`.
query_pos (Tensor): The positional encoding for `query`.
Default: None.
key_pos (Tensor): The positional encoding for `key`.
Default: None.
attn_masks (List[Tensor] | None): 2D Tensor used in
calculation of corresponding attention. The length of
it should equal to the number of `attention` in
`operation_order`. Default: None.
query_key_padding_mask (Tensor): ByteTensor for `query`, with
shape [bs, num_queries]. Only used in `self_attn` layer.
Defaults to None.
key_padding_mask (Tensor): ByteTensor for `query`, with
shape [bs, num_keys]. Default: None.
Returns:
Tensor: forwarded results with shape [num_queries, bs, embed_dims].
"""
norm_index = 0
attn_index = 0
ffn_index = 0
identity = query
if attn_masks is None:
attn_masks = [None for _ in range(self.num_attn)]
elif isinstance(attn_masks, torch.Tensor):
attn_masks = [
copy.deepcopy(attn_masks) for _ in range(self.num_attn)
]
warnings.warn(f'Use same attn_mask in all attentions in '
f'{self.__class__.__name__} ')
else:
assert len(attn_masks) == self.num_attn, f'The length of ' \\
f'attn_masks {len(attn_masks)} must be equal ' \\
f'to the number of attention in ' \\
f'operation_order {self.num_attn}'
for layer in self.operation_order:
# temporal self attention
if layer == 'self_attn':
query = self.attentions[attn_index](
query,
prev_bev,
prev_bev,
identity if self.pre_norm else None,
query_pos=bev_pos,
key_pos=bev_pos,
attn_mask=attn_masks[attn_index],
key_padding_mask=query_key_padding_mask,
reference_points=ref_2d,
spatial_shapes=torch.tensor(
[[bev_h, bev_w]], device=query.device),
level_start_index=torch.tensor([0], device=query.device),
**kwargs)
attn_index += 1
identity = query
elif layer == 'norm':
query = self.norms[norm_index](query)
norm_index += 1
# spaital cross attention
elif layer == 'cross_attn':
query = self.attentions[attn_index](
query,
key,
value,
identity if self.pre_norm else None,
query_pos=query_pos,
key_pos=key_pos,
reference_points=ref_3d,
reference_points_cam=reference_points_cam,
mask=mask,
attn_mask=attn_masks[attn_index],
key_padding_mask=key_padding_mask,
spatial_shapes=spatial_shapes,
level_start_index=level_start_index,
**kwargs)
attn_index += 1
identity = query
elif layer == 'ffn':
query = self.ffns[ffn_index](
query, identity if self.pre_norm else None)
ffn_index += 1
return query
三. 训练方法
BEVFormer采用端到端监督学习,训练过程包括数据准备、损失函数和优化策略:
- 数据准备:使用大规模3D数据集(如nuScenes),数据集提供多摄像头图像序列和对应的3D标注(如边界框)。数据增强包括随机裁剪、旋转和颜色抖动,以提高鲁棒性。
- 损失函数:主要针对下游任务设计。例如,对于3D目标检测,采用多任务损失:
L=λclsLcls+λregLreg+λiouLiou
\\mathcal{L} = \\lambda_{cls} \\mathcal{L}_{cls} + \\lambda_{reg} \\mathcal{L}_{reg} + \\lambda_{iou} \\mathcal{L}_{iou}
L=λclsLcls+λregLreg+λiouLiou
其中Lcls\\mathcal{L}_{cls}Lcls是分类损失(如Focal Loss),Lreg\\mathcal{L}_{reg}Lreg是边界框回归损失(如Smooth L1),Liou\\mathcal{L}_{iou}Liou是IoU损失。权重λ\\lambdaλ通过网格搜索优化。 - 优化策略:使用AdamW优化器,学习率采用余弦衰减调度。初始学习率为10−410^{-4}10−4,批量大小设置为8-16(取决于GPU内存)。训练通常在100-200个epoch内收敛,使用预训练CNN backbone(如ImageNet权重)加速收敛。
- 实现细节:在PyTorch中实现,支持分布式训练。模型参数量约为50M,训练时需注意内存管理(如梯度累积)。
该方法确保了模型从原始图像中学习鲁棒的BEV表示,支持实时推理。
四. 模型实验
BEVFormer在标准数据集上进行了全面实验,验证其有效性:
-
数据集:主要在nuScenes数据集上评估,该数据集包含1000个驾驶场景,每个场景有6个摄像头和3D标注。
-
评估指标:核心指标包括:
- mAP(平均精度):用于3D目标检测,计算不同距离阈值下的平均精度。
- NDS(nuScenes Detection Score):综合指标,考虑mAP、位置误差和方向误差。
- 推理速度:FPS(帧每秒)评估实时性。
-
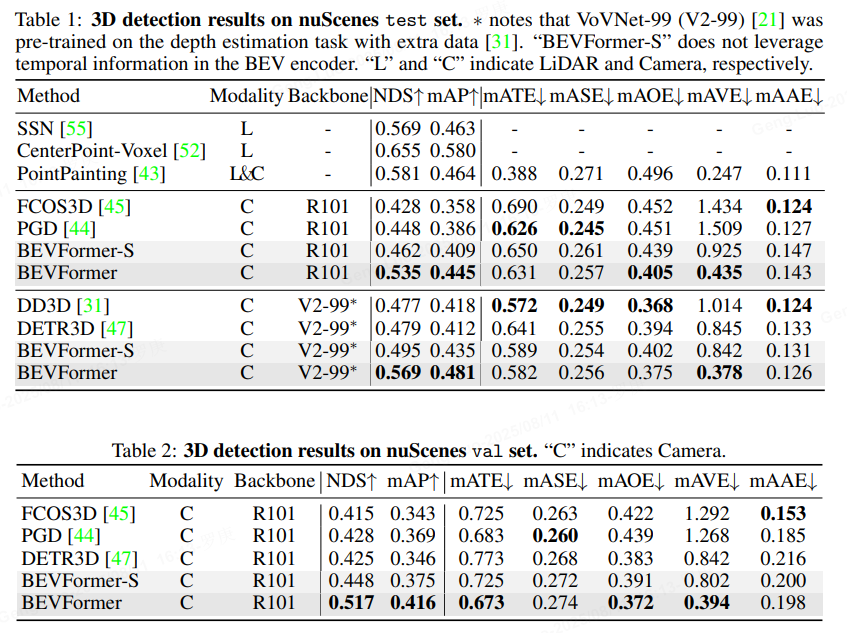
实验结果:
- BEVFormer在nuScenes测试集上达到SOTA(state-of-the-art)性能,例如mAP为48.1%,NDS为53.5%,显著优于基线模型(如LSS或DETR3D)。
- 消融实验证明:时空变换器贡献最大,mAP提升约8%;时间建模模块(T=3T=3T=3帧)比单帧提升5%。
- 效率方面:在NVIDIA V100 GPU上,推理速度达15 FPS,适合实时系统。
-
对比分析:与同类模型(如PolarFormer或PETR)相比,BEVFormer在复杂场景(如雨雾天气)下鲁棒性更强,归功于其时空融合设计。实验还扩展到其他任务(如BEV分割),性能一致优异。
总结
BEVFormer通过创新的时空变换器架构,高效地从多摄像头图像生成BEV表示,解决了自动驾驶中的3D感知挑战。其核心优势在于端到端学习、实时性和高精度。实验表明,它在nuScenes等基准上领先,为实际应用提供了可靠基础。未来工作可探索轻量化版本或扩展到更多传感器融合。








评论前必须登录!
注册