 网硕互联帮助中心
网硕互联帮助中心前言
本文对RL入门做一个串联,中间会穿插着各种关键结论和优化以及对应的细节文章,细节可以去对应的文章观看。
从RL基础理论 -> 策略梯度 -> REINFORCE -> RLOO/TRPO -> PPO -> GRPO
RL理论基础
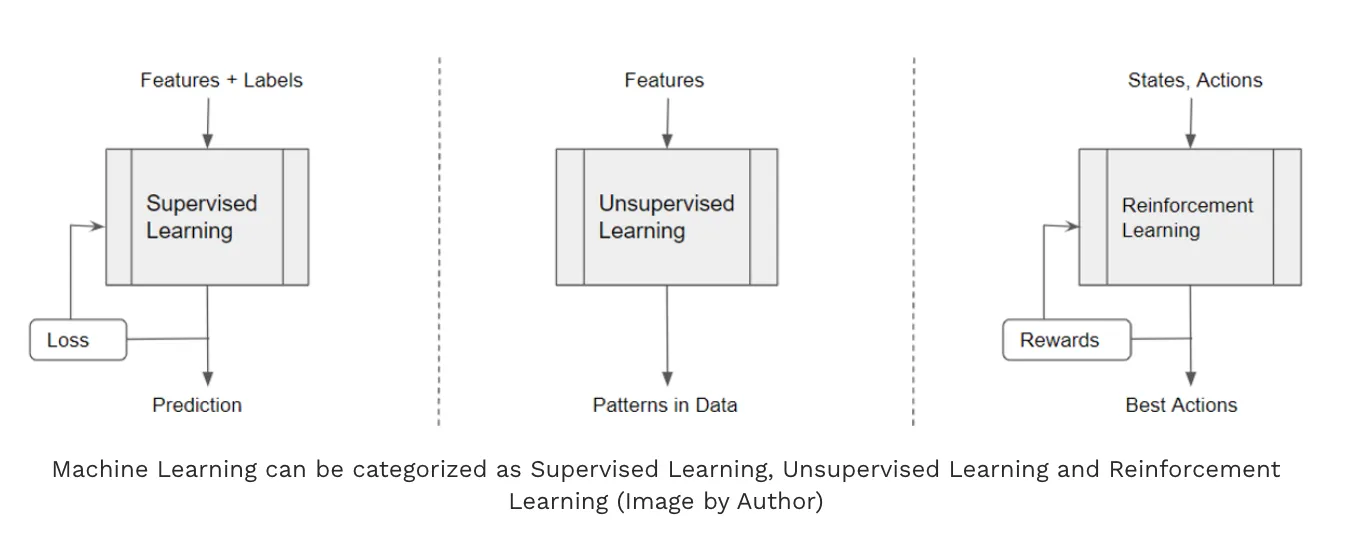
这些概念是要搞清楚的:
- 代理(Agent)
- 环境(Environment)
- 状态(state)
- 动作(action)
- 策略(policy)
- 轨迹(trajectory)
- 奖励(reward) 和 回报(Return)
- 状态价值函数(Value function)和 动作价值函数(Q-function)
- Value-based/Policy-based
细节请看:https://zhuanlan.zhihu.com/p/1929929237504198470
策略梯度
首先要明确RL的目标是什么, 目标就是去优化策略(π\\piπ),使得回报(Return)的期望最大:
J(θ)=Eτ∼πθ[R(τ)]J(\\theta) = \\mathbb{E}_{\\tau \\sim \\pi_\\theta} \\left[ R(\\tau) \\right]J(θ)=Eτ∼πθ[R(τ)]
这个期望是在整个轨迹τ\\tauτ上,轨迹τ\\tauτ指代一系列状态和动作,一个时间的序列:
τ=(s0,a0,s1,a1,… )\\tau = (s_0, a_0, s_1, a_1, \\dots)τ=(s0,a0,s1,a1,…)
策略梯度最终推导为:
∇θJ(θ)=Eτ∼πθ[∑t=0∞∇θlogπθ(at∣st)R(τ)]
\\nabla_\\theta J(\\theta) = \\mathbb{E}_{\\tau \\sim \\pi_\\theta} \\left[ \\sum_{t=0}^\\infty \\nabla_\\theta \\log \\pi_\\theta(a_t | s_t) R(\\tau) \\right]
∇θJ(θ)=Eτ∼πθ[t=0∑∞∇θlogπθ(at∣st)R(τ)]
细节看:
https://zhuanlan.zhihu.com/p/1932820715456931793
REINFORCE
利用蒙特卡罗方法,多次采样来近似期望,策略梯度可以近似的写成:
∇θJ(θ)≈1N∑i=1N∑t=0Ti−1∇θlogπθ(at(i)∣st(i))R(τ(i))
\\nabla_\\theta J(\\theta) \\approx \\frac{1}{N} \\sum_{i=1}^N \\sum_{t=0}^{T_i – 1} \\nabla_\\theta \\log \\pi_\\theta\\left(a_t^{(i)} \\mid s_t^{(i)}\\right) R\\left(\\tau^{(i)}\\right)
∇θJ(θ)≈N1i=1∑Nt=0∑Ti−1∇θlogπθ(at(i)∣st(i))R(τ(i))
其中:
- TiT_iTi 是第 iii 条轨迹 τ(i)\\tau^{(i)}τ(i) 的长度(因实际轨迹有限,求和到 Ti−1T_i – 1Ti−1);
- at(i)a_t^{(i)}at(i) 和 st(i)s_t^{(i)}st(i) 是第 iii 条轨迹中 ttt 时刻的动作与状态;
- R(τ(i))R\\left(\\tau^{(i)}\\right)R(τ(i)) 是第 iii 条轨迹的总奖励。
通过两个方法来降低训练方差大的问题:
把Q函数和Advantage引入,则策略梯度可以写为:
g^=1N∑i=1N∑t=0Ti−1∇θlogπθ(at(i)∣st(i))(Qπ(st(i),at(i))−Vπ(st(i)))
\\hat{g} = \\frac{1}{N} \\sum_{i=1}^N \\sum_{t=0}^{T_i – 1} \\nabla_\\theta \\log \\pi_\\theta\\left(a_t^{(i)} \\mid s_t^{(i)}\\right) \\left(Q_\\pi(s_t^{(i)}, a_t^{(i)})-V_\\pi(s_t^{(i)})\\right)
g^=N1i=1∑Nt=0∑Ti−1∇θlogπθ(at(i)∣st(i))(Qπ(st(i),at(i))−Vπ(st(i)))
其中Q-V则为advantage:
Aπ(s,a)=Qπ(s,a)−Vπ(s)
A_\\pi(s, a) = Q_\\pi(s, a) – V_\\pi(s)
Aπ(s,a)=Qπ(s,a)−Vπ(s)
详细看:
https://zhuanlan.zhihu.com/p/1932820715456931793
RLOO

提出了基于REINFORCE的RLOO强化学习算法(REINFORCE Leave-One-Out)
相比于REINFORCE,RLOO核心实现细节在于,它采用批次中其他样本的平均奖励来计算基线,而不是对批次中的所有奖励取平均值。
对于RLOO基线,给定 KKK 个采样轨迹或动作 a1,…,aKa_1, \\ldots, a_Ka1,…,aK,对于给定的提示 sss,每个提示的基线为:
b(s,ak)=1K−1∑i=1,i≠kKr(s,ai)
b(s, a_k) = \\frac{1}{K – 1} \\sum_{\\substack{i=1, i \\neq k}}^{K} r(s, a_i)
b(s,ak)=K−11i=1,i=k∑Kr(s,ai)
从而带来每个提示的优势:
A(s,ak)=r(s,ak)−b(s,ak)
A(s, a_k) = r(s, a_k) – b(s, a_k)
A(s,ak)=r(s,ak)−b(s,ak)
等效地,这可以表示为:
A(s,ak)=KK−1(r(s,ak)−1K∑i=1Kr(s,ai))
A(s, a_k) = \\frac{K}{K – 1} \\left( r(s, a_k) – \\frac{1}{K} \\sum_{i=1}^{K} r(s, a_i) \\right)
A(s,ak)=K−1K(r(s,ak)−K1i=1∑Kr(s,ai))
在RLOO中主要针对response-level的reward
详细看:
https://zhuanlan.zhihu.com/p/1932821169993675011
TRPO

策略梯度基本原理是利用梯度上升法朝着最大预期收益的方向优化。
然而,不合理的学习步长,会导致梯度上升法中的错误步骤可能导致次优操作,进而导致糟糕的状态。这反过来又会导致策略更新不佳和样本数据收集不佳。如此循环往复,最终可能导致策略性能崩溃,训练过程彻底失败。
需要了解:
通过KL散度限制以及重要性采样才优化。
最终的TRPO的优化等式为:
maximizeθ Es∼ρθoldEa∼πθold(a∣s)[πθ(a∣s)πθold(a∣s)Aθold(s,a)]subject to Es∼ρθold[DKL(πθold(⋅∣s)∥πθ(⋅∣s))]≤δ
\\begin{aligned}
&\\underset{\\theta}{\\text{maximize}}\\ \\mathbb{E}_{s\\sim\\rho_{\\theta_{\\text{old}}}}\\mathbb{E}_{a\\sim\\pi_{\\theta_{\\text{old}}}(a|s)}\\left[\\frac{\\pi_\\theta(a|s)}{\\pi_{\\theta_{\\text{old}}}(a|s)}A_{\\theta_{\\text{old}}}(s,a)\\right]\\\\
&\\text{subject to}\\ \\mathbb{E}_{s\\sim\\rho_{\\theta_{\\text{old}}}}\\left[D_{\\text{KL}}(\\pi_{\\theta_{\\text{old}}}(\\cdot|s)\\|\\pi_\\theta(\\cdot|s))\\right]\\leq\\delta
\\end{aligned}
θmaximize Es∼ρθoldEa∼πθold(a∣s)[πθold(a∣s)πθ(a∣s)Aθold(s,a)]subject to Es∼ρθold[DKL(πθold(⋅∣s)∥πθ(⋅∣s))]≤δ
详细看:
https://zhuanlan.zhihu.com/p/1934627686388588878
PPO
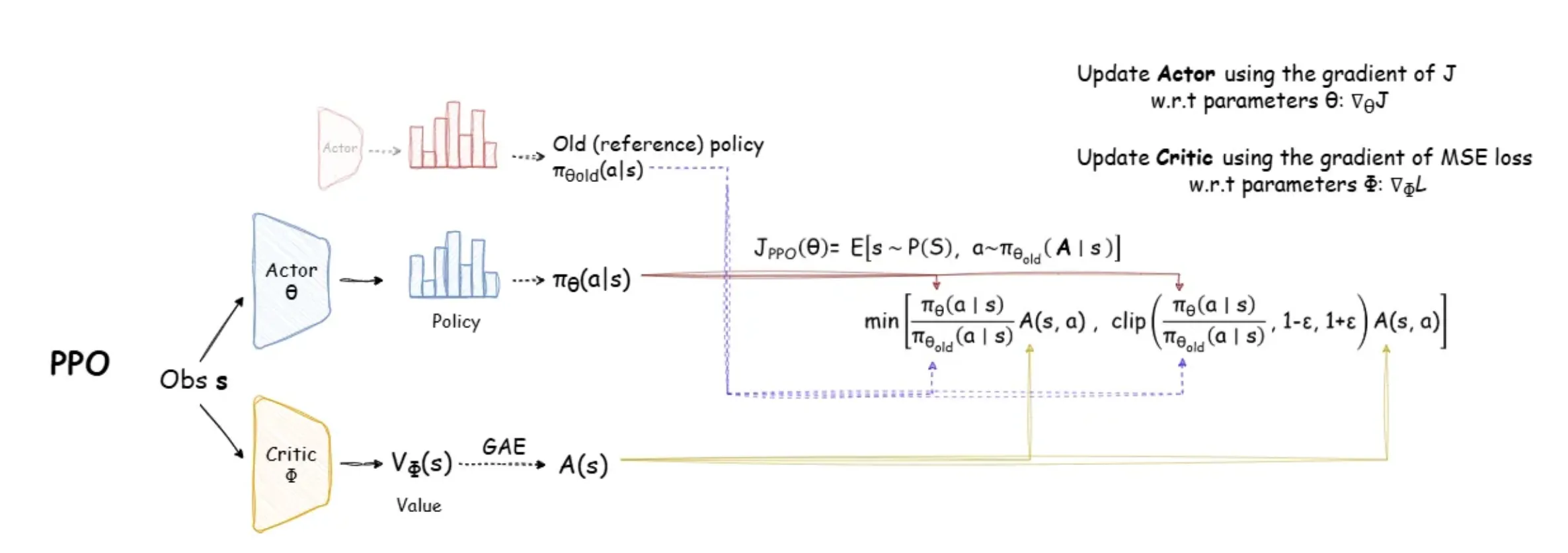
PPO基于GRPO继续优化。PPO方法实现要简单得多,且性能与TRPO相当。
有两种形式,其中效果更好的是Clip优化,
它依赖于目标函数中的专门Clip裁剪操作,以消除新策略远离旧策略的动机。
Lppo−clip(θ)=E^t[min(rt(θ)A^t,clip(rt(θ),1−ϵ,1+ϵ)A^t)]
L_{ppo-clip}(\\theta)=\\hat{\\mathbb{E}}_t\\left[\\min(r_t(\\theta)\\hat{A}_t,\\text{clip}(r_t(\\theta),1-\\epsilon,1+\\epsilon)\\hat{A}_t)\\right]
Lppo−clip(θ)=E^t[min(rt(θ)A^t,clip(rt(θ),1−ϵ,1+ϵ)A^t)]
其中rt(θ)r_t(\\theta)rt(θ)为重要性采样部分:
rt(θ)=πθ(at∣st)πθold(at∣st)
r_t(\\theta)=\\frac{\\pi_\\theta(a_t|s_t)}{\\pi_{\\theta_{\\text{old}}}(a_t|s_t)}
rt(θ)=πθold(at∣st)πθ(at∣st)
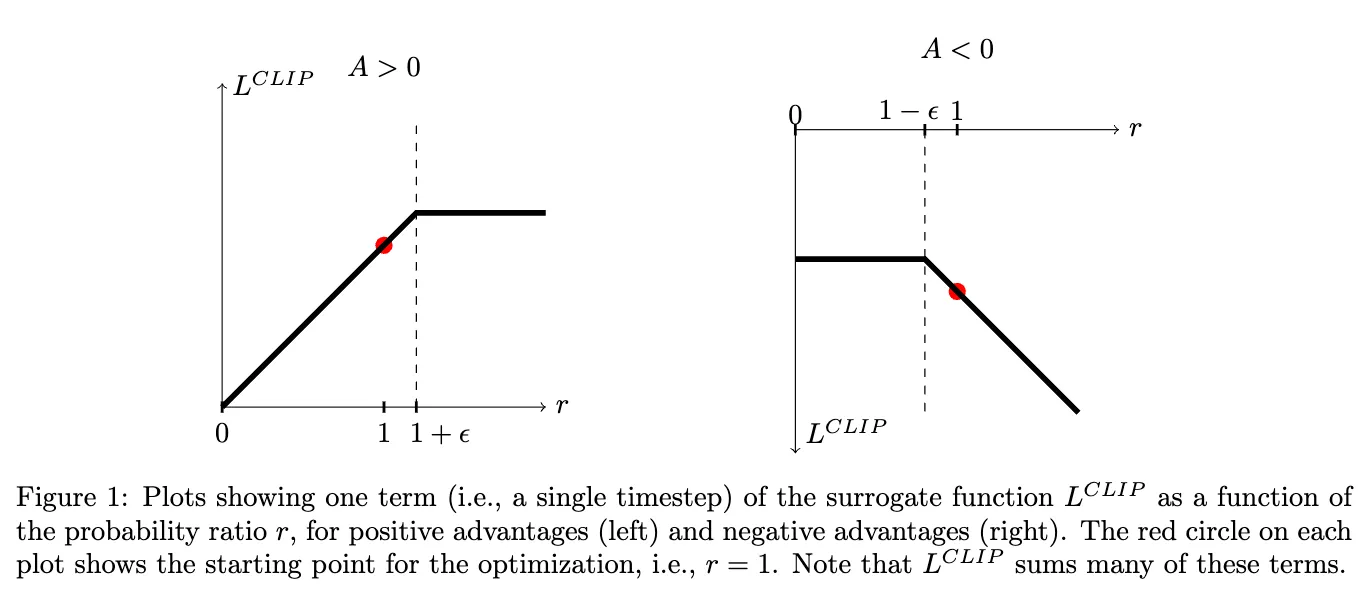
其中Advantage的估计采用了GAE方法进行估计,通过reward model的reward分数以及Value Model估计的期望回报计算残差进行估计。详细的GAE方法可见:https://zhuanlan.zhihu.com/p/1934626865701720143
PPO的公式和代码解读可以看:
https://zhuanlan.zhihu.com/p/1937882242291598044
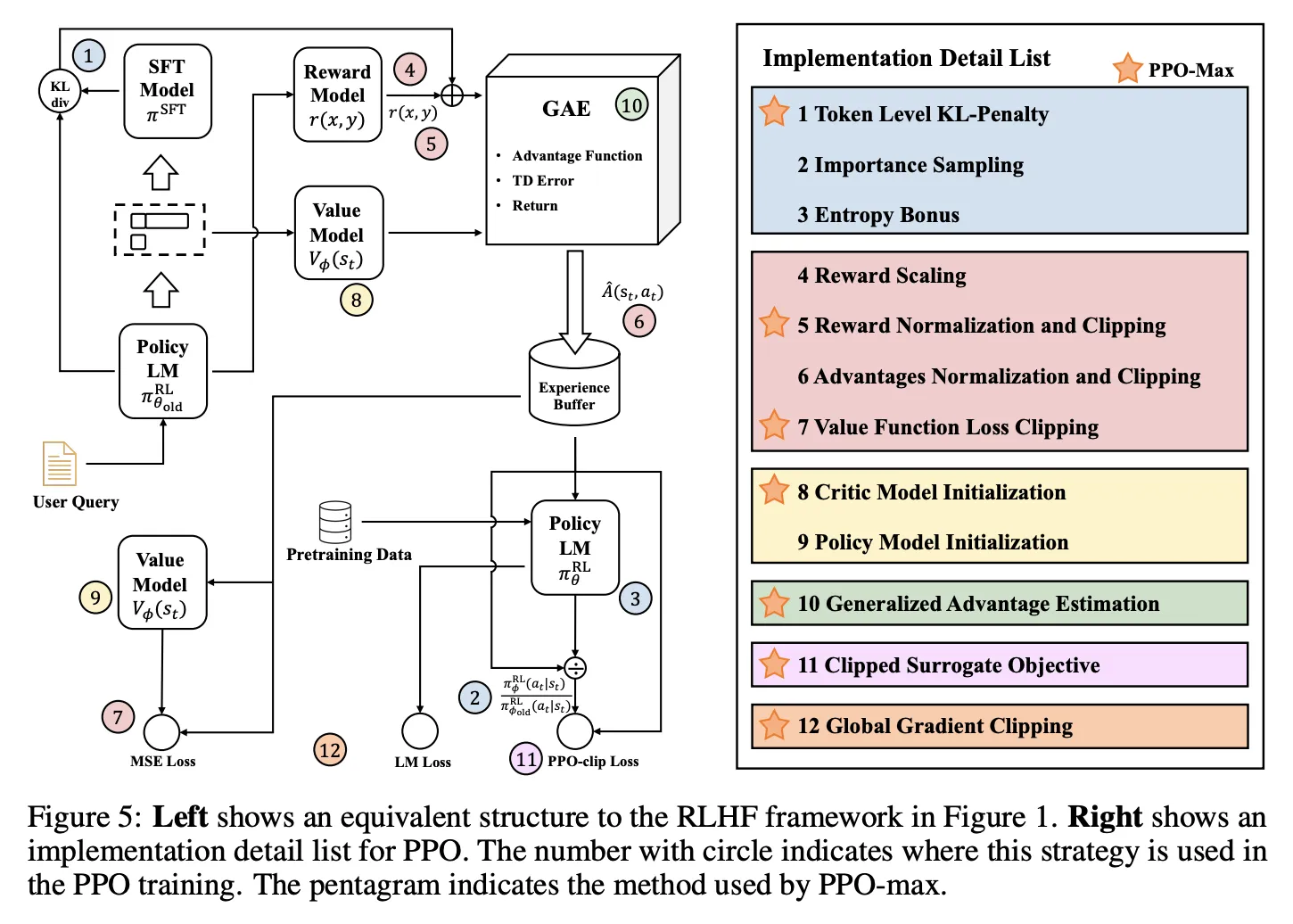
PPO训练的稳定技巧(参考:https://zhuanlan.zhihu.com/p/1937885098239325591):
GRPO
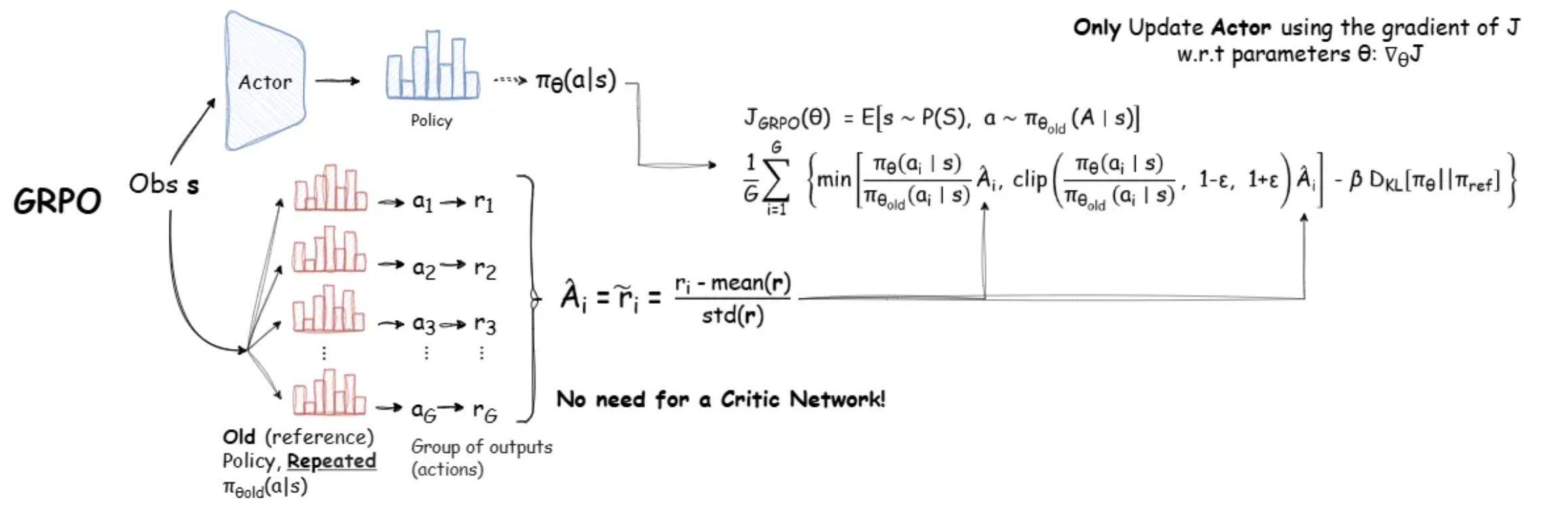
采样多个输出的平均reward作为baseline,而不用单独的Value Model去预测baseline,节省了Value Model,从而显著的减少了训练资源的使用。
作为基线,用于回答相同问题。对于每个问题 qqq,从旧策略πθold\\pi_{\\theta_{\\text{old}}}πθold 中采样一组输出 $ {o_1, o_2, \\cdots, o_G}$,然后通过最大化以下目标来优化策略模型:
JGRPO(θ)=E[q∼P(Q),{oi}i=1G∼πθold(O∣q)]1G∑i=1G1∣oi∣∑t=1∣oi∣{min[πθ(oi,t∣q,oi,<t)πθold(oi,t∣q,oi,<t)A^i,t,clip(πθ(oi,t∣q,oi,<t)πθold(oi,t∣q,oi,<t),1−ε,1+ε)A^i,t]−βDKL[πθ∥πref]}
\\begin{align*}
\\mathcal{J}_{\\text{GRPO}}(\\theta) &= \\mathbb{E} \\left[ q \\sim P(Q), \\{o_i\\}_{i=1}^G \\sim \\pi_{\\theta_{\\text{old}}}(O|q) \\right] \\\\
&\\quad \\frac{1}{G} \\sum_{i=1}^G \\frac{1}{|o_i|} \\sum_{t=1}^{|o_i|} \\left\\{ \\min \\left[ \\frac{\\pi_\\theta(o_{i,t}|q, o_{i, < t})}{\\pi_{\\theta_{\\text{old}}}(o_{i,t}|q, o_{i,< t})} \\hat{A}_{i,t}, \\text{clip} \\left( \\frac{\\pi_\\theta(o_{i,t}|q, o_{i,< t})}{\\pi_{\\theta_{\\text{old}}}(o_{i,t}|q, o_{i,< t})}, 1 – \\varepsilon, 1 + \\varepsilon \\right) \\hat{A}_{i,t} \\right] – \\beta \\mathbb{D}_{\\text{KL}} \\left[ \\pi_\\theta \\|\\pi_{\\text{ref}} \\right] \\right\\}
\\end{align*}
JGRPO(θ)=E[q∼P(Q),{oi}i=1G∼πθold(O∣q)]G1i=1∑G∣oi∣1t=1∑∣oi∣{min[πθold(oi,t∣q,oi,<t)πθ(oi,t∣q,oi,<t)A^i,t,clip(πθold(oi,t∣q,oi,<t)πθ(oi,t∣q,oi,<t),1−ε,1+ε)A^i,t]−βDKL[πθ∥πref]}
其中 $ \\varepsilon $ 和 $ \\beta $ 是超参数,$ \\hat{A}_{i,t} $ 是仅基于每组内部输出的相对奖励计算的优势。
GRPO使用无偏估计来估计 KL 散度:
DKL[πθ∥πref]=πref(oi,t∣q,oi,<t)πθ(oi,t∣q,oi,<t)−logπref(oi,t∣q,oi,<t)πθ(oi,t∣q,oi,<t)−1,
\\mathbb{D}_{KL} \\left[ \\pi_\\theta \\|\\pi_{\\text{ref}} \\right] = \\frac{\\pi_{\\text{ref}}(o_{i,t} \\mid q, o_{i,< t})}{\\pi_\\theta(o_{i,t} \\mid q, o_{i,< t})} – \\log \\frac{\\pi_{\\text{ref}}(o_{i,t} \\mid q, o_{i,< t})}{\\pi_\\theta(o_{i,t} \\mid q, o_{i,< t})} – 1,
DKL[πθ∥πref]=πθ(oi,t∣q,oi,<t)πref(oi,t∣q,oi,<t)−logπθ(oi,t∣q,oi,<t)πref(oi,t∣q,oi,<t)−1,
这个值一定为正。
解读参考: https://zhuanlan.zhihu.com/p/1938204409831069009









评论前必须登录!
注册