 网硕互联帮助中心
网硕互联帮助中心文章目录
- ADK基础调用流程
-
- 配置模型
- 定义一个极简Agent
- 创建Session
- 创建智能体执行器(Runner)
- 执行对话
- ADK项目主页
- ADK项目说明文档
import os
import asyncio
from google.adk.agents import Agent
from google.adk.models.lite_llm import LiteLlm
from google.adk.sessions import InMemorySessionService
from google.adk.runners import Runner
from google.genai import types
ADK基础调用流程
配置模型
- 作为工业级Agent开发框架,ADK的一个基本调用流程如下:
- 首先需要创建一个模型(ADK的模型调用适配器),需要采用ADK中封装的LiteLlm库来完成,需要注意的是,这个适配器负责配置好 model、认证、连接参数,然后统一管理模型调用接口。LiteLlm?
核心参数如下:
| model | str 字符串 | ✅ 必填 | 指定要调用的模型名称(例如 openai/gpt-4o, deepseek/deepseek-chat, ollama/qwen2.5) |
| llm_client | LiteLLMClient对象 | ❎ 可选 | 默认自动创建一个内部的客户端;高级用法允许你传自己定制的客户端(一般开发初期用不到) |
- 创建一个ADK能够识别的DeepSeek模型
from google.adk.models.lite_llm import LiteLlm
OPENAI_API_BASE="https://dashscope.aliyuncs.com/compatible-mode/v1"
OPENAI_API_KEY="sk-xxx"
MODEL="deepseek/deepseek-r1-0528"
model = LiteLlm(
model=MODEL,
api_base=OPENAI_API_BASE,
api_key=OPENAI_API_KEY
)
定义一个极简Agent
- 接下来创建一个Agent对象。和一般Multi Agent框架类似,ADK也是通过Agent类来创建一个个能够独立完成一些功能的代理,而在实际工作中,会通过创建多个代理来协同完成复杂任务。 Agent是 Google ADK 中管理LLM推理+工具使用+多Agent协作的标准组件,其功能概述如下:
- 封装一个模型(例如 LiteLlm 连接的模型)
- 定义这个Agent的指令说明(Instruction)
- 注册可以调用的工具(Tools)
- 支持子Agent管理(比如自己不能完成就转交子Agent)
- 支持调用前后回调(比如修改请求、监控日志)
- 支持输入输出Schema校验(结构化输入输出)
- 可以嵌套在更大系统中(比如成为子Agent)
Agent?
- 核心参数如下:
| name | str | Agent的名称,必须唯一 | 代理的名字(必填) |
| description | str | Agent的简短描述,通常在多Agent系统中用于路由/选择 | 代理的简短介绍 |
| parent_agent | BaseAgent or None | 父Agent(如果这个Agent是子代理的话) | 父代理,默认无 |
| sub_agents | list[BaseAgent] | 这个Agent下面挂载的子Agent们 | 子代理列表 |
| before_agent_callback | Callable or None | 在Agent处理输入前,进行预处理的回调 | 处理前的自定义函数 |
| after_agent_callback | Callable or None | 在Agent完成任务后,进行后处理的回调 | 处理后的自定义函数 |
| model | str or BaseLlm | 关联的模型,可以是字符串名或模型实例(如LiteLlm) | 使用的模型(必填) |
| instruction | str or Callable | 给Agent的详细指令,可以是固定文本,也可以是函数动态生成 | 指令说明(必填或推荐填写) |
| global_instruction | str or Callable | 在整个Agent树范围共享的指令(全局指令) | 全局指令(少用) |
| tools | list[Callable or BaseTool] | 这个Agent可以调用的外部工具列表 | 工具列表 |
| generate_content_config | GenerateContentConfig or None | 控制模型生成内容时的一些配置,比如最大Token数、温度等 | 生成设置(选填) |
| disallow_transfer_to_parent | bool | 禁止把任务转给父Agent(防止死循环) | 禁止转移到父代理 |
| disallow_transfer_to_peers | bool | 禁止把任务转给同级Agent | 禁止转移到同级代理 |
| include_contents | ‘default’ or ‘none’ | 是否在提示中包含历史对话内容 | 是否包含上下文 |
| input_schema | pydantic.BaseModel or None | 限定输入必须符合某种结构(Pydantic模型) | 输入校验模型 |
| output_schema | pydantic.BaseModel or None | 限定输出必须符合某种结构(Pydantic模型) | 输出校验模型 |
| output_key | str or None | 指定模型输出结果中的哪个字段作为最终输出 | 输出字段名 |
| planner | BasePlanner or None | 自定义计划器(比如动态规划步骤) | 规划器(进阶功能) |
| code_executor | BaseCodeExecutor or None | 允许Agent执行代码(如Python沙盒环境) | 代码执行器(进阶功能) |
| examples | list[Example] or BaseExampleProvider or None | 示例对话或行为示范,帮助模型更好完成任务 | 示例数据 |
| before_model_callback | Callable or None | 在发送给模型推理前,修改请求内容 | 模型请求前回调 |
| after_model_callback | Callable or None | 在收到模型响应后,修改或处理响应 | 模型响应后回调 |
| before_tool_callback | Callable or None | 在调用工具前修改参数或做拦截 | 工具调用前处理 |
| after_tool_callback | Callable or None | 在工具返回结果后做处理 | 工具调用后处理 |
其中四个核心参数:
- model 是必须指定的(不指定Agent就不会工作)
- instruction 和 description 是推荐填写的(帮助大模型更好理解自己要干什么)
- tools 是选填的(如果需要调用外部API、数据库等,就注册工具)
- sub_agents 是选填的(需要多Agent协作时再用)
- 创建一个简单的Agent对象方法如下:
import os
import asyncio
from google.adk.agents import Agent
from google.adk.models.lite_llm import LiteLlm
from google.adk.sessions import InMemorySessionService
from google.adk.runners import Runner
from google.genai import types
OPENAI_API_BASE="https://dashscope.aliyuncs.com/compatible-mode/v1"
OPENAI_API_KEY="sk-xxx"
MODEL="deepseek/deepseek-r1-0528"
model = LiteLlm(
model=MODEL,
api_base=OPENAI_API_BASE,
api_key=OPENAI_API_KEY
)
agent = Agent(
name="simple_agent",
model=model,
instruction="你是一个乐于助人的中文助手。",
description="回答用户的问题。"
)
创建Session
- 紧接着创建一个Session对象,用于保存Agent运行过程中的多轮对话内容。ADK提供了一个InMemorySessionService类。
- 其核心作用如下:
- 保存每轮用户输入(user messages)
- 保存每轮模型输出(assistant messages)
- 保存工具调用过程中的中间数据(如果有工具的话)
- 提供历史对话上下文,让模型能基于完整对话继续推理,而不是每次都从空白开始
- 可以创建一个InMemorySessionService()实例。对话管理示例实际会在内存中进行历史会话信息管理。而具体的会话信息会保存在.sessions属性里,默认为空:from google.adk.sessions import InMemorySessionService
session_service = InMemorySessionService()
print(session_service.sessions) - 在正式开启对话之前,需要创建一个初始session对象,为了区分不同的会话,该对象需要设置APP名称、用户ID和对话ID,方便后续进行查找和调用。from google.adk.sessions import InMemorySessionService
session_service = InMemorySessionService()
session_service.sessions
APP_NAME = "test_app"
USER_ID = "user_1"
SESSION_ID = "session_001"session = session_service.create_session(
app_name=APP_NAME,
user_id=USER_ID,
session_id=SESSION_ID
)
print(f"Session created: App='{APP_NAME}', User='{USER_ID}', Session='{SESSION_ID}'") - 目前session对象是空的,而在后续执行过程中,伴随着上下文生成器存储了更多的会话信息,也可以将更多的上下文信息保存在session中。需要注意的是,在创建session对象的同时,对话生成器session_service的.sessions也发生了变化,其内容与session基本一致。
- 需要注意的是,在后续对话中,我们实际上是带入session_service进行对话,并读取session_service.sessions里面的历史对话信息作为上下文。这里可以将单独创建的session对象视作一个中间对象或者一个备份。
创建智能体执行器(Runner)
- 接下来进一步创建Runner对象,Runner 是 ADK 中真正让 Agent“动起来”的引擎,其核心功能和Agents SDK中的Runner类似,具体职责如下:
| 会话管理 | 自动读取/写入 SessionService,维护历史 |
| Agent调用 | 调用指定的 Agent 完成推理和工具调用 |
| 输入输出流转 | 把用户输入交给Agent,把Agent输出返回 |
| 流程控制 | 支持多轮对话、子Agent委托、工具调用等 |
| 生命周期管理 | 处理每一次对话流程的完整生命周期 |
- Runner:Agent的管理者,负责组织每一次对话交互的完整生命周期。
Runner?
Init signature:
Runner(
*,
app_name: 'str',
agent: 'BaseAgent',
artifact_service: 'Optional[BaseArtifactService]' = None,
session_service: 'BaseSessionService',
memory_service: 'Optional[BaseMemoryService]' = None,
)
Docstring:
The Runner class is used to run agents.
It manages the execution of an agent within a session, handling message
processing, event generation, and interaction with various services like
artifact storage, session management, and memory.
Attributes:
app_name: The application name of the runner.
agent: The root agent to run.
artifact_service: The artifact service for the runner.
session_service: The session service for the runner.
memory_service: The memory service for the runner.
Init docstring:
Initializes the Runner.
Args:
app_name: The application name of the runner.
agent: The root agent to run.
artifact_service: The artifact service for the runner.
session_service: The session service for the runner.
memory_service: The memory service for the runner.
File: c:\\programdata\\anaconda3\\envs\\jupyter_env\\lib\\site-packages\\google\\adk\\runners.py
Type: type
Subclasses: InMemoryRunner
其核心参数解释如下:
| app_name | str | 应用程序的名称,用于标识不同的应用实例 | 应用名称 |
| agent | BaseAgent | 要运行的根 Agent,负责执行实际的任务和推理 | 要运行的主代理 |
| artifact_service | Optional[BaseArtifactService] | 可选的文件存储服务,用于处理生成的工件(如文件、模型) | 文件存储服务(可选) |
| session_service | BaseSessionService | 必需的会话服务,用于管理和维护对话历史 | 会话服务(必须) |
| memory_service | Optional[BaseMemoryService] | 可选的内存服务,用于长期和短期记忆管理 | 内存服务(可选) |
- Runner类有个直观重要的方法:Runner.run_asyncb
Signature:
Runner.run_async(
self,
*,
user_id: 'str',
session_id: 'str',
new_message: 'types.Content',
state_delta: 'Optional[dict[str, Any]]' = None,
run_config: 'RunConfig' = RunConfig(speech_config=None, response_modalities=None, save_input_blobs_as_artifacts=False, support_cfc=False, streaming_mode=<StreamingMode.NONE: None>, output_audio_transcription=None, input_audio_transcription=None, realtime_input_config=None, enable_affective_dialog=None, proactivity=None, session_resumption=None, max_llm_calls=500),
) –> 'AsyncGenerator[Event, None]'
Docstring:
Main entry method to run the agent in this runner.
Args:
user_id: The user ID of the session.
session_id: The session ID of the session.
new_message: A new message to append to the session.
run_config: The run config for the agent.
Yields:
The events generated by the agent.
File: c:\\users\\kongyue\\.conda\\envs\\langchain_stu\\lib\\site-packages\\google\\adk\\runners.py
Type: function
- runner.run_async 是 Runner 类的核心方法之一,用于以异步方式执行 Agent 的任务。这个方法接收用户输入的消息,并将其添加到会话中,随后启动 Agent 来处理该消息,并生成一系列的事件(Event)。
具体参数解释如下:
user_id (str):
- 该参数表示用户的唯一标识,用于标记当前会话是属于哪个用户的。每个用户可以有多个会话实例。
- 示例:user_id="user_123"
session_id (str):
- 该参数表示会话的唯一标识,用于区分不同用户或同一用户的不同对话会话。每次创建会话时,都会为其分配一个唯一的 session_id。
- 示例:session_id="session_456"
new_message (types.Content):
- 这是 ADK 中的一个核心对象,表示传递给 Agent 的新消息。types.Content 是一个包含了消息的具体内容的对象,通常它包含 role(角色)、text(消息文本)等字段。
- 示例:new_message=types.Content(role="user", parts=[types.Part(text="今天天气如何?")])
run_config (RunConfig, 可选):
- 这是一个配置对象,用于定制执行时的参数设置。可以根据需求设置一些如语音配置、响应方式、最大模型调用次数等参数。其默认值为 RunConfig(),这是一个内置的默认配置类。
RunConfig 的核心字段解释:
- speech_config: 用于配置语音识别和语音输出的相关设置(例如语音转文本、语音输出等)。通常与语音助手相关。
- response_modalities: 配置响应的方式,例如,返回文本、语音等。
- save_input_blobs_as_artifacts: 是否将输入文件保存为工件(例如,将用户上传的图片保存为文件以供后续处理)。默认值为 False。
- support_cfc: 是否支持 CFC(Custom Function Calling),即是否允许 Agent 调用自定义函数。
- streaming_mode: 设置流模式(例如是否开启流式输出),用于处理长时间生成的响应。
- output_audio_transcription: 配置输出的音频转录设置(如果支持语音输出)。
- max_llm_calls: 配置在一次会话中最大可以调用 LLM(大语言模型)次数的上限。默认值为 500。
import asyncio
from google.adk.agents import Agent
from google.adk.models.lite_llm import LiteLlm
from google.adk.sessions import InMemorySessionService
from google.adk.runners import Runner
from google.genai import types
OPENAI_API_BASE="https://dashscope.aliyuncs.com/compatible-mode/v1"
OPENAI_API_KEY="sk-xxx"
MODEL="deepseek/deepseek-r1-0528"
model = LiteLlm(
model=MODEL,
api_base=OPENAI_API_BASE,
api_key=OPENAI_API_KEY
)
agent = Agent(
name="simple_agent",
model=model,
instruction="你是一个乐于助人的中文助手。",
description="回答用户的问题。"
)
session_service = InMemorySessionService()
session_service.sessions
APP_NAME = "test_app"
USER_ID = "user_1"
SESSION_ID = "session_001"
session =await session_service.create_session(
app_name=APP_NAME,
user_id=USER_ID,
session_id=SESSION_ID
)
runner = Runner(
agent=agent, # The agent we want to run
app_name=APP_NAME, # Associates runs with our app
session_service=session_service # Uses our session manager
)
print(f"Runner created for agent '{runner.agent.name}'.")
Runner created for agent 'simple_agent'.
执行对话
- 接下来创建call_agent_async的函数来获得Agent响应,其代码如下:
async def call_agent_async(query: str, runner, user_id, session_id):
"""将查询发送给代理并打印最终响应。"""
print(f"\\n>>> User Query: {query}")
# 准备用户的ADK格式消息
content = types.Content(role='user', parts=[types.Part(text=query)])
final_response_text = "代理未生成最终响应。" # 默认值
# 关键概念:run_async执行代理逻辑并生成事件。
# 遍历事件以找到最终答案。
async for event in runner.run_async(user_id=user_id, session_id=session_id, new_message=content):
# 您可以取消下面一行的注释以在执行期间查看*所有*事件
print(f" [Event] 作者: {event.author}, 类型: {type(event).__name__}, 最终: {event.is_final_response()}, 内容: {event.content}")
# 关键概念:is_final_response()标记该回合的结束消息。
if event.is_final_response():
if event.content and event.content.parts:
# 假设文本响应在第一部分中
final_response_text = event.content.parts.text
elif event.actions and event.actions.escalate: # 处理潜在的错误/升级
final_response_text = f"代理已升级: {event.error_message or '没有具体消息。'}"
# 如果需要可以添加更多检查(例如特定错误代码)
break # 一旦找到最终响应就停止处理事件
print(f"<<< Agent Response: {final_response_text}")
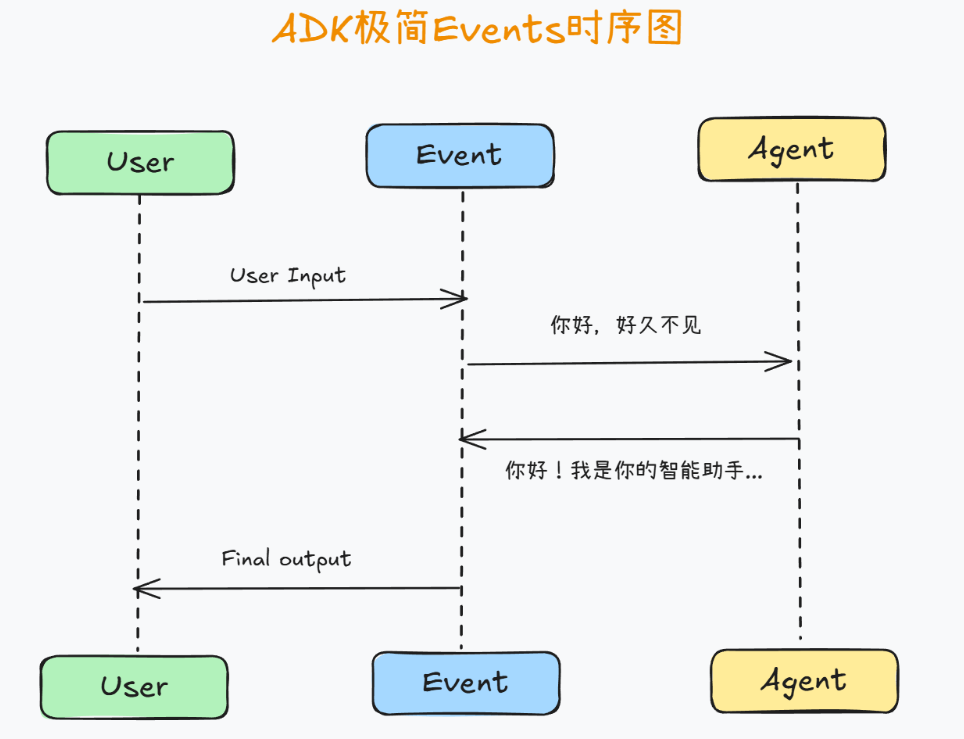
这段代码定义call_agent_async 异步函数,用来:
其核心运行流程是:
- 将用户查询转换为 ADK 需要的格式
- 通过 runner.run_async() 运行 Agent
- 通过 事件驱动机制 获取和处理每一轮的消息、工具调用、回复
- 当 最终响应 到达时,停止循环并返回 Agent 的最终回答。
注意:
- 为什么要定义这个辅助函数?在这段代码中,我们通过 call_agent_async 这个辅助函数来实现与 Agent 的交互。它的作用不仅是简单地给用户回复答案,而是通过 事件驱动 机制,来处理与 Agent 的复杂交互和状态管理。
- 为什么不直接调用 runner.run_async?其实是为了能够更方便地处理和监控整个过程,尤其是在多轮对话或复杂交互中。将这些复杂逻辑封装到一个函数里,使得代码更加清晰、可维护,并且容易扩展。
- 也就是说,可以把call_agent_async 想象成一个管控器,它负责管理这个异步对话的过程,并确保每一部分顺利完成。这个过程很复杂,因为:
- 它不是一次性任务,可能涉及多步推理、外部工具调用、错误处理等环节。
- 需要逐步监控每一个事件(可能有很多中间状态、工具调用等)。
- 只有当所有步骤完成,最终的模型回复才算“最终回应”。
>>> User Query: 你好,我叫陈明,好久不见!
[Event] 作者: simple_agent, 类型: Event, 最终: True, 内容: parts=[Part(
text='陈明先生您好!很高兴认识您!虽然我们可能是初次对话,但很乐意为您提供帮助。请问今天有什么问题需要解答,或是有什么我可以为您做的吗?😊'
)] role='model'
<<< Agent Response: 陈明先生您好!很高兴认识您!虽然我们可能是初次对话,但很乐意为您提供帮助。请问今天有什么问题需要解答,或是有什么我可以为您做的吗?😊
- Author:simple_agent — 这个事件是由 simple_agent 发出的,表示当前响应来自于我们定义的Agent。
- Type:Event — 表明这是一个事件对象,表示某个状态发生。
- Final:True — True 表示这是最终的响应,模型已经完成任务并准备返回最终结果。
- Content:content.parts=[Part(…)] — 这里包含了模型回复的实际内容。它是一个 Part 对象,其中 text 字段就是最终的文本回答:'你好!我是你的智能助手,专门用来回答你的问题、提供帮助或陪你聊天。我可以帮你查询信息、解答疑问、提供建议,或者只是随便聊聊。有什么我可以帮你的吗? 😊'
- role:'model' — 角色是 模型,意味着这条消息是从模型生成的,不是用户输入。






评论前必须登录!
注册