 网硕互联帮助中心
网硕互联帮助中心C语言
内容提要
- 函数
- 函数的嵌套关系
- 函数的递归调用
- 数组做函数参数
- 变量的作用域
- 变量的生命周期
函数
函数的嵌套调用
定义
函数不允许嵌套定义,但是允许嵌套调用。
-
正确示例
void a()
{
...
}
//函数的嵌套调用
void b()
{
a()
}int main()
{
printf(...);
} -
错误示例:
//函数的嵌套定义
void a()
{
void b()
{
...
}
}
**嵌套调用:**在被调用函数内又主动去调其他函数,这样的函数调用形式,称之为嵌套调用。
案例
案例1
-
需求:编写一个函数,判断给定的3~100的正整数是否是素数,若是返回1,否则返回0
-
分析:
- 素数:又被称作质数,素数是大于1的自然数,除了1和它本身以外,不能被其他数整除。
-
代码:
/*************************************************************************
> File Name: demo01.c
> Author: 朱旭博
> Description:
> Created Time: 2025年07月23日 星期三 09时30分20秒
************************************************************************/#include <stdio.h>
/**
*定义一个函数,判断一个自然数是否是素数
*@param n 待判断的自然数
*@return 1-素数,0-非素数
*/
int is_prime(int n)
{
//定义一个标记,默认是素数
int flag = 1;
//循环变量
int i;//生成测试数据 2~n/2
for (i = 2; i <= n/2; i++)
{
//校验
if (n % i == 0)
{
flag = 0;
break;
}
}return flag;
}int main(int argc,char *argv[])
{
//生成3~100之间的自然数
for (int i = 3; i <= 100; i++)
{
//如果是自然数,就打印,否则不打印
if (is_prime(i)) printf("%-4d",i);
}printf("\\n");
return 0;
} -
运行结果

案例2
-
需求:通过控制台输入一个整数,校验这个整数在一个已知数组中的位置,如果找到,返回下标,找不到,返回-1
-
代码:
/*************************************************************************
> File Name: demo02.c
> Author: 朱旭博
> Description:
> Created Time: 2025年07月23日 星期三 09时47分20秒
************************************************************************/#include <stdio.h>
/*
*定义一个函数,在一个数组中查找指定数据的位置
*@param arr[] 待查询的数组
*@oaram len 数组传参,只传数组首地址,因此我们没法通过sizeof关键字计算数组的大小,所以需要从外部传递进来
*@param n 待查询的数据
*return >=0:找到,-1:未找到
*/
int find_index(int arr[], int len, int n)
{
//定义一个标记
int index = –1;//遍历数组
for (int i = 0; i < len; i++)
{
//获取位置
if (arr[i] == n)
{
//更新位置
index = i;
break;
}
}return index;
}
int main(int argc,char *argv[])
{
int arr[] = {11,22,33,44,55};
int len = sizeof(arr) / sizeof(arr[0]);int n = 66;
int index = find_index(arr,len,n);
index != –1 ? printf("%d在数组中的位置是%d\\n",n,index) : printf("未找到%d在数组中的位置!\\n",n);int n2 = 33;
int index2 = find_index(arr,len,n2);
index2 != –1 ? printf("%d在数组中的位置是%d\\n",n2,index2) : printf("未找到%d在数组中的位置!\\n",n2);return 0;
} -
运行结果:

案例3
-
需求:
-
代码
/*************************************************************************
> File Name: demo03.c
> Author: 朱旭博
> Description:
> Created Time: 2025年07月23日 星期三 10时10分06秒
************************************************************************/#include <stdio.h>
//函数声明
int max_2(int,int);
int max_4(int,int,int,int);/*
*求2个数中的最大值
*/
int max_2(int a, int b)
{
return a > b ? a : b;
}/*
*求4个数中的最大值
*/
int max_4(int a, int b, int c, int d)
{
//写法1
//int max;
//max = max_2(a,b);
//max = max_2(max,c);
//max = max_2(max,d);//写法2
return max_2(a,b) > max_2(c,d) ? max_2(a,b) : max_2(c,d);
}
int main(int argc,char *argv[])
{
int a, b, c, d;printf("请输入4个整数:\\n");
scanf("%d%d%d%d",&a,&b,&c,&d);printf("%d,%d,%d,%d中最大数是%d\\n",a,b,c,d,max_4(a,b,c,d));
return 0;
} -
运行结果

函数的递归调用
定义
递归调用的含义
在一个函数中,直接或者间接调用了函数本身,就称之为递归调用。本质上还是函数的嵌套调用。
//直接调用推荐
a() → a();
//间接调用
a() → b() → a();
a() → b() → ... →a();
递归调用的本质
递归调用是一种循环结构,它不同于我们之前学过的while,for,do…while这样的循环结构,这些循环结构是借助于循环变量;而递归调用是利用函数自身实现循环结构,如果不加以控制,很容易产生死循环。
注意事项
①递归调用必须要有出口,一定要想办法终止递归(否则会产生死循环)
②对终止条件的判断一定要放在函数递归之前。(先判断,再执行)
③进行函数的递归调用。
④函数递归的同时一定要将函数调用向出口逼近。
递归的底层实现
C语言函数递归的底层实现依赖于程序调用栈(Call Stack),其核心过程是通过栈帧(Stack Frame)的创建与销毁来管理函数的多次调用。具体底层逻辑如下:
每次函数调用(包括递归调用自身)时,系统会在内存的栈区为该次调用分配一块独立的内存空间,即栈帧。栈帧用于存储:
-
函数的参数值
-
函数内的局部变量
-
调用结束后返回的地址(即该次调用结束后,程序应回到的原执行位置)
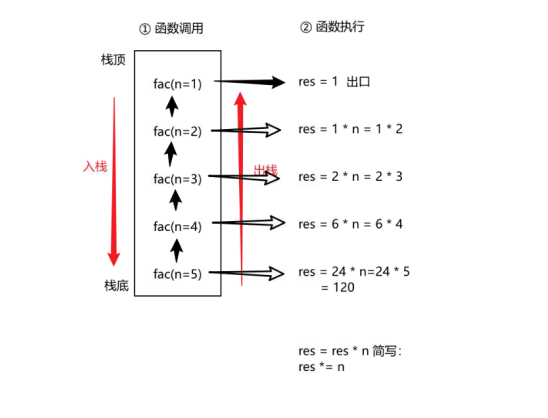
以计算阶乘 n! 的递归函数 fac(n) 为例(fac(n) = n *fac(n-1) ,终止条件 fac(1) = 1 ):
-
第一步:调用 fac(3) 时,系统创建栈帧1,存储参数 n=3 、局部变量及返回地址(假设主函数调用处),然后执行函数体,发现需要调用 fac(2) 。
-
第二步:调用 fac(2) 时,系统在栈顶创建栈帧2,存储参数 n=2 及新的返回地址(fac(3) 中等待结果的位置),暂停 fac(3) 的执行,转去执行 fac(2) 。
-
第三步:同理,调用 fac(1) 时,创建栈帧3,存储 n=1 及返回地址(fac(2) 中等待结果的位置)。
-
终止与回溯:当执行到 fac(1) 时,触发终止条件,直接返回结果 1 。此时栈帧3被销毁,程序回到栈帧2中继续执行(计算 2 * 1 = 2 ),栈帧2销毁后回到栈帧1(计算 3 * 2 = 6 ),最终栈帧1销毁,返回结果给主函数。
-
栈的“后进先出”特性:递归调用时,新的栈帧总是压在栈顶,而只有最顶层的栈帧(即最后一次调用)执行完毕并返回结果后,上层的栈帧才能继续执行(对应递归的“回溯”过程)。
-
栈溢出风险:若递归次数过多(如未设置终止条件或终止条件无法触发),会导致栈帧不断创建,超出栈区内存上限,触发“栈溢出(Stack Overflow)”错误,程序崩溃。
简言之,递归的底层本质是通过栈帧的层层创建(递推)和销毁(回溯),实现函数自身的多次调用管理,而栈的特性保证了递归调用的顺序和结果传递。
案例
案例1
-
需求:
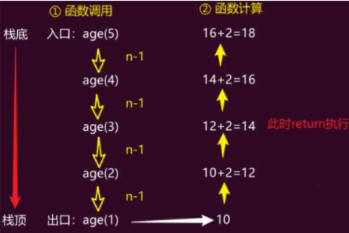
递归案例
有5个人坐在一起,
问第5个人多少岁?他说比第4个人大2岁。
问第4个人多少岁?他说比第3个人大2岁。
问第3个人多少岁?他说比第2个人大2岁。
问第2个人多少岁?他说比第1个人大2岁。
最后问第1个人,他说是10岁。
请问第5个人多大。
-
分析:
-
代码:
/*************************************************************************
> File Name: demo04.c
> Author: 朱旭博
> Description:
> Created Time: 2025年07月23日 星期三 11时16分00秒
************************************************************************/#include <stdio.h>
/*
*定义一个函数,求年龄
*@param n 第n个人
*@return 第n个人的年龄
*/
int age(int n)
{
//创建一个变量,存储当前这个人的年龄
int _age;//出口
if (n == 1)//第一个人
{
_age = 10;
}
else if (n > 1)
{
_age = age(n–1) + 2;//当前这个人的年龄 = 上一个人的年龄 + 2
}
return _age;
}
int main(int argc,char *argv[])
{
int n = 5;
printf("第%d个人的年龄是%d岁!\\n",n,age(5));
return 0;
} -
运行结果:

案例2
-
需求:求n的阶乘
-
分析:
-
代码:
/*************************************************************************
> File Name: demo05.c
> Author: 朱旭博
> Description:
> Created Time: 2025年07月23日 星期三 11时30分47秒
************************************************************************/#include <stdio.h>
/*
*创建一个函数,实现n的阶乘
*@param n 阶乘上限
*@return n的阶乘结果
*/
size_t fac(int n)
{
//定义一个变量,用来接收阶乘的结果
size_t res;//出口校验
if (n <= 0)
{
printf("n的范围不能是0及以下数字!\\n");
return –1;
}
else if (n == 1) //出口
{
res = 1; //出口设置
}
else
{
res = fac(n–1) * n;
}
return res;
}int main(int argc,char *argv[])
{
size_t n;
printf("请输入一个整数:\\n");
scanf("%lu",&n);printf("%lu的阶乘结果时%lu\\n",n,fac(n));
return 0;
} -
运行结果:

快速排序算法
快速排序是一种高效的分治(Divide and Conquer)排序算法。它的核心思想是通过选取一个基准值(pivot),将数组划分为两个子数组:一个子数组的所有原酸比基准值小,另一个子数组的所有元素比基准值大,然后递归地对子数组进行排序。
快速排序的基本步骤
1.选择基准值(Pivot Selection):
- 从数组中选择一个元素作为基准值。常见的选择方式包括:
- 第一个或最后一个元素(简单但可能效率不高,尤其在已排序或接近排序的数组中)。
- 随机选择一个元素(减少最坏情况概率)。
- 三数取中法(如第一个、中间、最后一个元素的中位数,提高分区均衡性)。
2.分区(Partition):
- 重新排列数组,使得:
- 所有比基准值小的元素移到基准值的左侧。
- 所有比基准值大的元素移到基准值的右侧。
- 分区完成后基准值处于其最终排序后的正确位置。
- (注:分区是快速排序的关键步骤,常见的实现有Lomuto分区和Hoare分区方案。)
3.递归排序(Recursion):
- 对基准值左侧的子数组和右侧的子数组递归地调用快速排序。
- 递归地终止条件是子数组的长度为0或1(已有序)
4.合并结果(Combine):
- 由于每次分区后基准值已位于正确位置,且左右子数组通过递归排序完成,因此无需显示合并操作,整个数组自然有序。
总结
通过一个基准值(pivot)不断拆分数组,直到子数组无法再拆分(即子数组长度为1或0),此时整个数组就有序了。
代码:
/*************************************************************************
> File Name: demo06.c
> Author: 朱旭博
> Description:
> Created Time: 2025年07月23日 星期三 14时23分45秒
************************************************************************/
#include <stdio.h>
/*
*快速排序函数(递归实现)
*@param arr 待排序数组
*@param n 数组长度
*/
void QSort(int arr[], int n)
{
//出口限制,如果排序数组的大小<=1,此时数组就不再排序
if (n <= 1) return;
//定义两个标记,i从左向右,j从右向左,锁定排序数组的区间
int i = 0, j = n – 1;
//选择排序数组的第一个元素作为基准值(可优化为取中法)
int pivot = arr[0];
//分区过程
while (i < j)
{
//从右向左查找第一个小于等于基准值的元素(<=基准值的数据)
while (i < j && arr[j] > pivot) j—;
//从左向右查找第一个大于基准值的元素(>基准值的数据)
while (i < j && arr[i] <= pivot) i++;
//交换这两个元素
if (i < j)
{
int temp = arr[i];
arr[i] = arr[j];
arr[j] = temp;
}
}
//将基准值更新到正确位置(i == j)
arr[0] = arr[i];
arr[j] = pivot;
//切割子数组
QSort(arr,i);//左边部分
QSort(arr+i+1,n–i–1);//右边部分
}
int main(int argc,char *argv[])
{
int arr[] = {23,45,56,78,33,22,19};
int n = sizeof(arr) / sizeof(arr[0]);
QSort(arr,n);//函数的参数是数组,传递的是这个数组的首地址,函数中可以修改实参数据,符合这种条件的参数称之为输出型参数
//此时是可以直接遍历数组,此时的数组已经经过了修改
for (int i = 0; i < n; i++)
{
printf("%-4d",arr[i]);
}
printf("\\n");
return 0;
}
运行结果:

数组做函数参数
定义
当使用数组作为函数的实参时,形参应该使用数组形式或者指针变量来接收。需要注意的是:
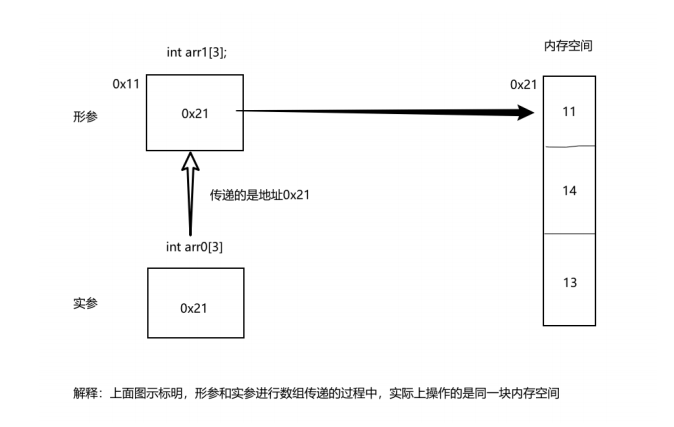
这种传递方式并不是传递数组中的所有的元素数据,而是传递数组首地址,此时数组降级为指针。
形参接收到这个地址后,形参和实参指向同一块内存空间。
因此,通过形参对数组元素的修改会直接影响到实参。
这种传递方式称为“地址传递”(或“指针传递”),它与“值传递”的不同:
-
值传递:传递数据的副本,修改形参不影响实参
-
地址传递:传递数据的地址,通过形参可以修改实参。“地址传递”是逻辑上的说法,强调 传递的是地址,而不是数据本身。数据本质上还是值传递。
当使用数组作为函数的形参时,通常需要额外传递一个参数表示数组的元素个数。这是因为:
数组形参退化为指针 在函数参数传递时,数组名会退化为指向其首元素的指针(即int arr[] 等价于int *arr),因此函数内部无法直接获取数组的实际长度。
防止越界访问 由于形参仅知道数组的首地址,而不知道数组的实际大小,如果不传递元素个数,函数内部可能因错误计算或循环导致 数组下标越界(访问非法内存),引发未定义行为(如程序崩溃、数据损坏)。
通用性 即使实参数组的声明长度固定(如 int a[10] ),函数仍应接收元素个数参数,因为函数可能需要处理不同长度的数组(例如动态数组或部分填充的数组)。
案例:
#include <stdio.h>
/**
* 定义一个函数,将数组作为参数
*/
void fun(int arr[], int len) // 数组传参会被降级为指针,实际传递的是地址值
{
for (int i = 0; i < len; i++) printf("%-4d",arr[i]); printf("\\n");
}
void main()
{
int arr[] = {11,22,33,44,55};
int len = sizeof(arr) / sizeof(arr[0]);
fun(arr,len);
}
但有一个例外,如果是用字符数组做形参,且实参数组中存放的是字符串数据(形参是字符数组,实参是字符串常量)。则不用表示数组个数的形参,原因是字符串本身会添加自动结束标志 \\0 ,举例:
#include <stdio.h>
/**
* 定义一个函数,传递一个字符串
*/
void fun(char arr[])
{
char c;
int i = 0;
while((c = arr[i]) != '\\0') // arr[i] → arr + i
{
printf("%c",c);
i++;
}
}
void main()
{
fun("hello world");
**为什么sizeof不能用于形参数组?**在函数内部,sizeof(arr)返回的是指针的大小(32位系统返回4字节,64位系统返回8字节)。例如:
void printSize(int arr[])
{
printf("%zu\\n",sizeof(arr)); // 输出的是指针的大小(8字节),而非数组大小
}
案例
案例1
-
需求:
有两个数组a和b,各有5个元素,将它们对应元素逐个地相比(即a[0]与b[0]比,a[1]与b[1]比……)。如果a数组中的元素大于b数组中的相应元素的数目多于b数组中元素大于a数组中相应元素的数目(例如,a[i]>b]i]6次,b[i]>a[i] 3次,其中i每次为不同的值),则认为a数组大于b数组,并分别统计出两个数组相应元素大于、等于、小于的个数。
int a[10] = {12,12,10,18,5};
int b[10] = {111,112,110,8,5}; -
代码:
#include <stdio.h>
#define LEN 5
/**
* 定义一个函数,实现两个数字的比较
* @param x,y 参与比较的两个数字
* @return x>y–> 1, x<y–>-1, x==y–>0
*/
int get_large(int x, int y)
{
int flag = 0;
if (x > y) flag = 1;
else if (x < y) flag = –1;
return flag;
}
int main(int argc,char *argv[])
{
// 定义a,b两个测试数组
int a[LEN] = {12,12,10,18,5};
int b[LEN] = {111,112,110,8,5};
int max = 0, min = 0, k = 0;
// 遍历数组,进行比较
for (int i = 0; i < LEN; i++)
{
// 同一位置两个数比较
int res = get_large(a[i], b[i]);
if (res == 1) max++;
else if (res == –1) min++;
else k++;
}
printf("max=%d,min=%d,k=%d\\n", max, min, k);
return 0;
}
案例2
-
需求:编写一个函数,用来分别求数组score_1(有5个元素)和数组score_2(有10个元素)各元素的平均值 。
-
代码:
#include <stdio.h>
/**
* 定义一个函数,求一个数组的平均值
*/
float get_avg(float scores[], int len)
{
int i;
float aver, sum = scores[0]; // 平均值,总分
// 遍历数组
for (i = 1; i < len; i++) sum += scores[i];
// 求平均分
aver = sum / len;
return aver;
}
int main(int argc,char *argv[])
{
// 测试数组
float scores1[] = {77,88,99,66,57};
float scores2[] = {67,87,98,78,67,99,88,77,77,67};
int len = sizeof(scores1) / sizeof(scores1[0]);
int len2 = sizeof(scores2) / sizeof(scores2[0]);
printf("%6.2f,%6.2f\\n", get_avg(scores1, len),
get_avg(scores2, len2));
return 0;
}
案例3
-
需求:编写一个函数,实现类似strcpy的效果 。
-
代码:
#include <stdio.h>
/**
* 自定义一个字符串拷贝函数
* @param source 源数组
* @param dest 需要替换的字符串
*/
void _strcpy(char source[], const char dest[])
{
// 遍历源数组,以源数组的大小作为循环
for (int i = 0; source[i] != '\\0'; i++)
{
// 获取dest相应位置的字符
source[i] = dest[i];
}
}
int main(int argc,char *argv[])
{
char str[] = "hello world!";
printf("%s\\n", str);
_strcpy(str,"hi yifan!");
printf("%s\\n", str);
_strcpy(str,"娇娇");
printf("%s\\n", str);
return 0;
}
变量的作用域
引入问题
我们在函数设计的过程中,经常要考虑对于参数的设计,换句话说,我们需要考虑函数需要几个参数,需要什么类型的参数,但我们并没有考虑函数是否需要提供参数,如果说函数可以访问到已定义的数据,则就不需要提供函数形参。那么我们到底要不要提供函数形参,取决于什么?答案就是变量的作用域(如果函数在变量的作用域范围内,则函数可以直接访问数据,无需提供形参)
变量作用域
**概念:**变量的作用范围,也就是说变量在什么范围有效。
变量的分类
根据变量的作用域不同,变量可以分为:
- 全局变量
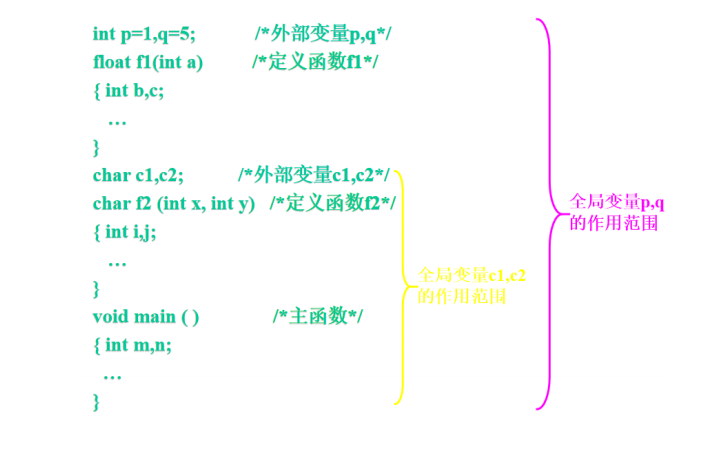
说明:定义在函数之外,也称之为外部变量或者全程变量。
作用域:从全局变量定义到本源文件结束。
初始值:整型和浮点型,默认值是0;字符型,默认值是\\0;指针型,默认值NULL
举例:
int num1; // 全局变量,num1能被fun1、fun2、main共同访问
void fun1(){}
int num2; // 全局变量,num2能被fun2、main共同访问
void fun2(){}
void main(){}
int num3; // 全局变量,不能被任何函数访问
- 局部变量
| 形式参数(形参) | 函数作用域 | 随机值,需要手动赋初值 |
| 函数内定义的变量 | 函数作用域 | 随机值,需要手动赋初值 |
| 复合语句中定义的变量 | 块作用域 | 随机值,需要手动赋初值 |
| for循环表达式1定义的变量 | 块作用域 | 随机值,需要手动赋初值 |
举例:
// a,b就是形式参数(局部变量)
int add(int a, int b)
{
return a + b;
}
int add2(int a, int b)
{
// z就是函数内定义的变量(局部变量)
int z = a + b;
return z;
}
int list(int arr[], int len)
{
// i就是for循环表达式1的变量(局部变量)
for(int i = 0; i < len; i++)
{
// num就是复合语句中定义的变量(局部变量)
int num = arr[i];
}
}
使用全局变量的优缺点:
优点:
缺点:
全局变量在程序的整个运行期间,始终占据内存空间,会引起资源消耗。
过多的全局变量会引起程序的混乱,操作程序结果错误。
降低程序的通用性,特别是当我们进行函数移植时,不仅仅要移植函数,还要考虑全局变量。
违反了“高内聚,低耦合”的程序设计原则。
总结:
我们发现弊大于利,建议尽量减少对全局变量的使用,函数之间要产生联系,仅通过实参+形参的方式产生联系。
作用域举例
注意:
如果全局变量和局部变量同名,程序执行的时候,就近原则(区分作用域)
int a = 10; // 全局变量 全局作用域
int main()
{
int a = 20; // 局部变量 函数作用域
printf("%d\\n", a); // 20 就近原则
for (int a = 0; a < 5; a++) // 局部变量 块作用域
{
printf("%d", a); // 0 1 2 3 4 就近原则
}
printf("%d\\n",a); // 20 就近原则
}
变量的生命周期
定义
**概念:**变量在程序运行中的存在时间(内存申请到内存释放的时间)
根据变量存在的时间不同,变量可分为静态存储方式和动态存储方式
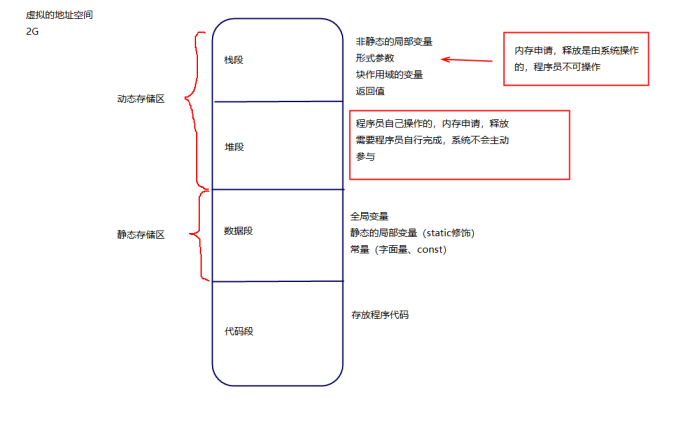
变量的存储类型
语法:
变量的完整定义格式: [存储类型] 数据类型 变量列表;
存储类型:
-
auto
auto存储类型只能修饰局部变量,被auto修饰的局部变量是存储在动态存储区(栈区和堆区)的。auto也是局部变量默认的存储类型。
int main()
{
int a;
int b;
// 以下写法等价于上面写法
auto int a;
auto int b;
int a,b;
// 以下写法等价于上面写法
auto int a,b;
} -
static
**修饰局部变量:**局部变量会被存储在静态存储区。局部变量的生命周期被延长。但是作用域不发生改变,不推荐
**修饰全局变量:**全局变量的生命周期不变,但是作用域衰减,一般限制全局变量只能在本源文件内访问,其他文件不可访问。
**修饰函数:**被static修饰的函数,只能被当前文件访问,其他引用该文件的文件是无法访问的,有点类似于java中private
-
extern
外部存储类型:只能修饰全局变量,此全局变量可以被其他文件访问,相当于扩展了全局变量的作用域。
extern修饰外部变量,往往是外部变量进行声明,声明该变量是在外部文件中定义的。起到一个标识作用。函数同理。
demo01.c
#include "demo01.h"
int fun_a = 10;
int fun1(){..}demo02.c
#include "demo01.h"
// 声明访问的外部文件的变量
extern int fun_a;
// 声明访问的外部文件的函数
extern int fun1();
int fun2(); -
register
寄存器存储类型:只能修饰局部变量,用register修饰的局部变量会直接存储到CPU的寄存器中,往往将循环变量设置为寄存器存储类型(提高读的效率)
for (register int i = 0; i < 10; i++)
{
...
}面试题
static关键字的作用
-
static修饰局部变量,延长其生命周期,但不影响局部变量的作用域。
-
static修饰全局变量,不影响全局变量的生命周期,会限制全局变量的作用域仅限本文件内使用(私有化);
-
static修饰函数:此函数就称为内部函数,仅限本文件内调用(私有化)。 static int funa(){..}
内部函数和外部函数
- 内部函数:使用static修饰的函数,称作内部函数,内部函数只能在当前文件中调用。
- 外部函数:使用extern修饰的函数,称作外部函数,extern是默认的,可以不写(区分编译环境),也就是说本质上我们所写的函数基本上都是外部函数,建议外部函数在被其他文件调用的时候,在其他文件中声明的时候,加上extern关键字,主要是提高代码的可读性。
,此全局变量可以被其他文件访问,相当于扩展了全局变量的作用域。
extern修饰外部变量,往往是外部变量进行声明,声明该变量是在外部文件中定义的。起到一个标识作用。函数同理。
demo01.c
#include "demo01.h"
int fun_a = 10;
int fun1(){..}
demo02.c
#include "demo01.h"
// 声明访问的外部文件的变量
extern int fun_a;
// 声明访问的外部文件的函数
extern int fun1();
int fun2();
-
register
寄存器存储类型:只能修饰局部变量,用register修饰的局部变量会直接存储到CPU的寄存器中,往往将循环变量设置为寄存器存储类型(提高读的效率)
for (register int i = 0; i < 10; i++)
{
...
}面试题
static关键字的作用
-
static修饰局部变量,延长其生命周期,但不影响局部变量的作用域。
-
static修饰全局变量,不影响全局变量的生命周期,会限制全局变量的作用域仅限本文件内使用(私有化);
-
static修饰函数:此函数就称为内部函数,仅限本文件内调用(私有化)。 static int funa(){..}
内部函数和外部函数
- 内部函数:使用static修饰的函数,称作内部函数,内部函数只能在当前文件中调用。
- 外部函数:使用extern修饰的函数,称作外部函数,extern是默认的,可以不写(区分编译环境),也就是说本质上我们所写的函数基本上都是外部函数,建议外部函数在被其他文件调用的时候,在其他文件中声明的时候,加上extern关键字,主要是提高代码的可读性。






评论前必须登录!
注册