 网硕互联帮助中心
网硕互联帮助中心一、项目简介
本项目是一个基于影刀RPA(ShadowBot)平台开发的自动化解决方案,旨在通过机器人流程自动化技术实现业务流程的自动化处理。项目采用Python语言开发,结合影刀RPA特有的流程设计和元素定位技术,实现了一系列自动化操作流程,可有效提高工作效率,减少人工操作错误。
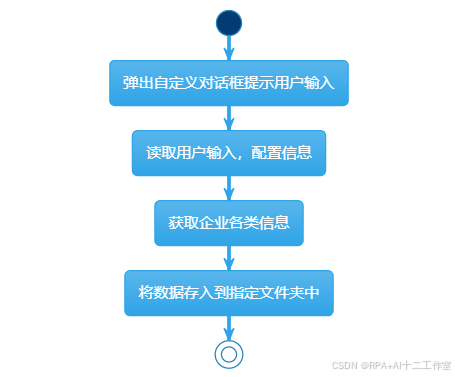
二、项目结构
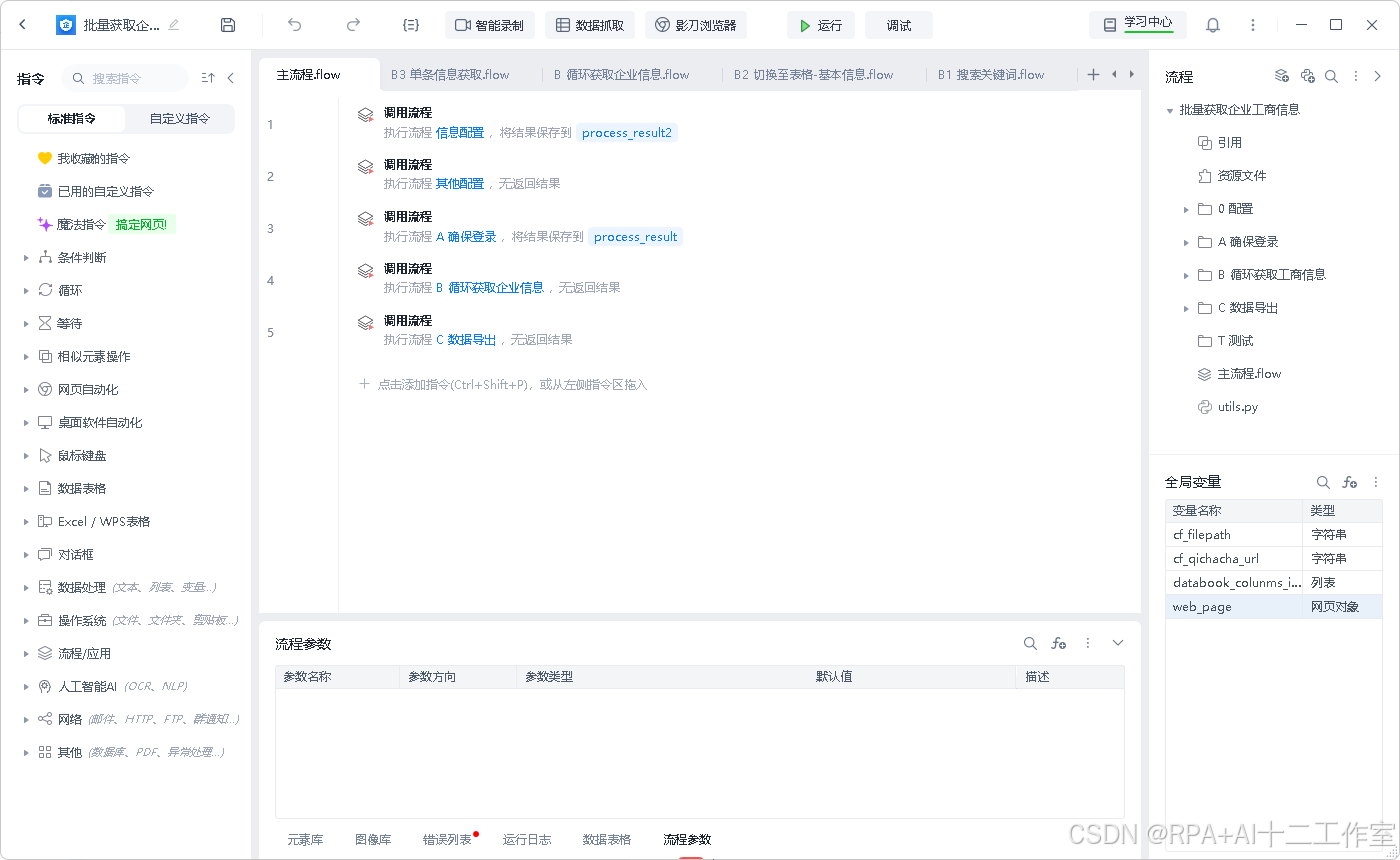
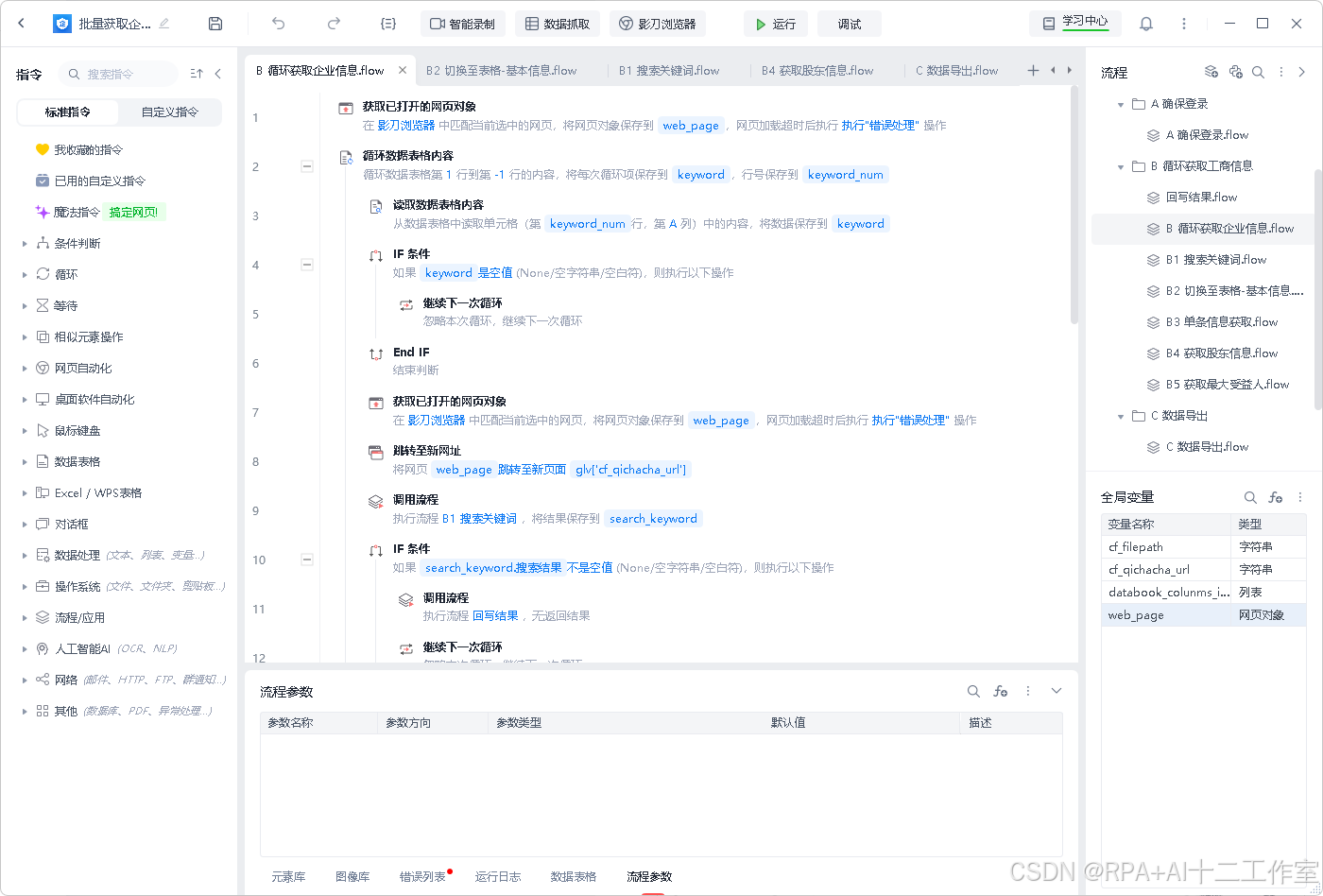
xbot_robot
├── .dev\\ # 开发相关文件
│ ├── icon\\ # 图标资源
│ ├── screenshot\\ # 截图资源
│ ├── *.flow.json # 流程配置文件
│ └── *.pdb # 流程调试文件
├── __pycache__\\ # Python编译缓存
├── resources\\ # 项目资源
├── __init__.py # Python包初始化
├── main.py # 项目入口文件
├── package.py # 项目打包配置
├── utils.py # 通用工具函数
├── process*.py # 自动化流程实现(process2.py至process14.py)
├── images.xml # 图像资源配置
├── imagesV2.xml # 图像资源配置V2
├── selectors.xml # 元素选择器配置
├── selectorsV2.xml # 元素选择器配置V2
└── settings.json # 项目设置
三、项目特点和核心代码
项目特点
核心代码示例
1. 主流程控制(main.py):
import xbot
import xbot_visual
from . import package
def main(args):
try:
# 依次调用各个子流程
process_result2 = xbot_visual.process.run(process="process6", package=__name__, inputs={},
outputs=["dialog_result"], _block=("主流程", 1, "调用流程"))
_ = xbot_visual.process.run(process="process7", package=__name__, inputs={},
outputs=[], _block=("主流程", 2, "调用流程"))
process_result = xbot_visual.process.run(process="process5", package=__name__,
inputs={"web_page": package.variables['web_page']}, outputs=["loop_index"],
_block=("主流程", 3, "调用流程"))
# 更多流程调用…
finally:
pass
2. 网页数据抓取与处理(process2.py):
import xbot
import xbot_visual
from . import package
def main(args):
company_data_list = []
try:
# 获取网页对象
package.variables['web_page'] = xbot_visual.web.get(web_type="cef", mode="activated",
wait_load_completed=True, load_timeout="20", _block=("B3 单条信息获取", 1, "获取已打开的网页对象"))
# 批量数据抓取
web_data_table = xbot_visual.web.element.data_scraping(
browser=package.variables['web_page'], table_element=package.selector("企业工商信息"),
handle_pager=False, _block=("B3 单条信息获取", 4, "批量数据抓取"))
# 数据清洗与处理
for loop_item in xbot_visual.workflow.list_iterator(list=web_data_table, loop_start_index="0",
loop_end_index="-1", _block=("B3 单条信息获取", 12, "ForEach列表循环")):
# 移除空值和特殊字符
loop_item = [x.replace('复制','').strip() if x else "空" for x in loop_item]
# 组装字典数据
assembled_object = xbot_visual.process.run(process="xbot_extensions.shadowbot_list.process9",
package=__name__, inputs={"list_instance1": table_name, "list_instance2": company_data_list},
outputs=["assembled_object"], _block=("B3 单条信息获取", 22, "列表组装"))
finally:
args["company_data_list"] = company_data_list
3. 通用工具函数(utils.py):
def get_selector(selector_name):
"""根据选择器名称从配置文件中获取对应的选择器"""
# 从selectors.xml或selectorsV2.xml中读取选择器配置
# 实现代码…
return selector
def click_element(selector):
"""点击指定选择器对应的元素"""
xbot_visual.mouse.click(selector=selector, click_type="left", _block=("通用操作", 1, "鼠标点击"))
time.sleep(0.5)
def input_text(selector, text):
"""向指定选择器对应的输入框输入文本"""
xbot_visual.keyboard.input_text(selector=selector, text=text, _block=("通用操作", 2, "输入文本"))
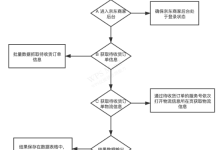
四、适用场景
五、常见问题与建议
常见问题
建议
选择器维护策略:
- 为关键选择器添加版本注释,如<!– 2023-10-20 更新:适配网站改版 –>
- 在process2.py中实现选择器自动验证功能,启动时检查关键选择器有效性
def validate_selectors():
critical_selectors = ["企业工商信息", "登录按钮", "数据表格"]
for selector in critical_selectors:
if not xbot_visual.element.exists(package.selector(selector)):
xbot_visual.log.warning(f"选择器失效: {selector}")
流程调用优化:
- 在main.py的流程调用中添加错误捕获和恢复机制
try:
process_result = xbot_visual.process.run(process="process5", …)
except Exception as e:
xbot_visual.log.error(f"process5执行失败: {e}")
# 尝试恢复机制
xbot_visual.process.run(process="process5_recovery", …)
网页数据抓取增强:
- 在process2.py中增加页面加载完成验证
xbot_visual.web.wait_for_element(package.selector("表格加载完成标志"), timeout=30)
资源管理规范:
- 建立截图文件命名规范:{process_name}_{step}_{timestamp}.png
- 实现截图自动清理功能,保留最近30天文件
多版本选择器管理:
- 在package.py中添加选择器版本控制逻辑
def get_selector(selector_name, version="v2"):
if version == "v2":
return selectorsV2[selector_name]
return selectors[selector_name]





评论前必须登录!
注册