 网硕互联帮助中心
网硕互联帮助中心博主介绍: ✌我是阿龙,一名专注于Java技术领域的程序员,全网拥有10W+粉丝。作为CSDN特邀作者、博客专家、新星计划导师,我在计算机毕业设计开发方面积累了丰富的经验。同时,我也是掘金、华为云、阿里云、InfoQ等平台的优质作者。通过长期分享和实战指导,我致力于帮助更多学生完成毕业项目和技术提升。
技术范围: 我熟悉的技术领域涵盖SpringBoot、Vue、SSM、HLMT、Jsp、PHP、Nodejs、Python、爬虫、数据可视化、小程序、安卓app、大数据、物联网、机器学习等方面的设计与开发。如果你有任何技术难题,我都乐意与你分享解决方案。
主要内容: 我的服务内容包括:免费功能设计、开题报告、任务书、中期检查PPT、系统功能实现、代码编写、论文撰写与辅导、论文降重、长期答辩答疑辅导。我还提供腾讯会议一对一的专业讲解和模拟答辩演练,帮助你全面掌握答辩技巧与代码逻辑。
🍅获取源码请在文末联系我🍅
温馨提示:文末有 CSDN 平台官方提供的阿龙联系方式的名片!
温馨提示:文末有 CSDN 平台官方提供的阿龙联系方式的名片!

目录:
一、详细操作演示视频 在文章的尾声,您会发现一张电子名片👤,欢迎通过名片上的联系方式与我取得联系,以获取更多关于项目演示的详尽视频内容。视频将帮助您全面理解项目的关键点和操作流程。期待与您的进一步交流! 承诺所有开发的项目,全程售后陪伴!!!
2 相关工具及介绍
2.1 Python语言
2.2 hive简介
2.5 Spark
2.4 数据采集
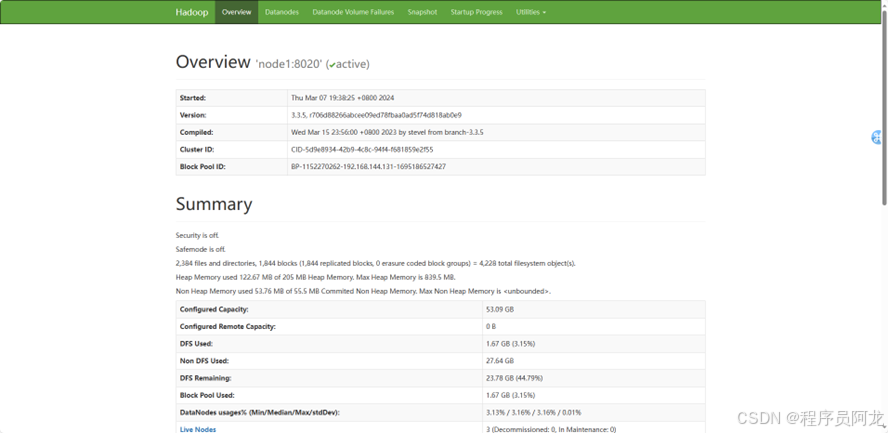
2.5 环境部署
2.6 环境部署
系统实现界面展示:
预测代码大数据分析核心代码介绍:
2.7 测试概述
2.8软件测试原则
2.9测试用例
论文部分参考:编辑
为什么选择我(我可以给你的定制项目推荐核心功能,一对一推荐)实现定制!!!
一、详细操作演示视频 在文章的尾声,您会发现一张电子名片👤,欢迎通过名片上的联系方式与我取得联系,以获取更多关于项目演示的详尽视频内容。视频将帮助您全面理解项目的关键点和操作流程。期待与您的进一步交流! 承诺所有开发的项目,全程售后陪伴!!!

2 相关工具及介绍
2.1 Python语言
Python是由荷兰数学和计算机研究学会的吉多·范罗苏姆于20世纪90年代设计的一款高级语言。Python优雅的语法和动态类型,以及解释型语言的本质,使它成为许多领域脚本编写和快速开发应用的首选语言。Python相比与其他高级语言,开发代码量较小,代码风格简洁优雅,拥有丰富的第三方库。Python的代码风格导致其可读性好,便于维护人员阅读维护,程序更加健壮。Python能够轻松地调用其他语言编写的模块,因此也被成为“胶水语言”。
2.2 hive简介
Hive是一个数据仓库工具,当把特定结构地数据文件存入Hive对应的HDFS目录时,Hive能将其映射成表,并提供类 SQL 查询功能。底层会将sql语句转成MapReduce程序,大大方便程序开发,其中执行引擎可以更换,执行效率大大提高,Hive主要用于解决海量结构化日志的数据统计。
在本课题中,配置Hive为主要数据仓库,有以下几点原因
(1) Hive的操作接口采用类SQL语法,提供快速开发能力。
(2)相对于传统的关系型数据库,Hive更擅长于数据分析。
(3) Hive支持用户自定义函数,用户可根据自己的需求来实现自己的函数。
(4) Hive基于HDFS进行存储,扩展性高,可靠性高。
(5) Hive底层计算引擎可更换。
由于Hive默认底层引擎位MapReduce,MapReduce在遇到迭代式任务时,会将任务落盘至HDFS再进行运算,对于大批量数据处理来说,这很影响效率,所以我们会将引擎改成Tez。
2.3 hadoop技术
Hadoop 是 Apache 软件基金会下的一个开源分布式计算平台,它以分布式文件系统HDFS和MapReduce算法为核心。Hadoop提供了一个可靠的共享存储与分析系统[2]。用户可以在不了解分布式底层细节的情况下,开发分布式程序,充分利用集群的威力进行高速运算和存储。
Hadoop拥有以下4大优势:
(1) 高容错性:Hadoop底层维护多个数据副本,所以即使Hadoop某个计算元素或存储出现故障,也不会导致数据的丢失。
(2) 高扩展性:在集群间分配任务数据,可方便扩展数以千计的节点。
(3) 高效性:在MapReduce的思想下,Hadoop是并行工作的,大大加快了任务的处理速度。
Hadoop实现了一个分布式文件系统( Distributed File System),其中一个组件是HDFS(Hadoop Distributed File System)。HDFS有高容错性的特点,并且设计用来部署在低廉的(low-cost)硬件上;而且它提供高吞吐量(high throughput)来访问应用程序的数据,适合那些有着超大数据集(large data set)的应用程序。HDFS放宽了(relax)POSIX的要求,可以以流的形式访问(streaming access)文件系统中的数据。
在本课题中,由于其中的Mapreduce框架其设计初衷并不是为了满足循环迭代式数据流处理,因此在多并行运行的数据可复用场景中存在诸多计算效率等问题,Hadoop框架主要用于数据存储。
2.5 Spark
是一种DAG(有向无环图)的,基于内存的快速、通用、可扩展的大数据分析计算引擎。Spark 是分布式数据快速分析项目。它的核心技术是弹性分布式数据集(Resilient Distributed Datasets),简称RDD,提供了比 MapReduce 丰富的模型,可以快速在内存中对数据集进行多次迭代,不像MapReduce需要落盘数据才能进行迭代式运算,可支持复杂的数据挖掘算法和图形计算算法[4]。Spark的运行模式包括Local、Standalone、Yarn及Mesos几种。其中Local模式仅用于本地开发,Mesos模式国内几乎不用。在公司中因为大数据服务基本搭载Yarn集群调度,因此Spark On Yarn模式会用的比较多。
Spark是一个基于内存的,用于大规模数据处理的统一分析引擎,其运算速度可以达到Mapreduce的10-100倍。具有如下特点:内存计算。Spark优先将数据加载到内存中,数据可以被快速处理,并可启用缓存。shuffle过程优化。和Mapreduce的shuffle过程中间文件频繁落盘不同,Spark对Shuffle机制进行了优化,降低中间文件的数量并保证内存优先。RDD计算模型。Spark具有高效的DAG调度算法,同时将RDD计算结果存储在内存中,避免重复计算。
2.4 数据采集
考虑到更方便后续对数据的处理和分析,在采集视频数据后,选择了将爬取到的数据存入CSV文件中。CSV提供了一种轻量级、便捷的方式来批量写入数据且CSV文件较小,便于在网络间传输和分享,这对于分布式计算框架如Hadoop非常有利。而且CSV以纯文本形式存储表格数据,每行代表一条记录,各字段由逗号(或其他分隔符)分隔。这种结构化数据格式可以被各种编程语言和工具解析,包括Hadoop生态中的MapReduce程序。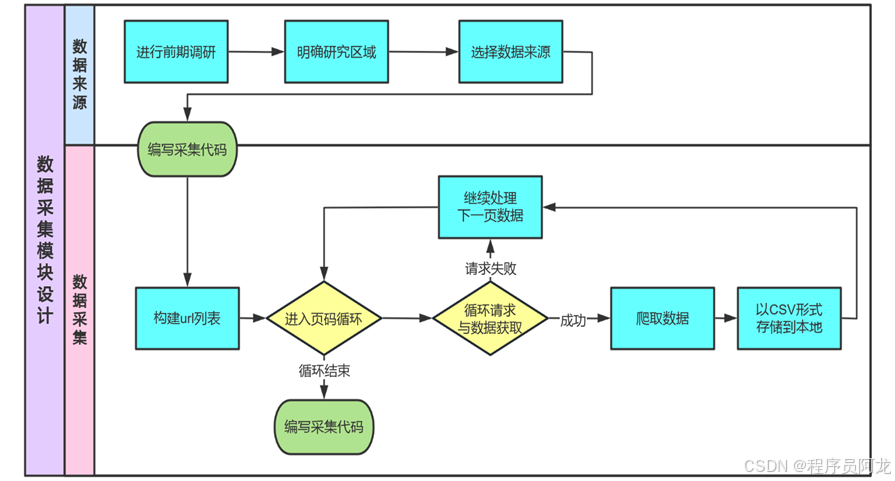
2.5 环境部署
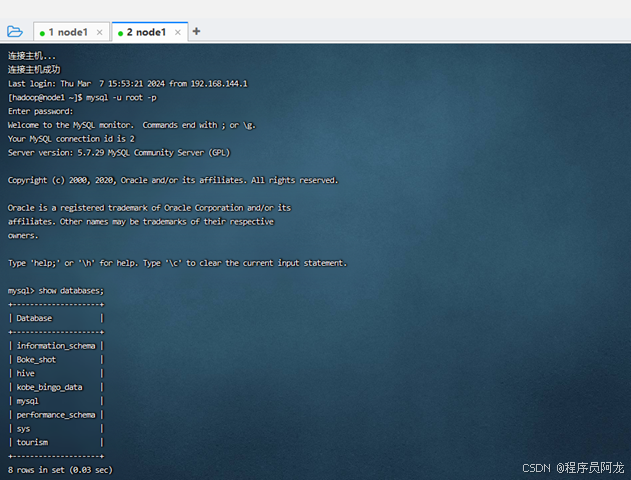
本文的软件开发环境及运行环境如下。操作系统:Linux;JDK:1.8.0_241 版本;Hadoop:hadoop-3.3.5版本;虚拟机:VMware-16.0;数据库工具:mysql-5.7.29版本、SQLyog-13.2.0版本;框架:Flask;可视化工具:Echarts。
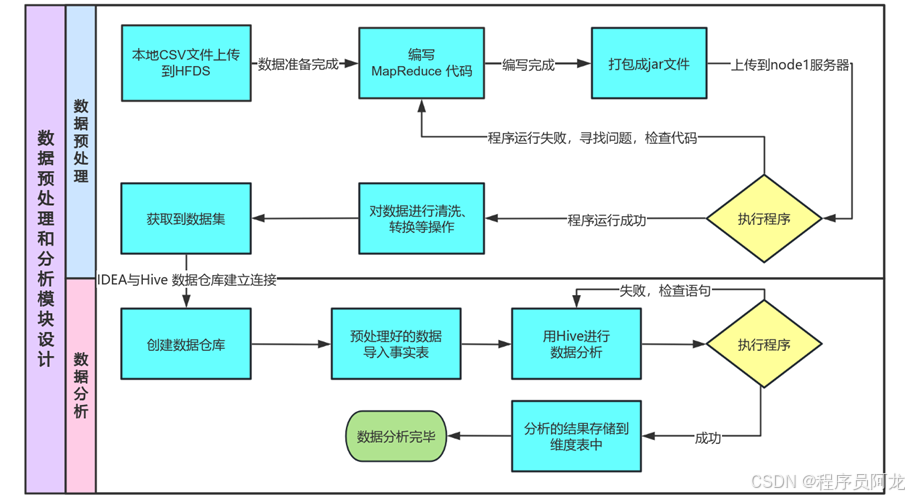
为了实现基于大数据技术的视频数据分析与研究,需要搭建Hadoop集群,它可提供海量数据的分布式存储、分布式计算和分布式管理功能[9]。首先创建三台Linux系统的虚拟机,修改三台虚拟机的IP(192.168.144.131、192.168.144.132、192.168.144.133)并添加免密登录和安装JDK与Hadoop,修改Hadoop配置文件(hadoop-env.sh、core-site.xml、hdfs-site.xml、mapred-site.xml、yarn-site.xml),在终端运行hadoop namenode -format命令进行格式化格式化HDFS,最后启动Hadoop(start-all.sh),能在浏览器中http://192.168.144.131:9870查看是否HDFS正常运行,访问成功如图4.1所示。
2.6 环境部署
本文的软件开发环境及运行环境如下。操作系统:Linux;JDK:1.8.0_241 版本;Hadoop:hadoop-3.3.5版本;虚拟机:VMware-16.0;数据库工具:mysql-5.7.29版本、SQLyog-13.2.0版本;框架:Flask;可视化工具:Echarts。
为了实现基于大数据技术的视频数据分析与研究,需要搭建Hadoop集群,它可提供海量数据的分布式存储、分布式计算和分布式管理功能[9]。首先创建三台Linux系统的虚拟机,修改三台虚拟机的IP(192.168.144.131、192.168.144.132、192.168.144.133)并添加免密登录和安装JDK与Hadoop,修改Hadoop配置文件(hadoop-env.sh、core-site.xml、hdfs-site.xml、mapred-site.xml、yarn-site.xml),在终端运行hadoop namenode -format命令进行格式化格式化HDFS,最后启动Hadoop(start-all.sh),能在浏览器中http://192.168.144.131:9870查看是否HDFS正常运行,访问成功如图4.1所示。
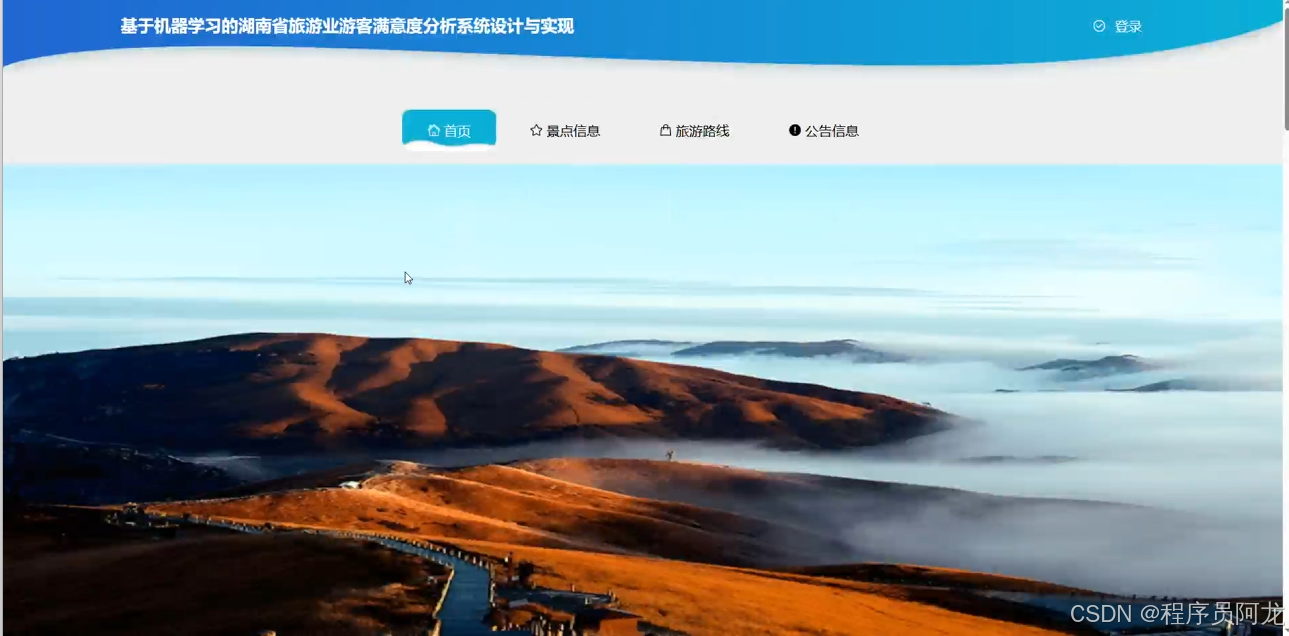
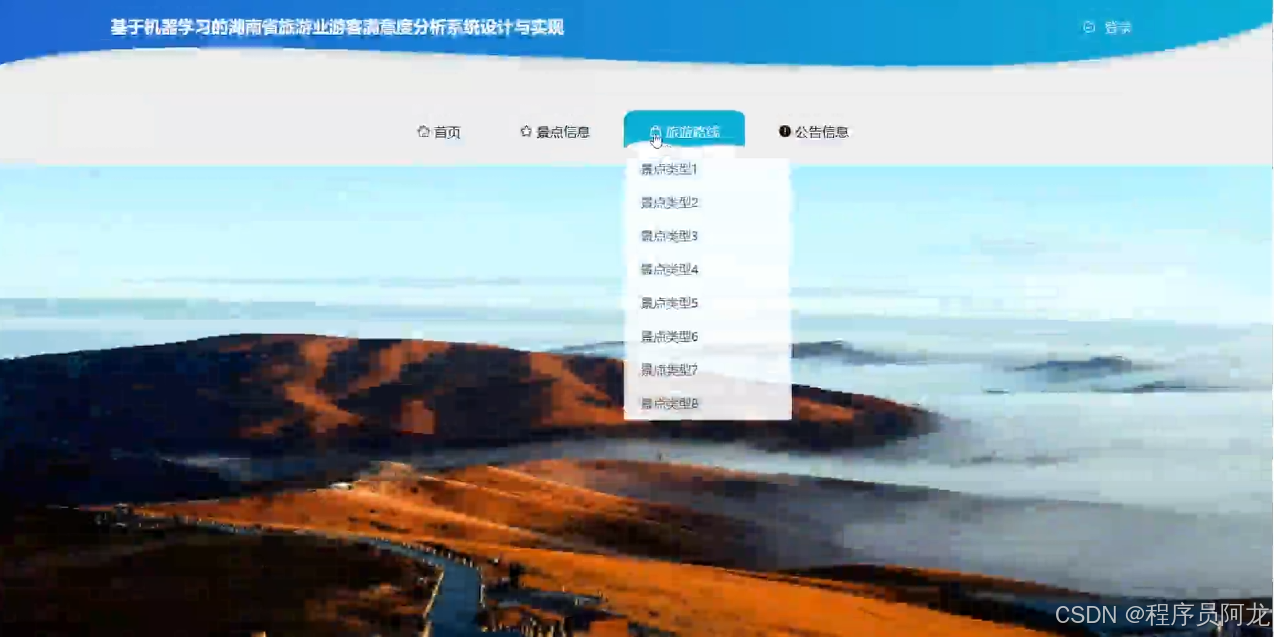
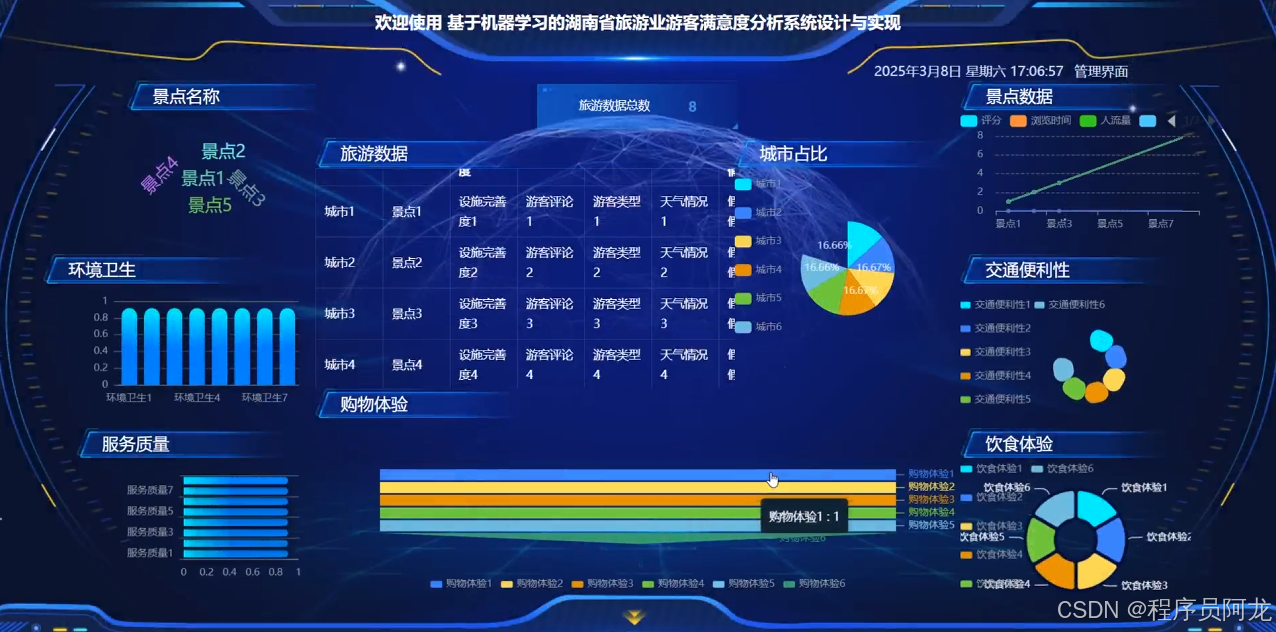
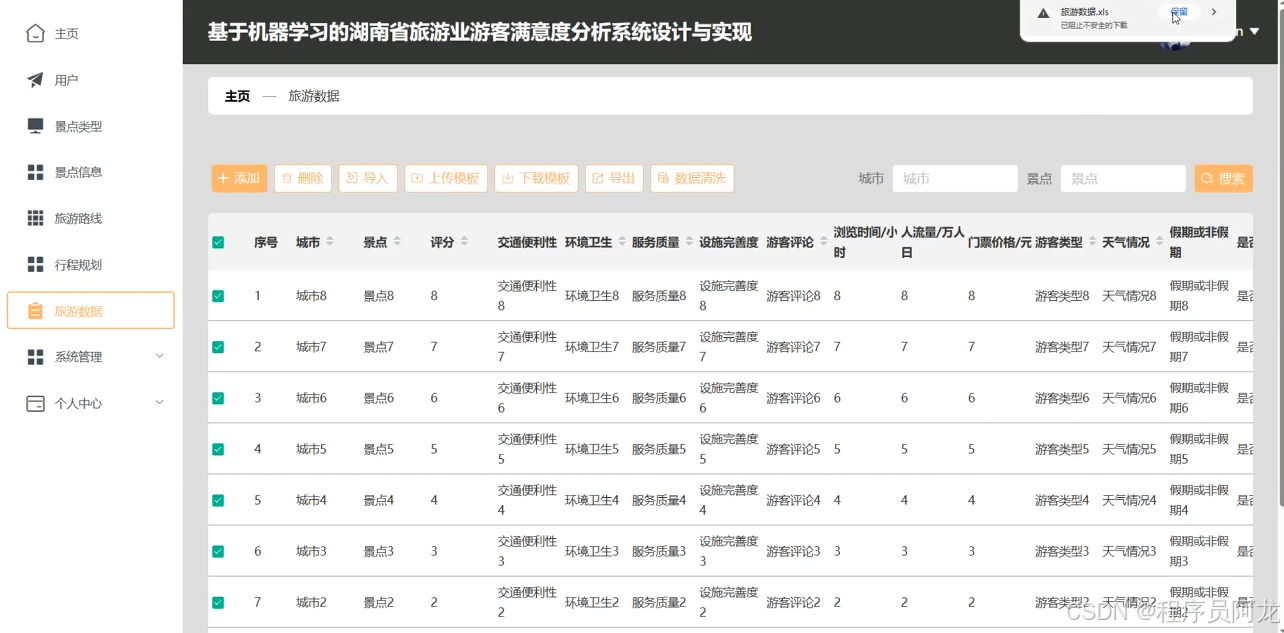
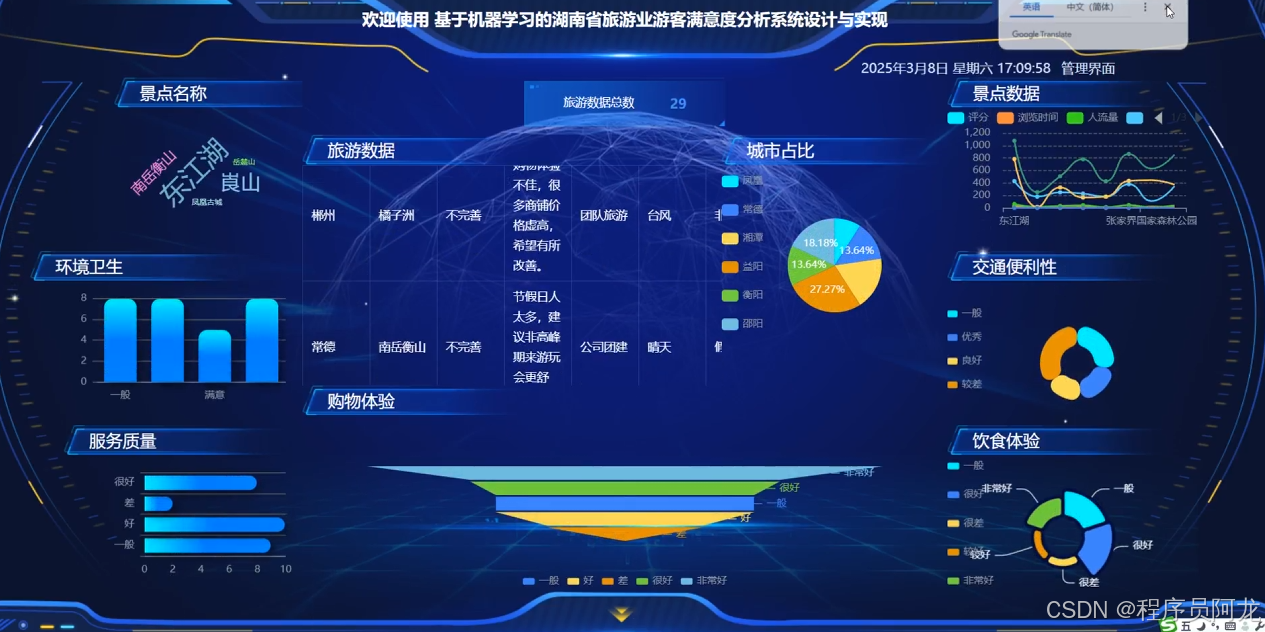
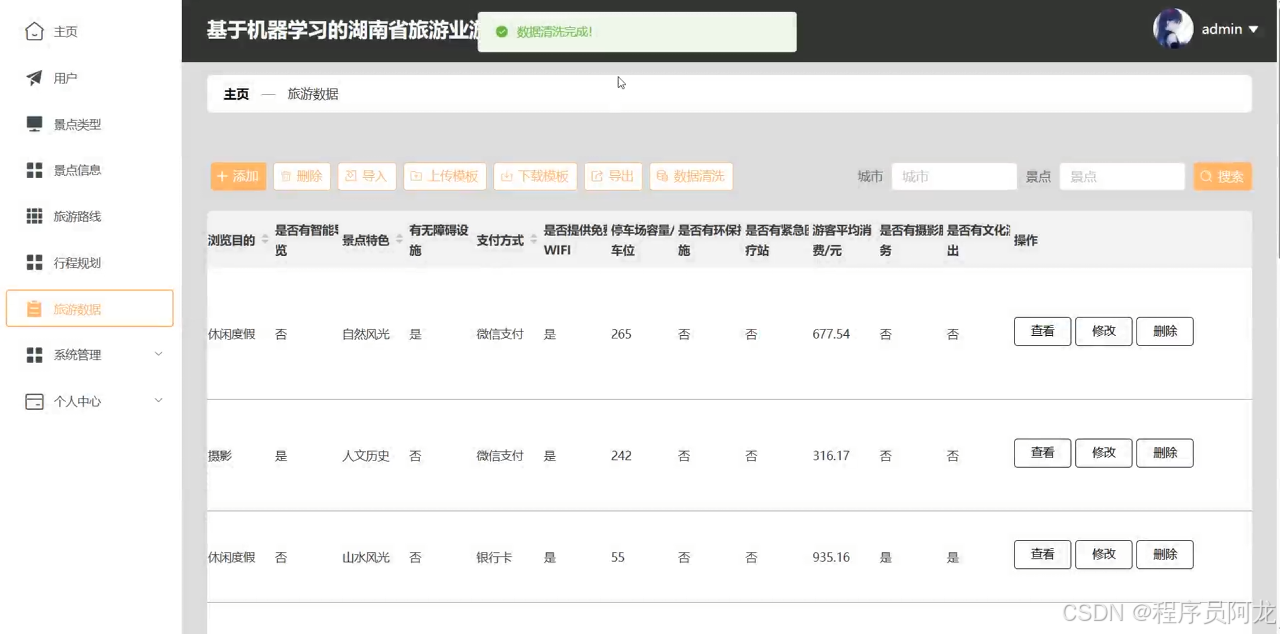
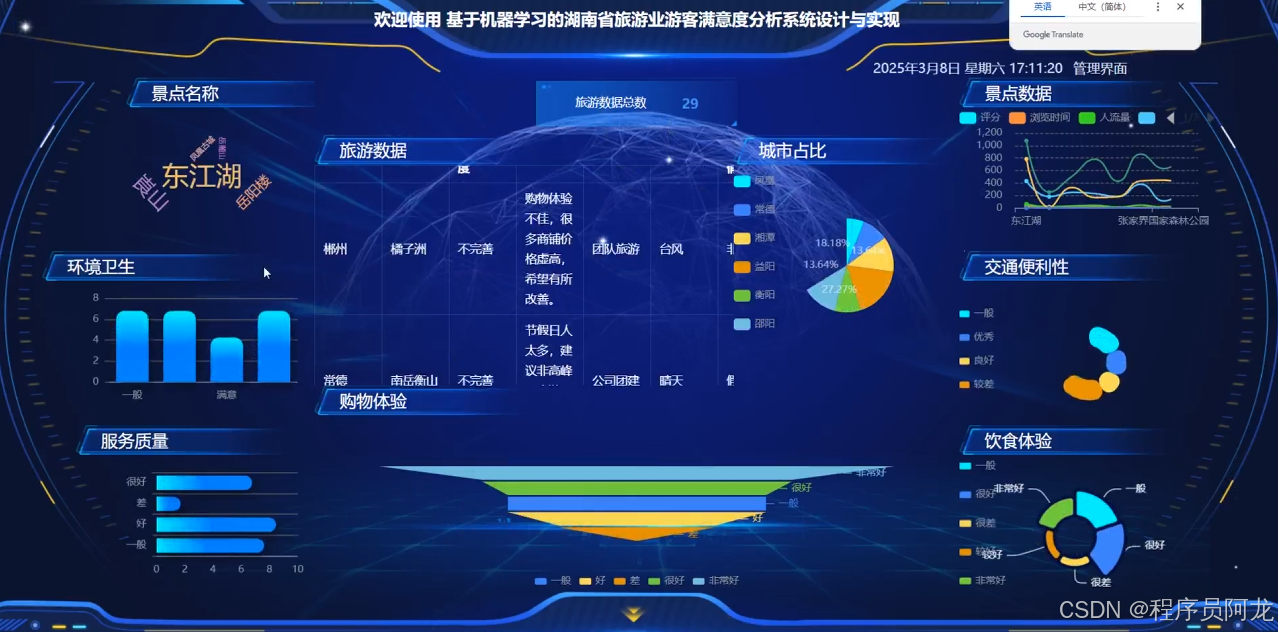
 系统实现界面展示:
系统实现界面展示:
预测代码大数据分析核心代码介绍:
'user':user,
'password': passwd,
'database': dbName,
'port':port
}
#获取预测可视化图表接口
@main_bp.route("/python0z9ftoqa/tourismdataforecast/forecastimgs", methods=['GET','POST'])
def tourismdataforecast_forecastimgs():
if request.method in ["POST", "GET"]:
msg = {'code': normal_code, 'message': 'success'}
# 指定目录
directory = os.path.join(parent_directory, "api", "templates", "upload", "tourismdataforecast")
# 获取目录下的所有文件和文件夹名称
all_items = os.listdir(directory)
# 过滤出文件(排除文件夹)
files = [f'upload/tourismdataforecast/{item}' for item in all_items if os.path.isfile(os.path.join(directory, item))]
msg["data"] = files
return jsonify(msg)
@main_bp.route("/python0z9ftoqa/tourismdataforecast/forecast", methods=['GET','POST'])
#预测接口
def tourismdataforecast_forecast():
import datetime
if request.method in ["POST", "GET"]:#get、post请求
msg = {'code': normal_code, 'message': 'success'}
#获取数据集
req_dict = session.get("req_dict")
connection = pymysql.connect(**mysql_config)
query = "SELECT transportationconvenience,environmentalsanitation,qualityofservice,facilitycompleteness, score,scenicspot FROM tourismdata"
#处理缺失值
data = pd.read_sql(query, connection).dropna()
id = req_dict.pop('id',None)
req_dict.pop('addtime',None)
grouped = data.groupby([
'scenicspot',
])
df = pd.DataFrame(columns=[
'score',
'scenicspot',
])
for (scenicspot), group in grouped:
y_predict = to_forecast(group,req_dict,''.join((scenicspot)).replace("/",""))
if not y_predict.empty:
y_predict['scenicspot'] = scenicspot
df = pd.concat([df, y_predict], ignore_index=True)
#创建数据库连接,将DataFrame 插入数据库
connection_string = f"mysql+pymysql://{mysql_config['user']}:{mysql_config['password']}@{mysql_config['host']}:{mysql_config['port']}/{mysql_config['database']}"
engine = create_engine(connection_string)
try:
if req_dict :
#遍历 DataFrame,并逐行更新数据库
with engine.connect() as connection:
for index, row in df.iterrows():
sql = """
INSERT INTO tourismdataforecast (id
,score
)
VALUES (%(id)s
,%(score)s
)
ON DUPLICATE KEY UPDATE
score = VALUES(score)
"""
connection.execute(sql, {'id': id
, 'score': row['score']
})
else:
df.to_sql('tourismdataforecast', con=engine, if_exists='append', index=False)
print("数据更新成功!")
except Exception as e:
print(f"发生错误: {e}")
finally:
engine.dispose() # 关闭数据库连接
return jsonify(msg)
#训练数据并进行预测
def to_forecast(data,req_dict,value):
if len(data) < 5:
print(f"的样本数量不足: {len(data)}")
return pd.DataFrame()
#处理特征值和目标值
labels={}
for key in data.keys():
if pd.api.types.is_string_dtype(data[key]):
label_encoder = LabelEncoder()
labels[key] = label_encoder
data[key] = label_encoder.fit_transform(data[key])
#数据集划分
X = data[[
'transportationconvenience',
'environmentalsanitation',
'qualityofservice',
'facilitycompleteness',
]]
y = data[[
'score',
]]
x_train, x_test, y_train, y_test = train_test_split(X, y,test_size=0.2, random_state=22)
#构建预测特征值
#根据输入的特征值去预测
if req_dict:
req_dict.pop('addtime',None)
future_df = pd.DataFrame([req_dict])
for key in future_df.keys():
if key in labels:
encoder = labels[key]
values = future_df[key][0]
try:
values = encoder.transform([values])[0]
except ValueError as e: #处理未见过的标签
values = np.array([encoder.transform([v])[0] if v in encoder.classes_ else -1 for v in values]).sum()
future_df[key][0] = values
else:
future_df = x_test
#特征工程-标准化
estimator_file = os.path.join(parent_directory, "tourismdataforecast.pkl")
estimator = RandomForestRegressor(n_estimators=100, random_state=42)
_, num_columns = y_train.shape
if num_columns>=2:
estimator.fit(x_train, y_train)
else:
estimator.fit(x_train, y_train.values.ravel())
y_pred = estimator.predict(x_test)
plt.rcParams['font.sans-serif'] = ['SimHei','simhei'] # 使用黑体 SimHei
plt.rcParams['axes.unicode_minus'] = False # 解决负号 '-' 显示为方块的问题
# 绘制预测值与实际值的散点图
plt.scatter(y_test, y_test, alpha=0.5)
plt.plot([y_test.min(), y_test.max()], [y_test.min(), y_test.max()], color='red', lw=2)
plt.xlabel("实际值")
plt.ylabel("预测值")
plt.title("实际值与预测值(随机森林回归)")
directory =os.path.join(parent_directory,"api", "templates","upload","tourismdataforecast","figure.png")
os.makedirs(os.path.dirname(directory), exist_ok=True)
plt.savefig(directory)
plt.clf()
# 绘制特征重要性
feature_importances = estimator.feature_importances_
features = [
'transportationconvenience',
'environmentalsanitation',
'qualityofservice',
'facilitycompleteness',
]
plt.figure(figsize=(8, 4))
sns.barplot(x=feature_importances, y=features)
plt.xlabel("重要性得分")
plt.ylabel("特征")
plt.title("特征重要性")
if value!=None:
directory =os.path.join(parent_directory,"api", "templates","upload","tourismdataforecast","{value}_figure.png")
os.makedirs(os.path.dirname(directory), exist_ok=True)
plt.savefig(directory)
else:
directory =os.path.join(parent_directory,"api", "templates","upload","tourismdataforecast","figure_other.png")
os.makedirs(os.path.dirname(directory), exist_ok=True)
plt.savefig(directory)
plt.clf()
#保存模型

2.7 测试概述
系统测试就是对项目是否存在错误而运行程序的一种检测方式。系统测试对于一个软件来说极为重要,并且在开发过程中占有很大的比重。每一次功能的实现都伴随着很多次的测试。它是软件是否能用的检测环节,对于软件质量的评估有着重要影响。系统能否被验收成功是测试中最后一个至关重要的环节。
2.8软件测试原则
当进行软件测试时,有一些原则需要遵循,以确保测试的有效性和效率。
第一:测试应该尽早开始。在需求分析和系统设计阶段就应该进行测试准备,以便尽早发现系统的不足之处。这样可以降低修复成本,提高开发效率。测试人员应该在分析需求时就参与进来,确保需求具备可测试性和正确性。
第二:测试应该是全面的。测试应该覆盖软件的各个功能模块和不同的使用场景,以确保软件在各种情况下都能正常运行。测试还应该关注软件的性能、安全性和可用性等方面,以全面评估软件的质量。
随着软件开发的复杂性增加,手动测试已经无法满足需求。自动化测试可以提高测试的效率和准确性,减少人为错误。通过编写自动化测试脚本,可以快速执行大量的测试用例,并及时发现问题。软件的开发是一个迭代的过程,每个迭代都会引入新功能和修复旧问题。因此,测试也应该是一个持续的过程,与开发同步进行。持续集成和持续交付等技术可以帮助实现持续测试,确保软件在每个迭代中都能达到预期的质量标准。通过测试不仅仅是为了发现问题,更重要的是提供有价值的反馈给开发人员。测试人员应该及时向开发人员报告问题,并提供详细的复现步骤和环境信息,以便开发人员能够快速定位和解决问题。
2.9测试用例
(1)用户登陆测试用例
表 6-1 用户登录用例表
|
项目/软件 |
编制时间 |
20xx/xx/xx |
||||
|
功能模块名 |
用户登陆模块 |
用例编号 |
xxxx |
|||
|
功能特性 |
用户身份验证 |
|||||
|
测试目的 |
验证是否输入合法的信息,允许合法登陆,阻止非法登陆 |
|||||
|
测试数据 |
用户名=1密码=a1身份= 非认证用户 |
|||||
|
操作步骤 |
操作描述 |
数 据 |
期望结果 |
实际结果 |
状态 |
|
|
1 |
输入用户名和密码 |
用户名= 1密码=1 |
显示进入后的页面。 |
同期望结果。 |
正常 |
|
|
2 |
输入用户名和密码 |
用户名= 1密码=aaa |
显示警告信息“不存在该用户名或密码错误!” |
同期望结果。 |
正常 |
|
|
3 |
输入用户名和密码 |
用户名= aaa密码=1 |
显示警告信息“不存在该用户名或密码错误” |
同期望结果。 |
正常 |
|
|
4 |
输入用户名和密码 |
用户名=“” 密码=“” |
显示警告信息“用户名密码不能为空!” |
同期望结果。 |
正常 |
|
(2)用户注册测试用例
表 6-2 用户注册用例表
|
项目/软件 |
编制时间 |
20xx/xx/xx |
|||||
|
功能模块名 |
用户注册模块 |
用例编号 |
xxxx |
||||
|
功能特性 |
用户注册 |
||||||
|
测试目的 |
验证私注册是否成功,注册数据是否合法 |
||||||
|
测试数据 |
用户名=aaa 密码=aaa电子邮件=dwa@qq.com |
||||||
|
操作步骤 |
操作描述 |
数 据 |
期望结果 |
实际结果 |
测试状态 |
||
|
1 |
输入注册数据 |
用户名= aaa密码=aaa 电子邮件=dwa@qq.com |
提示:注册成功!转入用户主页 |
同期望结果。 |
正常 |
||
|
2 |
输入注册数据 |
用户名= aaa密码=aaa 电子邮件=dwa@qq.com |
提示:用户名已注册 |
同期望结果。 |
正常 |
||
|
3 |
输入注册数据 |
用户名= aaa密码=”” 电子邮件=dwa@qq.com |
提示:密码不能为空 |
同期望结果。 |
正常 |
||
|
4 |
输入注册数据 |
密码=aaa 电子邮件=dwa@qq.com |
提示:用户名为空 |
同期望结果。 |
正常 |
||



 论文部分参考:
论文部分参考:
为什么选择我(我可以给你的定制项目推荐核心功能,一对一推荐)实现定制!!!
我是程序员阿龙,专注于软件开发,拥有丰富的编程能力和实战经验。在过去的几年里,我辅导了上千名学生,帮助他们顺利完成毕业项目,同时我的技术分享也吸引了超过50W+的粉丝。我是CSDN特邀作者、博客专家、新星计划导师,并在Java领域内获得了多项荣誉,如博客之星。我的作品也被掘金、华为云、阿里云、InfoQ等多个平台推荐,成为各大平台的优质作者。 已经为上百名同学获得优秀毕业生! 源码获取 文章下方名片联系我即可~ 大家点赞、收藏、关注、评论啦 、查看👇🏻获取联系方式👇🏻 精彩专栏推荐订阅:在下方专栏









评论前必须登录!
注册