 网硕互联帮助中心
网硕互联帮助中心雷达阵列信号处理中的最大似然方法
A. L. Swindlehurst and P. Stoica, “Maximum likelihood methods in radar array signal processing,” in Proceedings of the IEEE, vol. 86, no. 2, pp. 421-441, Feb. 1998, doi: 10.1109/5.659495.
本文探讨了在雷达目标信号被传感器阵列观测时,如何在未知二阶统计特性的干扰环境中,使用鲁棒且计算高效的最大似然算法来估计目标参数。文章提出了两种数据模型:一种使用目标到达方向和信号幅度作为参数,另一种是使用通用目标"空间特征"的简化非结构化模型。通过引入扩展不变性原理,展示了如何将从简单模型获得的较不精确的最大似然估计进行改进,以渐近地达到使用结构化模型所能获得的性能。
引言
在主动雷达系统中,主要目标是在噪声、地杂波和电子对抗措施(如干扰)存在的情况下检测目标并估计其参数。对于机载雷达应用,感兴趣的参数包括目标信号幅度(与其雷达截面积相关)、到达方向(DOA)、距离和多普勒频率。即使只有单个目标存在,由于需要搜索的参数空间体积巨大,这个检测和估计问题也相当艰巨。因此,计算的简便性和效率至关重要。
标准解决方案涉及使用经典的时空滤波器,可以是数据无关的(如延迟求和波束形成器)或"自适应"的(如使用线性约束、最大信号干扰噪声比准则等)。最大似然(ML)方法在这个问题上没有被广泛考虑,主要是因为它们被认为计算过于复杂,而且在接受所需的建模假设方面存在一些阻力。最近的工作表明,对于高斯干扰中具有未知空间协方差的单个目标源,ML解可以通过对目标DOA和多普勒进行二维搜索,然后进行广义似然比检验(GLRT)来获得。
雷达数据模型
结构化阵列模型
假设一个mmm元天线阵列使用某组发射权重发射一系列脉冲。在给定的相干处理间隔(CPI)期间,存在于特定距离单元中的目标可以建模为产生以下基带向量信号(经过脉冲压缩和解调后):
target signal=b0a(θ0)ejω0t,t=1,⋯ ,N\\text{target signal} = b_0\\mathbf{a}(\\theta_0)e^{j\\omega_0 t}, \\quad t = 1, \\cdots, Ntarget signal=b0a(θ0)ejω0t,t=1,⋯,N
其中b0b_0b0是信号的复振幅,ω0\\omega_0ω0是由阵列平台和目标之间的相对运动引起的多普勒频移,a(θ)\\mathbf{a}(\\theta)a(θ)是阵列对从方位角θ0\\theta_0θ0到达的平面波的响应。向量a(θ)\\mathbf{a}(\\theta)a(θ)被假定为缩放,使得其第一个元素对所有θ\\thetaθ都为1。
假设在任何给定的距离单元中最多存在一个目标,阵列在时间ttt的采样向量输出或"快照"可以写成:
x(t)=b0a(θ0)ejω0t+e(t)∈Cm,t=1,⋯ ,N\\mathbf{x}(t) = b_0\\mathbf{a}(\\theta_0)e^{j\\omega_0 t} + \\mathbf{e}(t) \\in \\mathbb{C}^m, \\quad t = 1, \\cdots, Nx(t)=b0a(θ0)ejω0t+e(t)∈Cm,t=1,⋯,N
其中如果没有目标存在则b0b_0b0取为零,e(t)\\mathbf{e}(t)e(t)表示由于杂波、接收机噪声和干扰引起的干扰。由于e(t)\\mathbf{e}(t)e(t)依赖于如此多的物理变量,为其推导确定性模型是有问题的,通常也是不实际的。首先,我们选择将e(t)\\mathbf{e}(t)e(t)建模为在CPI的NNN个样本上的平稳、时间白性高斯随机过程,具有零均值和未知空间协方差Q\\mathbf{Q}Q。
非结构化阵列模型
在上面的讨论中,我们已经明确地用θ0\\theta_0θ0来表示阵列响应。当然,要估计θ0\\theta_0θ0,向量值函数a(θ)\\mathbf{a}(\\theta)a(θ)必须对所有感兴趣的θ\\thetaθ都是已知的。函数a(θ)\\mathbf{a}(\\theta)a(θ)可以通过阵列的实验或分析校准获得,但这种校准程序永远不会完全准确,这是由于天线元件的增益和相位响应误差、互耦、量化和插值误差,以及由于天气、环境等变化导致的接收机电子特性漂移。根据实际阵列响应与其模型的差异程度,检测和估计性能可能会显著下降。出于这个原因,我们在非结构化阵列模型下开发了目标检测的GLRT,该模型本质上不依赖于阵列校准数据的可用性。考虑以下数据模型,其中信号幅度和阵列响应已合并为单个非结构化向量项:
x(t)=α0ejω0t+e(t),t=1,⋯ ,N\\mathbf{x}(t) = \\boldsymbol{\\alpha}_0 e^{j\\omega_0 t} + \\mathbf{e}(t), \\quad t = 1, \\cdots, Nx(t)=α0ejω0t+e(t),t=1,⋯,N
向量α0\\boldsymbol{\\alpha}_0α0被称为目标的"空间特征",在这个模型中取代了b0a(θ0)b_0\\mathbf{a}(\\theta_0)b0a(θ0),简单地被视为一组未知的复常数。
扩展不变性原理
假设为了估计上述雷达参数,我们有一个损失函数(例如,ML准则),可以用η\\boldsymbol{\\eta}η或η~\\tilde{\\boldsymbol{\\eta}}η~参数化。将得到的准则分别表示为VN(η)V_N(\\boldsymbol{\\eta})VN(η)和V~N(η~)\\tilde{V}_N(\\tilde{\\boldsymbol{\\eta}})V~N(η~)。如果存在一个(可逆的)映射η=g(η~)∈Dη,∀η~∈Dη~\\boldsymbol{\\eta} = g(\\tilde{\\boldsymbol{\\eta}}) \\in D_\\eta, \\quad \\forall\\tilde{\\boldsymbol{\\eta}} \\in D_{\\tilde{\\eta}}η=g(η~)∈Dη,∀η~∈Dη~,使得准则相等,经典的估计理论不变性原理可以被调用来证明最小化VN(η)V_N(\\boldsymbol{\\eta})VN(η)和V~N(η~)\\tilde{V}_N(\\tilde{\\boldsymbol{\\eta}})V~N(η~)的等价性。
扩展不变性原理(EXIP)通过以下定理给出:
定理1:定义
η^=argminηVN(η)\\hat{\\boldsymbol{\\eta}} = \\arg\\min_{\\boldsymbol{\\eta}} V_N(\\boldsymbol{\\eta})η^=argηminVN(η)
η~^=argminη~V~N(η~)\\hat{\\tilde{\\boldsymbol{\\eta}}} = \\arg\\min_{\\tilde{\\boldsymbol{\\eta}}} \\tilde{V}_N(\\tilde{\\boldsymbol{\\eta}})η~^=argη~minV~N(η~)
并假设存在满足η~=f(η)∈Dη~,∀η∈Dη\\tilde{\\boldsymbol{\\eta}} = f(\\boldsymbol{\\eta}) \\in D_{\\tilde{\\eta}}, \\quad \\forall\\boldsymbol{\\eta} \\in D_\\etaη~=f(η)∈Dη~,∀η∈Dη的函数fff。假设fff在其输入参数的整个定义域上是一对一的且定义良好。如果limN→∞η~^=limN→∞f(η^)\\lim_{N \\to \\infty} \\hat{\\tilde{\\boldsymbol{\\eta}}} = \\lim_{N \\to \\infty} f(\\hat{\\boldsymbol{\\eta}})limN→∞η~^=limN→∞f(η^),则
η^=argminη[η~^−f(η)]TW[η~^−f(η)]\\hat{\\boldsymbol{\\eta}} = \\arg\\min_{\\boldsymbol{\\eta}} [\\hat{\\tilde{\\boldsymbol{\\eta}}} – f(\\boldsymbol{\\eta})]^T \\mathbf{W} [\\hat{\\tilde{\\boldsymbol{\\eta}}} – f(\\boldsymbol{\\eta})]η^=argηmin[η~^−f(η)]TW[η~^−f(η)]
渐近地(对于大NNN)等价于估计η^\\hat{\\boldsymbol{\\eta}}η^,其中
W=E{∂V~N(η~^)∂η~^∂η~^T}η~^=η~\\mathbf{W} = \\mathcal{E}\\left\\{\\frac{\\partial \\tilde{V}_N(\\hat{\\tilde{\\boldsymbol{\\eta}}})}{\\partial \\hat{\\tilde{\\boldsymbol{\\eta}}} \\partial \\hat{\\tilde{\\boldsymbol{\\eta}}}^T}\\right\\}_{\\hat{\\tilde{\\boldsymbol{\\eta}}} = \\tilde{\\boldsymbol{\\eta}}}W=E{∂η~^∂η~^T∂V~N(η~^)}η~^=η~
最大似然估计
结构化模型
完全参数化模型的NNN个数据样本的负对数似然函数在乘法和加法常数内容易表示为:
VN(η)=log∣Q∣+Tr{Q−1C(b,θ,ω)}V_N(\\boldsymbol{\\eta}) = \\log |\\mathbf{Q}| + \\text{Tr}\\{\\mathbf{Q}^{-1}\\mathbf{C}(b, \\theta, \\omega)\\}VN(η)=log∣Q∣+Tr{Q−1C(b,θ,ω)}
其中
C(b,θ,ω)=1N∑t=1N[x(t)−ba(θ)ejωt][x(t)−ba(θ)ejωt]∗\\mathbf{C}(b, \\theta, \\omega) = \\frac{1}{N}\\sum_{t=1}^{N}[\\mathbf{x}(t) – b\\mathbf{a}(\\theta)e^{j\\omega t}][\\mathbf{x}(t) – b\\mathbf{a}(\\theta)e^{j\\omega t}]^*C(b,θ,ω)=N1t=1∑N[x(t)−ba(θ)ejωt][x(t)−ba(θ)ejωt]∗
关于Q\\mathbf{Q}Q和bbb的最小化可以显式执行。使用标准矩阵微积分结果,关于Q\\mathbf{Q}Q的准则梯度容易表示为:
∂VN(η)∂Q=Q−1−Q−1C(b,θ,ω)Q−1\\frac{\\partial V_N(\\boldsymbol{\\eta})}{\\partial \\mathbf{Q}} = \\mathbf{Q}^{-1} – \\mathbf{Q}^{-1}\\mathbf{C}(b, \\theta, \\omega)\\mathbf{Q}^{-1}∂Q∂VN(η)=Q−1−Q−1C(b,θ,ω)Q−1
从中可以清楚地看出,Q\\mathbf{Q}Q的ML估计由下式给出:
Q^s=C(b,θ,ω)\\hat{\\mathbf{Q}}_s = \\mathbf{C}(b, \\theta, \\omega)Q^s=C(b,θ,ω)
当将此代入准则时,集中准则为:
VN(b,θ,ω)=log∣C(b,θ,ω)∣+mV_N(b, \\theta, \\omega) = \\log |\\mathbf{C}(b, \\theta, \\omega)| + mVN(b,θ,ω)=log∣C(b,θ,ω)∣+m
可以进一步关于bbb集中,得到:
b^s=a∗(θ^s)R^s−1y(ω^s)a∗(θ^s)R^s−1a(θ^s)\\hat{b}_s = \\frac{\\mathbf{a}^*(\\hat{\\theta}_s)\\hat{\\mathbf{R}}_s^{-1}\\mathbf{y}(\\hat{\\omega}_s)}{\\mathbf{a}^*(\\hat{\\theta}_s)\\hat{\\mathbf{R}}_s^{-1}\\mathbf{a}(\\hat{\\theta}_s)}b^s=a∗(θ^s)R^s−1a(θ^s)a∗(θ^s)R^s−1y(ω^s)
θ^s,ω^s=argmaxθ,ω∣a∗(θ)R^−1y(ω)∣2[1−y∗(ω)R^−1y(ω)][a∗(θ)R^−1a(θ)]\\hat{\\theta}_s, \\hat{\\omega}_s = \\arg\\max_{\\theta,\\omega} \\frac{|\\mathbf{a}^*(\\theta)\\hat{\\mathbf{R}}^{-1}\\mathbf{y}(\\omega)|^2}{[1 – \\mathbf{y}^*(\\omega)\\hat{\\mathbf{R}}^{-1}\\mathbf{y}(\\omega)][\\mathbf{a}^*(\\theta)\\hat{\\mathbf{R}}^{-1}\\mathbf{a}(\\theta)]}θ^s,ω^s=argθ,ωmax[1−y∗(ω)R^−1y(ω)][a∗(θ)R^−1a(θ)]∣a∗(θ)R^−1y(ω)∣2
其中
y(ω)=1N∑t=1Nx(t)e−jωt\\mathbf{y}(\\omega) = \\frac{1}{N}\\sum_{t=1}^{N}\\mathbf{x}(t)e^{-j\\omega t}y(ω)=N1t=1∑Nx(t)e−jωt
R^s=R^−y(ω)y∗(ω)\\hat{\\mathbf{R}}_s = \\hat{\\mathbf{R}} – \\mathbf{y}(\\omega)\\mathbf{y}^*(\\omega)R^s=R^−y(ω)y∗(ω)
R^=1N∑t=1Nx(t)x∗(t)\\hat{\\mathbf{R}} = \\frac{1}{N}\\sum_{t=1}^{N}\\mathbf{x}(t)\\mathbf{x}^*(t)R^=N1t=1∑Nx(t)x∗(t)
非结构化模型
非结构化模型的ML解可以类似地推导。η~\\tilde{\\boldsymbol{\\eta}}η~的负对数似然函数具有与结构化情况相同的形式,但用α\\boldsymbol{\\alpha}α替换ba(θ)b\\mathbf{a}(\\theta)ba(θ)。关于α\\boldsymbol{\\alpha}α的最小化给出:
α^u=y(ω)\\hat{\\boldsymbol{\\alpha}}_u = \\mathbf{y}(\\omega)α^u=y(ω)
其中下标uuu用于明确表示使用非结构化模型获得的估计。将此代入准则并简化后,ω\\omegaω的解简单地为:
ω^u=argmaxωy∗(ω)R^−1y(ω)\\hat{\\omega}_u = \\arg\\max_\\omega \\mathbf{y}^*(\\omega)\\hat{\\mathbf{R}}^{-1}\\mathbf{y}(\\omega)ω^u=argωmaxy∗(ω)R^−1y(ω)
因此,非结构化ML估计ω\\omegaω由下式给出:
ω^u=argmaxωy∗(ω)R^−1y(ω)\\hat{\\omega}_u = \\arg\\max_\\omega \\mathbf{y}^*(\\omega)\\hat{\\mathbf{R}}^{-1}\\mathbf{y}(\\omega)ω^u=argωmaxy∗(ω)R^−1y(ω)
使用EXIP进行参数估计
根据定理4,给定从非结构化模型获得的Q^u\\hat{\\mathbf{Q}}_uQ^u、α^u\\hat{\\boldsymbol{\\alpha}}_uα^u和ω^u\\hat{\\omega}_uω^u,雷达目标参数的渐近(在NNN中)有效估计可以如下找到:
Q^e=Q^u\\hat{\\mathbf{Q}}_e = \\hat{\\mathbf{Q}}_uQ^e=Q^u
ω^e=ω^u\\hat{\\omega}_e = \\hat{\\omega}_uω^e=ω^u
b^e,θ^e=argminb,θ[((α^u)r(α^u)i)−A(θ)(brbi)]T⋅WQ[((α^u)r(α^u)i)−A(θ)(brbi)]\\hat{b}_e, \\hat{\\theta}_e = \\arg\\min_{b,\\theta} \\left[\\begin{pmatrix} (\\hat{\\boldsymbol{\\alpha}}_u)_r \\\\ (\\hat{\\boldsymbol{\\alpha}}_u)_i \\end{pmatrix} – \\mathbf{A}(\\theta)\\begin{pmatrix} b_r \\\\ b_i \\end{pmatrix}\\right]^T \\cdot \\mathbf{W}_Q \\left[\\begin{pmatrix} (\\hat{\\boldsymbol{\\alpha}}_u)_r \\\\ (\\hat{\\boldsymbol{\\alpha}}_u)_i \\end{pmatrix} – \\mathbf{A}(\\theta)\\begin{pmatrix} b_r \\\\ b_i \\end{pmatrix}\\right]b^e,θ^e=argb,θmin[((α^u)r(α^u)i)−A(θ)(brbi)]T⋅WQ[((α^u)r(α^u)i)−A(θ)(brbi)]
其中
WQ=2N[Re{Q^u−1}−Im{Q^u−1}Im{Q^u−1}Re{Q^u−1}]\\mathbf{W}_Q = 2N\\begin{bmatrix} \\text{Re}\\{\\hat{\\mathbf{Q}}_u^{-1}\\} & -\\text{Im}\\{\\hat{\\mathbf{Q}}_u^{-1}\\} \\\\ \\text{Im}\\{\\hat{\\mathbf{Q}}_u^{-1}\\} & \\text{Re}\\{\\hat{\\mathbf{Q}}_u^{-1}\\} \\end{bmatrix}WQ=2N[Re{Q^u−1}Im{Q^u−1}−Im{Q^u−1}Re{Q^u−1}]
A(θ)=[Re{a(θ)}−Im{a(θ)}Im{a(θ)}Re{a(θ)}]\\mathbf{A}(\\theta) = \\begin{bmatrix} \\text{Re}\\{\\mathbf{a}(\\theta)\\} & -\\text{Im}\\{\\mathbf{a}(\\theta)\\} \\\\ \\text{Im}\\{\\mathbf{a}(\\theta)\\} & \\text{Re}\\{\\mathbf{a}(\\theta)\\} \\end{bmatrix}A(θ)=[Re{a(θ)}Im{a(θ)}−Im{a(θ)}Re{a(θ)}]
可以显式求解b^e\\hat{b}_eb^e,得到仅依赖于θ\\thetaθ的准则:
b^e=a∗(θ^e)Q^u−1α^ua∗(θ^e)Q^u−1a(θ^e)\\hat{b}_e = \\frac{\\mathbf{a}^*(\\hat{\\theta}_e)\\hat{\\mathbf{Q}}_u^{-1}\\hat{\\boldsymbol{\\alpha}}_u}{\\mathbf{a}^*(\\hat{\\theta}_e)\\hat{\\mathbf{Q}}_u^{-1}\\mathbf{a}(\\hat{\\theta}_e)}b^e=a∗(θ^e)Q^u−1a(θ^e)a∗(θ^e)Q^u−1α^u
θ^e=argmaxθ∣a∗(θ)Q^u−1α^u∣2a∗(θ)Q^u−1a(θ)\\hat{\\theta}_e = \\arg\\max_\\theta \\frac{|\\mathbf{a}^*(\\theta)\\hat{\\mathbf{Q}}_u^{-1}\\hat{\\boldsymbol{\\alpha}}_u|^2}{\\mathbf{a}^*(\\theta)\\hat{\\mathbf{Q}}_u^{-1}\\mathbf{a}(\\theta)}θ^e=argθmaxa∗(θ)Q^u−1a(θ)∣a∗(θ)Q^u−1α^u∣2
检测
在本节中,我们讨论在确定给定数据集中是否存在目标时出现的二元假设检验问题。特别是,需要决定以下两个假设中哪一个对x(t),t=1,⋯ ,N\\mathbf{x}(t), t = 1, \\cdots, Nx(t),t=1,⋯,N有效:
H0:x(t)=e(t)H_0: \\mathbf{x}(t) = \\mathbf{e}(t)H0:x(t)=e(t)
H1:x(t)=b0a(θ0)ejω0t+e(t)H_1: \\mathbf{x}(t) = b_0\\mathbf{a}(\\theta_0)e^{j\\omega_0 t} + \\mathbf{e}(t)H1:x(t)=b0a(θ0)ejω0t+e(t)
结构化模型的GLRT
如果pH0p_{H_0}pH0和pH1p_{H_1}pH1表示对应于两个假设的数据概率密度,结构化ML模型的GLRT可以表述为:
λ=pH1(x(1),⋯ ,x(N)∣b^s,θ^s,ω^s,Q^s)pH0(x(1),⋯ ,x(N)∣Q^s)≷H1H0λT\\lambda = \\frac{p_{H_1}(\\mathbf{x}(1), \\cdots, \\mathbf{x}(N)|\\hat{b}_s, \\hat{\\theta}_s, \\hat{\\omega}_s, \\hat{\\mathbf{Q}}_s)}{p_{H_0}(\\mathbf{x}(1), \\cdots, \\mathbf{x}(N)|\\hat{\\mathbf{Q}}_s)} \\underset{H_0}{\\overset{H_1}{\\gtrless}} \\lambda_Tλ=pH0(x(1),⋯,x(N)∣Q^s)pH1(x(1),⋯,x(N)∣b^s,θ^s,ω^s,Q^s)H0≷H1λT
其中b^s,θ^s,ω^s,Q^s\\hat{b}_s, \\hat{\\theta}_s, \\hat{\\omega}_s, \\hat{\\mathbf{Q}}_sb^s,θ^s,ω^s,Q^s是结构化ML估计,λT\\lambda_TλT是某个阈值。由于H0H_0H0和H1H_1H1下的数据都是高斯的,通常取两边的对数,此时GLRT形式为:
λ=2logλ′=2N(log∣R^∣−log∣C(b^s,θ^s,ω^s)∣)≷H1H02logλT=λT′\\lambda = 2\\log \\lambda' = 2N(\\log |\\hat{\\mathbf{R}}| – \\log |\\mathbf{C}(\\hat{b}_s, \\hat{\\theta}_s, \\hat{\\omega}_s)|) \\underset{H_0}{\\overset{H_1}{\\gtrless}} 2\\log \\lambda_T = \\lambda_T'λ=2logλ′=2N(log∣R^∣−log∣C(b^s,θ^s,ω^s)∣)H0≷H12logλT=λT′
非结构化模型的GLRT
对于非结构化模型,两个竞争假设是:
H0:x(t)=e(t)H_0: \\mathbf{x}(t) = \\mathbf{e}(t)H0:x(t)=e(t)
H1u:x(t)=α0ejω0t+e(t)H_1^u: \\mathbf{x}(t) = \\boldsymbol{\\alpha}_0 e^{j\\omega_0 t} + \\mathbf{e}(t)H1u:x(t)=α0ejω0t+e(t)
得到的GLRT在形式上类似于结构化情况,用α^u\\hat{\\boldsymbol{\\alpha}}_uα^u替换b^s,θ^s\\hat{b}_s, \\hat{\\theta}_sb^s,θ^s:
λu=2N(log∣R^∣−log∣C(α^u,ω^u)∣)≷H1H0λTu\\lambda_u = 2N(\\log |\\hat{\\mathbf{R}}| – \\log |\\mathbf{C}(\\hat{\\boldsymbol{\\alpha}}_u, \\hat{\\omega}_u)|) \\underset{H_0}{\\overset{H_1}{\\gtrless}} \\lambda_{T_u}λu=2N(log∣R^∣−log∣C(α^u,ω^u)∣)H0≷H1λTu
从前面的推导可知:
log∣C(α^u,ω^u)∣=log(1−zR(ω^u))+log∣R^∣\\log |\\mathbf{C}(\\hat{\\boldsymbol{\\alpha}}_u, \\hat{\\omega}_u)| = \\log(1 – z_R(\\hat{\\omega}_u)) + \\log |\\hat{\\mathbf{R}}|log∣C(α^u,ω^u)∣=log(1−zR(ω^u))+log∣R^∣
因此问题是确定λTu\\lambda_{T_u}λTu使得:
λu=−2Nlog(1−zR(ω^u))>λTu\\lambda_u = -2N\\log(1 – z_R(\\hat{\\omega}_u)) > \\lambda_{T_u}λu=−2Nlog(1−zR(ω^u))>λTu
在H0H_0H0下以给定的PFA PfP_fPf发生。由于对数是单调的,不等式等价于条件:
2NzR(ω^u)>2N(1−exp(−λTu/2N))2Nz_R(\\hat{\\omega}_u) > 2N(1 – \\exp(-\\lambda_{T_u}/2N))2NzR(ω^u)>2N(1−exp(−λTu/2N))
对于大NNN可以进一步近似为:
2NzR(ω^u)>λTu2Nz_R(\\hat{\\omega}_u) > \\lambda_{T_u}2NzR(ω^u)>λTu
仿真结果
渐近性验证
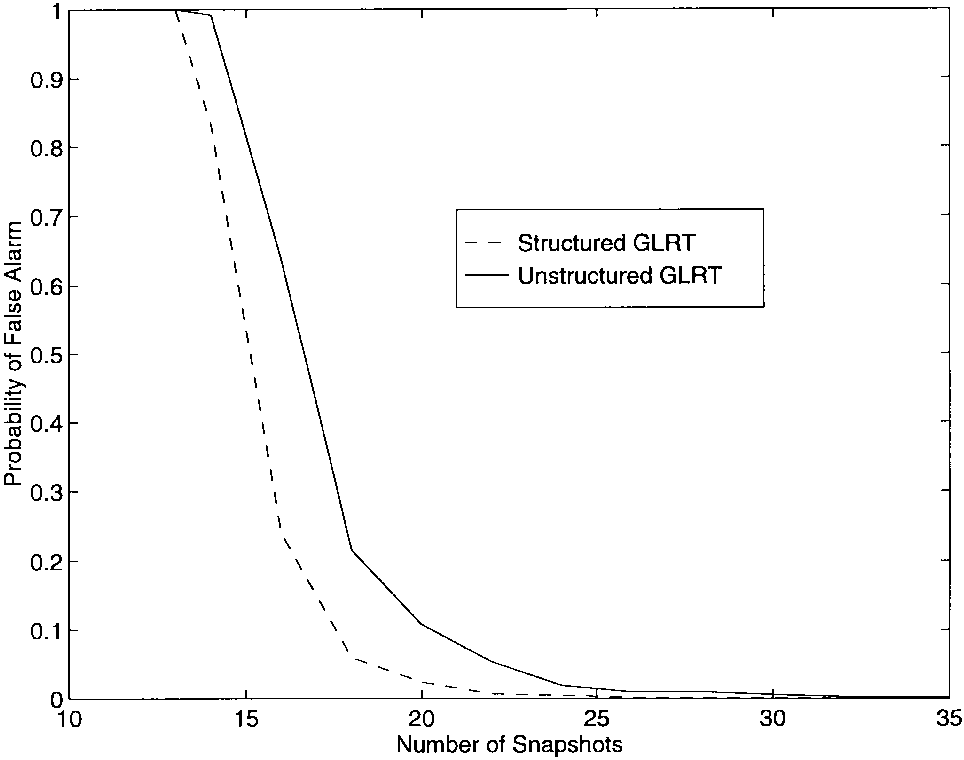
图1显示了在没有信号存在时,结构化和非结构化GLRT的PFA与从阵列获取的快照数的关系。结果基于每个NNN值的1000次试验。虽然两个测试都随着NNN的增加接近低PFA值,但结构化GLRT的"阈值"似乎比非结构化GLRT小几个(两到三个)快照。
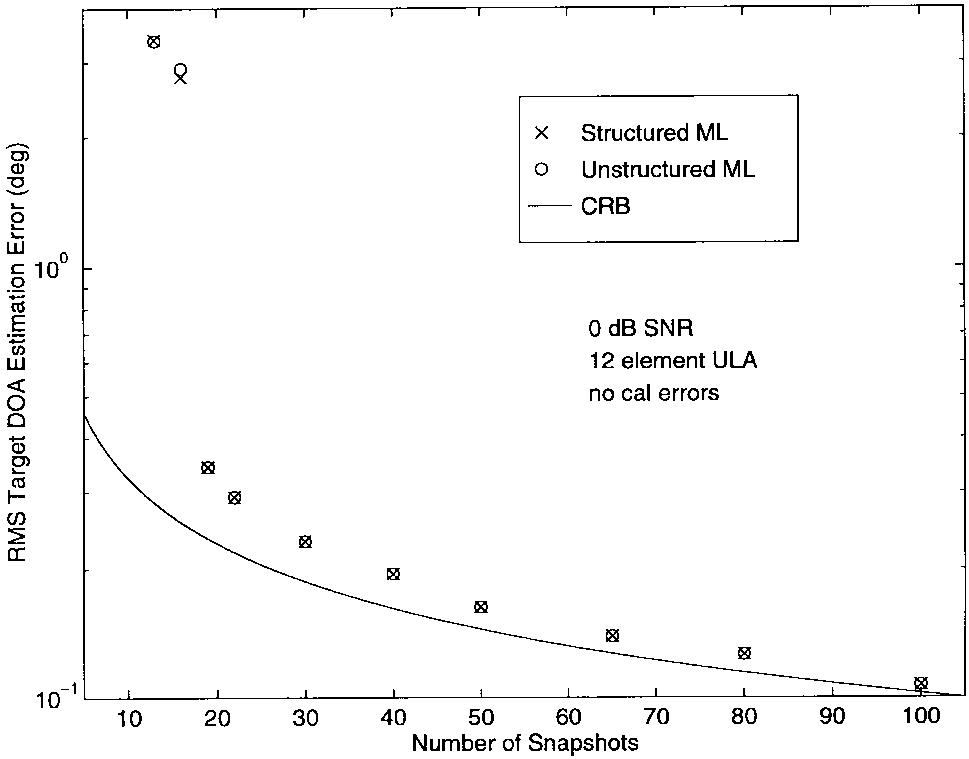
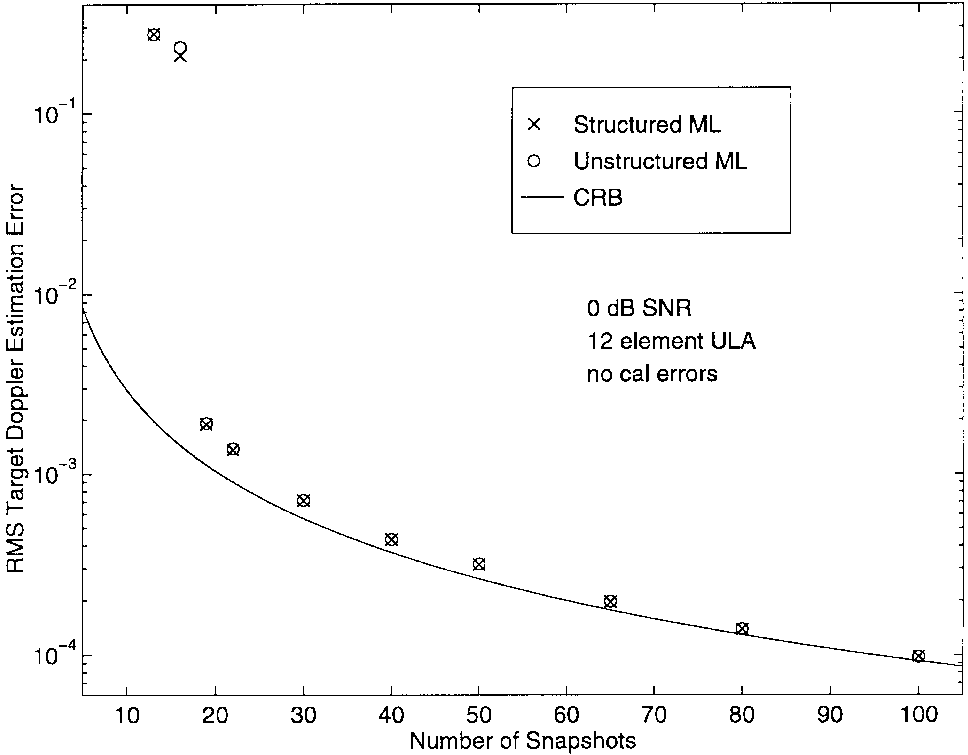
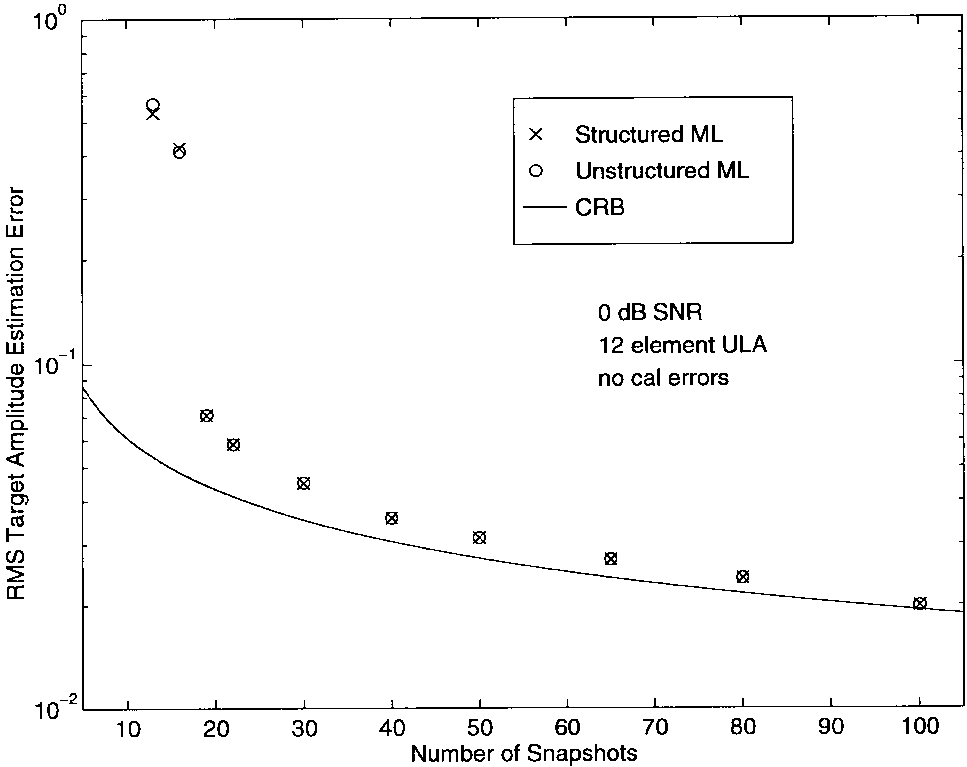
图2-4分别显示了DOA、多普勒和幅度估计的均方根(rms)误差与NNN的关系,针对0-dB SNR和理想阵列(无校准误差)的情况。从图中可以清楚地看出,对于所有NNN值,SML和UML估计的质量基本上没有差异。因此,至少对于这些情况,两种方法的渐近等价性在数据很少的情况下就很明显。
鲁棒检测
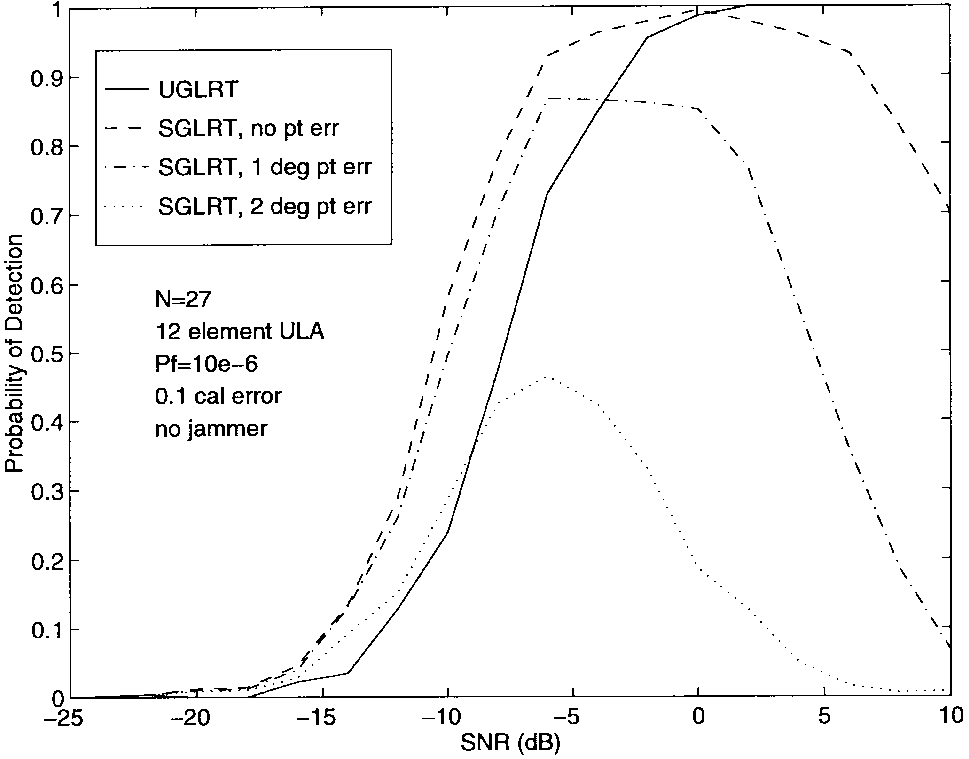
图5比较了在各种SNR下SGLRT和UGLRT的检测概率(每个SNR 500次试验),针对校准误差为0.1的阵列情况。SGLRT的三条曲线显示了其在"指向"误差为0°、1°和2°时的性能。图5表明SGLRT对θt=θ0\\theta_t = \\theta_0θt=θ0的假设非常敏感。当然,UGLRT不会遇到这种困难,因为它不使用DOA信息。
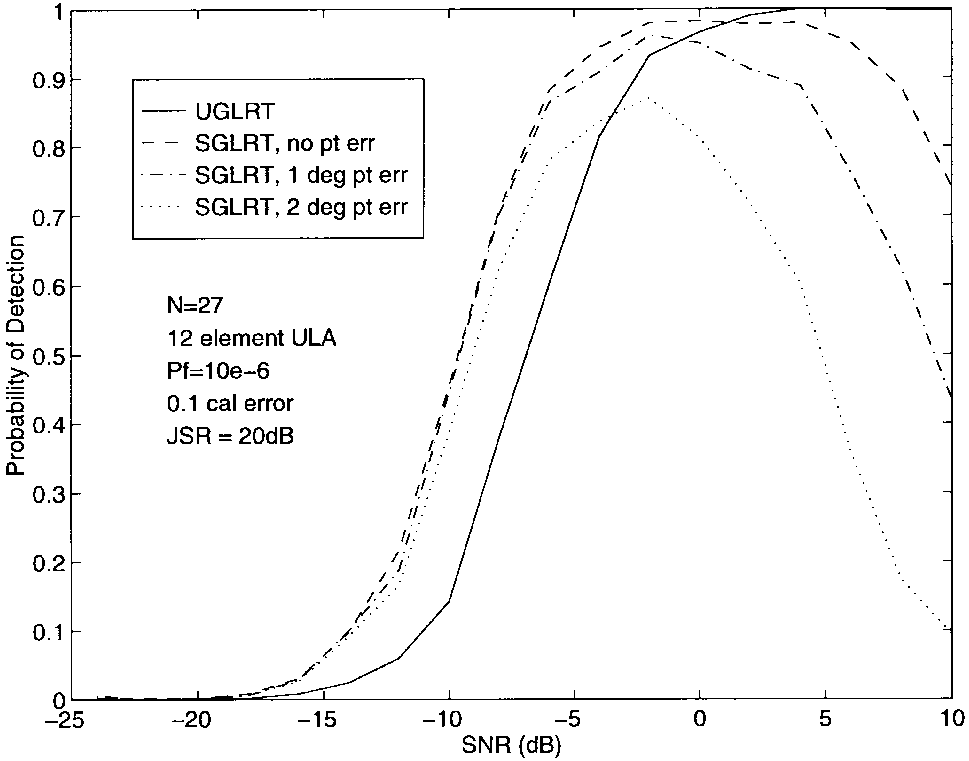
在数据中添加了强干扰器后重复了上述实验,结果绘制在图6中。干扰器位于5°的DOA,干扰信号比(JSR)固定为20 dB。干扰器的存在导致低SNR时检测概率略有降低,但似乎在较高SNR时提高了SGLRT的性能。然而,这种改进只是人为的,因为干扰器的随机贡献推动了检测准则的峰值超过阈值。
鲁棒估计
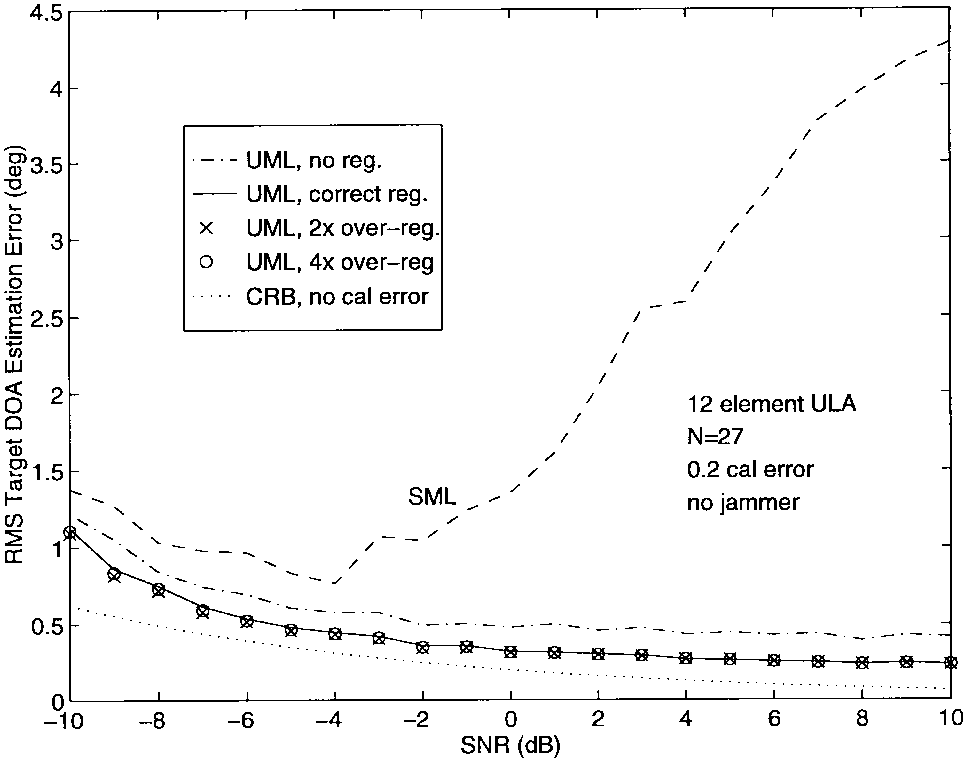
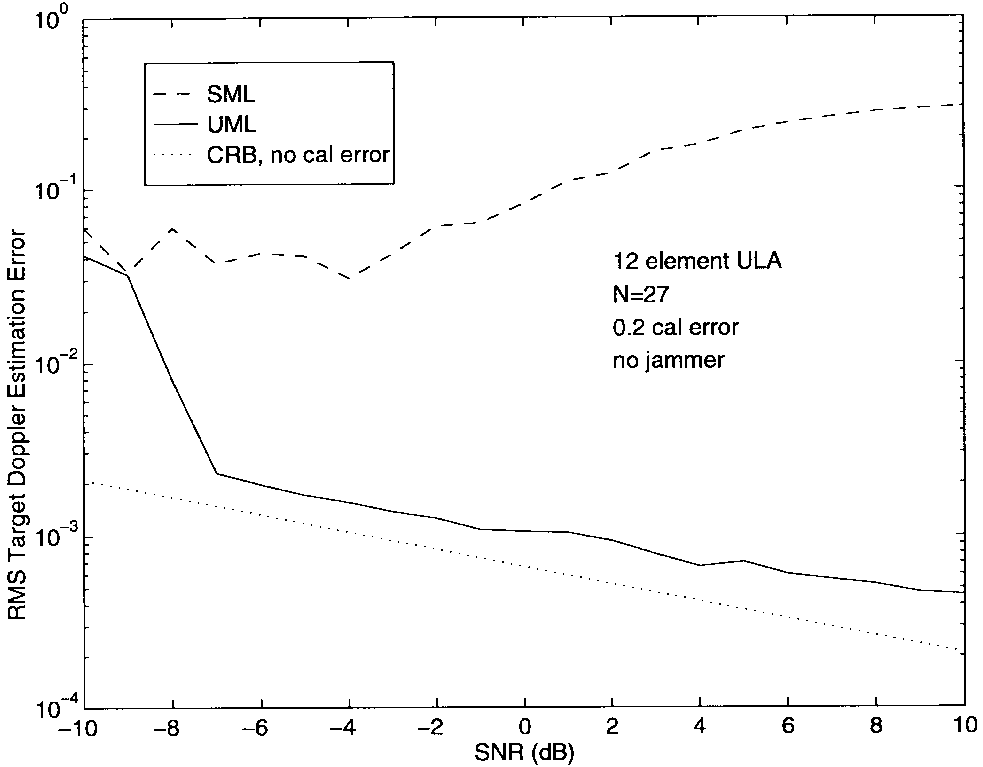
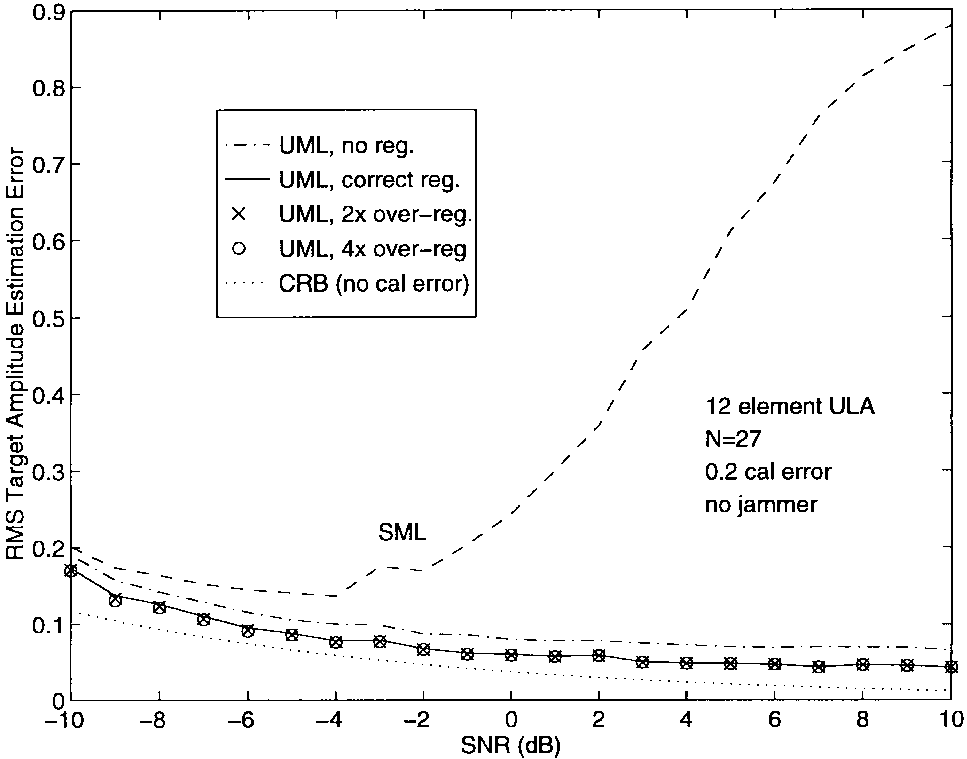
图7-9显示了在没有干扰器存在时,目标DOA、多普勒和幅度估计的rms误差与SNR的关系。图中的虚线表示使用标准加权的UML性能。实线给出了正确加权的结果。图上的符号"x"和"o"对应于正则化UML的结果,分别实现了σa\\sigma_aσa被高估2倍和4倍的情况。可以看出,正则化提供的性能改进对该参数的确切知识非常不敏感。
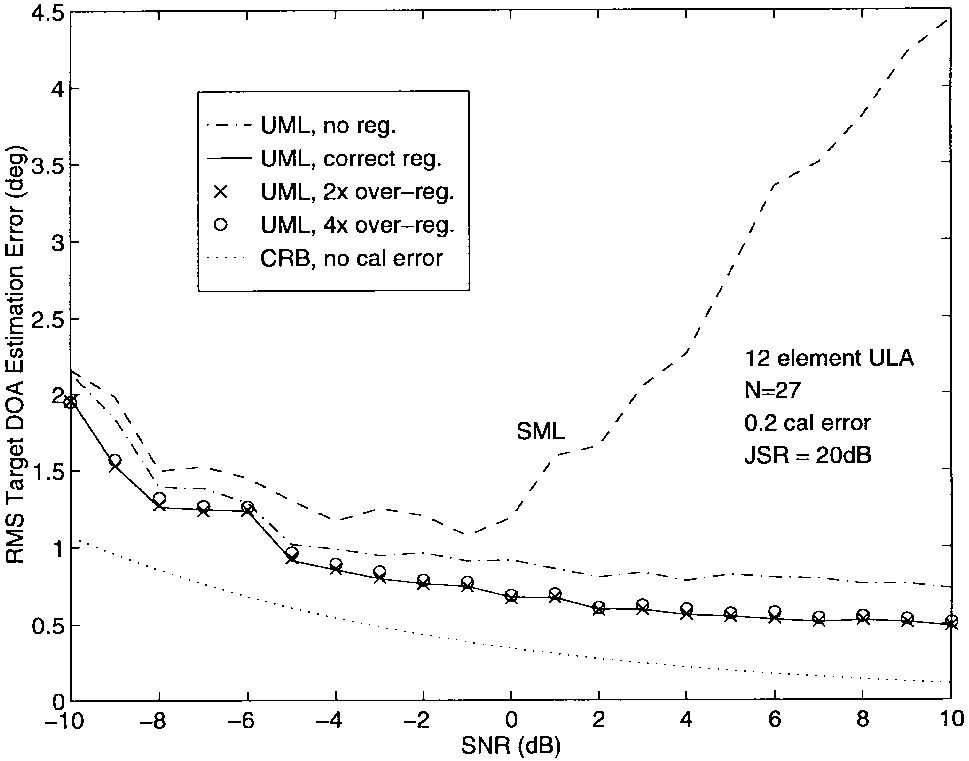
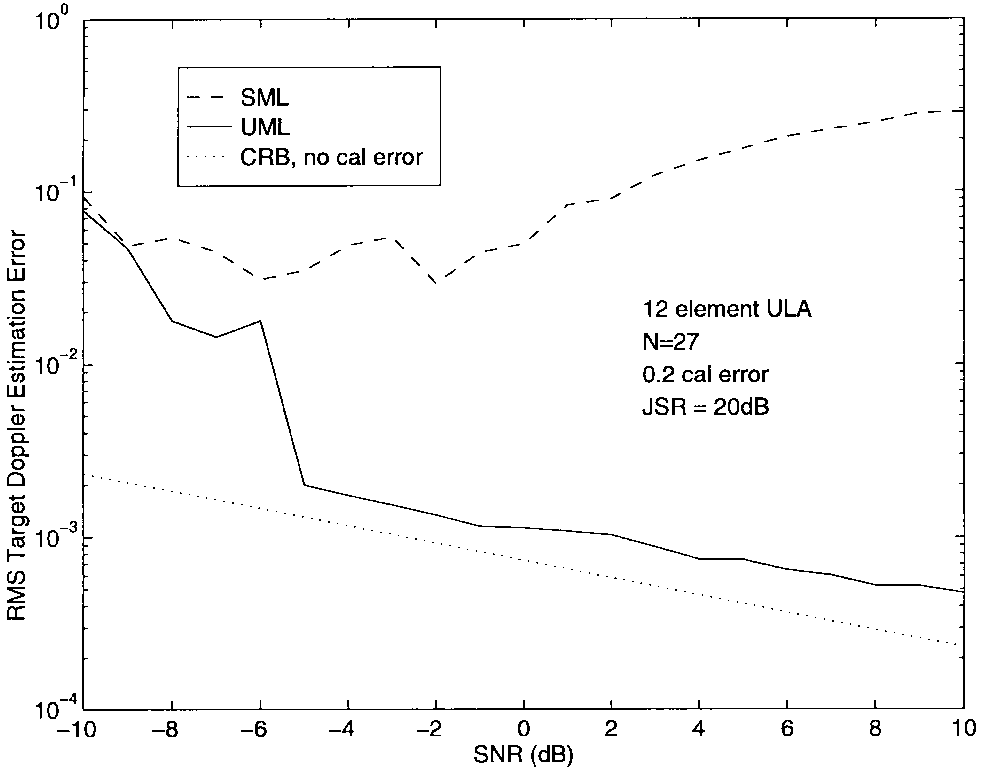
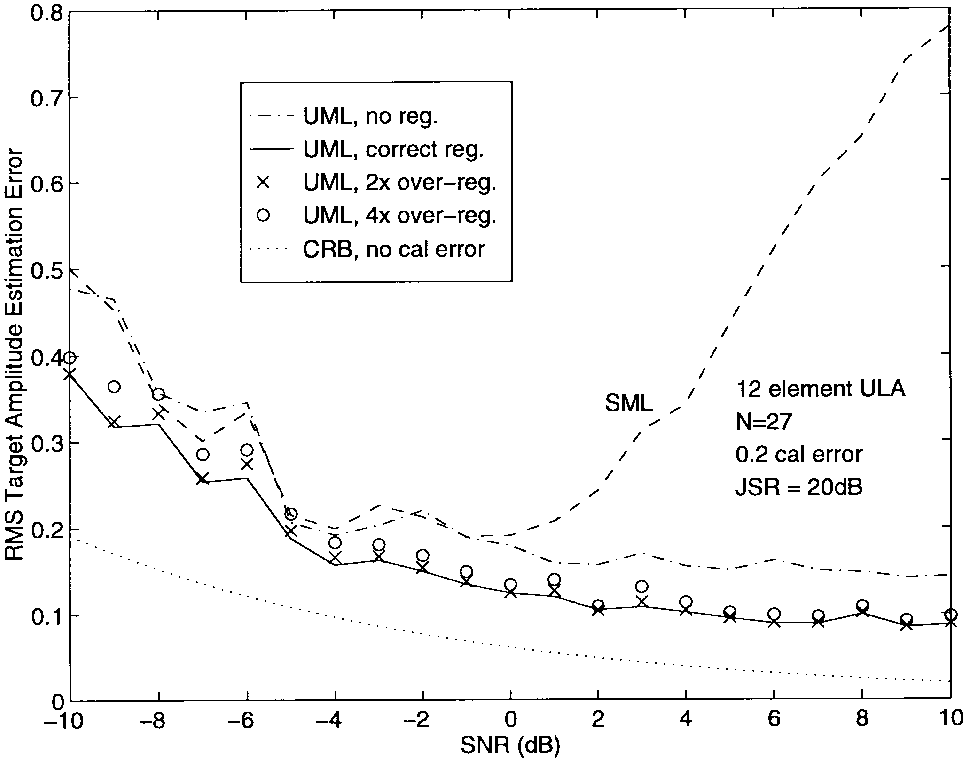
图10-12显示了当5°处存在干扰器且JSR = 20 dB时的结果。无论有无正则化,UML方法都比SML在高SNR时精确几倍。校准误差的存在降低了真实θ\\thetaθ和ω\\omegaω处的2-D SML准则的峰值,并产生了远离它们的局部最大值。UML技术不会遇到这个问题,因为在高SNR时,它能够准确估计ω\\omegaω而不受阵列扰动的影响。有了ω\\omegaω的准确估计,DOA参数的误差相应减少。
结论
本文提出了几种用于雷达问题中检测和估计的技术,其中目标被具有未知空间协方差的噪声中的天线阵列观测。引入了两种数据模型:一种使用结构化模型,将目标信号幅度和DOA作为参数,另一种是阵列响应的更简单的非结构化模型。为每种情况推导了ML解并建立了相应的CRB。使用EXIP展示了如何处理更简单的非结构化解以估计具有与更复杂的结构化算法相同渐近精度的目标参数。
观察到EXIP方法的几个优点。首先,可以使用两个1-D搜索而不是一个2-D搜索获得目标参数的统计有效估计。由于估计通常通过在网格上评估给定准则来确定,这可以提供大量的计算节省。此外,如果使用均匀线性阵列,可以消除其中一个1-D搜索以进一步减少计算负担。其次,使用非结构化模型的两步方法为在目标DOA估计中考虑阵列校准误差提供了一种简单有效的方法。由此产生的DOA估计可以显著更准确,对此类误差的敏感性大大降低。最后,使用阵列响应的非结构化模型允许开发不依赖于阵列校准数据的准确性或可用性的似然比检测测试,也不依赖于目标DOA的先验信息。因此,在这些信息不精确已知的情况下,该测试是鲁棒的。我们的仿真表明,当阵列完美校准时,使用更简单的两步算法而不是直接结构化方法几乎没有退化。当存在校准或指向误差时,更简单的算法提供了更好的性能。
总之,使用非结构化阵列模型与EXIP相结合为将ML方法应用于雷达信号处理问题提供了一个非常简单的程序。所提出的估计和检测算法的计算简单性和鲁棒性使它们值得在实际雷达应用中认真考虑。
附录
附录A:结构化ML估计器的性质
A. 一致性
首先建立结构化ML算法的一致性。首先,我们有:
limN→∞y(ω)=limN→∞1N∑t=1N[b0a(θ0)ej(ω0−ω)t+e(t)e−jωt]\\lim_{N \\to \\infty} \\mathbf{y}(\\omega) = \\lim_{N \\to \\infty} \\frac{1}{N}\\sum_{t=1}^{N}\\left[b_0\\mathbf{a}(\\theta_0)e^{j(\\omega_0-\\omega)t} + \\mathbf{e}(t)e^{-j\\omega t}\\right]N→∞limy(ω)=N→∞limN1t=1∑N[b0a(θ0)ej(ω0−ω)t+e(t)e−jωt]
=limN→∞1N∑t=1Nb0a(θ0)ej(ω0−ω)t+limN→∞1N∑t=1Ne(t)e−jωt= \\lim_{N \\to \\infty} \\frac{1}{N}\\sum_{t=1}^{N}b_0\\mathbf{a}(\\theta_0)e^{j(\\omega_0-\\omega)t} + \\lim_{N \\to \\infty} \\frac{1}{N}\\sum_{t=1}^{N}\\mathbf{e}(t)e^{-j\\omega t}=N→∞limN1t=1∑Nb0a(θ0)ej(ω0−ω)t+N→∞limN1t=1∑Ne(t)e−jωt
如果我们令δ(ω)\\delta(\\omega)δ(ω)表示Kronecker delta函数,第一项的极限简单地为b0a(θ0)δ(ω0−ω)b_0\\mathbf{a}(\\theta_0)\\delta(\\omega_0 – \\omega)b0a(θ0)δ(ω0−ω),因为:
limN→∞1N∑t=1Nej(ω0−ω)t={1如果 ω=ω00否则\\lim_{N \\to \\infty} \\frac{1}{N}\\sum_{t=1}^{N}e^{j(\\omega_0-\\omega)t} = \\begin{cases} 1 & \\text{如果 } \\omega = \\omega_0 \\\\ 0 & \\text{否则} \\end{cases}N→∞limN1t=1∑Nej(ω0−ω)t={10如果 ω=ω0否则
根据大数定律,第二项以概率1一致收敛到零,因为e(t)\\mathbf{e}(t)e(t)是零均值的。因此:
limN→∞y(ω)={b0a(θ0)如果 ω=ω00否则w.p.1\\lim_{N \\to \\infty} \\mathbf{y}(\\omega) = \\begin{cases} b_0\\mathbf{a}(\\theta_0) & \\text{如果 } \\omega = \\omega_0 \\\\ 0 & \\text{否则} \\end{cases} \\quad \\text{w.p.1}N→∞limy(ω)={b0a(θ0)0如果 ω=ω0否则w.p.1
令R^=limN→∞R^\\hat{\\mathbf{R}} = \\lim_{N \\to \\infty} \\hat{\\mathbf{R}}R^=limN→∞R^,则在(16)(16)(16)中的ML准则渐近地由下式给出:
VN(θ,ω)=∣b0∣2∣a∗(θ)R−1a(θ0)∣2[1−∣b0∣2a∗(θ0)R−1a(θ0)]a∗(θ)R−1a(θ)V_N(\\theta, \\omega) = \\frac{|b_0|^2|\\mathbf{a}^*(\\theta)\\mathbf{R}^{-1}\\mathbf{a}(\\theta_0)|^2}{[1-|b_0|^2\\mathbf{a}^*(\\theta_0)\\mathbf{R}^{-1}\\mathbf{a}(\\theta_0)]\\mathbf{a}^*(\\theta)\\mathbf{R}^{-1}\\mathbf{a}(\\theta)}VN(θ,ω)=[1−∣b0∣2a∗(θ0)R−1a(θ0)]a∗(θ)R−1a(θ)∣b0∣2∣a∗(θ)R−1a(θ0)∣2
概率为1。在ω≠ω0\\omega \\neq \\omega_0ω=ω0时,极限ML准则为零。柯西-施瓦茨不等式可以用来获得极限ML准则的以下上界:
limN→∞VN(θ,ω0)=∣b0∣2∣a∗(θ)R−1a(θ0)∣2ca∗(θ)R−1a(θ)≤∣b0∣2a∗(θ0)R−1a(θ0)c\\lim_{N \\to \\infty} V_N(\\theta, \\omega_0) = \\frac{|b_0|^2|\\mathbf{a}^*(\\theta)\\mathbf{R}^{-1}\\mathbf{a}(\\theta_0)|^2}{c\\mathbf{a}^*(\\theta)\\mathbf{R}^{-1}\\mathbf{a}(\\theta)} \\leq \\frac{|b_0|^2\\mathbf{a}^*(\\theta_0)\\mathbf{R}^{-1}\\mathbf{a}(\\theta_0)}{c}N→∞limVN(θ,ω0)=ca∗(θ)R−1a(θ)∣b0∣2∣a∗(θ)R−1a(θ0)∣2≤c∣b0∣2a∗(θ0)R−1a(θ0)
其中c=1−∣b0∣2a∗(θ0)R−1a(θ0)c = 1 – |b_0|^2\\mathbf{a}^*(\\theta_0)\\mathbf{R}^{-1}\\mathbf{a}(\\theta_0)c=1−∣b0∣2a∗(θ0)R−1a(θ0)。当且仅当R−1/2a(θ)=κR−1/2a(θ0)\\mathbf{R}^{-1/2}\\mathbf{a}(\\theta) = \\kappa\\mathbf{R}^{-1/2}\\mathbf{a}(\\theta_0)R−1/2a(θ)=κR−1/2a(θ0)时等式成立,这进而只有当a(θ)=κa(θ0)\\mathbf{a}(\\theta) = \\kappa\\mathbf{a}(\\theta_0)a(θ)=κa(θ0)时才可能,因为我们隐含地假设了一个"无歧义"的阵列。
虽然极限ML准则在真实参数值处具有全局最大值,但由于准则在ω\\omegaω中的不连续性,建立一致性是复杂的。使用类似于文献中引理1和定理1的论证可以解决这个问题。已经证明,只要VN(θ,ω)V_N(\\theta, \\omega)VN(θ,ω)可以写成两个分量VN(1)(θ,ω)V_N^{(1)}(\\theta, \\omega)VN(1)(θ,ω)和VN(2)(θ,ω)V_N^{(2)}(\\theta, \\omega)VN(2)(θ,ω)的和,满足以下条件,就可以实现一致性:
B. Cramér-Rao界
由于结构化ML估计是一致的,它们将是统计有效的,其渐近方差将由CRB给出。在结构化模型下,观测x(1),⋯ ,x(N)\\mathbf{x}(1), \\cdots, \\mathbf{x}(N)x(1),⋯,x(N)是独立的圆形高斯随机变量,均值为:
E{x(t)}=b0a(θ0)ejω0t\\mathcal{E}\\{\\mathbf{x}(t)\\} = b_0\\mathbf{a}(\\theta_0)e^{j\\omega_0 t}E{x(t)}=b0a(θ0)ejω0t
和协方差Q\\mathbf{Q}Q,其中为简洁起见我们省略了下标000。在这种情况下,NNN个观测的FIM的元素(i,j)(i,j)(i,j)可以表示为:
[JN]ij=N⋅tr{Q−1∂Q∂ηiQ−1∂Q∂ηj}+2Re{∑t=1N∂μ∗(t)∂ηiQ−1∂μ(t)∂ηj}[\\mathbf{J}_N]_{ij} = N \\cdot \\text{tr}\\left\\{\\mathbf{Q}^{-1}\\frac{\\partial \\mathbf{Q}}{\\partial \\eta_i}\\mathbf{Q}^{-1}\\frac{\\partial \\mathbf{Q}}{\\partial \\eta_j}\\right\\} + 2\\text{Re}\\left\\{\\sum_{t=1}^{N}\\frac{\\partial \\mu^*(t)}{\\partial \\eta_i}\\mathbf{Q}^{-1}\\frac{\\partial \\mu(t)}{\\partial \\eta_j}\\right\\}[JN]ij=N⋅tr{Q−1∂ηi∂QQ−1∂ηj∂Q}+2Re{t=1∑N∂ηi∂μ∗(t)Q−1∂ηj∂μ(t)}
由于Q\\mathbf{Q}Q和{b,θ,ω}\\{b, \\theta, \\omega\\}{b,θ,ω}依赖于η\\boldsymbol{\\eta}η的不同元素,很明显JN\\mathbf{J}_NJN将相对于信号和噪声参数是块对角的。特别地,(103)(103)(103)的第一项只对噪声块给出非零结果,而第二项只对信号块非零。由于我们只关心信号参数的CRB,我们只需要考虑第二项:
JN(s)=2Re{∑t,s=1N∂μ∗(t)∂ηsQ−1∂μ(s)∂ηsT}ej(ω0−ω)(s−t)\\mathbf{J}_N^{(s)} = 2\\text{Re}\\left\\{\\sum_{t,s=1}^{N}\\frac{\\partial \\mu^*(t)}{\\partial \\boldsymbol{\\eta}_s}\\mathbf{Q}^{-1}\\frac{\\partial \\mu(s)}{\\partial \\boldsymbol{\\eta}_s^T}\\right\\}e^{j(\\omega_0-\\omega)(s-t)}JN(s)=2Re{t,s=1∑N∂ηs∂μ∗(t)Q−1∂ηsT∂μ(s)}ej(ω0−ω)(s−t)
所需的偏导数如下:
∂μ(t)∂Re{b}=a(θ)ejωt\\frac{\\partial \\mu(t)}{\\partial \\text{Re}\\{b\\}} = \\mathbf{a}(\\theta)e^{j\\omega t}∂Re{b}∂μ(t)=a(θ)ejωt
∂μ(t)∂Im{b}=ja(θ)ejωt\\frac{\\partial \\mu(t)}{\\partial \\text{Im}\\{b\\}} = j\\mathbf{a}(\\theta)e^{j\\omega t}∂Im{b}∂μ(t)=ja(θ)ejωt
∂μ(t)∂θ=jba˙(θ)ejωt\\frac{\\partial \\mu(t)}{\\partial \\theta} = jb\\dot{\\mathbf{a}}(\\theta)e^{j\\omega t}∂θ∂μ(t)=jba˙(θ)ejωt
∂μ(t)∂ω=jtba(θ)ejωt\\frac{\\partial \\mu(t)}{\\partial \\omega} = jtb\\mathbf{a}(\\theta)e^{j\\omega t}∂ω∂μ(t)=jtba(θ)ejωt
其中a˙(θ)=∂a(θ)∂θ\\dot{\\mathbf{a}}(\\theta) = \\frac{\\partial \\mathbf{a}(\\theta)}{\\partial \\theta}a˙(θ)=∂θ∂a(θ)。
将这些代入(104)(104)(104)得到CRB表达式。为了找到ML多普勒和DOA估计的方差,我们使用分块对称矩阵逆的以下公式:
[ABTBC]−1=[(A−BTC−1B)−1−A−1BTD−DTBA−1D]\\begin{bmatrix} \\mathbf{A} & \\mathbf{B}^T \\\\ \\mathbf{B} & \\mathbf{C} \\end{bmatrix}^{-1} = \\begin{bmatrix} (\\mathbf{A} – \\mathbf{B}^T\\mathbf{C}^{-1}\\mathbf{B})^{-1} & -\\mathbf{A}^{-1}\\mathbf{B}^T\\mathbf{D} \\\\ -\\mathbf{D}^T\\mathbf{B}\\mathbf{A}^{-1} & \\mathbf{D} \\end{bmatrix}[ABBTC]−1=[(A−BTC−1B)−1−DTBA−1−A−1BTDD]
其中D=(C−BA−1BT)−1\\mathbf{D} = (\\mathbf{C} – \\mathbf{B}\\mathbf{A}^{-1}\\mathbf{B}^T)^{-1}D=(C−BA−1BT)−1是JN−1\\mathbf{J}_N^{-1}JN−1的下2×22 \\times 22×2块。为方便起见,定义:
Qr=Re{Q}\\mathbf{Q}_r = \\text{Re}\\{\\mathbf{Q}\\}Qr=Re{Q}
Qi=Im{Q}\\mathbf{Q}_i = \\text{Im}\\{\\mathbf{Q}\\}Qi=Im{Q}
αr=Re{b0a(θ0)}\\boldsymbol{\\alpha}_r = \\text{Re}\\{b_0\\mathbf{a}(\\theta_0)\\}αr=Re{b0a(θ0)}
αi=Im{b0a(θ0)}\\boldsymbol{\\alpha}_i = \\text{Im}\\{b_0\\mathbf{a}(\\theta_0)\\}αi=Im{b0a(θ0)}
δN=[γN−βN2]α0∗Q−1α0\\delta_N = [\\gamma_N – \\beta_N^2]\\boldsymbol{\\alpha}_0^*\\mathbf{Q}^{-1}\\boldsymbol{\\alpha}_0δN=[γN−βN2]α0∗Q−1α0
βN\\beta_NβN、γN\\gamma_NγN由(21)(21)(21)和(22)(22)(22)定义。
估计方差因此由下式给出:
E{(θ^s−θ0)2}=a∗Q−1a2N∣b∣2[(a∗Q−1a)(a˙∗Q−1a˙)−∣a∗Q−1a˙∣2]\\mathcal{E}\\{(\\hat{\\theta}_s – \\theta_0)^2\\} = \\frac{\\mathbf{a}^*\\mathbf{Q}^{-1}\\mathbf{a}}{2N|b|^2[(\\mathbf{a}^*\\mathbf{Q}^{-1}\\mathbf{a})(\\dot{\\mathbf{a}}^*\\mathbf{Q}^{-1}\\dot{\\mathbf{a}}) – |\\mathbf{a}^*\\mathbf{Q}^{-1}\\dot{\\mathbf{a}}|^2]}E{(θ^s−θ0)2}=2N∣b∣2[(a∗Q−1a)(a˙∗Q−1a˙)−∣a∗Q−1a˙∣2]a∗Q−1a
E{(ω^s−ω0)2}=12N∣b∣2(γN−βN2)a∗Q−1a≈6N3∣b∣2a∗Q−1a\\mathcal{E}\\{(\\hat{\\omega}_s – \\omega_0)^2\\} = \\frac{1}{2N|b|^2(\\gamma_N – \\beta_N^2)\\mathbf{a}^*\\mathbf{Q}^{-1}\\mathbf{a}} \\approx \\frac{6}{N^3|b|^2\\mathbf{a}^*\\mathbf{Q}^{-1}\\mathbf{a}}E{(ω^s−ω0)2}=2N∣b∣2(γN−βN2)a∗Q−1a1≈N3∣b∣2a∗Q−1a6
附录B:非结构化ML估计器的性质
A. 一致性
非结构化ML算法的一致性以类似于结构化情况的方式建立。按照(96)(96)(96)–(98)(98)(98),我们有:
limN→∞y(ω)={α0如果 ω=ω00否则\\lim_{N \\to \\infty} \\mathbf{y}(\\omega) = \\begin{cases} \\boldsymbol{\\alpha}_0 & \\text{如果 } \\omega = \\omega_0 \\\\ 0 & \\text{否则} \\end{cases}N→∞limy(ω)={α00如果 ω=ω0否则
因此:
limN→∞y∗(ω)R^−1y(ω)={α0∗R−1α0如果 ω=ω00否则\\lim_{N \\to \\infty} \\mathbf{y}^*(\\omega)\\hat{\\mathbf{R}}^{-1}\\mathbf{y}(\\omega) = \\begin{cases} \\boldsymbol{\\alpha}_0^*\\mathbf{R}^{-1}\\boldsymbol{\\alpha}_0 & \\text{如果 } \\omega = \\omega_0 \\\\ 0 & \\text{否则} \\end{cases}N→∞limy∗(ω)R^−1y(ω)={α0∗R−1α00如果 ω=ω0否则
将准则分成两项:
y∗(ω)R^−1y(ω)=1N2∑t,s=1Nα0∗R−1α0e−j(ω0−ω)(t−s)+1N2∑t,s=1N[α0∗R−1e(t)e−jωs+e∗(s)R−1α0ejωt+e∗(s)R−1e(t)]e−jω(t−s)\\mathbf{y}^*(\\omega)\\hat{\\mathbf{R}}^{-1}\\mathbf{y}(\\omega) = \\frac{1}{N^2}\\sum_{t,s=1}^{N}\\boldsymbol{\\alpha}_0^*\\mathbf{R}^{-1}\\boldsymbol{\\alpha}_0 e^{-j(\\omega_0-\\omega)(t-s)} + \\frac{1}{N^2}\\sum_{t,s=1}^{N}[\\boldsymbol{\\alpha}_0^*\\mathbf{R}^{-1}\\mathbf{e}(t)e^{-j\\omega s} + \\mathbf{e}^*(s)\\mathbf{R}^{-1}\\boldsymbol{\\alpha}_0 e^{j\\omega t} + \\mathbf{e}^*(s)\\mathbf{R}^{-1}\\mathbf{e}(t)]e^{-j\\omega(t-s)}y∗(ω)R^−1y(ω)=N21t,s=1∑Nα0∗R−1α0e−j(ω0−ω)(t−s)+N21t,s=1∑N[α0∗R−1e(t)e−jωs+e∗(s)R−1α0ejωt+e∗(s)R−1e(t)]e−jω(t−s)
我们再次有两个满足一致性条件的函数。因此,limN→∞ω^u=ω0\\lim_{N \\to \\infty} \\hat{\\omega}_u = \\omega_0limN→∞ω^u=ω0,此外:
limN→∞α^u=limN→∞y(ω^u)=α0\\lim_{N \\to \\infty} \\hat{\\boldsymbol{\\alpha}}_u = \\lim_{N \\to \\infty} \\mathbf{y}(\\hat{\\omega}_u) = \\boldsymbol{\\alpha}_0N→∞limα^u=N→∞limy(ω^u)=α0
Q^u\\hat{\\mathbf{Q}}_uQ^u的一致性通过将α^u,ω^u\\hat{\\boldsymbol{\\alpha}}_u, \\hat{\\omega}_uα^u,ω^u代入(25)(25)(25)得到。
B. Cramér-Rao界
非结构化模型下的数据x(1),⋯ ,x(N)\\mathbf{x}(1), \\cdots, \\mathbf{x}(N)x(1),⋯,x(N)是独立的圆形高斯随机变量,均值为μu(t)=α0ejω0t\\mu_u(t) = \\boldsymbol{\\alpha}_0e^{j\\omega_0 t}μu(t)=α0ejω0t和协方差Q\\mathbf{Q}Q。与结构化情况一样,非结构化CRB相对于信号{αr,αi,ω}\\{\\boldsymbol{\\alpha}_r, \\boldsymbol{\\alpha}_i, \\omega\\}{αr,αi,ω}和噪声(Q)(\\mathbf{Q})(Q)参数是块对角的。FIM的计算与(104)(104)(104)完全相同,用η~\\tilde{\\boldsymbol{\\eta}}η~替换η\\boldsymbol{\\eta}η,所需的偏导数由下式给出:
∂μ(t)∂αr=Iejωt\\frac{\\partial \\mu(t)}{\\partial \\boldsymbol{\\alpha}_r} = \\mathbf{I}e^{j\\omega t}∂αr∂μ(t)=Iejωt
∂μ(t)∂αi=jIejωt\\frac{\\partial \\mu(t)}{\\partial \\boldsymbol{\\alpha}_i} = j\\mathbf{I}e^{j\\omega t}∂αi∂μ(t)=jIejωt
∂μ(t)∂ω=jtαejωt\\frac{\\partial \\mu(t)}{\\partial \\omega} = jt\\boldsymbol{\\alpha}e^{j\\omega t}∂ω∂μ(t)=jtαejωt
将(117)(117)(117)–(119)(119)(119)代入(104)(104)(104)得到FIM表达式。可以通过求逆(120)(120)(120)获得CRB的显式表达式。为此,我们使用(112)(112)(112)和矩阵求逆引理。
附录C:定理4的证明
通过将一般EXIP结果应用于结构化和非结构化ML雷达目标参数估计器的准则来证明该定理。特别地,将定义一个满足(7)(7)(7)的函数fff,该函数关联SML和UML参数,并将显示(9)(9)(9)的WLS最小化简化为(47)(47)(47)–(50)(50)(50)、(53)(53)(53)和(54)(54)(54)。因此,定理1表明分别由(47)(47)(47)、(48)(48)(48)、(53)(53)(53)和(54)(54)(54)获得的bbb和θ\\thetaθ的估计渐近地与结构化ML算法获得的估计一样准确,因此在统计上是有效的。
关联DηD_\\etaDη和Dη~D_{\\tilde{\\eta}}Dη~元素的函数fff由下式隐式定义:
Qs=Q\\mathbf{Q}_s = \\mathbf{Q}Qs=Q
ωs=ω\\omega_s = \\omegaωs=ω
Re{b0a(θ0)}=Re{α}=A(θ)(brbi)\\text{Re}\\{b_0\\mathbf{a}(\\theta_0)\\} = \\text{Re}\\{\\boldsymbol{\\alpha}\\} = \\mathbf{A}(\\theta)\\begin{pmatrix} b_r \\\\ b_i \\end{pmatrix}Re{b0a(θ0)}=Re{α}=A(θ)(brbi)
Im{b0a(θ0)}=Im{α}\\text{Im}\\{b_0\\mathbf{a}(\\theta_0)\\} = \\text{Im}\\{\\boldsymbol{\\alpha}\\}Im{b0a(θ0)}=Im{α}
其中:
A(θ)=[Re{a(θ)}−Im{a(θ)}Im{a(θ)}Re{a(θ)}]\\mathbf{A}(\\theta) = \\begin{bmatrix} \\text{Re}\\{\\mathbf{a}(\\theta)\\} & -\\text{Im}\\{\\mathbf{a}(\\theta)\\} \\\\ \\text{Im}\\{\\mathbf{a}(\\theta)\\} & \\text{Re}\\{\\mathbf{a}(\\theta)\\} \\end{bmatrix}A(θ)=[Re{a(θ)}Im{a(θ)}−Im{a(θ)}Re{a(θ)}]
这些方程连同在附录A和B中建立的两个算法的一致性,满足定理1的条件(7)(7)(7)和(8)(8)(8)。
由于在这个问题中使用了ML准则,(10)(10)(10)中的最优加权被视为等于FIM,在这种情况下是针对非结构化模型评估的。在附录B中显示,非结构化模型的FIM相对于信号{αr,αi,ω}\\{\\boldsymbol{\\alpha}_r, \\boldsymbol{\\alpha}_i, \\omega\\}{αr,αi,ω}和噪声参数是块对角的,因此(9)(9)(9)的准则将由两项组成,一项仅涉及ω\\omegaω,另一项仅涉及Q\\mathbf{Q}Q的元素。因此,这两项可以分别最小化。由于Q\\mathbf{Q}Q的参数化在结构化和非结构化模型下相同,涉及Q\\mathbf{Q}Q的项可以通过简单地设置Q^e=Q^u\\hat{\\mathbf{Q}}_e = \\hat{\\mathbf{Q}}_uQ^e=Q^u使其为零。这建立了(47)(47)(47)。
涉及η~\\tilde{\\boldsymbol{\\eta}}η~的剩余项通过将(129)(129)(129)和(130)(130)(130)代入(9)(9)(9)找到:
J=[(α^urα^uiω^u)−(A(θ)00A(θ)00)(brbiω)]TWQ~[(α^urα^uiω^u)−(A(θ)00A(θ)00)(brbiω)]J = \\left[\\begin{pmatrix} \\hat{\\boldsymbol{\\alpha}}_{ur} \\\\ \\hat{\\boldsymbol{\\alpha}}_{ui} \\\\ \\hat{\\omega}_u \\end{pmatrix} – \\begin{pmatrix} \\mathbf{A}(\\theta) & 0 \\\\ 0 & \\mathbf{A}(\\theta) \\\\ 0 & 0 \\end{pmatrix}\\begin{pmatrix} b_r \\\\ b_i \\\\ \\omega \\end{pmatrix}\\right]^T \\mathbf{W}_{\\tilde{Q}} \\left[\\begin{pmatrix} \\hat{\\boldsymbol{\\alpha}}_{ur} \\\\ \\hat{\\boldsymbol{\\alpha}}_{ui} \\\\ \\hat{\\omega}_u \\end{pmatrix} – \\begin{pmatrix} \\mathbf{A}(\\theta) & 0 \\\\ 0 & \\mathbf{A}(\\theta) \\\\ 0 & 0 \\end{pmatrix}\\begin{pmatrix} b_r \\\\ b_i \\\\ \\omega \\end{pmatrix}\\right]J=α^urα^uiω^u−A(θ)000A(θ)0brbiωTWQ~α^urα^uiω^u−A(θ)000A(θ)0brbiω
其中加权由在η~^\\hat{\\tilde{\\boldsymbol{\\eta}}}η~^处评估的FIM给出。如果我们关于ω\\omegaω最小化(131)(131)(131),简单的计算得出ω^e=ω^u\\hat{\\omega}_e = \\hat{\\omega}_uω^e=ω^u,这也验证了(48)(48)(48)。ω^e=ω^u\\hat{\\omega}_e = \\hat{\\omega}_uω^e=ω^u的事实也证明了(131)(131)(131)等于(49)(49)(49)。方程(50)(50)(50)通过将(53)(53)(53)代入(50)(50)(50)获得。因此,定理4中的所有陈述都得到验证,证明完成。





评论前必须登录!
注册