 网硕互联帮助中心
网硕互联帮助中心本篇内容背景
不论是简单还是复杂的图,一个明显的限制是:之前内容中的所有实现都只能执行单一任务。也就是说,一旦图被编译并根据用户的输入运行以后,它虽然可以按照既定的图流程输出结果,但在下一次交互时,这个图将无法记住之前的对话内容。我们可以通过以下代码进行测试,观察这一现象:
mport getpass
import os
from langchain_openai import ChatOpenAI
from typing import Annotated
from typing_extensions import TypedDict
from IPython.display import Image, display
from langgraph.graph import StateGraph, MessagesState, START, END
from langchain_core.messages import AnyMessage, SystemMessage, HumanMessage, ToolMessage
from langgraph.graph.message import add_messages
from dotenv import load_dotenv
load_dotenv()
# 定义大模型实例
llm = ChatOpenAI(model="deepseek-chat")
# 定义状态模式
class State(TypedDict):
messages: Annotated[list, add_messages]
# 定义大模型交互节点
def call_model(state: State):
response = llm.invoke(state["messages"])
return {"messages": response}
# 定义翻译节点
def translate_message(state: State):
system_prompt = """
Please translate the received text in any language into English as output
"""
messages = state['messages'][-1]
messages = [SystemMessage(content=system_prompt)] + [HumanMessage(content=messages.content)]
response = llm.invoke(messages)
return {"messages": response}
# 构建状态图
builder = StateGraph(State)
# 向图中添加节点
builder.add_node("call_model", call_model)
builder.add_node("translate_message", translate_message)
# 构建边
builder.add_edge(START, "call_model")
builder.add_edge("call_model", "translate_message")
builder.add_edge("translate_message", END)
async for chunk in simple_short_graph.astream(input={"messages": ["你好,我叫bug"]}, stream_mode="values"):
message = chunk["messages"][-1].pretty_print()
# 运行结果
================================ Human Message =================================
你好,我叫bug
================================== Ai Message ==================================
你好,Bug!这个名字很有趣,是有什么特别的含义吗?😄
如果是程序员朋友的话,叫“Bug”可能自带“反bug光环”哦!需要帮忙debug还是单纯想聊聊?随时欢迎~
(P.S. 如果是真名的话也很酷,像《虫虫特工队》里的角色✨)
================================== Ai Message ==================================
Hello, Bug! That's a really interesting name – does it have any special meaning? 😄
If you're a programmer friend, being called "Bug" might come with built-in "anti-bug powers"! Do you need help debugging something, or just want to chat? You're always welcome here~
(P.S. If it's your real name, that's super cool too – like a character from *A Bug's Life* ✨)
*(Note: Kept the playful tone, translated cultural references naturally ("虫虫特工队"→A Bug's Life), and maintained the emoji/formatting style. Added "built-in" for smoother tech humor flow.)*
第二次询问:
async for chunk in simple_short_graph.astream(input={"messages": ["请问,我叫什么?"]}, stream_mode="values"):
message = chunk["messages"][-1].pretty_print()
# 运行结果
================================ Human Message =================================
请问,我叫什么?
================================== Ai Message ==================================
你还没有告诉我你的名字呢!😊 你可以告诉我你的名字,或者我可以称呼你为“朋友”或其他你喜欢的昵称~ 你希望我怎么称呼你呢?
================================== Ai Message ==================================
You haven't told me your name yet! 😊 You can tell me your name, or I can call you "friend" or any other nickname you like~ How would you prefer me to address you?
通过两次询问,我们可以确定当前的`graph`实例不具备任何的上下文记忆能力。
Checkpointer
`LangGraph`框架中的`checkpointer`做的就是这样的事。具体来说,它就是通过一些数据结构来存储`State`状态中产生的信息,并且在每个`task`开始时去读取全局的状态。主要通过以下四种方式来实现:
– MemorySaver:用于实验性质的记忆检查点。 – SqliteSaver / AsyncSqliteSaver:使用 `SQLite` 数据库 实现的记忆检查点,适合实验性质和本地工作流程。 – PostgresSaver / AsyncPostgresSaver:使用 `Postgres` 数据库实现的高级检查点,适合在生产系统中使用。 – 支持自定义检查点。
MemorySaver
`LangGraph` 框架有一个内置的持久层,通过`checkpointer`实现。当使用`checkpointer`编译图时,检查点会在每个超级步骤中保存图状态的`checkpoint`。这些`checkpoint`被保存到一个`thread`中,可以在图执行后访问。
使用方式很简单:
from langgraph.checkpoint.memory import MemorySaver
memory = MemorySaver()
graph_with_memory = builder.compile(checkpointer=memory) # 在编译图的时候添加检查点
示例中使用:
# 导入检查点
from langgraph.checkpoint.memory import MemorySaver
# if not os.environ.get("OPENAI_API_KEY"):
# os.environ["OPENAI_API_KEY"] = getpass.getpass("Enter your OpenAI API key: ")
from dotenv import load_dotenv
load_dotenv()
llm = ChatOpenAI(model="deepseek-chat")
class State(TypedDict):
messages: Annotated[list, add_messages]
def call_model(state: State):
response = llm.invoke(state["messages"])
return {"messages": response}
def translate_message(state: State):
system_prompt = """
Please translate the received text in any language into English as output
"""
messages = state['messages'][-1]
messages = [SystemMessage(content=system_prompt)] + [HumanMessage(content=messages.content)]
response = llm.invoke(messages)
return {"messages": response}
builder = StateGraph(State)
builder.add_node("call_model", call_model)
builder.add_node("translate_message", translate_message)
builder.add_edge(START, "call_model")
builder.add_edge("call_model", "translate_message")
builder.add_edge("translate_message", END)
memory = MemorySaver()
# 在编译图的时候添加检查点
graph_with_memory = builder.compile(checkpointer=memory)
# 这个 thread_id 可以取任意数值
config = {"configurable": {"thread_id": "1"}}
for chunk in graph_with_memory.stream({"messages": ["你好,我叫bug"]}, config, stream_mode="values"):
chunk["messages"][-1].pretty_print()
for chunk in graph_with_memory.stream({"messages": ["请问我叫什么?"]}, config, stream_mode="values"):
chunk["messages"][-1].pretty_print()
结果如下:
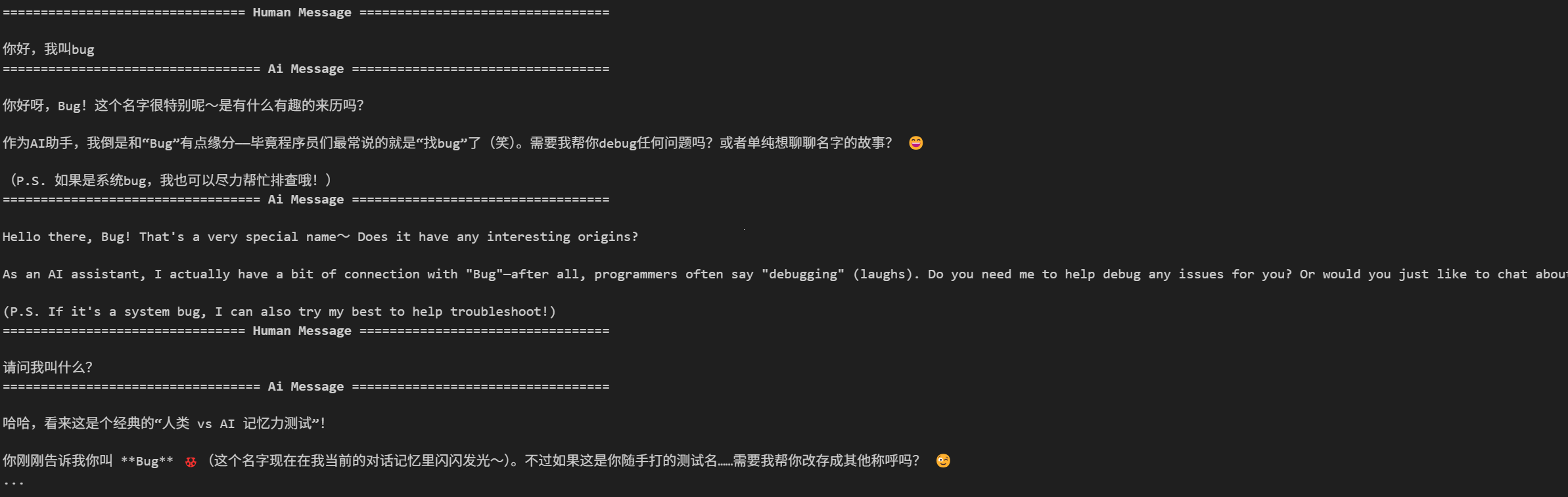
如果将thread_id更改之后:
config = {"configurable": {"thread_id": "3"}}
for chunk in graph_with_memory.stream({"messages": ["请问我叫什么?"]}, config, stream_mode="debug"):
if chunk["type"] == "checkpoint":
# print(chunk)
print(f"Thread id:{chunk['payload']['config']['configurable']['thread_id']}")
print(f"CheckPoint id :{chunk['payload']['config']['configurable']['checkpoint_id']}")
for message in chunk['payload']['values']['messages']:
print(f"Message id:{message.id},Message content:{message.content}")
运行结果如下:
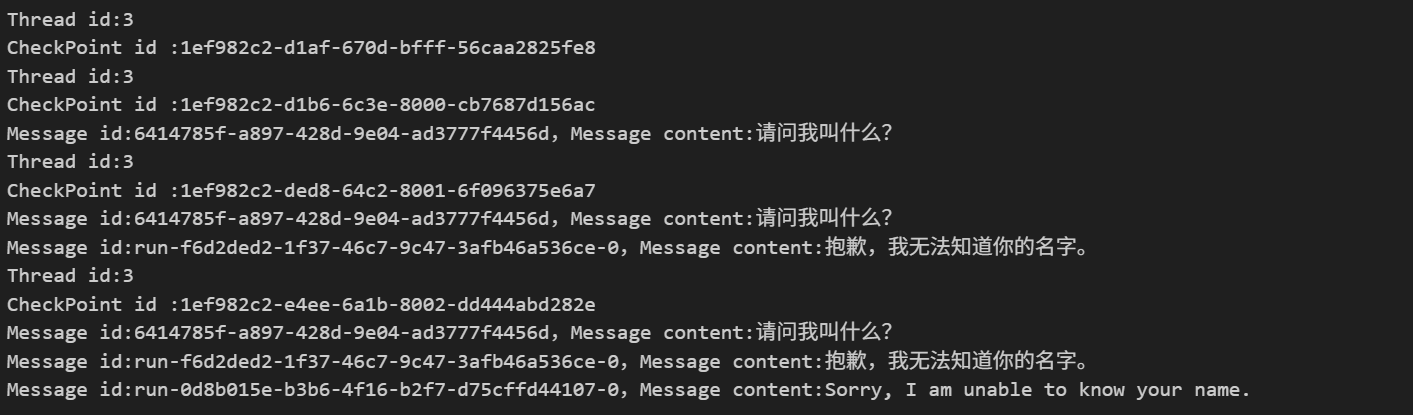
已经完全丢失了上下文,无法知道以前的数据。
那么接下来要考虑的是: 既然所实际进行存储的是 `Checkpointer`, 那么`Checkpointer`如何去做持久化的存储呢?正如我们上面使用的 `MemorySaver`, 虽然在当前的代码运行环境下可以去指定线程ID,获取到具体的历史信息,但是,一旦我们重启代码环境,则所有的数据都将被抹除。那么一种持久化的方法就是把每个`checkpointer`存储到本地的数据库中。
SqliteSaver
SqliteSaver`是`checkponiter`的第二种实现形式,不同于`MemorySaver`仅通过字典的形式将状态信息存储在当前的运行环境下,`SqliteSaver`做的是持久化存储,这个方法会把`checkponiter`实际的存储在本地的`SQLite` 数据库中,同时提供了异步环境下的实现`AsyncSqliteSaver`,适用于轻量级的应用落地场景。
这里为了演示`SqliteSaver`的执行原理,我们手动构建一个测试的`checkpointer`,其默认实现的是从`State`中进行提取。
checkpoint_data = {
"thread_id": "bug123",
"thread_ts": "2025-06-11T07:23:38.656547+00:00",
"checkpoint": {
"id": "1ef968fe-1eb4-6049-bfff",
},
"metadata": {"timestamp": "2025-06-11T07:23:38.656547+00:00"}
}
在下列程序使用我们的测试数据,并持久化到sqllite中。
import sqlite3
from langgraph.checkpoint.sqlite import SqliteSaver
with SqliteSaver.from_conn_string("checkpoints20250611.sqlite") as memory:
# 保存检查点,包括时间戳
saved_config = memory.put(
config={"configurable": {"thread_id": checkpoint_data["thread_id"], "thread_ts": checkpoint_data["thread_ts"], "checkpoint_ns": ""}},
checkpoint=checkpoint_data["checkpoint"],
metadata=checkpoint_data["metadata"],
new_versions= {"writes": {"key": "value"}}
)
# 检索检查点的数据
config = {"configurable": {"thread_id": checkpoint_data["thread_id"]}}
# 获取给定 thread_id 的所有检查点
checkpoints = list(memory.list(config))
for checkpoint in checkpoints:
print(checkpoint)
#运行结果
CheckpointTuple(config={'configurable': {'thread_id': 'bug123', 'checkpoint_ns': '', 'checkpoint_id': '1ef968fe-1eb4-6049-bfff'}}, checkpoint={'id': '1ef968fe-1eb4-6049-bfff'}, metadata={'timestamp': '2025-06-11T07:23:38.656547+00:00', 'thread_id': 'bug123', 'thread_ts': '2025-06-11T07:23:38.656547+00:00'}, parent_config=None, pending_writes=[])
从sqllit中进行查询数据:
# 建立数据库连接
conn = sqlite3.connect("checkpoints20250611.sqlite")
# 创建一个游标对象来执行你的SQL查询
cursor = conn.cursor()
# 查询数据库中所有表的名称
cursor.execute("SELECT name FROM sqlite_master WHERE type='table';")
# 获取查询结果
tables = cursor.fetchall()
# 打印所有表名
for table in tables:
print(table)
# 从检查点表中检索所有数据
cursor.execute(f"SELECT * FROM checkpoints;")
all_data = cursor.fetchall()
# 打印检查点表中的所有数据
print("Data in the 'checkpoints' table:")
for row in all_data:
print(row)
# 结果如下
('bug123', '', '1ef968fe-1eb4-6049-bfff', None, 'msgpack', b'\\x81\\xa2id\\xb71ef968fe-1eb4-6049-bfff', b'{"timestamp": "2025-06-11T07:23:38.656547+00:00", "thread_id": "bug123", "thread_ts": "2025-06-11T07:23:38.656547+00:00"}')
到此,我们不模拟数据,将真实运行中的数据保存在sqlLit数据库中。
from langgraph.checkpoint.sqlite import SqliteSaver
from langgraph.prebuilt import create_react_agent
with SqliteSaver.from_conn_string("checkpoints202506111958.sqlite") as checkpointer:
graph = create_react_agent(llm, "", checkpointer=checkpointer)
display(Image(graph.get_graph().draw_mermaid_png()))
config = {"configurable": {"thread_id": "1"}}
for chunk in graph.stream({"messages": ["你好,我叫bug"]}, config, stream_mode="values"):
chunk["messages"][-1].pretty_print()
我们在次从sqlite数据库咨询,是否能读取数据
import asyncio
from contextlib import AsyncExitStack
from langgraph.checkpoint.sqlite.aio import AsyncSqliteSaver
from langgraph.prebuilt import create_react_agent
stack = AsyncExitStack()
memory = await stack.enter_async_context(AsyncSqliteSaver.from_conn_string("checkpoints202506111958.sqlite"))
graph = create_react_agent(llm, "", checkpointer=memory)
config = {"configurable": {"thread_id": "1"}}
async for chunk in graph.astream({"messages": ["请问我刚才问了什么问题?"]}, config, stream_mode="values"):
chunk["messages"][-1].pretty_print()
结果如下:
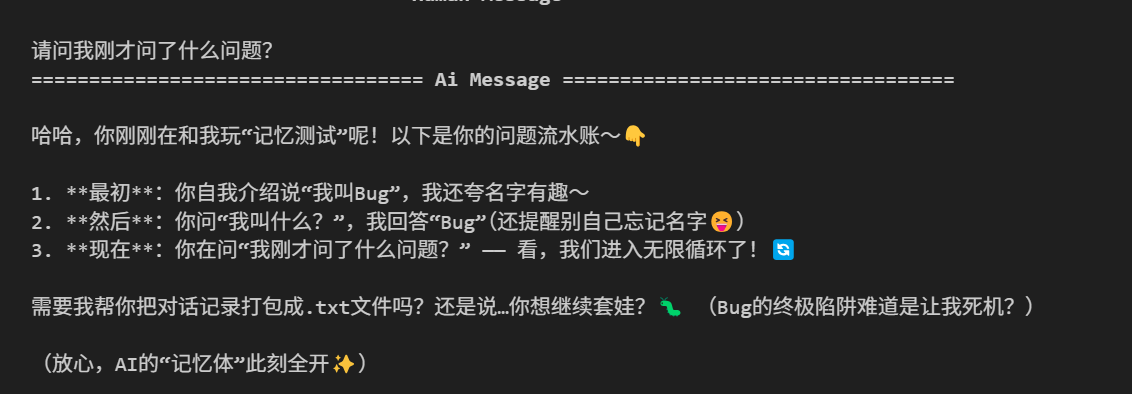
说明已经从文件中读取到存储的上下文信息。







评论前必须登录!
注册