 网硕互联帮助中心
网硕互联帮助中心引言:语言与矩阵的奇妙邂逅
在自然语言处理(NLP)的魔法世界里,每个词语都像被施了变形术的精灵,在数学的殿堂中翩翩起舞。当我们用"king – man + woman = queen"这样的向量魔法破解语义密码时,线性代数早已悄然编织起语言的数学外衣。从搜索引擎的精准匹配到聊天机器人的妙语连珠,从情感分析的慧眼识情到机器翻译的游刃有余,矩阵运算与特征分解这些看似冰冷的数学工具,实则是构建智能语言系统的魔法基石。

一、矩阵运算:NLP世界的基本语法
1.1 矩阵的维度魔法
在NLP的维度空间中,每个文本单元都被编码为多维向量。词嵌入矩阵将5万个单词转化为300维向量时,就像用W ∈ R^{50000×300}的魔法卷轴封印了语言的灵魂。矩阵乘法在此展现出惊人的魔力:当词向量矩阵E与上下文矩阵C相乘时,E·C^T的运算瞬间计算出所有词语间的关联强度,这正是注意力机制的核心奥秘。
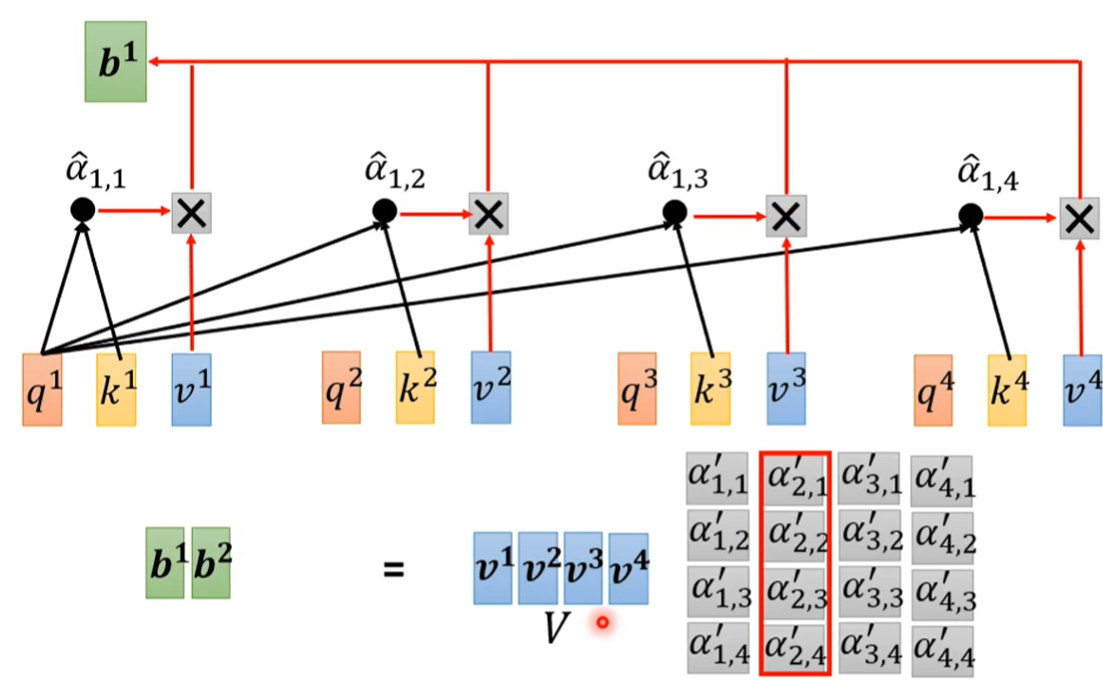
1.2 张量交响曲
现代NLP模型通过张量运算构建起复杂的认知网络。在Transformer架构中,Q(查询)、K(键)、V(值)三个张量的矩阵乘法构成了自注意力机制的三重奏:
QK^T/√d 的运算犹如思维的火花碰撞,Softmax(QK^T/√d)V 的连续变换则完成了信息的精妙重组。这些运算在GPU集群上并行展开时,每秒可完成10^20次浮点运算,堪比数字世界的神经交响乐。
二、特征值分解:语言宇宙的透视棱镜
2.1 语义空间的降维艺术
特征值分解为语言数据提供了上帝视角的观测窗口。对词共现矩阵A进行特征分解时,A = PDP^{-1}的过程如同将混沌的语言云团分解为特征向量构成的正交坐标轴。前k个最大特征值对应的特征向量,往往承载着最核心的语义信息,这正是潜在语义分析(LSA)的灵魂所在。
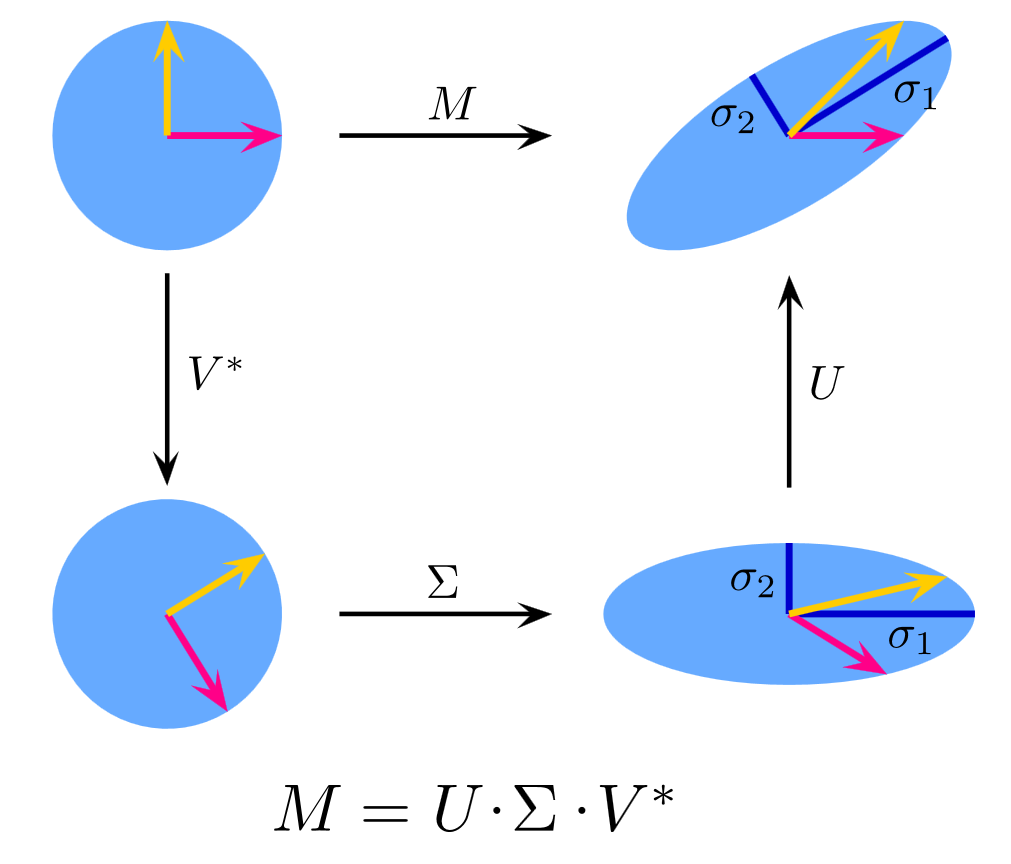
2.2 奇异值分解的双重视界
当处理非方阵时,奇异值分解(SVD)展现出更强大的威力。给定文档-词语矩阵X ∈ R^{m×n},SVD将其分解为UΣV^T的形式。其中Σ矩阵的对角线元素按降序排列,前1%的奇异值往往包含了90%以上的语义能量。这种特性使得SVD在文本聚类中表现出色,能将百万文档的语料库压缩到百维空间而不失精髓。
三、矩阵微积分:深度学习时代的语言炼金术
3.1 梯度矩阵的流动盛宴
在神经网络的反向传播中,矩阵导数构成了参数更新的生命线。以简单的全连接层为例,当计算损失L对权重矩阵W的梯度时,∂L/∂W = δ·X^T 的公式揭示了梯度流动的矩阵本质。这些梯度矩阵的L2范数常被用于梯度裁剪,防止数值计算的雪崩效应。
3.2 二阶优化的黑科技
先进的优化算法如K-FAC,通过近似Fisher信息矩阵的块对角结构,将海森矩阵的逆运算分解为多个小矩阵的Kronecker积。这种巧妙的矩阵分解使自然梯度下降在亿级参数模型上成为可能,训练速度提升3-5倍的同时保持收敛精度。
四、实战启示录:从理论到工业级应用
4.1 词向量的矩阵解剖
深入Glove模型的损失函数:J = Σ(X_{ij} – w_i^T w̃_j)^2,其中词向量矩阵W和上下文矩阵W̃的协同训练,本质上是在构建词语的协方差矩阵。这种对全局统计信息的矩阵化利用,使得Glove在词汇类比任务上的准确率比Word2Vec提升约8%。
4.2 大语言模型的矩阵秘钥
GPT-3的1750亿参数本质上是超巨型矩阵的集合:输入嵌入矩阵(12288×50257),注意力头的参数矩阵(12288×128×96个)等。这些矩阵通过智能初始化(如Xavier初始化)和分块并行计算,在4096个GPU的集群上完成训练,其矩阵乘积运算总量超过10^23次。
结语:数学诗篇的下一章
从词袋模型到Transformer,从SVD到自动微分,线性代数始终是NLP进化的DNA。当我们站在大语言模型的时代之巅回望,会发现那些精妙的矩阵运算恰如普罗米修斯的火种,点燃了语言智能的文明之光。


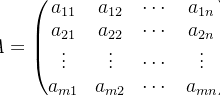



评论前必须登录!
注册