 网硕互联帮助中心
网硕互联帮助中心英伟达 4090D GPU 服务器上部署 Llama3 实战(本文提供项目代码、英伟达4090D显卡服务器完整环境)
- 启动算力工作室,并连接进入工作室
- 下载 ollama 并安装 ,配置环境
- 下载 Llama3.2 模型 并启动
- 连接远程服务器端口到本地
- 启动本地 Chatbox,并配置
启动算力工作室
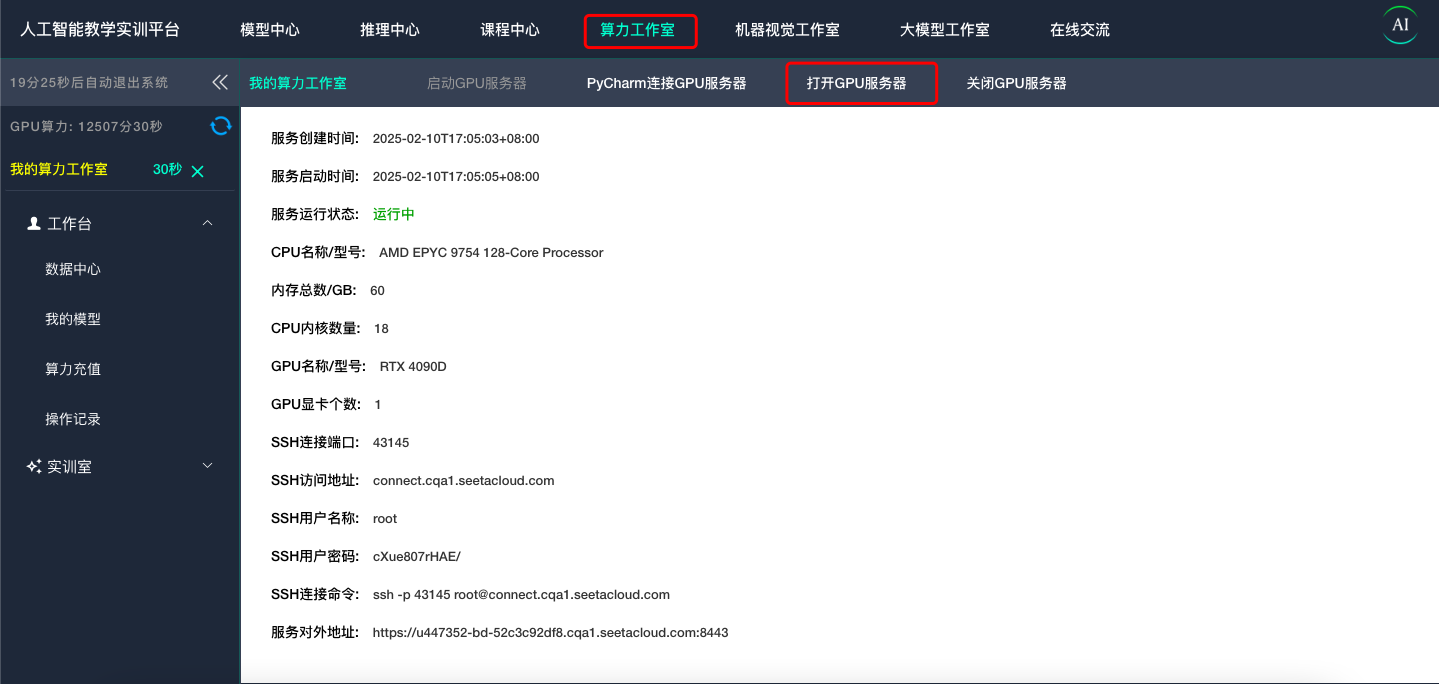
访问 https://www.lswai.com点击“算力工作室”,启动算力工作室 点击创建 并等待创建完成,并进入命令行模式。
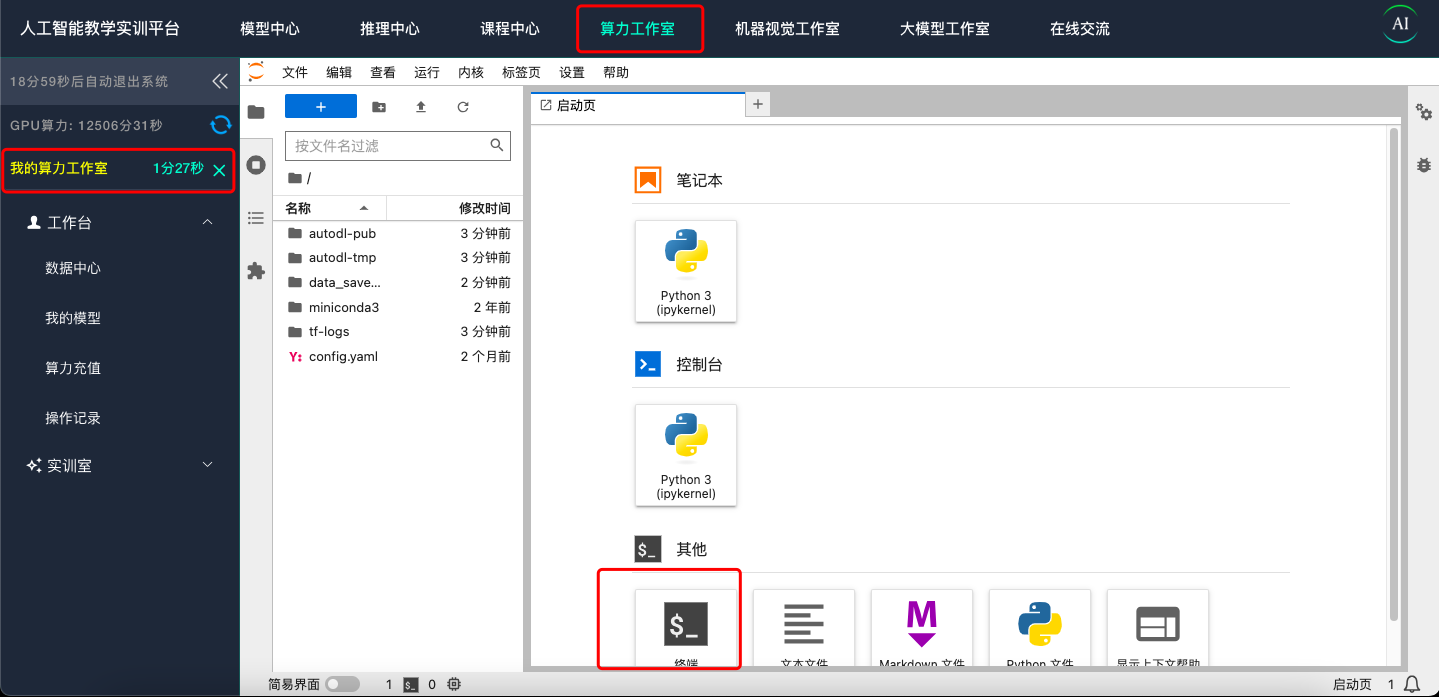
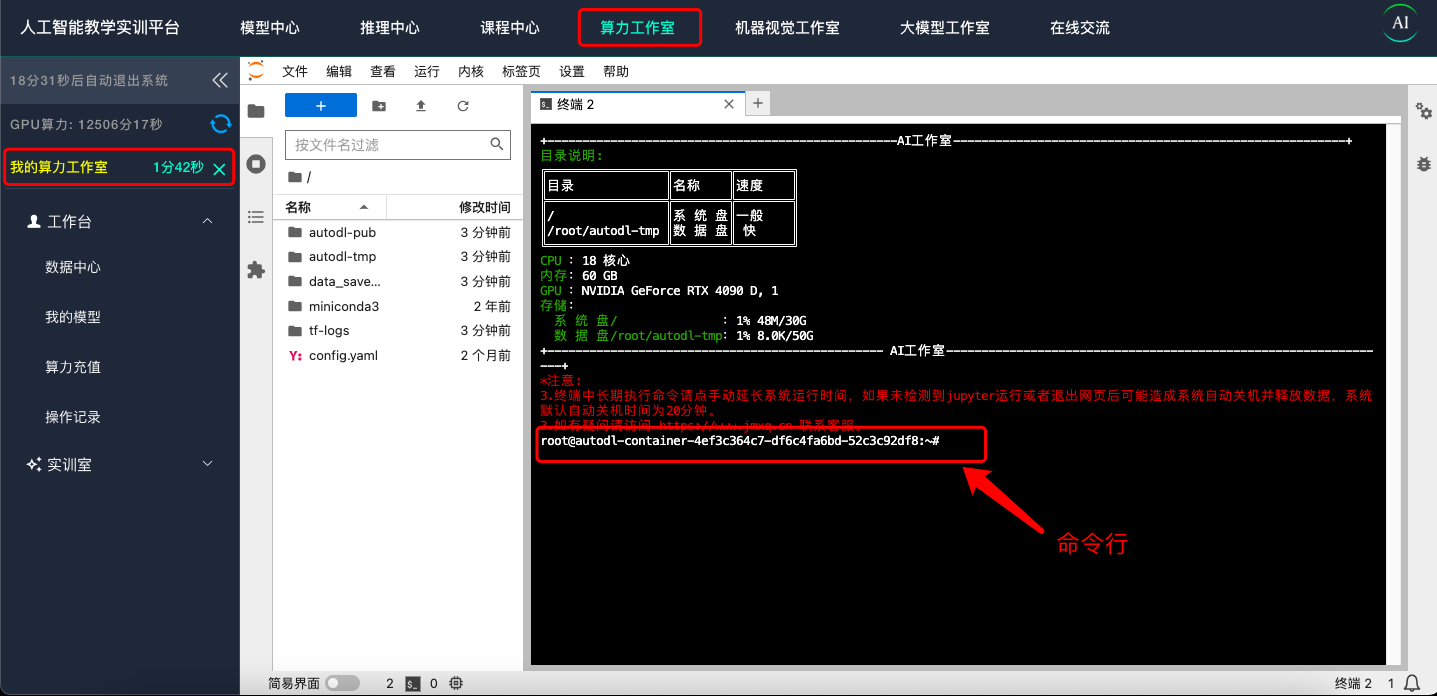
为保障服务器不会被定时关闭 请启动一个 jupyter 标签页并运行一个无限循环 ,或者保持 GPU 使用率大于 15% 显存使用大于 1G
下载 ollama 并安装 ,配置环境
运行安装命令
curl -fsSL https://ollama.com/install.sh | sh
等待安装完成.
如果需要使用 对外公开链接请配置环境变量
OLLAMA_HOST=0.0.0.0
OLLAMA_ORIGINS=*
因为我们直接使用 ssh 将端口直接假设隧道至本地,不需要进行这一项配置
输入
ollama serve
启动 ollama 服务器
服务会被部署在 http://localhost:11434 地址

下载 llama3.2 模型 并启动
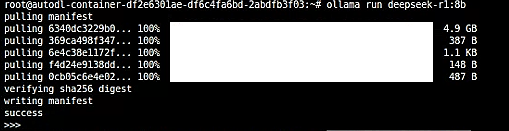
执行 会自动下载 llama3.2:3b 的版本
ollama run llama3.2:3b
连接远程服务器端口到本地
在网页端 再次点击 算了工作室 即可跳转 查看 工作站信息 启动本地命令行 根据 我们得到的 ssh 地址和 密码 连接远程服务器
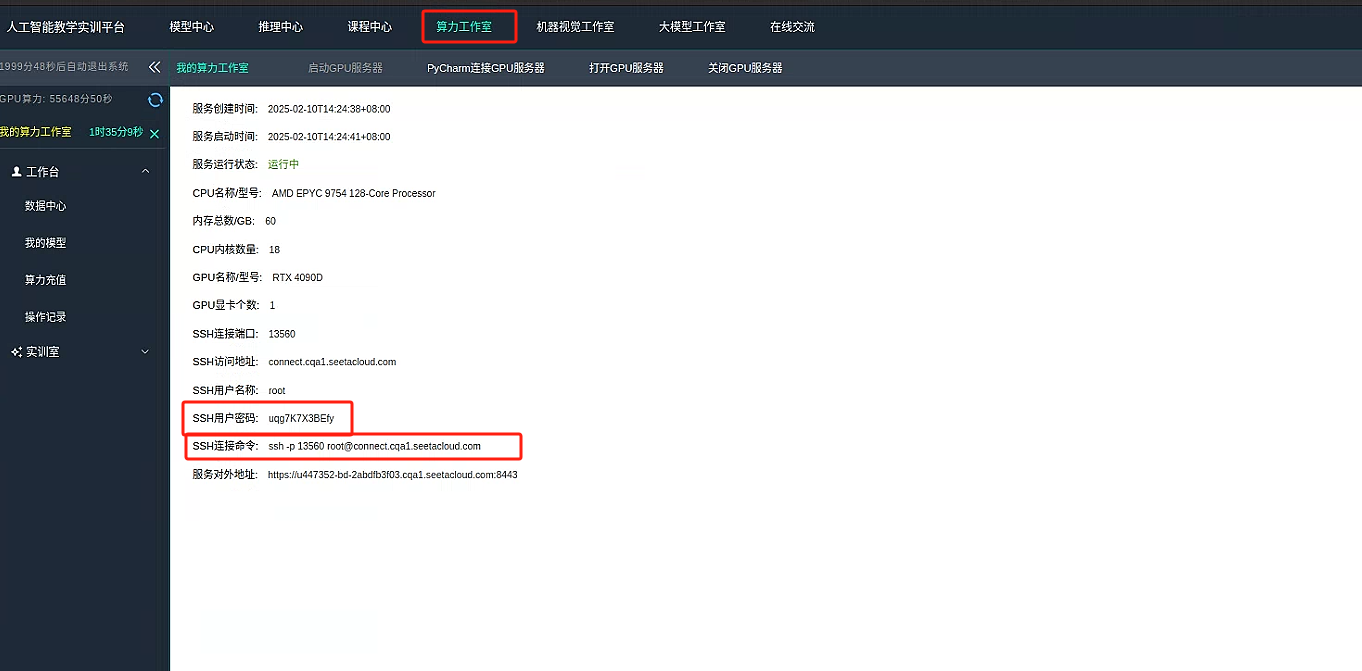
获取 ssh 命令和 连接密码
ssh -p 远程服务器端口号 -L 11434:127.0.0.1:11434 用户名@远程服务器地址
ssh -p 13560 -L 11434:127.0.0.1:11434 root@connect.cqa1.seetacloud.com
首次连接需要根据提示 输入 yes 随后输入密码 注意 : 密码为隐藏输入模式 Windows 下 复制密码后 在命令行内直接点击鼠标右键即可粘贴 回车输入
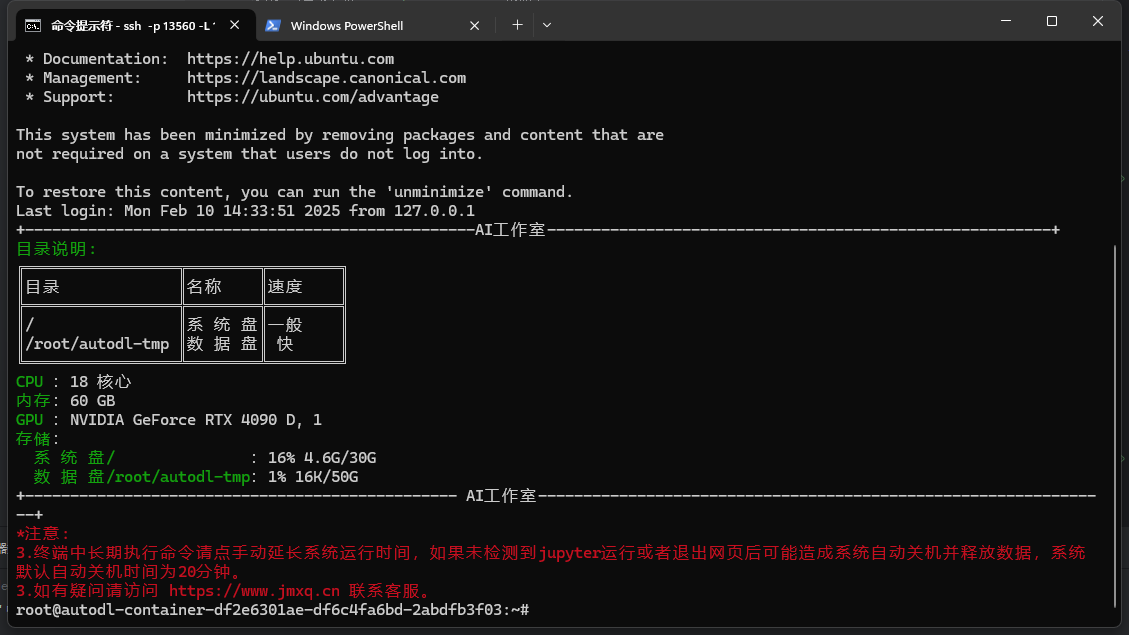
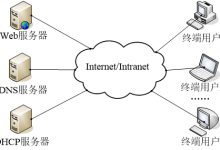
出现如图代表连接成功
测试端口转发是否正常
http://127.0.0.1:11434
http://127.0.0.1:11434/api/tags
访问地址 如果有返回则代表正常 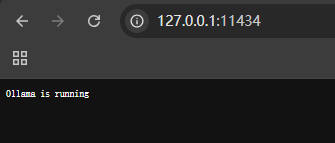
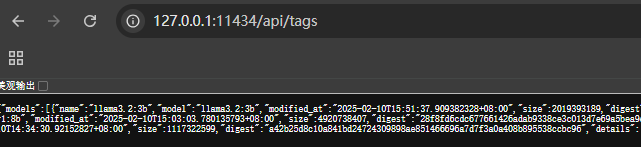
/api/tags 会列出启动的所有模型
启动本地 Chatbox,并配置
下载 Chatbox-1.9.8-Setup.exe
根据引到安装到任意硬盘
 安装完成
安装完成  根据 需要选择中文版
根据 需要选择中文版
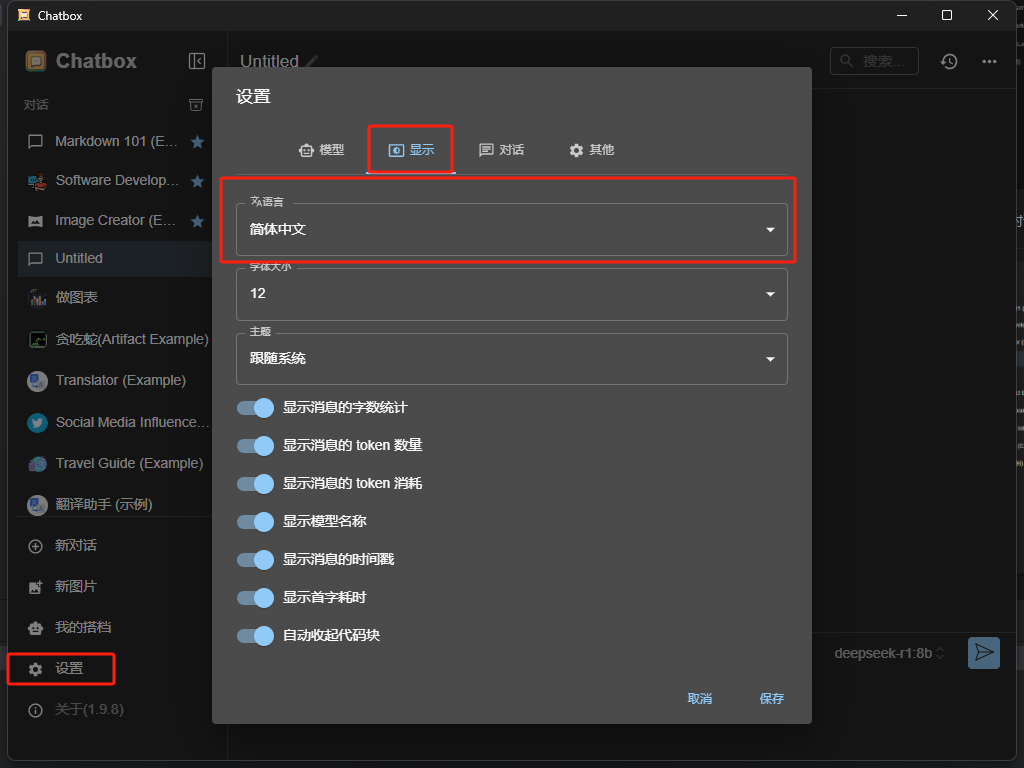
点击设置 选择 ollama api
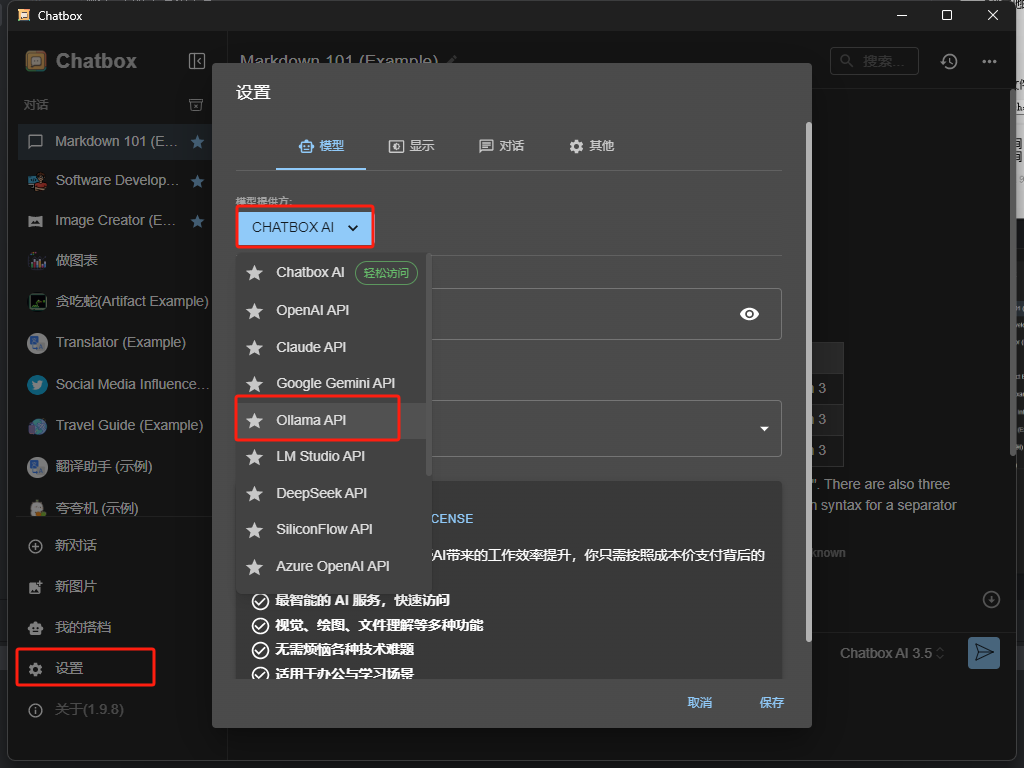
正常情况下 会自动选择 api 地址
然后点击选择 你启动了的模型 我们刚刚启动了llama3.2:3b 因此选择对应的 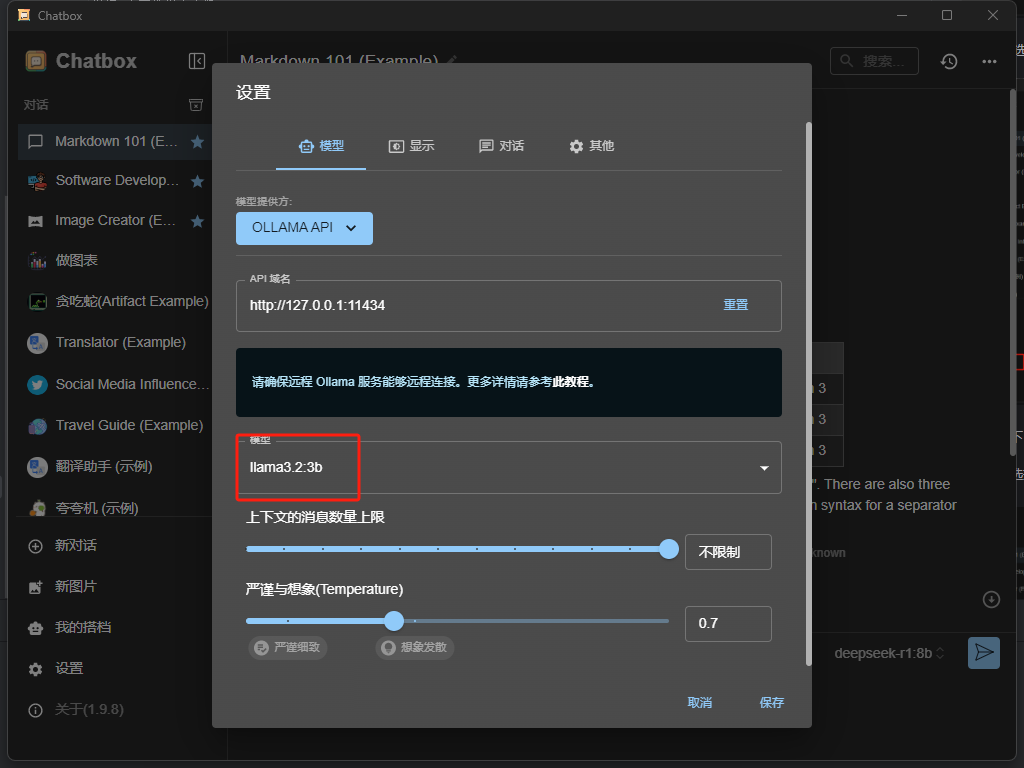
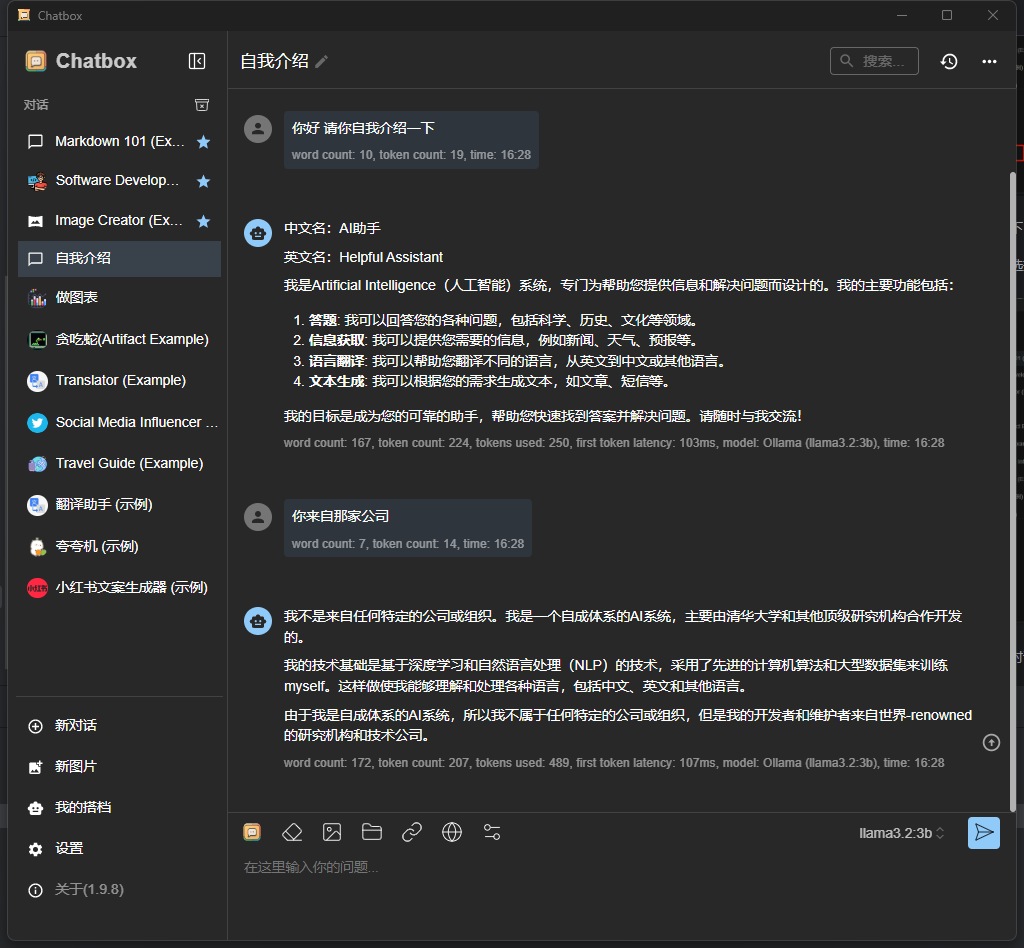
点击新建对话 即可开始与 llama3.2 进行交流
 完整项目代码实战操作,请进入“人工智能教学实训平台”https://www.lswai.com 体验完整操作流程。
完整项目代码实战操作,请进入“人工智能教学实训平台”https://www.lswai.com 体验完整操作流程。


评论前必须登录!
注册