 网硕互联帮助中心
网硕互联帮助中心
DeepSeek服务器挤爆了 教你一招解决——Ollama 本地部署DeepSeek
文章浏览阅读5.4k次。蒸馏版本本地化部署的意义在于,可以免费使用个人电脑算力进行逻辑推理。而且,蒸馏模型相对于教师模型,是一个体积缩小60% 到80%、推理速...
文章浏览阅读5.4k次。蒸馏版本本地化部署的意义在于,可以免费使用个人电脑算力进行逻辑推理。而且,蒸馏模型相对于教师模型,是一个体积缩小60% 到80%、推理速...
文章浏览阅读964次,点赞16次,收藏20次。本地服务器部署开源大模型有一个前提,就是得有 GPU 显卡资源,在我下面的例子中我租用了 autodl 中的算力资...
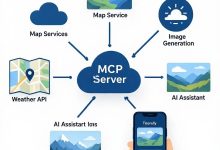
文章浏览阅读1k次,点赞14次,收藏13次。因此如果大语言模型可以自由的使用不同专长模态的模型, 它就可以快速准确的解决自身技术的不足, 和扩展处理业务范围, ...
文章浏览阅读1.9k次,点赞22次,收藏25次。LLaMA-Factory 是一个强大的大型语言模型微调框架:支持多种模型:涵盖 LLaMA、LLaVA、Mis...
![一文搞明白DeepSeek【满血版】和【贫血版】差异,以及【X86架构】和【C86架构】(搭配国产卡)服务器,硬件配置参数要求 [文末有福利]【建议收藏】-网硕互联帮助中心](https://www.wsisp.com/helps/wp-content/uploads/2025/04/20250418172919-68028bef78eee-220x150.png)
文章浏览阅读6.6k次,点赞40次,收藏38次。关于671B转译和量化过程中智商降低多少的问题,是一个开放性问题,转译和量化一定是跟原版的智商是有区别的,智商下...
文章浏览阅读858次,点赞6次,收藏5次。因为我们实验室的服务器不能联网,所以glm4部署到docker里面,如果有需要补充的包只能在本地下载好了,再上传到服务...
文章浏览阅读759次,点赞10次,收藏11次。Uvicorn 是一个基于 Python 的快速 ASGI(异步服务器网关接口)服务器。它的主要作用是作为 Web...

文章浏览阅读1.7k次,点赞37次,收藏35次。Deepseek官网老是显示服务器繁忙?显卡闲着不用可惜了,本地化部署Deepseek-R1模型体验独自畅享对话...

文章浏览阅读878次,点赞7次,收藏29次。最近DeepSeek大火,很多人都想用DeepSeek,但是无奈经常提示服务器繁忙,那就试试将DeepSeek部署到...

文章浏览阅读6.7k次,点赞12次,收藏41次。DeepSeek的火爆,不仅让我们看到了国产AI的崛起,也让我们意识到,技术的进步正在让AI变得更加普惠。无论是...
