 网硕互联帮助中心
网硕互联帮助中心一、能耗监测的“三大死穴”,90%的企业都在踩
做工业自动化这么多年,我发现能耗管理的痛点逃不出这三个“死穴”:
1. 设备“语言不通”:旧设备成了“数据孤岛”
很多工厂的“能耗黑洞”藏在老设备里。比如我接触过的某汽配厂,车间有8台2005年买的车床,用的是RS485接口的旧电表,而市面上的标准化监测系统只支持Modbus TCP,根本接不上。结果这些设备的能耗数据只能靠人工抄表,误差高达15%。
2. 数据“雾里看花”:只知道总能耗,不知道“谁在浪费”
去年帮浙江一家服装厂做诊断,他们的电费单显示“月均8万”,但没人知道这8万里,空调占35%、照明占20%、闲置设备待机占18%。就像家里开着所有水龙头却只看总水表,根本找不到漏水点。
3. 方案“水土不服”:标准化系统难解个性化需求
某食品厂曾花20万买了套“通用能耗监测系统”,结果发现系统预设的“空调能耗模型”和他们车间的“蒸汽加热+热风循环”工艺完全不匹配。最后系统成了摆设,只在领导检查时亮个屏。
二、基于 Java 的能源管理系统架构解析
一个典型的基于 Java 的能源管理系统通常采用分层架构设计,这种架构模式将系统的不同功能模块进行分离,使得系统具有良好的可维护性、可扩展性和可复用性。

三、数据采集层
数据采集层是能源管理系统的 “触角”,负责从各种能源设备和数据源中收集原始能源数据 。这一层主要通过传感器、智能电表、智能水表、燃气表等设备来实现数据采集 。例如,在工业生产场景中,电流传感器和电压传感器可以实时监测生产设备的电力消耗情况,将采集到的模拟信号转换为数字信号,然后传输给数据采集设备;智能电表则能够自动记录用电量,并具备通信功能,可以通过有线或无线方式将电量数据发送出去 。
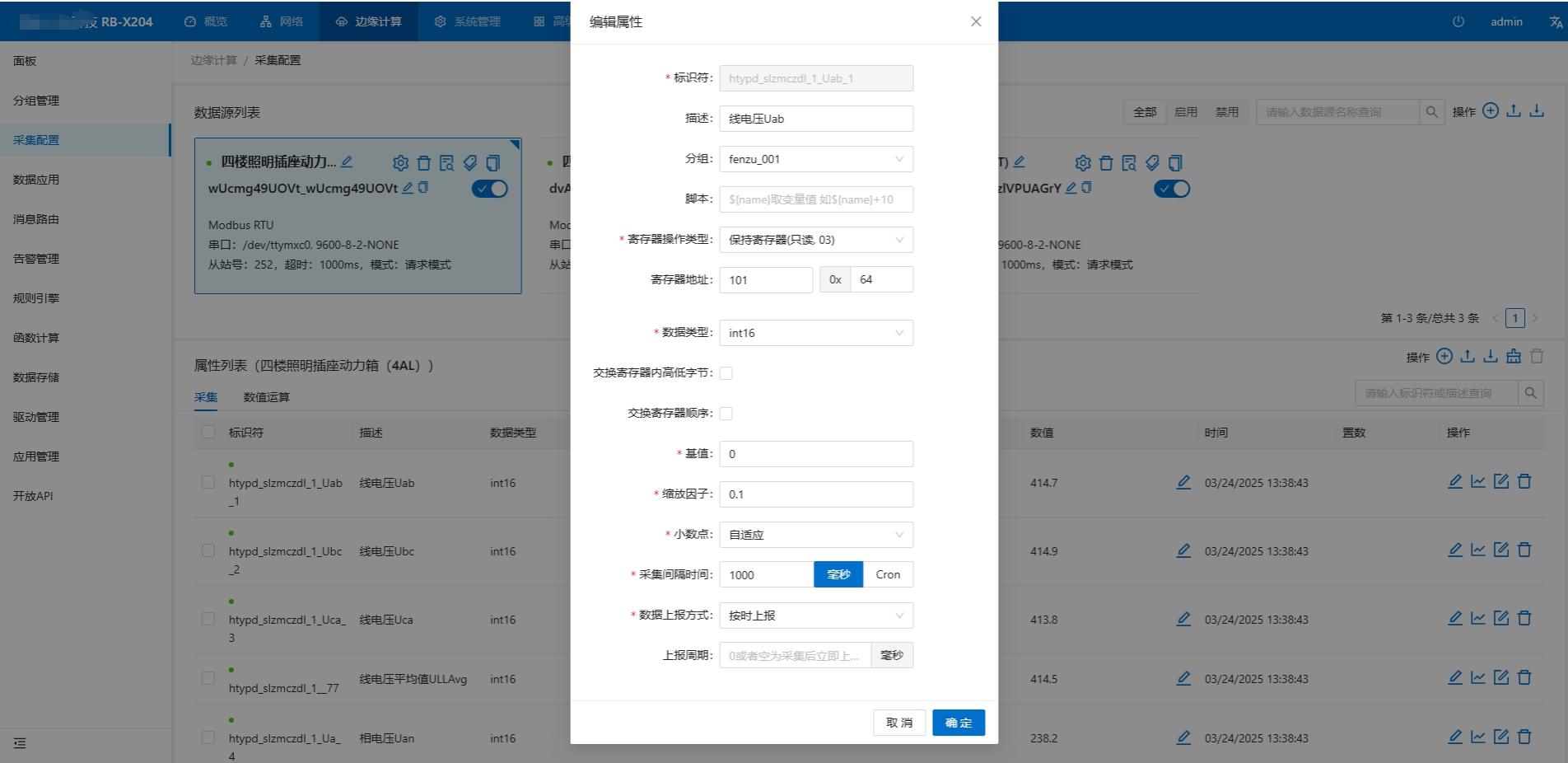
四、业务逻辑层
业务逻辑层是能源管理系统的 “智慧中枢”,它承载着系统的核心业务功能,通过编写 Java 代码实现各种复杂的业务逻辑,将数据处理与存储层提供的数据转化为有价值的信息和决策依据 。
在能源数据统计分析方面,业务逻辑层运用 Java 的面向对象编程特性,将各种统计分析算法封装成独立的类和方法 。例如,为了实现能源消耗的同比和环比分析,创建一个 EnergyAnalysis 类,在其中定义 calculateYoY(计算同比)和 calculateMoM(计算环比)方法 。这些方法从数据处理与存储层获取历史能源数据和当前数据,通过特定的计算公式得出同比和环比的结果,并将结果返回给用户界面层进行展示 。通过这种方式,不仅提高了代码的可读性和可维护性,还便于对统计分析算法进行扩展和优化 。
设备管理也是业务逻辑层的重要功能之一 。在能源管理系统中,需要对各种能源设备进行全面的管理,包括设备的注册、状态监测、故障预警等 。以设备状态监测为例,通过 Java 的定时任务调度框架,如 Quartz,定期从数据采集层获取设备的运行数据,如温度、压力、转速等 。然后,在业务逻辑层中编写逻辑代码,将这些实时数据与设备的正常运行参数进行对比 。如果发现某个设备的运行数据超出正常范围,系统会触发故障预警机制,通过短信、邮件或系统弹窗等方式通知相关管理人员,以便及时采取措施进行设备维护和修复,保障能源设备的稳定运行 。
五、软件界面层

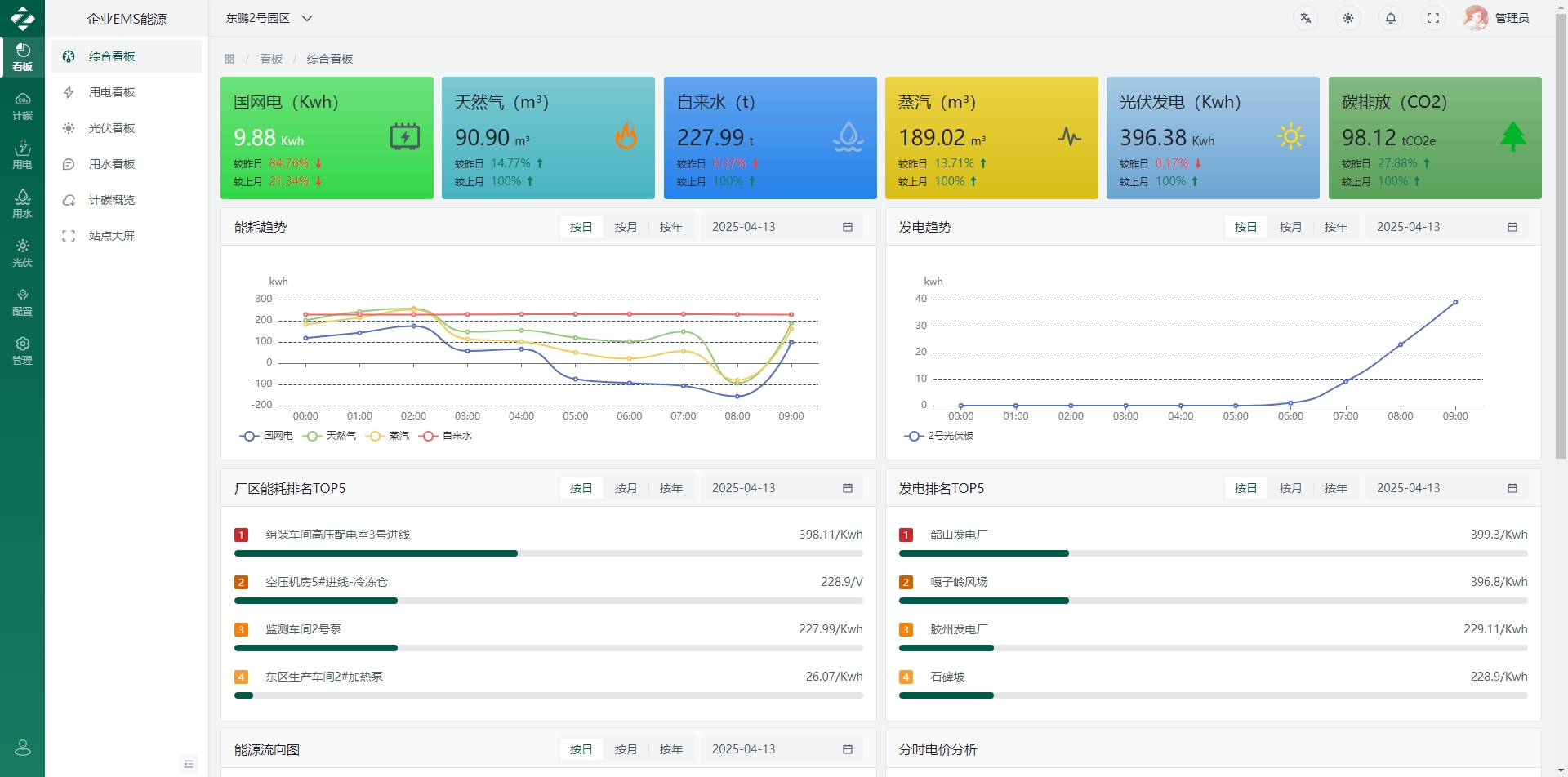
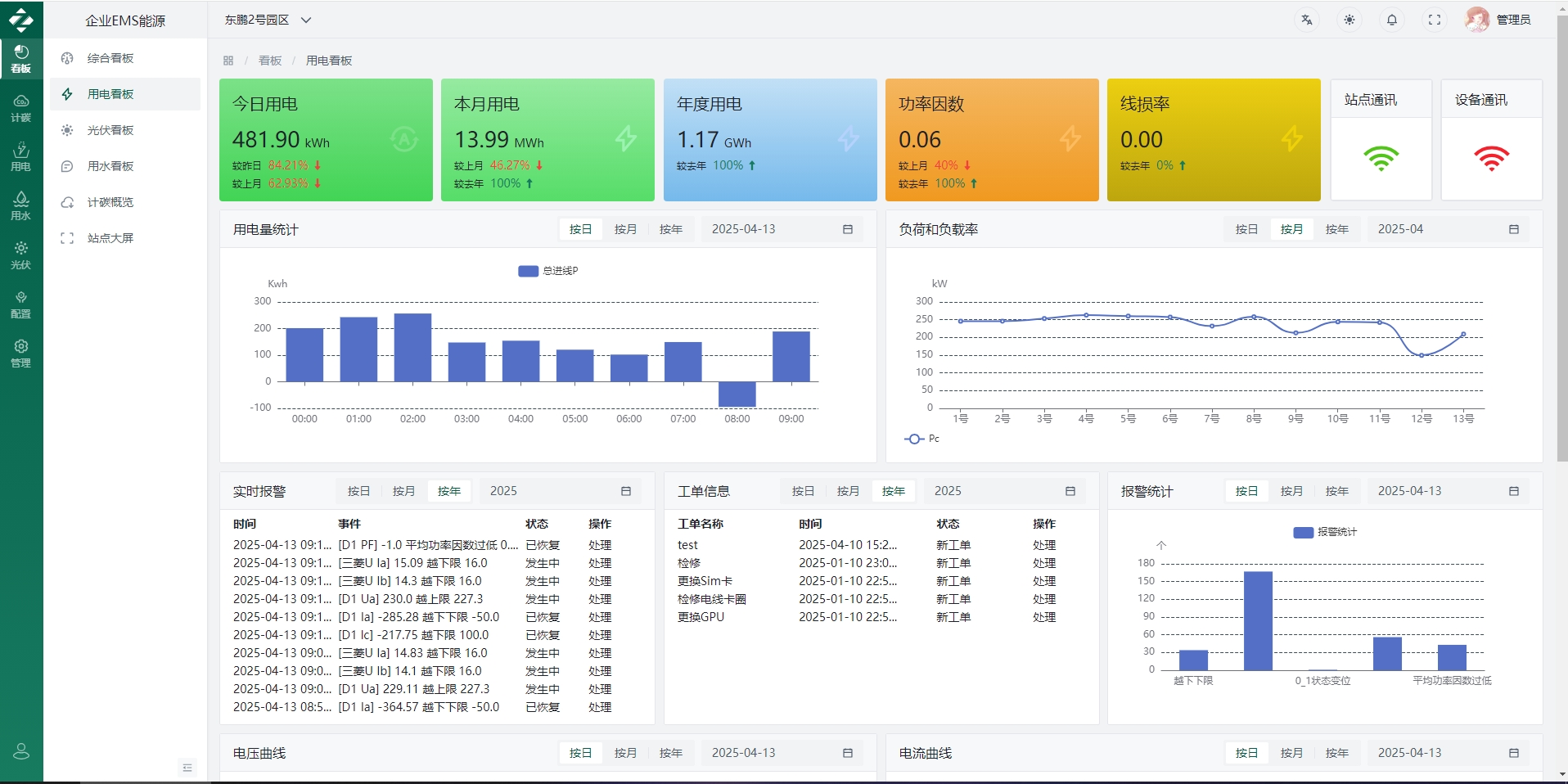
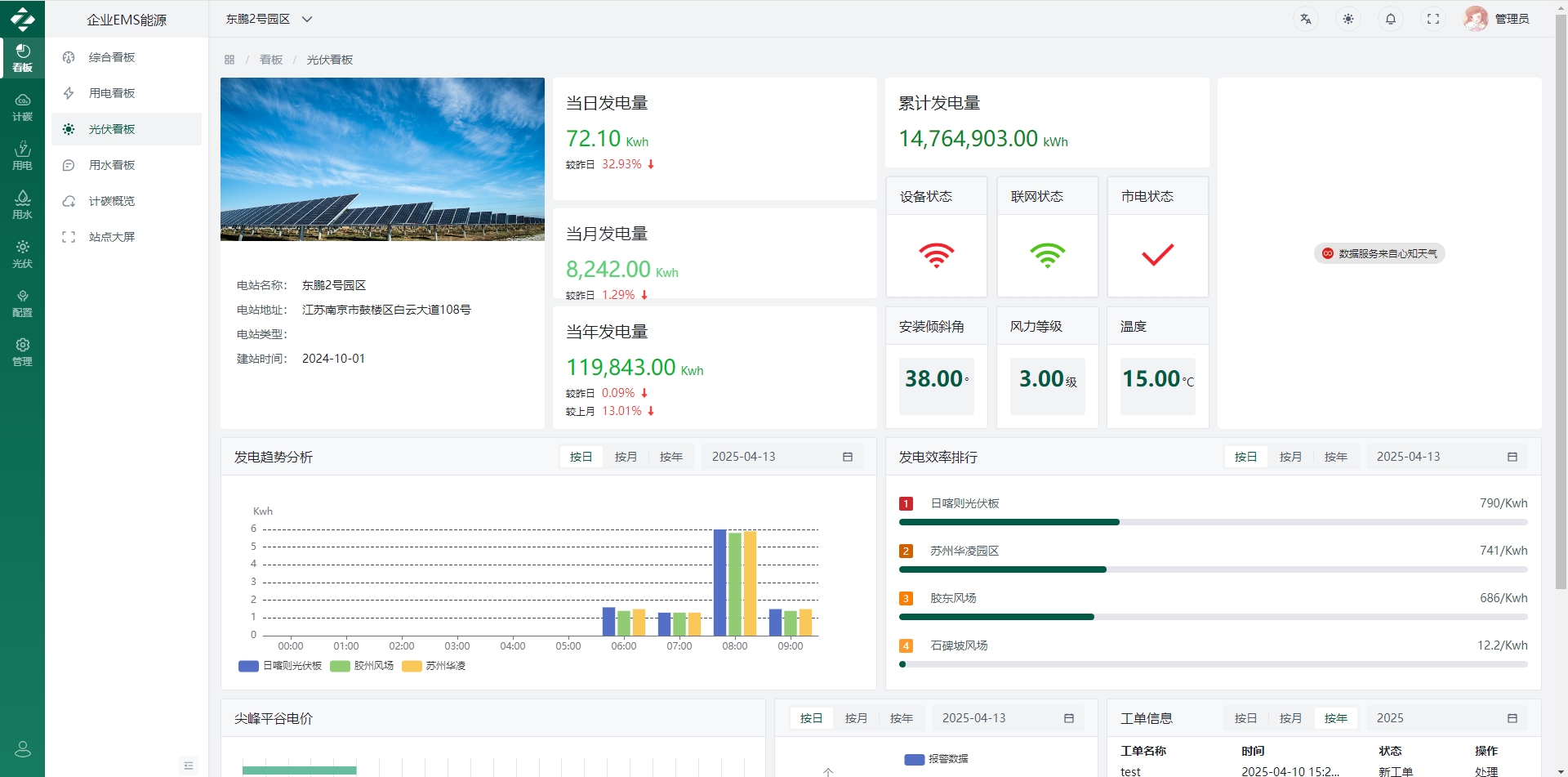
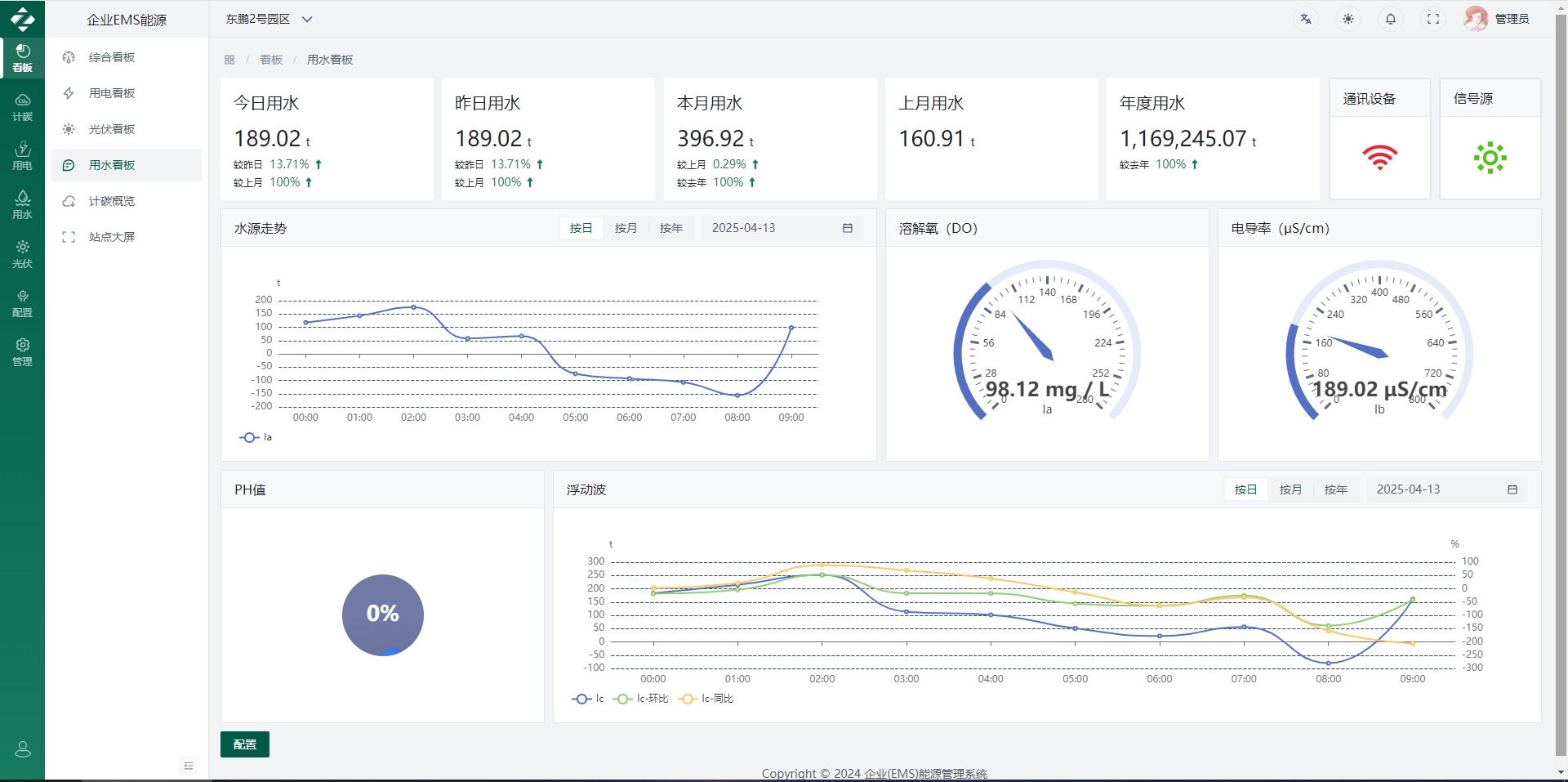

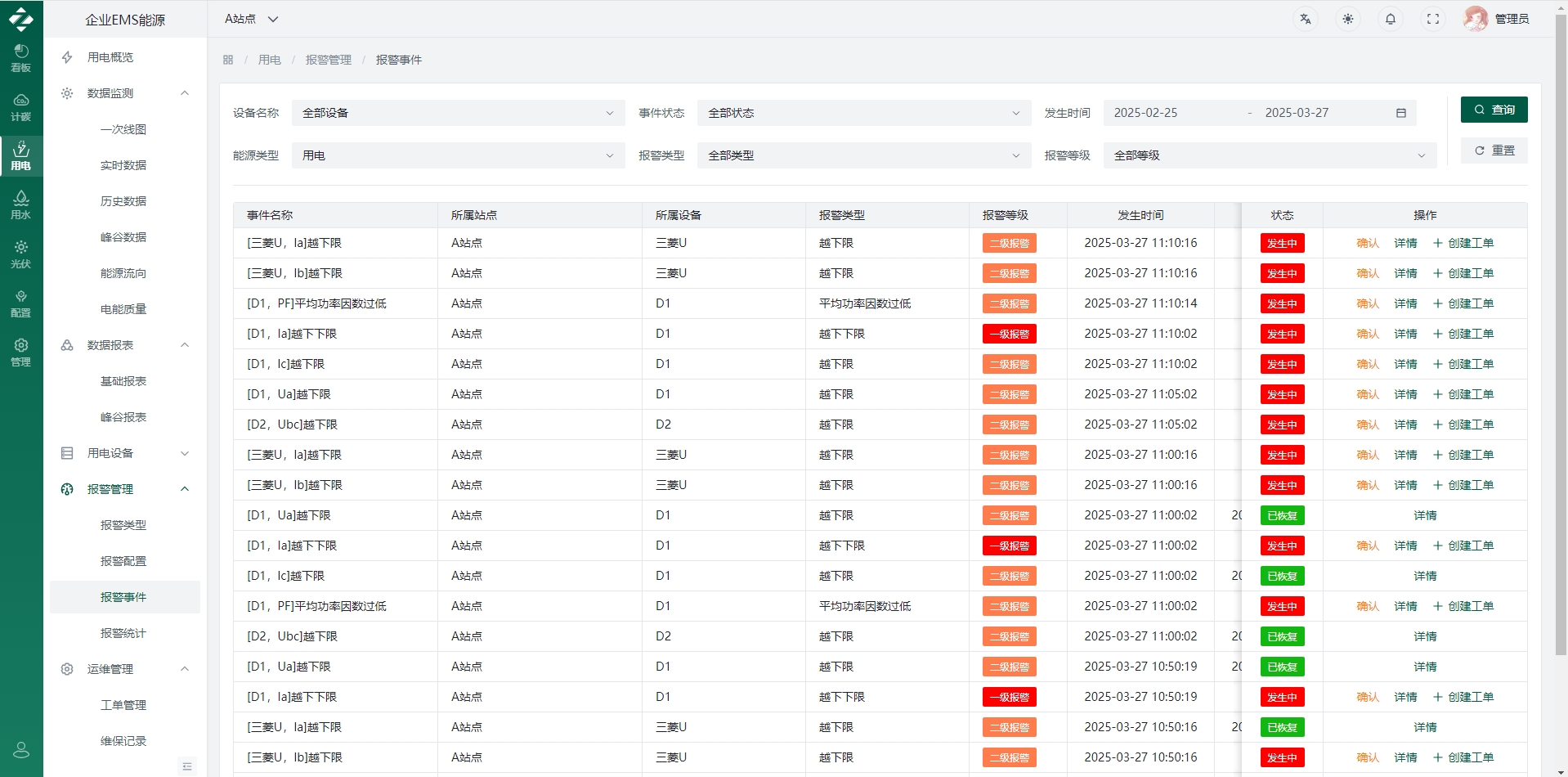
六、从“能用”到“好用”:源码落地的3个关键细节
光有源码不够,要让系统真正跑起来,还得注意这三点:
1. 边缘计算:别让“数据拥堵”拖慢响应
工业现场的网络环境复杂,如果所有数据都往云端传,不仅延迟高,还可能丢包。我们的源码在设备端加了边缘计算模块,先在本地处理“实时告警”(如某设备功率突增20%),只把“统计数据”上传云端,既保证了响应速度,又节省了带宽。
2. 安全机制:能耗数据也是“商业机密”
有次参观某化工企业,他们担心“能耗数据被竞争对手窃取”。我们的源码支持本地化部署,数据加密用国密SM4算法,还留了“权限分级”接口——普通员工只能看本车间数据,管理层才能看全厂汇总,老板才有“能耗成本分析”的最高权限。
3. 生态对接:别让系统成“信息孤岛”
能耗数据只有和业务系统打通才有价值。源码预留了API接口,可以对接ERP(同步产量数据算“单位产品能耗”)、MES(关联工艺参数优化能耗)、甚至钉钉/企业微信(推送能耗告警)。某机械厂把能耗数据和MES绑定后,发现“某型号零件的单位能耗比行业标准高18%”,通过调整加工参数,半年降低了12%的生产能耗。


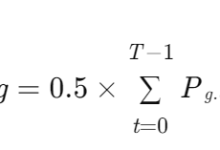





评论前必须登录!
注册