 网硕互联帮助中心
网硕互联帮助中心1. Spring Cloud 5 大组件有哪些?
早期 Spring Cloud 五大核心组件:
- 服务注册中心:Eureka
- 客户端负载均衡器:Ribbon
- 声明式的服务调用:Feign
- 服务熔断器:Hystrix
- API 网关:Zuul/Gateway
Spring Cloud Alibaba 技术组件(项目常用):
- 服务注册与配置中心:Nacos
- 负载均衡:LoadBalancer(新版本) Ribbon(旧版本)
- 服务调用:Feign(集成 LoadBalancer)
- 服务保护:Sentinel
- API 网关:Gateway
2. 服务注册和发现是什么意思?Spring Cloud 如何实现服务注册发现?
服务注册与发现包含服务注册、服务发现、服务状态监控三大核心功能,项目中采用 Eureka 实现:
- 服务注册:服务提供者将自身信息(服务名称、IP、端口等)注册到 Eureka
- 服务发现:服务消费者从 Eureka 获取服务列表,通过负载均衡算法选择实例调用
- 服务监控:服务提供者定期向 Eureka 发送心跳报告健康状态,超时未接收心跳则剔除该服务实例
3. Nacos 与 Eureka 的区别?
共同点:均支持服务注册与发现,通过心跳检测实现服务健康检查。
区别:
4. 项目中负载均衡如何实现的?
项目中使用 Spring Cloud Ribbon 实现客户端负载均衡,Feign 客户端底层已集成 Ribbon,使用方式简洁:发起远程调用时,Ribbon 先从注册中心获取服务地址列表,再根据预设路由策略(常用轮询)选择服务实例调用。
5. Ribbon 负载均衡策略有哪些?
Ribbon 核心负载均衡策略:
- RoundRobinRule:简单轮询策略
- WeightedResponseTimeRule:根据服务响应时间加权选择
- RandomRule:随机选择服务实例
- ZoneAvoidanceRule:区域感知策略,优先选择同区域可用服务器
6. 如何自定义 Ribbon 负载均衡策略?
提供两种自定义方式,适用不同范围:
7. 什么是服务雪崩,怎么解决这个问题?
服务雪崩:单个服务失败,导致整个调用链路的服务相继故障的连锁反应。
解决方式:通过服务降级和服务熔断保障系统稳定性:
- 服务降级:请求量突增时,主动降低非核心服务级别,确保核心服务可用
- 服务熔断:服务调用失败率达到阈值时,触发熔断机制,防止请求持续过载导致系统崩溃
-
状态机包括三个状态:
closed:关闭状态,断路器放行所有请求,并开始统计异常比例、慢请求比例。超过阈值则切换到open状态
open:打开状态,服务调用被熔断,访问被熔断服务的请求会被拒绝,快速失败,直接走降级逻辑。Open状态持续一段时间后会进入half-open状态
half-open:半开状态,放行一次请求,根据执行结果来判断接下来的操作。-
请求成功:则切换到closed状态
-
请求失败:则切换到open状态
-
8. 微服务是怎么监控的?
项目中采用 SkyWalking 实现微服务全维度监控:
9. 项目中如何做限流的?
针对突发流量,项目采用分版本限流方案,适配不同场景:
- 版本 1:基于 Nginx 限流,通过漏桶算法控制请求处理速率,按 IP 维度限流
- 版本 2:基于 Spring Cloud Gateway 限流,通过 RequestRateLimiter 过滤器实现,采用令牌桶算法,支持按 IP / 路径维度限流
- 版本3:通过Sentinel在可视化页面来手动设置限流
10. 限流常见的算法有哪些?
核心限流算法及特点:
- 漏桶算法:以固定速率处理请求,可平滑突发流量,抑制请求峰值
- 令牌桶算法:按固定速率生成令牌,请求需获取令牌后方可处理,适配请求量有波动的场景
- 两者核心区别:
1.流量控制逻辑:漏桶是请求先进入桶中,桶以固定速率匀速处理,满桶则丢弃,不管请求来的快慢,输出速率始终不变;令牌桶是桶以固定速率生成令牌,请求拿令牌才能处理,桶会累积令牌,有令牌就能一次性处理突发请求。
2.抗突发能力:漏桶几乎无抗突发能力,仅靠桶容量缓冲少量请求,突发请求多了直接限流;令牌桶抗突发能力强,突发请求可直接消耗桶中累积的令牌,突发后再恢复平均速率。
3.适用场景:漏桶适合需要绝对平滑流量的场景,比如网关层保护下游弱依赖(数据库 / 第三方接口)、Nginx 全局流量整形;令牌桶适合业务接口限流,比如下单、查询接口,兼顾平均 QPS 控制和业务偶尔的请求突发,也是后端开发中最常用的限流算法。
11. 什么是 CAP 理论?
CAP 理论是分布式系统设计的基础理论,包含三大核心特性:
- 一致性(Consistency):分布式系统中所有节点的数据保持实时一致
- 可用性(Availability):系统提供的服务始终处于可用状态,请求能得到及时响应
- 分区容错性(Partition tolerance):网络分区发生时,系统仍能正常提供服务核心结论:网络分区发生时,系统只能在一致性和可用性之间二选一。
12. 为什么分布式系统中无法同时保证一致性和可用性?
分布式系统中必须保证分区容错性(网络分区是分布式场景的常态);若优先保证一致性,需让所有节点同步数据,此过程中部分节点可能无法响应请求,牺牲了可用性;若优先保证可用性,节点需立即响应请求,可能导致各节点数据不一致,牺牲了一致性,因此二者无法同时保证。
13. 什么是 BASE 理论?
BASE 理论是 CAP 理论中 AP 方案的延伸,是分布式系统面向高可用的设计准则,包含三大特性:
- 基本可用(Basically Available):系统发生故障时,仍能保证核心功能可用,非核心功能可降级
- 软状态(Soft State):系统允许数据存在临时的不一致状态,无需实时同步
- 最终一致性(Eventually Consistent):经过一定时间后,系统所有节点的数据会达到一致状态
14.Seata的XA、AT、TCC模式?
Seata 事务管理中有三个重要的角色:
- TC (Transaction Coordinator) – 事务协调者:维护全局和分支事务的状态,协调全局事务提交或回滚。
- TM (Transaction Manager) – 事务管理器:定义全局事务的范围、开始全局事务、提交或回滚全局事务。
- RM (Resource Manager) – 资源管理器:管理分支事务处理的资源,与 TC 交谈以注册分支事务和报告分支事务的状态,并驱动分支事务提交或回滚。
XA模式:(CP-强一致性)
RM 一阶段的工作:
① 注册分支事务到 TC
② 执行分支业务 sql 但不提交
③ 报告执行状态到 TC
TC 二阶段的工作:
TC 检测各分支事务执行状态
a. 如果都成功,通知所有 RM 提交事务
b. 如果有失败,通知所有 RM 回滚事务
RM 二阶段的工作:
接收 TC 指令,提交或回滚事务
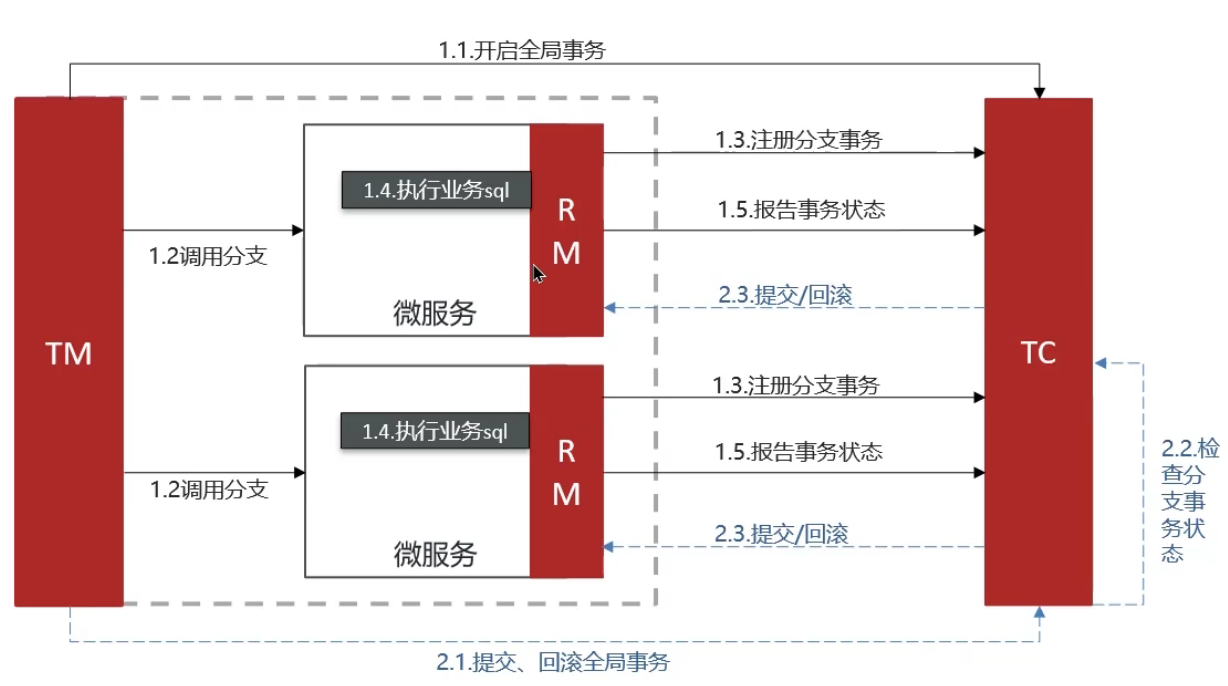
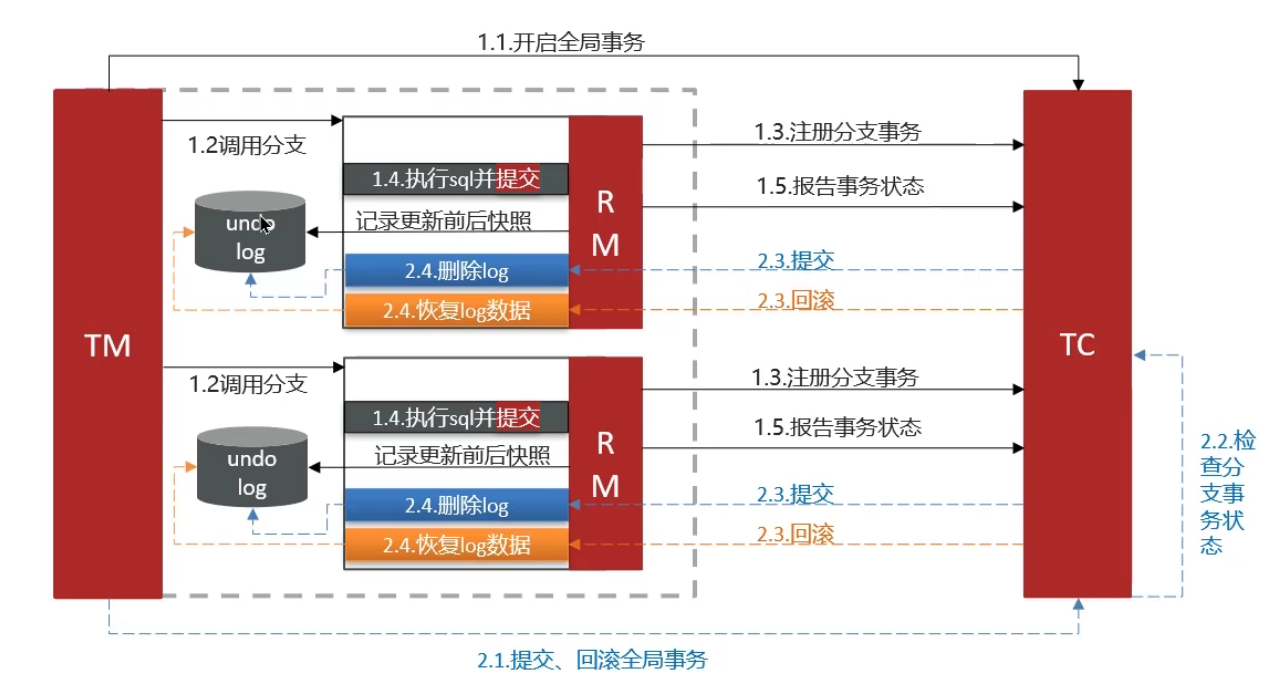
AT模式:(AP-高可用)–推荐
AT 模式同样是分阶段提交的事务模型,不过缺弥补了 XA 模型中资源锁定周期过长的缺陷。
阶段一 RM 的工作:
1、注册分支事务
2、记录 undo-log(数据快照)
3、执行业务 sql 并提交
4、报告事务状态
阶段二提交时 RM 的工作:
1、删除 undo-log 即可
阶段二回滚时 RM 的工作:
1、根据 undo-log 恢复数据到更新前
TCC模式(AP)
1、Try:资源的检测和预留;
2、Confirm:完成资源操作业务;要求 Try 成功 Confirm 一定要能成功。
3、Cancel:预留资源释放,可以理解为 try 的反向操作。

14. 项目采用哪种分布式事务解决方案?
项目中使用Seata 的 AT 模式解决分布式事务问题,核心原理:通过记录业务数据的变更日志,基于本地事务 + 全局协调,保证分布式事务的最终一致性。
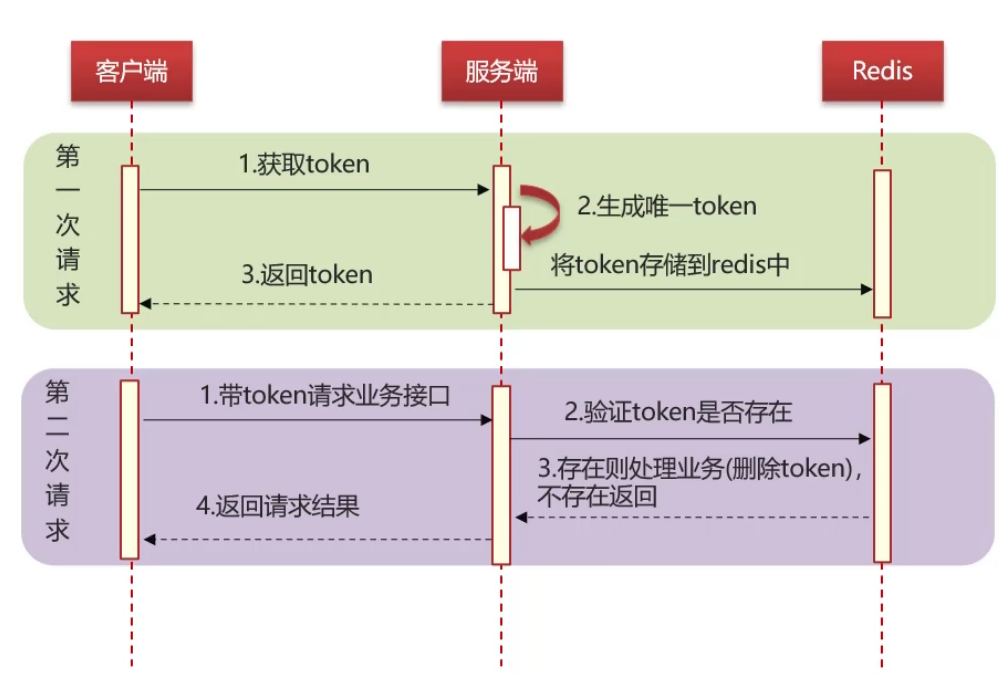
15. 分布式服务的接口幂等性如何设计?
项目中通过Token+Redis实现接口幂等性,核心流程:
16. xxl-job 路由策略有哪些?
xxl-job 核心路由策略:轮询、故障转移、分片广播等。
17. xxl-job 任务执行失败怎么解决?
针对 xxl-job 任务执行失败,采用多重兜底方案:
18. 大数据量的任务同时执行该怎么解决?
通过分布式分片分散任务负载,核心方案:





评论前必须登录!
注册