 网硕互联帮助中心
网硕互联帮助中心作者:昇腾实战派 知识地图:强化学习知识地图
背景与意义
本篇文章主要基于VeRL框架上提出的GSPO算法在昇腾NPU上进行实践部署,并为大家简单介绍GRPO算法思想以及其和GSPO算法特性差异。
算法原理
论文地址 GRPO:https://arxiv.org/abs/2402.03300 GSPO:https://arxiv.org/abs/2507.18071
GRPO:群组相对策略优化
群组相对策略优化(GRPO)的核心创新在于消除了对计算密集型价值模型的依赖,该算法采用了一种创新的群组生成和相对评估机制:对于给定的输入提示,系统生成G个不同的响应构成一个群组,随后奖励模型对群组内所有响应进行评分。通过计算群组内分数的均值和标准差,算法为每个响应计算相对优势值
A
^
i
\\hat{A}_i
A^i。优于群组平均水平的响应获得正向优势,反之则获得负向优势。这种设计显著降低了强化学习训练的内存占用和计算复杂度,使大规模模型的训练变得更加高效和可行,但其底层实现存在一个关键的设计缺陷,该缺陷在大规模模型训练中会导致严重的稳定性问题。
问题的根源在于奖励分配与优化更新之间的粒度不匹配:奖励值
A
^
i
\\hat{A}_i
A^i是基于完整序列计算得出,而GRPO的优化更新却在token级别执行。为了将序列级奖励应用于每个token,GRPO引入了token级别的重要性权重
w
i
,
t
(
θ
)
w_{i,t}(\\theta)
wi,t(θ),权重
w
i
,
t
(
θ
)
w_{i,t}(\\theta)
wi,t(θ)表示当前模型生成 token 的概率 ÷ 旧模型生成相同 token 的概率比值,如下图中的
w
i
,
t
(
θ
)
w_{i,t}(\\theta)
wi,t(θ) 
序列内各token的重要性权重可能出现显著差异,导致学习信号的噪声化和不一致性。随着训练序列长度的增加,这种噪声效应累积并可能触发整个训练过程的失稳,最终导致模型崩溃。该问题在稀疏专家混合(Mixture-of-Experts, MoE)模型中尤为严重,在MoE架构的模型训练过程中,由于模型更新后每次激活的专家可能会发生变化,off-policy偏差会变得更严重。因此,GRPO的这种重要性采样的方式有可能会导致更大的偏差,致使训练崩溃。
GSPO:群组序列策略优化
上述问题可以发现,其根源在于优化粒度和奖励粒度不在同一单位。所以GSPO算法提出序列级别的重要性采样,并引入
y
i
y_i
yi保证在数值上保持稳定,无论序列长度为10个token还是1000个token。该算法使用稳定的序列级重要性比率
s
i
(
θ
)
s_i(\\theta)
si(θ)替代了噪声较大的token级别权重,给定序列内的所有token接收完全一致的更新,该更新由
s
i
(
θ
)
A
^
i
s_i(\\theta)\\hat{A}_i
si(θ)A^i确定。token级别的不一致反馈被消除,取而代之的是基于完整序列奖励的统一更新机制。 
针对多轮场景,GSPO提供token-level的变体,以进行更精细的应用  论文中实验数据及算法表明,对于GRPO算法来说,在MoE模型上进行训练,由于模型更新后每次激活的专家可能会发生变化,off-policy偏差会变得更严重,而这种混合专家激活导致的波动会严重影响模型收敛。在固定采样和训练激活相同的专家后(Routing Replay),训练reward可以正常上涨,但会引入额外的内存和通信开销,限制MOE的实际容量。而GSPO用sequence-level的clip进行优化,对精度差异的容忍度要更高,从根本上解决了MoE模型中的专家激活波动问题,简化和稳定了训练过程,训练效果也更好
论文中实验数据及算法表明,对于GRPO算法来说,在MoE模型上进行训练,由于模型更新后每次激活的专家可能会发生变化,off-policy偏差会变得更严重,而这种混合专家激活导致的波动会严重影响模型收敛。在固定采样和训练激活相同的专家后(Routing Replay),训练reward可以正常上涨,但会引入额外的内存和通信开销,限制MOE的实际容量。而GSPO用sequence-level的clip进行优化,对精度差异的容忍度要更高,从根本上解决了MoE模型中的专家激活波动问题,简化和稳定了训练过程,训练效果也更好
特性适配工作分析
整体算法流程
Verl的GRPO整体算法流程如下图所示,GSPO与其类似,差异点在于重要性采样计算和loss计算模块
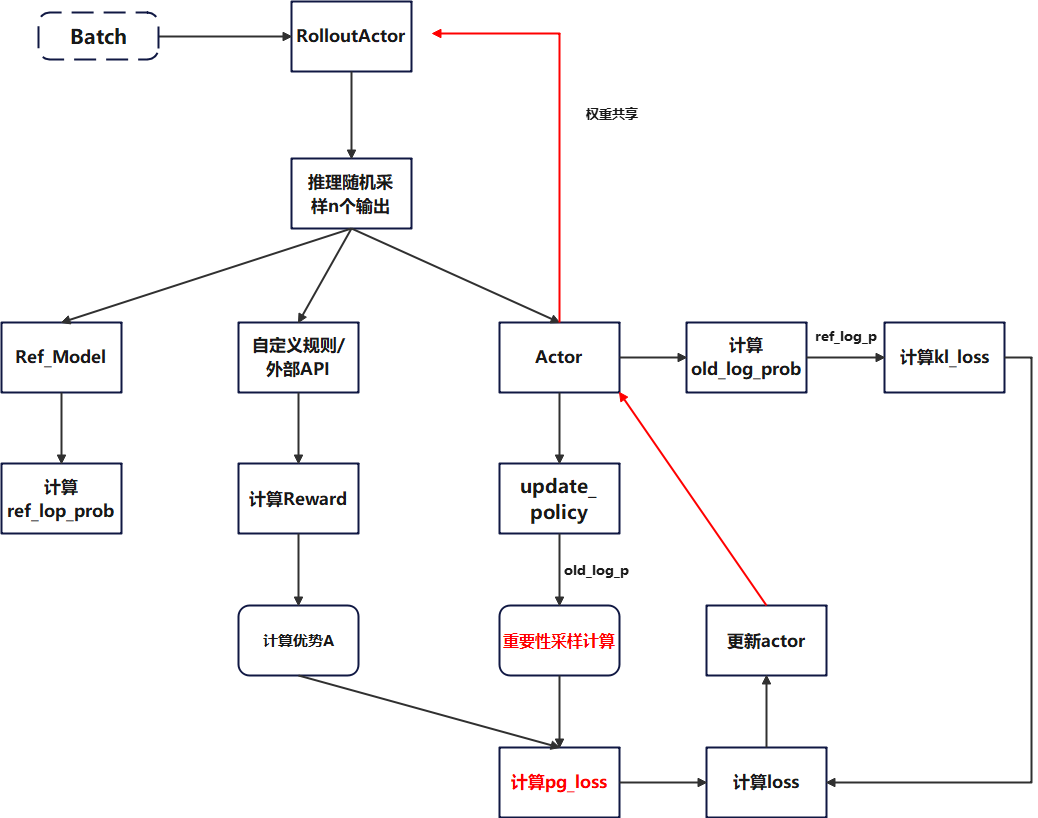
模块分析
算法pr: https://github.com/volcengine/verl/pull/2775
基于verl代码分析,可以发现其重要性采样计算相关代码位置位于:verl/trainer/ppo/core_algos.py
@register_policy_loss("gspo")
def compute_policy_loss_gspo(
old_log_prob: torch.Tensor,
log_prob: torch.Tensor,
advantages: torch.Tensor,
response_mask: torch.Tensor,
loss_agg_mode: str = "seq-mean-token-mean",
config: Optional[ActorConfig] = None,
rollout_is_weights: torch.Tensor | None = None,
) –> tuple[torch.Tensor, dict[str, Any]]:
"""
Compute the clipped policy objective and related metrics for GSPO.
See https://arxiv.org/pdf/2507.18071 for more details.
Args:
old_log_prob (torch.Tensor):
Log-probabilities of actions under the old policy, shape (batch_size, response_length).
log_prob (torch.Tensor):
Log-probabilities of actions under the current policy, shape (batch_size, response_length).
advantages (torch.Tensor):
Advantage estimates for each action, shape (batch_size, response_length).
response_mask (torch.Tensor):
Mask indicating which tokens to include in the loss, shape (batch_size, response_length).
loss_agg_mode (str, optional):
Aggregation mode for `agg_loss`. For GSPO, it is recommended to use "seq-mean-token-mean".
"""
assert config is not None
assert isinstance(config, ActorConfig)
clip_ratio_low = config.clip_ratio_low if config.clip_ratio_low is not None else config.clip_ratio
clip_ratio_high = config.clip_ratio_high if config.clip_ratio_high is not None else config.clip_ratio
negative_approx_kl = log_prob – old_log_prob
# compute sequence-level importance ratio:
# si(θ) = (π_θ(yi|x)/π_θold(yi|x))^(1/|yi|) =
# exp [(1/|y_i|) * Σ_t log(π_θ(y_i,t|x,y_i,<t)/π_θold(y_i,t|x,y_i,<t))]
seq_lengths = torch.sum(response_mask, dim=–1).clamp(min=1)
negative_approx_kl_seq = torch.sum(negative_approx_kl * response_mask, dim=–1) / seq_lengths
# Combined ratio at token level:
# s_i,t(θ) = sg[s_i(θ)] · π_θ(y_i,t|x, y_i,<t) / sg[π_θ(y_i,t|x, y_i,<t)]
# In log space: log(s_i,t(θ)) = sg[log(s_i(θ))] + log_prob – sg[log_prob]
log_seq_importance_ratio = log_prob – log_prob.detach() + negative_approx_kl_seq.detach().unsqueeze(–1)
log_seq_importance_ratio = torch.clamp(log_seq_importance_ratio, max=10.0) # clamp for numerical stability
# finaly exp() to remove log
seq_importance_ratio = torch.exp(log_seq_importance_ratio)
pg_losses1 = –advantages * seq_importance_ratio
pg_losses2 = –advantages * torch.clamp(seq_importance_ratio, 1 – clip_ratio_low, 1 + clip_ratio_high)
pg_losses = torch.maximum(pg_losses1, pg_losses2)
# Apply rollout correction weights if provided
if rollout_is_weights is not None:
pg_losses = pg_losses * rollout_is_weights
# for GSPO, we need to aggregate the loss at the sequence level (seq-mean-token-mean)
pg_loss = agg_loss(
loss_mat=pg_losses, loss_mask=response_mask, loss_agg_mode="seq-mean-token-mean", **config.global_batch_info
)
# For compatibility, return zero for pg_clipfrac_lower (not used in standard GSPO)
pg_clipfrac = verl_F.masked_mean(torch.gt(pg_losses2, pg_losses1).float(), response_mask)
pg_clipfrac_lower = torch.tensor(0.0, device=pg_loss.device)
ppo_kl = verl_F.masked_mean(–negative_approx_kl, response_mask)
pg_metrics = {
"actor/pg_clipfrac": pg_clipfrac.detach().item(),
"actor/ppo_kl": ppo_kl.detach().item(),
"actor/pg_clipfrac_lower": pg_clipfrac_lower.detach().item(),
}
return pg_loss, pg_metrics
GRPO基于token级别计算重要性ratio,GSPO基于sequence级别计算重要性ratio,相关代码差异如下图所示
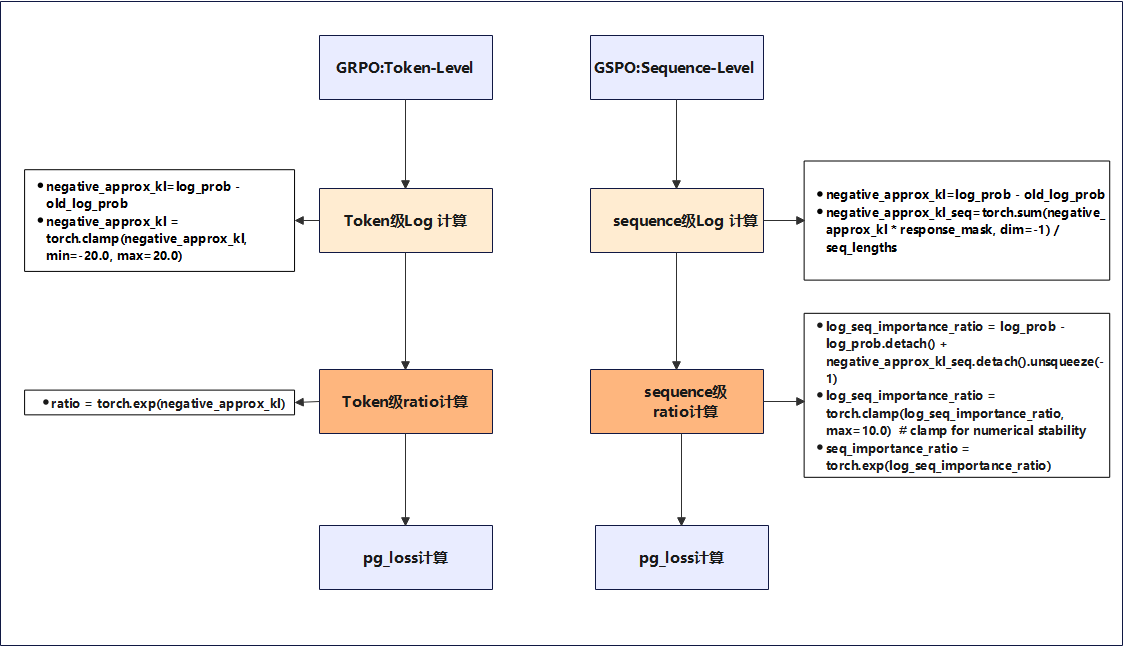
组件分析
背景:GRPO已在NPU支持
观测现有GRPO和GSPO的代码差异分析,仅涉及常规torch编码,不涉及其余组件,不涉及NPU适配工作
调试用例
调试目标
配置GSPO相关参数,拉起训练,reward曲线正常上升
基于GRPO脚本,参数使能
loss_mode=gspo
loss_agg_mode="seq-mean-token-mean"
actor_rollout_ref.actor.policy_loss.loss_mode=${loss_mode} \\
actor_rollout_ref.actor.loss_agg_mode=${loss_agg_mode} \\
调试用例1:Qwen25-3B
稠密模型调试FSDP后端,以官方脚本为准,观测reward曲线是否上升
调试用例2:Qwen3-30B-A3B
MOE模型调试Megatron后端,观测GRPO和GSPO两种算法的reward曲线
调试实践
调试环境
| AI服务器 | Atlas 800T A2 64G |
| 驱动、固件 | 24.1.0.3 |
| Python | 3.10.12 |
| CANN | 8.2.RC2 |
| torch | 2.7.1 |
| torch_npu | 2.7.1 |
| transformer | 4.53.3 |
| vllm | 0.10.0 |
| vllm-ascend | 0.10.0rc1 |
| verl | 0.7.0.dev0 |
| Megatron-core | 0.12.1 |
| MindSpeed | 2.2.0_core_r0.12.1 |
| Mbridge | 0.13.1 |
调试用例1:Qwen25-3B
调试脚本
set -x
pkill -9 python
ps -ef | grep "python" |grep -v grep |awk '{print $2}' |xargs -t -i kill -9 {}
ray stop –force
pkill -9 python
pkill -9 torchrun
ps -ef | grep "defaunct" |grep python |awk '{print $3}' |xargs -t -i kill -9 {}
ps -ef | grep "defaunct" |grep torchrun |awk '{print $3}' |xargs -t -i kill -9 {}
ps -ef | grep -i python |grep -i [name] |grep -v grep |awk '{print $2}' |xargs -t -I {} kill -9 {}
ps -ef | grep -i torchrun |grep -i [name] |grep -v grep |awk '{print $2}' |xargs -t -I {} kill -9 {}
ps -ef | grep "python" |grep -v grep |awk '{print $2}' |xargs -t -i kill -9 {}
# Set how many GPUs we actually have on this node.
export GPUS_PER_NODE=8
export NNODES=1
echo "Using $NNODES nodes for training…"
# ————————————- Setup xp params —————————————
project_name='RL-GSPO'
adv_estimator=grpo
loss_mode=gspo
loss_agg_mode="seq-mean-token-mean"
MODEL_PATH=XX/Qwen25-3B-Instruct
offload=false # it's a small model, offloading will just slow-down training
rollout_engine=vllm
rollout_mode=sync # can be async to speedup large scale xps
gpu_memory_utilization=0.6
reward_manager=dapo
adv_estimator=grpo
shuffle_dataset=true
first_time_dataset_prep=true # prepare dataset
test_freq=10
save_freq=10
total_epochs=10
total_training_steps=500
val_before_train=false
use_kl_in_reward=false
kl_coef=0.0
use_kl_loss=false
kl_loss_coef=0.0
clip_ratio_low=0.0003 # as recommended by the paper, see Sec. 5.1
clip_ratio_high=0.0004 # as recommended by the paper, see Sec. 5.1
train_batch_size=512
ppo_mini_batch_size=128 # maintain 4 mini-batches as recommended by the paper, see Sec. 5.1
ppo_micro_batch_size_per_gpu=8 # setup depending on your GPU memory
n_resp_per_prompt=16
max_prompt_length=$((1024 * 2))
max_response_length=$((1024 * 8))
# dapo reward manager params
enable_overlong_buffer=false # true
overlong_buffer_len=$((1024 * 4))
overlong_penalty_factor=1.0
# Paths and namings
SFT_MODEL=$(basename $MODEL_PATH)
exp_name="${loss_mode}-epslow-${clip_ratio_low}-epshigh-${clip_ratio_high}–${SFT_MODEL}-RL"
CKPTS_DIR=/rl/checkpoints/experimental/4b/${loss_mode}/${exp_name}
# Sampling params at rollouts
temperature=1.0
top_p=1.0
top_k=-1 # 0 for HF rollout, -1 for vLLM rollout
val_top_p=0.7
# Performance Related Parameter
sp_size=4
use_dynamic_bsz=true
actor_ppo_max_token_len=$(((max_prompt_length + max_response_length) * 1))
infer_ppo_max_token_len=$(((max_prompt_length + max_response_length) * 1))
offload=true
gen_tp=2
entropy_checkpointing=true # This enables entropy recomputation specifically for the entropy calculation, lowering memory usage during training.
gsm8k_train_path=xx/gsm8k/post_data/gsm8k/train.parquet
gsm8k_test_path=xx/gsm8k/post_data/gsm8k/test.parquet
# set the paths
train_files="['$gsm8k_train_path']"
test_files="['$gsm8k_test_path']"
#! 修改filter_overlong_prompts false
python3 -m verl.trainer.main_ppo \\
algorithm.adv_estimator=${adv_estimator} \\
actor_rollout_ref.actor.policy_loss.loss_mode=${loss_mode} \\
data.train_files="${train_files}" \\
data.val_files="${test_files}" \\
data.shuffle=$shuffle_dataset \\
data.prompt_key=prompt \\
data.truncation='error' \\
data.filter_overlong_prompts=true \\
data.train_batch_size=${train_batch_size} \\
data.max_prompt_length=${max_prompt_length} \\
data.max_response_length=${max_response_length} \\
actor_rollout_ref.rollout.n=${n_resp_per_prompt} \\
algorithm.use_kl_in_reward=${use_kl_in_reward} \\
algorithm.kl_ctrl.kl_coef=${kl_coef} \\
actor_rollout_ref.actor.use_kl_loss=${use_kl_loss} \\
actor_rollout_ref.actor.kl_loss_coef=${kl_loss_coef} \\
actor_rollout_ref.actor.clip_ratio_low=${clip_ratio_low} \\
actor_rollout_ref.actor.clip_ratio_high=${clip_ratio_high} \\
actor_rollout_ref.model.use_remove_padding=true \\
actor_rollout_ref.actor.use_dynamic_bsz=${use_dynamic_bsz} \\
actor_rollout_ref.ref.log_prob_use_dynamic_bsz=${use_dynamic_bsz} \\
actor_rollout_ref.rollout.log_prob_use_dynamic_bsz=${use_dynamic_bsz} \\
actor_rollout_ref.actor.ppo_max_token_len_per_gpu=${actor_ppo_max_token_len} \\
actor_rollout_ref.ref.log_prob_max_token_len_per_gpu=${infer_ppo_max_token_len} \\
actor_rollout_ref.rollout.log_prob_max_token_len_per_gpu=${infer_ppo_max_token_len} \\
actor_rollout_ref.rollout.name=vllm \\
actor_rollout_ref.rollout.name=${rollout_engine} \\
actor_rollout_ref.rollout.mode=${rollout_mode} \\
actor_rollout_ref.model.path="${MODEL_PATH}" \\
actor_rollout_ref.model.enable_gradient_checkpointing=true \\
actor_rollout_ref.actor.optim.lr=1e-6 \\
actor_rollout_ref.actor.optim.lr_warmup_steps_ratio=0.05 \\
actor_rollout_ref.actor.optim.weight_decay=0.1 \\
actor_rollout_ref.actor.ppo_mini_batch_size=${ppo_mini_batch_size} \\
actor_rollout_ref.actor.ppo_micro_batch_size_per_gpu=${ppo_micro_batch_size_per_gpu} \\
actor_rollout_ref.actor.fsdp_config.param_offload=${offload} \\
actor_rollout_ref.actor.fsdp_config.optimizer_offload=${offload} \\
actor_rollout_ref.actor.entropy_coeff=0 \\
actor_rollout_ref.actor.grad_clip=1.0 \\
actor_rollout_ref.actor.loss_agg_mode=${loss_agg_mode} \\
actor_rollout_ref.actor.ulysses_sequence_parallel_size=${sp_size} \\
actor_rollout_ref.rollout.gpu_memory_utilization=${gpu_memory_utilization} \\
actor_rollout_ref.rollout.tensor_model_parallel_size=${gen_tp} \\
actor_rollout_ref.rollout.enable_chunked_prefill=true \\
actor_rollout_ref.rollout.max_num_batched_tokens=$((max_prompt_length + max_response_length)) \\
actor_rollout_ref.rollout.temperature=${temperature} \\
actor_rollout_ref.rollout.top_p=${top_p} \\
actor_rollout_ref.rollout.top_k=${top_k} \\
actor_rollout_ref.rollout.val_kwargs.temperature=${temperature} \\
actor_rollout_ref.rollout.val_kwargs.top_p=${val_top_p} \\
actor_rollout_ref.rollout.val_kwargs.top_k=${top_k} \\
actor_rollout_ref.rollout.val_kwargs.do_sample=true \\
actor_rollout_ref.rollout.val_kwargs.n=1 \\
actor_rollout_ref.ref.fsdp_config.param_offload=${offload} \\
actor_rollout_ref.ref.ulysses_sequence_parallel_size=${sp_size} \\
actor_rollout_ref.actor.entropy_checkpointing=${entropy_checkpointing} \\
reward_model.reward_manager=${reward_manager} \\
+reward_model.reward_kwargs.overlong_buffer_cfg.enable=${enable_overlong_buffer} \\
+reward_model.reward_kwargs.overlong_buffer_cfg.len=${overlong_buffer_len} \\
+reward_model.reward_kwargs.overlong_buffer_cfg.penalty_factor=${overlong_penalty_factor} \\
+reward_model.reward_kwargs.overlong_buffer_cfg.log=false \\
+reward_model.reward_kwargs.max_resp_len=${max_response_length} \\
trainer.logger='["console"]' \\
actor_rollout_ref.rollout.enforce_eager=True \\
actor_rollout_ref.actor.use_torch_compile=False \\
trainer.project_name="${project_name}" \\
trainer.experiment_name="${exp_name}" \\
trainer.n_gpus_per_node=16 \\
trainer.nnodes=1 \\
trainer.val_before_train=${val_before_train} \\
trainer.test_freq=${test_freq} \\
trainer.save_freq=${save_freq} \\
trainer.total_epochs=${total_epochs} \\
trainer.total_training_steps=${total_training_steps} \\
trainer.default_local_dir="${CKPTS_DIR}" \\
trainer.resume_mode=auto \\
trainer.device=npu \\
trainer.log_val_generations=2 \\
$@
官方调试数据
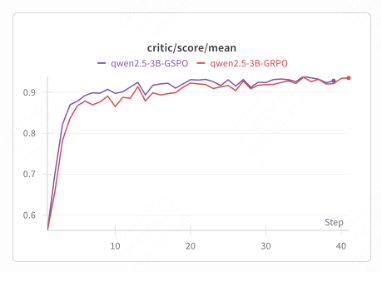
调试结果
结论:曲线正常上升,上升趋势一致,符合预期结果
调试用例2:Qwen3-30B-A3B
调试脚本
project_name='DAPO'
exp_name='GSPO-Qwen3-30B-A3B-4nodes'
adv_estimator=grpo
use_kl_in_reward=False
kl_coef=0.0
use_kl_loss=False
kl_loss_coef=0.0
clip_ratio_low=3e-4
clip_ratio_high=4e-4
max_prompt_length=$((1024 * 2))
max_response_length=$((1024 * 8))
enable_overlong_buffer=True
overlong_buffer_len=$((1024 * 4))
overlong_penalty_factor=1.0
loss_agg_mode="token-mean"
loss_mode=gspo
train_prompt_bsz=32
n_resp_per_prompt=2
train_prompt_mini_bsz=4
NNODES=${NNODES:–2}
NGPUS_PER_NODE=${NGPUS_PER_NODE:–8}
MODEL_PATH=xx/weight/Qwen3_30B/Qwen3_30B
CKPTS_DIR=$DATA_ROOT/checkpoint/${project_name}/${exp_name}
TRAIN_FILE=xx/rl_data/dapo–math/dapo–math–17k.parquet
# aime24_test_path=/data01/huawei-2025/rl_data/aime-2024/aime-2024.parquet
aime24_test_path=xx/rl_data/dapo–math/dapo–math–17k.parquet
TEST_FILE="['$aime24_test_path']"
# Algorithm
temperature=1.0
top_p=1.0
top_k=–1 # 0 for HF rollout, -1 for vLLM rollout
val_top_p=0.7
# Performance Related Parameter
use_dynamic_bsz=True
actor_ppo_max_token_len=$(((max_prompt_length + max_response_length) * 1))
infer_ppo_max_token_len=$(((max_prompt_length + max_response_length) * 1))
offload=True
# gen
rollout_name=vllm # vllm or sglang
gen_tp=4
gen_dp=8
# gen_ep=4
# train
train_tp=4
train_pp=4
EP=8
ETP=1
RUNTIME_ENV=verl/trainer/mc2_env.yaml
cd /opt/verl
ray job submit ––runtime–env="${RUNTIME_ENV}" \\
–– python3 –m verl.trainer.main_ppo \\
––config–path=config \\
––config–name='ppo_megatron_trainer.yaml' \\
data.train_files="${TRAIN_FILE}" \\
data.val_files="${TEST_FILE}" \\
data.prompt_key=prompt \\
data.return_raw_chat=True \\
data.truncation='left' \\
data.max_prompt_length=${max_prompt_length} \\
data.max_response_length=${max_response_length} \\
data.train_batch_size=${train_prompt_bsz} \\
actor_rollout_ref.rollout.n=${n_resp_per_prompt} \\
actor_rollout_ref.actor.policy_loss.loss_mode=${loss_mode} \\
algorithm.adv_estimator=${adv_estimator} \\
algorithm.use_kl_in_reward=${use_kl_in_reward} \\
algorithm.kl_ctrl.kl_coef=${kl_coef} \\
actor_rollout_ref.actor.use_kl_loss=${use_kl_loss} \\
actor_rollout_ref.actor.kl_loss_coef=${kl_loss_coef} \\
actor_rollout_ref.actor.clip_ratio_low=${clip_ratio_low} \\
actor_rollout_ref.actor.clip_ratio_high=${clip_ratio_high} \\
actor_rollout_ref.actor.clip_ratio_c=10.0 \\
actor_rollout_ref.actor.use_dynamic_bsz=${use_dynamic_bsz} \\
actor_rollout_ref.ref.log_prob_use_dynamic_bsz=${use_dynamic_bsz} \\
actor_rollout_ref.rollout.log_prob_use_dynamic_bsz=${use_dynamic_bsz} \\
actor_rollout_ref.actor.ppo_max_token_len_per_gpu=${actor_ppo_max_token_len} \\
actor_rollout_ref.ref.log_prob_max_token_len_per_gpu=${infer_ppo_max_token_len} \\
actor_rollout_ref.rollout.log_prob_max_token_len_per_gpu=${infer_ppo_max_token_len} \\
actor_rollout_ref.model.path="${MODEL_PATH}" \\
actor_rollout_ref.actor.optim.lr=1e-6 \\
actor_rollout_ref.actor.optim.lr_warmup_steps=10 \\
actor_rollout_ref.actor.optim.weight_decay=0.1 \\
actor_rollout_ref.actor.ppo_mini_batch_size=${train_prompt_mini_bsz} \\
actor_rollout_ref.actor.entropy_coeff=0 \\
actor_rollout_ref.actor.optim.clip_grad=1.0 \\
actor_rollout_ref.actor.loss_agg_mode=${loss_agg_mode} \\
actor_rollout_ref.actor.megatron.param_offload=${offload} \\
actor_rollout_ref.actor.megatron.optimizer_offload=${offload} \\
actor_rollout_ref.actor.megatron.grad_offload=${offload} \\
actor_rollout_ref.actor.megatron.pipeline_model_parallel_size=${train_pp} \\
actor_rollout_ref.actor.megatron.tensor_model_parallel_size=${train_tp} \\
actor_rollout_ref.actor.megatron.expert_model_parallel_size=$EP \\
actor_rollout_ref.actor.megatron.expert_tensor_parallel_size=$ETP \\
actor_rollout_ref.rollout.gpu_memory_utilization=0.80 \\
actor_rollout_ref.rollout.enable_chunked_prefill=True \\
actor_rollout_ref.rollout.max_num_batched_tokens=$((max_prompt_length + max_response_length)) \\
actor_rollout_ref.rollout.temperature=${temperature} \\
actor_rollout_ref.rollout.top_p=${top_p} \\
actor_rollout_ref.rollout.top_k=${top_k} \\
actor_rollout_ref.rollout.val_kwargs.temperature=${temperature} \\
actor_rollout_ref.rollout.val_kwargs.top_p=${val_top_p} \\
actor_rollout_ref.rollout.val_kwargs.top_k=${top_k} \\
actor_rollout_ref.rollout.val_kwargs.do_sample=True \\
actor_rollout_ref.rollout.val_kwargs.n=1 \\
actor_rollout_ref.rollout.name=${rollout_name} \\
actor_rollout_ref.rollout.mode=sync \\
actor_rollout_ref.rollout.calculate_log_probs=True \\
actor_rollout_ref.rollout.tensor_model_parallel_size=${gen_tp} \\
actor_rollout_ref.rollout.data_parallel_size=${gen_dp} \\
actor_rollout_ref.ref.megatron.pipeline_model_parallel_size=${train_pp} \\
actor_rollout_ref.ref.megatron.tensor_model_parallel_size=${train_tp} \\
actor_rollout_ref.ref.megatron.expert_model_parallel_size=$EP \\
actor_rollout_ref.ref.megatron.expert_tensor_parallel_size=$ETP \\
actor_rollout_ref.ref.megatron.param_offload=${offload} \\
actor_rollout_ref.actor.megatron.use_mbridge=True \\
+actor_rollout_ref.actor.megatron.override_transformer_config.moe_router_dtype=fp32 \\
+actor_rollout_ref.actor.megatron.override_transformer_config.recompute_method=uniform \\
+actor_rollout_ref.actor.megatron.override_transformer_config.recompute_granularity=full \\
+actor_rollout_ref.actor.megatron.override_transformer_config.recompute_num_layers=1 \\
reward_model.reward_manager=dapo \\
+reward_model.reward_kwargs.overlong_buffer_cfg.enable=${enable_overlong_buffer} \\
+reward_model.reward_kwargs.overlong_buffer_cfg.len=${overlong_buffer_len} \\
+reward_model.reward_kwargs.overlong_buffer_cfg.penalty_factor=${overlong_penalty_factor} \\
+reward_model.reward_kwargs.overlong_buffer_cfg.log=False \\
+reward_model.reward_kwargs.max_resp_len=${max_response_length} \\
trainer.logger="console" \\
trainer.project_name="${project_name}" \\
trainer.experiment_name="${exp_name}-tp${gen_tp}-ep${gen_ep}" \\
trainer.n_gpus_per_node="${NGPUS_PER_NODE}" \\
trainer.nnodes="${NNODES}" \\
trainer.val_before_train=False \\
trainer.test_freq=–1 \\
trainer.save_freq=–1 \\
trainer.total_epochs=10 \\
trainer.total_training_steps=300 \\
trainer.default_local_dir="${CKPTS_DIR}" \\
trainer.resume_mode=auto \\
trainer.log_val_generations=10 \\
+actor_rollout_ref.actor.megatron.override_transformer_config.use_flash_attn=True \\
trainer.device="npu" $@
GRPO vs GSPO 调试结果
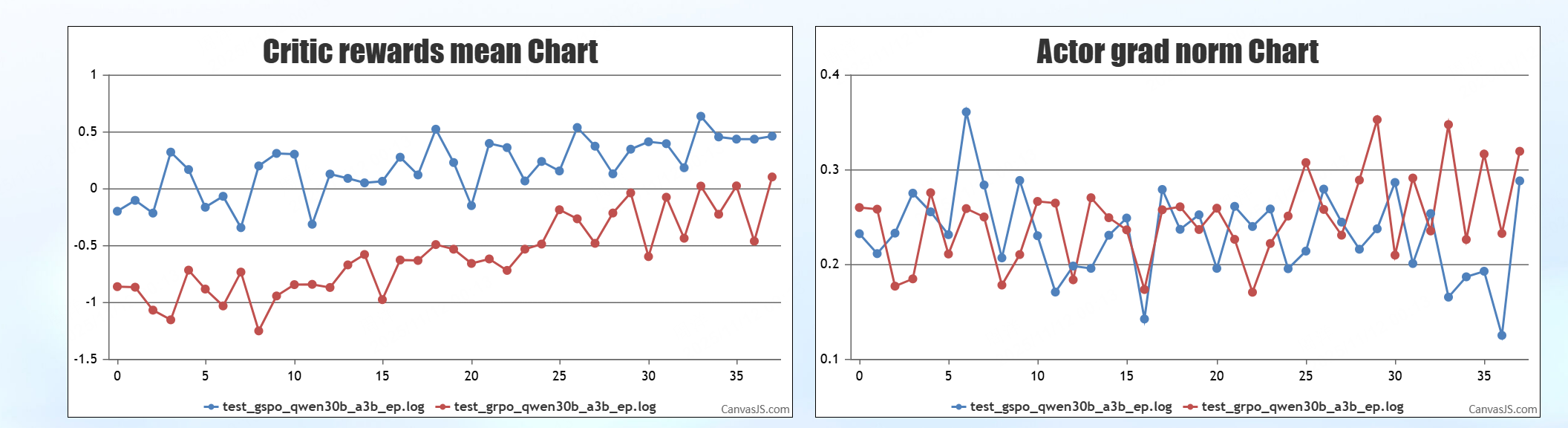
结论:GSPO在MOE模型上展示出了更好的训练效果
最新版本调试
基于最新版本verl调试服务化vllm后端和engineworker功能
环境
| CANN | 8.3.RC1 | |
| torch | 2.7.1 | |
| torch_npu | 2.7.1 | |
| transformer | 4.57.3 | |
| vllm | v0.11.0 | |
| vllm-ascend | v0.11.0rc1 | |
| verl | commit:5a2e0b1c272b33 | 10月10日代码 |
调试用例3:服务化vllm后端GSPO功能调试
调试脚本
#!/usr/bin/env bash
set -x
pkill -9 python
ps -ef | grep "python" |grep -v grep |awk '{print $2}' |xargs -t -i kill -9 {}
ray stop –force
pkill -9 python
pkill -9 torchrun
ps -ef | grep "defaunct" |grep python |awk '{print $3}' |xargs -t -i kill -9 {}
ps -ef | grep "defaunct" |grep torchrun |awk '{print $3}' |xargs -t -i kill -9 {}
ps -ef | grep -i python |grep -i [name] |grep -v grep |awk '{print $2}' |xargs -t -I {} kill -9 {}
ps -ef | grep -i torchrun |grep -i [name] |grep -v grep |awk '{print $2}' |xargs -t -I {} kill -9 {}
ps -ef | grep "python" |grep -v grep |awk '{print $2}' |xargs -t -i kill -9 {}
# Set how many GPUs we actually have on this node.
export GPUS_PER_NODE=8
export NNODES=1
export VLLM_ASCEND_ENABLE_NZ=0
echo "Using $NNODES nodes for training…"
#export ASCEND_LAUNCH_BLOCKING=1
# ————————————- Setup xp params —————————————
project_name='RL-GSPO'
adv_estimator=grpo
loss_mode=gspo
loss_agg_mode="seq-mean-token-mean"
MODEL_PATH=xx/weights/Qwen2.5-3B-Instruct
offload=false # it's a small model, offloading will just slow-down training
rollout_engine=vllm
rollout_mode=async
return_raw_chat="True"
if [ "$rollout_engine" = "vllm" ]; then
export VLLM_USE_V1=1
fi
gpu_memory_utilization=0.6
reward_manager=dapo
adv_estimator=grpo
shuffle_dataset=true
first_time_dataset_prep=true # prepare dataset
test_freq=10
save_freq=10
total_epochs=10
total_training_steps=500
val_before_train=false
use_kl_in_reward=false
kl_coef=0.0
use_kl_loss=false
kl_loss_coef=0.0
clip_ratio_low=0.0003 # as recommended by the paper, see Sec. 5.1
clip_ratio_high=0.0004 # as recommended by the paper, see Sec. 5.1
train_batch_size=512
ppo_mini_batch_size=128 # maintain 4 mini-batches as recommended by the paper, see Sec. 5.1
ppo_micro_batch_size_per_gpu=8 # setup depending on your GPU memory
n_resp_per_prompt=16
max_prompt_length=$((1024 * 2))
max_response_length=$((1024 * 8))
# dapo reward manager params
enable_overlong_buffer=false # true
overlong_buffer_len=$((1024 * 4))
overlong_penalty_factor=1.0
# Paths and namings
SFT_MODEL=$(basename $MODEL_PATH)
exp_name="${loss_mode}-epslow-${clip_ratio_low}-epshigh-${clip_ratio_high}–${SFT_MODEL}-RL"
CKPTS_DIR=/rl/checkpoints/experimental/4b/${loss_mode}/${exp_name}
# Sampling params at rollouts
temperature=1.0
top_p=1.0
top_k=-1 # 0 for HF rollout, -1 for vLLM rollout
val_top_p=0.7
# Performance Related Parameter
sp_size=4
use_dynamic_bsz=true
actor_ppo_max_token_len=$(((max_prompt_length + max_response_length) * 1))
infer_ppo_max_token_len=$(((max_prompt_length + max_response_length) * 1))
offload=true
gen_tp=2
entropy_checkpointing=true # This enables entropy recomputation specifically for the entropy calculation, lowering memory usage during training.
# ————————————- train/val data preparation —————————————
# if [ "$first_time_dataset_prep" = true ]; then
# echo "Preprocessing GSM8K dataset…"
# python examples/data_preprocess/gsm8k.py –local_save_dir /data01/huawei-2025/rl_data/gsm8k/data_later –local_dataset_path /data01/huawei-2025/rl_data/gsm8k/
# fi
gsm8k_train_path=xx/data/post_gsm8k/train.parquet
gsm8k_test_path=xx/data/post_gsm8k/test.parquet
# set the paths
train_files="['$gsm8k_train_path']"
test_files="['$gsm8k_test_path']"
#! 修改filter_overlong_prompts false
python3 -m verl.trainer.main_ppo \\
algorithm.adv_estimator=${adv_estimator} \\
actor_rollout_ref.actor.policy_loss.loss_mode=${loss_mode} \\
data.train_files="${train_files}" \\
data.val_files="${test_files}" \\
data.shuffle=$shuffle_dataset \\
data.prompt_key=prompt \\
data.truncation='error' \\
data.filter_overlong_prompts=true \\
data.return_raw_chat=${return_raw_chat} \\
data.train_batch_size=${train_batch_size} \\
data.max_prompt_length=${max_prompt_length} \\
data.max_response_length=${max_response_length} \\
actor_rollout_ref.rollout.n=${n_resp_per_prompt} \\
algorithm.use_kl_in_reward=${use_kl_in_reward} \\
algorithm.kl_ctrl.kl_coef=${kl_coef} \\
actor_rollout_ref.actor.use_kl_loss=${use_kl_loss} \\
actor_rollout_ref.actor.kl_loss_coef=${kl_loss_coef} \\
actor_rollout_ref.actor.clip_ratio_low=${clip_ratio_low} \\
actor_rollout_ref.actor.clip_ratio_high=${clip_ratio_high} \\
actor_rollout_ref.model.use_remove_padding=true \\
actor_rollout_ref.actor.use_dynamic_bsz=${use_dynamic_bsz} \\
actor_rollout_ref.ref.log_prob_use_dynamic_bsz=${use_dynamic_bsz} \\
actor_rollout_ref.rollout.log_prob_use_dynamic_bsz=${use_dynamic_bsz} \\
actor_rollout_ref.actor.ppo_max_token_len_per_gpu=${actor_ppo_max_token_len} \\
actor_rollout_ref.ref.log_prob_max_token_len_per_gpu=${infer_ppo_max_token_len} \\
actor_rollout_ref.rollout.log_prob_max_token_len_per_gpu=${infer_ppo_max_token_len} \\
actor_rollout_ref.rollout.name=${rollout_engine} \\
actor_rollout_ref.rollout.mode=${rollout_mode} \\
actor_rollout_ref.model.path="${MODEL_PATH}" \\
actor_rollout_ref.model.enable_gradient_checkpointing=true \\
actor_rollout_ref.actor.optim.lr=1e-6 \\
actor_rollout_ref.actor.optim.lr_warmup_steps_ratio=0.05 \\
actor_rollout_ref.actor.optim.weight_decay=0.1 \\
actor_rollout_ref.actor.ppo_mini_batch_size=${ppo_mini_batch_size} \\
actor_rollout_ref.actor.ppo_micro_batch_size_per_gpu=${ppo_micro_batch_size_per_gpu} \\
actor_rollout_ref.actor.fsdp_config.param_offload=${offload} \\
actor_rollout_ref.actor.fsdp_config.optimizer_offload=${offload} \\
actor_rollout_ref.actor.entropy_coeff=0 \\
actor_rollout_ref.actor.grad_clip=1.0 \\
actor_rollout_ref.actor.loss_agg_mode=${loss_agg_mode} \\
actor_rollout_ref.actor.ulysses_sequence_parallel_size=${sp_size} \\
actor_rollout_ref.rollout.gpu_memory_utilization=${gpu_memory_utilization} \\
actor_rollout_ref.rollout.tensor_model_parallel_size=${gen_tp} \\
actor_rollout_ref.rollout.enable_chunked_prefill=true \\
actor_rollout_ref.rollout.max_num_batched_tokens=$((max_prompt_length + max_response_length)) \\
actor_rollout_ref.rollout.temperature=${temperature} \\
actor_rollout_ref.rollout.top_p=${top_p} \\
actor_rollout_ref.rollout.top_k=${top_k} \\
actor_rollout_ref.rollout.val_kwargs.temperature=${temperature} \\
actor_rollout_ref.rollout.val_kwargs.top_p=${val_top_p} \\
actor_rollout_ref.rollout.val_kwargs.top_k=${top_k} \\
actor_rollout_ref.rollout.val_kwargs.do_sample=true \\
actor_rollout_ref.rollout.val_kwargs.n=1 \\
actor_rollout_ref.ref.fsdp_config.param_offload=${offload} \\
actor_rollout_ref.ref.ulysses_sequence_parallel_size=${sp_size} \\
actor_rollout_ref.actor.entropy_checkpointing=${entropy_checkpointing} \\
reward_model.reward_manager=${reward_manager} \\
+reward_model.reward_kwargs.overlong_buffer_cfg.enable=${enable_overlong_buffer} \\
+reward_model.reward_kwargs.overlong_buffer_cfg.len=${overlong_buffer_len} \\
+reward_model.reward_kwargs.overlong_buffer_cfg.penalty_factor=${overlong_penalty_factor} \\
+reward_model.reward_kwargs.overlong_buffer_cfg.log=false \\
+reward_model.reward_kwargs.max_resp_len=${max_response_length} \\
trainer.logger='["console"]' \\
actor_rollout_ref.rollout.enforce_eager=True \\
actor_rollout_ref.actor.use_torch_compile=False \\
trainer.project_name="${project_name}" \\
trainer.experiment_name="${exp_name}" \\
trainer.n_gpus_per_node=8 \\
trainer.nnodes=1 \\
trainer.val_before_train=${val_before_train} \\
trainer.test_freq=${test_freq} \\
trainer.save_freq=-1 \\
trainer.total_epochs=${total_epochs} \\
trainer.total_training_steps=${total_training_steps} \\
trainer.default_local_dir="${CKPTS_DIR}" \\
trainer.resume_mode=auto \\
trainer.device=npu \\
trainer.log_val_generations=2 \\
$@
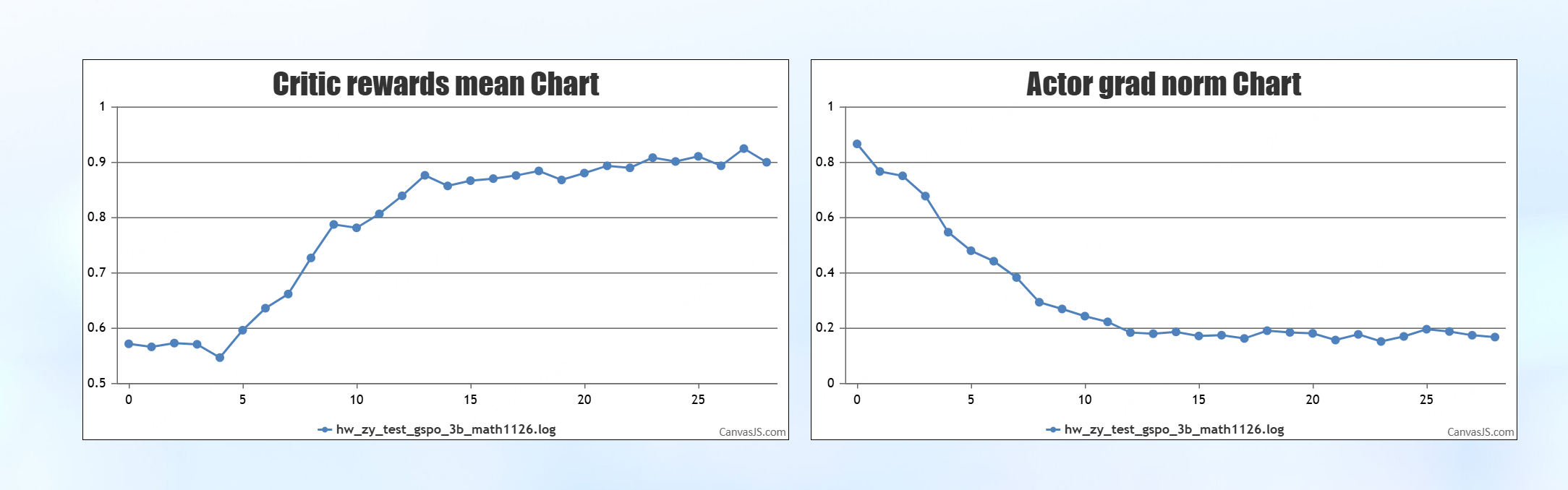
调试结果
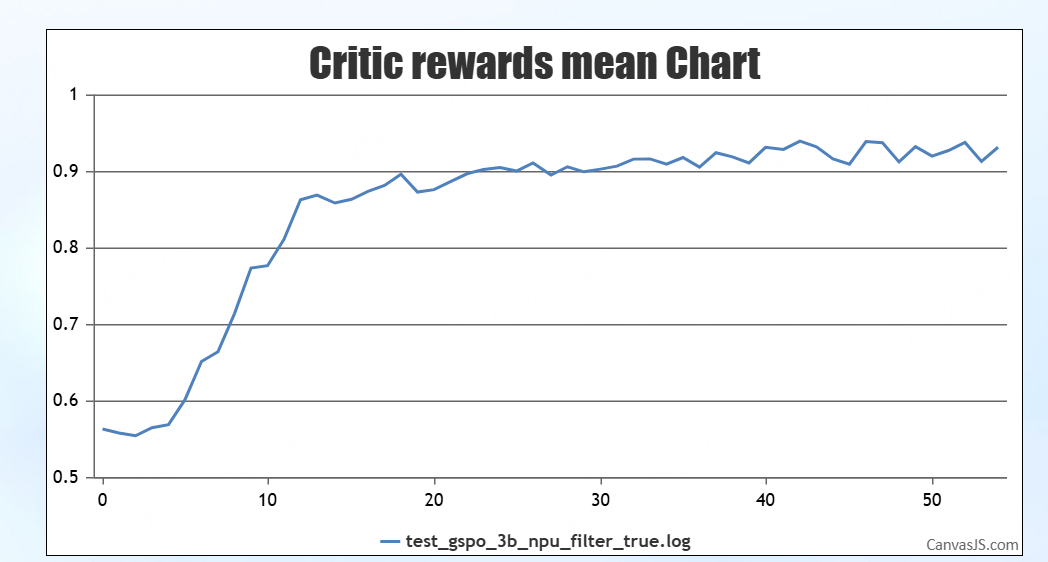
结论:曲线正常上升,上升趋势与官方脚本一致,调试结果符合要求
调试用例4:engineworker后端调试
engineworker使能方法:
trainer.use_legacy_worker_impl=disable \\
调试脚本
#!/usr/bin/env bash
set -x
pkill -9 python
ps -ef | grep "python" |grep -v grep |awk '{print $2}' |xargs -t -i kill -9 {}
ray stop –force
pkill -9 python
pkill -9 torchrun
ps -ef | grep "defaunct" |grep python |awk '{print $3}' |xargs -t -i kill -9 {}
ps -ef | grep "defaunct" |grep torchrun |awk '{print $3}' |xargs -t -i kill -9 {}
ps -ef | grep -i python |grep -i [name] |grep -v grep |awk '{print $2}' |xargs -t -I {} kill -9 {}
ps -ef | grep -i torchrun |grep -i [name] |grep -v grep |awk '{print $2}' |xargs -t -I {} kill -9 {}
ps -ef | grep "python" |grep -v grep |awk '{print $2}' |xargs -t -i kill -9 {}
# Set how many GPUs we actually have on this node.
export GPUS_PER_NODE=8
export NNODES=1
export VLLM_ASCEND_ENABLE_NZ=0
echo "Using $NNODES nodes for training…"
#export ASCEND_LAUNCH_BLOCKING=1
# ————————————- Setup xp params —————————————
project_name='RL-GSPO'
adv_estimator=grpo
loss_mode=gspo
loss_agg_mode="seq-mean-token-mean"
MODEL_PATH=xx/weights/Qwen2.5-3B-Instruct
offload=false # it's a small model, offloading will just slow-down training
rollout_engine=vllm
rollout_mode=async
return_raw_chat="True"
if [ "$rollout_engine" = "vllm" ]; then
export VLLM_USE_V1=1
fi
gpu_memory_utilization=0.6
reward_manager=dapo
adv_estimator=grpo
shuffle_dataset=true
first_time_dataset_prep=true # prepare dataset
test_freq=10
save_freq=10
total_epochs=10
total_training_steps=500
val_before_train=false
use_kl_in_reward=false
kl_coef=0.0
use_kl_loss=false
kl_loss_coef=0.0
clip_ratio_low=0.0003 # as recommended by the paper, see Sec. 5.1
clip_ratio_high=0.0004 # as recommended by the paper, see Sec. 5.1
train_batch_size=512
ppo_mini_batch_size=128 # maintain 4 mini-batches as recommended by the paper, see Sec. 5.1
ppo_micro_batch_size_per_gpu=8 # setup depending on your GPU memory
n_resp_per_prompt=16
max_prompt_length=$((1024 * 2))
max_response_length=$((1024 * 8))
# dapo reward manager params
enable_overlong_buffer=false # true
overlong_buffer_len=$((1024 * 4))
overlong_penalty_factor=1.0
# Paths and namings
SFT_MODEL=$(basename $MODEL_PATH)
exp_name="${loss_mode}-epslow-${clip_ratio_low}-epshigh-${clip_ratio_high}–${SFT_MODEL}-RL"
CKPTS_DIR=/rl/checkpoints/experimental/4b/${loss_mode}/${exp_name}
# Sampling params at rollouts
temperature=1.0
top_p=1.0
top_k=-1 # 0 for HF rollout, -1 for vLLM rollout
val_top_p=0.7
# Performance Related Parameter
sp_size=4
use_dynamic_bsz=true
actor_ppo_max_token_len=$(((max_prompt_length + max_response_length) * 1))
infer_ppo_max_token_len=$(((max_prompt_length + max_response_length) * 1))
offload=true
gen_tp=2
entropy_checkpointing=true # This enables entropy recomputation specifically for the entropy calculation, lowering memory usage during training.
# ————————————- train/val data preparation —————————————
# if [ "$first_time_dataset_prep" = true ]; then
# echo "Preprocessing GSM8K dataset…"
# python examples/data_preprocess/gsm8k.py –local_save_dir /xx/rl_data/gsm8k/data_later –local_dataset_path xx/rl_data/gsm8k/
# fi
gsm8k_train_path=xx/data/post_gsm8k/train.parquet
gsm8k_test_path=xx/data/post_gsm8k/test.parquet
# set the paths
train_files="['$gsm8k_train_path']"
test_files="['$gsm8k_test_path']"
#! 修改filter_overlong_prompts false
python3 -m verl.trainer.main_ppo \\
algorithm.adv_estimator=${adv_estimator} \\
actor_rollout_ref.actor.policy_loss.loss_mode=${loss_mode} \\
data.train_files="${train_files}" \\
data.val_files="${test_files}" \\
data.shuffle=$shuffle_dataset \\
data.prompt_key=prompt \\
data.truncation='error' \\
data.filter_overlong_prompts=false \\
data.return_raw_chat=${return_raw_chat} \\
data.train_batch_size=${train_batch_size} \\
data.max_prompt_length=${max_prompt_length} \\
data.max_response_length=${max_response_length} \\
actor_rollout_ref.rollout.n=${n_resp_per_prompt} \\
algorithm.use_kl_in_reward=${use_kl_in_reward} \\
algorithm.kl_ctrl.kl_coef=${kl_coef} \\
actor_rollout_ref.actor.use_kl_loss=${use_kl_loss} \\
actor_rollout_ref.actor.kl_loss_coef=${kl_loss_coef} \\
actor_rollout_ref.actor.clip_ratio_low=${clip_ratio_low} \\
actor_rollout_ref.actor.clip_ratio_high=${clip_ratio_high} \\
actor_rollout_ref.model.use_remove_padding=true \\
actor_rollout_ref.actor.use_dynamic_bsz=${use_dynamic_bsz} \\
actor_rollout_ref.ref.log_prob_use_dynamic_bsz=${use_dynamic_bsz} \\
actor_rollout_ref.rollout.log_prob_use_dynamic_bsz=${use_dynamic_bsz} \\
actor_rollout_ref.actor.ppo_max_token_len_per_gpu=${actor_ppo_max_token_len} \\
actor_rollout_ref.ref.log_prob_max_token_len_per_gpu=${infer_ppo_max_token_len} \\
actor_rollout_ref.rollout.log_prob_max_token_len_per_gpu=${infer_ppo_max_token_len} \\
actor_rollout_ref.rollout.name=${rollout_engine} \\
actor_rollout_ref.rollout.mode=${rollout_mode} \\
actor_rollout_ref.model.path="${MODEL_PATH}" \\
actor_rollout_ref.model.enable_gradient_checkpointing=true \\
actor_rollout_ref.actor.optim.lr=1e-6 \\
actor_rollout_ref.actor.optim.lr_warmup_steps_ratio=0.05 \\
actor_rollout_ref.actor.optim.weight_decay=0.1 \\
actor_rollout_ref.actor.ppo_mini_batch_size=${ppo_mini_batch_size} \\
actor_rollout_ref.actor.ppo_micro_batch_size_per_gpu=${ppo_micro_batch_size_per_gpu} \\
actor_rollout_ref.actor.fsdp_config.param_offload=${offload} \\
actor_rollout_ref.actor.fsdp_config.optimizer_offload=${offload} \\
actor_rollout_ref.actor.entropy_coeff=0 \\
actor_rollout_ref.actor.grad_clip=1.0 \\
actor_rollout_ref.actor.loss_agg_mode=${loss_agg_mode} \\
actor_rollout_ref.actor.ulysses_sequence_parallel_size=${sp_size} \\
actor_rollout_ref.rollout.gpu_memory_utilization=${gpu_memory_utilization} \\
actor_rollout_ref.rollout.tensor_model_parallel_size=${gen_tp} \\
actor_rollout_ref.rollout.enable_chunked_prefill=true \\
actor_rollout_ref.rollout.max_num_batched_tokens=$((max_prompt_length + max_response_length)) \\
actor_rollout_ref.rollout.temperature=${temperature} \\
actor_rollout_ref.rollout.top_p=${top_p} \\
actor_rollout_ref.rollout.top_k=${top_k} \\
actor_rollout_ref.rollout.val_kwargs.temperature=${temperature} \\
actor_rollout_ref.rollout.val_kwargs.top_p=${val_top_p} \\
actor_rollout_ref.rollout.val_kwargs.top_k=${top_k} \\
actor_rollout_ref.rollout.val_kwargs.do_sample=true \\
actor_rollout_ref.rollout.val_kwargs.n=1 \\
actor_rollout_ref.ref.fsdp_config.param_offload=${offload} \\
actor_rollout_ref.ref.ulysses_sequence_parallel_size=${sp_size} \\
actor_rollout_ref.actor.entropy_checkpointing=${entropy_checkpointing} \\
reward_model.reward_manager=${reward_manager} \\
+reward_model.reward_kwargs.overlong_buffer_cfg.enable=${enable_overlong_buffer} \\
+reward_model.reward_kwargs.overlong_buffer_cfg.len=${overlong_buffer_len} \\
+reward_model.reward_kwargs.overlong_buffer_cfg.penalty_factor=${overlong_penalty_factor} \\
+reward_model.reward_kwargs.overlong_buffer_cfg.log=false \\
+reward_model.reward_kwargs.max_resp_len=${max_response_length} \\
trainer.logger='["console"]' \\
actor_rollout_ref.rollout.enforce_eager=True \\
actor_rollout_ref.actor.use_torch_compile=False \\
trainer.project_name="${project_name}" \\
trainer.experiment_name="${exp_name}" \\
trainer.n_gpus_per_node=8 \\
trainer.nnodes=1 \\
trainer.val_before_train=${val_before_train} \\
trainer.test_freq=${test_freq} \\
trainer.save_freq=-1 \\
trainer.total_epochs=${total_epochs} \\
trainer.total_training_steps=${total_training_steps} \\
trainer.use_legacy_worker_impl=disable \\
trainer.default_local_dir="${CKPTS_DIR}" \\
trainer.resume_mode=auto \\
trainer.device=npu \\
trainer.log_val_generations=2 \\
$@
调试结果
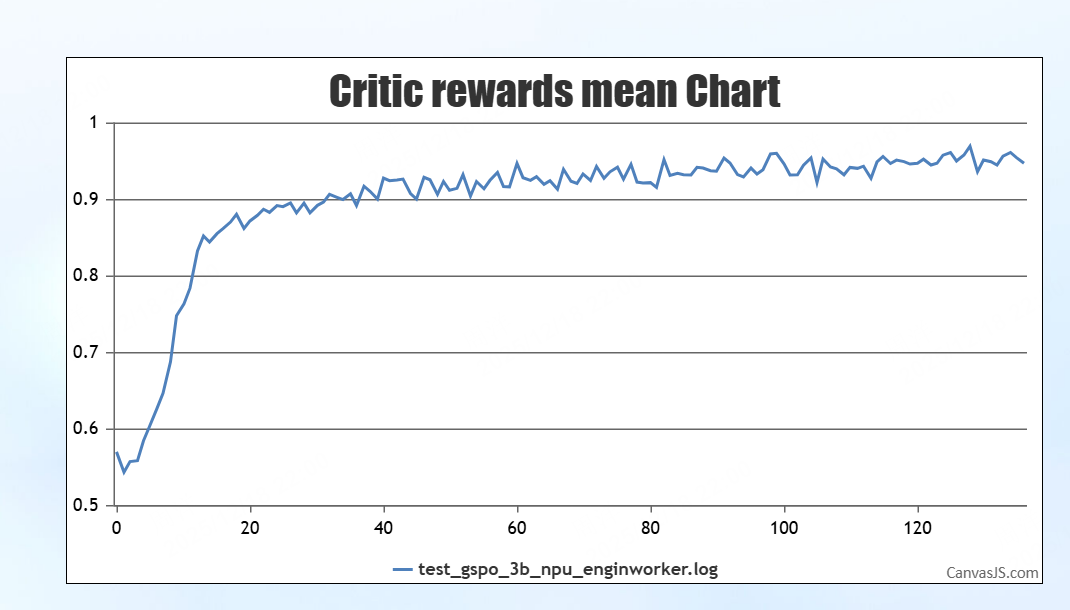
结论:reward曲线正常上升,调试结果符合要求
总结
常见问题与解决方案
问题1:importlib.metadata.PackageNotFoundError:Npackage metadata was found for flash attnith overrides
定位:transformer的npu版本patch未正确使能,可修改如下部分代码/使能4.52.4或4.57.3的transformer版本也可以解决**** 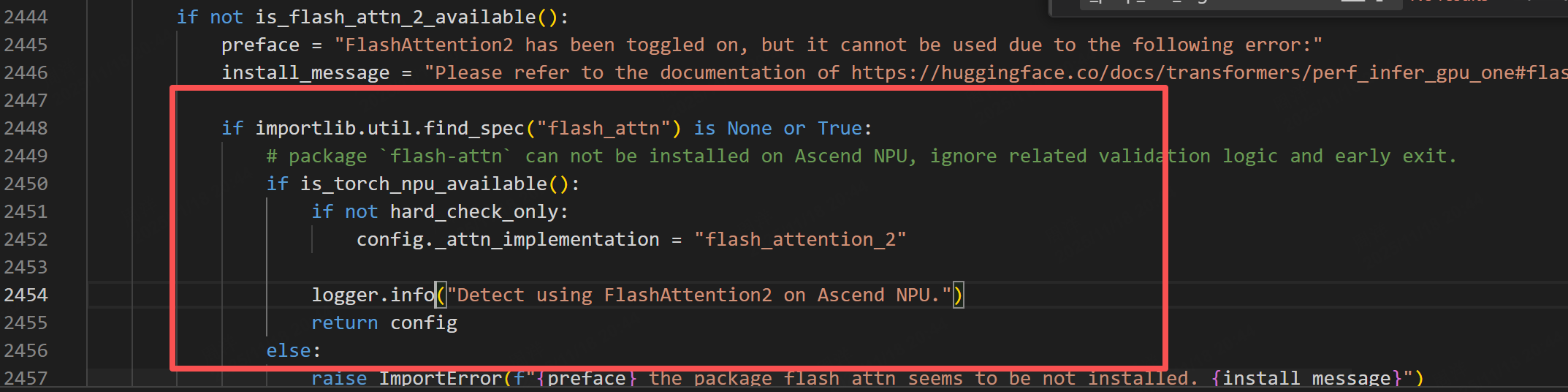
在代码定位过程中发现官方bug:https://github.com/volcengine/verl/pull/3978,现已合入
问题2:raise e.remove_dynamo_frames() from None # see TORCHDYNAMO_VERBOSE=1
File “/opt/pyvenv/lib/python3.10/site-packages/torch/_inductor/compile_fx.py”, line 760, in _compile_fx_inner
定位:走到了图模式 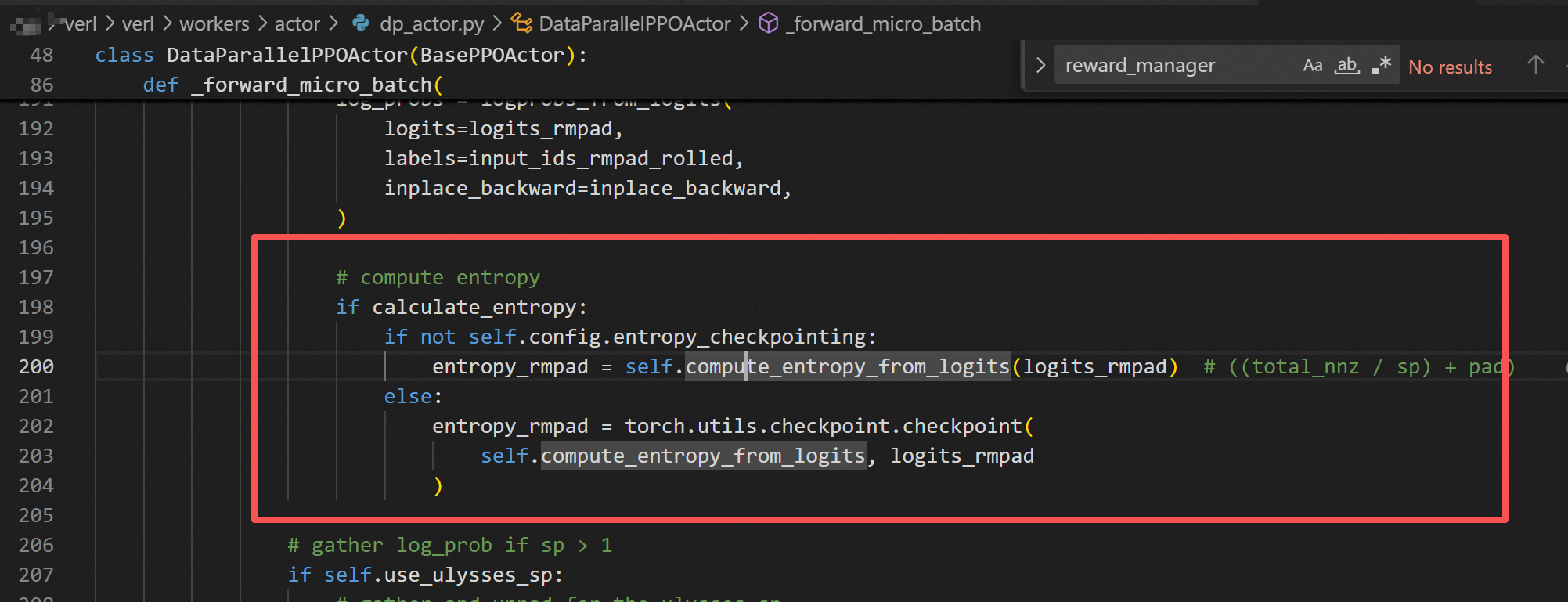
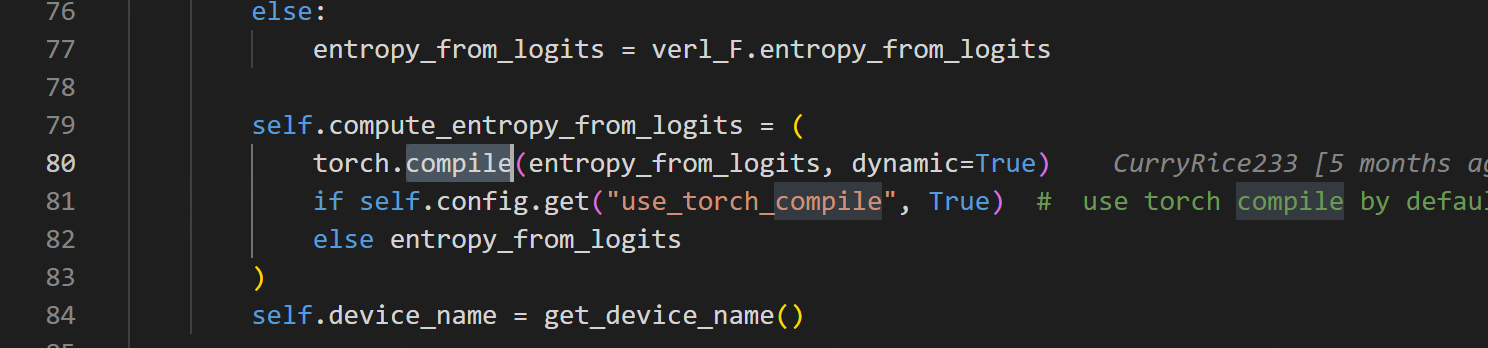
所以增加参数 actor_rollout_ref.actor.use_torch_compile=False \\
问题解决后,拉起训练 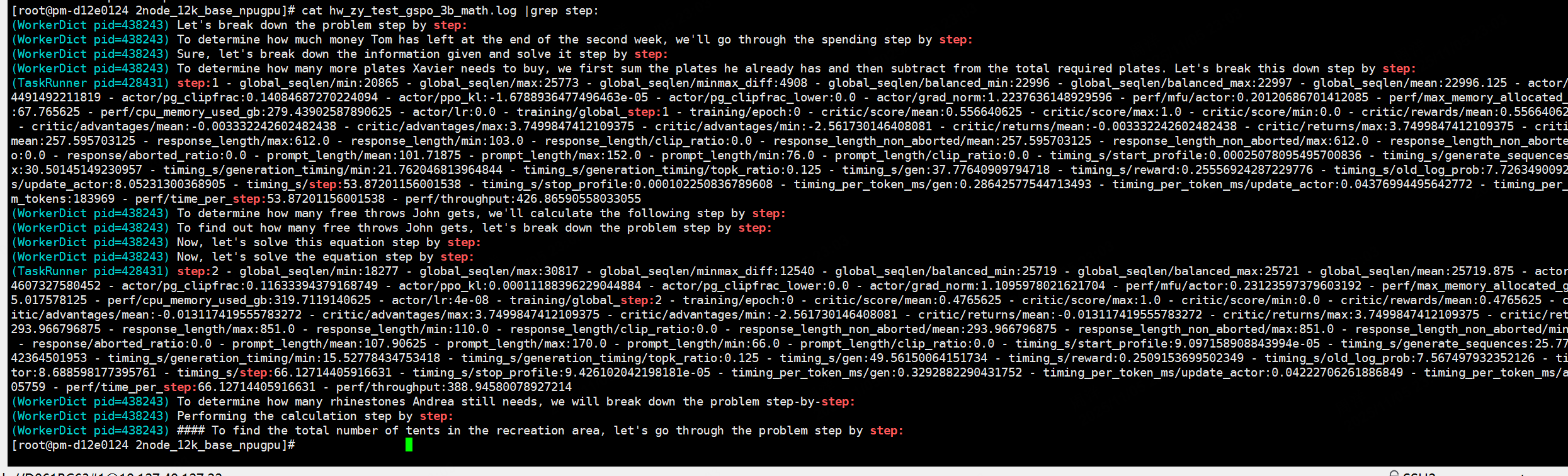
问题3:内存分配失败
调小gbs配置,修改gpu_utils_memory值,这个要根据seq,模型动态调整,否则容易存在碎片张量OOM
问题4:RuntimeError: Please set micro_batch_size or set use_flash_attn=True in config.
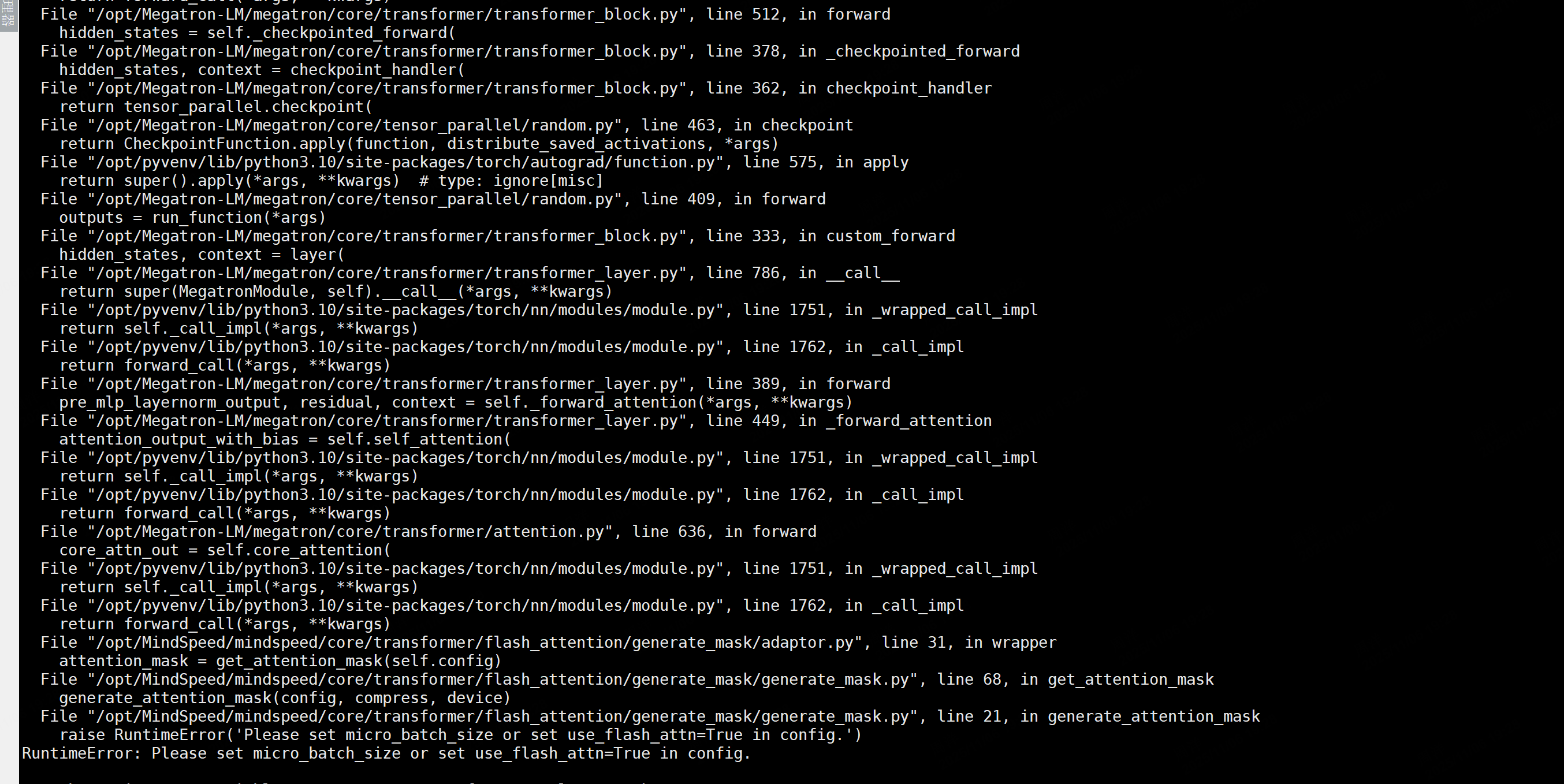
解决方案:
rain_prompt_bsz=32
n_resp_per_prompt=8
train_prompt_mini_bsz=8
问题5 优化器更新阶段OOM
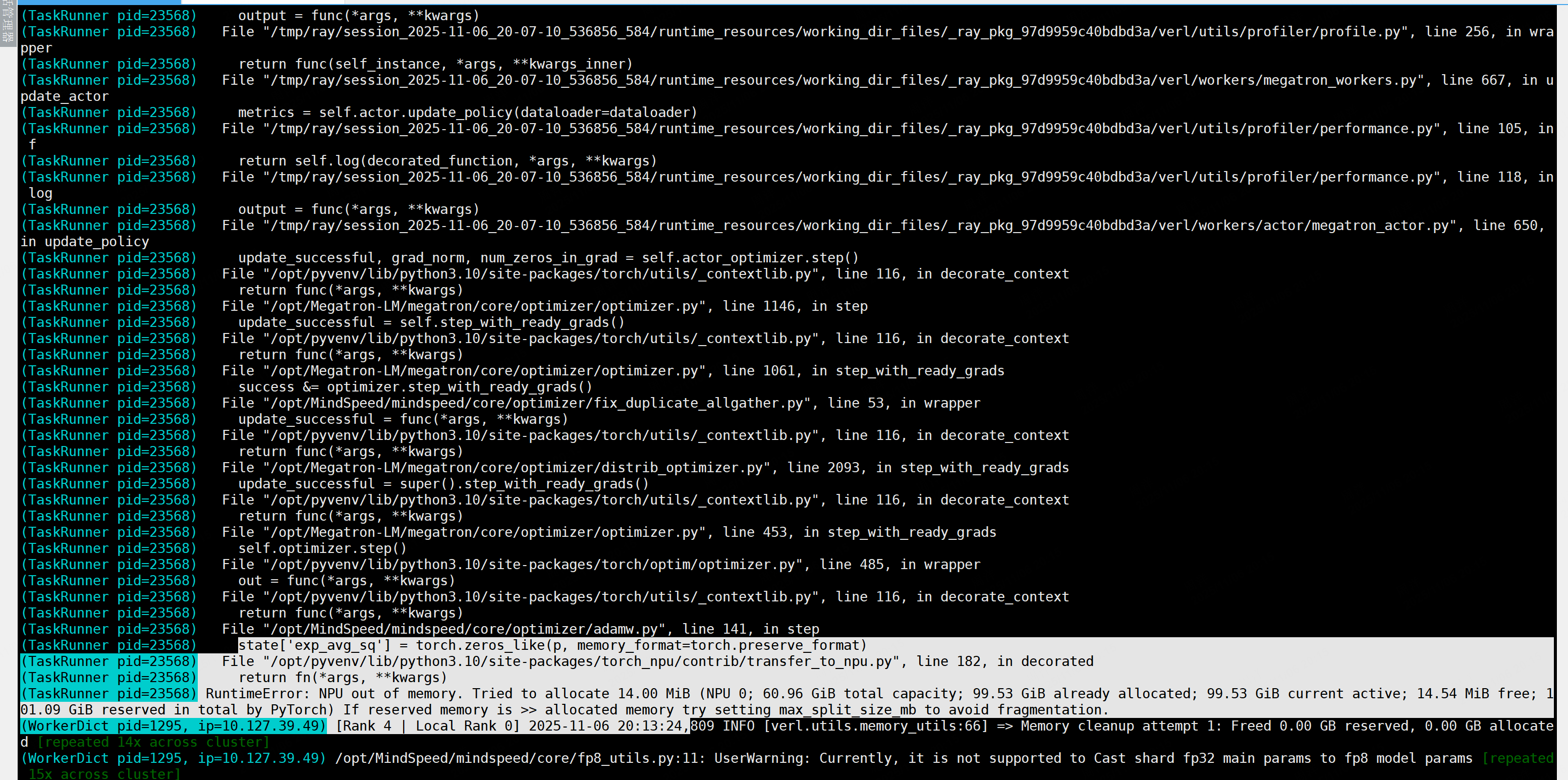
修改训练阶段的策略,使用序列并行
+actor_rollout_ref.actor.megatron.override_transformer_config.use_flash_attn=True \\
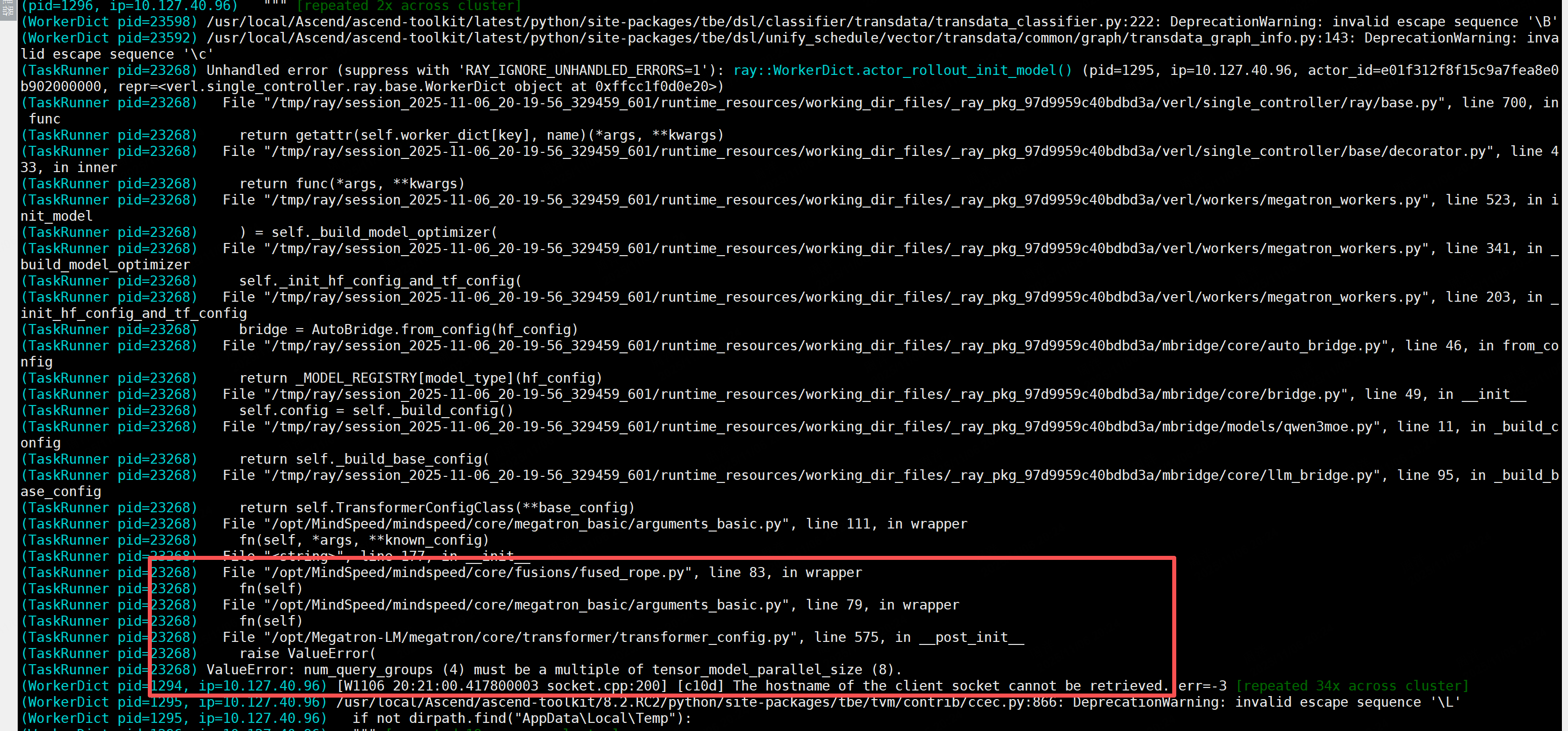
问题6.ValueError: num_query_groups (4) must be a multiple of tensor_model_parallel_size (8).
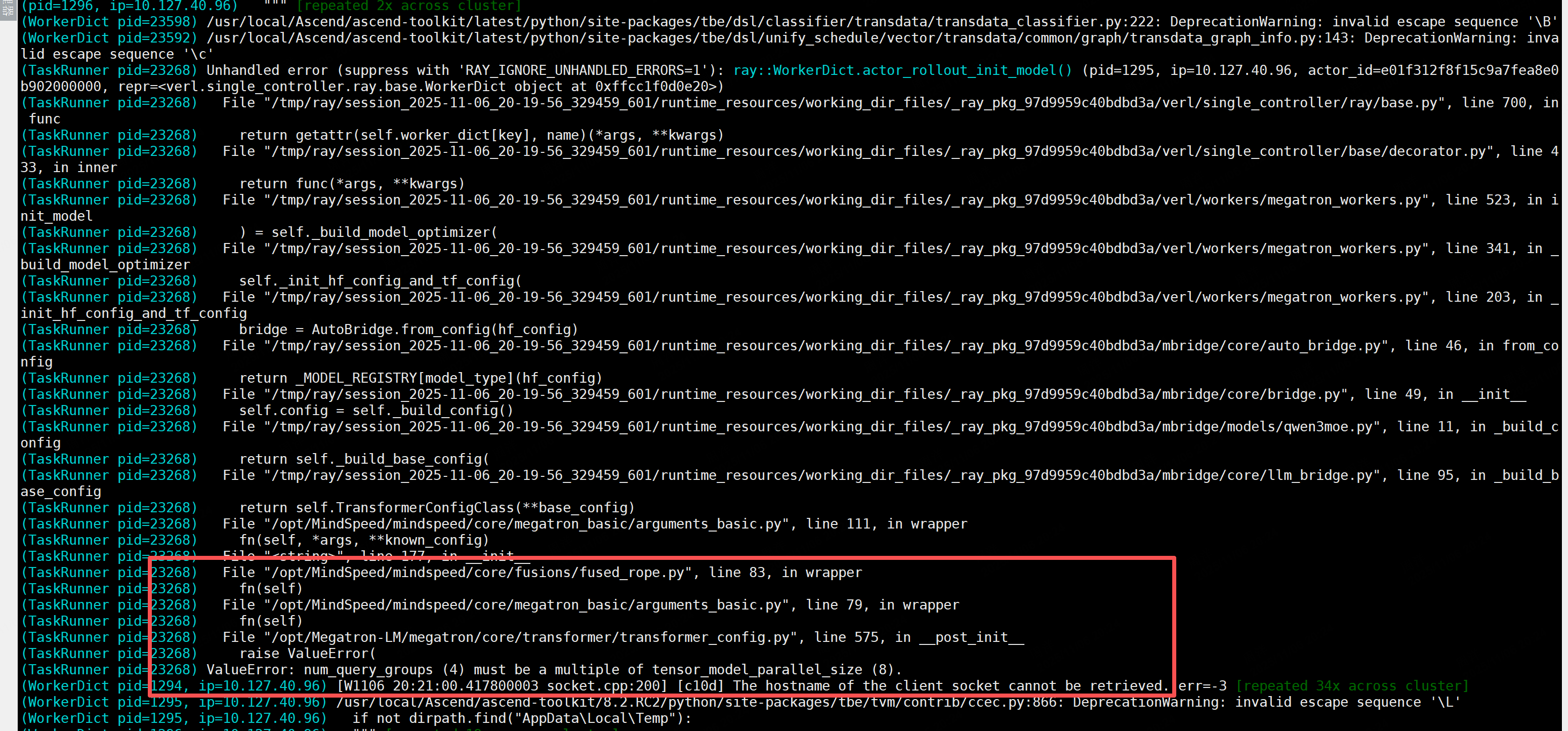
模型参数限制
num_query_groups (4)需要能被TP切分,切换训练切分策略
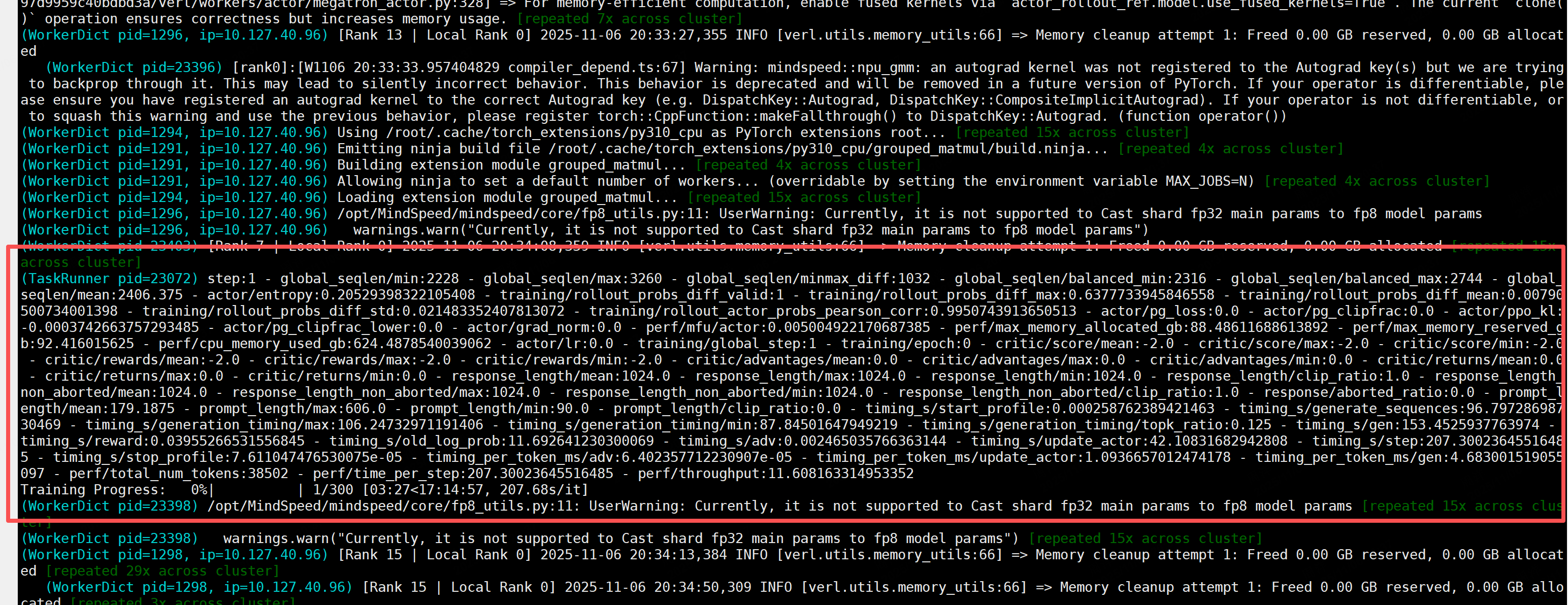
修改后,拉起megaton后端的代码
问题7:基于DAPO脚本修改GSPO算法的时候,发生报错Could not override ‘algorithm. filter_groups. enable’.
原因:GSPO没有这个filter_groups属性,脚本改动疏忽修改即可 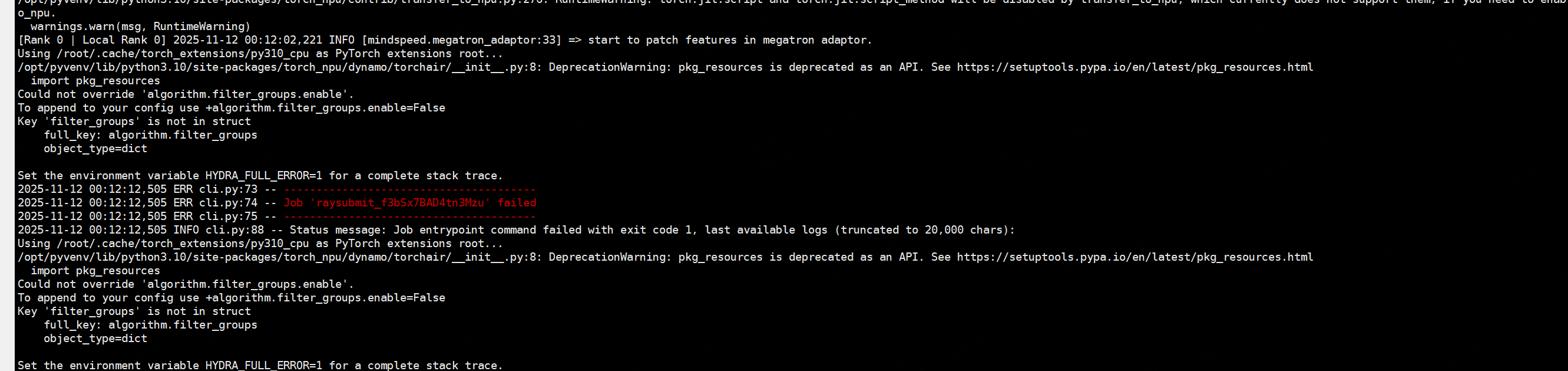









评论前必须登录!
注册