 网硕互联帮助中心
网硕互联帮助中心更加完整详细内容可查看【免费版Java学习笔记】和【免费版Java面试题】
免费版Java学习笔记(28w字)链接:https://www.yuque.com/aoyouaoyou/sgcqr8
免费版Java面试题(20w字)链接:https://www.yuque.com/aoyouaoyou/wh3hto
完整版Java学习笔记200w字,附有代码实现,图解清楚,仅需9.9
完整版Java面试题,150w字,高频面试题,内容详细,仅需9.9
完整版链接:
https://www.xiaohongshu.com/user/profile/63c2d512000000002601232c
祝您新的一年事事马到成功,身体健康,阖家幸福,大展宏图!
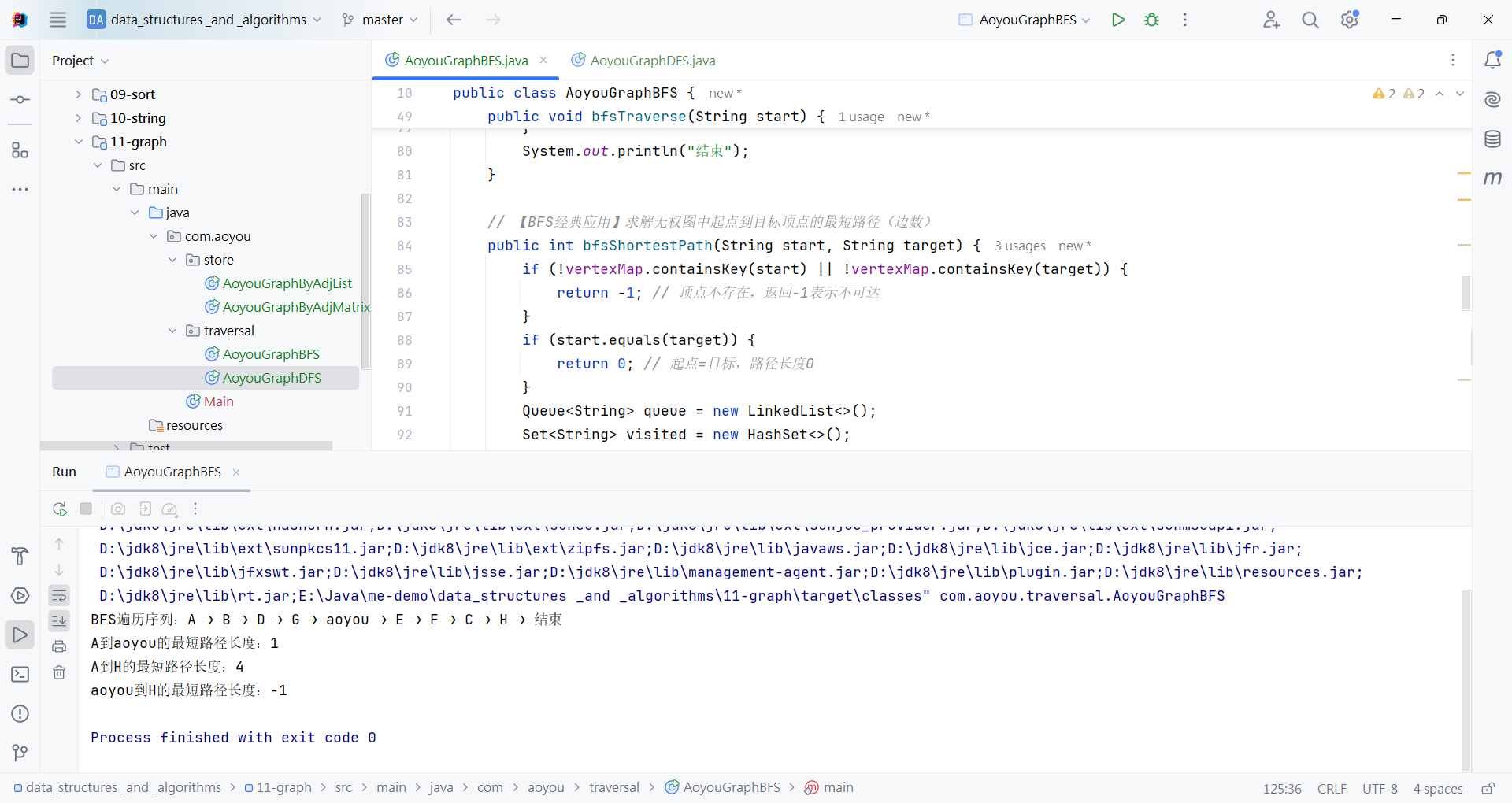
一、图的遍历介绍
1.1 遍历的定义与要求
图的遍历是指从图中任意指定顶点(初始点)出发,按照特定搜索策略沿着边访问所有顶点且每个顶点仅访问一次的过程,遍历得到的顶点序列称为遍历序列。
要求:全访问、不重复——这是因为图存在环和多对多连接,相比二叉树(无环、一对多),遍历需增加访问标记避免重复访问,是图遍历的关键要点。
1.2 两种搜索策略
根据访问顶点的顺序不同,图的遍历分为深度优先搜索(DFS)和广度优先搜索(BFS),二者是图论中最基础、应用最广泛的算法,分别基于栈和队列实现,适配不同的业务场景:
- DFS:深度优先,“一条路走到黑”,适合判断连通性(是否存在路径);
- BFS:广度优先,“地毯式层层推进”,适合求解最短路径(无权图)。
1.3 与二叉树遍历的关联与差异
二叉树的前/中/后序遍历本质是特殊的图遍历(二叉树是无环的连通图),但图的遍历更复杂,差异如下:
|
对比维度 |
二叉树遍历 |
图的遍历 |
|
结构特性 |
无环、一对多、连通 |
可能有环、多对多、可能非连通 |
|
访问标记 |
无需(无重复路径) |
必须有(数组/集合标记,避免环导致重复访问) |
|
辅助结构 |
递归(隐式栈)/显式栈 |
DFS用栈、BFS用队列 |
|
遍历结果 |
唯一(固定左右子树顺序) |
不唯一(依赖邻接顶点的访问顺序) |
二、深度优先搜索(DFS,Depth First Search)
2.1 思想
DFS的是“深度优先,回溯探索”,类似走迷宫:从起点出发,选择一个方向一直往前走,直到走到“死胡同”(当前顶点无未访问的邻接顶点),再回溯到上一个顶点,尝试其他未走的方向,直到遍历所有顶点。
简单总结:先深后广,遇阻回溯。
2.2 实现依赖
DFS的实现依赖栈(Stack)(后进先出LIFO),有两种实现方式:
无论哪种方式,都需要访问标记数组/集合(如visited[]),标记顶点是否已被访问。
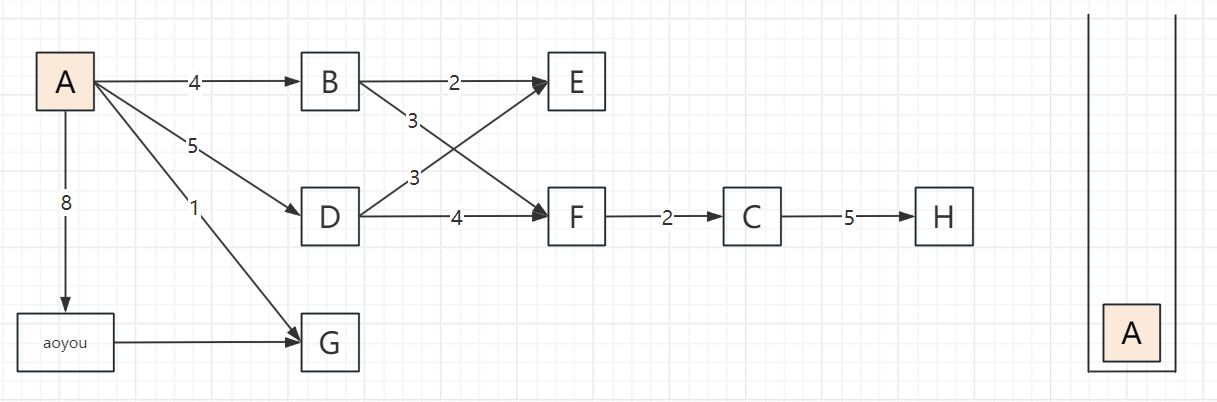
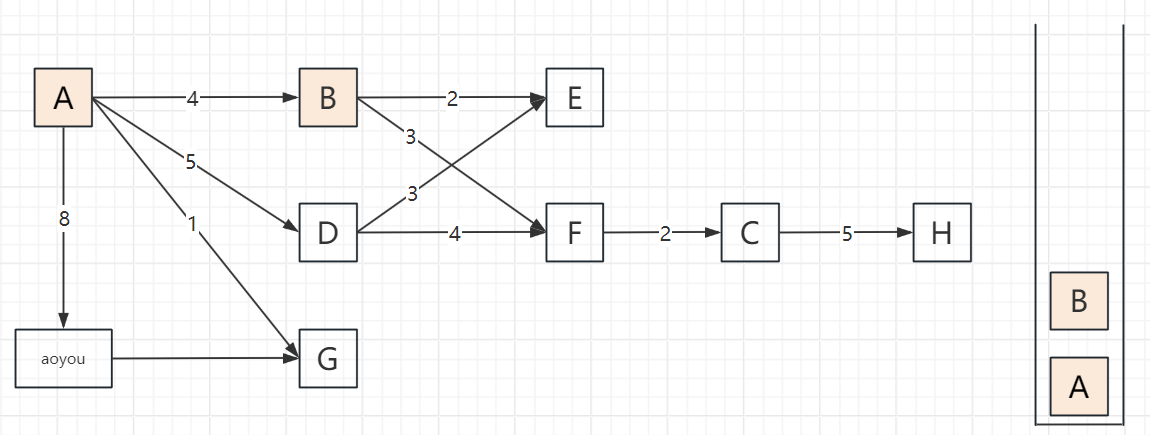
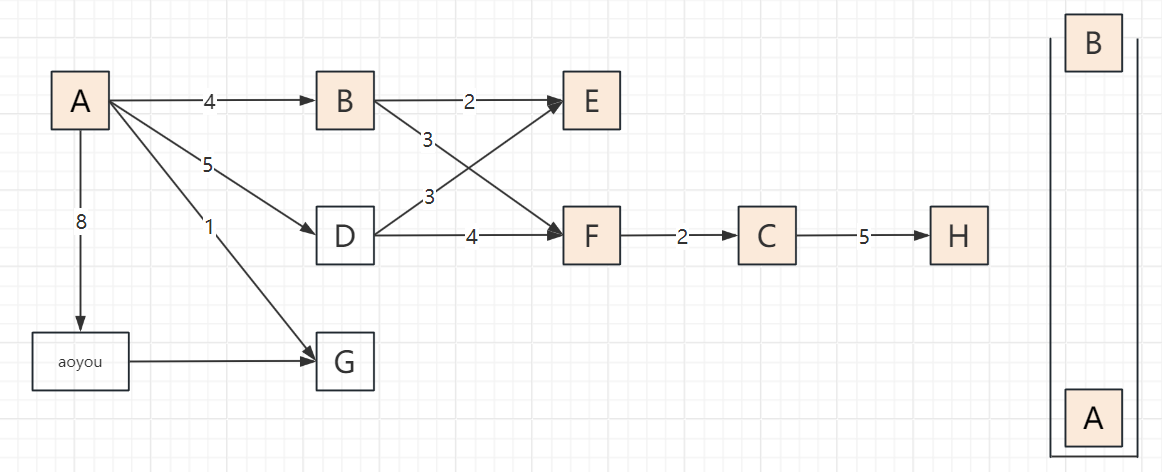
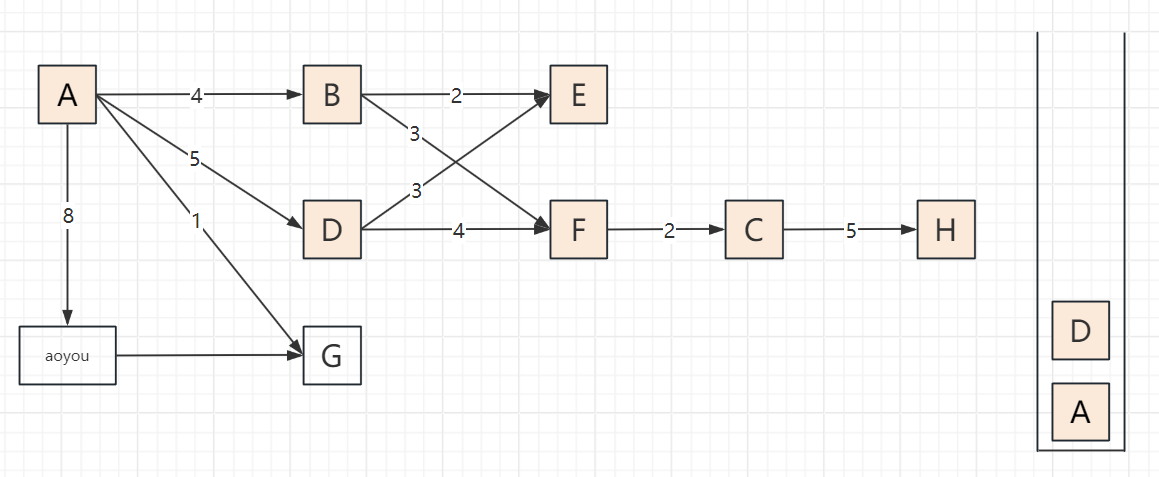
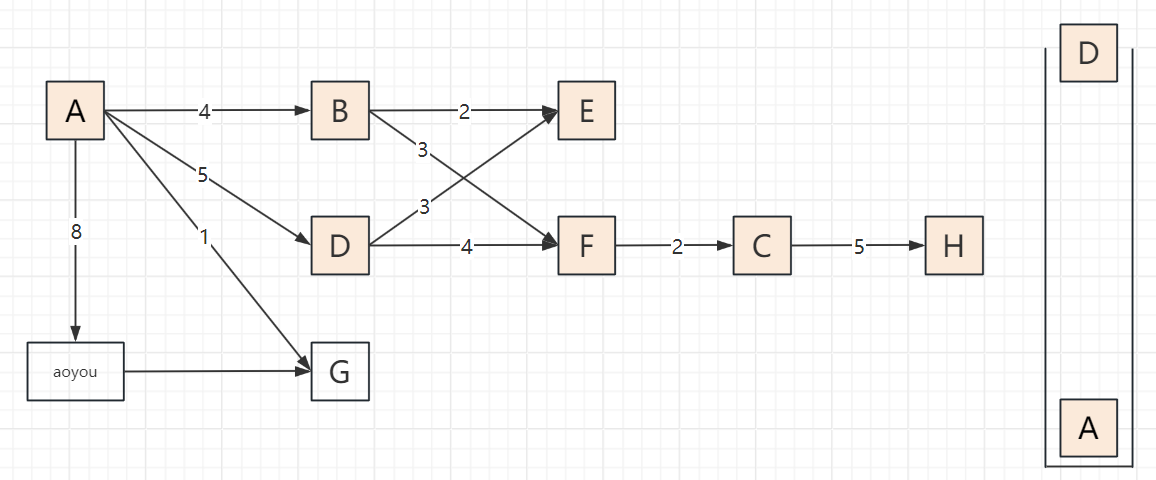
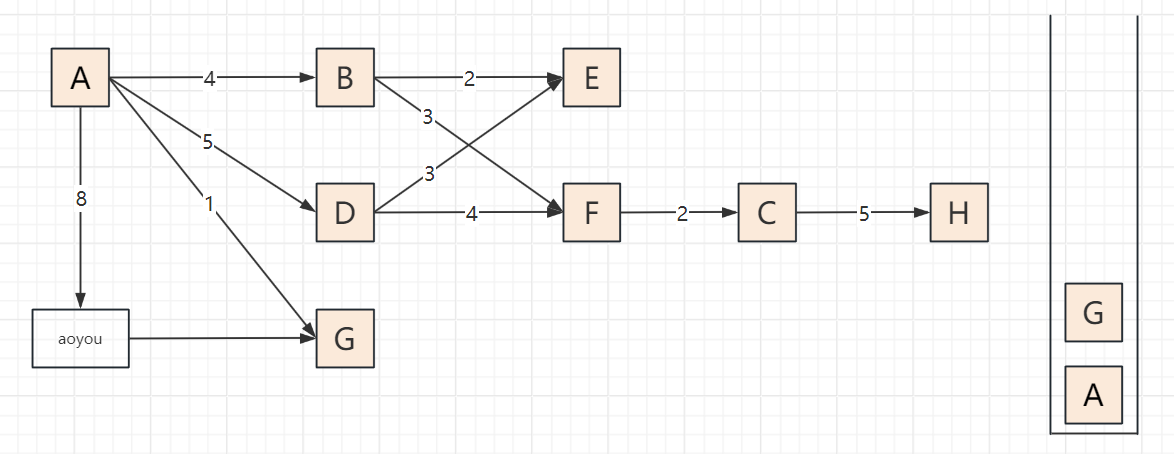
2.3 遍历步骤(以顶点A为起点,邻接顶点按字母序访问)
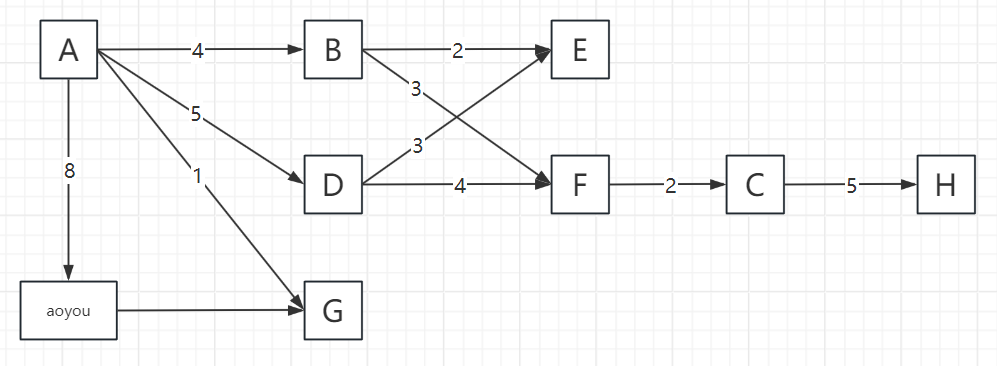
以包含顶点A、B、C、D、E、F、G、H、aoyou的连通图为例,步骤可概括为“入栈标记→深度探索→死胡同出栈→回溯再探索”,关键节点:
遍历过程
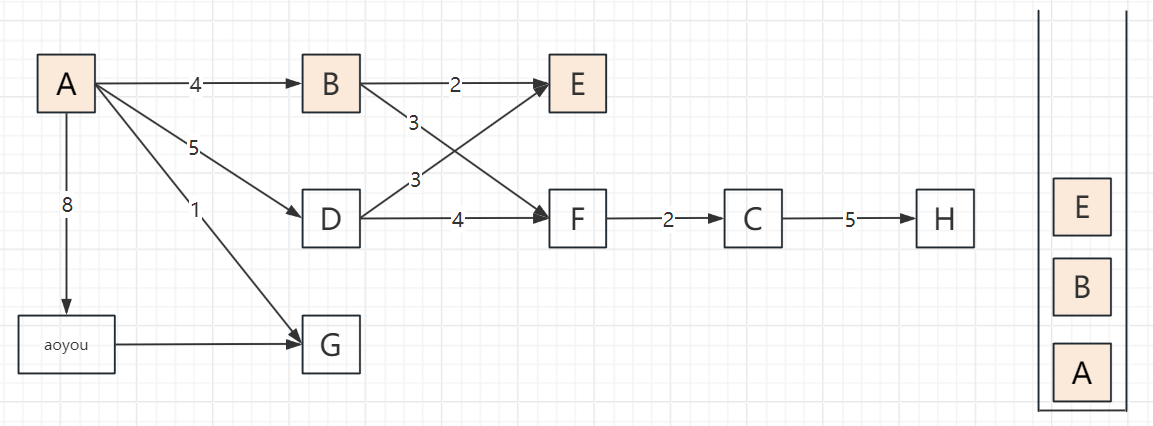
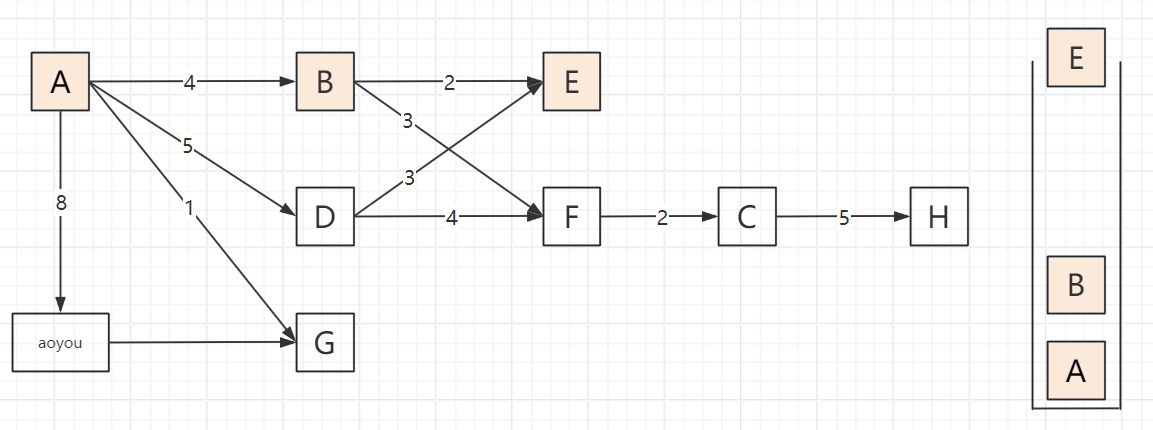
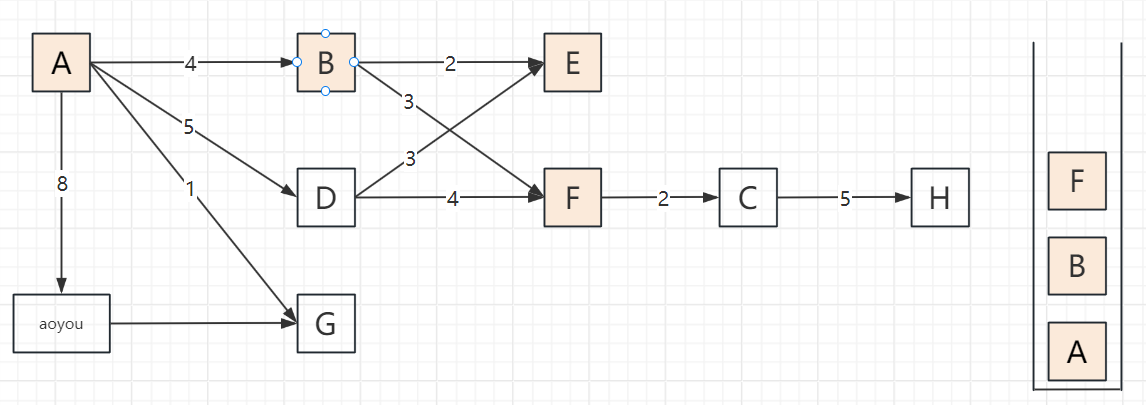
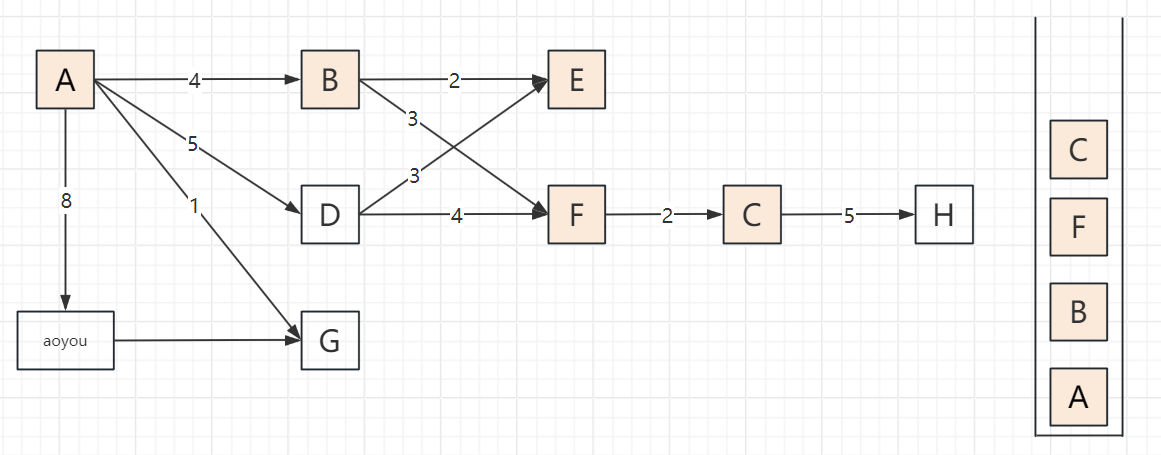
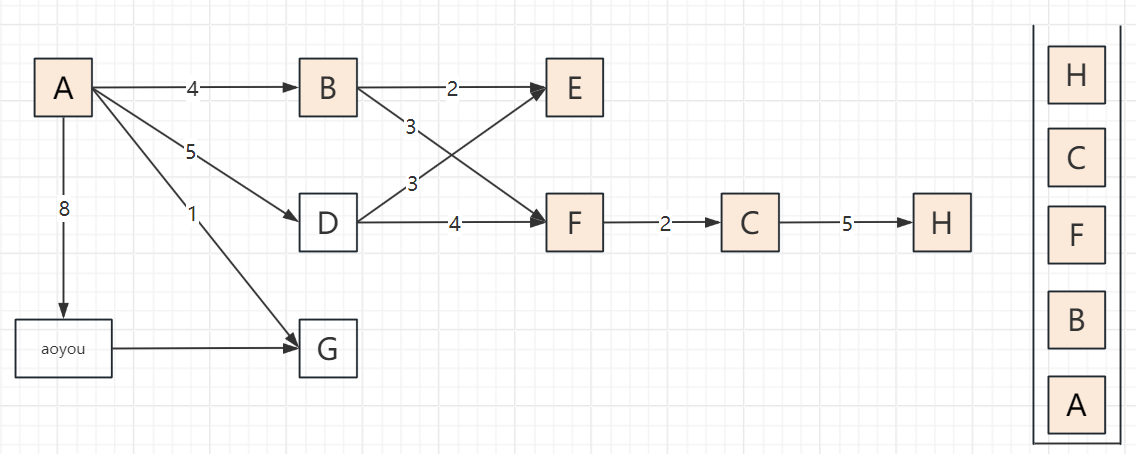
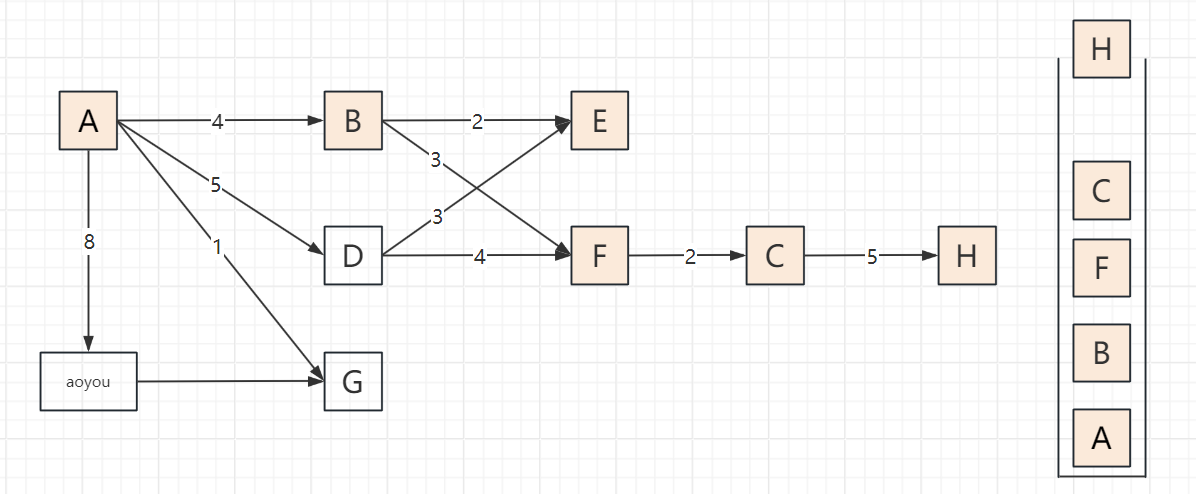
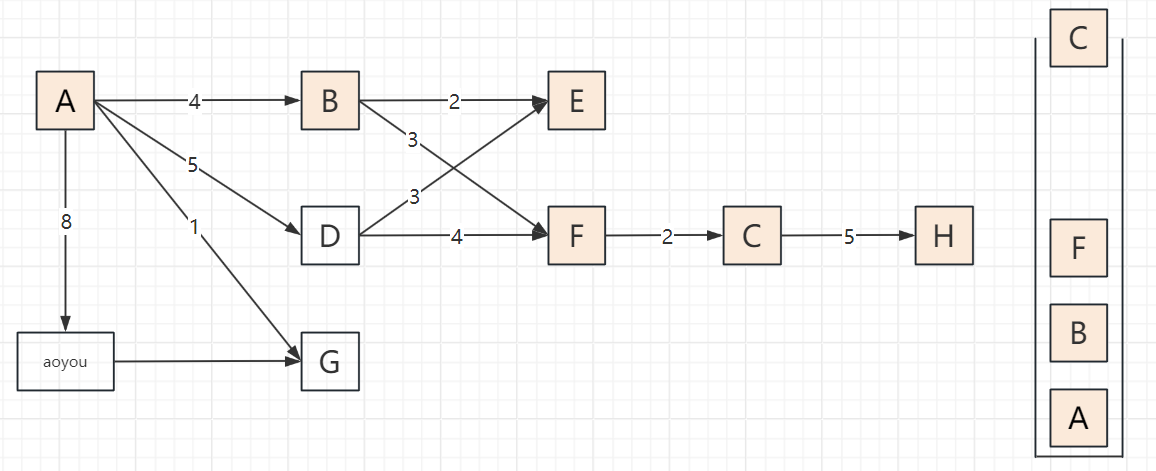
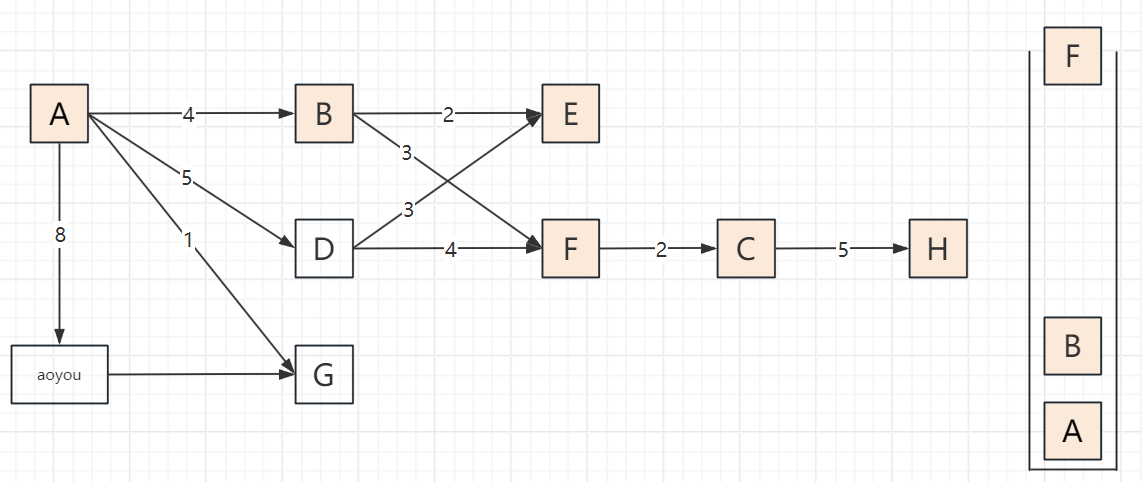
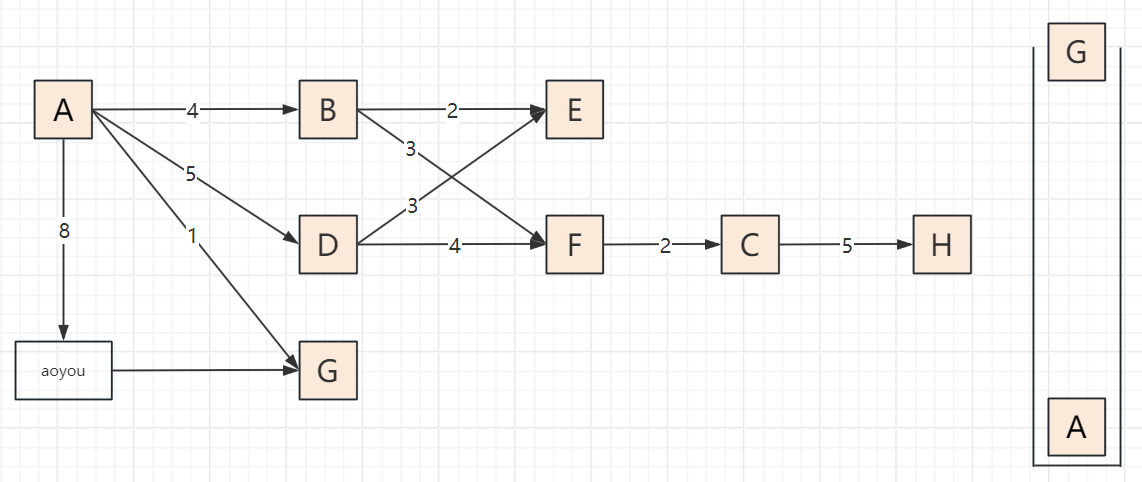
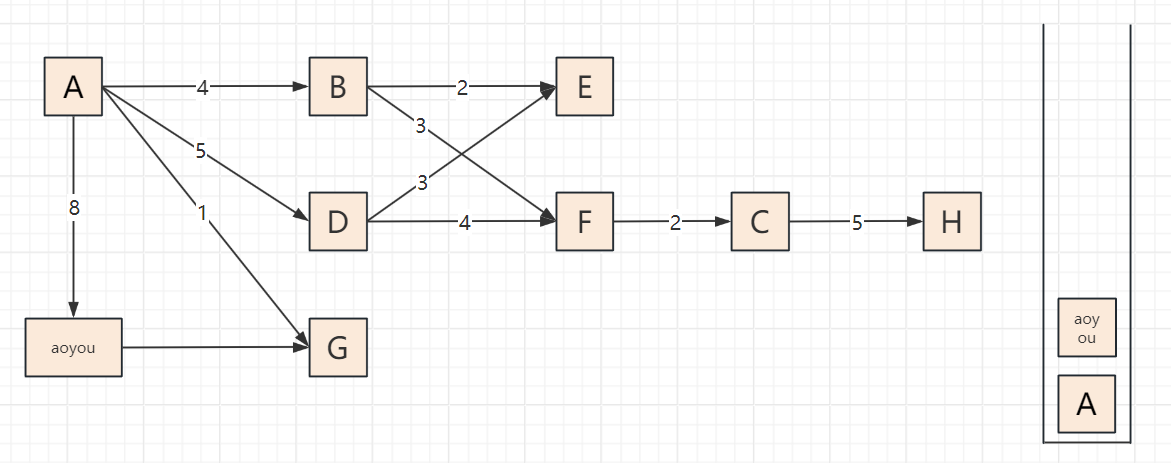
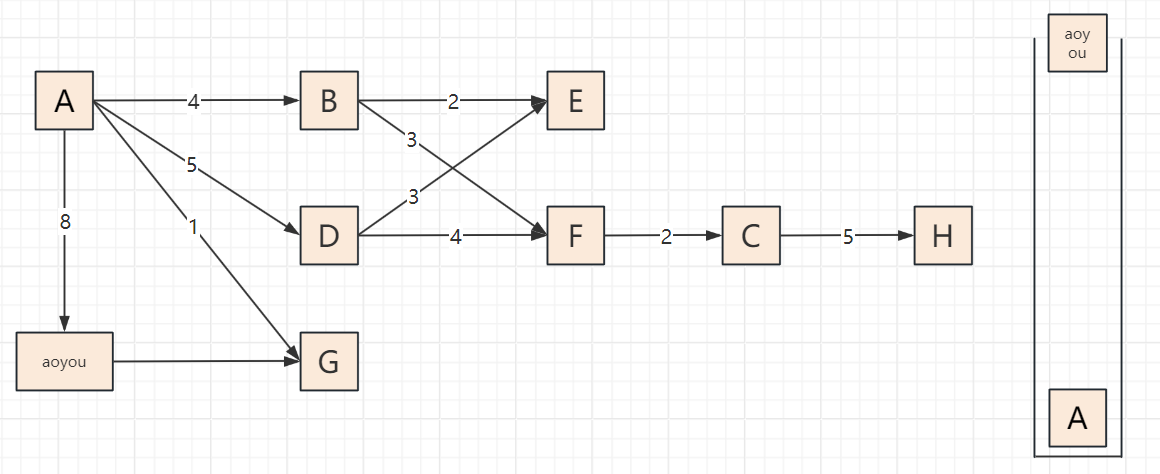
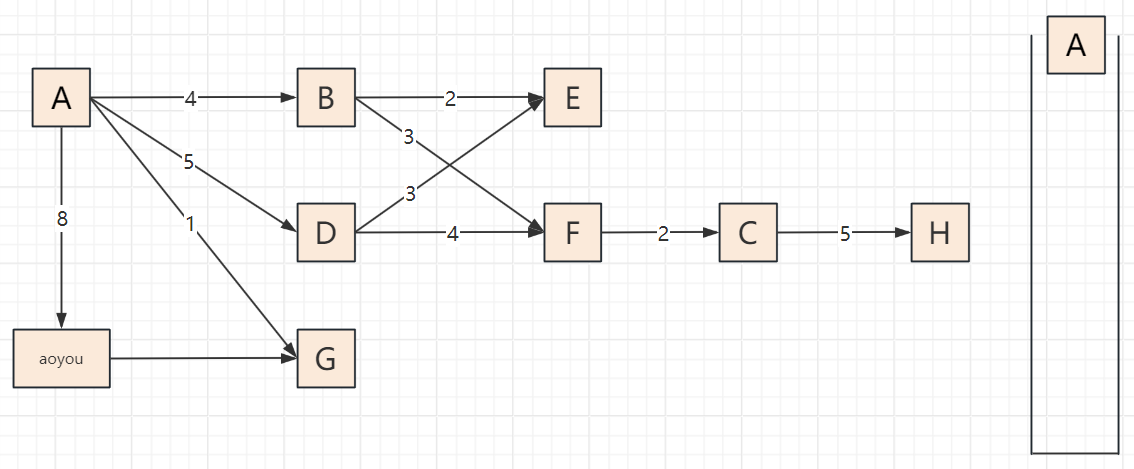

2.4 代码实现(邻接表版,递归+非递归)
基于之前的邻接表图结构,实现DFS的递归版(简洁)和非递归版(通用),融入aoyou顶点,贴合示例要求:
import java.util.*;
/**
* 图的遍历:DFS(深度优先搜索)
* 基于邻接表实现,包含递归+非递归版,融入aoyou顶点
* @author aoyou
*/
public class AoyouGraphDFS {
// 顶点类:封装顶点名称和边链表
static class Vertex {
String name;
Edge next;
public Vertex(String name, Edge next) {
this.name = name;
this.next = next;
}
}
// 边类:封装目标顶点和权值
static class Edge {
String target;
int weight;
Edge next;
public Edge(String target, int weight, Edge next) {
this.target = target;
this.weight = weight;
this.next = next;
}
}
private Map<String, Vertex> vertexMap; // 存储所有顶点
private Set<String> visited; // 访问标记集合,替代数组(更灵活)
public AoyouGraphDFS() {
vertexMap = new HashMap<>();
visited = new HashSet<>();
}
// 插入顶点
public void insertVertex(String name) {
vertexMap.putIfAbsent(name, new Vertex(name, null));
}
// 插入有向边:begin→end,权值weight
public void insertEdge(String begin, String end, int weight) {
Vertex beginV = vertexMap.get(begin);
Edge newEdge = new Edge(end, weight, beginV.next);
beginV.next = newEdge; // 头插法(不影响遍历,仅简化代码)
// 无向图需额外插入end→begin的边
// insertEdge(end, begin, weight);
}
// 【DFS递归版】从指定起点开始遍历
public void dfsRecursive(String start) {
if (!vertexMap.containsKey(start) || visited.contains(start)) {
return;
}
// 1. 访问当前顶点:打印+标记
System.out.print(start + " → ");
visited.add(start);
// 2. 遍历当前顶点的所有邻接顶点,递归访问未标记的顶点
Vertex current = vertexMap.get(start);
Edge edge = current.next;
// 按字母序排序邻接顶点(保证遍历顺序一致)
List<String> neighbors = new ArrayList<>();
while (edge != null) {
neighbors.add(edge.target);
edge = edge.next;
}
Collections.sort(neighbors);
// 递归访问每个邻接顶点
for (String neighbor : neighbors) {
if (!visited.contains(neighbor)) {
dfsRecursive(neighbor);
}
}
}
// 【DFS非递归版】从指定起点开始遍历(显式栈)
public void dfsNonRecursive(String start) {
if (!vertexMap.containsKey(start)) {
return;
}
Stack<String> stack = new Stack<>();
Set<String> visited = new HashSet<>();
// 1. 起点入栈+标记
stack.push(start);
visited.add(start);
System.out.print("非递归DFS:");
while (!stack.isEmpty()) {
// 2. 出栈并访问当前顶点
String current = stack.pop();
System.out.print(current + " → ");
// 3. 遍历邻接顶点,未标记的入栈+标记(逆序入栈,保证访问顺序为字母序)
Vertex v = vertexMap.get(current);
Edge edge = v.next;
List<String> neighbors = new ArrayList<>();
while (edge != null) {
neighbors.add(edge.target);
edge = edge.next;
}
Collections.sort(neighbors, Collections.reverseOrder()); // 逆序
for (String neighbor : neighbors) {
if (!visited.contains(neighbor)) {
stack.push(neighbor);
visited.add(neighbor);
}
}
}
}
// 重置访问标记(多次遍历用)
public void resetVisited() {
visited.clear();
}
// 测试示例(无向图需注释掉边的单向插入)
public static void main(String[] args) {
AoyouGraphDFS graph = new AoyouGraphDFS();
// 1. 插入顶点(包含A、B、C、D、E、F、G、H、aoyou)
String[] vertexes = {"A", "B", "C", "D", "E", "F", "G", "H", "aoyou"};
for (String v : vertexes) {
graph.insertVertex(v);
}
// 2. 插入有向边(模拟连通图)
graph.insertEdge("A", "B", 4);
graph.insertEdge("A", "D", 5);
graph.insertEdge("A", "G", 1);
graph.insertEdge("A", "aoyou", 8);
graph.insertEdge("B", "E", 2);
graph.insertEdge("B", "F", 3);
graph.insertEdge("D", "F", 4);
graph.insertEdge("D", "E", 3);
graph.insertEdge("F", "C", 2);
graph.insertEdge("C", "H", 5);
graph.insertEdge("aoyou", "G", 2); // aoyou连接G
// 3. 递归版DFS(起点A)
System.out.print("递归版DFS:");
graph.dfsRecursive("A");
System.out.println("结束");
// 4. 非递归版DFS(起点A)
graph.dfsNonRecursive("A");
System.out.println("结束");
}
}
2.5 运行结果
递归版DFS:A → B → E → F → C → H → D → G → aoyou → 结束
非递归DFS:A → B → E → F → C → H → D → G → aoyou → 结束

2.6 时间复杂度
DFS的时间复杂度与图的存储方式相关,取决于访问所有顶点和遍历所有边的开销:

(V为顶点数),遍历所有边耗时

(E为边数),总时间复杂度

;

,总时间复杂度

。
2.7 应用场景
DFS专注于“是否存在路径”,不关心路径长度,典型应用:
- 判断图的连通性(无向图是否为连通图、有向图是否强连通);
- 寻找图中的环(如检测任务依赖是否有循环);
- 拓扑排序(有向无环图DAG)、迷宫探索、排列组合问题;
- 深度优先的搜索遍历(如文件夹的递归遍历,本质是树的DFS)。
三、广度优先搜索(BFS,Breadth First Search)
3.1 思想
BFS的是“广度优先,层层推进”,类似水面波纹扩散:从起点出发,先访问起点的所有邻接顶点(第一层),再依次访问第一层每个顶点的邻接顶点(第二层),以此类推,直到遍历所有顶点。
简单总结:先广后深,层层遍历。
3.2 实现依赖
BFS的实现依赖队列(Queue)(先进先出FIFO),必须显式实现(无递归版),同时需要访问标记数组/集合,原因:队列保证“层层推进”的顺序,标记避免同一顶点被多次入队。
3.3 遍历步骤(以顶点A为起点,邻接顶点按字母序入队)
以上述连通图为例,BFS的是“入队标记→出队访问→邻接顶点入队标记”,层层遍历:
遍历过程









3.4 代码实现(邻接表版,求解最短路径)
基于同一邻接表结构,实现BFS遍历,并增加无权图最短路径求解功能(BFS的经典应用):
import java.util.*;
/**
* 图的遍历:BFS(广度优先搜索)
* 基于邻接表实现,含遍历+无权图最短路径求解
* @author aoyou
*/
public class AoyouGraphBFS {
// 复用顶点类和边类(与DFS一致,省略)
static class Vertex {
String name;
Edge next;
public Vertex(String name, Edge next) {
this.name = name;
this.next = next;
}
}
static class Edge {
String target;
int weight;
Edge next;
public Edge(String target, int weight, Edge next) {
this.target = target;
this.weight = weight;
this.next = next;
}
}
private Map<String, Vertex> vertexMap;
public AoyouGraphBFS() {
vertexMap = new HashMap<>();
}
// 插入顶点、插入边(与DFS一致,省略)
public void insertVertex(String name) {
vertexMap.putIfAbsent(name, new Vertex(name, null));
}
public void insertEdge(String begin, String end, int weight) {
Vertex beginV = vertexMap.get(begin);
Edge newEdge = new Edge(end, weight, beginV.next);
beginV.next = newEdge;
// 无向图请添加:insertEdge(end, begin, weight);
}
// 【BFS遍历】从指定起点遍历所有顶点
public void bfsTraverse(String start) {
if (!vertexMap.containsKey(start)) {
System.out.println("起点顶点不存在!");
return;
}
Queue<String> queue = new LinkedList<>();
Set<String> visited = new HashSet<>();
// 起点入队+标记
queue.offer(start);
visited.add(start);
System.out.print("BFS遍历序列:");
while (!queue.isEmpty()) {
// 出队并访问当前顶点
String current = queue.poll();
System.out.print(current + " → ");
// 遍历邻接顶点,未标记的入队+标记(按字母序)
Vertex v = vertexMap.get(current);
Edge edge = v.next;
List<String> neighbors = new ArrayList<>();
while (edge != null) {
neighbors.add(edge.target);
edge = edge.next;
}
Collections.sort(neighbors);
for (String neighbor : neighbors) {
if (!visited.contains(neighbor)) {
queue.offer(neighbor);
visited.add(neighbor);
}
}
}
System.out.println("结束");
}
// 【BFS经典应用】求解无权图中起点到目标顶点的最短路径(边数)
public int bfsShortestPath(String start, String target) {
if (!vertexMap.containsKey(start) || !vertexMap.containsKey(target)) {
return -1; // 顶点不存在,返回-1表示不可达
}
if (start.equals(target)) {
return 0; // 起点=目标,路径长度0
}
Queue<String> queue = new LinkedList<>();
Set<String> visited = new HashSet<>();
Map<String, Integer> pathLen = new HashMap<>(); // 记录每个顶点到起点的路径长度
// 初始化
queue.offer(start);
visited.add(start);
pathLen.put(start, 0);
while (!queue.isEmpty()) {
String current = queue.poll();
// 遍历邻接顶点
Vertex v = vertexMap.get(current);
Edge edge = v.next;
while (edge != null) {
String neighbor = edge.target;
if (neighbor.equals(target)) {
return pathLen.get(current) + 1; // 找到目标,返回路径长度
}
if (!visited.contains(neighbor)) {
visited.add(neighbor);
queue.offer(neighbor);
pathLen.put(neighbor, pathLen.get(current) + 1);
}
edge = edge.next;
}
}
return -1; // 无路径可达
}
// 测试示例
public static void main(String[] args) {
AoyouGraphBFS graph = new AoyouGraphBFS();
// 1. 插入顶点(A、B、C、D、E、F、G、H、aoyou)
String[] vertexes = {"A", "B", "C", "D", "E", "F", "G", "H", "aoyou"};
for (String v : vertexes) {
graph.insertVertex(v);
}
// 2. 插入有向边
graph.insertEdge("A", "B", 4);
graph.insertEdge("A", "D", 5);
graph.insertEdge("A", "G", 1);
graph.insertEdge("A", "aoyou", 8);
graph.insertEdge("B", "E", 2);
graph.insertEdge("B", "F", 3);
graph.insertEdge("D", "F", 4);
graph.insertEdge("D", "E", 3);
graph.insertEdge("F", "C", 2);
graph.insertEdge("C", "H", 5);
graph.insertEdge("aoyou", "G", 2);
// 3. BFS遍历(起点A)
graph.bfsTraverse("A");
// 4. 求解最短路径(无权图)
System.out.println("A到aoyou的最短路径长度:" + graph.bfsShortestPath("A", "aoyou"));
System.out.println("A到H的最短路径长度:" + graph.bfsShortestPath("A", "H"));
System.out.println("aoyou到H的最短路径长度:" + graph.bfsShortestPath("aoyou", "H"));
}
}
3.5 运行结果
BFS遍历序列:A → B → D → G → aoyou → E → F → C → H → 结束
A到aoyou的最短路径长度:1
A到H的最短路径长度:4
aoyou到H的最短路径长度:-1

3.6 时间复杂度
BFS的时间复杂度与DFS完全一致,仅依赖存储方式,与遍历策略无关:
3.7 应用场景
BFS专注于“最短路径”(无权图),层层推进的特性使其适合多源遍历,典型应用:
- 求解无权图的最短路径(如迷宫的最短走出路线、社交网络的一度/二度好友);
- 社交网络的好友推荐(一度好友、二度好友查找,层层推进);
- 多源BFS(如洪水填充、地图上的多起点路径规划);
- 双端BFS(从起点和终点同时BFS,大幅提升长路径搜索效率);
- 图的连通性判断、层序遍历(如二叉树的层序遍历是特殊的BFS)。
四、DFS与BFS对比
从思想、辅助结构、访问顺序、适用场景等8个维度做全面对比,是实际开发中选择遍历算法的关键依据:
|
对比维度 |
深度优先搜索(DFS) |
广度优先搜索(BFS) |
|
思想 |
深度优先,一条路走到黑,遇阻回溯 |
广度优先,地毯式层层推进,逐层遍历 |
|
辅助结构 |
栈(递归:隐式方法栈;非递归:显式栈) |
队列(LinkedList,显式实现) |
|
访问顺序 |
先深后广,不按距离排序 |
先广后深,按到起点的距离(边数)排序 |
|
特性 |
不保证最短路径,适合连通性判断 |
保证无权图的最短路径,适合路径求解 |
|
空间复杂度 |
最坏 (栈存储顶点) |
最坏 (队列存储顶点) |
|
时间复杂度 |
邻接表 ,邻接矩阵 |
与DFS完全一致 |
|
实现方式 |
递归(简洁)、非递归(通用) |
仅显式队列实现(无递归) |
|
典型应用 |
连通性判断、找环、拓扑排序、迷宫探索 |
无权图最短路径、好友推荐、双端BFS、洪水填充 |





评论前必须登录!
注册