 网硕互联帮助中心
网硕互联帮助中心
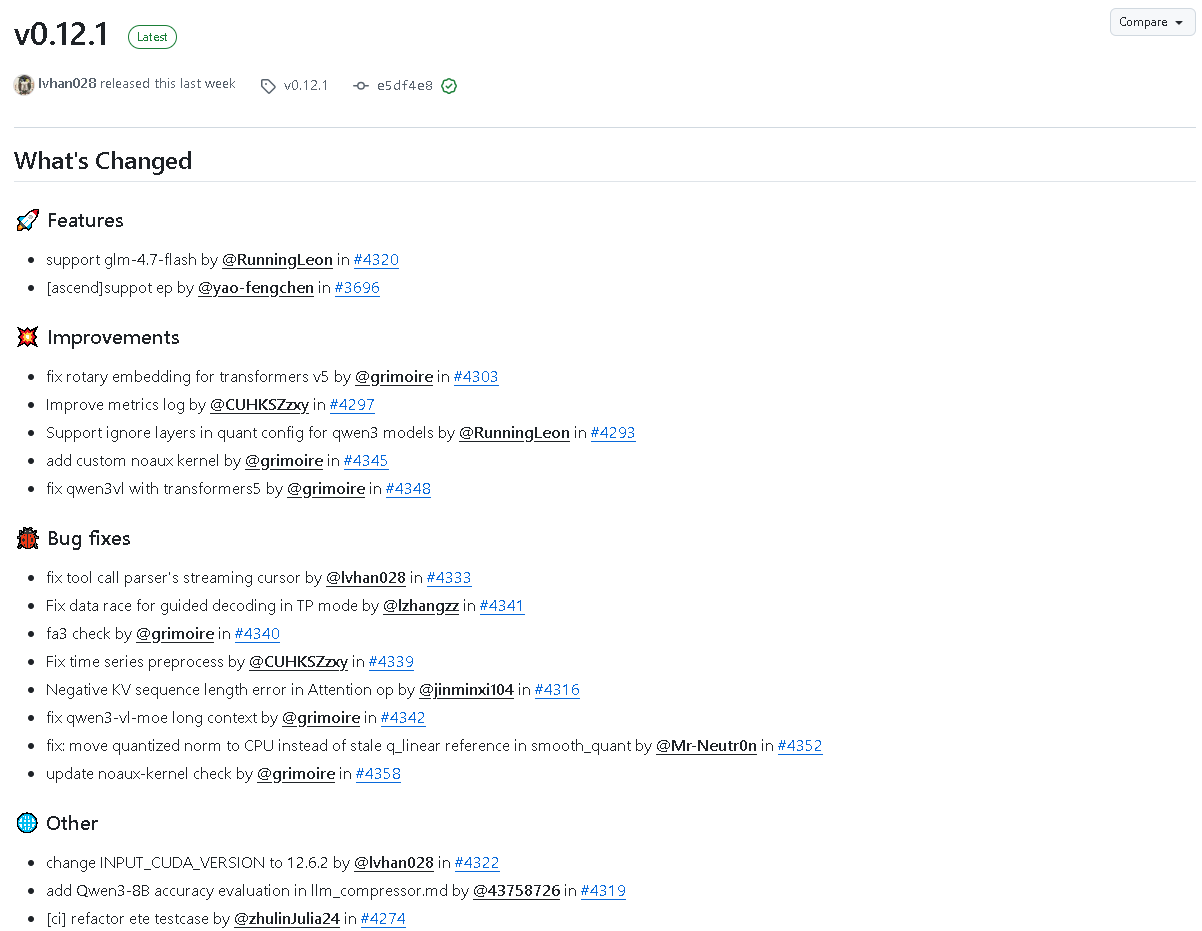
近日,lmdeploy v0.12.1版本正式发布!这一版本不仅在功能上实现了重要突破,还在性能优化与Bug修复方面带来了全面升级,标志着lmdeploy框架在大模型部署与推理领域迈出了坚实一步。以下为本次更新的详细内容。
🚀 新功能(Features)
在v0.12.1中,新增了几个关键功能:
- 支持glm-4.7-flash:新增对glm-4.7-flash模型的全面支持,为用户提供更高效的推理体验。
- Ascend平台支持EP:正式支持Ascend平台的EP运行模式,提升在华为昇腾硬件上的兼容和性能表现。
💥 改进(Improvements)
性能与兼容性方面进行了多项优化:
- 修复Transformers v5的rotary embedding兼容问题:有效解决了在新版transformers中旋转嵌入异常的问题,提升模型稳定性。
- 改进指标日志(metrics log)输出:优化指标记录与性能监控机制,使调试与性能评估更直观。
- 支持Qwen3模型量化配置中忽略特定层:进一步增强Qwen3模型的量化灵活性,方便开发者自定义量化策略。
- 新增自定义noaux kernel:提升系统可扩展性和内核处理能力。
- 修复Qwen3-VL与Transformers v5兼容问题:保证视觉语言模型在最新Transformers环境下的兼容与稳定运行。
🐞 Bug修复(Bug fixes)
本次版本修复了多个关键问题,有效提升系统的稳定性与可靠性:
- 修复工具调用解析器的流式游标问题。
- 解决TP模式下引导解码的并发竞争问题。
- 修复FA3检查逻辑。
- 修复时间序列预处理中出现的异常。
- 修复Attention算子中负KV序列长度错误。
- 修复Qwen3-VL-MOE模型在长上下文场景下的不稳定问题。
- 优化smooth quant逻辑,将量化后的norm移至CPU,避免旧q_linear引用问题。
- 更新noaux-kernel检查机制,提升内核稳定性。
🌐 其他更新(Other)
在系统环境与文档方面也进行了更新:
- 输入CUDA版本调整为12.6.2,适配最新CUDA环境,提高兼容性。
- 在llm_compressor.md中新增Qwen3-8B精度评估,为开发者提供更全面的参考指标。
- 重构CI测试用例,提升持续集成的稳定性与效率。
- 设置interns1_1为interns1_pro别名,简化模型调用配置。
- Docker构建优化:在使用CU13环境时自动跳过FA2组件,提高构建灵活性。
- 最后,版本号正式升级至v0.12.1。
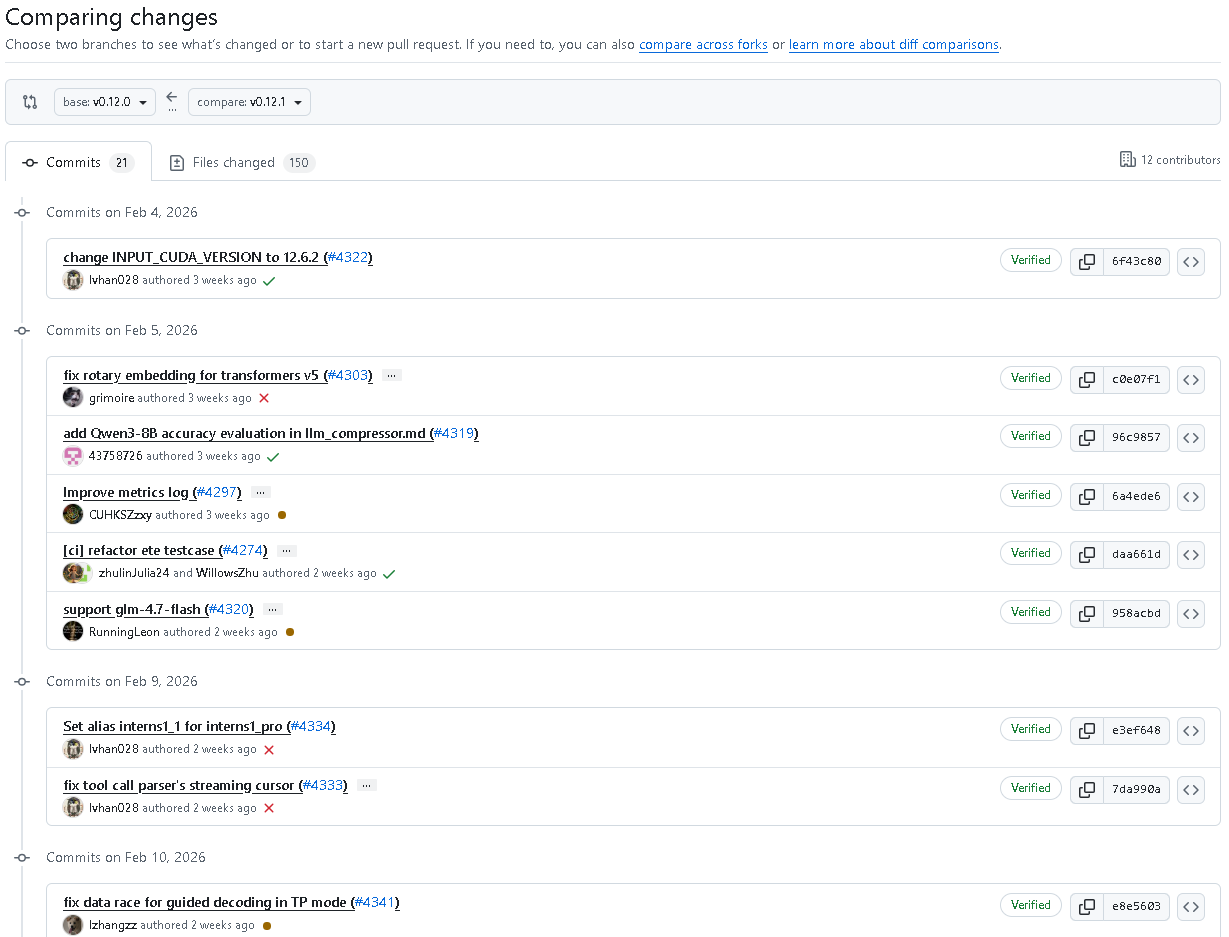
📦 更新概览
- 共计12位贡献者参与本次版本迭代
- 提交次数:21次
- 文件改动:150处
🔧 总结
代码地址:github.com/InternLM/lmdeploy
lmdeploy v0.12.1版本专注于多平台适配、模型兼容性提升与高稳定性优化。此次更新不仅扩展了对新模型(如glm-4.7-flash、Qwen3-VL)的支持,还在性能日志、量化策略、内核执行方面实现了更高层次的优化。对于开发者而言,这一版本无疑是当前最值得升级的版本之一。







评论前必须登录!
注册