 网硕互联帮助中心
网硕互联帮助中心分组背包:
1.定义:给定一个整数m表示背包的容量,有n个货物可供挑选。每个货物有自己的体积,价值,组号。同一个组的物品只能挑选一件,所有挑选物品的体积总和不能超过背包容量。
怎么挑选货物能达到价值最大,返回最大价值。
2.dp[i][j]表示1~i组上,每组只能选一件商品(注意:i表示的是组,不是商品)容量不超过j的条件下的最大价值。
1)不要i组商品就满足条件——dp[i-1][j]
2)要i组商品,考虑要哪一件?全试!!!
a:dp[i-1][j-a的体积]+a的价值
b:dp[i-1][j-b的体积]+b的价值
c:dp[i-1][j-c的体积]+c的价值
(注意:a,b,c是i组中的商品)
关键是给物品分好组,这样才能进行后面的计算。
3.时间复杂度:
for(组的数量)
for(背包容量)
for(组内物品数量)
组1:m*组1物品数量
组2:m*组2物品数量
……
组i:m*组i物品数量
o(m*物品总个数)
例题一:通天之分组背包
题目描述
自 01 背包问世之后,小 A 对此深感兴趣。一天,小 A 去远游,却发现他的背包不同于 01 背包,他的物品大致可分为 k 组,每组中的物品相互冲突,现在,他想知道最大的利用价值是多少。
输入格式
两个数 m,n,表示一共有 n 件物品,背包能承受的最大重量为 m。
接下来 n 行,每行 3 个数 ai,bi,ci,表示物品的重量,利用价值,所属组数。
输出格式
一个数,最大的利用价值。
输入
45 3
10 10 1
10 5 1
50 400 2
输出
10
说明/提示
0≤m≤1000,1≤n≤1000,1≤k≤100,ai,bi,ci 在 int 范围内。
代码实现:
#include<stdio.h>
#define MAXN 1010
#define MAXM 1010
typedef struct{
int w;
int v;
int k;
} Node;
Node a[MAXN];
int dp[MAXN][MAXM]; // dp[i][j]表示前i组,容量为j时的最大价值
int max(int a, int b) {
return a > b ? a : b;
}
int compute(int m, int n) {
// 统计有多少组
int teams = 1;
for(int i = 2; i <= n; i++) {
if(a[i].k != a[i-1].k) {
teams++;
}
}
int start = 1; // 当前组的起始位置
int end = 1; // 当前组的结束位置
int i = 1; // 组索引,表示第一组
// 按组处理物品
for(start = 1, end = 2, i = 1; start <= n; i++) {
// 找到当前组的结束位置
while(end <= n && a[end].k == a[start].k) {
end++;
}
// 此时end指向下一组的第一个元素
//完成第i组的归纳后,就要对这一组进行处理。找到一件价值最大的商品
// 处理第i组
for(int j = 0; j <= m; j++) {//对所有重量进行遍历。先取一个重量,对所有物品进行遍历,找到最大的那个。再取其他重量,最后找到的肯定是所有物品中价值最大的。
// 不选当前组的任何物品
dp[i][j] = dp[i-1][j];
// 尝试选择当前组中的每个物品
for(int g = start; g < end; g++) {
if(j >= a[g].w) {
dp[i][j] = max(dp[i][j], dp[i-1][j – a[g].w] + a[g].v);
}//上述取最大值刚好符合我们分析的部分背包的最大价值取法。
}
}
// 移动到下一组,再开始进行下一组的处理
start = end; // 下一组的起始位置是当前的end
end++; // end指向下一组的第二个位置
}
return dp[i-1][m];//因为先处理i++,然后才发现下一组不能循环了,所以最终返回的是dp[i-1][m]
}
int main() {
int m, n;
scanf("%d%d", &m, &n);
// 输入从1开始,方便处理
for(int i = 1; i <= n; i++) {
scanf("%d%d%d", &a[i].w, &a[i].v, &a[i].k);
}
// 根据组号进行排序(按组号升序)
for(int i = 1; i < n; i++) {
for(int j = 1; j <= n – i; j++) {
if(a[j].k > a[j+1].k) {
Node temp = a[j];
a[j] = a[j+1];
a[j+1] = temp;
}
}
}
int sum = compute(m, n);
printf("%d\\n", sum);
return 0;
}
例题二:摆花
题目描述
小明的花店新开张,为了吸引顾客,他想在花店的门口摆上一排花,共 m 盆。通过调查顾客的喜好,小明列出了顾客最喜欢的 n 种花,从 1 到 n 标号。为了在门口展出更多种花,规定第 i 种花不能超过 ai 盆,摆花时同一种花放在一起,且不同种类的花需按标号的从小到大的顺序依次摆列。
试编程计算,一共有多少种不同的摆花方案。
输入格式
第一行包含两个正整数 n 和 m,中间用一个空格隔开。
第二行有 n 个整数,每两个整数之间用一个空格隔开,依次表示 a1,a2,⋯,an。
输出格式
一个整数,表示有多少种方案。注意:因为方案数可能很多,请输出方案数对 10^6+7 取模的结果。
输入
2 4
3 2
输出
2
说明/提示
【数据范围】
对于 20% 数据,有 0<n≤8,0<m≤8,0≤ai≤8。
对于 50% 数据,有 0<n≤20,0<m≤20,0≤ai≤20。
对于 100% 数据,有 0<n≤100,0<m≤100,0≤ai≤100。
代码实现:
#include <stdio.h>
#include <string.h>
#define maxn 105
#define mod 1000007
int main() {
int n, m;
int a[maxn];
int f[maxn][maxn];
// 读取输入
scanf("%d %d", &n, &m);
for (int i = 1; i <= n; i++) {
scanf("%d", &a[i]);
}
// 初始化 DP 数组
memset(f, 0, sizeof(f));
f[0][0] = 1;
// 动态规划计算方案数
for (int i = 1; i <= n; i++) {
for (int j = 0; j <= m; j++) {
int limit = (a[i] < j) ? a[i] : j; // min(j, a[i])
for (int k = 0; k <= limit; k++) {
f[i][j] = (f[i][j] + f[i-1][j-k]) % mod;
}
}
}
// 输出结果
printf("%d\\n", f[n][m]);
return 0;
}
解题思路:
相当于是已经分好组了。还是从一个组中取物品。
dp[i][j]表示从1~i组中取花摆成j盆花的方案数。根据上述dp数组含义,说明这是要累加算方案数的。
1)不用第i组的花就可以满足j盆花的要求
2)用第i组的花才能满足j盆花的要求
可能用一朵花,也可能两朵花,还可能n朵花……
因为组已经分好了,所以直接从第一组开始遍历,在最外层的循环。然后就是遍历j,也就是从0~4遍历花盆,最后在最里面的循环是遍历每一组的花,因为每一组的花是一样的,所以遍历的是每一组的花的数量,就像上面分析的。有多少朵花就遍历多少次,但不能超出j的最大值。
最后的递推公式是累加,因为所有符合题意的dp数组都属于方案数。这就是为什么不是把dp数组作为标志变量最后用另一个变量累加的原因,因为所有的dp数组都是符合题意的。
为什么在砝码称重问题中dp数组作为标志变量,有的成立,有的不成立呢?
因为dp数组含义决定这个问题。要求的是可以称出的重量,遍历的是所有可能达到的重量,但有些重量不一定达到,所以不能直接累加,而是将dp数组作为标志变量,i那样摆放是否可以达到称出j的作用,然后最后才计算累加。
为什么上述题目可以直接累加呢?
因为dp数组一定成立,所有计算出的dp[i][j]都是成立的方案数。主要是由dp数组的含义决定,表示的就是方案数。而且初始化保证了基础成立,状态转移方程都是根据成立的初始化来的,所以肯定是成立的方案数。
例题三:从栈中取出k个硬币的最大面值和
主要看解题思路。很巧妙。
一张桌子上总共有 n 个硬币 栈 。每个栈有 正整数 个带面值的硬币。
每一次操作中,你可以从任意一个栈的 顶部 取出 1 个硬币,从栈中移除它,并放入你的钱包里。
给你一个列表 piles ,其中 piles[i] 是一个整数数组,分别表示第 i 个栈里 从顶到底 的硬币面值。同时给你一个正整数 k ,请你返回在 恰好 进行 k 次操作的前提下,你钱包里硬币面值之和 最大为多少 。
示例 1:
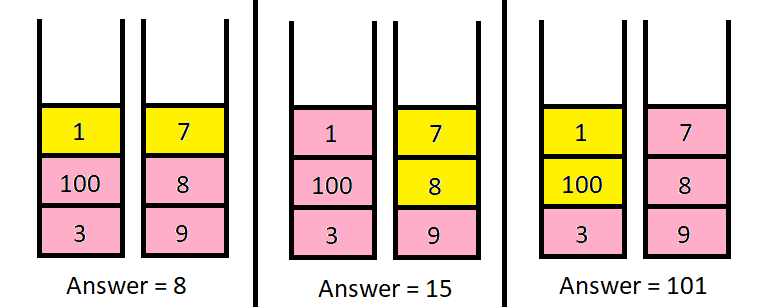
输入:piles = [[1,100,3],[7,8,9]], k = 2
输出:101
解释:
上图展示了几种选择 k 个硬币的不同方法。
我们可以得到的最大面值为 101 。
示例 2:
输入:piles = [[100],[100],[100],[100],[100],[100],[1,1,1,1,1,1,700]], k = 7
输出:706
解释:
如果我们所有硬币都从最后一个栈中取,可以得到最大面值和。
提示:
- n == piles.length
- 1 <= n <= 1000
- 1 <= piles[i][j] <= 105
- 1 <= k <= sum(piles[i].length) <= 2000
主要解决的是怎么转化成分组背包的类型:
第一组:
- 进行一次操作,取走1,面值为1
- 进行两次操作,取走1和100,面值为101
- 进行三次操作,取走1,100和3,面值为104
也就是可以将上述分成类似分组背包中的第一个组有三个物品。
第二组:
- 进行一次操作,取走7,面值为7
- 进行两次操作,取走7和8,面值为15
- 进行三次操作,取走7,8和9,面值为24
第二个组也有三个物品。
按上述就可以将上述问题转化成分组背包问题。
代码实现:一维数组
#include <stdio.h>
#include <string.h>
#include <stdlib.h>
#define MAX(a, b) ((a) > (b) ? (a) : (b))
// 计算每个栈取不同数量硬币时的最大价值
int* getStackValues(int* pile, int pileSize, int k) {//只是将每个组的几种情况计算出来
int* values = (int*)calloc(k + 1, sizeof(int));
int sum = 0;
// 取 t 个硬币的价值就是前 t 个硬币的和
for (int t = 1; t <= pileSize && t <= k; t++) {
sum += pile[t – 1]; // pile[0]是栈顶
values[t] = sum;//这种将和赋值给数组每个元素的方法要会
}
return values;
}
int maxValueOfCoins(int** piles, int pilesSize, int* pilesColSize, int k) {
// dp[j] 表示恰好取 j 个硬币时的最大面值和
int* dp = (int*)calloc(k + 1, sizeof(int));
// 遍历每个栈(每个组)
for (int i = 0; i < pilesSize; i++) {
// 获取当前栈取不同数量硬币的价值
int* values = getStackValues(piles[i], pilesColSize[i], k);
// 逆序更新dp,保证每个栈只取一次
for (int j = k; j >= 0; j–) {
// 尝试从当前栈取 t 个硬币
for (int t = 1; t <= pilesColSize[i] && t <= j; t++) {
dp[j] = MAX(dp[j], dp[j – t] + values[t]);
}
}
free(values);
}
int result = dp[k];
free(dp);
return result;
}
二维数组:
#include <stdio.h>
#include <string.h>
#include <stdlib.h>
#define MAX(a, b) ((a) > (b) ? (a) : (b))
int maxValueOfCoins(int** piles, int pilesSize, int* pilesColSize, int k) {
// dp[i][j] 表示从前i个栈中恰好取j个硬币时的最大面值和
int** dp = (int**)malloc((pilesSize + 1) * sizeof(int*));
for (int i = 0; i <= pilesSize; i++) {
dp[i] = (int*)calloc(k + 1, sizeof(int));
}//将数组全初始化为0
// 遍历每个栈
for (int i = 1; i <= pilesSize; i++) {
int pileIndex = i – 1; // 当前栈在piles中的索引
int pileSize = pilesColSize[pileIndex];
// 先复制不取当前栈的情况
for (int j = 0; j <= k; j++) {
dp[i][j] = dp[i – 1][j];
}
// 计算当前栈的前缀和,表示取t个硬币的总价值
int sum = 0;
// 尝试从当前栈取t个硬币
for (int t = 1; t <= pileSize && t <= k; t++) {
sum += piles[pileIndex][t – 1]; // piles[pileIndex][0]是栈顶
// 从当前栈取t个,那么前面i-1个栈取j-t个
for (int j = t; j <= k; j++) {
dp[i][j] = MAX(dp[i][j], dp[i – 1][j – t] + sum);
}
}
}
int result = dp[pilesSize][k];
// 释放内存
for (int i = 0; i <= pilesSize; i++) {
free(dp[i]);
}
free(dp);
return result;
}
解析上述代码:
1.// dp[i][j] 表示从前i个栈中恰好取j个硬币时的最大面值和
int** dp = (int**)malloc((pilesSize + 1) * sizeof(int*));
for (int i = 0; i <= pilesSize; i++) {
dp[i] = (int*)calloc(k + 1, sizeof(int));
}
// 第一步:分配指针数组(第一维)
int** dp = (int**)malloc((pilesSize + 1) * sizeof(int*));
// 此时:
// dp[0] 是未初始化的指针(指向垃圾值)
// dp[1] 是未初始化的指针
// …
// dp[pilesSize] 是未初始化的指针
// 第二步:为每一行分配实际数据空间(第二维)
for (int i = 0; i <= pilesSize; i++) {
dp[i] = (int*)calloc(k + 1, sizeof(int));
}
// 此时:
// dp[0] 指向一个大小为 k+1 的int数组
// dp[1] 指向另一个大小为 k+1 的int数组
// …
第一步后:
dp → [ptr0][ptr1][ptr2]…[ptr_pilesSize] (每个ptr都是未初始化的)
↓ ↓ ↓ ↓
? ? ? ? (指向哪里?不知道!)
第二步后:
dp → [ptr0][ptr1][ptr2]…[ptr_pilesSize]
↓ ↓ ↓ ↓
[0,0,0] [0,0,0] [0,0,0] … [0,0,0] (现在都指向合法的数组)
2.上述代码中主要有一个不一样的点是:
将在该栈中不取硬币的情况单独放到一个循环中,先算完该栈中不取任何硬币的面值,然后再开始循环,计算从栈中取一个,两个……的情况,取两个就是进行加和,将和作为一个物品进行计算面值。但也可以将不取的情况和取的情况放在一起,只是循环条件发生变化。
注意这个地方最容易因题而异!!!





评论前必须登录!
注册