 网硕互联帮助中心
网硕互联帮助中心TF-IDF —— 给单词发放“重要性准考证”
在词袋模型中,像“的”、“在”、“是”这种高频词会占据极高的数值,甚至掩盖掉真正的关键词(如“半导体”、“量化”)。TF-IDF 的核心逻辑是:如果一个词在当前文档出现很多次,但在其他文档里很少见,那它才是这篇文档的灵魂。
1. 公式拆解:两股力量的制衡
TF-IDF 由两部分乘积组成:
- TF (Term Frequency, 词频):
含义:这个词在这一篇里火不火?
- IDF (Inverse Document Frequency, 逆文档频率):
含义:这个词在整个图书馆里是不是“烂大街”的货色?
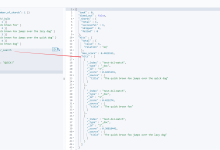
2. Python 实战:从“计数”转向“加权”
我们直接使用 Scikit-learn 里的 TfidfVectorizer。它比之前的 CountVectorizer 多了一步自动计算权重的过程。
from sklearn.feature_extraction.text import TfidfVectorizer
import pandas as pd
import jieba
# 1. 模拟语料库:两篇关于科技,一篇关于生活
corpus = [
"人工智能 改变 了 医疗 行业",
"人工智能 算法 是 科技 的 核心",
"今天 的 晚餐 味道 真的 很不错"
]
# 2. 初始化 TF-IDF 模型
# stop_words: 停用词过滤(这里手动演示,生产环境建议加载外部词表)
vectorizer = TfidfVectorizer(stop_words=['了', '是', '的'])
# 3. 计算并转换
tfidf_matrix = vectorizer.fit_transform(corpus)
# 4. 提取特征词
feature_names = vectorizer.get_feature_names_out()
# 5. 转化为 DataFrame 查看
df_tfidf = pd.DataFrame(tfidf_matrix.toarray(), columns=feature_names)
print("TF-IDF 权重矩阵(部分数据):")
print(df_tfidf.round(3))
3. 结果解读:为什么它比 BoW 强?
观察上面的矩阵你会发现:
- “人工智能”:虽然在两篇文档里都出现了,但因为它在库中比较常见,所以它的权重会被 IDF 适当拉低。
- “医疗”:只在第一篇出现,它的 IDF 值很高。在第一篇文档的向量中,它的数值会非常突出。
- 区分度:通过 TF-IDF,文档 1 和文档 2 的重心被放在了“医疗”和“算法”上,而不是无意义的“的”或“是”。
4. 关键参数设置(避坑指南)
在实际做 Text as Data 研究时,你通常需要调整这几个开关:
| max_df | 设为 0.8 | 过滤掉在 80% 以上文档都出现的“太常见词”。 |
| min_df | 设为 2 | 过滤掉只出现过 1 次的“孤僻词”(可能是错别字)。 |
| use_idf | 默认 True | 如果关掉,它就退化成了带归一化的词袋模型。 |
| norm | 默认 'l2' | 将向量长度归一化为 1,防止长文章天然比短文章得分高。 |
5. 这个主题的“天花板”在哪里?
TF-IDF 依然是基于字面匹配的。如果你搜“番茄”,它绝对找不到包含“西红柿”但不包含“番茄”的文章。它懂统计,但依然不懂语义。




评论前必须登录!
注册