 网硕互联帮助中心
网硕互联帮助中心大家读完觉得 有帮助记得关注和点赞!!!
摘要
多视角相机系统能够对复杂的现实世界场景进行丰富的观测,理解多视角设置下的动态物体已成为各种应用的核心。在这项工作中,我们提出了 MV-TAP,一种新颖的点跟踪器,它通过利用跨视角信息来跟踪动态场景多视角视频中的点。MV-TAP 利用相机几何和跨视角注意力机制来聚合跨视角的时空信息,从而在多视角视频中实现更完整和可靠的轨迹估计。为支持此任务,我们构建了一个大规模合成训练数据集和专为多视角跟踪定制的真实世界评估集。大量实验表明,MV-TAP 在具有挑战性的基准测试中优于现有的点跟踪方法,为推进多视角点跟踪研究建立了一个有效的基线。
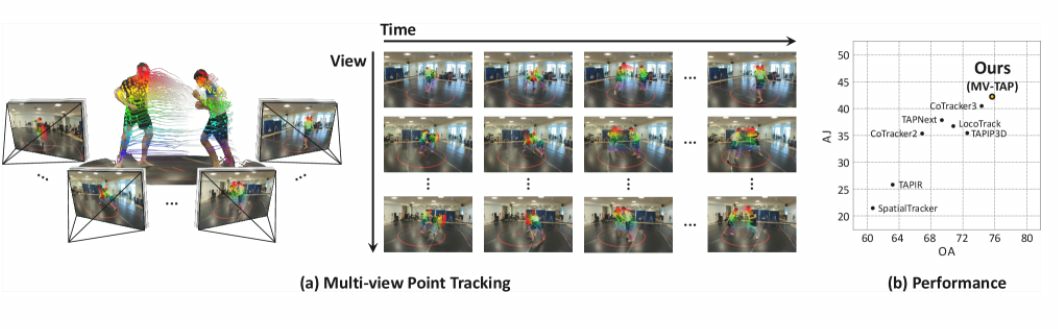
图 1: 我们提出了 MV-TAP(多视角视频中的任意点跟踪),这是一个旨在有效整合多个视角信息以实现鲁棒、高质量点跟踪的模型。(a) 我们在 Harmony4D [khirodkar2024harmony4d] 上可视化 MV-TAP 的结果。(b) MV-TAP 相较于其他基线方法 [doersch2023tapir, karaev2024cotracker, karaev2024cotracker3, cho2024local, zholus2025tapnext, xiao2024spatialtracker, zhang2025tapip3d] 取得了显著提升,展示了其利用多视角信息的能力。
1 引言
近年来,多视角相机系统取得了显著进展,使得理解复杂的现实世界场景成为可能。基于这些进展,理解多视角系统中的动态物体对于动作捕捉 [joo2015panoptic, chatzitofis2020human4d, ghorbani2020movi, khirodkar2024harmony4d]、机器人操作 [zhao2023learning, james2020rlbench, seo2023multi] 和自动驾驶 [li2025nugrounding, caesar2020nuscenes] 等广泛应用变得至关重要。
点跟踪通过提供跨视频帧的细粒度时空对应关系并指示逐点遮挡 [harley2022particle, doersch2022tap, karaev2024cotracker3, cho2024local],已被广泛用于理解动态场景。因此,它支持广泛的下游任务,包括具身智能 [vecerik2024robotap, bharadhwaj2024track2act]、自动驾驶 [balasingam2024drivetrack]、4D 重建 [wang2024shape, st4rtrack2025] 和视频编辑 [geng2025motion, jeong2025track4gen]。尽管功能强大,现有的点跟踪方法仅在单视角视频中进行了探索。由于 3D 场景的 2D 投影本身会带来几何模糊性,例如频繁遮挡、不规则运动和深度不确定性,单视角方法 [harley2022particle, doersch2022tap] 难以应对这些挑战。因此,将这些跟踪器直接独立应用于每个视角无法利用构建可靠多视角点轨迹所需的多视角线索。
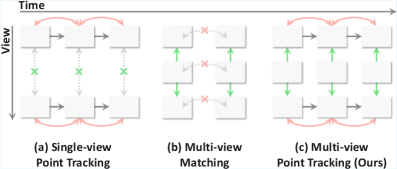
图 2: 动机。我们在概念上对比了我们的 (c) 多视角点跟踪与 (a) 单视角点跟踪 以及 (b) 多视角匹配。我们的方法同时建模视角内和帧间交互,以确保跨视角和时间一致性。
受这些观察的启发,我们提出了多视角点跟踪这一新任务,其目标是在动态场景的多个视频中跟踪一组查询点。我们的关键直觉是,联合处理动态场景的多个视频流可以提供有用的时空约束,有助于解决单视角设置带来的模糊性。例如,在一个视角中被遮挡或运动模糊的点,在其他视角中可能清晰可见。通过同时跨这些视角进行推理,可以解决此类模糊性,从而实现更鲁棒和准确的点跟踪。
虽然多视角对应关系已被研究为一种有前景的方法 [lowe2004distinctive, rublee2011orb, detone2018superpoint, sarlin2020superglue, sun2021loftr] 来捕捉几何关系,但这些方法通常不适合动态点跟踪。它们通常侧重于静态场景 [schonberger2016structure]、假设刚体几何或需要几何先验 [zhang2025tapip3d],而这些在随意的、野外视频中是不可用的。
尽管先前的一种方法 [rajivc2025multi] 旨在 3D 世界坐标系中进行多视角 3D 点跟踪,但它依赖于外部深度输入,这可能在将 3D 点重投影到 2D 像素空间时引入重投影误差。这在方法论上留下了一个关键空白:目前尚无成熟的范式来仅利用多视角视频在像素空间中跟踪动态场景中的点。
为应对这些挑战,我们提出了 MV-TAP(多视角视频中的任意点跟踪),它构建了对多视角视频中动态场景的整体理解。我们的框架利用相机编码和跨视角注意力机制来有效聚合所有视角和时间步的信息。此外,为促进该方向的研究,我们构建了一个专为训练多视角点跟踪模型而设计的大规模合成数据集,并提出了一个评估基准来评估跨不同多场景设置的泛化性和鲁棒性。在多视角基准测试上的实验表明,我们的方法相较于现有跟踪方法有显著改进,产生了更完整和准确的预测。我们的代码和数据集将公开提供。
我们的贡献总结如下:
• 我们首次定义了像素空间中的多视角点跟踪任务,旨在为多视角动态视频建立鲁棒的时空对应关系。
• 我们提出了 MV-TAP,一个利用相机几何和跨视角信息来解决单视角点跟踪固有局限性(如遮挡和运动模糊性)的框架。
• 我们通过大量实验证明,我们的方法实现了有竞争力的性能,为这一新任务提供了有效的基线。
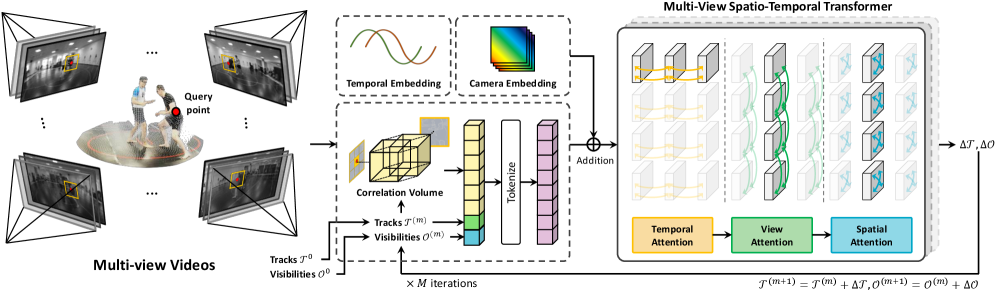
图 3: MV-TAP 的整体架构。给定同步的多视角视频,从 CNN 编码器特征中为每个查询点提取每视角相关体积。然后,将这些相关性进行标记化,并与相机嵌入(用于跨视角的相对几何上下文)和时间嵌入相加。轨迹和遮挡状态通过一个 Transformer 架构进行迭代更新,该架构包含时间、空间和视角注意力模块。
2 相关工作
点跟踪。 点跟踪的目标是预测给定查询点在视频内的轨迹和可见性。最近的方法 侧重于通过跨帧查找对应关系并捕捉时间上下文来估计轨迹。具体来说,PIPs [harley2022particle] 提出使用局部相关体积对初始查询点进行迭代优化。 将此思想与 TAP-Net [koppula2024tapvid] 引入的全局相关方法相结合。LocoTrack [cho2024local] 进一步引入了双向局部 4D 相关体积以增强局部对应性。值得注意的是, 通过交错帧间和轨迹间注意力模块来学习跟踪点之间的相关性。这种方法通过显式学习跟踪点之间的相关性以及时间一致性,实现了卓越的性能。与先前方法不同,SpatialTracker [xiao2024spatialtracker] 通过结合 2D 跟踪器和深度估计来执行 3D 点跟踪。TAPNext [zholus2025tapnext] 将点跟踪问题重新定义为自回归的下一个标记预测,实现了无需特殊归纳偏置的因果在线跟踪。尽管有这些进展,现有方法主要设计用于单目视频,其在多视角场景中的应用仍未得到充分探索。
与我们工作最相关的是 MVTracker [rajivc2025multi],它在 3D 空间中跨多视角同步视频跟踪查询点。然而,该方法高度依赖于预计算深度的质量以提升到 3D 空间。与 MVTracker 不同,MV-TAP 直接在 2D 像素空间中运行,并带有视角注意力模块,显示出改进的鲁棒性。
多视角点匹配。 多视角点匹配旨在识别从多个视角捕获的图像中一组查询点的对应关系。传统方法使用手工设计的局部特征(如 SIFT [lowe2004distinctive] 和 ORB [rublee2011orb])执行成对匹配。最近的工作采用基于学习的方法,例如自监督检测器-描述子 [detone2018superpoint]、基于图的匹配器 [sarlin2020superglue] 和无检测器的变换器匹配器 [sun2021loftr]。这些方法可以与单视角跟踪器结合,通过匹配来自参考视角的跨视角轨迹来扩展到多视角设置。然而,这种简单的组合忽略了每个视角内的时间一致性,并且由于冗余的逐帧匹配而效率低下。
3 方法
3.1 动机与概述
现有的点跟踪方法 主要侧重于在单视角视频中实现时空一致性。虽然这些方法擅长预测时间一致的轨迹,但它们并非设计用于利用多视角系统中可用的几何约束和互补信息。
在本文中,我们在 2D 相机空间中定义多视角点跟踪。我们的目标是利用多视角信息来增强跟踪性能,同时保持 2D 跟踪器建立的强时空一致性。为实现此目标,我们提出了 MV-TAP(多视角视频中的任意点跟踪),这是一个旨在有效整合多个视角信息的模型。我们的方法将强大的 2D 跟踪主干 [karaev2024cotracker3] 与设计用于利用多视角信息的附加模块相结合。具体来说,我们引入了一个相机编码模块来注入几何信息,以及一个跨视角注意力模块来聚合跨视角的互补线索。这种组合使我们的模型能够在多个视角上实现鲁棒的时空一致性。
首先,我们形式化像素空间中的多视角点跟踪(第 3.2 节)。然后,我们描述我们构建的相机感知表示(第 3.4 节),接着是多视角时空变换器(第 3.5 节),它通过视角注意力有效利用多视角线索。最后,我们解释我们的训练策略(第 3.7 节)。我们架构的概述如图 3 所示。
3.2 问题定义
多视角点跟踪的输入是多视角帧 ℐ = {I_v,t ∈ ℝ^(H×W×3)}、查询点 𝒬 = {q_v,n ∈ ℝ³} 和相机参数 𝒢 = {G_v,t = K [R_v,t | t_v,t]},其中 K ∈ ℝ^(3×3) 表示跨视角共享的内参矩阵,R_v,t ∈ SO(3) 和 t_v,t ∈ ℝ³ 表示旋转和平移参数。此处,v = 1, …, V 表示相机视角的索引,t = 1, …, T 指帧索引,n = 1, …, N 表示查询点的索引。我们假设来自不同视角的视频在时间上是同步的。一组 N 个查询点是为每个视角独立定义的,因为可见的时间步长因视角而异。尽管是独立定义的,跨视角的查询点代表相同的场景点,其中视角 v 上的每个查询点由一个 3 维向量 q_v = (t_q, x_q, y_q) 表示。具体来说,t_q 表示查询的帧索引,(x_q, y_q) 表示该帧中的空间坐标。此任务的目标是预测一组轨迹 𝒯 ∈ ℝ^(V×T×N×2) 和遮挡状态 𝒪 ∈ ℝ^(V×T×N×1),其中 𝒯 表示 N 个点在 T 个时间步长和 V 个视角上的 2D 像素位置,𝒪 指示每个点在跨视角和时间上是否可见或被遮挡。

图 4: 定性比较。我们在 DexYCB [chao2021dexycb] 和 Panoptic Studio [joo2015panoptic] 数据集上可视化 MV-TAP 和单视角基线 [karaev2024cotracker3] 的结果。虽然单视角基线在遮挡和大运动下失败,导致高度碎片化的轨迹,但 MV-TAP 显示出卓越的鲁棒性,在具有挑战性的场景中保持一致的轨迹。
3.3 沿时间轴的局部 4D 相关性
从初始或中间轨迹出发,我们计算一个成本体积作为匹配表示。中间轨迹在此过程中被优化。遵循最近的单视角点跟踪方法 [cho2024local, karaev2024cotracker3],我们采用局部 4D 相关性来利用丰富的外观线索。形式上,给定一个初始或中间轨迹假设 𝒯⁰,我们定义查询点 q = (t_q, x_q, y_q) 及其假设匹配点 p = (t_p, x_p, y_p) 周围的局部相关性。我们分别在空间半径 r_p 和 r_q 内构建 p 和 q 周围的局部邻域。得到的局部 4D 相关张量定义为:
ℒ_t(i, j; p, q) = (F_t(i) · F_t_q(j)) / (‖F_t(i)‖₂ ‖F_t_q(j)‖₂), (1)
其中 F_t 和 F_t_q 分别来自帧 t 和查询帧 t_q 的特征图,且 i ∈ 𝒩(p, r_p) 和 j ∈ 𝒩(q, r_q)。局部 4D 相关张量捕捉了 p 和 q 周围两个邻域之间的成对相似性。
请注意,相关体积也可以在视角维度上构建。然而,当视角之间的基线较大时,相应局部块之间的外观相似性会显著降低。因此,相关性变得不可靠,并可能向模型引入噪声。所以,我们仅沿时间维度计算相关性。
在每个时间步,相关性 ℒ_t 和当前假设位置被编码为一个标记。跨帧和查询点堆叠标记形成输入标记 X ∈ ℝ^(V×T×N×d)。
表 1: 定量比较。我们在 DexYCB [chao2021dexycb]、Panoptic Studio [joo2015panoptic]、Kubric [greff2022kubric] 和 Harmony4D [khirodkar2024harmony4d] 数据集上提供了单视角和多视角点跟踪器的定量比较。"Target"表示预测轨迹的维度。"Space"指定坐标域:"Camera"和"World"分别表示像素空间和世界空间。"Depth"指示是否需要深度输入。与基线相比,MV-TAP 实现了更优的性能,展示了其利用多视角信息的能力。
|
|
|
|
|
AJ |
<δ_avg> |
OA |
AJ |
|
单视角输入 |
|
|
|
|
|
|
|
|
TAPIR [doersch2023tapir] |
2D |
Camera |
✗ |
29.6 |
43.9 |
66.4 |
22.1 |
|
CoTracker2 [karaev2024cotracker] |
2D |
Camera |
✗ |
37.5 |
62.5 |
69.4 |
33.3 |
|
LocoTrack [cho2024local] |
2D |
Camera |
✗ |
38.7 |
55.8 |
74.1 |
34.9 |
|
CoTracker3 [karaev2024cotracker3] |
2D |
Camera |
✗ |
41.5 |
59.6 |
76.4 |
39.6 |
|
TAPNext [zholus2025tapnext] |
2D |
Camera |
✗ |
39.6 |
57.7 |
71.9 |
36.2 |
|
SpatialTracker [xiao2024spatialtracker] |
3D |
Camera |
✓ |
23.2 |
43.3 |
61.8 |
19.7 |
|
TAPIP3D [zhang2025tapip3d] |
3D |
World |
✓ |
29.1 |
43.4 |
66.1 |
41.9 |
|
多视角输入 |
|
|
|
|
|
|
|
|
CoTracker3 w/ Flat. |
2D |
Camera |
✗ |
2.7 |
7.1 |
35.7 |
1.0 |
|
CoTracker3 w/ Tri. |
2D |
Camera |
✗ |
39.2 |
57.1 |
76.4 |
37.9 |
|
MVTracker [rajivc2025multi] |
3D |
World |
✓ |
– |
32.6 |
– |
– |
|
MV-TAP |
2D |
Camera |
✗ |
44.2 |
61.9 |
78.3 |
40.3 |
3.4 视角感知的相机编码
在本节中,我们描述我们的视角感知相机参数嵌入。由于相机参数编码了 3D 空间信息,我们利用它们为模型提供跨视角跟踪点的相对几何上下文。具体来说,我们利用普吕克坐标 [plucker1828analytisch] 来编码与每个跟踪点对应的射线。每条射线 r_v,t,n ∈ ℝ⁶ 由普吕克坐标定义:
r = [d; m], 其中 m = o × d, (2)
其中 d ∈ ℝ³ 是射线的方向,m ∈ ℝ³ 表示矩向量,计算为射线方向 d 和射线原点 o ∈ ℝ³ 的叉积。特定像素的射线方向 d 和射线原点 o 计算如下:
d = Rᵀ K⁻¹ x, o = -Rᵀ t, (3)
其中 x = (u, v, 1)ᵀ 表示齐次像素坐标。方向 d 被归一化为单位长度以确保尺度不变表示。基于此定义,我们为所有轨迹构建普吕克坐标 ℛ ∈ ℝ^(V×T×N×6),并通过一个 MLP 层将其投影到一个特征维度。得到的嵌入随后与正弦位置编码 [vaswani2017attention] 一起添加到输入标记中。这种相机编码策略为模型提供了对多视角相机几何的显式感知,使其能够捕捉跨不同视角的空间对应关系。
3.5 多视角时空变换器
编码后的标记由一个变换器处理,该变换器交错应用时间注意力、空间注意力和视角注意力。当沿不同轴应用注意力时,特征维度 d 始终保留,而其他轴被展平到批次维度中,以便沿所选轴进行注意力计算。
时间注意力。 时间注意力沿时间轴 T 聚合信息。形式上,对于固定点,给定查询、键和值投影 Q_T, K_T, V_T ∈ ℝ^(T×d),
𝙰𝚝𝚝𝚗_temp(X) = 𝚂𝚘𝚏𝚝𝚖𝚊𝚡( (Q_T K_Tᵀ) / √d ) V_T, (4)
它整合了帧序列中的证据,确保时间上平滑的轨迹更新。
空间注意力。 空间注意力在单个帧内沿点轴 N 聚合信息。形式上,对于固定时间步,给定投影 Q_N, K_N, V_N ∈ ℝ^(N×d),
𝙰𝚝𝚝𝚗_spatial(X) = 𝚂𝚘𝚏𝚝𝚖𝚊𝚡( (Q_N K_Nᵀ) / √d ) V_N, (5)
它通过链接具有一致运动模式的点来帮助捕捉刚性先验。
表 2: 不同视角数量的消融研究。我们将 MV-TAP 与使用不同数量输入视角的基线进行比较。虽然性能通常随着视角数量的增加而提高,但基线方法仅显示出边际增益。相比之下,MV-TAP 始终显示出显著更大的改进,突显了其利用多视角信息的卓越能力。
|
|
AJ |
<δ_avg> |
OA |
AJ |
|
CoTracker3 |
37.5 |
56.4 |
77.8 |
38.9 |
|
CoTracker3 w/ Flat. |
9.5 |
19.5 |
54.3 |
4.4 |
|
CoTracker3 w/ Tri. |
37.1 |
55.6 |
77.8 |
37.8 |
|
MVTracker |
– |
35.8 |
– |
– |
|
MV-TAP |
39.2 |
56.8 |
76.8 |
40.3 |
表 3: 多视角信息能否解决遮挡模糊性?我们还评估了帧内被遮挡点的位置精度。我们的模型在遮挡上显示出鲁棒性,表明我们的模型有效地利用了多视角线索。<δ_occ> 表示帧内遮挡点上的点精度。
|
|
<δ_avg> |
<δ_occ> |
<δ_avg> |
|
CoTracker3 |
59.6 |
33.9 |
61.4 |
|
CoTracker3 w/ Flat. |
7.1 |
1.9 |
12.7 |
|
CoTracker3 w/ Tri. |
57.1 |
34.8 |
59.5 |
|
MVTracker |
32.6 |
16.0 |
62.4 |
|
MV-TAP |
61.9 |
38.4 |
62.8 |
视角注意力。 虽然时间注意力和空间注意力捕捉了视角内关系(如时间平滑性和局部刚性),但它们在建模视角间关系方面存在固有局限性。为显式对齐不同视角的表示,我们沿视角轴 V 应用注意力。这里,Q_V, K_V, V_V ∈ ℝ^(V×d),
𝙰𝚝𝚝𝚗_view(X) = 𝚂𝚘𝚏𝚝𝚖𝚊𝚡( (Q_V K_Vᵀ) / √d ) V_V. (6)
此注意力模块允许模型在不同视点之间交换信息,从而克服依赖于视角的模糊性。
3.6 循环轨迹和遮挡更新
通过时间、空间和视角注意力,变换器迭代地优化点轨迹和遮挡概率。具体来说,在每个优化步骤,变换器预测轨迹位置和遮挡状态的增量更新:
Δ𝒯, Δ𝒪 = 𝚃𝚛𝚊𝚗𝚜𝚏𝚘𝚛𝚖𝚎𝚛(X). (7)
这些更新被应用到先前的估计中:
𝒯^(m+1) = 𝒯^(m) + Δ𝒯, 𝒪^(m+1) = 𝒪^(m) + Δ𝒪, (8)
使得经过 M 次优化步骤后,模型产生最终轨迹 𝒯 和遮挡状态 𝒪。
3.7 训练损失
为训练 MV-TAP,我们同时优化轨迹回归和遮挡预测。对于轨迹监督,我们使用 Huber 损失 [huber1992robust]:
ℒtrack(𝒯, 𝒯*) = ∑{m=1}^M γ^(M-m) ℓ_Huber(𝒯^(m), 𝒯*), (9)
其中 𝒯^(m) 是优化步骤 m 时的预测轨迹,𝒯* 是真实轨迹。
对于遮挡监督,我们使用二元交叉熵(BCE)损失。在计算损失之前,我们对遮挡逻辑值 𝒪^(m) 应用 sigmoid 激活:
ℒocc(𝒪, 𝒪*) = ∑{m=1}^M γ^(M-m) 𝙱𝙲𝙴(σ(𝒪^(m)), 𝒪*), (10)
其中 𝒪^(m) 是优化步骤 m 时的预测遮挡状态,𝒪* 是真实值。
4 实验
4.1 实验设置
训练。 由于现有的点跟踪训练数据集仅适用于单视角场景,我们利用 Kubric 生成引擎 [greff2022kubric] 生成了一个用于多视角点跟踪的合成数据集。我们生成的数据集包含 5,000 个场景的同步多视角视频,以及标注,包括点轨迹、相应的遮挡状态和相机参数(内参和外参)。我们在第 D 节提供更多细节。我们的模型在生成的多视角数据集上训练了 50K 步,使用 4 块 NVIDIA A6000 GPU,每块 GPU 的批次大小为 1。我们采用 AdamW 优化器 [loshchilov2017decoupled],学习率为 10⁻⁴,权重衰减为 10⁻⁴。我们使用带有 1,000 步预热阶段的余弦学习率调度器,并应用阈值为 1.0 的梯度裁剪以实现稳定收敛。由于 MV-TAP 基于 CoTracker3 [karaev2024cotracker3],我们采用预训练权重来初始化特征编码器和变换器层。在训练期间,我们仅冻结特征提取网络,同时更新所有其他参数。输入视角的数量在 1 到 4 之间随机选择。输入分辨率为 384×512,轨迹数量为 384。我们将优化迭代次数设置为 M=4,局部 4D 相关性的空间半径设置为 r_p = r_q = 3。
评估协议。 我们在 DexYCB 数据集 [chao2021dexycb]、Panoptic Studio 数据集 [joo2015panoptic]、Kubric 数据集 [greff2022kubric] 和 Harmony4D 数据集 [khirodkar2024harmony4d] 上评估我们的方法和基线。对于 DexYCB 和 Panoptic Studio,我们分别使用 [koppula2024tapvid] 和 [rajivc2025multi] 提供的点跟踪标注,而对于 Kubric 和 Harmony4D,我们使用生成引擎和基于人体网格恢复的标注流程 [kim2025learning] 构建点跟踪标注。在 DexYCB 的情况下,我们在手部和交互的物体上采样动态点,以专注于动态点跟踪评估。为确保一致的评估,我们在所有数据集下进行 8 视角设置的主要实验,其中在 DexYCB 和 Kubric 中使用所有 8 个可用视角,并从 Panoptic Studio 和 Harmony4D 中采样 8 个视角。对于视角采样,我们设计了三种采样策略:最近、随机和最远,这些策略基于相机之间的距离定义。
表 4: 额外训练的效果。虽然从相同的预训练模型初始化,但 MV-TAP 在所有指标上始终获得更高的性能。这表明其增益主要来自架构设计,而非仅仅是延长训练时间。
|
|
AJ |
<δ_avg> |
|
CoTracker3 |
41.8 |
59.0 |
|
MV-TAP |
44.2 |
61.9 |
在正文中,我们采用最远采样策略作为主要结果,而其他采样策略的结果在第 C 节提供。
表 5: 不同点数量的比较。我们测量了不同查询点数量下的跟踪性能。与基线相比,我们的模型在稀疏和密集设置下始终表现出更好的鲁棒性。
|
|
AJ |
<δ_avg> |
OA |
AJ |
|
CoTracker3 |
42.0 |
59.9 |
74.6 |
41.9 |
|
CoTracker3 w/ Flat. |
2.7 |
7.4 |
34.4 |
2.5 |
|
CoTracker3 w/ Tri. |
39.4 |
53.4 |
74.6 |
39.4 |
|
MVTracker |
– |
34.2 |
– |
– |
|
MV-TAP |
44.3 |
62.0 |
77.5 |
44.7 |
表 6: 模型架构消融研究。我们展示了模型组件在多视角感知方面的消融研究。随着每个组件的添加,性能持续提高,表明每个模块都对利用多视角信息有显著贡献。
|
|
AJ |
<δ_avg> |
|
CoTracker3 |
41.5 |
59.6 |
|
+ View attn. |
43.6 |
61.5 |
|
+ Cam embed. |
42.2 |
60.6 |
|
MV-TAP |
44.2 |
61.9 |
表 7: 频繁遮挡轨迹下的比较。我们评估了在具有高遮挡频率的轨迹上的方法,该频率通过可见性转换率衡量。MV-TAP 利用跨视角线索,在频繁遮挡的点上保持鲁棒,提高了 AJ、<δ_avg> 和 OA。
|
|
AJ |
<δ_avg> |
|
CoTracker3 |
26.2 |
43.4 |
|
CoTracker3 w/ Flat. |
0.5 |
1.8 |
|
CoTracker3 w/ Tri. |
26.0 |
43.6 |
|
MVTracker |
– |
7.9 |
|
MV-TAP |
29.7 |
47.3 |
我们使用来自 TAP-Vid [doersch2022tap] 的标准点跟踪指标,包括位置精度(<δ_avg>)、遮挡精度(OA)和平均杰卡德系数(AJ)。<δ_avg> 代表平均正确关键点百分比(PCK),用于评估预测关键点位置的准确性。具体来说,它通过对真实值中可见点在 1、2、4、8 和 16 像素误差阈值上的 PCK 取平均来计算。OA 表示遮挡二元预测的准确性。AJ 是一个综合得分,联合评估每个点的位置和遮挡预测。
基线。 我们将我们的方法与最近的最先进的点跟踪方法进行比较,包括单视角和多视角方法,涵盖 2D 和 3D 公式。我们采用 TAPIR [doersch2023tapir]、CoTracker2 [karaev2024cotracker]、LocoTrack [cho2024local]、CoTracker3 [karaev2024cotracker3]、TAPNext [zholus2025tapnext]、SpatialTracker [xiao2024spatialtracker] 和 TAPIP3D [zhang2025tapip3d] 作为单视角基线,MVTracker [rajivc2025multi] 作为多视角基线。特别是,SpatialTracker、TAPIP3D 和 MVTracker 需要深度图作为输入,我们在可用时提供真实深度图。否则,我们使用现成的深度估计器 [wang2024dust3r]。此外,MVTracker 的目标是在世界空间中进行 3D 跟踪,并预测跨所有视角的聚合可见性,因此无法提供每视角可见性。因此,我们通过将其世界空间轨迹投影到每个相机的像素空间来仅报告 MVTracker 的 <δ_avg>。对于为单目视频设置设计的单视角跟踪基线,我们在每个视角上独立执行跟踪,然后聚合每视角结果以计算与多视角方法进行公平比较的最终指标。
此外,我们还包括单视角跟踪器的一个朴素多视角扩展。该变体将视角和时间维度展平,允许跟踪器将多视角视频作为单个序列处理。我们使用 CoTracker3 实现了此扩展作为额外的多视角基线(CoTracker3 w/Flat.)。此外,为检验简单的几何线索是否能解决单目模糊性,我们利用提供的相机参数进行多视角几何处理。我们考虑两种方法:使用极线约束进行优化或三角测量。然而,基于极线的方法需要一个参考点来定义极线。由于参考点由于预测不准确性已经存在噪声,这会导致显著的误差传播。因此,我们在实验中排除了此方法。相反,我们采用基于三角测量的优化。对于每个时间步,我们根据单视角跟踪器的 2D 输出通过三角测量计算一个 3D 点,然后将其重投影到每个视角以优化 2D 轨迹。基于三角测量的方法也建立在 CoTracker3 之上,作为额外的多视角基线(CoTracker3 w/Tri.)。
4.2 主要结果
定量结果。 我们在 DexYCB [chao2021dexycb]、Panoptic Studio [joo2015panoptic]、Kubric [greff2022kubric] 和 Harmony4D [khirodkar2024harmony4d] 上将我们的方法与最近最先进的点跟踪器进行比较。如表 1 所示,MV-TAP 在所有基准测试中始终表现出强大的性能,取得了显著的成绩。虽然 TAPIP3D [zhang2025tapip3d] 和 TAPNext [zholus2025tapnext] 在少数指标上略优于我们的方法,但 TAPIP3D 依赖于真实深度,而 TAPNext 采用了基于 SSM 和 ViT 块的更重架构,这两种方法在特定基准测试上表现不佳。有鉴于此,MV-TAP 的性能表明了其强大的多视角点跟踪能力。
定性结果。 我们在图 4 中展示了定性比较,并在图 5 中展示了额外的定性结果。我们可视化了 DexYCB、Panoptic Studio 和 Harmony4D 上的结果。MV-TAP 对大运动和非刚性运动显示出卓越的鲁棒性,证明了多视角信息对于点跟踪的有效性。
4.3 消融研究与分析
虽然我们的主要比较包括了第 4.2 节描述的所有基线,但在以下的消融和分析实验中,我们选择了一个基线子集,以保持清晰度和计算效率。
不同视角数量的消融研究。 表 3.5 展示了 MV-TAP 与选定的基线子集在 DexYCB [chao2021dexycb] 数据集上的比较,评估了不同视角数量下的性能。尽管由于资源限制,MV-TAP 仅使用 1 到 4 个视角进行训练,但由于注意力机制,它可以处理任意数量的视角,甚至超过 4 个。MV-TAP 在各种视角设置下始终优于基线,并且指标性能随着视角数量的增加而稳步提高。这表明额外的视角为多视角跟踪提供了更丰富的空间信息。

图 5: MV-TAP 在不同数据集上获得的点轨迹可视化。我们在 DexYCB [chao2021dexycb]、Panoptic Studio [joo2015panoptic] 和 Harmony4D [khirodkar2024harmony4d] 数据集上展示了我们模型的预测结果。
多视角信息能否解决遮挡模糊性? 为研究多视角信息是否有助于解决遮挡模糊性,我们评估了特定遮挡点上的 <δ_avg>。在传统的点跟踪评估流程中,由于人工标注数据集 [doersch2022tap] 的限制,<δ_avg> 仅在可见点上测量,因为遮挡点难以标注。然而,自动标注的数据集 [chao2021dexycb, joo2015panoptic, greff2022kubric, khirodkar2024harmony4d] 即使对于仍留在帧内的被遮挡点也提供准确的坐标。因此,我们将遮挡分为帧内遮挡和帧外遮挡,并评估帧内被遮挡点的点精度。如表 3.5 所示,引入多视角信息有助于处理遮挡。基于三角测量的优化方法在帧内遮挡点上显示出强大的鲁棒性,因为显式利用相机几何有助于解决遮挡模糊性。然而,由于其依赖于单视角跟踪器的估计,其在可见点上的性能会下降。相比之下,MV-TAP 即使没有显式的几何优化,也通过利用多视角信息保持了有竞争力的稳定性。
额外训练的效果。 虽然 MV-TAP 是从预训练的 CoTracker3 [karaev2024cotracker3] 初始化的,但我们进一步分析了额外训练的效果。在表 4.1 中,MV-TAP 显示出相对于基线的明显性能改进。这一结果表明,MV-TAP 的性能增益并非简单地来自额外训练,而是得益于其精心设计的架构,该架构有效地利用了多视角信息来增强泛化性和鲁棒性。
不同查询点数量的比较。 下游应用 [vecerik2024robotap, bharadhwaj2024track2act, balasingam2024drivetrack, wang2024shape, st4rtrack2025, geng2025motion, jeong2025track4gen] 的需求各不相同,根据任务范围从稀疏到稠密的对应关系估计。为考虑这种多样性,我们评估了不同查询点数量下的跟踪性能。如表 4.1 所示,MV-TAP 总体上取得了比基线更高的结果,突显了其普遍适用性。
模型组件消融研究。 在表 4.1 中,我们展示了 MV-TAP 架构的消融研究。我们检查了单独应用相机嵌入和视角注意力以及组合应用的效果。这些结果表明,两个模块单独都能提高基线性能。值得注意的是,结合了视角注意力和相机嵌入的组合版本实现了最佳性能,证明了它们的互补效应。
频繁遮挡场景下的比较。 在表 4.1 中,我们专门在频繁遮挡的轨迹上评估 MV-TAP 与基线。对于此评估,我们量化了遮挡频率,其定义为每条轨迹的可见性状态转换次数。然后,我们通过选择具有最高遮挡频率的前 30% 轨迹来筛选高遮挡频率的轨迹。如前所述,由于缺乏跨视角信息,单视角点跟踪模型在频繁遮挡的轨迹上显示出有限的鲁棒性。相比之下,即使在频繁遮挡下,MV-TAP 也保持了强大而一致的性能,证明了我们精心设计的方法在利用多视角信息进行鲁棒点跟踪方面的有效性。
5 结论
本工作将多视角 2D 点跟踪确立为一项新的重要任务,用于推进动态、真实世界场景中可靠的时空对应关系。通过引入 MV-TAP(一个通过相机嵌入和视角注意力聚合跨视角信息的模型),我们展示了如何利用多视角输入来克服单目跟踪器的关键局限性,如遮挡和运动模糊性。结合专为此任务设计的大规模合成数据集和真实世界评估数据集,我们的贡献既提供了问题的原则性表述,也提供了强大的基线方法,为未来鲁棒多视角点跟踪的研究铺平了道路。



评论前必须登录!
注册