 网硕互联帮助中心
网硕互联帮助中心📌 所属章节:第三阶段 – LLM / ChatModel 大模型接口
← 上一篇:langchain-community 与厂商集成包 | 📚 系列目录 | 下一篇:Messages 与 Prompt 提示词模板 →
📋 摘要
本文详细讲解了 LLM / ChatModel 大模型接口,包括核心概念、实战代码示例和最佳实践。通过本文的学习,你将掌握 LangChain 1.0 的核心技术要点,能够快速构建基于大模型的 AI 应用。
适合人群:
- 想系统学习 LangChain 1.0 的开发者
- 需要构建 AI Agent 应用的工程师
- 对 LLM 应用开发感兴趣的技术爱好者
3.1 LLM / ChatModel 大模型接口
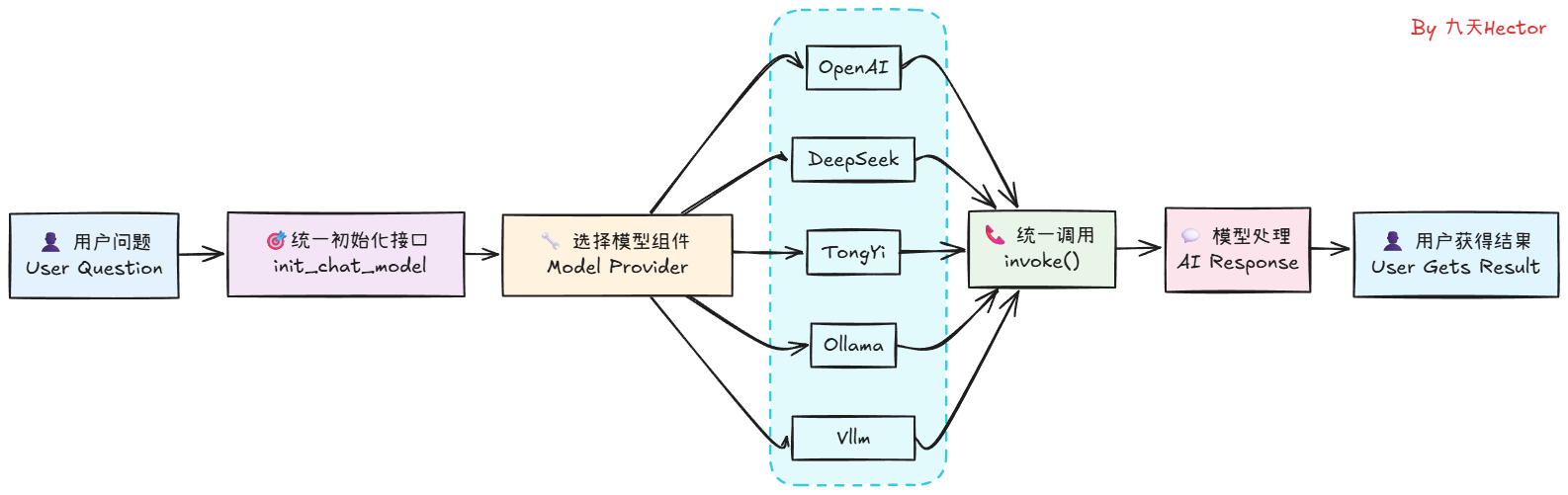
LangChain区分两种模型类型:
-
LLM:传统的文本进-文本出模型
-
ChatModel:基于消息的对话模型,更适合构建聊天机器人
-
封装具体的 LLM 提供者(OpenAI、Anthropic、local LLM),统一调用接口(sync/async、streaming)。
-
学习要点:如何配置 provider、温控、并发与 retry 策略。
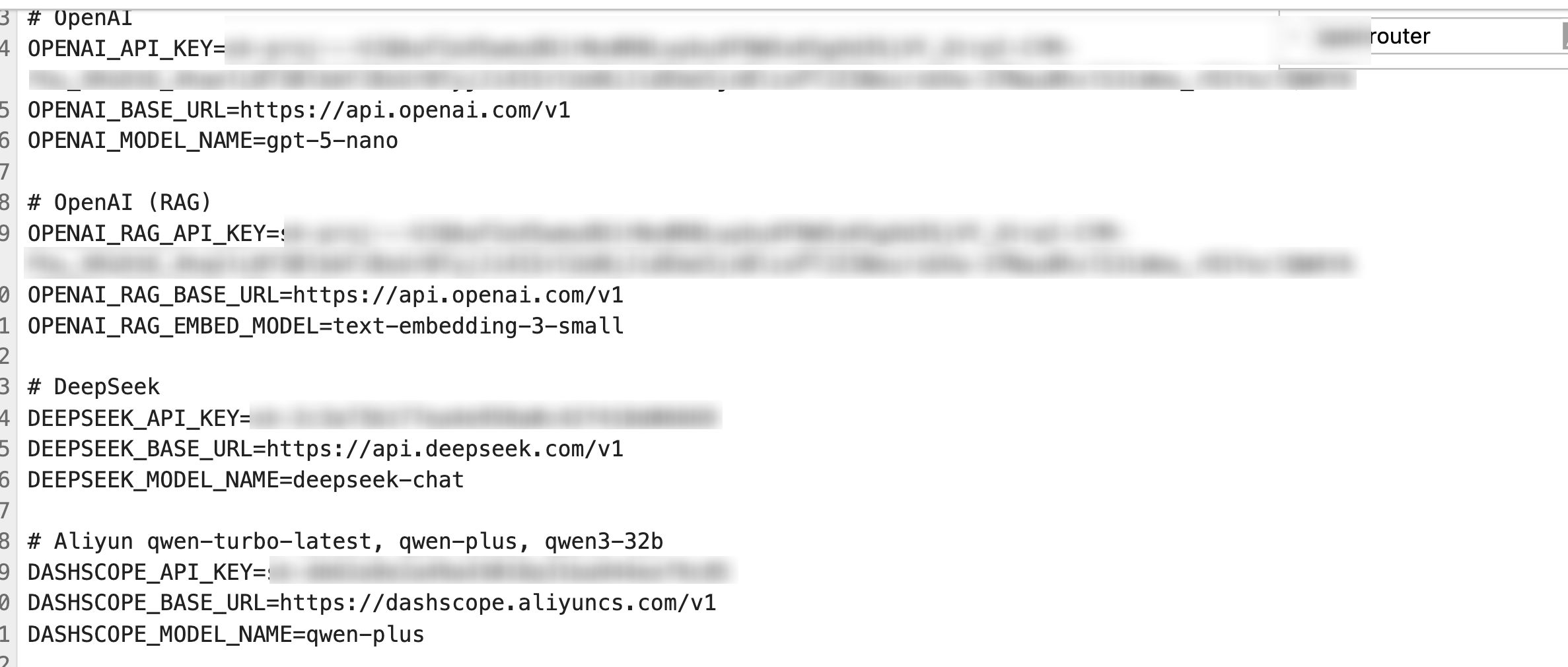
# 1 导入 os 与 dotenv
import os
from dotenv import load_dotenv
# 2 加载 .env 环境变量
load_dotenv(override=True)
# 3 读取密钥与地址
DeepSeek_API_KEY = os.getenv("DEEPSEEK_API_KEY")
DeepSeek_BASE_URL = os.getenv("DEEPSEEK_BASE_URL")
# 4 可选:打印密钥
print(DeepSeek_API_KEY) # 可以通过打印查看
输出结果:
sk-********************
1. DeepSeek
# !pip install openai
# 1 导入 OpenAI 客户端
from openai import OpenAI
# 2 初始化 DeepSeek API 客户端
client = OpenAI(api_key = "********************", base_url="https://api.deepseek.com")
# 3 创建对话消息并发起请求
response = client.chat.completions.create(
model="deepseek-chat",
[messages](06_messages_prompt.md)=[
{"role": "system", "content": "你是乐于助人的助手,请根据用户的问题给出回答"},
{"role": "user", "content": "你好,请你介绍一下你自己。"},
],
)
# 4 打印模型最终的响应结果
print(response.choices[0].message.content)
输出结果:
你好!我是DeepSeek,很高兴认识你!😊
我是由深度求索公司创造的AI助手,致力于为大家提供热情、贴心的帮助。我有以下几个特点:
🌟 **能力方面**:
– 纯文本模型,擅长理解和生成文字内容
– 支持文件上传功能,可以处理图像、txt、pdf、ppt、word、excel等文件,从中读取文字信息
– 拥有128K的上下文长度,能记住我们对话的详细内容
– 支持联网搜索功能(需要你在Web/App中手动开启)
💝 **服务理念**:
– 完全免费使用,没有任何收费计划
– 回复风格热情细腻,希望能给你温暖的交流体验
– 乐于助人,无论是学习、工作还是生活中的问题,我都会尽力帮忙
📱 **使用方式**:
– 可以通过官方应用商店下载App
– 也可以在网页端直接使用
我的知识截止到2024年7月,会尽我所能为你提供准确、有用的信息。有什么想了解的或需要帮助的吗?我很期待为你服务!✨
# !pip install langchain-deepseek
# 1 导入 ChatDeepSeek
from langchain_deepseek import ChatDeepSeek
# 2 初始化模型参数
model = ChatDeepSeek(
model="deepseek-chat",
temperature=0.0, # 温度参数,用于控制模型的随机性,值越小则随机性越小
max_tokens=512, # 最大生成token数
timeout=30, # 超时时间,单位秒
base_url=DeepSeek_BASE_URL # 默认为https://api.deepseek.com
)
# 3 定义问题
question = "你好,请你介绍一下你自己。"
# 4 调用模型
result = model.invoke(question)
# 5 输出结果
print(result.content)
输出结果:
你好!我是DeepSeek,很高兴认识你!😊
我是由深度求索公司创造的AI助手,致力于为大家提供热情、细腻的帮助。让我简单介绍一下自己的特点:
**我的能力:**
– 📝 **文本处理**:可以帮你写作、翻译、总结、分析等各种文字工作
– 📚 **知识问答**:涵盖科学、技术、人文、生活等各个领域
– 💡 **创意协助**:头脑风暴、策划方案、创意写作等
– 🔍 **信息处理**:可以读取你上传的文件(图像、PDF、Word、Excel、PPT等),从中提取文字信息进行分析
– 🌐 **联网搜索**:虽然需要你手动开启搜索功能,但我可以获取最新信息
**我的特色:**
– 🆓 **完全免费**:目前没有任何收费计划
– 💬 **上下文128K**:能记住我们对话的较长历史
– 📱 **多平台使用**:可通过网页版或官方App使用
– 📅 **知识更新**:我的知识截止到2024年7月
**我的风格:**
我喜欢用热情、细腻的方式与大家交流,力求提供准确、有用的帮助。无论是学习、工作还是生活中的问题,我都会认真对待,尽我所能为你提供支持!
有什么具体想了解的,或者需要我帮助的地方吗?我很乐意为你效劳!✨
2. DashScope
阿里云百炼API获取方式也非常简单,只需注册阿里云账号,然后前往我的API页面:https://bailian.console.aliyun.com/?tab=model#/api-key 进行充值和注册即可:
# !pip install dashscope
# !pip install langchain_community
from langchain_community.chat_models.tongyi import ChatTongyi
model = ChatTongyi(model="qwen-plus") # 默认qwen-turbo模型
question = "你好,请你介绍一下你自己。"
result = model.invoke(question)
print(result.content)
输出结果:
你好!😊 很高兴认识你!
我是通义千问(Qwen),由通义实验室研发的超大规模语言模型。我能够理解并生成多种语言的文本,比如中文、英文、法语、西班牙语、葡萄牙语、俄语、阿拉伯语、日语、韩语、越南语、泰语、印尼语等,支持广泛的国际交流。
我的能力包括但不限于:
🔹 回答问题:无论是常识、科学、历史、文化,还是日常生活中的小疑问,我都会尽力提供准确、易懂的解答;
🔹 创作文字:写故事、写公文、写邮件、写剧本、逻辑推理、编程,甚至模仿特定风格写作;
🔹 逻辑与数学:能进行多步推理、解决数学题或分析复杂问题;
🔹 多模态理解(在支持的版本中):部分版本还能理解图像内容(如描述图片、识别场景等);
🔹 对话理解:擅长多轮对话,能记住上下文,让交流更自然、连贯。
我注重事实准确性、价值观正向、尊重用户隐私,并持续学习和优化。不过我也坦诚说明:我无法实时联网获取最新信息(知识截止于2024年),也不能直接访问个人设备或外部数据库。
如果你有任何问题、需要帮助写作、想一起头脑风暴,或者只是聊聊天——我都非常乐意!🌟
那么,今天有什么我可以帮你的吗? 😊
3. OpenAI
# 1 导入 OpenAI
from langchain_openai import OpenAI
# 2 初始化模型
llm = OpenAI(model="gpt-4o-mini")
# 3 定义问题
question = "你好,请你介绍一下你自己。"
# 4 调用模型
result = llm.invoke(question)
# 5 打印结果
print(result)
# 1 导入 ChatOpenAI
from langchain_openai import ChatOpenAI
# 2 初始化模型
model = ChatOpenAI(model="gpt-4o-mini")
# 3 定义问题
question = "你好,请你介绍一下你自己。"
# 4 调用模型
result = model.invoke(question)
# 5 打印内容
print(result.content)
输出结果:
你好!我是一个人工智能助手,旨在帮助用户解答问题、提供信息和进行交流。我可以讨论各种主题,包括科学、历史、文化、技术等。如果你有什么具体的问题或需要了解的内容,请随时告诉我!
4. Ollama

#!pip install langchain-ollama
# 1 导入 OllamaLLM
from langchain_ollama import OllamaLLM
# 2 初始化本地模型
llm = OllamaLLM(model="deepseek-r1:8b")
# 3 定义问题
question = "你好,请你介绍一下你自己。"
# 4 调用模型
result = llm.invoke(question)
# 5 打印结果
print(result)
输出结果:
你好呀!👋我是 DeepSeek-R1,一个由深度求索公司开发的智能助手。你可以把我当作一个知识丰富、耐心细致、随时待命的聊天伙伴,不管你是想查资料、写文章、学知识、编程、翻译,还是只是想聊聊天,我都乐意帮忙!
我的特点包括:
🧠 **知识广泛**:截至2024年7月的知识我都知道,覆盖科技、历史、文学、生活、常识等等,什么都能聊!
📄 **处理文件能力强**:你可以上传 Word、Excel、PDF、PPT 等文件,我能帮你提取、总结、翻译甚至重写内容。
💡 **创造力高**:写故事、写诗、写剧本、写邮件、写简历、写代码,甚至帮你想点创业点子,我都擅长!
🤝 **耐心友好**:不管你说话是正式还是随意,我都会用最适合你的方式来回应。不会不耐烦,也不会啰嗦,只给你想要的答案!
而且,我现在是 **免费的**,你可以放心使用,有问题随时来问我哦!
那你想了解些什么呢?😊
# 1 导入 ChatOllama
from langchain_ollama import ChatOllama
# 2 初始化本地聊天模型
model = ChatOllama(model="deepseek-r1:8b")
# 3 定义问题
question = "你好,请你介绍一下你自己。"
# 4 调用模型
result = model.invoke(question)
# 5 打印内容
print(result.content)
输出结果:
您好!我是由中国的深度求索(DeepSeek)公司开发的智能助手DeepSeek-R1。如您有任何任何问题,我会尽我所能为您提供帮助。
5. Vllm
# 安装 vLLM(推荐用阿里云镜像加速)
#!pip install vllm -i https://mirrors.aliyun.com/pypi/simple/
# 连接本地vLLM服务
from langchain_openai import ChatOpenAI
# 连接到本地 vLLM 服务,配置长连接池,减少握手开销
model = ChatOpenAI(
model="qwen-32b-chat", # 指定使用的模型名称
base_url="http://localhost:8000/v1", # vLLM 的 OpenAI API 地址
api_key = "********************", # vLLM 不验证 key,可以随便写
max_retries=5, # 增加重试次数
timeout=120.0, # 超时时间设长
http_client={ # 自定义 HTTP 客户端
"limits": {
"max_connections": 100, # 最大连接数
"max_keepalive_connections": 20 # 最大保持活动连接数
}
}
)
6. init_chat_model()
# 使用init_chat_model初始化DeepSeek模型
from langchain.chat_models import init_chat_model
# 1. 初始化模型(自动识别供应商)
model = init_chat_model(
"deepseek-chat", # 指定DeepSeek的聊天模型
model_provider="deepseek", # 指定模型提供商为deepseek
)
# 一行代码切换模型,业务代码0改动
# model = init_chat_model("gpt-4o", model_provider="openai")
# model = init_chat_model("claude-3-5-sonnet", model_provider="anthropic")
question = "你好,请你介绍一下你自己。"
result = model.invoke(question)
print(result.content)
输出结果:
你好!我是DeepSeek,由深度求索公司创造的AI助手,很高兴认识你!😊
让我简单介绍一下自己:
**基本信息:**
– 我是一个纯文本AI模型,专注于理解和生成自然语言
– 知识截止到2024年7月,是DeepSeek的最新版本
– 拥有128K的上下文处理能力,可以处理较长的对话和文档
**我的能力:**
– 回答各种问题,进行深度对话
– 文件处理:支持上传图像、txt、pdf、ppt、word、excel文件,并读取其中的文字信息
– 联网搜索:虽然需要你在Web/App中手动点开联网搜索按键,但我可以获取最新信息
– 代码编写和问题解答
– 创意写作、翻译、分析等
**使用方式:**
– 完全免费使用,没有收费计划
– 可以通过官方应用商店下载App
– 目前是纯文本模型,不支持语音功能
我的回复风格比较热情细腻,希望能给你带来温暖和帮助。无论你有什么问题或需要什么协助,我都会尽我所能为你提供支持!
有什么特别想了解的,或者需要我帮助的吗?我很乐意为你服务!✨
其中:
-
model 代表具体模型名称(gpt-4o、claude-3-haiku、gemini-pro 等)
-
model_provider 代表模型来源(openai、anthropic、google)
| openai | OpenAI(GPT-4.1, GPT-4o, o3-mini 等) | OPENAI_API_KEY |
| anthropic | Anthropic(Claude 3 系列) | ANTHROPIC_API_KEY |
| Google(Gemini 系列) | GOOGLE_API_KEY | |
| cohere | Cohere(Command 系列) | COHERE_API_KEY |
| ollama | 本地模型(LLaMA、Qwen、Mistral 等) | 本地无需 API Key |
你可以让一个应用只换 provider,而不改逻辑:
RateLimit 模型速率限制器
# 1. 定义带速率限制的load_chat_model函数
from langchain.chat_models import init_chat_model
from langchain_core.rate_limiters import InMemoryRateLimiter
# 2. 配置速率限制器
rate_limiter = InMemoryRateLimiter(
requests_per_second=5, # 每秒最多5个请求
check_every_n_seconds=1.0 # 每1秒检查一次是否超过速率限制
)
# 3. 对模型调用进行封装,后续直接调用传参数就行
def load_chat_model(
model: str,
provider: str,
temperature: float = 0.7,
max_tokens: int | None = None,
base_url: str | None = None,
):
return init_chat_model(
model=model, # 模型名称
model_provider=provider, # 模型供应商
temperature=temperature, # 温度参数,用于控制模型的随机性,值越小则随机性越小
max_tokens=max_tokens, # 最大生成token数
base_url=base_url, # 专用于自定义 API Server 或代理
rate_limiter=rate_limiter # 自动限速
)
# 调用load_chat_model函数初始化gpt-4o-mini模型
# model = load_chat_model(
# model="gpt-4o-mini", # 指定OpenAI的gpt-4o-mini模型
# provider="openai", # 指定模型提供商为openai
# )
# res = model.invoke("请介绍一下你自己")
# res
model = load_chat_model(
model="deepseek-chat", # 指定OpenAI的gpt-4o-mini模型
provider="deepseek", # 指定模型提供商为openai
)
res = model.invoke("请介绍一下你自己")
res
.with_retry()模型重试机制
-
使用重试机制:通过 .with_retry() 方法为模型调用添加指数退避重试策略,在遇到临时性故障(如速率限制错误)时自动重试
-
指数退避的等待时间:
-
1s → 2s → 4s → 8s → 16s → …
-
每次失败都指数增加等待时间,避免快速重复打爆 API。
-
-
抖动 = 在等待时间上随机增加/减少一点随机数
-
防止集群中的多个客户端在相同时间重复同时回退,造成更大拥堵
-
失败的请求不会同时发起,极大降低 API 或本地模型的压力。
-
# 为模型添加指数退避重试策略
model = model.with_retry(
stop_after_attempt=3, # 最多重试3次
wait_exponential_jitter=True # 指数退避 + 随机抖动
)
7. init_embeddings()
# 1. 使用init_embeddings初始化嵌入模型
from langchain.embeddings import init_embeddings
# 2. 初始化OpenAI的text-embedding-3-small嵌入模型
embedding = init_embeddings(model="text-embedding-3-small",provider="openai")
# 3. 将文本转换为向量表示
res = embedding.embed_query("Hello world")
# 4. 打印向量的前10个元素
print(res[:10])
输出结果:
[-0.002078542485833168, -0.04908587411046028, 0.020946789532899857, 0.03135102614760399, -0.04530530795454979, -0.026402482762932777, -0.028999701142311096, 0.06030462309718132, -0.02571091614663601, -0.01482258178293705]
# 定义load_embedding函数封装嵌入模型初始化逻辑
# 该函数用于根据指定的模型名称、提供商和可选的自定义API地址,快速初始化并返回一个嵌入模型实例
from langchain.embeddings import init_embeddings
def load_embedding(
model: str, # 模型名称
provider: str, # 模型提供商
base_url: str | None = None, # 自定义API服务器地址
):
# 调用init_embeddings完成嵌入模型的初始化
return init_embeddings(
model=model, # 模型名称
provider=provider, # 模型提供商
base_url=base_url # 自定义API服务器地址
)
# 加载指定的文本嵌入模型(text-embedding-3-small)并指定提供商为 openai
load_embedding("text-embedding-3-small","openai")
# 使用已加载的嵌入模型对文本 "Hello world" 进行向量化,返回一个向量列表
res = embedding.embed_query("Hello world")
# 打印该向量列表的前 10 个元素,方便快速查看结果
print(res[:10])
输出结果:
[-0.0021342115942388773, -0.049084946513175964, 0.020961761474609375, 0.03135043382644653, -0.04533518850803375, -0.026371248066425323, -0.028922313824295998, 0.06024201214313507, -0.025725798681378365, -0.01483766920864582]
- 更多模型接入流程,详见:https://docs.langchain.com/oss/python/integrations/chat
🎯 总结
本文详细介绍了 LLM / ChatModel 大模型接口 的核心概念和实战技巧。希望这些内容能帮助你更好地理解和使用 LangChain 1.0!
如果你有任何问题或建议,欢迎在评论区留言交流!💬
← 上一篇:langchain-community 与厂商集成包 | 📚 系列目录 | 下一篇:Messages 与 Prompt 提示词模板 →
🏷️ 标签:LangChain 大模型 API接入
💝 感谢阅读!如果觉得有帮助,记得点赞收藏关注哦!
本文为原创内容,版权归作者所有,转载需注明出处。









评论前必须登录!
注册