 网硕互联帮助中心
网硕互联帮助中心在高风控网站(如 Amazon、Instagram、Google Ads)的数据采集场景中,静态代理 IP 已成为提升爬虫稳定性与成功率的关键工具。与动态代理不同,静态代理提供固定不变的出口 IP,特别适合需要长期身份一致性的任务,如账号养号、广告投放或电商防关联。
本文将深入解析静态代理 IP 的核心优势、使用注意事项,并提供可落地的代码示例与最佳实践,助你构建更智能、更隐蔽的爬虫系统。
一、什么是静态代理 IP?
静态代理 IP 是指在一段时间内(通常为数天至数月)保持不变的代理出口地址。根据来源可分为两类:
| 静态数据中心 IP | 成本低、速度快,但易被识别 | 公开数据抓取、低风控站点 |
| 静态住宅 IP | 来自真实家庭宽带,高匿名性 | 社交媒体、跨境电商、金融平台 |
核心价值:
IP固定 + 行为合规 = 高权重账号/稳定采集
二、静态代理 IP 的三大核心优势
1. 提升账号信任度
- 平台(如TikTok、Facebook)会基于IP历史行为评估账号可信度;
- 频繁更换IP会被视为“异常设备”,触发二次验证或限流;
- 固定IP模拟真实用户长期使用习惯,有助于提升账号权重。
2. 避免多账号关联
- 电商平台(如 Amazon、Shopify)通过IP、Cookie、设备指纹等维度检测多账号;
- 使用独享静态住宅IP为每个账号分配独立网络身份,有效隔离风险。
3. 稳定高效的数据通道
- 无轮换开销,连接复用率高;
- 适合长周期任务(如每日价格监控、广告报表拉取);
- 延迟低、带宽稳,保障高并发请求成功率。
三、使用静态代理IP的关键注意事项
⚠️ 1. 必须是“独享”而非“共享”
- 共享静态 IP 仍可能因其他用户违规被封;
- 务必选择独享(Dedicated)IP,确保唯一使用权。
⚠️ 2. 配合行为模拟,避免“干净IP + 机器人行为”
即使使用高质量静态 IP,若请求频率过高、Headers 固定,仍会被识别为爬虫。需同步优化:
- 随机 User-Agent
- 合理请求间隔(2–10 秒)
- 启用Cookie会话保持
- 模拟鼠标/滚动行为(如使用Playwright)
⚠️ 3. 定期健康检查
- 即使是静态IP,也可能因服务商问题或目标站封禁失效;
- 建议每24小时自动检测IP可用性。
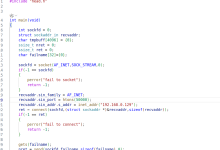
四、Python 实战:静态代理 IP 爬虫示例
示例 1:基础请求(requests)
import requests
import time
import random
# 独享静态代理配置(假设已获取)
STATIC_PROXIES = [
"http://user:pass@192.0.2.10:8080", # 账号A专用
"http://user:pass@192.0.2.11:8080", # 账号B专用
]
def fetch_with_static_proxy(url, proxy, retries=3):
headers = {
"User-Agent": random.choice([
"Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36…",
"Mozilla/5.0 (Macintosh; Intel Mac OS X 10_15_7) AppleWebKit/537.36…"
]),
"Accept-Language": "en-US,en;q=0.9",
"Referer": "https://www.google.com/"
}
for _ in range(retries):
try:
proxies = {"http": proxy, "https": proxy}
resp = requests.get(
url,
proxies=proxies,
headers=headers,
timeout=10
)
if resp.status_code == 200:
return resp
except Exception as e:
print(f"请求失败: {e}")
time.sleep(2)
return None
# 为每个账号绑定固定代理
accounts = [
{"proxy": STATIC_PROXIES[0], "url": "https://target.com/user1"},
{"proxy": STATIC_PROXIES[1], "url": "https://target.com/user2"},
]
for acc in accounts:
response = fetch_with_static_proxy(acc["url"], acc["proxy"])
if response:
print(f"成功获取数据: {len(response.text)} 字符")
time.sleep(random.uniform(3, 6)) # 模拟人工操作间隔
示例 2:Scrapy 中绑定静态代理(中间件)
# middlewares.py
class StaticProxyMiddleware:
def process_request(self, request, spider):
# 根据请求 meta 指定代理
if 'proxy' in request.meta:
request.meta['proxy'] = request.meta['proxy']
# spider.py
def start_requests(self):
yield scrapy.Request(
url="https://example.com/profile",
meta={"proxy": "http://user:pass@192.0.2.10:8080"},
callback=self.parse
)
五、高级策略:静态 + 动态混合架构
对于复杂业务,可采用分层代理策略:
| 主账号登录/发帖 | 静态住宅 IP | 保持身份一致性 |
| 批量点赞/评论 | 动态住宅 IP | 避免主 IP 被关联封禁 |
| 数据采集 | 数据中心 IP | 成本低、速度快 |
架构示例:
主账号用静态 IP 养权重 → 辅助互动用动态 IP 执行 → 采集公开数据用数据中心 IP 提效。
六、如何选择高质量静态代理?
| IP 类型 | 优先选择静态住宅IP(非数据中心) |
| 独享性 | 必须为独享(Dedicated),非共享 |
| 地理位置 | 支持按城市/ASN精准选择 |
| 协议支持 | 支持 HTTP/HTTPS/SOCKS5 |
| 认证方式 | 支持用户名密码或IP白名单 |
| SLA 保障 | 提供可用性承诺(如 99.9%) |
验证方法:
使用 https://ipinfo.io 检查 IP 是否为住宅类型;
用 https://bot.sannysoft.com 测试浏览器指纹是否暴露代理特征。
七、总结:静态代理不是“万能钥匙”,而是“信任基石”
- 适用场景:长期账号运营、高风控平台、多账号隔离;
- 不适用场景:大规模公开数据抓取(成本高,动态代理更优);
- 成功关键:静态 IP + 合规行为 + 会话管理 = 长期稳定
终极建议:
不要为了“不被封”而盲目堆砌代理,而应思考:
“如何让我的爬虫看起来像一个真实、合法、低频的普通用户?”
掌握这一思维,你才能在反爬与采集的博弈中立于不败之地。




评论前必须登录!
注册