 网硕互联帮助中心
网硕互联帮助中心一、前言
51job 作为国内主流的招聘平台,其岗位数据是求职分析、行业调研的重要数据源。传统的页面元素解析爬虫易受页面结构变更影响,且反爬风险高;本文将基于DrissionPage框架,采用接口监听的方式直接获取 51job 的结构化 JSON 数据,结合「自动关键词生成、岗位数据标准化、智能翻页、反爬休眠」等特性,实现 51job 岗位数据的批量爬取,最终输出结构化 JSON 文件,全程代码健壮性高,新手也能快速上手。
本次实战核心亮点
二、环境准备
1. 核心依赖安装
本次实战仅需安装DrissionPage框架(集成浏览器自动化 + 接口监听,无需额外安装 Selenium/Requests):
pip install DrissionPage
2. 环境说明
- Python 版本:3.8 及以上(推荐 3.9~3.11,兼容 DrissionPage);
- 操作系统:Windows/macOS/Linux 均支持;
- 浏览器:自动适配本地 Chrome 浏览器,无需手动配置驱动(DrissionPage 已内置适配逻辑)。
三、完整实战代码
直接复制以下代码,修改少量配置(如地区编码、岗位大类)即可运行:
import time
import json
import logging
from DrissionPage import ChromiumPage
# ===================== 自定义配置(根据需求修改) =====================
# 1. 岗位大类与细分岗位配置(可自行扩展)
JOB_BIG_TYPE = {
"技术开发": ["Python", "Java", "前端", "后端", "测试", "运维"],
"产品运营": ["产品经理", "运营", "新媒体", "电商运营"],
"设计": ["UI设计", "平面设计", "交互设计", "视觉设计"]
}
# 2. 爬取地区编码(040000=上海,可替换为其他城市:101010100=北京,101280600=深圳)
CITY_CODE = "040000"
# 3. 最大翻页数(避免爬取过多触发反爬)
MAX_PAGE_PER_KEYWORD = 3
# ===================== 数据模型与工具函数 =====================
def BossItem():
"""定义岗位数据模型(替代Scrapy Item,用字典标准化字段)"""
return {
"job_id": "", # 岗位唯一ID
"岗位名称": "", # 原始岗位名
"标准岗位": "", # 标准化后的岗位名
"岗位大类": "", # 岗位所属大类
"公司": "", # 公司全称
"公司领域": "", # 公司所属行业
"规模": "", # 公司规模
"薪资": "", # 薪资范围
"学历要求": "", # 学历要求
"经验要求": "", # 工作经验要求
"技能需求": "", # 岗位技能标签
"市": "", # 城市
"区": "", # 行政区
"商圈": "", # 商圈
"经度": "", # 经度
"纬度": "", # 纬度
"搜索关键词": "", # 爬取该岗位的搜索关键词
"来源渠道": "51job", # 数据来源
"访问地址": "" # 岗位详情页链接
}
def normalize_job(job_name):
"""标准化岗位名称,匹配大类和标准岗位"""
for big_type, jobs in JOB_BIG_TYPE.items():
for j in jobs:
if j in job_name:
return big_type, j
return "其他", "其他"
def build_search_keywords():
"""基于JOB_BIG_TYPE构建去重后的搜索关键词列表"""
keywords = []
for jobs in JOB_BIG_TYPE.values():
keywords.extend(jobs)
return list(set(keywords)) # 去重
# ===================== 核心爬虫类 =====================
class Job51Spider:
def __init__(self):
# 1. 配置日志(替代Scrapy logger,实时输出爬取进度)
logging.basicConfig(
level=logging.INFO,
format='%(asctime)s – %(levelname)s – %(message)s',
handlers=[logging.StreamHandler()] # 输出到控制台
)
self.logger = logging.getLogger(__name__)
# 2. 初始化浏览器(headless=True 启用无头模式,无界面运行)
self.dp = ChromiumPage(headless=False) # 调试时设为False,上线设为True
# 3. 开启接口监听,监听51job搜索接口标识(search-pc)
self.dp.listen.start("search-pc")
self.logger.info("✅ 浏览器初始化完成,接口监听已开启")
def parse_jobs(self, job_list, keyword):
"""
解析单页职位列表数据
:param job_list: 接口返回的岗位列表
:param keyword: 当前搜索关键词
:return: 结构化的岗位字典列表
"""
job_items = []
for job in job_list:
try:
item = BossItem()
job_name = job.get("jobName", "")
# 标准化岗位名称
big_type, std_job = normalize_job(job_name)
# 解析地区信息(嵌套字典容错)
area = job.get("jobAreaLevelDetail", {})
# 填充岗位数据(全量容错,避免字段缺失报错)
item["job_id"] = job.get("jobId", "")
item["岗位名称"] = job_name
item["标准岗位"] = std_job
item["岗位大类"] = big_type
item["公司"] = job.get("fullCompanyName", "")
item["公司领域"] = job.get("industryType1Str", "")
item["规模"] = job.get("companySizeString", "")
item["薪资"] = job.get("provideSalaryString", "")
item["学历要求"] = job.get("degreeString", "")
item["经验要求"] = job.get("workYearString", "")
# 提取技能标签(跳过前2个无关标签)
job_tags_slice = job.get("jobTags", [])[2:]
item["技能需求"] = ",".join(job_tags_slice) if job_tags_slice else "暂无"
item["市"] = area.get("cityString", "")
item["区"] = area.get("districtString", "")
item["商圈"] = job.get("landmarkString", "")
item["经度"] = job.get("lon", "")
item["纬度"] = job.get("lat", "")
item["搜索关键词"] = keyword
item["访问地址"] = job.get("jobHref", "")
job_items.append(item)
self.logger.info(f"📌 解析到职位:{job_name} – {item['公司']} – {item['薪资']}")
except Exception as e:
self.logger.warning(f"⚠️ 单个岗位解析失败,跳过:{str(e)}")
continue
# 解析完一页后休眠,降低反爬风险
time.sleep(5)
return job_items
def crawl(self):
"""核心爬取逻辑:遍历关键词→接口监听→翻页→解析数据"""
# 1. 构建所有搜索关键词
keywords = build_search_keywords()
self.logger.info(f"📋 共生成 {len(keywords)} 个搜索关键词:{keywords}")
# 2. 存储所有爬取的职位数据
all_jobs = []
# 3. 遍历每个关键词爬取
for keyword in keywords:
self.logger.info(f"\\n🚀 开始采集关键词:{keyword}")
# 构造搜索URL(拼接地区编码和关键词)
search_url = (
f"https://we.51job.com/pc/search"
f"?jobArea={CITY_CODE}&keyword={keyword}"
)
self.dp.get(search_url)
# 4. 获取第一页接口数据(容错处理)
try:
# 等待接口响应,超时10秒
resp = self.dp.listen.wait(timeout=10)
first_data = resp.response.body
# 兼容接口返回字符串的情况,转为字典
if isinstance(first_data, str):
first_data = json.loads(first_data)
except Exception as e:
self.logger.error(f"❌ 获取{keyword}第一页接口数据失败:{e}")
continue
# 5. 提取总页数(多层容错,避免数据格式异常)
total_page = first_data.get("resultbody", {}).get("job", {}).get("totalcount", 1)
try:
total_page = int(total_page)
total_page = max(total_page, 1) # 确保页数≥1
except (ValueError, TypeError):
total_page = 1
# 限制最大翻页数
actual_max_page = min(total_page, MAX_PAGE_PER_KEYWORD)
self.logger.info(f"📖 {keyword} 共 {total_page} 页数据(本次最多爬取 {actual_max_page} 页)")
# 6. 解析第一页数据
job_list = first_data.get("resultbody", {}).get("job", {}).get("items", [])
if not job_list:
self.logger.info(f"📭 {keyword} 无数据,跳过")
continue
# 解析并收集第一页职位
page1_jobs = self.parse_jobs(job_list, keyword)
all_jobs.extend(page1_jobs)
# 7. 翻页爬取(从第2页到实际最大页)
for page in range(2, actual_max_page + 1):
try:
# 滚动到页面底部,加载下一页按钮
self.dp.scroll.to_bottom()
# 查找下一页按钮(CSS选择器定位)
next_btn = self.dp.ele('css:button.btn-next', timeout=5)
if not next_btn:
self.logger.info(f"📄 {keyword} 已无下一页(预期{total_page}页,实际爬取到{page – 1}页)")
break
# 点击下一页按钮
next_btn.click()
self.logger.info(f"🔍 正在采集{keyword} 第{page}页的数据…")
# 等待下一页接口响应
resp = self.dp.listen.wait(timeout=10)
data = resp.response.body
if isinstance(data, str):
data = json.loads(data)
# 解析当前页职位列表
job_list = data.get("resultbody", {}).get("job", {}).get("items", [])
if not job_list:
self.logger.info(f"📭 {keyword} 第{page}页无数据,停止翻页")
break
# 解析并收集当前页职位
page_jobs = self.parse_jobs(job_list, keyword)
all_jobs.extend(page_jobs)
# 翻页后短休眠,避免请求过快
time.sleep(1.5)
except Exception as e:
self.logger.warning(f"⚠️ {keyword} 第 {page} 页爬取异常: {e},停止翻页")
break
# 8. 爬取完成,保存数据到JSON文件
self.save_data(all_jobs)
self.logger.info(f"\\n🎉 爬取完成!共采集到 {len(all_jobs)} 个有效职位数据")
def save_data(self, all_jobs):
"""将结构化岗位数据保存为JSON文件(UTF-8编码,格式化输出)"""
with open("51job_crawled_data.json", "w", encoding="utf-8") as f:
json.dump(all_jobs, f, ensure_ascii=False, indent=4)
self.logger.info(f"💾 数据已保存到:51job_crawled_data.json")
def close(self):
"""爬虫结束后,释放浏览器资源(必须执行)"""
self.logger.info("🔌 开始关闭浏览器,释放资源…")
self.dp.listen.stop() # 停止接口监听
self.dp.quit() # 关闭浏览器
self.logger.info("✅ 浏览器已关闭,资源释放完成")
# ===================== 运行爬虫 =====================
if __name__ == "__main__":
# 初始化爬虫实例
spider = Job51Spider()
try:
# 执行核心爬取逻辑
spider.crawl()
except Exception as e:
spider.logger.error(f"❌ 爬虫运行异常:{e}")
finally:
# 无论是否异常,都确保浏览器关闭
spider.close()
四、核心代码解析
1. 自定义配置模块(可快速调整)
- JOB_BIG_TYPE:定义岗位大类和细分岗位,爬取时会自动生成所有细分岗位的搜索关键词,无需手动维护;
- CITY_CODE:爬取地区编码(040000 = 上海,可替换为北京 / 深圳等),可在 51job 官网切换城市后,从 URL 中提取编码;
- MAX_PAGE_PER_KEYWORD:限制每个关键词的最大翻页数,避免爬取过多触发反爬机制。
2. 数据模型与工具函数
- BossItem():用字典标准化岗位字段,统一输出格式,后续可直接对接数据库 / Kafka,无需额外转换;
- normalize_job():将原始岗位名称标准化(如 “Python 开发工程师”→标准岗位 “Python”,大类 “技术开发”),便于后续分类分析;
- build_search_keywords():从JOB_BIG_TYPE中提取所有细分岗位,去重后生成搜索关键词列表,实现自动化批量爬取。
3. 爬虫类核心逻辑
(1)初始化(init)
- 配置日志:实时输出爬取进度、异常信息,便于调试和监控;
- 初始化浏览器:ChromiumPage(headless=False) 启动带界面浏览器(调试用),上线可改为True启用无头模式;
- 开启接口监听:dp.listen.start("search-pc") 监听 51job 搜索接口,无需分析完整接口 URL,框架自动匹配关键词。
(2)数据解析(parse_jobs)
- 全量容错:使用job.get(key, 默认值)替代直接取值,避免字段缺失导致程序崩溃;
- 技能标签处理:跳过前 2 个无关标签,只保留核心技能需求;
- 反爬休眠:解析完一页后休眠 5 秒,降低被检测风险。
(3)核心爬取(crawl)
- 关键词遍历:逐个爬取所有标准化关键词的岗位数据;
- 接口数据获取:dp.listen.wait(timeout=10) 等待接口响应,超时 10 秒避免无限等待;
- 页数容错:提取总页数时做类型转换和最小值限制,避免数据格式异常;
- 翻页逻辑:通过点击 “下一页” 按钮实现翻页,结合滚动到底部确保按钮加载,兼容 51job 的懒加载机制。
(4)数据保存与资源释放
- save_data():将所有岗位数据保存为 JSON 文件,ensure_ascii=False 避免中文乱码,indent=4 格式化输出便于阅读;
- close():爬虫结束后停止接口监听、关闭浏览器,避免资源泄露。
五、运行说明与结果展示
1. 运行步骤
2. 运行日志示例
3. 输出文件示例(51job_crawled_data.json)
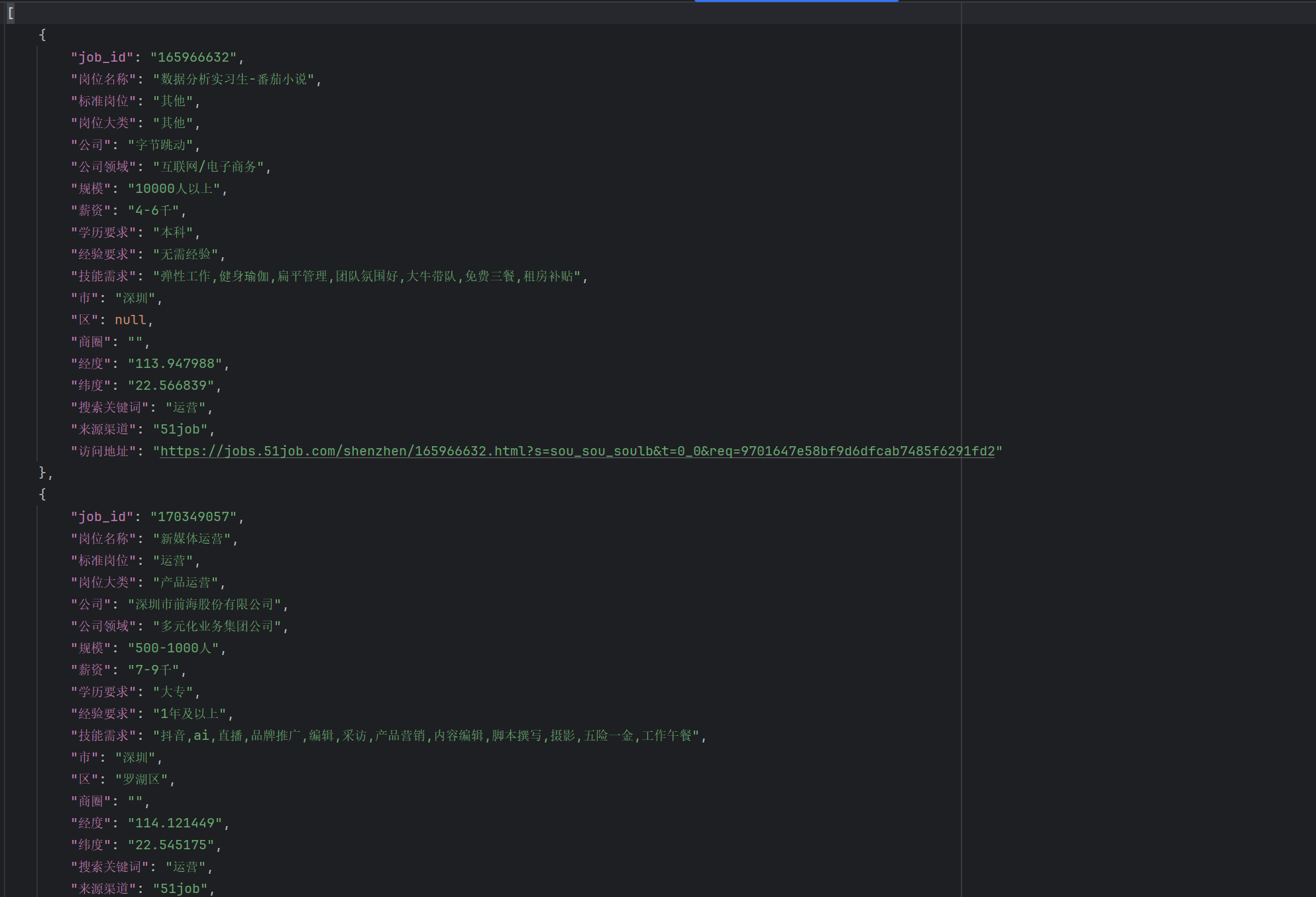
六、注意事项与优化建议
1. 核心注意事项
- 反爬机制规避:
- 切勿将MAX_PAGE_PER_KEYWORD设置过大(建议≤5),且休眠时间不可删除 / 减小;
- 避免短时间内重复运行,建议间隔≥30 分钟;
- 上线运行时启用headless=True,减少浏览器特征暴露。
- 接口监听失效:若search-pc关键词无法匹配接口,可打开浏览器 F12→网络→筛选 XHR,找到 51job 搜索接口的 URL / 响应,修改监听关键词。
- 地区编码获取:在 51job 官网切换城市后,复制 URL 中的jobArea参数值(如北京 = 101010100)。
2. 进阶优化建议
- 集成 Kafka:在parse_jobs方法中添加 Kafka 生产者,将解析后的岗位数据投递到 Kafka 主题,实现 “爬取→消息缓冲→消费存储” 解耦;
- 数据入库:编写 JSON 文件解析脚本,将数据存入 MySQL/MongoDB/Elasticsearch,便于后续查询分析;
- 多线程爬取:按关键词分线程爬取(需控制并发数≤3),提升爬取效率;
- 数据去重:基于job_id或 “岗位名称 + 公司 + 薪资” 去重,避免重复数据;
- 邮件告警:添加异常邮件通知,爬取失败时及时提醒。
七、总结
如果本文对你有帮助,欢迎点赞 + 收藏 + 关注!运行过程中遇到问题,可在评论区留言,我会第一时间解答~







评论前必须登录!
注册