 网硕互联帮助中心
网硕互联帮助中心Spring Batch实战
前言
在企业级应用中,批量数据处理是一个非常常见的需求。比如月底的工资代发、银行对账、数据报表生成等。当数据量达到几十万甚至上百万时,如何高效、可靠地处理这些数据,就成了一个技术挑战。
本文将以"50万笔工资代发"为实际场景,详细介绍如何使用Spring Batch框架来处理大规模批量数据,并重点讲解当处理失败时,如何实现部分回滚机制,确保已成功处理的数据不会因为少量失败记录而全部回滚。
一、什么是Spring Batch?
1.1 Spring Batch简介
Spring Batch是一个轻量级的、全面的批处理框架,由Spring团队开发,旨在帮助企业开发健壮的批处理应用程序。它于2008年首次发布,经过十多年的发展,已经成为Java批处理领域的事实标准。
Spring Batch的核心设计理念包括:
- Chunk-oriented Processing(块级处理):将大量数据分批处理,避免内存溢出
- 事务管理:每个Chunk作为一个独立的事务,支持部分回滚
- 容错机制:支持跳过(Skip)、重试(Retry)等容错策略
- 作业调度:支持定时任务、手动触发等多种调度方式
- 监控与统计:提供完整的执行记录和统计信息
1.2 核心概念详解
Job(作业)
Job是批处理的核心概念,代表一个完整的批处理任务。一个Job可以包含多个Step,按顺序或并行执行。
@Bean
public Job salaryPaymentJob() {
return jobBuilderFactory.get("salaryPaymentJob")
.start(step1())
.next(step2())
.build();
}
Step(步骤)
Step是Job的基本执行单元,每个Step包含:
- ItemReader:读取数据
- ItemProcessor:处理数据(可选)
- ItemWriter:写入数据
@Bean
public Step salaryPaymentStep() {
return stepBuilderFactory.get("salaryPaymentStep")
.<SalaryPayment, SalaryPayment>chunk(1000)
.reader(reader())
.processor(processor())
.writer(writer())
.build();
}
Chunk(数据块)
Chunk是Spring Batch处理数据的基本单位。每次从Reader读取指定数量的记录,处理后一起提交到数据库:
读取1000条 → 处理1000条 → 写入1000条 → 提交事务
1.3 应用场景
Spring Batch适用于以下典型场景:
| 数据迁移 | 跨系统数据同步 | 从旧系统迁移数据到新系统 |
| 数据转换 | ETL过程 | 从数据库读取、转换、写入数据仓库 |
| 批量处理 | 定期批量操作 | 月底工资代发、银行对账 |
| 报表生成 | 定期生成报表 | 每日交易汇总报表 |
1.4 与其他框架对比
| 批量处理 | ✅ 专用 | 需要 | 需要 |
| 事务管理 | ✅ 内置 | 无 | 无 |
| 容错机制 | ✅ 完善的Skip/Retry | 无 | 无 |
| 监控统计 | ✅ 数据库持久化 | 基础 | 无 |
| 并行处理 | ✅ 多种模式 | 无 | 基础 |
为什么需要部分回滚?
想象一下:你需要处理50万笔工资代发,如果第49万笔记录因为银行卡号错误而失败,在没有部分回滚机制的情况下,前面489,999笔已成功处理的数据会全部回滚!这对于业务来说是不可接受的。
二、系统架构设计
为了实现50万笔工资代发的高效处理,我们设计了如下的系统架构:
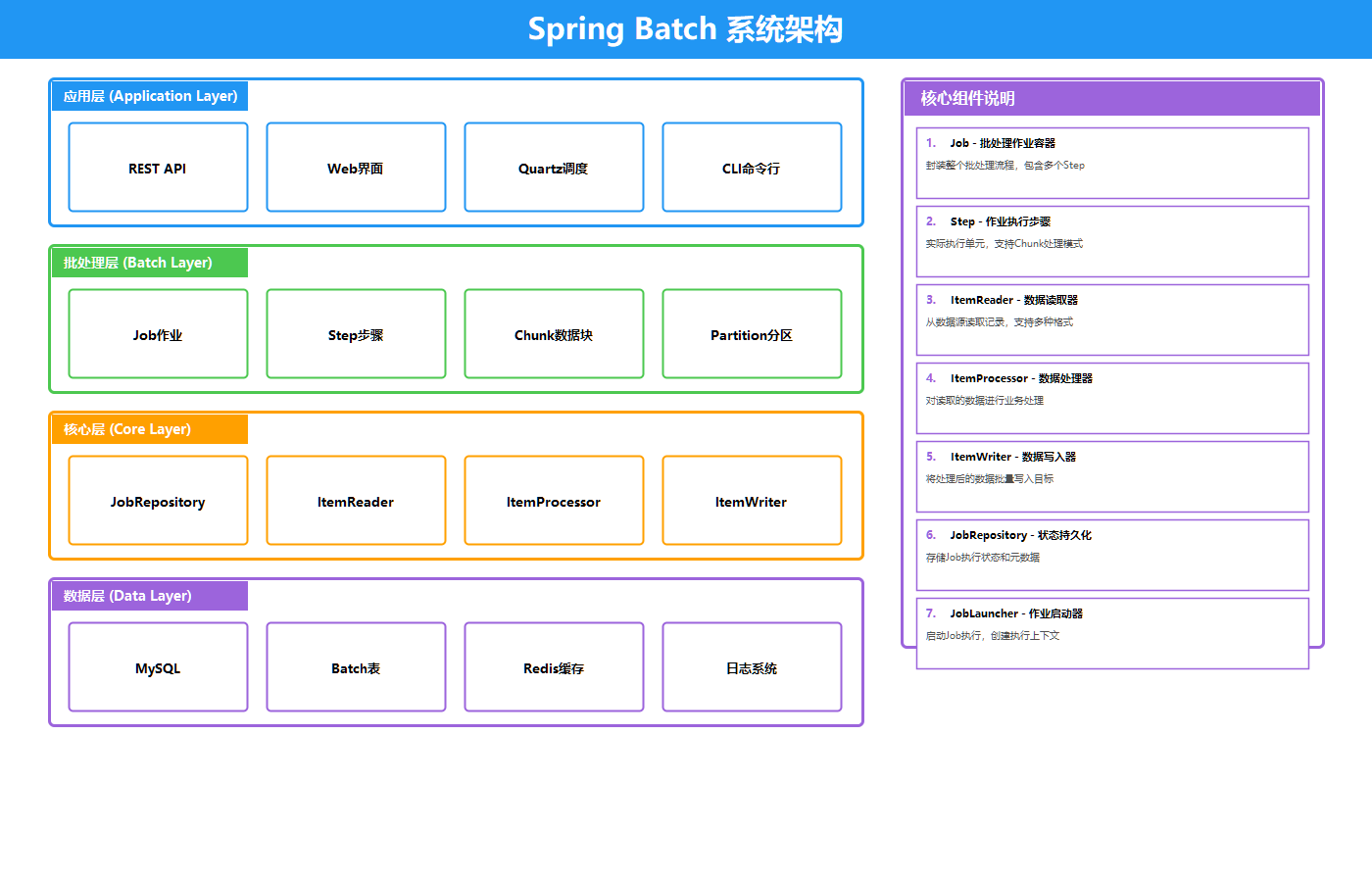
上图展示了Spring Batch工资代发系统的分层架构:
- Web层:提供监控面板,支持Job启动/停止、实时状态监控和统计信息查询
- Batch控制层:REST API接口,包含JobLauncher和JobRepository
- Spring Batch核心层:Job→Step→Chunk的处理流程,包含Reader、Processor、Writer三大组件
- 数据存储层:MySQL数据库、CSV文件和Job执行日志
2.1 核心组件说明
| Job | 整个批处理任务 | SalaryPaymentJob |
| Step | 任务中的一个步骤 | SalaryPaymentStep |
| ItemReader | 数据读取器 | FlatFileItemReader(读取CSV) |
| ItemProcessor | 数据处理器 | SalaryPaymentProcessor(数据验证) |
| ItemWriter | 数据写入器 | JdbcBatchItemWriter(批量写入数据库) |
三、部分回滚机制原理
3.1 Chunk-Oriented Processing
Spring Batch采用**Chunk-Oriented Processing(块级处理)**模式,这是实现部分回滚的核心机制:
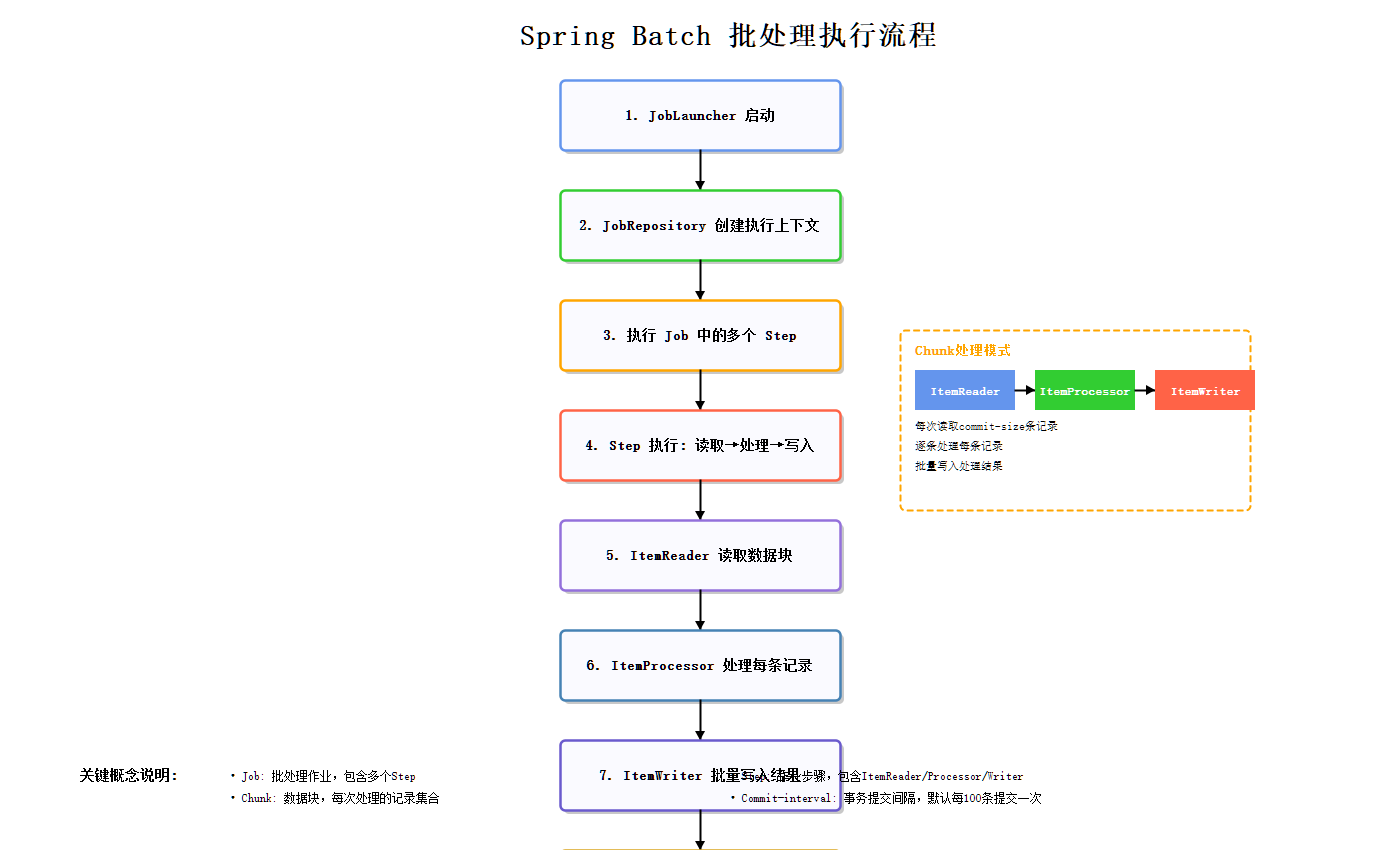
上图展示了Batch处理的核心流程:Reader读取数据 → Processor处理验证 → Writer批量写入,形成完整的处理管道。
对于50万笔数据的处理,Chunk机制的工作方式如下:
50万笔数据
│
├─► Chunk 1 (1-1000笔) ──► 独立事务 ──► 成功提交
├─► Chunk 2 (1001-2000笔) ──► 独立事务 ──► 成功提交
├─► Chunk 3 (2001-3000笔) ──► 独立事务 ──► 第2500笔失败 → 重试3次 → 跳过 → 其余999笔提交
├─► Chunk 4 (3001-4000笔) ──► 独立事务 ──► 成功提交
…
└─► Chunk 500 (499001-500000笔) ──► 独立事务 ──► 成功提交
最终结果:499,999笔成功,1笔被跳过
关键配置:
- chunkSize: 1000(每1000笔提交一次)
- skipLimit: 100(最多跳过100笔失败记录)
- retryLimit: 3(每笔失败重试3次)
3.2 事务边界与部分回滚
每个Chunk是独立的事务单元,这是实现部分回滚的关键:

上图清晰地展示了事务边界和部分回滚的工作机制:
事务规则:
- Chunk内任意记录失败 → 整个Chunk回滚
- 重试成功 → 继续处理
- 重试失败且可跳过 → 跳过该记录,继续处理Chunk内剩余记录
- 跳过次数超限 → 整个Job失败
实际案例:
假设Chunk 3中有1000笔数据,第500笔验证失败:
3.3 容错策略配置
.faultTolerant() // 启用容错
.skipLimit(100) // 最多跳过100条
.skip(IllegalArgumentException.class) // 跳过数据验证异常
.skip(NullPointerException.class) // 跳过空指针异常
.retryLimit(3) // 失败重试3次
.retry(Exception.class) // 重试所有异常
四、50万笔工资代发数据处理流程
在理解了部分回滚机制后,我们来看完整的工资代发数据处理流程:
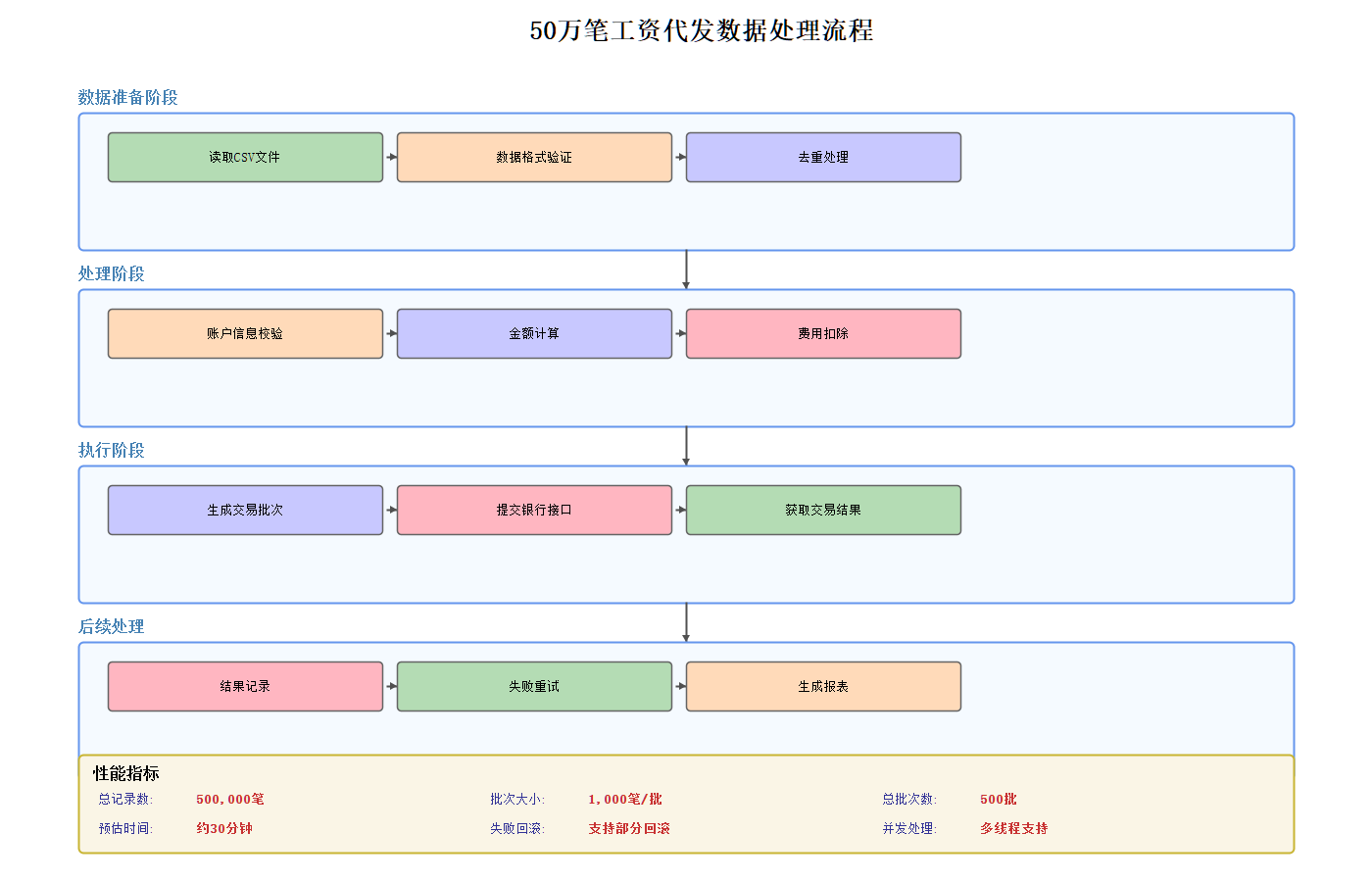
上图展示了从CSV文件读取到数据库写入的完整数据流,包含以下关键步骤:
- 员工ID非空验证
- 金额范围验证(0.01-100万)
- 银行卡号格式验证(16-19位数字)
五、核心代码实现
5.1 Job配置
@Configuration
public class SalaryPaymentJobConfig {
@Value("${batch.chunk.size:1000}")
private int chunkSize; // 每次处理的记录数
@Value("${batch.skip.limit:100}")
private int skipLimit; // 跳过限制
@Value("${batch.retry.limit:3}")
private int retryLimit; // 重试次数
@Bean
public Step salaryPaymentStep() {
return stepBuilderFactory
.get("salaryPaymentStep")
.<SalaryPayment, SalaryPayment>chunk(chunkSize)
.reader(salaryPaymentReader())
.processor(salaryPaymentProcessor())
.writer(salaryPaymentWriter())
.faultTolerant() // 启用容错
.skipLimit(skipLimit)
.skip(IllegalArgumentException.class)
.skip(NullPointerException.class)
.retryLimit(retryLimit)
.retry(Exception.class)
.listener(new SalaryItemReadListener())
.listener(new SalaryItemWriteListener())
.build();
}
@Bean
public Job salaryPaymentJob(Step step, SalaryJobExecutionListener listener) {
return jobBuilderFactory.get("salaryPaymentJob")
.incrementer(new RunIdIncrementer())
.listener(listener)
.start(step)
.build();
}
}
5.2 数据读取器
@Bean
public FlatFileItemReader<SalaryPayment> salaryPaymentReader() {
FlatFileItemReader<SalaryPayment> reader = new FlatFileItemReader<>();
reader.setName("salaryPaymentReader");
reader.setResource(new ClassPathResource("input/salary-payments.csv"));
reader.setLinesToSkip(1); // 跳过CSV标题行
// 设置列映射
DelimitedLineTokenizer tokenizer = new DelimitedLineTokenizer();
tokenizer.setNames(new String[]{
"employeeId", "employeeName", "accountNumber",
"accountName", "bankName", "amount", "currency",
"paymentDate", "remark"
});
// 设置字段映射
BeanWrapperFieldSetMapper<SalaryPayment> mapper = new BeanWrapperFieldSetMapper<>();
mapper.setTargetType(SalaryPayment.class);
DefaultLineMapper<SalaryPayment> lineMapper = new DefaultLineMapper<>();
lineMapper.setLineTokenizer(tokenizer);
lineMapper.setFieldSetMapper(mapper);
reader.setLineMapper(lineMapper);
return reader;
}
5.3 数据处理器(验证逻辑)
public class SalaryPaymentProcessor implements ItemProcessor<SalaryPayment, SalaryPayment> {
private static final BigDecimal MIN_AMOUNT = new BigDecimal("0.01");
private static final BigDecimal MAX_AMOUNT = new BigDecimal("1000000");
@Override
public SalaryPayment process(SalaryPayment item) throws Exception {
// 1. 数据验证
if (item.getEmployeeId() == null || item.getEmployeeId().trim().isEmpty()) {
throw new IllegalArgumentException("员工ID不能为空");
}
// 2. 金额验证
if (item.getAmount() == null) {
throw new IllegalArgumentException("发放金额不能为空");
}
if (item.getAmount().compareTo(MIN_AMOUNT) < 0) {
throw new IllegalArgumentException("发放金额不能小于0.01元");
}
if (item.getAmount().compareTo(MAX_AMOUNT) > 0) {
throw new IllegalArgumentException("发放金额不能大于100万元");
}
// 3. 银行卡号验证
if (item.getAccountNumber() == null ||
item.getAccountNumber().length() < 16 ||
item.getAccountNumber().length() > 19) {
throw new IllegalArgumentException("银行账号长度必须在16-19位之间");
}
// 4. 设置处理状态
item.setStatus("PROCESSING");
item.setTransactionId("SAL" + System.currentTimeMillis() + item.getEmployeeId());
return item;
}
}
5.4 数据写入器
public class SalaryPaymentWriter implements ItemWriter<SalaryPayment> {
private final JdbcBatchItemWriter<SalaryPayment> delegate;
public SalaryPaymentWriter(DataSource dataSource) {
this.delegate = new JdbcBatchItemWriter<>();
this.delegate.setDataSource(dataSource);
this.delegate.setSql(
"INSERT INTO salary_payment " +
"(employee_id, employee_name, account_number, account_name, " +
"bank_name, amount, currency, payment_date, remark, " +
"status, transaction_id, create_time, update_time) " +
"VALUES (:employeeId, :employeeName, :accountNumber, :accountName, " +
":bankName, :amount, :currency, :paymentDate, :remark, " +
":status, :transactionId, :createTime, :updateTime)");
this.delegate.setItemSqlParameterSourceProvider(
new BeanPropertyItemSqlParameterSourceProvider<>()
);
}
@Override
public void write(List<? extends SalaryPayment> items) throws Exception {
delegate.write(items);
}
}
5.5 自定义SkipPolicy
@Component
public class PartialRollbackHandler implements SkipPolicy {
private static final int SKIP_LIMIT = 100;
@Override
public boolean shouldSkip(Throwable throwable, int skipCount) {
// 超过跳过限制
if (skipCount >= SKIP_LIMIT) {
return false;
}
// 文件不存在,不能跳过
if (throwable instanceof FileNotFoundException) {
return false;
}
// 数据格式错误,可以跳过
if (throwable instanceof FlatFileParseException) {
return true;
}
// 数据验证失败,可以跳过
if (throwable instanceof IllegalArgumentException ||
throwable instanceof NullPointerException) {
return true;
}
return false;
}
}
六、监控与调度架构
除了数据处理,Spring Batch还提供了完善的监控和调度能力:
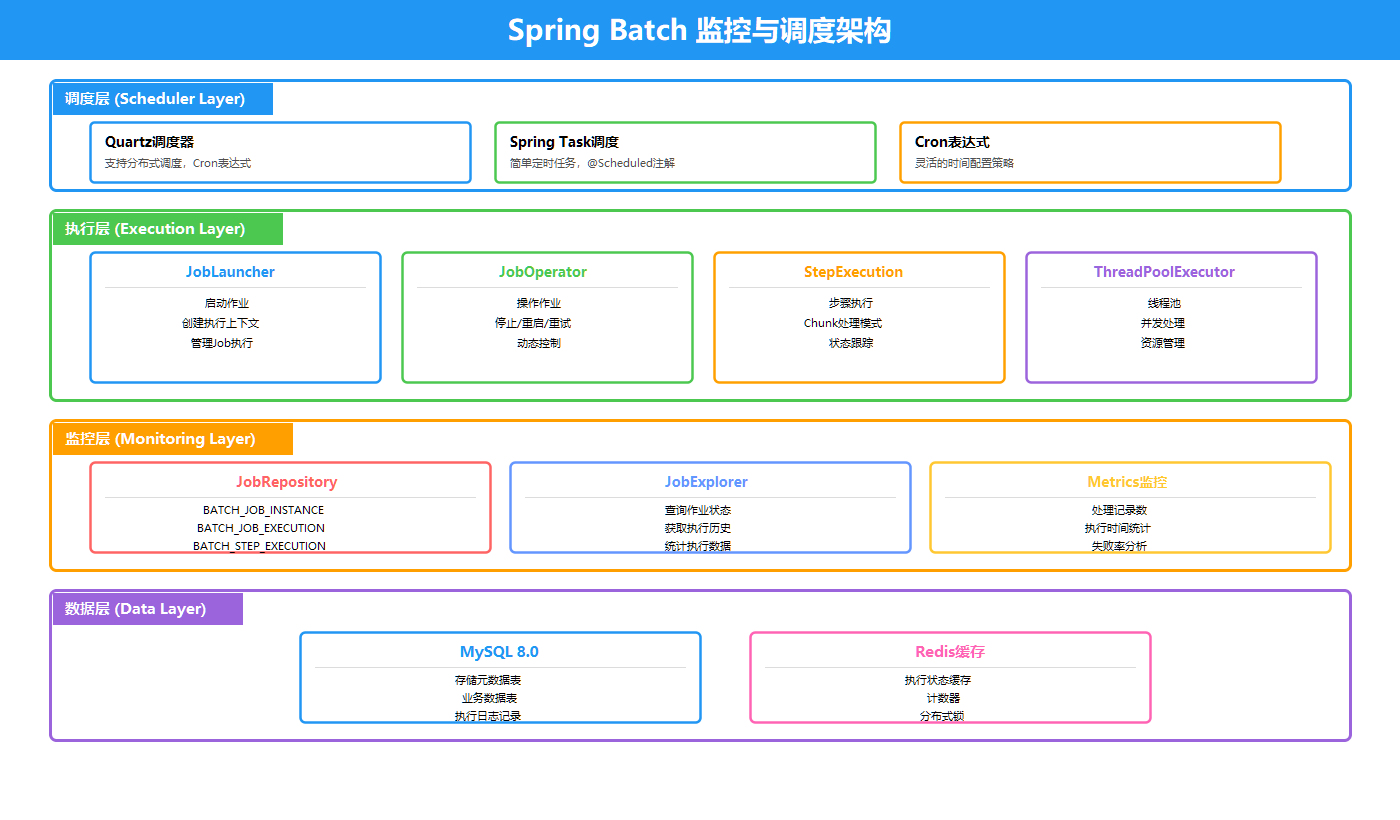
上图展示了完整的监控与调度架构:
调度层:支持三种调度方式
- Quartz调度器:支持分布式调度,适合集群环境
- Spring Task调度:简单的定时任务,轻量级选择
- Cron表达式:灵活的时间配置
执行层:核心执行组件
- JobLauncher:启动作业,创建执行上下文
- JobOperator:操作作业,支持停止/重启/重试
- StepExecution:步骤执行,采用Chunk处理模式
- ThreadPoolExecutor:线程池,实现并发处理
监控层:监控与统计
- JobRepository:存储元数据(BATCH_JOB_INSTANCE、BATCH_JOB_EXECUTION、BATCH_STEP_EXECUTION)
- JobExplorer:查询作业状态、获取执行历史
- Metrics:处理记录数、执行时间、失败率统计
数据层:数据存储
- MySQL 8.0:存储元数据表、业务数据表、日志记录
- Redis缓存:执行状态缓存、计数器、分布式锁
七、数据库设计
7.1 工资代发表
CREATE TABLE salary_payment (
id BIGINT AUTO_INCREMENT PRIMARY KEY,
employee_id VARCHAR(50) NOT NULL COMMENT '员工ID',
employee_name VARCHAR(100) NOT NULL COMMENT '员工姓名',
account_number VARCHAR(50) NOT NULL COMMENT '银行账号',
account_name VARCHAR(100) NOT NULL COMMENT '账户名称',
bank_name VARCHAR(100) NOT NULL COMMENT '开户行',
amount DECIMAL(18,2) NOT NULL COMMENT '发放金额',
currency VARCHAR(10) NOT NULL DEFAULT 'CNY' COMMENT '币种',
payment_date DATETIME NOT NULL COMMENT '发放日期',
remark VARCHAR(500) COMMENT '备注',
status VARCHAR(20) NOT NULL DEFAULT 'PENDING' COMMENT '状态',
transaction_id VARCHAR(100) COMMENT '交易ID',
error_message VARCHAR(1000) COMMENT '错误信息',
create_time DATETIME NOT NULL DEFAULT CURRENT_TIMESTAMP,
update_time DATETIME NOT NULL DEFAULT CURRENT_TIMESTAMP ON UPDATE CURRENT_TIMESTAMP,
INDEX idx_employee_id (employee_id),
INDEX idx_status (status)
) ENGINE=InnoDB DEFAULT CHARSET=utf8mb4;
7.2 Spring Batch元表
Spring Batch框架会自动创建以下元表来存储Job执行信息:
- batch_job_instance – Job实例表
- batch_job_execution – Job执行表
- batch_job_execution_params – Job参数表
- batch_step_execution – Step执行表
- batch_step_execution_context – Step上下文表
八、REST API设计
@RestController
@RequestMapping("/api/batch")
public class BatchJobController {
// 启动Job
@PostMapping("/start")
public ResponseEntity<Map<String, Object>> startJob(
@RequestParam String inputFile
) {
JobParameters params = new JobParametersBuilder()
.addLong("startTime", System.currentTimeMillis())
.addString("inputFile", inputFile)
.toJobParameters();
JobExecution execution = jobLauncher.run(salaryPaymentJob, params);
return ResponseEntity.ok(result);
}
// 获取Job状态
@GetMapping("/status/{jobExecutionId}")
public ResponseEntity<Map<String, Object>> getJobStatus(
@PathVariable Long jobExecutionId
) {
JobExecution execution = jobRepository.getJobExecution(jobExecutionId);
// 返回执行详情
}
// 停止Job
@PostMapping("/stop/{jobExecutionId}")
public ResponseEntity<Map<String, Object>> stopJob(
@PathVariable Long jobExecutionId
) {
JobExecution execution = jobRepository.getJobExecution(jobExecutionId);
execution.stop();
return ResponseEntity.ok(result);
}
// 获取统计信息
@GetMapping("/statistics")
public ResponseEntity<Map<String, Object>> getStatistics() {
// 返回总数、成功数、失败数等统计
}
// 健康检查
@GetMapping("/health")
public ResponseEntity<Map<String, Object>> health() {
// 返回系统健康状态
}
}
九、性能优化与并行处理
当数据量达到50万甚至更多时,单线程处理可能成为瓶颈。Spring Batch提供了多种并行处理方式。
9.1 多线程并发处理
Spring Batch支持多线程并发处理,大幅提升处理效率:
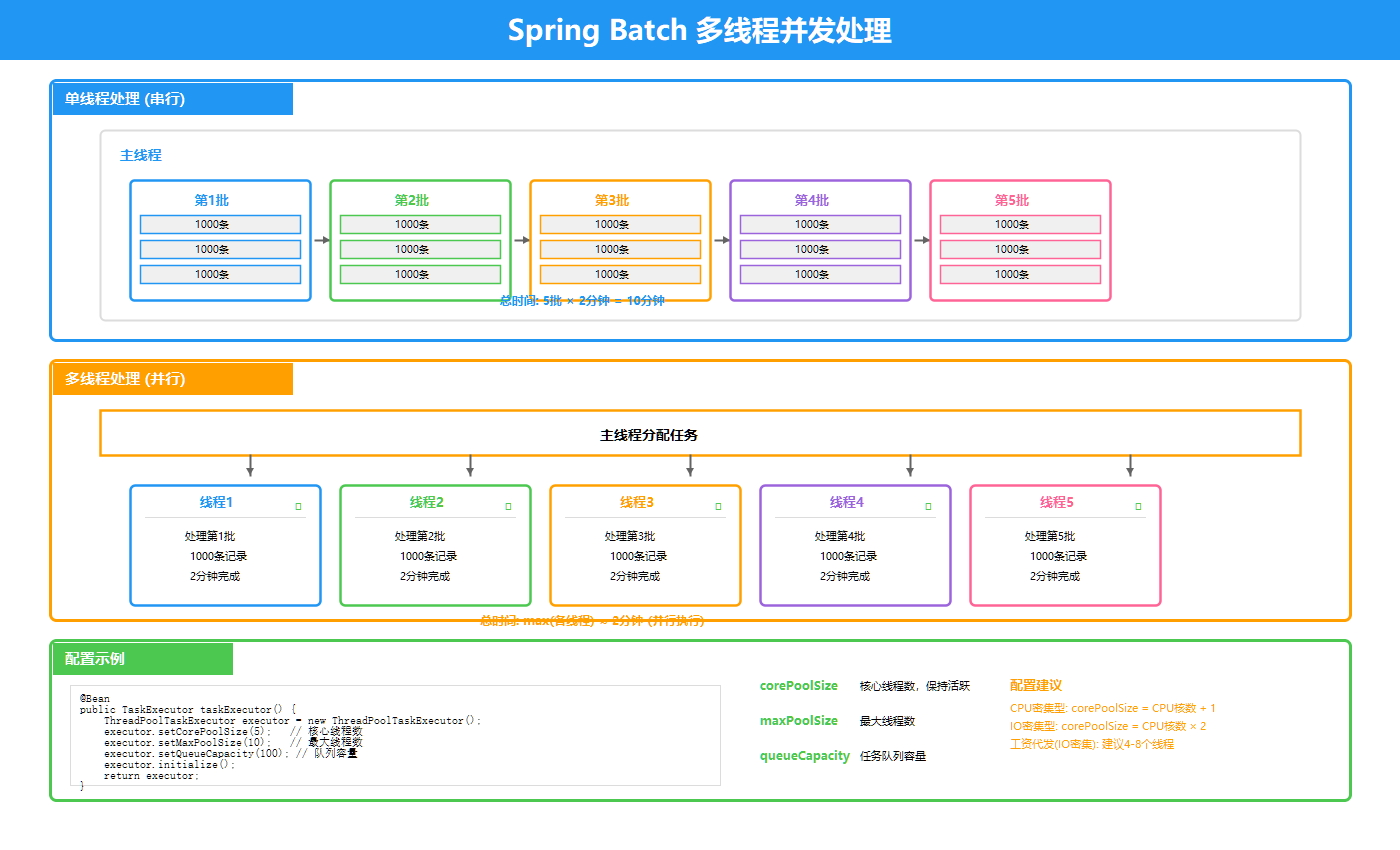
上图展示了多线程并发处理的工作原理:
核心机制:
- 主线程:创建线程池,分配任务
- 工作线程:并发执行多个Step或Chunk
- 线程安全:JobRepository保证线程安全的状态管理
- 负载均衡:任务均匀分配到各个线程
配置示例:
@Bean
public TaskExecutor taskExecutor() {
ThreadPoolTaskExecutor executor = new ThreadPoolTaskExecutor();
executor.setCorePoolSize(5);
executor.setMaxPoolSize(10);
executor.setQueueCapacity(100);
executor.setThreadNamePrefix("salary-batch-");
executor.initialize();
return executor;
}
// 在Step中使用
.step(stepName)
.chunk(chunkSize)
.taskExecutor(taskExecutor())
.throttleLimit(10) // 限制并发数
.build();
9.2 分区处理(Partitioning)
对于超大数据集,可以使用分区处理实现更高程度的并行:
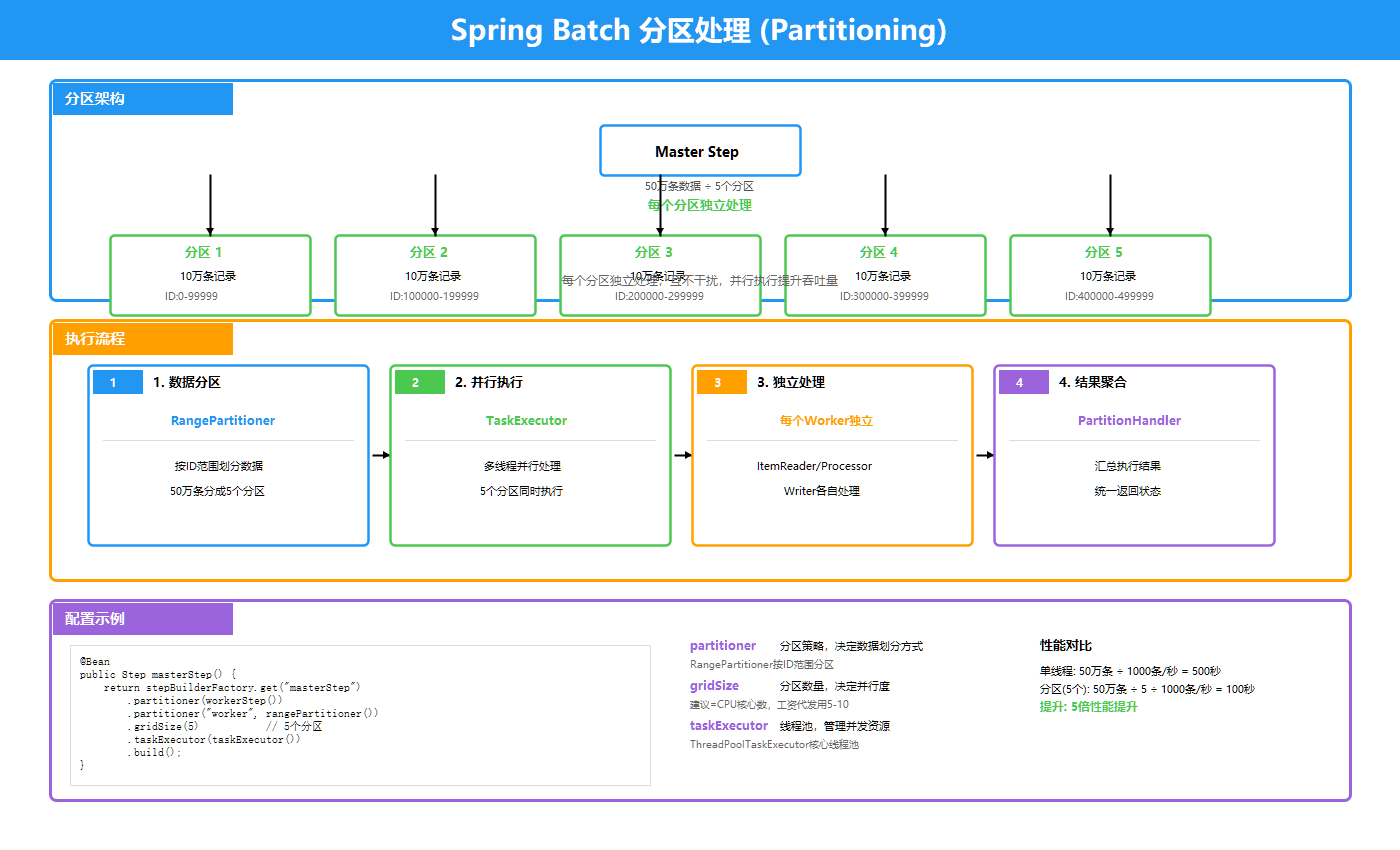
上图展示了分区处理的架构:
核心组件:
- Master Step:负责创建和管理分区
- Slave Step:每个分区独立执行
- Partitioner:将数据分成多个分区
- TaskExecutor:线程池执行分区任务
配置示例:
@Bean
public Step masterStep() {
return stepBuilderFactory.get("masterStep")
.partitioner(slaveStep().getName(), rangePartitioner(1, 10))
.step(slaveStep())
.gridSize(10) // 分成10个分区
.taskExecutor(taskExecutor())
.build();
}
@Bean
public Partitioner rangePartitioner(int min, int max) {
return new Partitioner() {
@Override
public Map<String, ExecutionContext> partition(int gridSize) {
Map<String, ExecutionContext> result = new HashMap<>();
int range = (max – min) / gridSize;
for (int i = 0; i < gridSize; i++) {
ExecutionContext context = new ExecutionContext();
context.putInt("minValue", min + i * range);
context.putInt("maxValue", min + (i + 1) * range – 1);
result.put("partition" + i, context);
}
return result;
}
};
}
9.3 调优参数
| chunkSize | 1000-5000 | 根据记录大小调整,越大吞吐量越高但内存占用也越大 |
| skipLimit | 100-500 | 根据数据质量设置 |
| retryLimit | 3-5 | 过多会浪费时间,过少可能误判暂时性故障 |
| 线程池大小 | CPU核心数*2 | 用于多线程处理 |
9.4 批量写入优化
使用JDBC批量操作代替单条插入:
// 单条插入(慢)
for (SalaryPayment p : payments) {
jdbcTemplate.update(sql, p.getId(), p.getName(), ...);
}
// 批量插入(快)
jdbcTemplate.batchUpdate(sql, new BatchPreparedStatementSetter() {
@Override
public void setValues(PreparedStatement ps, int i) throws SQLException {
// 设置参数
}
@Override
public int getBatchSize() {
return payments.size();
}
});
9.5 索引优化
— 为常用查询字段添加索引
CREATE INDEX idx_employee_id ON salary_payment(employee_id);
CREATE INDEX idx_status ON salary_payment(status);
CREATE INDEX idx_create_time ON salary_payment(create_time);
— 复合索引
CREATE INDEX idx_status_employee ON salary_payment(status, employee_id);
十、实际应用场景
场景1:月底工资代发
某公司月底需要为50,000名员工发放工资,使用Spring Batch:
- 设置chunkSize=1000,分成50个Chunk处理
- 假设第23个Chunk中第23,456号员工银行卡号错误
- 系统重试3次后跳过该记录
- 最终结果:49,999笔成功,1笔记录到失败列表供后续处理
场景2:银行对账文件处理
银行提供100万笔交易对账文件:
- 设置chunkSize=5000,提高处理效率
- 使用多线程并发处理(Partitioning)
- 完成后生成对账差异报告
场景3:数据报表生成
每天凌晨生成T+1交易报表:
- 使用Spring Task定时调度
- 读取当日交易数据
- 生成Excel报表并发送邮件
十一、常见问题与解决方案
Q1: Job执行一半挂了怎么办?
Spring Batch支持Job重启。通过JobRepository记录的执行状态,可以从上次失败的位置继续执行:
.job(salaryPaymentJob)
.allowStartIfComplete(false) // 已完成的Job不重新执行
.restartable(true) // 允许重启
Q2: 如何实现并行处理?
使用Partitioning方式实现多线程并行处理:
@Bean
public Step masterStep() {
return stepBuilderFactory.get("masterStep")
.partitioner(slaveStep().getName(), partitioner())
.step(slaveStep())
.gridSize(10) // 分成10个分区并行处理
.taskExecutor(taskExecutor())
.build();
}
Q3: 处理失败的数据如何重试?
可以通过以下方式重试:
十二、总结
Spring Batch作为成熟的批处理框架,提供了完整的解决方案来处理大规模批量数据。
适用场景:
- 银行对账、清算
- 工资代发、批量转账
- 报表生成、数据导出
注意事项:
- 合理设置chunkSize,平衡内存和性能
- 配置合适的Skip和Retry策略
- 做好失败记录的重处理机制
- 定期清理Job执行历史数据








评论前必须登录!
注册