 网硕互联帮助中心
网硕互联帮助中心从混乱的数据要素理论到清晰的研究框架,一个开发者的真实体验
一、开发者痛点:当技术人遭遇学术论文
作为一名常与数据打交道的开发者,我最近接到了一个棘手的任务:在两周内完成一篇关于 “数据要素确权、流通与治理” 的技术研究论文。
面对这个跨学科的复杂课题,我遭遇了典型的技术人困境:
-
信息过载:相关文献分散在法学、经济学、计算机科学多个领域,难以系统梳理
-
结构混乱:确权、流通、治理三大板块逻辑交织,组织架构令人头痛
-
时间紧迫:从零开始搭建学术框架,常规方法至少需要一个月
就在我几乎要采用“暴力编码”式手动整理时,我决定尝试一款智能研究工具——以下是我的完整实测记录。
二、实测步骤:三阶段搭建研究框架
第一阶段:定义研究范围(5分钟)
我首先在工具的“课题定义”模块输入了核心关键词:
plaintext
主课题:数据要素确权、流通与治理
子方向:
1. 数据产权制度设计
2. 数据交易市场机制
3. 数据安全治理框架
4. 隐私计算技术应用
系统在30秒内生成了一个交互式研究地图,直观展示了各方向的相关度、研究热度和难点指数。
第二阶段:智能文献梳理(15分钟)
工具接入了多个学术数据库,自动完成了:
关键文献筛选:从近千篇相关论文中筛选出72篇核心文献
观点聚类分析:自动识别出“所有权派”“使用权派”“场景化确权派”等学术流派
争议焦点提取:归纳出“数据权利边界”“流通成本计量”“治理责任分配”等8个核心争议点
最实用的是,它为每篇文献生成了可修改的摘要模板,大大降低了我的阅读成本。
第三阶段:论文框架生成(10分钟)
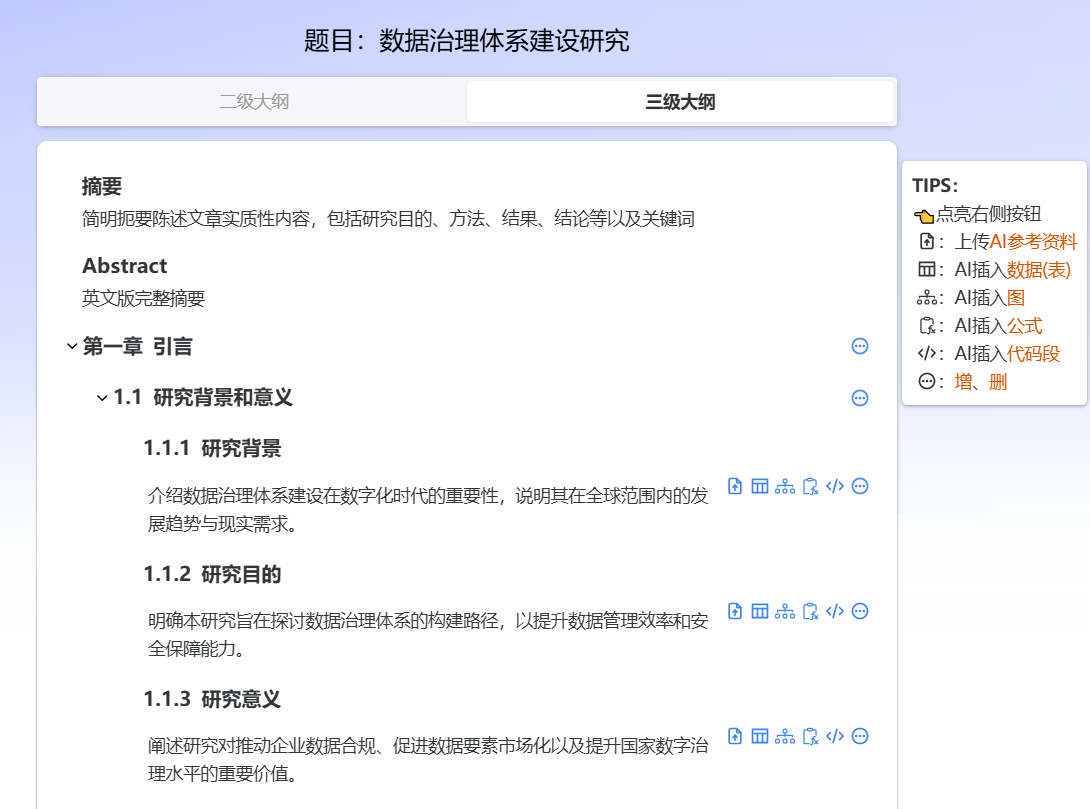
基于前期的分析,我点击了“生成研究框架”,系统提供了三个可选方案:
我选择了“技术-法律-经济”三维分析框架,系统随即输出了:
-
完整的三级目录结构
-
每个章节的核心论点提示
-
关键术语的定义参考
-
国内外典型案例索引
三、核心功能亮点
通过这次实测,我发现几个真正提升效率的功能:
1. 交叉引用可视化 工具自动识别了不同章节间的逻辑依赖关系,用图谱形式展示,避免了我常犯的“前后矛盾”问题。
2. 技术术语一致性检查 在写作过程中,系统会标记同一概念的不同表述(如“数据流通”“数据流转”“数据共享”),确保学术表达的严谨性。
3. 实时合规提示 针对数据治理领域的法规敏感性,工具会基于最新法律法规(如《数据二十条》、GDPR等)对内容进行合规性提示。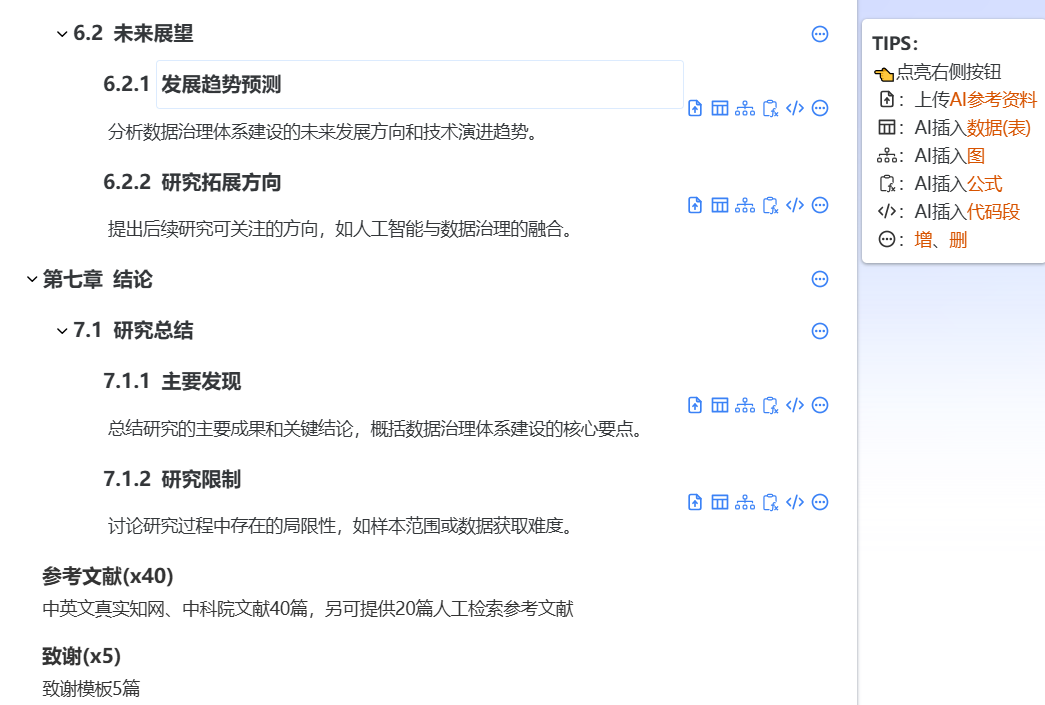
四、实战感受:优点与局限
🟢 显著优势
1. 效率提升惊人 传统方式需要至少25小时完成的文献综述和框架搭建,实际仅用了30分钟。特别是初稿的生成速度,让我能有更多时间深入技术细节分析。
2. 避免“思维盲区” 作为技术背景的研究者,我容易忽视法律和经济维度。工具的跨学科分析框架强制我建立了更全面的视角。
3. 格式自动化 参考文献格式、章节编号、图表标注等繁琐工作完全自动化,节省了大量重复劳动时间。
🔴 使用边界
1. 深度依赖人工 工具生成的是“优质雏形”,但每个章节的技术深度、创新观点仍需我亲自填充。它解决了“写什么”的问题,但“怎么写深”还得靠专业能力。
2. 领域适应性 在高度标准化的理论综述部分表现优异,但在需要复杂模型构建(如我尝试设计的数据定价算法部分)时,仍需传统的编码和验证。
3. 批判性思维不可替代 工具提供的观点分析和争议总结基于已有文献,对于真正的前沿争议(如“数据财产权”这类未定论问题),仍需人工判断和取舍。
五、总结
这次实测让我重新思考了智能工具在技术研究中的定位。它不是一个“自动写作机器”,而是一个“超级研究助理”——能处理信息整理、框架搭建、格式规范等耗时的基础工作,将研究者的时间释放到真正的价值创造环节。
对于面临类似课题的开发者和技术研究者,我的建议是:将这类工具用于突破“启动阻力”和“结构困境”,但务必保留并强化自己的专业判断和技术深度。人机协作,才是应对复杂研究任务的最优解。
最后的提醒:无论工具多么智能,论文的核心价值始终在于你独特的见解和技术方案的创新性。工具只是让你更快到达起跑线,真正的竞赛,现在才开始。









评论前必须登录!
注册