 网硕互联帮助中心
网硕互联帮助中心
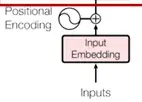
步骤1:位置嵌入与词映射
import torch
import torch.nn as nn
import math
class TransformerInput(nn.Module):
def __init__(self, vocab_size, d_model, max_len=5000):
super().__init__()
# 1. Embedding 层:将单词索引转为 512 维向量
self.embedding = nn.Embedding(vocab_size, d_model)
# 2. Positional Encoding:生成位置偏置
pe = torch.zeros(max_len, d_model)
position = torch.arange(0, max_len, dtype=torch.float).unsqueeze(1)
# 使用正余弦公式:PE(pos, 2i) = sin(pos/10000^(2i/d_model))
div_term = torch.exp(torch.arange(0, d_model, 2).float() * (-math.log(10000.0) / d_model))
pe[:, 0::2] = torch.sin(position * div_term)
pe[:, 1::2] = torch.cos(position * div_term)
self.register_buffer('pe', pe.unsqueeze(0)) # 固定权重,不参与训练
def forward(self, x):
# x 形状: [batch_size, seq_len] -> 词向量: [batch_size, seq_len, 512]
x = self.embedding(x) * math.sqrt(x.size(-1)) # 缩放以匹配 PE 强度
# 直接相加:图中那个圈圈里的 "+" 号
x = x + self.pe[:, :x.size(1)]
return x
相比传统 RNN 的逐词输入,Transformer 的输入是一整句话。为了区分每个词的位置信息,需要给它加上位置编码。
注意:vocab_size 涉及到句子解码所涉及的 token 量,即 BPE 算法最终停步的限制值。但是 Embedding 这个从 token 映射到向量的步骤是需要训练的。
| 组件名称 | 来源 | 是否涉及 Transformer 训练 | 比喻 |
| 词表 (Vocabulary) | 统计算法 (Tokenizer) 扫描语料库 | 否 (预处理阶段完成) | 字典的目录(决定了书里收录哪些字) |
| vocab_size | 人为设定的阈值 | 否 (配置参数) | 字典的厚度(决定了字典能查多少个字) |
| Embedding 矩阵 | nn.Embedding | 是 (核心训练对象) | 对字的理解(一开始瞎猜,越学越懂) |
| d_model | 人为设定的宽度 | 否 (配置参数) | 脑容量(用多少个脑细胞去记一个词) |
| 位置编码 (PE) | sin cos 数学公式 | 否 (固定参数) | 页码(无论书写什么内容,页码永远是 1, 2, 3…) |
步骤2:编码器部分(旁边的 Nx 表示可以组装 N 个编码器)
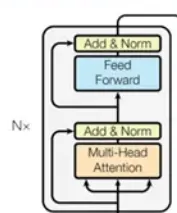
对于这个小灰框,我们认为是一层的 Encoder,称为 EncoderLayer,包含两个子层(多头注意力 + 前馈 FFN)。每个子层后都包含了层归一与残差链接。
import torch
import torch.nn as nn
import copy
# 辅助函数:用于克隆 N 个相同的层(后面构建 Encoder 时用到)
def clones(module, N):
return nn.ModuleList([copy.deepcopy(module) for _ in range(N)])
class EncoderLayer(nn.Module):
def __init__(self, d_model, num_heads, d_ff, dropout=0.1):
"""
初始化单层编码器
:param d_model: 词向量维度 (例如 512)
:param num_heads: 多头注意力的头数 (例如 8)
:param d_ff: 前馈神经网络的中间层维度 (例如 2048)
:param dropout: 丢弃率,防止过拟合
"""
super().__init__()
# — 子层 1: 多头自注意力 —
# 对应图中: Multi-Head Attention
self.self_attn = MultiHeadAttention(d_model, num_heads)
# — 子层 2: 前馈神经网络 —
# 对应图中: Feed Forward
self.feed_forward = PositionwiseFeedForward(d_model, d_ff)
# — 连接组件 —
# 对应图中: Add & Norm (有两个,分别跟在两个子层后面)
self.norm1 = nn.LayerNorm(d_model)
self.norm2 = nn.LayerNorm(d_model)
# Dropout (放在残差连接相加之前)
self.dropout = nn.Dropout(dropout)
def forward(self, x, mask):
"""
前向传播逻辑
:param x: 输入数据 [batch_size, seq_len, d_model]
:param mask: 掩码矩阵 (用于屏蔽 PAD token)
"""
# — 步骤 1: Self-Attention + Add + Norm —
# 1.1 保留原始输入用于残差连接 (Residue)
residual = x
# 1.2 执行多头注意力
# 注意:Encoder 中 Q, K, V 全部来源于同一个 x (所以叫"自"注意力)
x_attn = self.self_attn(x, x, x, mask)
# 1.3 Dropout + Add (残差连接) + Norm
# 公式: LayerNorm(x + Sublayer(x))
x = self.norm1(residual + self.dropout(x_attn))
# — 步骤 2: Feed Forward + Add + Norm —
# 2.1 再次保留当前状态用于残差连接
residual = x
# 2.2 执行前馈网络
x_ff = self.feed_forward(x)
# 2.3 Dropout + Add + Norm
x = self.norm2(residual + self.dropout(x_ff))
return x
多头注意力实际上就是使用三个矩阵对输入进行线性变换(矩阵乘法)。
import torch
import torch.nn as nn
import math
class MultiHeadAttention(nn.Module):
def __init__(self, d_model, num_heads):
super().__init__()
assert d_model % num_heads == 0
self.d_k = d_model // num_heads # 64
self.num_heads = num_heads # 8
self.d_model = d_model # 512
# 【关键点1】定义参数矩阵
# 注意:这里定义的是"所有头加起来"的大矩阵
# W_q, W_k, W_v 的形状都是 [512, 512]
self.linear_q = nn.Linear(d_model, d_model)
self.linear_k = nn.Linear(d_model, d_model)
self.linear_v = nn.Linear(d_model, d_model)
# 最后输出的线性层 W_o
self.linear_out = nn.Linear(d_model, d_model)
def forward(self, query, key, value, mask=None):
batch_size = query.size(0) # 32
# — 第一步:线性投影 + 切分头 —
# 1. 线性变换: [32, 10, 512] * [512, 512] -> [32, 10, 512]
# 2. view重塑: -> [32, 10, 8, 64] (把 512 拆成 8 * 64)
# 3. transpose转置: -> [32, 8, 10, 64] (交换 seq_len 和 num_heads 维度)
# 为什么要转置?因为我们要让 Attention 发生在 seq_len 维度上,
# 把 num_heads 放到前面,PyTorch 就会把它们当成独立的"批次"并行计算。
Q = self.linear_q(query).view(batch_size, -1, self.num_heads, self.d_k).transpose(1, 2)
K = self.linear_k(key).view(batch_size, -1, self.num_heads, self.d_k).transpose(1, 2)
V = self.linear_v(value).view(batch_size, -1, self.num_heads, self.d_k).transpose(1, 2)
# — 第二步:缩放点积注意力 (Scaled Dot-Product Attention) —
# Q: [32, 8, 10, 64]
# K.T: [32, 8, 64, 10] (最后两个维度转置)
# Matmul: [32, 8, 10, 10] -> 得到每个头内部的词与词的关系分数
scores = torch.matmul(Q, K.transpose(-2, -1)) / math.sqrt(self.d_k)
if mask is not None:
scores = scores.masked_fill(mask == 0, -1e9)
attn_weights = torch.softmax(scores, dim=-1) # [32, 8, 10, 10]
# 加权求和: [32, 8, 10, 10] * [32, 8, 10, 64] -> [32, 8, 10, 64]
context = torch.matmul(attn_weights, V)
# — 第三步:拼接头 (Concat) —
# transpose: -> [32, 10, 8, 64] (把 seq_len 换回来)
# contiguous().view: -> [32, 10, 512] (把 8 和 64 重新粘合在一起)
context = context.transpose(1, 2).contiguous().view(batch_size, -1, self.d_model)
# — 第四步:最终线性变换 —
return self.linear_out(context)
要点:自注意力的“自“的单位是句子,因此编码器 layer 中 x_attn = self.self_attn(x, x, x, mask),实际上输出了句子中每个 token 对其它 token 的注意力响应。
输入张量,形状:[32, 8, 10, 64]
| 维度索引 | 维度名称 | 示例值 | 解释与交互情况 |
| Dim 0 | batch_size | 32 | 独立的样本索引。 代表 32 个毫无关系的句子同时处理(例如句子 A 和句子 B)。 |
| Dim 1 | num_heads | 8 | 语义子空间。 将 512 维拆分成 8 组,每组关注不同特征(如 Head 1 看语法,Head 2 看指代)。 |
| Dim 2 | seq_len | 10 | 词的位置。 代表句子里的具体哪个词(如第 3 个词“爱”)。 |
| Dim 3 | d_k | 64 | 特征属性向量。 描述该词在当前视角下的具体属性(如“我是红色的”或“我是名词”)。Q 和 K 在此维度进行点积,算出匹配分数。 |
d_k 实际上就是对词向量的分割。因为希望让注意力的每个头能针对不同的语义做观察,将词向量 d_model 分为“注意力头”数个子向量 d_k = d_model // num_heads。
拆解视角:将待训练的句子用一个 32 * 10 维的表格,其中,句子总数是 32(一个 batch),每个句子长度固定为 10(seq_len)。表格中的每个各自填写了一个 8 * 64 维的表格用于表示一个词。
QKV 的形状分析:$W_{Q,K,V} = [512 * 512]$, 变换后的 $Q,K,V = [32, 8, 10, 64]$。
$W_{Q,K,V} = [512 * 512]$ 是对输入的线性变化,不考虑意义的情况下,就是矩阵乘法。为了匹配每个词的特征向量长度且转换不丢失语义,因此变化矩阵大小同词向量长度匹配。
$Q,K,V = [32, 8, 10, 64]$ 是经过上述变化后的结果。32 为 batch 中包含的句子数量,10 为确定的句子长度。有区别的是 8 * 64 的向量含义。QKV 分别对应的是 Q: 一个词向外查询的内容, K: 一个词包含的语义,V: QK 会导致的信息收益。(以上为个人理解)
注意,乘积结果的原始 QKV 是 $Q,K,V = [32, 10, 512]$,接下来简单分割维度就可以得到 $Q,K,V = [32, 8, 10, 64]$。
QK 碰撞的结果
| 操作步骤 | 输入形状 | 变换后形状 | 物理意义变化 |
| 1. 准备 |
Q: [32, 8, 10, 64]
K: [32, 8, 10, 64] |
K 转置为:
[32, 8, 64, 10] |
为了让 K 的特征维度 (64) 对齐 Q 的特征维度,准备进行点积。 |
| 2. 碰撞 (Matmul) | Q $\\times$ Kᵀ | [32, 8, 10, 10] | 维度 64 被消耗 (求和) 掉了。剩下的 [10, 10] 是 Attention Map (注意力图)。 |
| 3. 结果解读 | Score[b, h, i, j] | (标量数值) | 关注度 / 权重。 代表第 b 个句子的第 h 个视角下,第 i 个词对第 j 个词的关注程度。例如:Score("it", "animal") = 0.9 (高度关注)。 |
将 QK 进行碰撞(矩阵乘法),得到了一个 [32, 8, 10, 10] 的矩阵,这个矩阵前两个标识是哪一个句子的那一个关注点,后两个 10 表示单个句子的任意两个词之间的关系强弱。
为了让这个关系表现为概率,注意对其进行 Softmax。
基于这个关系强弱的关系:score = [32, 8, 10, 10], 我们需要基于 Value 获得真正的语义信息,即有:
# [10, 10] * [10, 64] -> [10, 64]
context = torch.matmul(attn_weights, V)
前两个维度的 batch 中句子总数和注意力头数不变,后面变成了句子中每个词所携带的其他词赋予的语义量(例如代词 "it" 原本的输入特征只有其本身的“它”,现在和句子中其它词例如“dog”的 value 乘了下,现在 "it" 也包含 "dog" 的语义信息了)。
最后提供给下一层 FFN 的语义信息为:
# [32, 8, 10, 64] -> 转置 -> [32, 10, 8, 64]
# view -> [32, 10, 512] (8 * 64 = 512)
context = context.transpose(1, 2).contiguous().view(batch_size, -1, self.d_model)
# — 第四步:最终线性变换 —
return self.linear_out(context)
首先进行直接的多头拼接,但是这种拼接太硬了,因此使用一个线性层(矩阵乘法)做形状不变的仿射变换(乘以一个 [512, 512] 的矩阵,语义矩阵的形状不变,但是具体语义信息有一定的融合)。
汇总下数据形状的变化:
-
输入一个 batch 的句子:input[32, 10, 512] (32 句话, 每个句子长度 10 token,每个 token 的语义用 512 维的语义向量表示)。
-
输入到多头(假设 8 个头)注意力层。
-
通过三个仿射变换获得不同用途的词语语义 Q, K, V 三个语义矩阵都是由 [512 * 512] 大小的三个变换阵乘出来的。然后对于输出的 QKV 拆分到将语义切分为 input_multi[32, 8, 10, 64] (32 句话,需要关注 8 个维度的语义, 每个句子长度 10 token,每个 token 的在某个维度的语义用 64 维的语义向量表示)。
-
之后通过 Q, K 碰撞得到词与词之间的关系分数 Score[32, 8, 10, 10],这个 Score 会再和 V 做乘积以通过其它词语的语义来得到某个词的表达 context[32, 8, 10, 64]。
-
最后将 context 各维度拼接,转为 [32, 10, 512],接着为了防止拼接过于生硬,通过一层反射变换(与一个 [512, 512] 的矩阵做乘积)得到橙色部分的输出 Atten_out[32, 10, 512]。
-
将输入 input[32, 10, 512] 和输出 Atten_out 相加然后进行正态分布归一化,最后在进行一次缩放平移以弥补归一化导致的语义损失。(缩放平移是在做逐元素乘法,不是很清楚弥补的能力,应该是消融实验结果)输出到 FFN 的输入形状保持为 [32, 10, 512]。这部分耗时基本可忽略。
-
FFN 就是两个基本线性层,原始操作是先升为 2048 维,然后降回 512 维:[32, 10, 512] → [32, 10, 2048] → [32, 10, 512]。
-
之后对于线性层输出内容,重新输回第一步,重复 N 次后进入解码器。
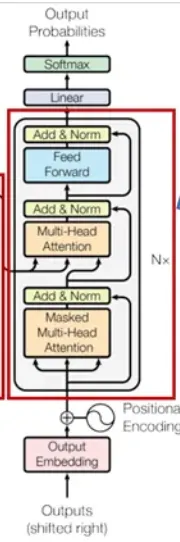
步骤3:解码器部分
import torch
import torch.nn as nn
from copy import deepcopy
class Decoder(nn.Module):
def __init__(self, layer, N):
"""
整体解码器 (由 N 个 DecoderLayer 堆叠而成)
"""
super().__init__()
# 克隆 N 个 DecoderLayer
self.layers = nn.ModuleList([deepcopy(layer) for _ in range(N)])
self.norm = nn.LayerNorm(layer.norm1.normalized_shape[0])
def forward(self, x, enc_output, src_mask, trg_mask):
"""
:param x: 经过 Embedding + Positional Encoding 后的目标序列输入
:param enc_output: Encoder 的输出结果 (Memory)
"""
# 串行流经每一层
for layer in self.layers:
x = layer(x, enc_output, src_mask, trg_mask)
return self.norm(x)
第一部分:底部 outputs 输入模型
这个地方和 RNN 一样,首先我们获得一个空序列 [<SOS>] 表示句子开始(Start of the Sentence)。
然后每一次解码过程后,顶部的 Output 输出需要加入这个序列。
一直这样重复,直到顶部 Output 输出了 <EOS> (End of Sentence)。
具体的处理方式还是和之前的编码器部分一样,加上位置编码,然后输入到多头中。
需要注意的是,训练过程中这个 outputs 不是动态生成的,而是一个字一个字漏给模型看,并行训练(应该是并行,每个批次更新一次参数)。
第二部分:掩码注意力
在编码器中的句子内容是我们的输入的 prompt,这个解码器部分的句子内容是输出句子(LLM 的回复)。模型的其它超参数都是一致的,只有 Seq_len 不同(就是之前是 10 的那个参数)。
假设它现在是 4。
重新列一遍参数:
-
Batch Size (B): 32 (一次并行处理 32 句话)
-
Seq Len (L): 4 (假设这句话是 [<SOS>, A, B, C])
-
d_model (D): 512
-
Heads (H): 8
-
d_k: 64
前面 QKV 生成过程还是一样的,具体的形状变换过程如下:
Input: [32, 4, 512] → W_{Q,K,V}: [512, 512] ⇒ Q,K,V: [32, 4, 512] → 多头划分:[32, 8, 4, 64]
然后计算 Score = Q × K^t : [32, 8, 4, 4]。
这一步里面需要使用掩码。
这个 Score 表示的是当前行索引的对应词汇对列索引的词汇的相关度。
但是现在的词汇不能看到后面还未生成的词汇。掩码逻辑参考以下内容:
Mask 矩阵
SOS A B C
SOS [[ 0, 1, 1, 1 ], <- 遮挡 A, B, C
A [ 0, 0, 1, 1 ], <- 遮挡 B, C
B [ 0, 0, 0, 1 ], <- 遮挡 C
C [ 0, 0, 0, 0 ]] <- 全都能看
Score 矩阵中掩码为 1 的地方设置为 -1e9 (极小值)。
因此变换后的 Score 矩阵大概如下:
SOS A B C
SOS [[ 2.5, -1e9, -1e9, -1e9 ], <- 后面全废了
A [ 1.8, 3.2, -1e9, -1e9 ],
B [ 0.5, 1.5, 2.8, -1e9 ],
C [ 0.2, 0.4, 1.2, 3.0 ]]
对每一行 Softmax 后, 极小值就转为概率 0 了。
然后和之前一样,Score × V = context[32, 4, 512]。
第三部分:编码器交互的多头注意力 (交叉注意力,区别于之前的自注意力)
参考原始的注意力三个矩阵:
-
Q:目前的问题
-
K:目前可以参考的信息
-
V:句子中各个词对应的含义
# x: 解码器目前的进度 (比如说已经生成了前3个词)
# enc_output: 编码器输出的记忆 (也就是原文的完整理解)
x = self.cross_attn(q=x, k=enc_output, v=enc_output, mask=src_mask)
假设最终的 Ground Truth 是“我爱你!”,然后 LLM 已经输出了“我”。
现在需要解答的问题是:下一个字符应该输出什么,因此需要输入已有的输出作为查询也就是目前输出的 “<SOS> 我”。
那么作为参考的应该是你输入的 prompt(要输出“我爱你”大约是输入了“你爱我吗?”这种 input)。
然后我需要的语义也是从原始输入中拿的。
所以 Q=x(当前输出一半的内容),KV 都是 encoder 在经过 N 层后的原始输入。
来看看张量形状:
之前说到 Encoder 的输出按照设定是 [32, 10, 512]。
这里的 x 虽然没生成完,但是也会被填充到预期的大小,是 [32, 4, 512]。
然后我们 QKV 还是和之前一样使用 [512, 512] 大小的转换矩阵。那么得到:
-
Q:[32, 4, 512]
-
K:[32, 10, 512]
-
V:[32, 10, 512]
然后我们 $QK^T$ 得到 score [32, 4, 10]。
对于 prompt 中的填充部分(一句话长度还不到 10,剩下的用 <PAD> 填充)用极小值进行填充。
对于 decoder 的输出,由于上一步的掩码操作,这一步 decoder 内容不需要重新掩码,直接沿用上一轮的上下文结果即可。
这样我们就得到了 Q 中每个字符对应 K 中每个字符的相关性了。
Transformer 强大的地方在于,只要词的向量表示维度相同,那么交叉注意力可以捕获两个任意长序列的每个词之间的相关性。
最终我们乘上 V 矩阵,得到了 context[32, 4, 512], 也就是这句话中的每个词所包含的内容含义。
第四部分:FFN
和编码器部分 FFN 的逻辑完全一致,首先进行直接的多头拼接,但是这种拼接太硬了,因此使用一个线性层(矩阵乘法)做形状不变的仿射变换(乘以一个 [512, 512] 的矩阵,语义矩阵的形状不变,但是具体语义信息有一定的融合)。
最后输出了一个平滑厚的 context[32, 4, 512]。
步骤4:最终线性层与分类输出
最后一层的交叉注意力我们获得了 context[32, 4, 512],其具体含义是:
-
这个 batch 中的句子个数:32
-
每个句子在填充后的 token 定长:4
-
每个 token 的语义向量:512(融合了这个 token 对其它 token 的语义摄入,这里的 "it" 或 "你我他" 不是简单代词了,已经融合了它具体指带的对象的语义)。
此时我们做一次线性映射,把这个句子 4 个 token 的语义向量映射到词表大小:
-
pred_result: [32, 4, 30000] 表示每个位置的词为词表中某个词的概率,概率最高的那个词即为结果。
-
ground_truth: [32, 4, 1] → 推广到 30000 维,即只有正确的词为 1,其余为 0 → [32, 4, 30000]。









评论前必须登录!
注册