 网硕互联帮助中心
网硕互联帮助中心POSIX信号量
POSIX信号量和SystemV信号量作用相同,都是用于同步操作,达到无冲突的访问共享资源目的。但是SystemV信号量是早期的UNIX进程间通信的机制,偏内核,适合多进程,而POSIX信号量是POSIX 标准定义的轻量级同步原语,简单直观,适合多线程编程。
初始化信号量
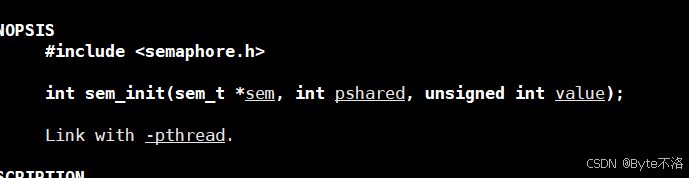
- sem
- 要初始化的信号量对象地址(和线程创建时调用的函数pthread_create中的第一个参数类似,通过指针返回线程ID,这里是对信号量这个对象进行初始化。)
- pshared
- 0:线程间共享(最常用)
- 非 0:进程间共享
- value
- 信号量初始值(资源个数)
销毁信号量
- sem:要销毁的信号量对象地址
等待信号量
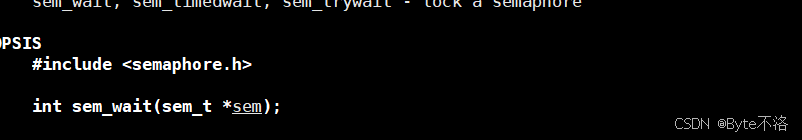
这个就相当于我们在学习操作系统中的P操作,当信号量的值大于0,对其进行减一;当信号量的值等于0,进行阻塞等待。
-
sem:要操作的信号量对象地址
归还信号量

同理,这个就相当于操作系统中的V操作,将信号量的值进行加一,如果此时有线程正在等待信号量,这个时候唤醒其中的一个即可。
- sem:要操作的信号量对象地址
在之前我们就对信号量有所了解,信号量的本质是一把计数器,用来描述临界资源中资源数量的多少。也就是我们的多线程在申请共享资源时,不是直接去拿共享资源,它首先会对这个共享资源进行预定,通过先申请这个信号量成功之后,就保证了这个共享资源已经被该线程获取到了(用看电影的例子进行对比就是,电影院所有的座位就是信号量的值,我们想要获取其中的一个座位去看电影,不是说我们做到位置上,这个位置就属于我们,而是我们必须先进行买票,买票的这个行为就是我们在申请信号量,当我们成功购买了票之后(成功申请到信号量),意味着我们这个座位才是我们),因此多线程在进行数据访问的时候,我们会先通过信号量记录所有的共享资源,如果又线程想要访问该数据,先得申请信号量,然后才可以对该数据进行访问。
信号量的申请(sem_wait)和释放(sem_post)操作是原子的。也就是说,当多个线程同时申请或释放同一个信号量时,操作会被内核保证一次只被一个线程完整执行,不会出现资源计数错误或竞争条件。这样就可以保证信号量申请和释放的完整性,保证了信号量的安全。
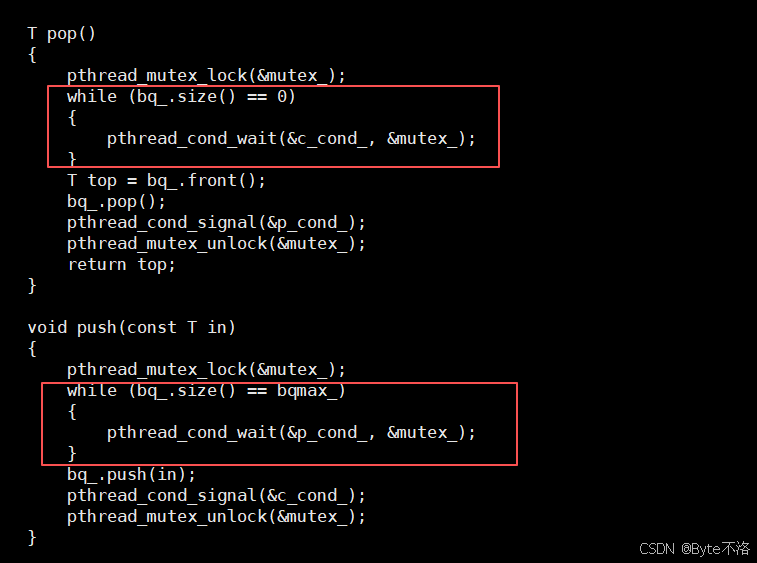
在之前我们的基于阻塞队列的生产者消费者模型中,为了保证访问临界资源的安全,我们必须先进行上锁,然后再进行判断是否资源的数量是否满足,如果满足,继续执行;不满足,阻塞等待。但是现在信号量不一样了,因为信号量本来就是表示资源的数量,只要我们申请信号量成功了,就表明资源一定是就绪的,这个时候我们就不需要再进行资源是否满足的判断了,这就是信号量的好处,只要申请到信号量,资源就一定有。
在上一篇博客中我们基于queue,通过互斥锁+条件变量的方式实现了一个生产者消费者模式,现在,我们基于环形队列,通过信号量的方式再次实现一个生产者消费者模式。
RingQueue:环形队列
环形队列简介
环形队列本质上是一个固定大小的数组,通过取模运算让下标首尾相连,从而实现逻辑上的“循环”。
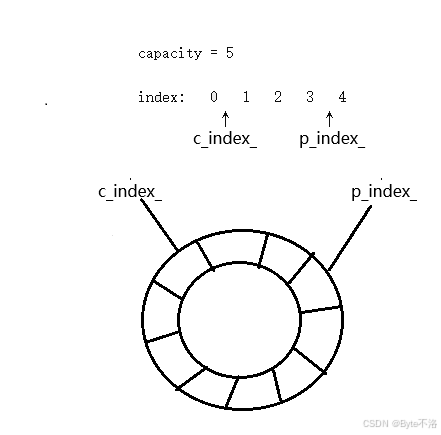
示意如下:
-
p_index_:生产者写入位置
-
c_index_:消费者读取位置
通过数组来模拟实现环形队列,当队列为满和为空时。生产者和消费者的索引会处于同一位置;当队列为空时,这个时候只有生产者生产数据之后,消费者才可以进行消耗数据;同时,当队列为满的时候,只有消费者消耗数据之后,生产者才可以继续生产数据。但是生产者和消费者关注的数据不一致,生产者关注的是队列中还有几个空位,而消费者关注的是队列中还有多少数据,就好比生活中,供货商不会关心超市的东西还有多少,它们只会关心超市现在空下来多少位置,它好继续供货,同样我们去超市购物的时候,不会关心超市空下多少位置了,只会关心我想要的东西还有没有。
核心数据结构设计
环形队列类中通常包含以下关键成员:
-
存储数据的容器(std::vector<T> rq_)
-
队列容量(capacity)
-
生产者下标(p_index_)
-
消费者下标(c_index_)
-
同步原语:
-
空位信号量(p_sem_)
-
数据信号量(c_sem_)
-
生产者互斥锁(p_mutex_)
-
消费者互斥锁(c_mutex_)
-
空位信号量(p_sem_)
sem_init(&blank_sem, 0, capacity);
因为在初始化的时候,环形队列中都是空位,没有一个数据,所以这个时候空位信号量初始化的值设置为环形队列的大小
作用:
-
当队列已满时,生产者会在该信号量上阻塞
-
保证不会向满队列中写入数据
数据信号量(c_sem_)
sem_init(&data_sem, 0, 0);
同样,在初始化的时候,环形队列中是没有数据的,所以这个时候数据信号量在进行初始化的时候将其设置为0;
作用:
-
当队列为空时,消费者会在该信号量上阻塞
-
保证不会从空队列中读取数据
完整代码
基于信号量的环形队列
template <class T>
class RingQueue
{
public:
// 构造函数
// c_index : 消费者下标
// p_index : 生产者下标
// capacity: 环形队列容量
RingQueue(int c_index = 0, int p_index = 0, int capacity = 10)
: c_index_(c_index), p_index_(p_index), capacity_(capacity)
{
// 1. 初始化环形队列空间
// resize 会默认构造 capacity 个 T 对象
rq_.resize(capacity_);
// 2. 初始化信号量
// p_sem_:表示“空位资源”的数量
// 初始值为 capacity,表示一开始队列是空的,有 capacity 个空位
sem_init(&p_sem_, 0, capacity_);
// c_sem_:表示“数据资源”的数量
// 初始值为 0,表示一开始没有数据可消费
sem_init(&c_sem_, 0, 0);
// 3. 初始化互斥锁
// p_mutex_:保护生产者写入临界区
// c_mutex_:保护消费者读取临界区
pthread_mutex_init(&p_mutex_, nullptr);
pthread_mutex_init(&c_mutex_, nullptr);
}
// 生产者接口:向队列中放入一个元素
void push(const T in)
{
// 1. 申请“空位资源”
// 如果队列满了(p_sem_ == 0),生产者在此阻塞
sem_wait(&p_sem_);
// 2. 加锁,进入生产者临界区
pthread_mutex_lock(&p_mutex_);
// 3. 写入数据
rq_[p_index_] = in;
// 4. 更新生产者下标(环形)
p_index_++;
p_index_ %= rq_.size();
// 5. 解锁,退出临界区
pthread_mutex_unlock(&p_mutex_);
// 6. 通知消费者:有新的数据可以消费
sem_post(&c_sem_);
}
// 消费者接口:从队列中取出一个元素
T pop()
{
// 1. 申请“数据资源”
// 如果队列为空(c_sem_ == 0),消费者在此阻塞
sem_wait(&c_sem_);
// 2. 加锁,进入消费者临界区
pthread_mutex_lock(&c_mutex_);
// 3. 读取数据
T temp = rq_[c_index_];
// 4. 更新消费者下标(环形)
c_index_++;
c_index_ %= rq_.size();
// 5. 解锁,退出临界区
pthread_mutex_unlock(&c_mutex_);
// 6. 通知生产者:释放了一个空位
sem_post(&p_sem_);
return temp;
}
// 析构函数:释放系统资源
~RingQueue()
{
sem_destroy(&c_sem_);
sem_destroy(&p_sem_);
pthread_mutex_destroy(&c_mutex_);
pthread_mutex_destroy(&p_mutex_);
}
private:
// 存储数据的环形队列
std::vector<T> rq_;
// 消费者读取位置
int c_index_;
// 生产者写入位置
int p_index_;
// 队列容量
int capacity_;
// 数据信号量:当前可消费的数据数量
sem_t c_sem_;
// 空位信号量:当前可用的空位数量
sem_t p_sem_;
// 消费者互斥锁
pthread_mutex_t c_mutex_;
// 生产者互斥锁
pthread_mutex_t p_mutex_;
};
Task任务
class Task
{
public:
// 默认构造函数
// vector::resize 需要类型支持默认构造
Task() {}
// 带参构造函数
Task(int x, int y, char oper, int result = 0, int exitcode = 0)
: x_(x), y_(y), oper_(oper), result_(result), exitcode_(exitcode)
{
}
// 执行任务
void run()
{
switch (oper_)
{
case '+':
result_ = x_ + y_;
break;
case '-':
result_ = x_ – y_;
break;
case '*':
result_ = x_ * y_;
break;
case '/':
if (y_ == 0)
exitcode_ = 1;
else
result_ = x_ / y_;
break;
case '%':
if (y_ == 0)
exitcode_ = 2;
else
result_ = x_ % y_;
}
printf("%d %c %d = %d[%d]\\n", x_, oper_, y_, result_, exitcode_);
}
// 打印任务内容(未执行)
void getTask()
{
printf("%d %c %d = ?\\n", x_, oper_, y_);
}
private:
int x_;
int y_;
char oper_;
int result_;
int exitcode_;
};
消费者线程函数
void *Consumer(void *args)
{
RingQueue<Task> *rq = (RingQueue<Task> *)args;
while (1)
{
// 从队列中取出任务
Task task = rq->pop();
std::cout << pthread_self() << " 消耗了一个任务 : ";
task.run();
sleep(2);
}
}
生产者线程函数
void *Producer(void *args)
{
// 共享环形队列
RingQueue<Task> *rq = (RingQueue<Task> *)args;
std::string oper("+-*/%");
while (1)
{
// 构造随机任务
int x = rand() % 10;
int y = rand() % 10;
Task task(x, y, oper[rand() % 5]);
// 向队列中投递任务
rq->push(task);
std::cout << pthread_self() << " 生产了一个任务 : ";
task.getTask();
sleep(1);
}
}
main函数
int main()
{
srand(time(nullptr));
pthread_t p[5], c[3];
// 创建共享的环形队列
RingQueue<Task> *rq = new RingQueue<Task>;
// 创建生产者和消费者线程
for (int i = 0; i < 5; i++)
{
pthread_create(p + i, nullptr, Producer, rq);
}
for (int i = 0; i < 3; i++)
{
pthread_create(c + i, nullptr, Consumer, rq);
}
// 等待线程结束
for (int i = 0; i < 5; i++)
{
pthread_join(p[i], nullptr);
}
for (int i = 0; i < 3; i++)
{
pthread_join(c[i], nullptr);
}
return 0;
}
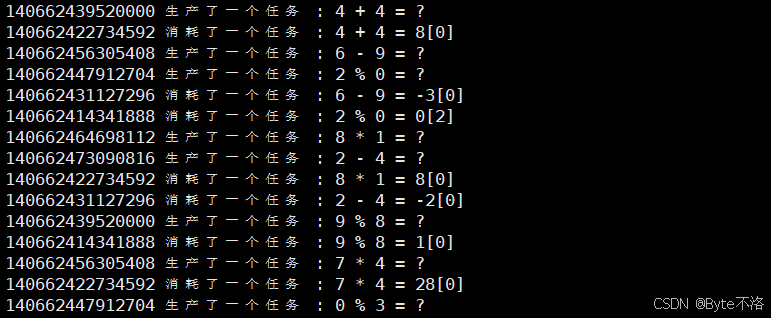
这样基于环形队列的生产者和消费者模型就成功运行起来了。但是其中还有一些问题隐藏在其中。
为什么使用两个互斥锁
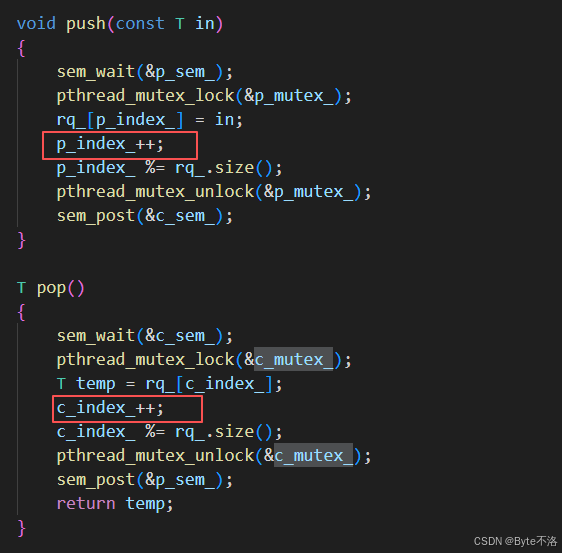
第一,避免同类线程之间的竞争。 多个生产者在生产数据时,会同时访问共享的生产索引并向队列中写入数据。如果不加锁,可能出现多个生产者写入同一位置的问题,因此需要一把互斥锁来保证生产过程的原子性。同理,多个消费者在消费数据时,也需要通过互斥锁来避免重复消费同一数据。
第二,生产和消费关注的临界资源不同。 生产者主要修改的是写入位置,而消费者主要修改的是读取位置。二者虽然操作的是同一个队列,但访问和修改的共享状态并不完全相同,因此可以使用不同的锁分别进行保护。
第三,提高并发性能,减少不必要的阻塞。 如果只使用一把全局互斥锁,会导致生产者和消费者之间互相阻塞,即使它们访问的是不同区域,也无法并发执行。而使用两把锁,可以在保证线程安全的前提下,让生产和消费操作在条件允许时并行进行,从而提高系统的并发度和执行效率。
方案一和方案二到底选择哪一种
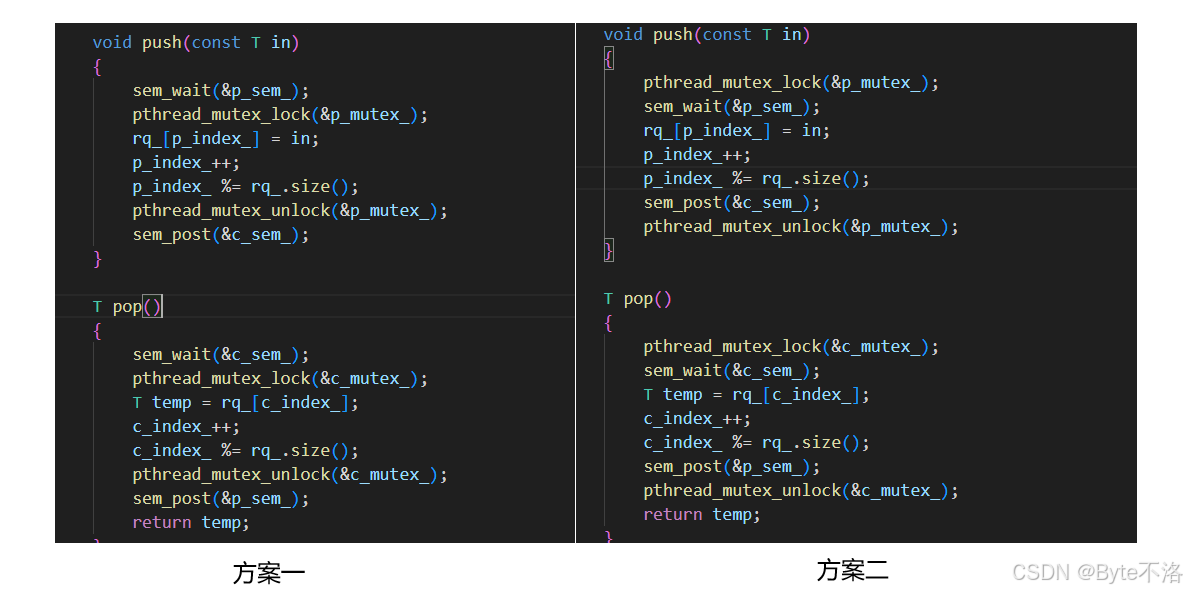
方案一选择的是先加锁然后申请信号量,方案二选择的是先申请信号量再加锁,那么我们应该选择哪一个方案呢?可以看到我们的代码中选择了方案二,这是为什么呢?
其一,因为信号量资源的申请是不需要进行保护的,申请信号量是原子的,所以不需要在加锁条件下进行申请,而我们加锁的话,就会让我们的多线程进行串行访问,所以我们要保证我们加锁之后的临界区尽可能的少,所以不需要将申请信号量放到加锁之后。
其二,就是因为方案二可以提高多线程的执行效率,当一个线程申请信号量成功并且获得锁之后,这个线程可以进入临界区执行临界区的代码,当其它线程到来的时候,它们可以先去申请信号量,然后再申请锁,这个时候锁被占用,这些进程就只能等待,当持有锁的线程结束释放锁之后,这些线程就可以直接去获取锁,不需要再去申请信号量,如果是先加锁再申请信号量的话,这些线程还得花费申请信号量的时间,与其这样,不如让它们在获取不到锁之前,先申请到信号量,这样就可以提高多线程的执行效率,提升并发度。
到这里,基于 POSIX 信号量 + 环形队列 的生产者消费者模型就完整跑通了。相比传统的“互斥锁 + 条件变量”方案,信号量天然就具备资源计数的语义,只要 sem_wait 成功,就意味着资源一定是就绪的,代码逻辑更加直接,也更不容易写错。
在实现中,我们通过 两个信号量控制资源数量、两把互斥锁保护临界区,既保证了线程安全,又避免了不必要的串行化,最大程度地提高了并发度。这也是为什么在实际工程中,信号量方案往往在高并发场景下表现得更加稳定、高效。
如果这篇文章对你有帮助,欢迎点赞、收藏、关注。



评论前必须登录!
注册