 网硕互联帮助中心
网硕互联帮助中心在上一篇《Linux 主机监控实战:CPU、内存、磁盘到底怎么看?》中,我们解决了一个问题:服务器这台“机器”是不是健康的。
在真实运维场景中,你很快就会发现:
-
机器活着
-
资源正常
-
用户却访问不了服务
👉 这正是因为:主机可用 ≠ 服务可用。
这一篇,我们正式进入 服务可用性监控。
一、什么是服务可用性监控?
服务可用性监控,只关心一件事:
👉 这个服务,现在到底还能不能被用?
它不是站在“系统”的角度,而是站在:
-
用户
-
调用方
-
业务系统
的视角来判断。
二、为什么“进程在 ≠ 服务可用”?
很多刚接触运维的同学,判断服务状态的第一反应是:
ps -ef | grep nginx
只要看到进程在,就觉得服务没问题。
但现实中,下面的情况非常常见:
-
进程存在,但端口未监听
-
进程存在,但监听在 127.0.0.1
-
进程存在,但线程卡死
-
进程存在,但接口早已超时
👉 结论:
进程在,只能说明程序没死;
端口通,才说明服务对外;
接口正常,才说明真的可用。
三、第一层:进程监控(服务程序还活着吗?)
1️⃣ 进程监控解决什么问题?
进程监控关注的是:
-
服务是否崩溃
-
是否频繁重启
-
是否资源占用异常
2️⃣ 常用进程监控命令
🔹 ps:查看进程是否存在
ps -ef | grep nginx
-
看是否有主进程 / worker 进程
-
是否异常消失
🔹 top:观察实时状态
top
重点关注:
-
服务进程 CPU / 内存是否异常
-
是否长期占用资源
🧠 实战案例:进程监控能发现什么?
场景:服务时好时坏。
排查发现:
ps -ef | grep java
进程不断退出又被拉起。
👉 说明:应用本身存在异常,而不是系统问题。
四、第二层:端口监控(服务是否对外提供能力)
1️⃣ 为什么端口监控比进程更重要?
在 Linux 中:
一个对外服务 = 一个监听端口
-
Web → 80 / 443
-
MySQL → 3306
-
DNS → 53
👉 端口不通,服务一定不可用。
2️⃣ 常用端口监控命令
🔹 ss(强烈推荐)
ss -lntp
参数说明:
-
-l:监听状态
-
-n:数字方式显示
-
-t:TCP
-
-p:显示进程信息
示例:
LISTEN 0 128 0.0.0.0:80
表示 Web 服务正在正常监听。
🔹 netstat(老系统常见)
netstat -lntp
🧠 实战案例:端口监控直接定位问题
场景: 网页打不开。
ss -lntp | grep 80
没有任何输出。
👉 结论: 不是网络问题,不是防火墙问题,服务根本没有对外监听。
五、第三层:接口监控(服务真的能用吗?)
1️⃣ 为什么端口通了,服务还是“不可用”?
因为可能存在:
-
接口返回 500
-
响应时间极慢
-
请求直接超时
👉 所以必须做接口级监控。
2️⃣ 常用接口监控命令
🔹 curl:最重要的工具
curl -I http://127.0.0.1
返回:
HTTP/1.1 200 OK
说明接口可以正常响应。
🔹 监控接口响应时间
curl -o /dev/null -s -w "time:%{time_total}\\n" http://127.0.0.1
用于判断:
-
接口是否变慢
-
是否影响用户体验
🧠 实战案例:接口监控发现性能问题
场景: 用户反馈“能打开,但很慢”。
curl -o /dev/null -s -w "time:%{time_total}\\n" http://service
响应时间 6 秒。
👉 结论: 服务没挂,但已经不可用(性能故障)。
六、健康检查的本质是什么?
很多系统、负载均衡、监控平台都有一个概念:
Health Check(健康检查)
它的本质其实非常简单:
模拟一次最小可用请求,验证服务是否能正常响应
健康检查 不是功能测试,而是确认:
-
服务在不在
-
能不能回应
-
响应是否可接受
七、Shell + curl:一个完整的服务监控示例
下面是一个极简但非常经典的服务可用性监控脚本。
示例:Web 服务可用性监控
#!/bin/bash
URL="http://127.0.0.1"
TIMEOUT=3
# 使用 curl 访问服务,获取 HTTP 状态码
HTTP_CODE=$(curl -o /dev/null -s -w "%{http_code}" –connect-timeout $TIMEOUT $URL)
# 判断服务状态
if [ "$HTTP_CODE" -eq 200 ]; then
echo "Web 服务正常,状态码:$HTTP_CODE"
else
echo "Web 服务异常,状态码:$HTTP_CODE"
fi
脚本说明
-
curl:模拟真实用户访问
-
–connect-timeout:防止卡死
-
状态码异常 → 直接告警
👉 这正是几乎所有监控系统的底层思想。
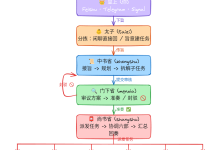
八、服务可用性监控在监控体系中的位置
完整监控体系是分层的:
主机监控(资源)
↓
服务可用性监控(端口 / 探活) ← 本篇
↓
应用监控(错误率 / 性能)
↓
业务监控(成功率 / 用户体验)
这一层,是:
告警是否有意义的分水岭。
九、写在最后:端口通不通,比服务在不在更重要
很多“无效告警”,根本原因是:
-
只看进程
-
不看端口
-
不做真实探活
而成熟运维一定会先问一句:
现在,端口到底通不通?接口到底能不能用?
💬 互动话题
当你发现服务不可用时, 第一步通常会做什么?
-
看进程
-
看端口
-
curl 探接口
-
直接重启 😅





评论前必须登录!
注册