 网硕互联帮助中心
网硕互联帮助中心目标
希望通过这份内容抛砖引玉,让你在阅读后不仅能独立编写 WordCount、接入 Kafka、使用 MySQL/Redis,对 Flink 作业有一个整体、清晰的认识。
一、第一部分:Flink 到底是什么?为什么要用它?
1.1 一句话定义
Flink 是一个“真·实时”流计算引擎,专门用来在数据不断产生的时候就立刻算出结果。
Flink核心目标,是“数据流上的有状态计算”(Stateful Computations over Data Streams )具体说明:Apache Flink是一个框架和分布式处理引擎,用于对无界和有界数据流进行有状态计算。(可以提一嘴,流批一体)
1.2 流处理的三个历史阶段
|
阶段 |
代表框架 |
延迟 |
状态管理 |
Exactly-once |
典型问题 |
|
第一代 |
Storm / Heron |
毫秒级 |
非常弱 |
非常麻烦 |
状态小、故障恢复难 |
|
第二代 |
Spark Streaming |
秒级(微批) |
有状态 |
有(但复杂) |
延迟高、不能真毫秒级 |
|
第三代(当前最优) |
Apache Flink |
毫秒级 |
超大状态 |
原生支持 |
几乎没有短板 |
结论:Flink 是目前唯一一个同时满足下面 5 个要求的开源引擎
所以一句话:现在公司里只要是“实时”两个字,基本默认就用 Flink。
1.3 Exactly-once
Exactly-once(精确一次)是流处理系统中最严格、最重要的“数据处理语义”保证。 简单来说,就是:不管程序挂了多少次、重启多少次、机器宕机多少次,最终每一条数据都恰好被正确处理一次,既不多也不少。
通俗的比喻解释
|
处理语义 |
比喻(你给女朋友发微信“到家了”) |
后果 |
|
At-most-once |
发了就不管了,网络断了女朋友也收不到 |
数据丢了(最轻松,但不能接受) |
|
At-least-once |
怕丢了就狂发,发 100 次确认她一定收到 |
数据重复了(女朋友炸了:你发 100 次干嘛) |
|
Exactly-once |
不管网络怎么抖、重连多少次,女朋友手机上永远只出现一次“到家了” |
完美(既不丢也不重) |
二、第二部分:Flink 核心概念
Flink分层API

有状态流处理:通过底层API(处理函数),对最原始数据加工处理。底层API与DdaSteamAPI相集成,可以处理复杂的计算。
DataSteamAPI(流处理) 和 DataSetAPI(批处理)封装了底层处理函数,提供了通用的模块,比如转换(tansfonmations,包括fatmap等),连接(joins),聚合(aggregations),窗口(windows)操作等。注意:Fnk1.12以后,DataSteamAPI已经实现map、真正的流批一体,所以DataSetAPI已经过时。
TableAPI是以表为中心的声明式编程,其中表可能会动态变化。TableAPI遵循关系模型:表有二维数据结构,类似于关系数据库中的表; 同时API提供可比较的操作,例如select、project、join、group-by、aggregate等。我们可以在表与 DataSteamDataset之间无缝切换,以允许程序将 TableAPl与DataStream 以及 DataSet 混合使用。
SOL这一层在语法与表达能力上与Table API类似,但是是以SOL查询表达式的形式表现程序。SOL抽象与tIabe API交互密切,同时SOL查询可以直接在Table API定义的表上执行.
Flink 运行时架构
这里以单列部署模式为列
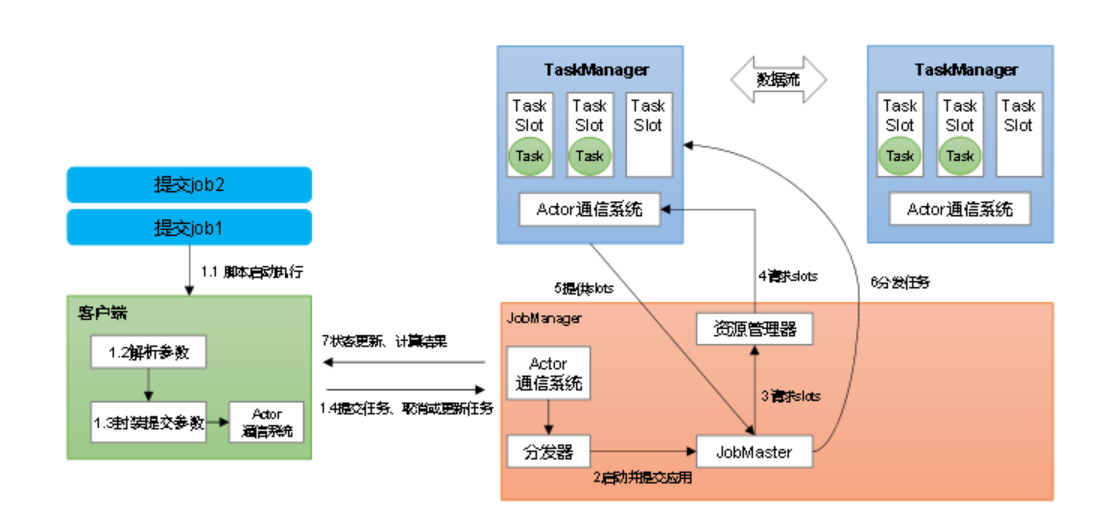
作业管理器(JobManager)
JobManager = Flink 集群里的大脑 + 管家
一句话总结: JobManager 是整个 Flink 作业的“总指挥官”,负责接收你提交的代码、把作业拆成小任务、给每个 TaskManager 发命令、协调 Checkpoint、监控所有任务的生死,一旦出事就负责重启恢复。
它干的三件最核心的事:
一个 Flink 集群永远只有一个活跃的 JobManager(高可用时有 standby),所有作业都归它管,它挂了 = 整个集群所有作业全停。
(细节可以去看官网教程,主要是)
任务管理器(TaskManager)
TaskManager 是真正执行计算的 JVM 进程,负责接收 JobManager 派发的子任务(subtask),在自己的 Slot 里跑算子代码、管理本地状态、做 Checkpoint 快照、跟其他 TaskManager 交换数据,它是集群里“干体力活”的地方。
Flink 核心概念
1. 并行度(Parallelism)
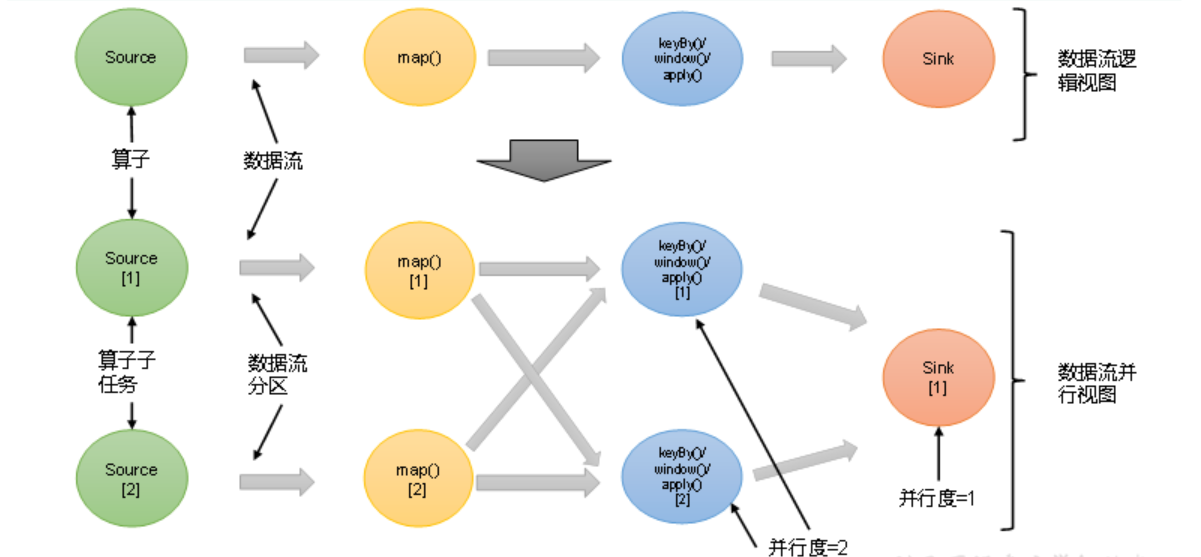
1.1. 并行度(Parallelism)一句话概述
并行度 = 一个算子同时有多少个并行实例在干活,它直接决定你的作业能多快、能吃多少数据。
用大白话: 想象你要把 1000 个苹果削皮。
- 并行度 = 1 → 你一个人削,慢慢来
- 并行度 = 8 → 8 个人一起削,理论上快 8 倍 Flink 里每一个算子(source、map、keyBy/window、sink)都可以单独设置并行度。
1.2. 并行度到底决定什么?
1.3. 实际生产中最常用的 4 种设置方式(优先级从高到低)
|
设置方式 |
代码/命令示例 |
适用场景 |
优先级 |
|
1. 算子级别单独设置 |
.keyBy(…).window(…).sum(0).setParallelism(16) 最常用! |
某个算子是热点,想单独给他开多线程 |
★★★★★ |
|
2. 提交作业时用 -p 指定 |
flink run -p 128 wordcount.jar |
快速调整体并行度,不想改代码 |
★★★★ |
|
3. 代码里全局设置 |
env.setParallelism(64) |
开发测试时用,生产不推荐 |
★★★ |
|
4. flink-conf.yaml 默认 |
parallelism.default: 64 |
整个集群默认值,最后手段 |
★★ |
1.4. 真实生产推荐做法
stream
.keyBy(…)
.window(TumblingEventTimeWindows.of(Time.minutes(1)))
.sum(0)
.setParallelism(32) // 窗口聚合是热点,开 32
.addSink(new ClickHouseSink())
.setParallelism(8); // ClickHouse 写压力大,开 8 就够
flink run -p 200 -c com.xxx.MyJob myjob.jar
1.5. 记住这几个黄金数字(生产常见值)
- Kafka Source:一般和分区数对齐(比如 24 分区 → 并行度 24)
- 窗口聚合:CPU 核心数的 2~4 倍(比如 32 核机器,开 64~128)
- JDBC/MySQL Sink:3~12(MySQL 扛不住太多)
- ClickHouse/Doris Sink:8~32(看库性能)
一句话总结: 并行度就是你给算子雇了多少个工人干活,生产中永远是“热点算子单独 setParallelism + 提交时 -p 整体控制”两招搞定 99% 的性能问题。
2. 算子链(Operator Chain)
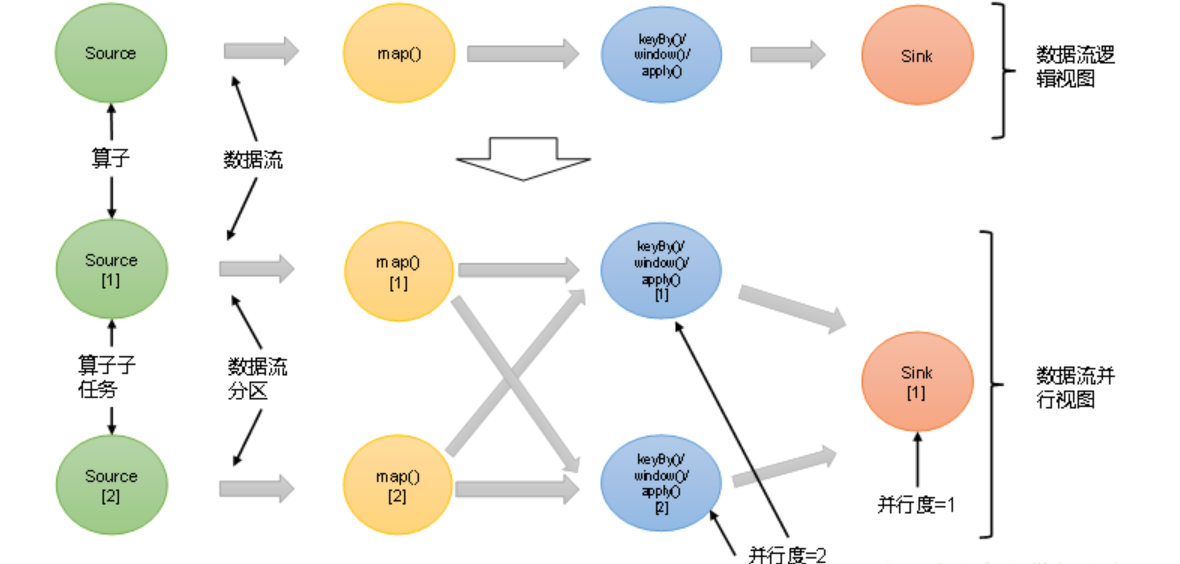
算子链 = Flink 把并行度相同、且是一对一(one-to-one)关系的多个算子“焊接”成一个任务,放在同一个线程里跑,从而省掉不必要的序列化/网络传输开销,是 Flink 性能杀手锏之一。
用大白话比喻: 本来 source → map → filter → map 这 4 个工人要 4 个工位、互相扔来扔去(序列化 + 网络)。 Flink 发现他们并行度都一样、数据顺序也不乱,就直接把 4 个人焊成一个“四头怪”,在一个线程里顺序执行,省了 3 次“扔来扔去”,性能直接起飞。
2.1. 什么时候能链?什么时候不能链?
|
情况 |
是否能链在一起 |
举例说明 |
|
并行度相同 |
能 |
都是 64 → 能链 |
|
并行度不同 |
一定不能链 |
source 64,map 32 → 必须断开 |
|
one-to-one 操作 |
能 |
map、filter、flatMap、select、where |
|
需要重新分区(redistribute) |
一定不能链 |
keyBy、shuffle、rebalance、broadcast |
|
手动禁用了链 |
不能 |
disableChaining()、startNewChain() |
2.2. 实际生产中怎么操作算子链
|
操作需求 |
代码怎么写(Java/Scala 通用) |
生产场景举例 |
|
1. 想让某个算子跟前面断开 |
.disableChaining() |
sink 之前加 disableChaining(),防止 sink 拖慢上游 |
|
2. 从某个算子开始重新开一条链 |
.startNewChain() |
keyBy 之后 startNewChain(),让窗口单独成链 |
|
3. 给某个算子单独指定 slot 共享组(最强控制) |
.slotSharingGroup(\”xxx\”) |
热点算子单独放一组 slot,防止互相抢资源 |
真实生产代码例子:
stream
.map(…) // 默认跟前面链在一起
.filter(…)
.map(…)
.keyBy(…) // 这里自动断链(因为要 shuffle)
.window(…) // 窗口开始新链
.sum(0)
.startNewChain() // 强制从窗口开始新链(可选)
.map(new RichMapFunction(…)) // Rich 开状态,自动断链
.disableChaining() // 强制跟前面断开(保险)
.addSink(new ClickHouseSink()) // sink 一般都单独断开
.setParallelism(8)
.disableChaining(); // 生产必写!防止 sink 反压拖垮整个链
2.3. 生产中最常见的 3 个算子链黄金写法
|
场景 |
推荐写法 |
|
写 MySQL/Redis/ES 等慢 sink |
一定在 sink 前加 .disableChaining() |
|
窗口聚合是热点 |
.window(…).sum(…).startNewChain() |
|
想完全掌控链的划分 |
给每个大算子都手动加 slotSharingGroup |
|
.slotSharingGroup(\”source\”) → source 单独一组 |
|
|
.slotSharingGroup(\”window\”) → 窗口单独一组 |
|
|
.slotSharingGroup(\”default\”) → 其他默认 |
一句话总结: 算子链是 Flink 免费送你的性能加速器,默认能链就链,但生产中永远记得给 sink 和热点算子主动断链(disableChaining),否则一旦反压,整个作业全卡死。
3. 任务槽(Task Slots)
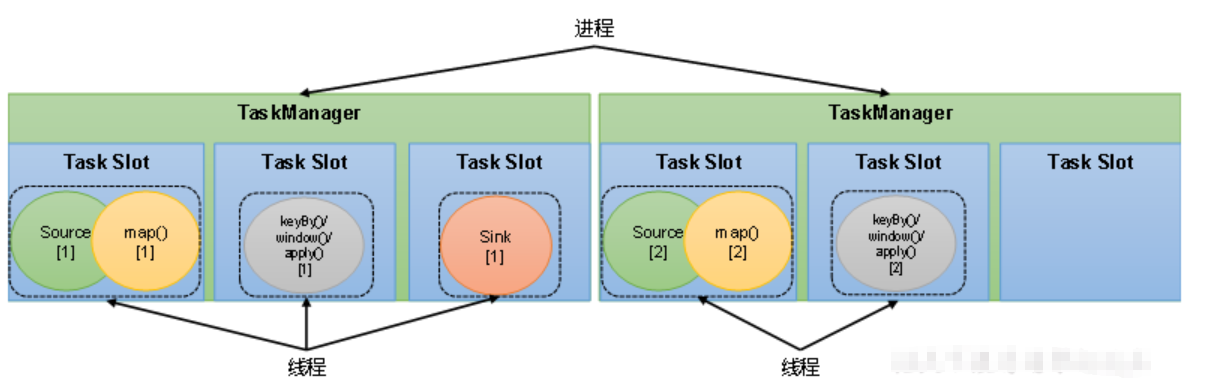
3.1. 任务槽(Task Slots)一句话概述
Task Slot = TaskManager 里的一块“工位”,一个 Slot 就是一个线程 + 一份固定内存,决定了这个 TaskManager 同一时刻最多能同时跑多少个并行子任务(subtask)。
用最通俗的比喻: 一个 TaskManager 就像学校的一间教室,Slot 就是教室里的课桌。
- 教室有 8 张课桌(8 个 slot)→ 最多同时坐 8 个学生(8 个 subtask)
- 学生可以共享课桌(默认开启 slot sharing)
- 你也可以规定某些学生只能坐指定颜色的课桌(slotSharingGroup)
3.2. Task Slot 和 Parallelism 的终极区别(背下来)
|
名词 |
含义 |
谁决定 |
举例 |
|
Parallelism |
我总共需要多少个工人干活 |
作业自己决定 |
我的 window 并行度 64 → 需要 64 个工人 |
|
Task Slot |
每个工厂(TaskManager)有几个工位 |
集群管理员配置 |
每台机器配 8 个 slot → 8 个工位 |
|
关系 |
Parallelism ≤ 所有 TaskManager 的 Slot 总数 |
否则作业起不来 |
3 台机 × 8 slot = 最多支持 24 并行度 |
3.3. 生产中最常用的 3 种操作(直接背代码和命令)
|
操作需求 |
具体怎么做(100% 生产真实写法) |
说明 |
|
1. 改一台机器的 slot 数量(最常用) |
编辑 flink-conf.yaml(每台机器都要改) taskmanager.numberOfTaskSlots: 16 |
生产主流配置:32核机器配 16~32 个 slot |
|
2. 某个算子独占 slot,不跟别人共享 |
.slotSharingGroup(\”heavy\”) |
防止热点算子被轻量级算子抢资源 |
|
3. 完全关闭 slot 共享(极少用) |
全局关闭(不推荐) taskmanager.slot-sharing.enabled: false |
每个 subtask 独占一个 slot,浪费资源,基本没人这么干 |
3.4. 生产黄金配置模板
# flink-conf.yaml(每台 TaskManager 都配这个)
taskmanager.numberOfTaskSlots: 24 # 32核机器最常见配 24
taskmanager.memory.process.size: 32g # 总内存
jobmanager.memory.process.size: 4g
# 代码里热点算子单独分组(强烈推荐)
stream
.source(…) # 默认组
.map(…)
.keyBy(…)
.window(…) # 热点!
.process(new MyHeavyProcessFunction())
.slotSharingGroup(\”window-heavy\”) # 单独一组 slot
.addSink(new SlowMySQLSink())
.slotSharingGroup(\”mysql-sink\”) # 慢 sink 单独一组
.setParallelism(6);
3.5. 生产中最常见的 3 个 slot 配置经验值
|
机器规格 |
推荐 slot 数 |
理由 |
|
16核 64G |
12~16 |
留点内存给 RocksDB |
|
32核 128G |
20~32 |
主流配置,24 最常见 |
|
64核 256G+ |
40~64 |
大状态作业才这么配 |
3.6. 一句话总结
Slot 是资源(工位),Parallelism 是需求(工人) → 工人不能比工位多 → 生产永远先看集群总 slot 够不够,再决定能开多大并行度 → 热点算子一定要 slotSharingGroup 分组,否则互相抢 slot 一卡全卡。
记住这三行配置,90% 的性能问题都解决了:
taskmanager.numberOfTaskSlots: 24
Java
.window(…).slotSharingGroup(\”heavy-window\”)
.addSink(…).slotSharingGroup(\”slow-sink\”)
三、第三部分:DataStreamAPI
DataStream API 是Flink的核心层API。一个Flink程序,其实就是对 DataStream (数据流) 的各种转换。具体来说,代码基本上都由以下几部分构成:
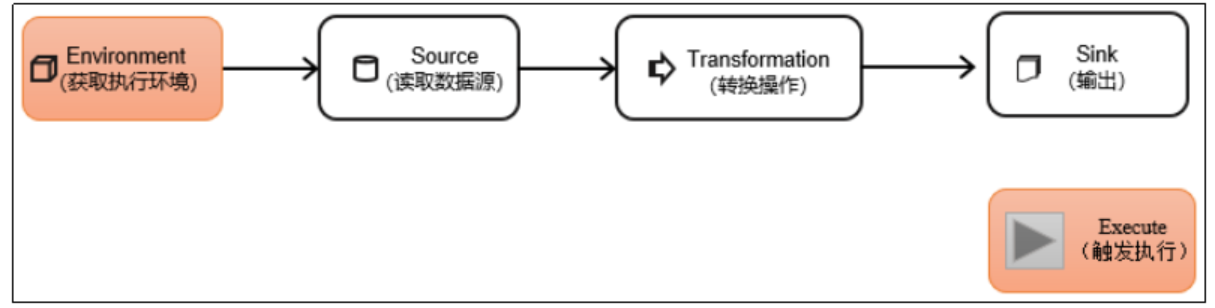
StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
// 1. Source(从哪读)
DataStream<String> stream = env
.fromSource(kafkaSource, WatermarkStrategy.noWatermarks(), \”kafka\”);
// 2. Transform(怎么算
stream
.map(json -> parse(json)) // 解析
.filter(obj -> obj != null)
.assignTimestampsAndWatermarks(watermarkStrategy) // 事件时间 + 水印(重点)
.keyBy(obj -> obj.id)
.window(TumblingEventTimeWindows.of(Time.minutes(1))) // 窗口
.aggregate(new MyAggFunction()) // 聚合(或者 .sum()/.reduce())等等
// 3. Sink(写到哪去)
.addSink(new ClickHouseSink())
.setParallelism(8)
.slotSharingGroup(\”ck-sink\”); // 生产必写 防止反压传染
env.execute(\”my-real-time-job\”);
1、执行环境(必须第一步)
最简单的方式,就是直接调用getExecutionEnvironment方法。它会根据当前运行的上下文直接得到正确的结果:如果程序是独立运行的,就返回一个本地执行环境;如果是创建了jar包,然后从命令行调用它并提交到集群执行,那么就返回集群的执行环境。也就是说,这个方法会根据当前运行的方式,自行决定该返回什么样的运行环境。
StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
// 可选:设置并行度、开启 Checkpoint
env.setParallelism(1); // 全局并行度(生产慎用)
env.enableCheckpointing(10000L); // 开启 Exactly-once Checkpoint
(如果生产使用的是云产品部署,这里代码里面就不要写死处理Checkpoint)
2、Source(从哪儿读数据)
Source 是整个 Flink 作业的入口,决定了数据从哪儿来、怎么来、是否带事件时间。 生产中 90% 的 Source 都是 Kafka,剩下 10% 是测试/文件/自定义。

1. Source 分类 & 使用频率
|
类型 |
使用场景 |
生产频率 |
推荐度 |
|
Kafka |
生产实时数据入口 |
★★★★★ |
必学 |
|
文件(File) |
批处理或小数据测试 |
★★ |
了解 |
|
集合(Collection) |
本地测试、单元测试 |
★★★ |
常用 |
|
Socket |
快速验证、nc 测试 |
★★ |
了解 |
|
DataGen |
性能测试、压测 |
★★★ |
推荐 |
|
自定义 Source |
特殊数据源(MySQL/Redis 等) |
★★★ |
进阶 |
生产推荐:Kafka + WatermarkStrategy(事件时间 + 水印)。
2. Kafka Source (生产主力)
// 加 flink-connector-kafka 依赖
KafkaSource<WaterSensor> kafkaSource = KafkaSource.<WaterSensor>builder()
.setBootstrapServers(\”hadoop102:9092,hadoop103:9092\”)
.setTopics(\”sensor-topic\”)
.setGroupId(\”flink-group-01\”)
.setStartingOffsets(OffsetsInitializer.earliest()) // 或 latest() / committedOffsets()
.setValueOnlyDeserializer(new DeserializationSchema<WaterSensor>() {
@Override
public WaterSensor deserialize(byte[] message) throws IOException {
// 自己写 JSON 解析,比如 FastJSON / Gson
return JSON.parseObject(message, WaterSensor.class);
}
@Override
public boolean isEndOfStream(WaterSensor nextElement) { return false; }
@Override
public TypeInformation<WaterSensor> getProducedType() {
return TypeInformation.of(WaterSensor.class);
}
})
.build();
DataStream<WaterSensor> stream = env.fromSource(
kafkaSource,
WatermarkStrategy.<WaterSensor>forBoundedOutOfOrderness(Duration.ofSeconds(5)) // 水印
.withTimestampAssigner((sensor, ts) -> sensor.ts),
\”kafka-source\”
);
3. Source 层生产必需考虑的 3 件事
|
配置项 |
代码位置 |
为什么必须配 |
|
Checkpoint(Exactly-once) |
env.enableCheckpointing(10000L, CheckpointingMode.EXACTLY_ONCE); |
Kafka Source 才能实现端到端精确一次 |
|
水印 + 事件时间 |
WatermarkStrategy.forBoundedOutOfOrderness(…) + withTimestampAssigner |
窗口才能基于事件时间正确计算,处理乱序 |
|
并行度对齐 Kafka 分区 |
Source 并行度 = Kafka 分区数 |
否则吞吐打折,某些分区消费慢 |
4. 一句话总结 Source 层
生产作业 99% 都是从 Kafka Source 开始<




评论前必须登录!
注册