 网硕互联帮助中心
网硕互联帮助中心一、Transformer 的输入是什么?
Transformer 的输入是数字化的序列数据,需经过3 层编码后才能送入注意力层和前馈网络,Encoder 和 Decoder 的输入有重叠但不完全相同,核心输入结构如下:
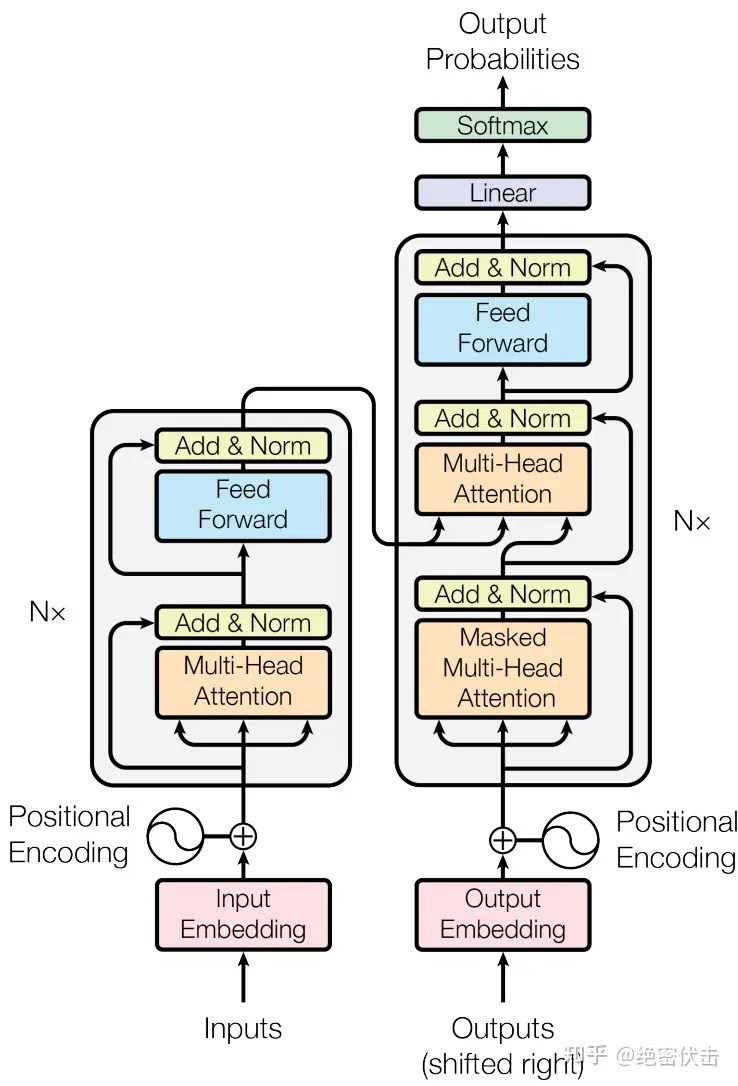
通用基础输入
- 位置编码的维度和词嵌入一致,保证相加后维度不变;
- 可选择可学习的位置编码,训练时更新参数,效果和正弦公式相近。
Encoder 的专属输入
仅需上述词嵌入 + 位置编码的组合向量,输入为完整的源序列,且 Encoder 的输入序列是一次性全部送入的。
Decoder 的专属输入
Decoder 是自回归结构,输入分为两部分,且训练 / 测试时输入形式不同:
输入维度总结:所有输入向量的核心维度为 [batch_size, seq_len, d_model](批次大小,序列长度,模型维度),这是 Transformer 的基础张量形状。
二、Mask 的作用是什么?Transformer 中有哪些 Mask?
Mask 翻译为掩码,核心作用是让模型在计算注意力时,忽略掉 “不该看到” 的 token,本质是在注意力分数矩阵中,给需要屏蔽的位置加一个极大的负数,经过 Softmax 后这些位置的概率会趋近于 0,相当于模型 “看不到” 这些 token。
Transformer 中有3 类核心 Mask,分别用于不同场景,无 Mask 则模型会学到错误的依赖关系:
1. 填充掩码(Padding Mask)—— 解决 “序列长度不一致” 问题
实际训练中,一个批次的序列长度是不一样的,会通过Padding补 0 让长度统一,但这些补 0 的位置是无意义的,需要用 Padding Mask 屏蔽。
- 适用场景:Encoder 的自注意力层 + Decoder 的交叉注意力层(两处都要屏蔽源 / 目标序列的 Padding 位)。
2. 未来掩码(Look-Ahead Mask / 因果掩码)—— 解决 “自回归因果性” 问题
Decoder 是自回归生成的(比如翻译时,生成第 3 个词时,只能看到前 2 个词,不能看到第 3、4、5 个词),因此需要用未来掩码屏蔽序列中当前位置之后的所有位置。
- 适用场景:Decoder 的自注意力层(仅此处需要,Encoder 无生成需求,不需要)。
3. 其他掩码(可选)
Mask 核心总结:Mask 不改变张量形状,仅通过修改注意力分数,让模型 “选择性关注” 有效 token,是 Transformer 保证计算合理性和因果性的关键。
三、Cross-Attention 交叉注意力的作用是什么?
Cross-Attention 是 Transformer 中Decoder 独有的层(Encoder 只有自注意力层 Self-Attention),核心作用是让 Decoder 的生成过程 “关注” Encoder 的源序列信息,实现源序列到目标序列的信息映射。
先区分两个基础注意力,再讲 Cross-Attention 的核心:
1. 自注意力(Self-Attention)
- 输入:同一序列的 Q(查询)、K(键)、V(值);
- 作用:让序列自身的 token 之间相互关注,学习序列内部的依赖关系。
2. 交叉注意力(Cross-Attention)
- 输入:不同序列的 Q 和 K/V —— Q 是Decoder 前一层的输出,K 和 V 是Encoder 的最终输出;
- 作用:让目标序列的 token 关注源序列的相关 token。
Cross-Attention 的核心价值
Cross 核心总结:Cross-Attention 是 Decoder “读懂” Encoder 的关键,让 Transformer 实现源序列语义到目标序列生成的精准映射,是所有 ** 序列到序列(Seq2Seq)** 任务的核心组件。
四、Transformer 训练和测试的区别是什么?
Transformer 的训练和测试阶段,模型结构不变,但输入形式、计算方式、效率、策略完全不同,核心差异源于 Decoder 的自回归特性,也是所有生成式模型的共性差异,关键区别如下表:
| 输入形式 |
1. Encoder:完整源序列 2. Decoder:完整的目标序列(带 Shift Right) |
1. Encoder:完整源序列 2. Decoder:逐词输入,自回归生成(初始输入为 [CLS],预测第 1 个词 I;再输入 [CLS, I],预测第 2 个词 am;依次类推,直到生成结束符 [EOS],即 “模型自己慢慢写”) |
| 计算方式 | 批处理 + 并行计算(一个批次的序列一次性计算,Decoder 的完整输入可并行计算注意力),效率高 | 串行计算(必须等前一个词生成后,才能输入计算下一个词),效率低(生成越长的序列,耗时越久) |
| Mask 使用 |
1. Encoder:Padding Mask 2. Decoder:Padding Mask + 未来掩码(Look-Ahead Mask) |
和训练一致,Decoder 的自注意力层仍需未来掩码,两处仍需 Padding Mask |
| 目标 | 最小化预测值和真实值的差距,更新模型所有参数:Encoder+Decoder 的词嵌入、注意力、前馈网络等所有参数 | 固定训练好的参数,根据源序列生成符合语义的目标序列,无参数更新 |
| 解码策略 | 无解码策略,直接用真实值作为输入,属于教师强制 | 需用解码策略控制生成效果,比如贪心解码(每次选概率最大的词)、集束搜索(Beam Search)(保留 top-k 个候选序列,选最优)、随机解码(采样概率分布,增加多样性) |
| 输入长度 | 批次内序列长度统一(Padding 补 0),固定seq_len | 序列长度动态变化(随生成过程逐步增加,直到生成 [EOS]) |
补充:教师强制(Teacher Forcing)
训练时 Decoder 用完整的目标序列作为输入,而非自己生成的序列,这个策略叫教师强制,核心优势是加速训练(并行计算),避免训练过程中 “错误累积”。
- 副作用:暴露偏差(Exposure Bias)—— 训练时模型看的是真实值,测试时看的是自己生成的值,两者分布不同,可能导致测试效果比训练效果差,可通过Scheduled Sampling(训练时随机用模型生成的词代替真实值)缓解。
训练 / 测试核心总结:核心差异在Decoder 的输入方式(训练一次性喂真实值,测试逐词自回归生成),导致计算效率、策略的全面不同;Encoder 在训练和测试时完全一致,无差异。
五、Transformer 训练的 Loss 怎么计算?
Transformer 的训练损失是基于 Decoder 的输出计算的,核心用于序列分类 / 生成任务,基础损失为交叉熵损失(Cross-Entropy Loss)。
1. 损失计算的前提
Decoder 的最终输出是一个形状为 [batch_size, seq_len, vocab_size] 的张量,其中:
- vocab_size:目标序列的词表大小;
- 张量中每个元素的值:模型预测该位置是词表中某个词的未归一化概率;
- 经过Softmax 层后,会转化为 [0,1] 之间的概率,代表该位置是对应词的概率。
2. 基础损失:负对数似然损失(NLLLoss)/ 交叉熵损失(CrossEntropyLoss)
PyTorch中,CrossEntropyLoss 已经整合了Softmax和NLLLoss,是 Transformer 训练的默认损失,计算步骤如下:
步骤 1:Decoder 输出处理
将 Decoder 的输出张量 [batch_size, seq_len, vocab_size] 展平为 [batch_size*seq_len, vocab_size],方便批量计算。
步骤 2:目标序列处理
将目标序列的真实标签(token 的索引)展平为 [batch_size*seq_len],并屏蔽 Padding 位。
步骤 3:计算交叉熵损失
对每个 token 的预测概率和真实标签计算交叉熵,再对所有有效 token求平均,得到批次的平均损失。
核心公式:
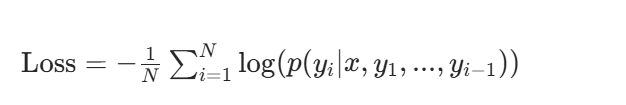
其中:
- N:批次中有效 token 的总数;
- yi:目标序列第i个位置的真实 token;
- p(yi∣…):模型预测第i个位置为yi的概率。
3. 损失计算的关键细节
- 仅计算 Decoder 的有效位置:Padding 位、<pad>``<cls>等特殊 token 可选择不计入损失,通过ignore_index参数实现(比如 PyTorch 中CrossEntropyLoss(ignore_index=0),0 为 Padding 的索引);
- 批次平均:损失通常对批次内的所有有效 token求平均,保证不同批次的损失尺度一致,便于梯度下降;
- 梯度更新:计算得到的损失通过反向传播更新 Transformer 的所有参数(Encoder+Decoder 的词嵌入、注意力层、前馈网络的权重和偏置)。
Loss 核心总结:Transformer 的基础训练损失是带 Padding 屏蔽的交叉熵损失,简单且适配序列生成任务;特殊场景可通过标签平滑、加权等方式优化,核心目标是最小化模型预测值和真实值的差距,让模型学习到源序列到目标序列的映射规律。






评论前必须登录!
注册