 网硕互联帮助中心
网硕互联帮助中心本文提供 Kafka 4.1.1 生产集群的完整部署指南,涵盖从集群规划、环境准备、KRaft模式配置、安全认证到监控管理的全流程。重点介绍如何在生产环境中构建高可用、安全的 Kafka 集群,包括集群架构设计、性能调优、健康监控等关键环节。适用于需要构建企业级消息中间件平台的技术团队。
一、生产环境规划与设计
本章节介绍生产环境中 Kafka 集群的规划与设计原则,包括集群规模、架构拓扑、关键参数配置以及生产环境与单机部署的核心差异。合理的规划是确保集群稳定、高性能运行的基础。
规划说明:生产环境 Kafka 集群需要考虑高可用性、数据安全性和可扩展性。本节将帮助您设计一个能够容忍节点故障、保证数据不丢失、并具备良好性能的集群架构。
1.集群架构设计
本小节详细描述了生产集群的架构设计,包括节点分配、角色配置和数据目录规划。合理的架构设计是确保集群高可用性和可扩展性的关键。
-
集群规模:3个节点(最小高可用配置),角色均为 broker,controller(组合模式)。
-
拓扑示例:
节点IP地址主机名角色数据目录 Node-1 172.16.130.3 kafka-node-01 broker,controller /data/kafka-logs Node-2 172.16.130.13 kafka-node-02 broker,controller /data/kafka-logs Node-3 172.16.130.15 kafka-node-03 broker,controller /data/kafka-logs -
关键生产参数:
- 副本因子 (Replication Factor):3(确保数据高可用)
- 最小同步副本 (MinISR):2(保证消息持久化且不影响可用性)
- Controller仲裁节点数:3(所有节点均为Controller)
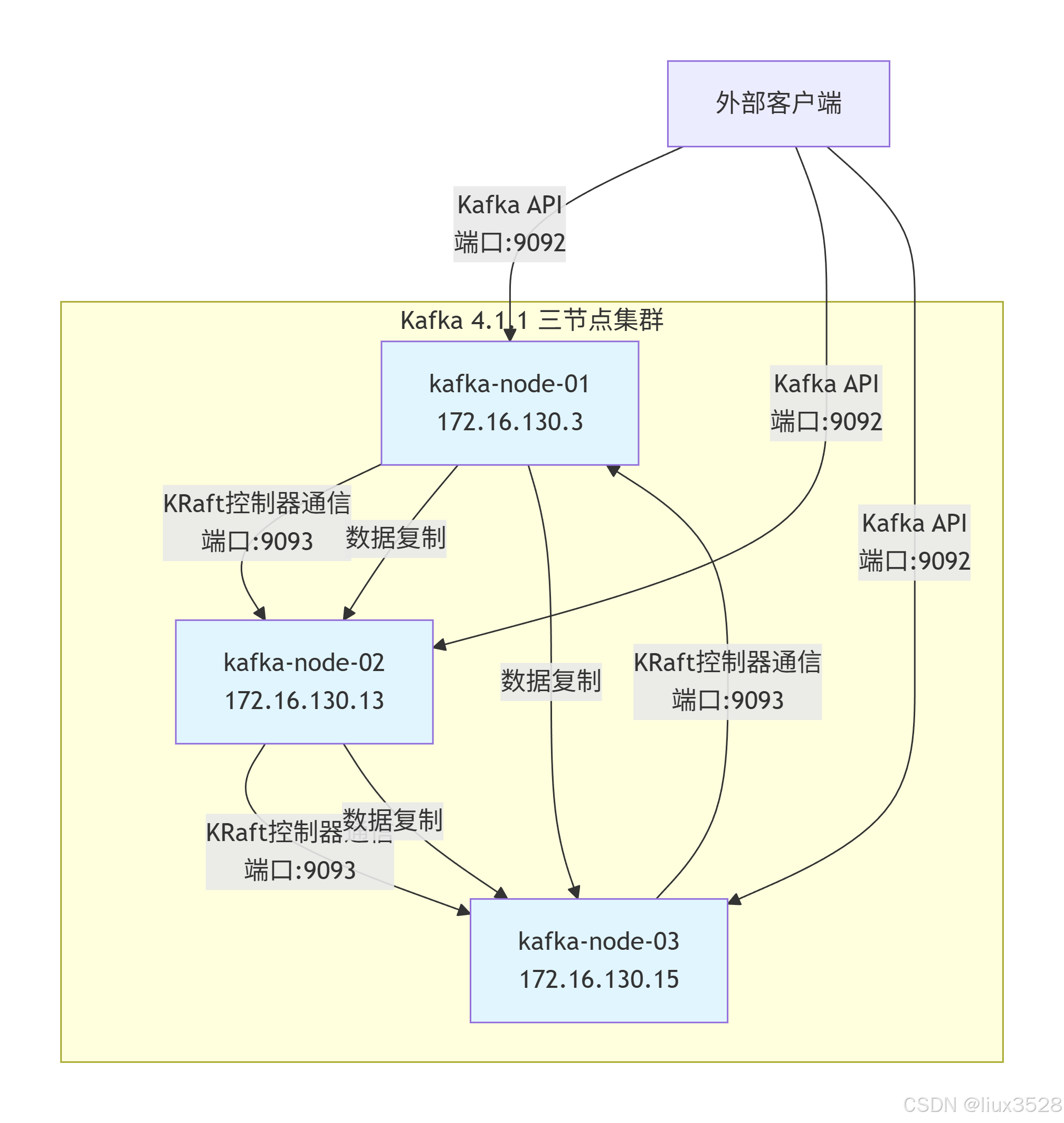
2.架构图
- 三节点对称架构:所有节点配置完全相同,同时承担Broker和Controller角色
- 双重通信机制:
- 控制器通信:通过9093端口进行KRaft协议通信(元数据同步与集群管理)
- 数据复制:节点间Topic数据副本同步,确保高可用性
- 统一客户端接入:外部应用通过9092端口可连接任意节点,自动负载均衡
- 完全对等设计:每个节点提供相同的服务能力,无单点故障,支持故障自动转移
3.生产与单机部署核心差异
本小节对比了生产集群与单机部署在关键维度的差异,帮助您理解生产环境对可用性、安全性和监控的更高要求。
| 节点数量 | ≥3(奇数) | 1 |
| 数据副本 | ≥3 | 1 |
| 容错能力 | 可容忍N-1/2节点故障 | 无 |
| 监听器配置 | 需使用主机名/IP,禁用localhost | 可使用localhost |
| 安全 | 必须启用SASL+SSL/TLS | 可选 |
| 监控告警 | 必须配置 | 可选 |
二、基础环境准备
本章节介绍部署 Kafka 集群前的系统环境准备工作,包括主机名配置、JDK安装等基础设置。良好的环境准备是集群稳定运行的前提。
准备说明:在部署 Kafka 之前,需要确保所有节点具有正确的网络配置和运行环境。本节将指导您完成主机名解析、JDK安装等基础配置。
1. 设置主机名与解析
配置主机名和 hosts 解析是确保 Kafka 节点间能够正确通信的基础。使用主机名而非IP地址可以提高配置的可读性和可维护性。
#172.16.130.3执行
hostnamectl set-hostname kafka-node-01
#172.16.130.13执行
hostnamectl set-hostname kafka-node-02
#172.16.130.15执行
hostnamectl set-hostname kafka-node-03
#所有节点执行
echo "172.16.130.3 kafka-node-01" | sudo tee -a /etc/hosts
echo "172.16.130.13 kafka-node-02" | sudo tee -a /etc/hosts
echo "172.16.130.15 kafka-node-03" | sudo tee -a /etc/hosts
2. 安装jdk17(Kafka 4.x要求)
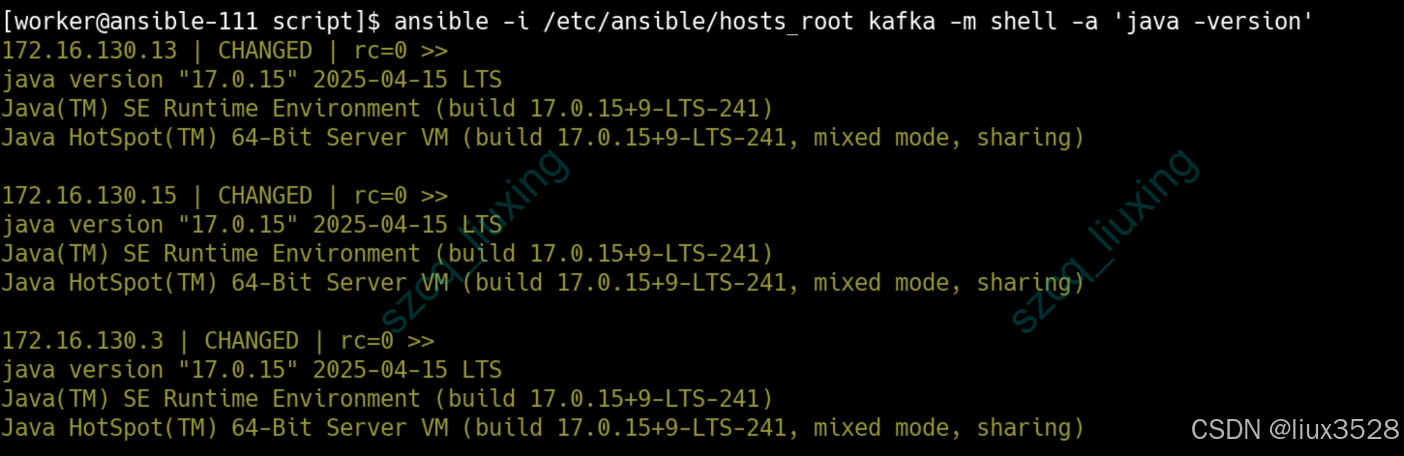
Kafka 4.x 需要 JDK 17 或更高版本。本小节使用 Ansible 自动化工具在多台服务器上统一安装 JDK 17,确保环境一致性。
我这里采用ansible统一安装
[worker@ansible-111 script]$ cat jdk_install.yml
—
– name: 快速安装 JDK 17
hosts: "{{ target_hosts }}"
become: yes
vars:
jdk_package: "jdk-17.0.15_linux-aarch64_bin.tar.gz"
install_base_dir: "/data/software"
jdk_home: "{{ install_base_dir }}/jdk-17"
tasks:
– name: 创建安装目录
file:
path: "{{ install_base_dir }}"
state: directory
mode: '0755'
owner: root
group: root
– name: 上传并安装JDK
unarchive:
src: "/data/software/{{ jdk_package }}"
dest: "{{ install_base_dir }}"
remote_src: no
creates: "{{ install_base_dir }}/jdk-17.0.15/bin/java"
– name: 创建软链接
file:
src: "{{ install_base_dir }}/jdk-17.0.15"
dest: "{{ jdk_home }}"
state: link
force: yes
– name: 设置环境变量
lineinfile:
path: /etc/profile.d/java.sh
line: 'export PATH={{ jdk_home }}/bin:$PATH'
create: yes
mode: '0644'
– name: 验证安装
shell: "java -version"
register: java_version
– debug:
msg: "JDK安装完成: {{ java_version.stdout_lines }}"
[worker@ansible-111 script]$ ansible-playbook -i /etc/ansible/hosts_root /etc/ansible/script/jdk_install.yml -e "target_hosts=kafka"
如图所示,已成功安装jdk17
三、集群部署
本章节详细介绍 Kafka 集群的部署过程,包括软件下载、配置修改、集群初始化和启动。重点介绍 KRaft 模式(去除ZooKeeper)的配置方法。
部署说明:Kafka 4.x 默认使用 KRaft 模式,不再依赖 ZooKeeper。本节将指导您完成从下载软件到启动集群的全过程,包括多节点间的配置差异和协调。
1.下载解压
从 Apache 官网下载 Kafka 二进制发行版并解压到指定目录。确保所有节点使用相同版本的 Kafka,为后续配置和部署做好准备。
#官网下载
https://dlcdn.apache.org/kafka/4.1.1/kafka_2.13-4.1.1.tgz
[worker@kafka-node-01 software]$ tar xf kafka_2.13-4.1.1.tgz
[worker@kafka-node-01 software]$ mv kafka_2.13-4.1.1 kafka_4.1.1
2.修改集群配置文件 (server.properties)
注意:每个节点的配置需调整 node.id 和 advertised.listeners,其余核心配置相同。
- Node-1 (node.id=1): advertised.listeners=PLAINTEXT://kafka-node-01:9092
- Node-2 (node.id=2): advertised.listeners=PLAINTEXT://kafka-node-02:9092
- Node-3 (node.id=3): advertised.listeners=PLAINTEXT://kafka-node-03:9092
[worker@kafka-node-01 software]$ cd kafka_4.1.1/config/
[worker@kafka-node-01 config]$ vim server.properties
############################# KRaft 核心配置 #############################
process.roles=broker,controller
# 【关键】每个节点唯一:node-1=1, node-2=2, node-3=3
node.id=1
# 【关键】所有节点必须完全一致!列出所有Controller节点
controller.quorum.voters=1@kafka-node-01:9093,2@kafka-node-02:9093,3@kafka-node-03:9093
controller.listener.names=CONTROLLER
############################# 网络监听器 #############################
# 外部客户端访问端口 (9092) 和 Controller内部通信端口 (9093)
listeners=PLAINTEXT://:9092,CONTROLLER://:9093
inter.broker.listener.name=PLAINTEXT
# 【关键】各节点需改为自己的主机名/IP
advertised.listeners=PLAINTEXT://kafka-node-01:9092
listener.security.protocol.map=CONTROLLER:PLAINTEXT,PLAINTEXT:PLAINTEXT
############################# 数据与日志 #############################
## Kafka数据目录
log.dirs=/data/kafka-logs
num.partitions=3
default.replication.factor=3
min.insync.replicas=2
############################# 内部Topic配置 #############################
offsets.topic.replication.factor=3
transaction.state.log.replication.factor=3
transaction.state.log.min.isr=2
3.拷贝包到其他节点修改配置
将配置好的文件复制到其他节点,并根据各节点信息修改相应的配置项。确保集群配置的一致性,同时适应每个节点的特定环境。
#设置免密
[worker@kafka-node-01 config]$ scp server.properties 172.16.130.13:`pwd`
server.properties 100% 1163 4.5MB/s 00:00
[worker@kafka-node-01 config]$ scp server.properties 172.16.130.15:`pwd`
server.properties 100% 1163 4.3MB/s 00:00
[worker@kafka-node-01 config]$
#节点172.16.130.13
[worker@kafka-node-03 config]$ vim server.properties
node.id=2
advertised.listeners=PLAINTEXT://kafka-node-02:9092
#节点172.16.130.15
[worker@kafka-node-03 config]$ vim server.properties
node.id=3
advertised.listeners=PLAINTEXT://kafka-node-03:9092
4.初始化集群
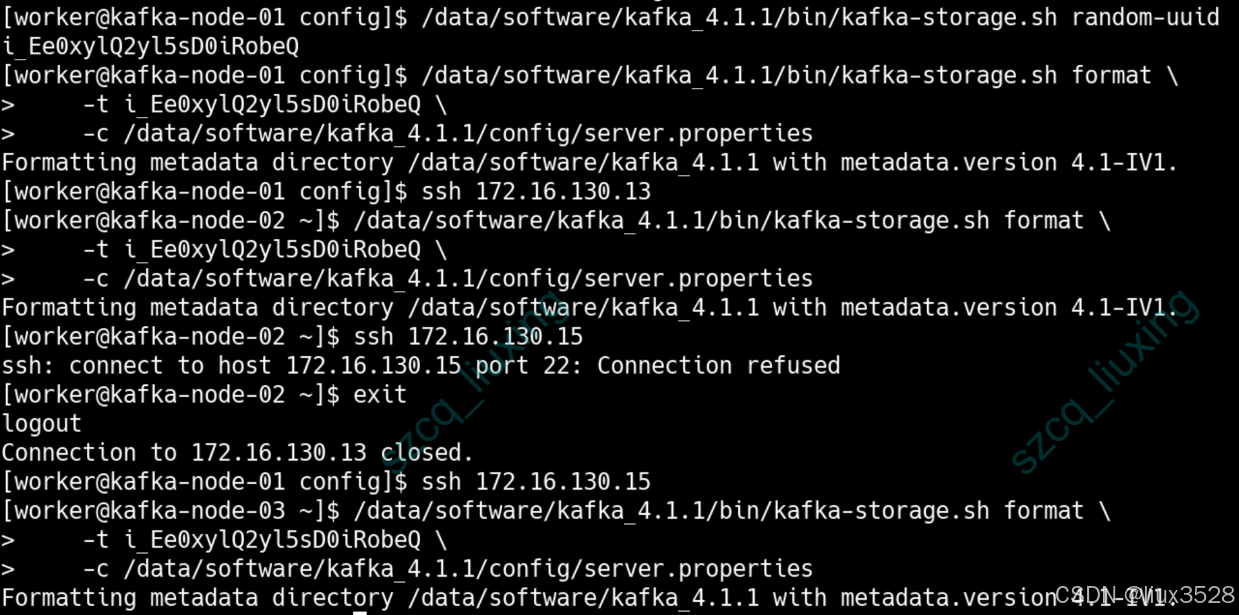
初始化是 Kafka 集群启动前的关键步骤,包括生成唯一的集群 ID 和格式化每个节点的存储目录。这确保集群具有唯一的标识,并且数据目录结构正确。
# 01. 生成集群UUID(仅在任意一个节点执行一次)
/data/software/kafka_4.1.1/bin/kafka-storage.sh random-uuid
# 输出示例:6UlNw0IfR5-mEArqnPh1aQ
# 02. 格式化存储目录(在每个节点执行,使用相同的UUID)
/data/software/kafka_4.1.1/bin/kafka-storage.sh format \\
-t 6UlNw0IfR5-mEArqnPh1aQ \\
-c /data/software/kafka_4.1.1/config/server.properties
5.创建启动脚本(所有节点)
编写统一的启动脚本,规范 Kafka 服务的启动、停止、重启和状态查看操作。脚本包含用户检查、进程管理和日志查看功能,便于日常运维。
[worker@kafka-node-01 bin]$ cat kafka.sh
#!/bin/bash
# kafka.sh – Kafka启动管理脚本
KAFKA_HOME="/data/software/kafka_4.1.1"
KAFKA_USER="worker"
CONFIG="$KAFKA_HOME/config/server.properties"
PID_FILE="$KAFKA_HOME/kafka.pid"
LOG_FILE="$KAFKA_HOME/logs/kafka.out"
# JVM参数(根据机器内存调整,这里设为8GB)
JVM_OPTS="-Xms8g -Xmx8g"
# 检查用户
check_user() {
if [ "$(whoami)" != "$KAFKA_USER" ]; then
echo "错误:请使用 $KAFKA_USER 用户运行此脚本"
echo "使用方法: sudo -u $KAFKA_USER $0"
exit 1
fi
}
# 启动Kafka
start() {
check_user
if [ -f "$PID_FILE" ]; then
PID=$(cat "$PID_FILE")
if kill -0 $PID 2>/dev/null; then
echo "Kafka已在运行 (PID: $PID)"
exit 0
fi
fi
echo "启动Kafka…"
export KAFKA_HEAP_OPTS="$JVM_OPTS"
cd "$KAFKA_HOME"
nohup bin/kafka-server-start.sh "$CONFIG" > "$LOG_FILE" 2>&1 &
echo $! > "$PID_FILE"
echo "Kafka已启动,PID: $(cat $PID_FILE)"
}
# 停止Kafka
stop() {
check_user
if [ -f "$PID_FILE" ]; then
PID=$(cat "$PID_FILE")
echo "停止Kafka (PID: $PID)…"
"$KAFKA_HOME/bin/kafka-server-stop.sh"
sleep 5
if kill -0 $PID 2>/dev/null; then
echo "强制终止Kafka…"
kill -9 $PID
fi
rm -f "$PID_FILE"
echo "Kafka已停止"
else
echo "未找到PID文件,尝试查找Kafka进程…"
PID=$(ps aux | grep kafka | grep -v grep | grep -v "$0" | awk '{print $2}')
if [ -n "$PID" ]; then
echo "停止Kafka进程: $PID"
kill $PID
else
echo "未找到运行的Kafka进程"
fi
fi
}
# 重启Kafka
restart() {
stop
sleep 2
start
}
# 查看状态
status() {
if [ -f "$PID_FILE" ]; then
PID=$(cat "$PID_FILE")
if kill -0 $PID 2>/dev/null; then
echo "Kafka正在运行 (PID: $PID)"
return 0
else
echo "Kafka已停止"
return 1
fi
else
echo "Kafka未运行"
return 1
fi
}
# 查看日志
logs() {
if [ -f "$LOG_FILE" ]; then
tail -f "$LOG_FILE"
else
echo "日志文件不存在: $LOG_FILE"
fi
}
# 使用方法
usage() {
echo "使用方法: $0 {start|stop|restart|status|logs}"
echo " 启动用户: $KAFKA_USER"
echo " 安装目录: $KAFKA_HOME"
}
# 主逻辑
case "$1" in
start)
start
;;
stop)
stop
;;
restart)
restart
;;
status)
status
;;
logs)
logs
;;
*)
usage
exit 1
;;
esac
#赋予执行权限
[worker@kafka-node-01 bin]$ chmod u+x kafka.sh
#拷贝到其他节点
[worker@kafka-node-01 bin]$ scp kafka.sh 172.16.130.13:`pwd`
[worker@kafka-node-01 bin]$ scp kafka.sh 172.16.130.15:`pwd`
6.集群管理脚本
创建集群级别的管理脚本,可以同时对多个节点执行相同的操作(启动、停止、重启、查看状态)。这大大简化了多节点集群的运维工作。
[worker@kafka-node-01 kafka_4.1.1]$ cat kafka-cluster-ctl.sh
#!/bin/bash
# Kafka集群快速控制脚本
NODES=("172.16.130.3" "172.16.130.13" "172.16.130.15")
SSH_USER="worker"
KAFKA_SCRIPT="/data/software/kafka_4.1.1/bin/kafka.sh"
usage() {
echo "Usage: $0 {start|stop|restart|status} [node_ip]"
echo "Example:"
echo " $0 start # 启动所有节点"
echo " $0 stop 172.16.130.3 # 停止指定节点"
exit 1
}
run_command() {
local cmd=$1
local node=$2
if [ -n "$node" ]; then
echo "[Executing on $node]"
ssh $SSH_USER@$node "$KAFKA_SCRIPT $cmd"
else
for node in "${NODES[@]}"; do
echo "[Executing on $node]"
ssh $SSH_USER@$node "$KAFKA_SCRIPT $cmd" &
done
wait
echo "All nodes processed."
fi
}
# 主逻辑
case $1 in
start|stop|restart|status)
run_command $1 $2
;;
*)
usage
;;
esac
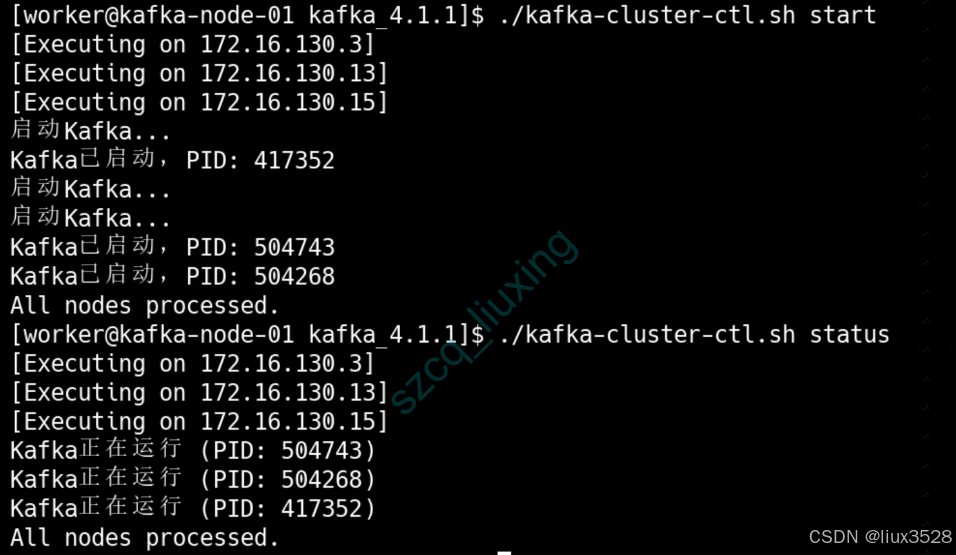
[worker@kafka-node-01 kafka_4.1.1]$ ./kafka-cluster-ctl.sh start
如下图所示,说明我们kafka集群已经成功启动
7.测试
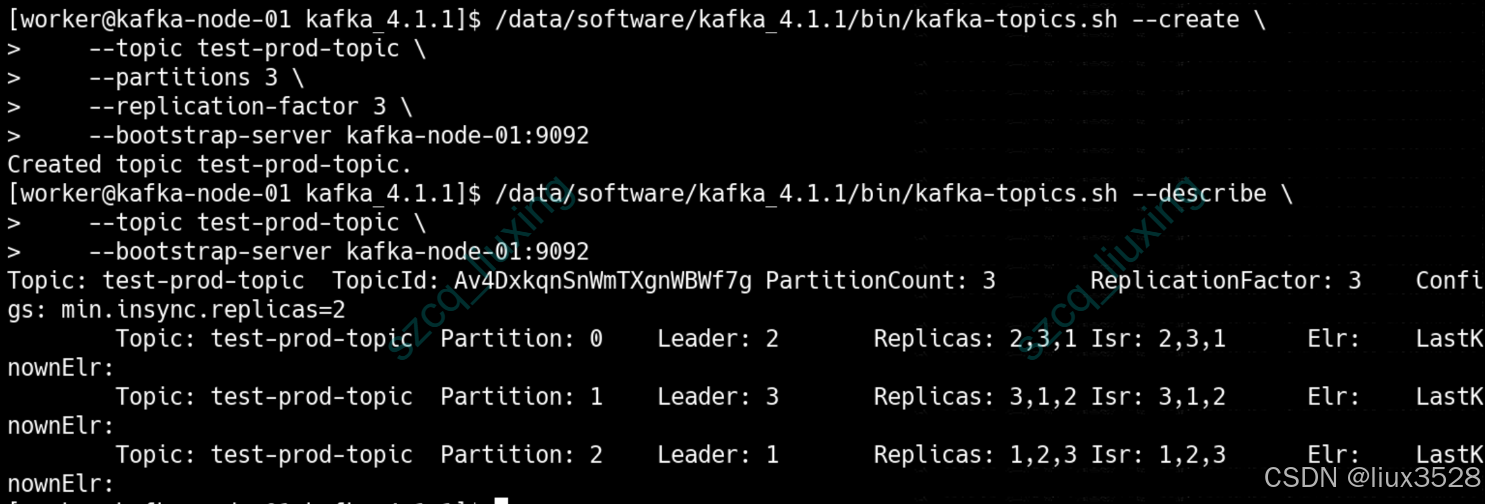
集群启动后,通过创建 Topic、查看分区分布等操作验证集群是否正常工作。这是部署完成后必要的验证步骤,确保集群可以正常提供服务。
/data/software/kafka_4.1.1/bin/kafka-topics.sh –create \\
–topic test-prod-topic \\
–partitions 3 \\
–replication-factor 3 \\
–bootstrap-server kafka-node-01:9092
# 查看Topic详情,确认分区均匀分布在不同Broker上
/data/software/kafka_4.1.1/bin/kafka-topics.sh –describe \\
–topic test-prod-topic \\
–bootstrap-server kafka-node-01:9092
四、安全认证
本章节介绍如何为生产环境 Kafka 集群配置 SASL/SCRAM 安全认证。安全认证是生产环境的基本要求,可以防止未授权访问,保护数据安全。
安全说明:生产环境中,Kafka 集群必须启用安全认证。SASL/SCRAM 提供了一种相对安全且支持动态用户管理的认证机制,适合大多数生产场景。
1. 动态创建SCRAM用户(集群启动后执行)
使用 Kafka 管理工具动态创建 SCRAM 用户。与静态配置文件不同,SCRAM 用户凭证存储在 Kafka 内部,支持动态添加和修改,无需重启服务。
# 在任一节点,使用PLAINTEXT连接先创建用户(集群安全启用前操作)
/data/software/kafka_4.1.1/bin/kafka-configs.sh \\
–bootstrap-server kafka-node-01:9092 \\
–entity-type users –entity-name admin \\
–alter –add-config 'SCRAM-SHA-512=[password=aTu!O8jxoTH4$q%o]'
#安全启动后
/data/software/kafka_4.1.1/bin/kafka-configs.sh \\
–bootstrap-server kafka-node-01:9092 \\
–entity-type users –entity-name kafkaui \\
–alter –add-config 'SCRAM-SHA-512=[password=4LT%897@211uRuhO]' \\
–command-config /data/software/kafka_4.1.1/config/client-scram.properties
/data/software/kafka_4.1.1/bin/kafka-configs.sh \\
–bootstrap-server kafka-node-01:9092 \\
–entity-type users –entity-name kafka_canal \\
–alter –add-config 'SCRAM-SHA-512=[password=vvJ20n7j7iKv!vA4]' \\
–command-config /data/software/kafka_4.1.1/config/client-scram.properties
# 验证用户已添加
/data/software/kafka_4.1.1/bin/kafka-configs.sh \\
–bootstrap-server kafka-node-01:9092 \\
–entity-type users –describe
如下图所示账号已成功添加


2. 修改server.properties配置文件(所有节点)
修改 Kafka 服务器的配置文件,将监听器协议从 PLAINTEXT 改为 SASL_PLAINTEXT,并指定使用 SCRAM-SHA-512 认证机制。这是启用安全认证的关键配置。
[worker@kafka-node-01 config]$ vim server.properties
# ====== 关键修改点 ======
############################# 网络监听器 #############################
# 外部客户端访问端口 (9092) 和 Controller内部通信端口 (9093)
listeners=SASL_PLAINTEXT://:9092,CONTROLLER://:9093
inter.broker.listener.name=SASL_PLAINTEXT
# 【关键】各节点需改为自己的主机名/IP
advertised.listeners=SASL_PLAINTEXT://kafka-node-01:9092
listener.security.protocol.map=CONTROLLER:PLAINTEXT,SASL_PLAINTEXT:SASL_PLAINTEXT
# ====== SASL 配置 ======
sasl.enabled.mechanisms=SCRAM-SHA-512
sasl.mechanism.inter.broker.protocol=SCRAM-SHA-512
3. 创建JAAS文件 kafka_server_jaas.conf(所有节点)
创建 JAAS 配置文件,为 Kafka Broker 提供自身认证信息。在 SCRAM 模式下,该文件仅包含 Broker 进程用于启动和内部通信的凭证。
[worker@kafka-node-01 ~]$ cat > /data/software/kafka_4.1.1/config/kafka_server_jaas.conf << 'EOF'
KafkaServer {
org.apache.kafka.common.security.scram.ScramLoginModule required
username="admin"
password="aTu!O8jxoTH4$q%o";
};
EOF
chmod 600 /data/software/kafka_4.1.1/config/kafka_server_jaas.conf
4. 更新启动文件
修改启动脚本,通过环境变量指定 JAAS 配置文件的路径,确保 Kafka 进程启动时能够加载安全认证配置。
#在启动文件中添加下面一行
[worker@kafka-node-01 bin]$ vim kafka.sh
export KAFKA_OPTS="Djava.security.auth.login.config=/data/software/kafka_4.1.1/config/kafka_server_jaas.conf"
#拷贝到其他节点
[worker@kafka-node-01 bin]$ scp kafka.sh 172.16.130.13:`pwd`
[worker@kafka-node-01 bin]$ scp kafka.sh 172.16.130.15:`pwd`
5. 启动集群
使用集群管理脚本重新启动所有节点,使安全认证配置生效。重启后,所有客户端连接都需要提供正确的认证信息。
[worker@kafka-node-01 kafka_4.1.1]$ ./kafka-cluster-ctl.sh stop
[worker@kafka-node-01 kafka_4.1.1]$ ./kafka-cluster-ctl.sh start
6. 客户端连接测试
创建客户端配置文件,使用正确的用户名和密码连接启用了安全认证的 Kafka 集群,验证认证配置是否正确。
#01 添加连接配置
[worker@kafka-node-01 config]$ cat client-scram.properties
bootstrap.servers=kafka-node-01:9092,kafka-node-02:9092,kafka-node-03:9092
security.protocol=SASL_PLAINTEXT
sasl.mechanism=SCRAM-SHA-512
sasl.jaas.config=org.apache.kafka.common.security.scram.ScramLoginModule required \\
username="admin" \\
password="aTu!O8jxoTH4$q%o";
#02 连接测试
# 1. 测试列出Topic (最基本的连接和认证测试)
/data/software/kafka_4.1.1/bin/kafka-topics.sh –list \\
–bootstrap-server kafka-node-01:9092 \\
–command-config /data/software/kafka_4.1.1/config/client-scram.properties
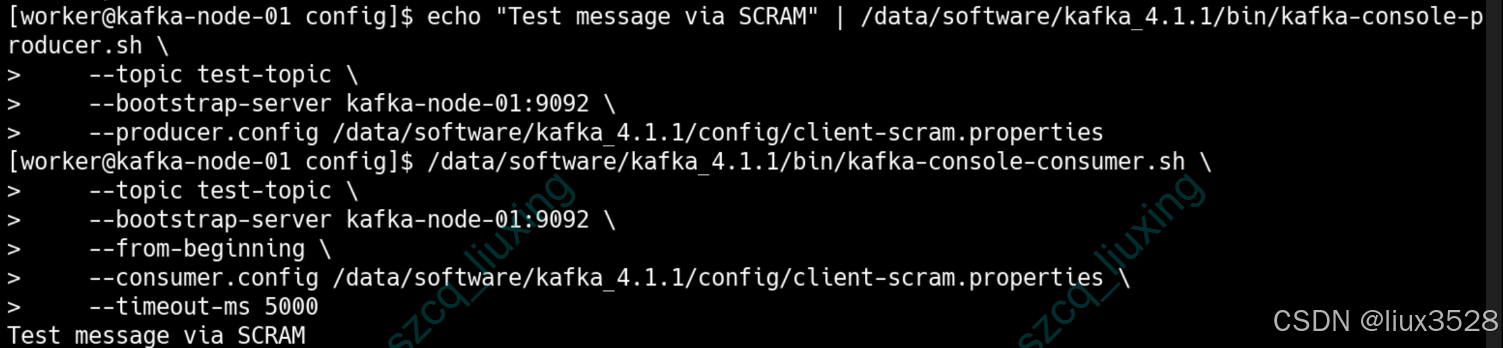
# 2. 生产一条测试消息
echo "Test message via SCRAM" | /data/software/kafka_4.1.1/bin/kafka-console-producer.sh \\
–topic test-topic \\
–bootstrap-server kafka-node-01:9092 \\
–producer.config /data/software/kafka_4.1.1/config/client-scram.properties
# 3. 消费测试消息
/data/software/kafka_4.1.1/bin/kafka-console-consumer.sh \\
–topic test-topic \\
–bootstrap-server kafka-node-01:9092 \\
–from-beginning \\
–consumer.config /data/software/kafka_4.1.1/config/client-scram.properties \\
–timeout-ms 5000
五、生产调优
1.操作系统调优(所有节点)
优化操作系统内核参数,提升网络性能和文件处理能力,为 Kafka 的高性能运行提供底层支持。
# 调整内核参数
[root@kafka-node-01 kafka_4.1.1]# tee -a /etc/sysctl.conf << EOF
net.core.rmem_default=262144
net.core.wmem_default=262144
net.core.rmem_max=16777216
net.core.wmem_max=16777216
net.ipv4.tcp_rmem=4096 87380 16777216
net.ipv4.tcp_wmem=4096 65536 16777216
vm.swappiness=1
EOF
[root@kafka-node-01 kafka_4.1.1]# sysctl -p
# 调整文件句柄限制
[root@kafka-node-01 kafka_4.1.1]# vim /etc/security/limits.conf
* soft nofile 655350
* hard nofile 655350
2.Kafka关键生产参数(所有节点)
调整 Kafka 的关键配置参数,优化网络处理、数据复制、日志保留等方面的性能,以适应生产环境的高负载需求。
[worker@kafka-node-01 ~]$ cd /data/software/kafka_4.1.1/config/
[worker@kafka-node-01 config]$ vim server.properties
# 网络与IO性能
#网络线程池大小。设置过小会成为网络瓶颈,设置过大会造成不必要的上下文切换。 对于生产环境,8-16 是常见范围。
num.network.threads=8
#IO 线程池大小,其数量通常配置为 CPU 核心数的 1.5 到 2 倍左右。您配置的 16 适合 8-12 核的服务器。
num.io.threads=16
#TCP 发送缓冲区大小 (SO_SNDBUF) 约 1 MB
socket.send.buffer.bytes=1024000
#TCP 接收缓冲区大小 (SO_RCVBUF) 约 1 MB
socket.receive.buffer.bytes=1024000
# 复制与可用性
#是否允许“非同步”副本当选 Leader
unclean.leader.election.enable=false
#副本滞后最大时间 30s
replica.lag.time.max.ms=30000
# 日志保留策略
#基于时间的日志保留策略。Kafka 会自动删除超过 168 小时(即 7 天) 的旧日志段文件。这是控制数据保留期的核心参数。如果同时设置了 log.retention.bytes,则任一条件满足时都会触发删除.
log.retention.hours=168
#基于分区大小的日志保留策略
#Kafka 会保证单个分区的日志文件总大小不超过 10 GB,超出部分会被删除。这个限制是针对每个分区的,如果一个 Topic 有多个分区,则其总存储空间 = 10 GB × 分区数。它常与 log.retention.hours 结合使用,形成“时间或空间任一超标即清理”的双重保障。
log.retention.bytes=10737418240
#日志段文件大小。Kafka 的日志在物理上由多个“段文件”组成。此参数规定每个段文件的最大大小为 1 GB。当活跃段文件达到此大小时,Kafka 会将其关闭并创建一个新的段文件。更大的段文件可以减少文件数量,提升顺序IO效率,但会延长日志压缩和加载时间。
log.segment.bytes=1073741824
六、集群常用命令
本章节汇总了 Kafka 集群运维中常用的命令行工具和命令,涵盖基础操作、消费组管理和 KRaft 集群状态检查等。
命令说明:掌握 Kafka 命令行工具是日常运维的基础。本节整理了最常用的命令和它们的典型用途,帮助您快速管理和监控集群。
1.基础命令测试
Kafka 基础操作命令,包括 Topic 管理、消息生产和消费等。这些是日常运维中最常用的功能。
# 1. 测试列出Topic (最基本的连接和认证测试)
/data/software/kafka_4.1.1/bin/kafka-topics.sh –list \\
–bootstrap-server kafka-node-01:9092 \\
–command-config /data/software/kafka_4.1.1/config/client-scram.properties
#查看单个topic详细信息
/data/software/kafka_4.1.1/bin/kafka-topics.sh \\
–bootstrap-server kafka-node-01:9092 \\
–describe –topic event_es_index \\
–command-config /data/software/kafka_4.1.1/config/client-scram.properties
# 2.创建topic event_es_index
/data/software/kafka_4.1.1/bin/kafka-topics.sh –create \\
–bootstrap-server kafka-node-01:9092 \\
–topic event_es_index \\
–partitions 3 \\
–replication-factor 3\\
–command-config /data/software/kafka_4.1.1/config/client-scram.properties
# 3. 生产一条测试消息
echo "Test message via SCRAM" | /data/software/kafka_4.1.1/bin/kafka-console-producer.sh \\
–topic test-topic \\
–bootstrap-server kafka-node-01:9092 \\
–producer.config /data/software/kafka_4.1.1/config/client-scram.properties
# 4. 消费测试消息
#从头开始消费
/data/software/kafka_4.1.1/bin/kafka-console-consumer.sh \\
–topic event_es_index \\
–bootstrap-server kafka-node-01:9092 \\
–from-beginning \\
–consumer.config /data/software/kafka_4.1.1/config/client-scram.properties \\
–timeout-ms 5000
#消费最新消息
/data/software/kafka_4.1.1/bin/kafka-console-consumer.sh \\
–bootstrap-server kafka-node-01:9092 \\
–topic task_es_index \\
–property print.timestamp=true \\
–property print.key=true \\
–property print.value=true \\
–consumer.config /data/software/kafka_4.1.1/config/client-scram.properties
2.消费组命令
消费组管理命令,用于查看消费者组的状态、偏移量和积压情况,是监控消费进度和排查消费问题的重要工具。
#查看消费者组
/data/software/kafka_4.1.1/bin/kafka-consumer-groups.sh –list \\
–bootstrap-server 172.16.130.3:9092 \\
–command-config /data/software/kafka_4.1.1/config/client-scram.properties
#查看消费者组详细信息
/data/software/kafka_4.1.1/bin/kafka-consumer-groups.sh \\
–bootstrap-server 172.16.130.3:9092 \\
–group canal_task_group –describe \\
–command-config /data/software/kafka_4.1.1/config/client-scram.properties
关键指标说明:
CURRENT-OFFSET: 消费者当前消费到的偏移量
LOG-END-OFFSET: 分区最新消息的偏移量
LAG: 积压消息数 = LOG-END-OFFSET – CURRENT-OFFSET
LAG=0: 表示所有消息都已消费,无积压
3.KRaft 核心状态
KRaft 模式特有的集群状态检查命令,用于监控 Controller 集群的健康状况和数据一致性。这是确保 KRaft 集群正常运行的关键。
这是KRaft模式特有的健康检查,关乎集群的“大脑”是否正常。
3.1 查看集群ID
/data/software/kafka_4.1.1/bin/kafka-cluster.sh cluster-id \\
–bootstrap-server kafka-node-01:9092 \\
–config /data/software/kafka_4.1.1/config/client-scram.properties

3.2 查看集群状态摘要
/data/software/kafka_4.1.1/bin/kafka-metadata-quorum.sh \\
–bootstrap-server kafka-node-01:9092 \\
–command-config /data/software/kafka_4.1.1/config/client-scram.properties \\
describe –status
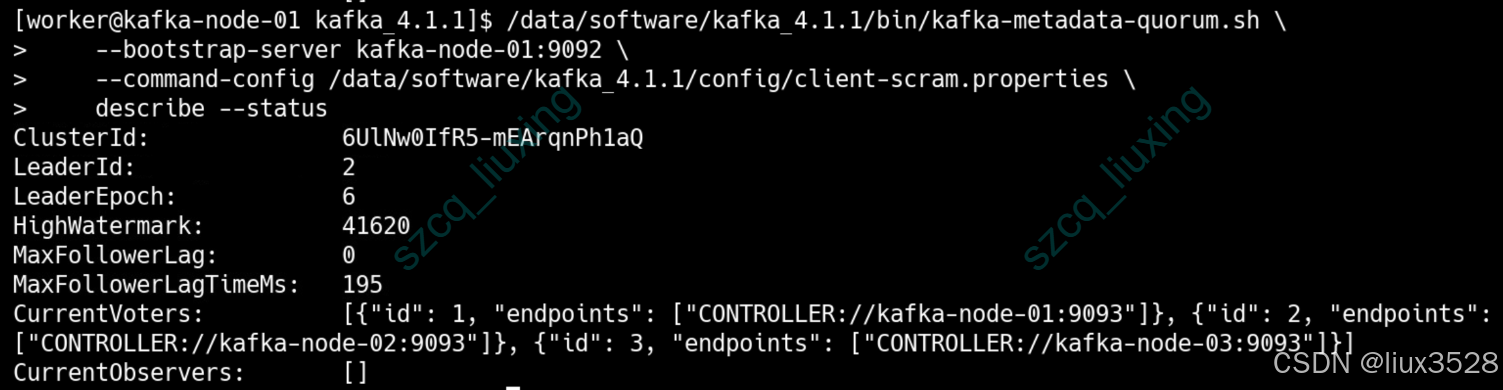
#重点分析 describe 命令的输出:
#集群有唯一标识符
ClusterId: 6UlNw0IfR5-mEArqnPh1aQ
# Leader是节点2(kafka-node-02)
LeaderId: 2
#Leader任期正常
LeaderEpoch: 6
#数据一致性校验
#已提交日志位置
HighWatermark: 41620
#关键指标:所有follower与leader完全同步,零延迟!
MaxFollowerLag: 0
# 延迟时间仅192毫秒,非常低
MaxFollowerLagTimeMs: 195
#控制器集群完整,所有3个controller节点都在线并参与投票
CurrentVoters: [{"id": 1, "endpoints": ["CONTROLLER://kafka-node-01:9093"]}, {"id": 2, "endpoints": ["CONTROLLER://kafka-node-02:9093"]}, {"id": 3, "endpoints": ["CONTROLLER://kafka-node-03:9093"]}]
CurrentObservers: []
3.3 查看集群复制详情
/data/software/kafka_4.1.1/bin/kafka-metadata-quorum.sh \\
–bootstrap-server kafka-node-01:9092 \\
–command-config /data/software/kafka_4.1.1/config/client-scram.properties \\
describe –replication –human-readable

| NodeId | 节点ID | 2,1,3 | 三个broker节点 |
| DirectoryId | 元数据目录ID | AAAAAAAAAAAAAAAAAAAAAA | 所有节点使用相同的元数据目录 |
| LogEndOffset | 日志结束偏移量 | 42152 | 所有节点日志位置完全一致 |
| Lag | 延迟消息数 | 0 | 所有节点零延迟 |
| LastFetchTimestamp | 最后获取时间 | 21 ms / 294 ms / 295 ms | 最近一次从Leader获取数据的时间 |
| LastCaughtUpTimestamp | 最后同步时间 | 22 ms / 294 ms / 295 ms | 最近一次与Leader同步的时间 |
| Status | 节点角色 | Leader/Follower | 节点2是Leader,1和3是Follower |
4.检查 Broker 与数据层状态
检查 Kafka Broker 和数据层的健康状况,包括 Broker 是否在线、分区副本是否同步、是否有不可用分区等。这是确保数据服务正常的关键检查。
确认数据存储和服务的“肢体”是否健康。
- 健康标志:
- broker-api-versions 成功返回所有配置的Broker地址和版本信息。
- –under-replicated-partitions 命令输出为空(表示没有未同步的副本)。
- –unavailable-partitions 命令输出为空(表示所有分区都有活跃的Leader,可读写)。
# 1. 检查所有Broker是否在线
/data/software/kafka_4.1.1/bin/kafka-broker-api-versions.sh \\
–bootstrap-server kafka-node-01:9092 \\
–command-config /data/software/kafka_4.1.1/config/client-scram.properties
# 2. 检查所有Topic的详细状态,重点关注 “Under-Replicated” 分区
/data/software/kafka_4.1.1/bin/kafka-topics.sh –describe \\
–under-replicated-partitions \\
–bootstrap-server kafka-node-01:9092 \\
–command-config /data/software/kafka_4.1.1/config/client-scram.properties
# 3. 检查是否有离线分区 (Offline Partitions)
/data/software/kafka_4.1.1/bin/kafka-topics.sh –describe \\
–unavailable-partitions \\
–bootstrap-server kafka-node-01:9092 \\
–command-config /data/software/kafka_4.1.1/config/client-scram.properties
七、部署kafka-ui
本章节介绍如何部署 Kafka-UI,一个流行的 Kafka 集群管理界面。Kafka-UI 提供了图形化的管理界面,方便查看集群状态、管理 Topic 和监控消费组。
UI说明:Kafka-UI 是一个开源的 Web 管理界面,提供了比命令行更直观的集群管理方式。部署 Kafka-UI 可以显著提高运维效率。
1.下载
从 GitHub 发布页面下载 Kafka-UI 的 JAR 包。选择与您的环境兼容的版本。
https://github.com/provectus/kafka-ui/releases/download/v0.7.2/kafka-ui-api-v0.7.2.jar
2.编写配置文件
创建 Kafka-UI 的配置文件,指定要连接的 Kafka 集群地址、安全认证信息以及 Web 服务的端口等。正确的配置是 Kafka-UI 能够正常连接和展示集群信息的关键。
[worker@ansible-111 kafka-ui]$ vim application.yml
# application.yml 示例
kafka:
clusters:
# 这里定义你的第一个KRaft集群
– name: kafka-prod-cluster # 自定义集群名称
bootstrapServers: "kafka-node-01:9092,kafka-node-02:9092,kafka-node-03:9092" #【关键】你的KRaft集群Broker地址[citation:1]
# 注意:对于KRaft模式,只需配置bootstrapServers,无需zookeeper配置[citation:1]
properties:
security.protocol: SASL_PLAINTEXT
sasl.mechanism: SCRAM-SHA-512
sasl.jaas.config: org.apache.kafka.common.security.scram.ScramLoginModule required username="kafkaui" password="4LT%897@211uRuhO";
# 【生产环境建议启用】安全认证配置
auth:
type: LOGIN_FORM # 使用表单登录,设为 DISABLED 则无需登录
spring:
security:
user:
name: admin # 登录用户名
password: jczz@1234 # 设置强密码[citation:1]
# 服务端口
server:
port: 18080
3.在kafka中添加kafkaui用户
为 Kafka-UI 创建一个专用的用户,并授予适当的权限。这遵循了最小权限原则,提高安全性。
#添加用户 #安全启动后 创建kafkaui用户需要加–command-config执行密钥
/data/software/kafka_4.1.1/bin/kafka-configs.sh \\
–bootstrap-server kafka-node-01:9092 \\
–entity-type users –entity-name kafkaui \\
–alter –add-config 'SCRAM-SHA-512=[password=4LT%897@211uRuhO]' \\
–command-config /data/software/kafka_4.1.1/config/client-scram.properties
#修改密码
/data/software/kafka_4.1.1/bin/kafka-configs.sh \\
–bootstrap-server kafka-node-01:9092 \\
–command-config /data/software/kafka_4.1.1/config/client-scram.properties \\
–entity-type users \\
–entity-name kafkaui \\
–alter \\
–add-config 'SCRAM-SHA-512=[password=KJB^Xde!CmFkW6bG]'
4.添加启动kafka脚本
创建 Kafka-UI 的启动脚本,方便服务的启动、停止和管理。脚本会自动处理进程管理和日志输出。
#启动脚本
[worker@ansible-111 kafka-ui]$ vim restart.sh
#!/bin/bash
pid=`ps -ef|grep kafka-ui | grep -v grep | awk '{print $2}'`
kill -9 $pid
sleep 3s
nohup java -jar kafka-ui-*.jar –spring.config.location=application.yml >>kafkaui.out 2>&1 &
[worker@ansible-111 kafka-ui]$ chmod u+x restart.sh
[worker@ansible-111 kafka-ui]$ ./restart.sh
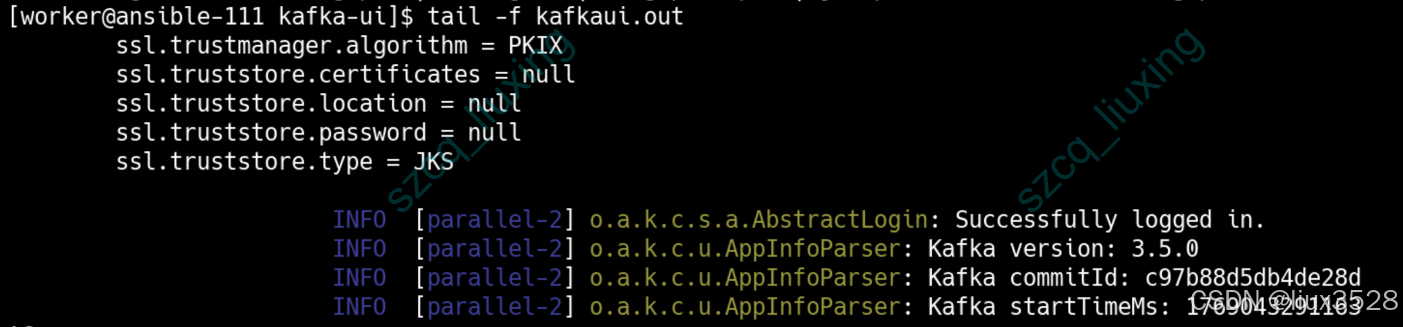
[worker@ansible-111 kafka-ui]$ tail -f kafkaui.out
如下图所示,kafka-ui已经启动成功了
八、部署kafka-exporter
本章节介绍如何部署 Kafka Exporter,将 Kafka 集群的监控指标暴露给 Prometheus。Kafka Exporter 是监控 Kafka 集群健康状态和性能的关键组件。
监控说明:Kafka Exporter 收集 Kafka 集群的各种指标(如 Topic 分区数、消费组延迟、Broker 状态等),并通过 HTTP 端点暴露给 Prometheus,便于集中监控和告警。
1.下载
从 GitHub 发布页面下载 Kafka Exporter 的二进制包。选择与您的系统架构匹配的版本。
https://github.com/danielqsj/kafka_exporter/releases/download/v1.9.0/kafka_exporter-1.9.0.linux-arm64.tar.gz
2.解压部署
解压下载的压缩包,并将可执行文件移动到合适的位置,准备配置和启动。
tar xf kafka_exporter-1.9.0.linux-arm64.tar.gz
mv kafka_exporter-1.9.0.linux-arm64 kafka_exporter
mv kafka_exporter /usr/local/
3.配置启动文件
创建 Systemd 服务文件,配置 Kafka Exporter 的启动参数,包括要监控的 Kafka 集群地址、安全认证信息以及监听的端口。然后启动服务并设置开机自启。
# 01. 创建系统服务文件
[root@ansible-111 worker]# cat /etc/systemd/system/kafka-exporter.service
[Unit]
Description=Kafka Exporter for Prometheus
Documentation=https://github.com/danielqsj/kafka_exporter
After=network.target
[Service]
User=worker
Group=worker
WorkingDirectory=/usr/local/kafka_exporter
ExecStart=/usr/local/kafka_exporter/kafka_exporter \\
–kafka.server=172.16.130.3:9092 \\
–kafka.server=172.16.130.13:9092 \\
–kafka.server=172.16.130.15:9092 \\
–kafka.version=4.1.1 –web.listen-address=:9308 \\
–log.level=info –sasl.enabled \\
–sasl.mechanism=scram-sha512 \\
–sasl.username=admin \\
–sasl.password='aTu!O8jxoTH4$q%%o'
Restart=always
RestartSec=5
[Install]
WantedBy=multi-user.target
# 02. 重载系统服务并启动
systemctl daemon-reload
systemctl start kafka-exporter
systemctl enable kafka-exporter
# 03. 验证运行状态(输出 active (running) 则正常)
systemctl status elasticsearch-exporter
journalctl -u kafka-exporter -f
# 04. 验证指标接口(返回 es_ 开头的指标则说明采集成功)
curl http://172.16.130.111:9308/metrics
九、总结
本文详细介绍了 Kafka 4.1.1 生产集群的完整部署流程,从环境规划、集群部署、安全认证到监控管理,涵盖了生产环境所需的各个环节。通过遵循本指南,您可以构建一个高可用、安全且易于维护的 Kafka 集群。
关键要点总结:
- 架构设计:采用 3 节点 KRaft 模式,实现高可用和去 ZooKeeper 依赖。合理设置副本因子和最小同步副本,确保数据安全。
- 安全认证:启用 SASL/SCRAM 认证,为不同应用创建专用用户,遵循最小权限原则。动态用户管理提高了运维灵活性。
- 性能调优:根据硬件资源和业务需求调整操作系统参数和 Kafka 配置,优化集群性能。
- 运维工具:提供集群管理脚本、常用命令行工具,部署 Kafka-UI 和 Kafka Exporter,简化日常运维和监控。
- 健康检查:掌握 KRaft 集群状态检查和数据层健康检查方法,确保集群稳定运行。
通过本指南的实践,您不仅能够成功部署 Kafka 集群,还能够建立一套完整的运维体系,为业务提供可靠的消息服务基础。建议在生产环境中结合具体的业务场景和性能测试,进一步调整和优化相关参数。




评论前必须登录!
注册