 网硕互联帮助中心
网硕互联帮助中心最近在学习 Python 数据分析,我用 PyCharm 写了几段代码,把从数据清洗到可视化的完整流程跑了一遍。今天就来分享一下我的实战心得,希望能帮到刚入门的朋友。
📊 一、Pandas:数据处理的基石
数据分析的第一步,永远是处理原始数据。Pandas 作为 Python 数据分析的核心库,让这个过程变得非常高效。
1. 创建与查看 DataFrame我们可以用字典快速构造一个数据集,然后转换成 DataFrame 表格,这样就能直观地看到数据结构。
import pandas as pd
dic = {'name': ['kiti', 'beta', 'peter', 'tom'],
'age':[20,18, 35,21],
'gender': ['f', 'f', 'm', 'm']}
df = pd.DataFrame(dic)
print(df)
df = df.sort_values(by=['age'])
df = df.sort_values(by=['age'], ascending=False)
a= df['gender']
b = a.replace(['m', 'f'],['male', 'female'])
df['gender'] = b
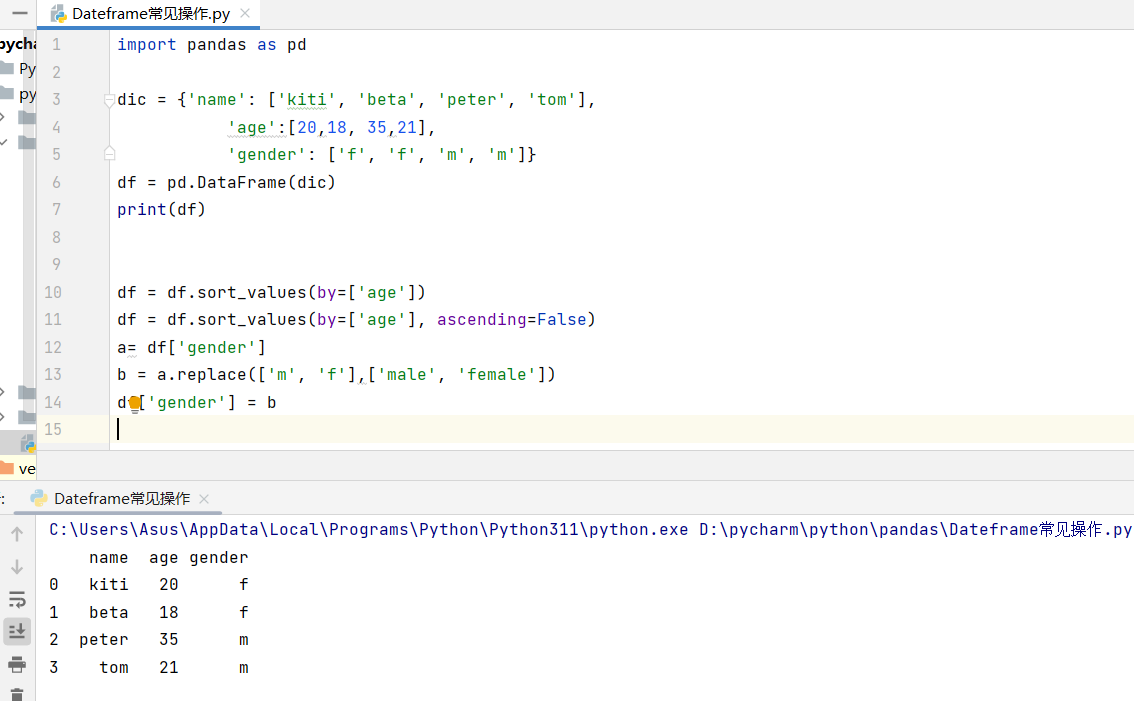
2. 数据排序
sort_values() 是我最常用的函数之一,它可以让我快速按某一列排序,找到极值。
# 按年龄升序
df = df.sort_values(by=['age'])
# 按年龄降序
df = df.sort_values(by=['age'], ascending=False)
这一步能帮我快速定位到年龄最大或最小的记录,为后续分析提供线索。
3. 数据映射与替换
原始数据里的简写(比如 'm' 和 'f')可读性很差,用 replace() 可以轻松映射成更直观的文字。
a = df['gender']
b = a.replace(['m', 'f'], ['male', 'female'])
df['gender'] = b
处理后,gender 列就会显示 male 和 female,整个数据集的可读性立刻提升。
4. 文件读写
数据分析离不开和外部文件打交道,Pandas 支持多种格式的读写,非常方便。
import pandas as pd
df_1 = pd.read_csv("../numpy/data1.csv")
df_2 = pd.read_csv("../numpy/data2.csv", encoding='utf8', header=None)
df_3 = pd.read_excel("data3.xlsx") #
df_4 = pd.read_table("data4.txt",sep=',',header=None)
df_1.to_csv("导出.csv",index=True, header=True)
df_1.to_excel("导出.xlsx",index=True, header=True)
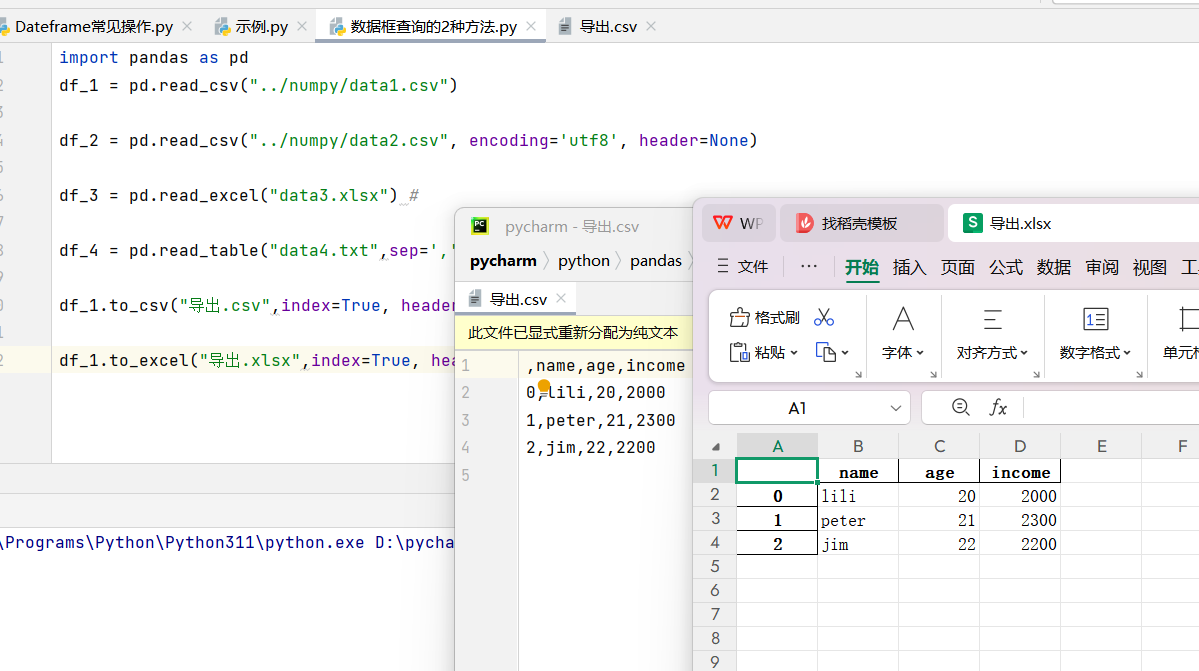
📌 小技巧:遇到乱码问题时,可以试试 encoding='utf8' 或 'gbk';如果文件没有表头,记得设置 header=None。
5. 缺失值处理
真实数据总会有缺失值,Pandas 提供了两种核心处理方式:
import pandas as pd
df = pd.read_csv(r"../numpy/data1.csv", encoding='gbk')
na = df.isnull()
df1 = df.fillna('1')
df2 = df.dropna()
print(df2)
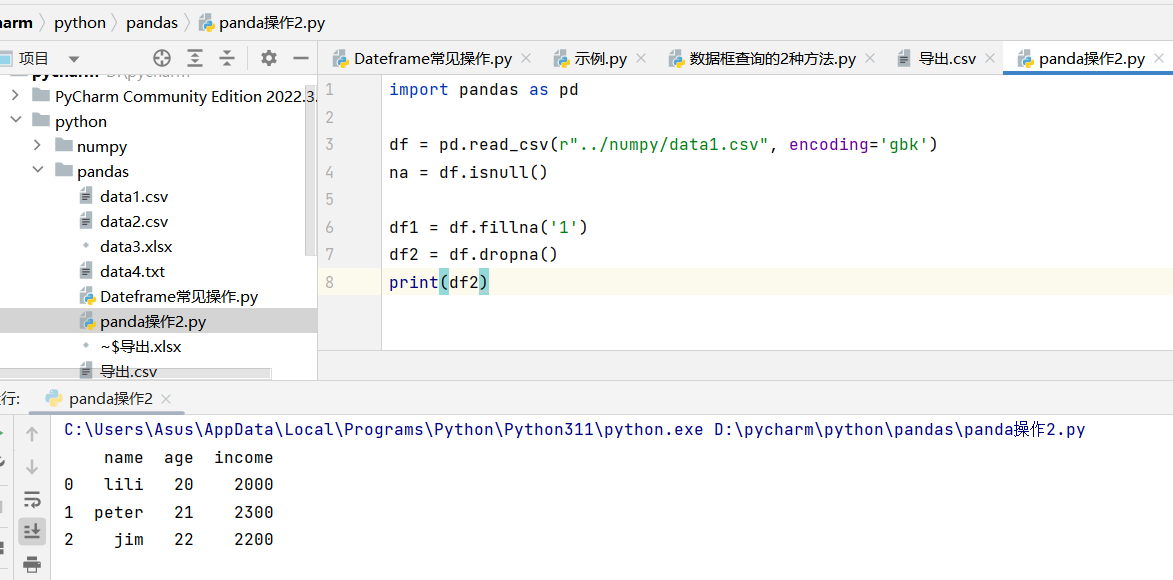
• fillna():适合缺失值较少,且可以用默认值或统计值填充的场景。
• dropna():适合缺失值比例较高,删除后不影响整体分析的场景。
🎨 二、Matplotlib:让数据“活”起来
处理完数据,下一步就是把它变成直观的图表。Matplotlib 是 Python 最经典的可视化库,上手也很快。
1. 基础散点图散点图可以清晰地展示两个变量之间的关系,用 plot() 函数就能快速实现。
import matplotlib.pyplot as plt
import numpy as np
x = np.array([1, 2, 3, 4, 5])
y = np.array([10, 20, 25, 30, 40])
plt.plot(x, y, color='red', marker='*')
plt.title('Scatter Plot Example')
plt.xlabel('X Axis')
plt.ylabel('Y Axis')
plt.show()
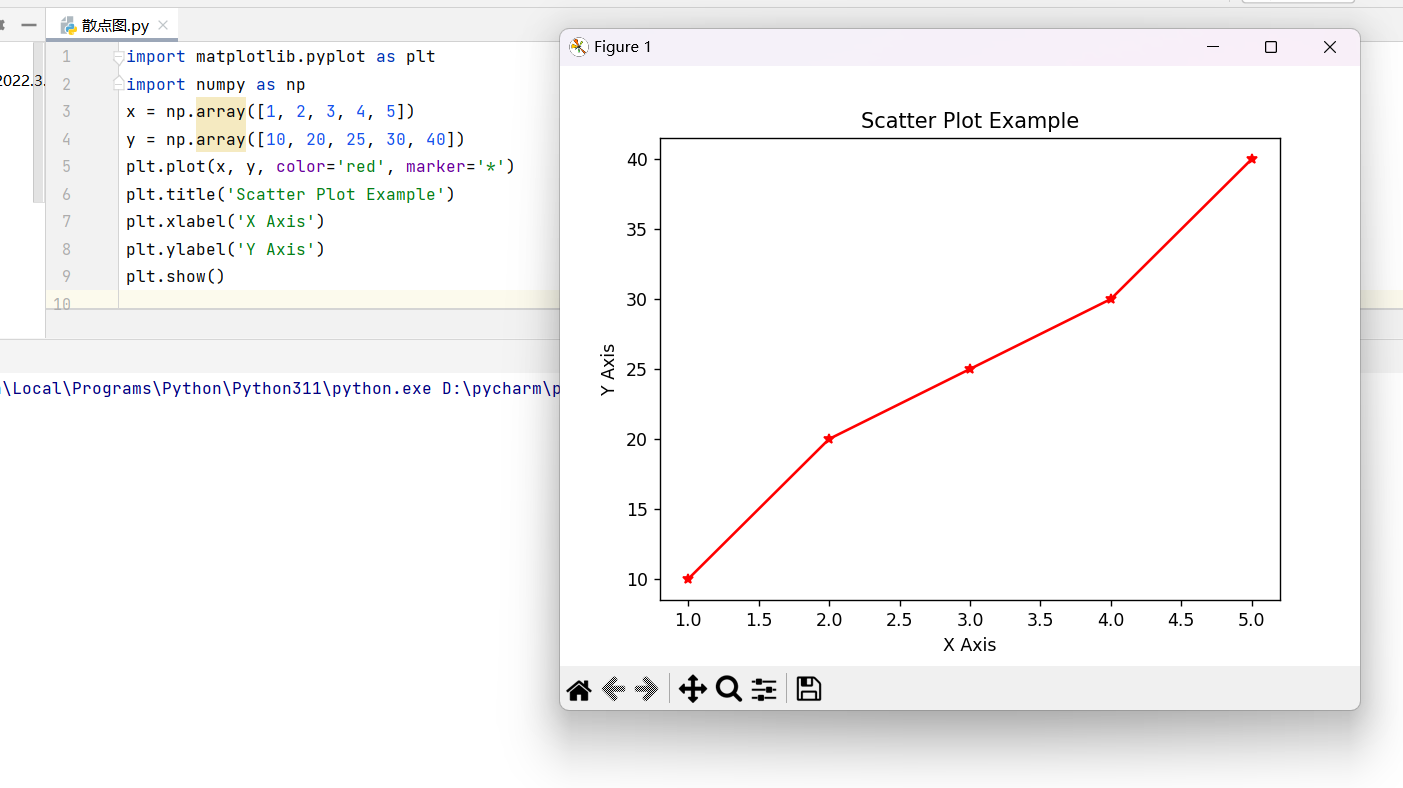
运行这段代码,你就能看到一个带星型标记的红色散点图,非常直观。
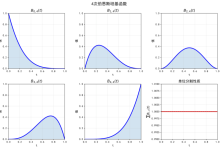
2. 多图布局
如果想在一张图里展示多个图表,subplots() 是个好帮手。我用它画了四个三角函数的对比图:
import numpy as np
x = np.linspace(0, 10, 10000)#
y1 = np.sin(x)
y2 = np.cos(x)
y3 = np.tan(x)
y4 = np.sin(x ** 2)
fig, axs = plt.subplots(2, 2, figsize=(10, 8))#
axs[0, 0].plot(x, y1, 'r')
axs[0, 0].set_title('sin(x)')
axs[0, 1].plot(x, y2, 'g')
axs[0, 1].set_title('cos(x)')
axs[1, 0].plot(x, y3, 'b')
axs[1, 0].set_title('tan(x)')
axs[1, 1].plot(x, y4, 'm')
axs[1, 1].set_title('sin(x^2)')
plt.show()
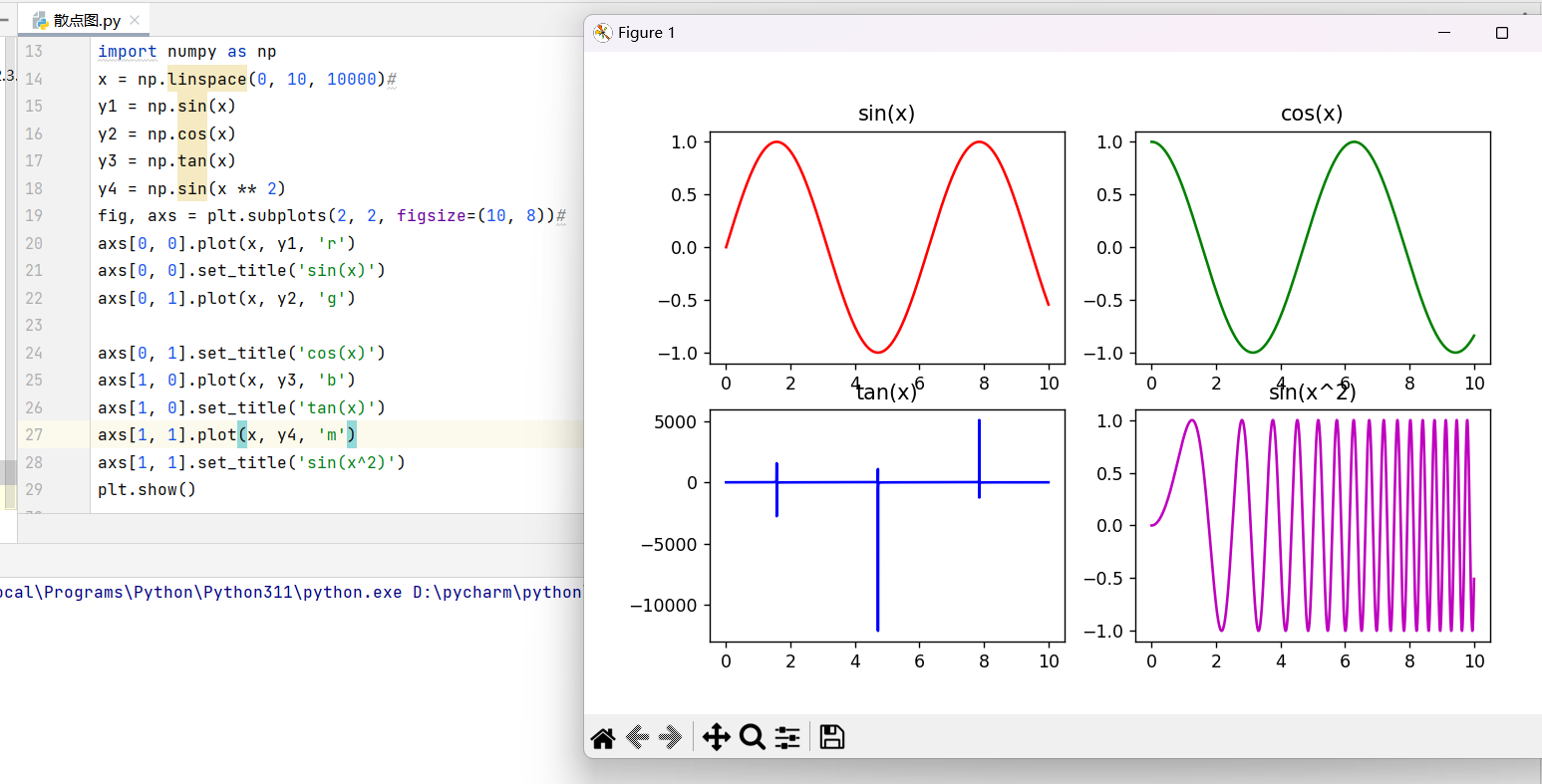
这样,我就能在一个画布上同时对比正弦、余弦、正切和正弦平方函数的曲线变化,一目了然。
✨ 写在最后
从数据处理到可视化,这一套流程走下来,我深刻体会到 Python 数据分析的魅力。Pandas 让我们能高效地清洗和整理数据,而 Matplotlib 则让这些数据变成了会说话的图表。
这些只是入门级的操作,但它们是数据分析的基石。随着学习的深入,我还会探索更多进阶技巧,比如用 Seaborn 画更漂亮的图,或者用 Scikit-learn 做机器学习预测。



评论前必须登录!
注册