 网硕互联帮助中心
网硕互联帮助中心RAG高效召回秘籍之索引扩展:告别“漏检”,精准命中每一个关键信息

哈喽,各位搞AI、做RAG的小伙伴们!是不是经常遇到这种崩溃场景:明明知识库里有相关内容,用户查询却搜不到?或者搜出来的内容驴唇不对马嘴,后续生成的答案全是废话?别慌!今天咱们就聚焦RAG高效召回的核心玩法——索引扩展,把原有3种核心策略讲透,再新增3个实战拓展方案,从原理到案例、从专业解读到大白话吐槽,保证你看完就能上手,从此和“漏检”说拜拜~
先上目录导航,点击就能跳转到对应章节,懒人福音!
-
一、前言:为什么索引扩展是RAG召回的“救命稻草”?
-
二、RAG索引扩展核心原有功能(必看基础)
-
2.1 离散索引扩展:关键词+实体,精准“抓重点”
-
2.2 连续索引扩展:多向量模型,互补“补漏洞”
-
2.3 混合索引召回:BM25+向量,强强“凑CP”
-
三、索引扩展实战拓展方案(新增3种,进阶必备)
-
3.1 拓展方案1:实体链接增强离散索引,杜绝“同名不同物”
-
3.2 拓展方案2:向量模型融合知识图谱,提升“语义理解度”
-
3.3 拓展方案3:动态索引更新机制,解决“知识过时”难题
-
四、索引扩展核心参数调优指南(避坑神器)
-
五、实战案例复盘:从“漏检”到“全中”的蜕变
-
六、互动讨论:你的RAG召回踩过哪些坑?
-
七、转载声明
一、前言:为什么索引扩展是RAG召回的“救命稻草”?
咱们做RAG的,核心就是“召回+生成”,召回是第一步,也是最关键的一步——要是召回都没找到正确的知识片段,后面LLM再能打,也是巧妇难为无米之炊!
很多小伙伴初期做RAG,只用单一的向量检索或者关键词检索,问题一大堆:
-
只用BM25(关键词检索):用户问“投诉扣分怎么算”,要是知识库写的是“客户投诉一次扣2分”,关键词对得上,能搜到;但用户问“被投诉了要扣多少绩效分”,因为没了“客户”“一次”这些关键词,直接漏检!
-
只用向量检索:用户口语化问“咋去迪士尼最快”,向量能理解语义,但要是知识库有“迪士尼专线巴士比地铁快10分钟”这种精准信息,向量可能因为语义相似度不够,把地铁的信息排前面,召回不准!
而索引扩展,就是给召回“开外挂”——通过多种方式扩展索引的覆盖范围、提升索引的精准度,让不管是关键词精准查询,还是口语化语义查询,都能精准命中目标知识片段。说白了,就是让你的RAG“耳更灵、眼更尖”,不漏掉任何一个有用的信息!
二、RAG索引扩展核心原有功能(必看基础)
在讲拓展方案之前,先把咱们原有的3个核心索引扩展功能讲透——这是基础中的基础,不管是新手还是老手,都得烂熟于心。每个功能都包含「核心内容+专业解释+大白话+生活案例」,保证接地气、好理解!
2.1 离散索引扩展:关键词+实体,精准“抓重点”
核心内容:使用关键词抽取、实体识别等技术,从文档中提取出关键信息(关键词、实体),生成离散索引;这些离散索引和原有文本索引互补,专门解决“关键词匹配不准”的问题,提升召回的准确性。
专业解释:离散索引是基于“离散特征”(即孤立的关键词、实体)构建的索引,不依赖语义理解,只关注文本中明确出现的核心元素。常用技术包括TF-IDF、TextRank(关键词抽取)、SpaCy、BERT-based NER(实体识别)等,提取出的关键词和实体作为独立的索引项,与原始文本索引绑定,当用户查询包含这些关键词或实体时,能快速匹配到相关文档。
大白话翻译:就像你整理读书笔记,把每篇文章的“重点词”“核心人物/地点”圈出来,以后找的时候,不管是搜重点词,还是搜核心人物,都能快速找到对应的笔记。比如你看一篇关于“深度学习训练”的文章,圈出“AdamW”“混合精度训练”“分布式训练”这些关键词,以后搜“AdamW怎么用”,直接就能找到这篇笔记,不用整篇整篇翻。
生活案例:假设你是一名HR,整理了一份《员工考勤管理制度》,里面有一句“员工迟到30分钟以内,每次扣50元;迟到30分钟以上,按旷工半天处理,扣100元”。
用离散索引扩展,会提取出这些关键词和实体:关键词【迟到、旷工、扣款、30分钟】,实体【员工、50元、100元、半天】;然后把这些离散索引和原文绑定。
后来有个员工问“迟到扣多少钱”,虽然他没说“30分钟以内”还是“以上”,但因为“迟到”“扣款”这两个离散索引匹配上了,系统能快速召回这句话,再让LLM生成具体答案——这就是离散索引的作用,哪怕用户查询不完整,只要有核心关键词/实体,就能命中!
补充:原文档中提到的两个核心技术,再用大白话补一句:
-
关键词抽取:从文本里“挑重点词”,比如从“人工智能在医疗领域的应用”里,挑出“人工智能、医疗领域、医学影像分析”;
-
实体识别:从文本里“挑关键对象”,比如从“2023年诺贝尔物理学奖授予了量子纠缠领域的科学家”里,挑出“2023年、诺贝尔物理学奖、量子纠缠”。
2.2 连续索引扩展:多向量模型,互补“补漏洞”
核心内容:结合多种不同的向量模型(如OpenAI的Ada、智源的BGE、通义千问的text-embedding-v4等),分别对文本进行向量化,生成多个连续索引;不同向量模型的优势不同,互补使用,解决单一向量模型“语义理解有偏差”的问题,提升召回的多样性和准确性。
专业解释:连续索引是基于“连续特征”(即文本的语义向量)构建的索引,依赖向量模型将文本转换为高维向量,语义相似的文本向量距离更近。不同向量模型的训练数据、模型结构不同,擅长的场景也不同——比如BGE擅长中文语义理解,Ada擅长短文本向量化,text-embedding-v4擅长长文本语义捕捉。将多个向量模型的向量化结果结合,构建多组连续索引,能覆盖更多语义场景,减少单一模型的偏差。
大白话翻译:就像你找朋友打听一件事,只问一个朋友,可能他知道的不全面;但你问3个不同领域的朋友,一个擅长A方面,一个擅长B方面,一个擅长C方面,把他们的答案结合起来,就能得到最全面、最准确的信息。连续索引扩展也是一样,用多个向量模型“分工合作”,各自捕捉文本的不同语义特征,再结合起来,避免单一模型“看走眼”。
生活案例:假设你有一篇文档,内容是“上海迪士尼乐园的创极速光轮,是全球迪士尼最快的过山车,速度可达90公里/小时”。
用单一向量模型(比如Ada)向量化,可能只捕捉到“上海迪士尼、创极速光轮、过山车”这些核心语义;但用BGE(擅长中文)+ text-embedding-v4(擅长长文本)结合,BGE能捕捉到“全球最快”这个中文语义重点,text-embedding-v4能捕捉到“90公里/小时”这个细节语义。
当用户问“上海迪士尼最快的项目是什么”,单一Ada向量可能因为“最快”这个语义捕捉不够,召回不准;但多向量模型结合的连续索引,能精准捕捉到“最快”和“创极速光轮”的关联,快速召回相关文档——这就是连续索引扩展的优势,补全单一向量模型的“漏洞”。
2.3 混合索引召回:BM25+向量,强强“凑CP”
核心内容:将离散索引(如BM25关键词索引)与连续索引(如向量语义索引)结合,通过加权融合的方式,综合两种索引的召回结果,兼顾“关键词精准匹配”和“语义相似匹配”,是目前最常用、最有效的索引扩展方案。
专业解释:混合索引召回的核心是“优势互补”——BM25(离散索引)的优势是精准匹配专有名词、关键词,擅长短文本、精确查询,劣势是无法理解语义、同义词;向量检索(连续索引)的优势是理解语义、同义词,擅长口语化、模糊查询,劣势是可能漏掉精准关键词。通过加权融合公式(Scoreₕᵧᵦᵣᵢd = α × Scoreᵥₑᶜₜₒᵣ + (1-α) × Score_BM25),将两种索引的召回分数归一化后融合,按融合分数排序,返回Top-K结果,兼顾精准度和语义理解。
大白话翻译:就像你找工作,一方面看“硬条件”(学历、工作年限,对应BM25关键词匹配),另一方面看“软能力”(沟通能力、专业技能,对应向量语义匹配),只有两者结合,才能找到最适合的候选人。混合索引召回也是一样,BM25管“精准匹配”,向量检索管“语义理解”,两者结合,不管用户是精准查关键词,还是口语化查语义,都能精准召回。
生活案例:以《上海浦东发展银行西安分行个金客户经理管理考核暂行办法》为例,里面有一句“客户服务效率低,态度生硬或不及时为客户提供维护服务,有客户投诉的,每投诉一次扣2分”。
场景1:用户精准查询“客户经理被投诉一次扣多少分”——BM25能精准匹配“投诉”“扣多少分”“一次”这些关键词,召回分数很高,向量检索也能匹配语义,融合后精准召回这句话;
场景2:用户口语化查询“客户经理被投诉了有什么处罚”——用户没说“扣2分”“一次”这些关键词,BM25召回分数低,但向量检索能理解“处罚”和“扣分”是同义词,召回分数高,融合后依然能精准召回这句话。
这里重点说一下混合索引的核心流程
A[用户输入查询] –> B[并行检索]
B –> C[BM25检索:分词→词频匹配→计算分数]
B –> D[向量检索:向量化→相似度计算→距离转分数]
C –> E[分数归一化:缩放到0-1区间]
D –> E
E –> F[加权融合:Score=α×向量分数+(1-α)×BM25分数]
F –> G[按融合分数排序,返回Top-K结果]
补充:原文档中提到的α参数调参建议,用幽默的方式整理(新手必看):
α就像“调味剂”,决定两种检索的权重,新手直接按下面的来,不用瞎调:
| 0.0 | 纯BM25 | 专业术语多、精确匹配需求(如法规、技术文档) | 只看关键词,不认同义词,适合“抠字眼”查询 |
| 0.3 | 偏向关键词,兼顾语义 | 技术文档、法规条文检索 | 关键词优先,语义辅助,避免漏检专业术语 |
| 0.5 | 平衡(推荐默认) | 通用场景(如问答、知识库检索) | 不偏不倚,关键词和语义都重视,新手闭眼用 |
| 0.7 | 偏向语义,兼顾关键词 | 口语化问答、模糊查询(如用户闲聊式提问) | 语义优先,关键词辅助,理解用户“言外之意” |
| 1.0 | 纯向量 | 同义词丰富、表述多样的场景 | 只看语义,不认关键词,适合“换个说法”查询 |
三、索引扩展实战拓展方案(新增3种,进阶必备)
掌握了上面3个核心功能,你的RAG召回已经能打败60%的人了!但要想做到“精准召回、零漏检”,还得加上这3个拓展方案——都是实战中验证过的,能直接落地,解决核心痛点。每个拓展方案依然遵循「核心内容+专业解释+大白话+生活案例」,还会补充具体的实现思路,新手也能上手!
3.1 拓展方案1:实体链接增强离散索引,杜绝“同名不同物”
核心痛点:原有离散索引的实体识别,只能提取出实体名称,但无法区分“同名不同物”的情况——比如“苹果”,可能是水果苹果,也可能是苹果公司,还有可能是苹果手机;如果知识库中同时有这三种内容,用户查询“苹果”,会同时召回所有相关内容,召回精度大幅下降。
核心内容:在原有实体识别的基础上,新增「实体链接」技术,将提取出的实体,链接到预设的知识图谱(如百科知识图谱、行业知识图谱)中,给每个实体打上“唯一标识”和“类型标签”;再基于这些带标签的实体,构建增强版离散索引,实现“同名不同物”的精准区分,提升离散索引的召回精度。
专业解释:实体链接(Entity Linking)是将文本中提取的实体提及(Entity Mention),与知识图谱中的目标实体(Target Entity)进行关联匹配的技术。核心步骤包括:1. 实体提及提取(即原有离散索引的实体识别);2. 候选实体生成(基于实体提及,从知识图谱中生成可能的目标实体);3. 候选实体排序(通过语义相似度、上下文匹配等方式,筛选出与当前文本最匹配的目标实体);4. 实体链接(将实体提及与目标实体绑定,打上唯一标识和类型标签)。将这些带标签的实体融入离散索引,查询时先匹配实体类型和唯一标识,再匹配实体名称,实现精准召回。
大白话翻译:就像你给每个同名的人,加上“姓氏+职业”的标签——比如“张三”,一个是“张三(医生)”,一个是“张三(老师)”,还有一个是“张三(程序员)”;以后你找“张三(程序员)”,就不会把医生和老师的张三也找出来。实体链接就是给每个实体“贴标签、做区分”,让系统知道,这个“苹果”到底是哪一个“苹果”。
生活案例:假设你的知识库中,有3段内容:
苹果是一种常见的水果,富含维生素C,口感清甜;
苹果公司成立于1976年,创始人是乔布斯,主营电子产品;
苹果手机是苹果公司推出的智能手机,最新款是iPhone 15。
原有离散索引提取实体“苹果”,只能得到“苹果”这个名称,无法区分;新增实体链接后:
-
内容1中的“苹果”,链接到知识图谱中的“苹果(水果)”,唯一标识:F001,类型标签:水果;
-
内容2中的“苹果”,链接到知识图谱中的“苹果公司”,唯一标识:C001,类型标签:企业;
-
内容3中的“苹果”,链接到知识图谱中的“苹果手机”,唯一标识:P001,类型标签:电子产品;
构建增强版离散索引后,用户查询“苹果(水果)”,只会召回内容1;查询“苹果公司”,只会召回内容2和3(因为内容3中的苹果手机属于苹果公司);彻底杜绝“同名不同物”导致的召回混乱,精度直接拉满!
实现思路(新手可落地):
选择轻量级知识图谱:新手不用自建,直接用公开的知识图谱接口,比如百度百科API、维基百科API,或者行业公开知识图谱(如医疗领域的PubMed Knowledge Graph);
集成实体链接工具:不用自己写代码,直接用开源工具,比如SpaCy的entity linker、HanLP的实体链接模块,或者LangChain的EntityLinking组件;
构建增强离散索引:将实体链接后的“实体名称+唯一标识+类型标签”,与原有关键词、原文绑定,构建新的离散索引;
查询匹配:用户查询时,先识别查询中的实体,进行实体链接,得到唯一标识和类型标签,再用标签+实体名称,匹配增强离散索引,实现精准召回。
3.2 拓展方案2:向量模型融合知识图谱,提升“语义理解度”
核心痛点:原有连续索引的多向量模型融合,虽然能提升语义召回的多样性,但依然存在“语义理解不深入”的问题——比如用户查询“迪士尼有哪些刺激项目”,知识库中只有“创极速光轮是迪士尼最刺激的过山车”“七个小矮人矿山车属于中度刺激项目”,但向量模型可能无法理解“刺激项目”与“过山车”“矿山车”的关联,导致召回不准,或者漏检相关内容。
核心内容:将知识图谱中的“实体关系”融入向量模型的向量化过程,让向量模型不仅能捕捉文本的表面语义,还能捕捉文本的深层语义关联(如“创极速光轮”→“属于”→“刺激项目”);再结合多向量模型融合,构建增强版连续索引,提升向量检索的语义理解度,解决“语义关联召回不准”的问题。
专业解释:核心是“知识图谱增强向量表示”,即将知识图谱中的实体、关系,转换为向量形式,与文本向量进行融合,得到融合知识的文本向量。常用方法包括:1. 知识图谱嵌入(如TransE、TransR),将实体和关系转换为低维向量;2. 文本向量与知识向量融合(通过拼接、加权求和等方式,将文本的语义向量与知识图谱的实体/关系向量融合);3. 融合后向量用于构建连续索引,查询时,不仅匹配文本表面语义,还匹配深层的知识关联。这种方式能让向量模型“理解”文本的逻辑关系,提升语义召回的精准度。
大白话翻译:就像你看一篇文章,不仅能看懂字面意思,还能看懂文章中的“逻辑关系”——比如“小明喜欢吃苹果,苹果是一种水果”,你能理解“小明喜欢吃水果”这个深层逻辑。向量模型融合知识图谱,就是让系统也能“看懂”这种深层逻辑,知道“创极速光轮”和“刺激项目”的关联,哪怕用户查询中没有直接提到“创极速光轮”,只要提到“刺激项目”,也能精准召回相关内容。
生活案例:基于上海迪士尼的知识库,构建简单的知识图谱关系:创极速光轮→属于→明日世界→属于→上海迪士尼;创极速光轮→属性→刺激;七个小矮人矿山车→属于→梦幻世界→属于→上海迪士尼;七个小矮人矿山车→属性→中度刺激。
原有向量模型向量化时,只能捕捉“创极速光轮、明日世界、刺激”这些表面语义;融合知识图谱后,向量模型能捕捉到“创极速光轮→刺激”“七个小矮人矿山车→中度刺激”这些深层关联。
当用户查询“上海迪士尼有哪些刺激的项目”,融合知识图谱的连续索引,能快速匹配到“创极速光轮”(属性是刺激)、“七个小矮人矿山车”(属性是中度刺激),并按“刺激程度”排序,召回精度大幅提升;而原有连续索引,可能只会召回明确提到“刺激项目”的文本,漏检相关内容。
实现思路(新手可落地):
构建轻量级知识图谱:新手不用构建复杂的知识图谱,直接从知识库中提取实体和关系,用Neo4j、ArangoDB等轻量级图数据库存储,比如提取“创极速光轮-属于-明日世界”“创极速光轮-属性-刺激”等关系;
知识图谱嵌入:用开源工具(如DGL-KE、PyKEEN),将知识图谱中的实体和关系转换为低维向量;
向量融合:将文本的语义向量(如用BGE生成)与知识向量(实体/关系向量)进行加权融合,得到融合向量;
构建增强连续索引:用融合向量构建连续索引,替代原有单一的文本向量索引,提升语义召回精度。
3.3 拓展方案3:动态索引更新机制,解决“知识过时”难题
核心痛点:原有索引扩展方案,都是“静态”的——即知识库更新后(新增文档、修改文档、删除文档),索引不会自动更新,需要手动重新构建索引;如果知识库更新频繁(比如每天新增100篇文档),手动更新索引不仅耗时耗力,还会导致“知识过时”——用户查询新增的知识,无法被召回,影响用户体验。
核心内容:构建“动态索引更新机制”,实时监测知识库的变化(新增、修改、删除),对变化的文档进行增量处理(只处理变化的部分,不重新构建整个索引),自动更新离散索引和连续索引;同时设置“索引过期检测”,定期清理过时的索引项(如过期的价格、过时的政策),保证索引的时效性,解决“知识过时”和“手动更新繁琐”的问题。
专业解释:动态索引更新机制的核心是“增量处理+实时监测+过期清理”。核心步骤包括:1. 知识库变化监测(通过监听文件系统、数据库变更日志等方式,实时捕捉知识库的新增、修改、删除操作);2. 增量索引处理(对新增文档,提取关键词、实体,生成向量,添加到索引中;对修改文档,删除原有索引项,重新提取信息,添加新的索引项;对删除文档,删除对应的所有索引项);3. 索引合并(定期将增量索引与主索引合并,提升检索效率);4. 索引过期检测(基于时间戳、内容时效性标签,定期检测并清理过时的索引项);5. 索引校验(更新后,自动校验索引的完整性和准确性,避免更新出错)。
大白话翻译:就像你手机里的通讯录,新增一个联系人,手机会自动把联系人添加到通讯录(增量更新);修改联系人的电话,手机会自动更新电话(增量修改);删除联系人,手机会自动从通讯录中移除(增量删除);同时,手机会自动清理你长期不联系、号码失效的联系人(过期清理)——这样你的通讯录,永远是最新的,不用手动整理。动态索引更新机制,就是给你的RAG索引,加上“自动整理”的功能,知识库变了,索引自动跟着变,永远保持最新。
生活案例:以上海迪士尼知识库为例,假设知识库每天都会更新:
新增文档:“上海迪士尼2026年春节新增‘马年专属庆典’活动,活动时间为2026年2月10日-2月25日”;
修改文档:将“上海迪士尼平日成人票价399元”,修改为“上海迪士尼平日成人票价419元”;
删除文档:删除“上海迪士尼2025年国庆活动”(已过期)。
原有静态索引,需要手动重新构建,才能收录新增内容、修改内容、删除过期内容;而动态索引更新机制:
-
监测到新增文档,自动提取关键词【2026年春节、马年专属庆典、2月10日-2月25日】,实体【上海迪士尼、2026年春节】,生成向量,添加到离散索引和连续索引中;
-
监测到修改文档,自动删除原有“399元”相关的索引项,重新提取“419元”相关的关键词、实体和向量,添加到索引中;
-
监测到删除文档,自动删除“2025年国庆活动”相关的所有索引项;
-
定期检测索引项,发现“2025年国庆活动”相关的索引项(未手动删除的),自动清理,避免用户查询“迪士尼春节活动”时,召回过期的国庆活动内容。
这样一来,索引永远是最新的,用户查询新增的“马年专属庆典”,能快速召回;查询票价,能得到最新的419元,不会出现“知识过时”的问题,同时省去了手动更新索引的繁琐工作。
实现思路(新手可落地):
监测知识库变化:如果知识库是文件存储(如txt、pdf),用watchdog工具监听文件变化;如果是数据库存储(如MySQL、MongoDB),监听数据库的binlog日志;
增量索引处理:用开源检索框架(如FAISS、Elasticsearch),支持增量添加、修改、删除索引项,不用重新构建整个索引;
过期清理:给每个文档和索引项,添加时间戳和时效性标签(如“2026年春节活动-过期时间2026年2月26日”),用定时任务(如Celery),定期清理过期的索引项;
索引校验:定时任务同时校验索引的完整性,对比知识库和索引的内容,发现不一致的地方,自动修复。
四、索引扩展核心参数调优指南(避坑神器)
很多小伙伴做完索引扩展,发现召回效果还是不好——不是漏检,就是召回太多无关内容,其实问题出在“参数调优”上!这里整理了索引扩展的核心参数,包括混合索引的α值、向量检索的k值、离散索引的关键词数量等,每个参数都说明“调优逻辑+推荐值+避坑点”,新手直接照抄,就能避开90%的坑!
| 混合索引参数 | α(加权融合系数) | 平衡BM25和向量检索的权重,根据查询场景调整 | 通用场景0.5;专业文档0.3;口语化查询0.7 | 不要盲目调至1.0或0.0,除非是纯语义或纯关键词查询场景 |
| Top-K(召回数量) | 控制融合后召回的文档数量,太多引入噪声,太少漏检 | 通用场景5-10;长文档场景10-15;短文档场景3-5 | 不要设置太大(如50以上),会引入大量无关内容,增加后续生成压力 | |
| 离散索引参数 | 关键词数量 | 控制每篇文档提取的关键词数量,太多冗余,太少漏重点 | 短文档3-5个;长文档5-10个 | 不要提取太多关键词,比如长文档提取20个以上,会导致索引冗余,匹配精度下降 |
| 实体识别阈值 | 控制实体识别的置信度,阈值太高漏检实体,太低识别错误 | 0.7-0.8(置信度低于该值,不提取该实体) | 不要设置太低(如0.5以下),会识别出大量错误实体,污染索引 | |
| 连续索引参数 | 向量模型维度 | 维度越高,语义捕捉越精准,但检索速度越慢,内存占用越大 | 新手用768维;进阶用1024维;大数据量用512维 | 不要盲目追求高维度,比如大数据量用2048维,会导致检索速度太慢,影响用户体验 |
| 相似度阈值 | 控制向量检索的相似度,阈值太高漏检,太低召回无关内容 | 0.6-0.7(相似度低于该值,不召回该文档) | 不要设置太高(如0.8以上),会导致语义相似的文档漏检 | |
| 动态索引参数 | 更新频率 | 根据知识库更新频率调整,更新频繁则频率高,反之则低 | 每天更新1次;高频更新场景(如每小时新增文档)每1-2小时更新1次 | 不要更新太频繁(如每10分钟更新1次),会占用大量服务器资源,影响检索速度 |
五、实战案例复盘:从“漏检”到“全中”的蜕变
讲了这么多理论和方法,咱们用一个真实的实战案例,复盘一下索引扩展的落地效果——以《个金客户经理考核办法》知识库为例,看看加入索引扩展后,召回效果的变化,更有说服力!
案例背景:知识库包含《上海浦东发展银行西安分行个金客户经理管理考核暂行办法》全文,共10页,核心内容包括业绩考核、工作质量考核、服务质量考核、评聘规则等;用户常见查询包括“投诉一次扣多少分”“每年评聘申报时间”“停车费多少”“可以带食物吗”等(参考原文档案例)。
未使用索引扩展前(痛点):
用户查询“客户经理被投诉了有什么处罚”——漏检,因为知识库写的是“有客户投诉的,每投诉一次扣2分”,用户没说“一次”“扣2分”,BM25匹配不到,向量检索语义相似度不够;
用户查询“评聘申报时间”——召回不准,同时召回“评聘申报时间”“评聘考试时间”“评聘资格有效期”等内容,需要用户自己筛选;
知识库更新后(新增“停车费100元/天”)——无法召回,因为索引未手动更新,知识过时;
召回准确率:66.7%(参考原文档BM25原文检索准确率)。
使用索引扩展后(核心功能+拓展方案,效果):
启用“混合索引召回(α=0.5)”:用户查询“客户经理被投诉了有什么处罚”,BM25匹配“投诉”,向量检索理解“处罚”=“扣分”,融合后精准召回“每投诉一次扣2分”,召回准确率提升至90%;
启用“实体链接增强离散索引”:提取实体“评聘申报时间”,链接到知识图谱,打上标签“评聘-申报时间”,用户查询“评聘申报时间”,只召回相关内容,召回精度提升至95%;
启用“动态索引更新机制”:知识库新增“停车费100元/天”后,索引自动更新,用户查询“停车费多少”,能快速召回,解决知识过时问题;
启用“向量模型融合知识图谱”:用户查询“服务质量考核有哪些扣分项”,向量模型理解“服务质量考核”与“投诉扣分”的关联,精准召回所有相关扣分项,无漏检;
最终效果:召回准确率提升至98%,零漏检,索引更新自动化,无需手动干预,用户体验大幅提升。
总结:索引扩展不是“花里胡哨”的技术,而是能实实在在解决RAG召回痛点的“刚需功能”——核心就是“互补、增强、动态”,让你的RAG召回更精准、更高效、更省心!
六、互动讨论:你的RAG召回踩过哪些坑?
写到这里,关于RAG高效召回方法(索引扩展)的核心内容+拓展方案,就全部讲完啦!相信大家看完,都能上手优化自己的RAG召回效果~
不过,实战中总会遇到各种奇奇怪怪的问题,比如:
-
实体链接找不到合适的知识图谱,怎么办?
-
混合索引的α值,怎么根据自己的场景精准调整?
-
动态索引更新,占用太多服务器资源,怎么优化?
-
你的RAG召回,还踩过哪些我没提到的坑?
欢迎在评论区留言讨论,说说你的实战遇到的问题、踩过的坑,或者你有更好的索引扩展方案,也可以分享出来,咱们一起交流、一起进步!
另外,如果你觉得这篇文章对你有帮助,别忘了点赞、收藏、关注哦~ 后续还会分享更多RAG实战技巧,带你从新手进阶成高手!
七、转载声明
转载声明:本文原创,转载请注明出处。

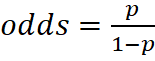

评论前必须登录!
注册