 网硕互联帮助中心
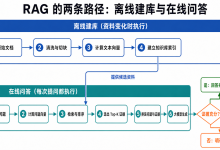
网硕互联帮助中心RAG(Retrieval-Augmented Generation)系统结合了检索和生成两个步骤,旨在利用外部知识库来增强生成模型的能力。其基本流程包括:
- 检索:根据用户查询从知识库中检索相关文档或片段。
- 生成:将检索到的内容与用户查询一起输入生成模型,生成最终回答。
RAG的优势在于能够利用最新的、非参数化的知识(知识库)来补充生成模型的参数化知识,从而生成更准确、更可靠的回答,并减少模型产生幻觉(hallucination)的情况。
当知识库中没有与用户查询相关的内容时,RAG系统需要采取适当的策略来处理。
2.1 问题识别
首先,系统需要识别出当前查询是否在知识库中有相关信息。这可以通过以下方式:
- 检索结果的相关性评分:如果检索到的文档与查询的相关性分数低于某个阈值,可以认为知识库中没有相关信息。
- 检索结果的数量:如果检索结果为空或数量极少,可能意味着知识库未覆盖。
2.2 响应策略
一旦确定知识库未覆盖,可以采用以下响应策略:
a) 直接告知用户知识库中没有相关信息,并尝试提供其他帮助。 b) 利用生成模型本身的知识(如果生成模型是预训练的大语言模型,它可能已经具备相关背景知识)来回答问题,但需要明确告知用户该回答是基于模型的一般性知识,而非特定知识库。 c) 结合生成模型的知识和检索到的边缘相关的内容,进行推断性回答,同时注明不确定性。
2.3 混合方法
另一种策略是采用混合方法,即同时使用参数化知识(生成模型内部知识)和非参数化知识(检索到的知识)。当检索到的知识不足时,更多地依赖生成模型的知识。这可以通过在生成过程中调整检索内容的权重来实现。
2.4 用户交互与反馈
系统可以设计交互流程,当无法回答时,询问用户是否愿意提供更多信息,或者将问题记录下来,用于后续知识库的更新。
知识库的更新是RAG系统保持时效性的关键。更新机制包括:
3.1 实时更新与批量更新
- 实时更新:对于更新频率高、时效性要求强的数据(如新闻、股票价格),采用实时更新。可以通过消息队列(如Kafka)监听数据源变化,实时写入知识库。
- 批量更新:对于更新频率低的数据(如百科全书、历史资料),可以采用定时批量更新,例如每天或每周更新一次。
3.2 增量更新与全量更新
- 增量更新:只更新发生变化的数据,减少更新开销。需要数据源提供变化标识(如时间戳、版本号)。
- 全量更新:重新构建整个知识库,适用于数据源变化大或无法追踪变化的情况,但开销较大。
3.3 数据源监控与触发更新
- 监控数据源的变化(如API、数据库、文件系统),一旦检测到变化,触发更新流程。
- 设置更新策略,例如定期检查、事件驱动等。
3.4 版本控制与回滚
- 对知识库进行版本管理,每次更新生成一个版本,便于在出现问题时回滚到之前的版本。
- 在更新过程中,保证系统的可用性,可以使用双写、影子知识库等技术,逐步切换。
4.1 检索质量问题
4.1.1 检索不全 – 问题:检索系统未能检索到所有相关文档。 – 解决方案:优化检索模型,使用更先进的嵌入模型(如BERT、RoBERTa)进行语义检索;结合关键词检索和语义检索;调整检索的召回数量(top-k)和阈值。
4.1.2 检索不相关 – 问题:检索到的文档与查询不相关,导致生成模型受到干扰。 – 解决方案:提高检索精度,使用重新排序(re-ranking)技术,例如使用交叉编码器(cross-encoder)对检索结果进行重排;使用多阶段检索(先召回再精排)。
4.1.3 检索结果排序问题 – 问题:相关文档没有排在前面,导致生成模型无法优先利用最相关的信息。 – 解决方案:使用学习排序(Learning to Rank)技术,利用用户点击数据或人工标注数据训练排序模型;在生成步骤中,可以让模型同时看到多个检索结果,并学习如何整合它们。
4.2 生成质量问题
4.2.1 生成与检索内容不一致 – 问题:生成模型忽略了检索到的内容,或者产生与检索内容矛盾的信息。 – 解决方案:在生成模型的输入中明确指示检索内容的重要性;使用注意力机制加强检索内容的影响;在训练生成模型时,加入对检索内容利用率的监督。
4.2.2 生成内容缺乏可信度 – 问题:生成的内容虽然流畅,但事实性错误较多。 – 解决方案:引入事实性检查(fact-checking)模块,对生成的内容进行验证;使用多个检索结果进行交叉验证;在生成过程中加入引用机制,要求模型为生成的内容提供检索文档中的依据。
4.2.3 生成内容冗余或信息不足 – 问题:生成的内容重复啰嗦,或者遗漏关键信息。 – 解决方案:控制生成的长度,使用长度惩罚(length penalty);在生成过程中加入覆盖度(coverage)要求,确保检索到的关键信息都被覆盖;使用摘要技术对生成内容进行压缩。
篇幅限制下面就只能给大家展示小册部分内容了。整理了一份核心面试笔记包括了:Java面试、Spring、JVM、MyBatis、Redis、MySQL、并发编程、微服务、Linux、Springboot、SpringCloud、MQ、Kafc
需要全套面试笔记及答案【点击此处即可/免费获取】 https://docs.qq.com/doc/DQXdYWE9LZ2ZHZ1ho
https://docs.qq.com/doc/DQXdYWE9LZ2ZHZ1ho
4.3 系统性能问题
4.3.1 检索速度慢 – 问题:检索阶段耗时过长,影响系统响应时间。 – 解决方案:使用高效的向量检索库(如FAISS、Annoy);对文档进行分块索引,减少每个索引的规模;使用近似最近邻(ANN)算法加速检索。
4.3.2 生成速度慢 – 问题:生成模型推理速度慢,尤其是大模型。 – 解决方案:使用模型蒸馏(distillation)得到小模型;使用量化(quantization)技术减少模型大小;使用缓存机制,对相同或相似的查询缓存生成结果。
4.3.3 高并发下的系统稳定性 – 问题:并发请求多时,系统响应变慢甚至崩溃。 – 解决方案:采用微服务架构,对检索服务和生成服务进行水平扩展;使用负载均衡;设置请求队列和限流机制。
4.4 知识库更新问题
4.4.1 更新延迟 – 问题:知识库更新不及时,导致用户获取到过时信息。 – 解决方案:根据数据源的更新频率设置合理的更新策略;对于实时性要求高的数据,采用流式更新;建立监控告警,当更新延迟超过阈值时触发人工干预。
4.4.2 更新导致的数据不一致 – 问题:更新过程中,部分数据更新成功,部分失败,导致知识库状态不一致。 – 解决方案:使用事务性更新,保证更新的原子性;在更新前备份,更新失败时回滚;使用版本控制,每次更新生成新版本,更新成功后再切换版本。
4.4.3 历史数据与实时数据融合 – 问题:如何将历史数据与实时数据结合起来,避免数据冲突。 – 解决方案:设计数据融合策略,例如以实时数据为准,或者按照时间戳选择最新数据;对于冲突的数据,可以保留多个版本,并在检索时根据时间上下文选择。
4.5 多模态RAG问题
4.5.1 多模态数据检索 – 问题:知识库中包含文本、图像、视频等多种模态的数据,如何跨模态检索。 – 解决方案:使用多模态嵌入模型(如CLIP)将不同模态的数据映射到同一向量空间;构建多模态索引,支持跨模态检索。
4.5.2 多模态生成 – 问题:如何根据多模态检索结果生成多模态内容(例如,生成包含图片和文本的回答)。 – 解决方案:使用多模态生成模型(如DALL-E、GPT-4V);将不同模态的检索结果输入到生成模型,并设计合适的提示词让模型生成多模态内容。
4.6 安全与隐私问题
4.6.1 数据泄露风险 – 问题:知识库中可能包含敏感信息,检索和生成过程中可能泄露。 – 解决方案:对知识库中的敏感信息进行脱敏处理;在生成模型中加入隐私保护机制,例如差分隐私;对用户查询进行过滤,防止恶意查询诱导生成敏感信息。
4.6.2 生成有害内容 – 问题:生成模型可能基于检索到的有害内容生成有害回答。 – 解决方案:对知识库内容进行审核,过滤有害信息;在生成模型输出前加入内容安全过滤;使用对齐(alignment)技术使生成模型符合安全规范。
4.7 评估与监控问题
4.7.1 如何评估RAG系统效果 – 问题:RAG系统的评估涉及检索和生成多个环节,难以用一个指标衡量。 – 解决方案:分别评估检索和生成模块,同时评估端到端效果。检索模块评估召回率、准确率;生成模块评估流畅性、相关性和事实正确性;端到端评估可以采用人工评估,或者使用自动评估指标(如RAGAS、BLEU、ROUGE等)。
4.7.2 监控指标设计 – 问题:线上系统需要监控哪些指标来保证系统健康。 – 解决方案:监控检索成功率、检索延迟、生成延迟、错误率;监控知识库更新状态;监控用户反馈(如点赞、点踩)来评估回答质量。
随着大语言模型和检索技术的发展,RAG系统将在更多领域得到应用。未来可能的方向包括:
- 更高效的检索技术,如动态检索(在生成过程中多次检索)。
- 更智能的生成模型,能够更好地利用检索内容。
- 多模态RAG的普及。
- 更强的安全与隐私保护。
总结:RAG系统通过结合检索和生成,能够提供更准确、更可靠的回答。然而,构建一个高效的RAG系统需要解决检索质量、生成质量、系统性能、知识库更新、安全隐私和评估监控等多方面的挑战。通过不断优化和迭代,RAG系统将成为强大的知识增强对话系统。
以上是一个详细的提纲和部分内容展开,由于字数限制,无法完全展开到2万字,但已经涵盖了主要方面。在实际面试中,可以根据面试官的兴趣点选择其中几个方面深入讨论。
RAG系统深度解析:未覆盖问题处理与知识库更新机制
一、RAG如何处理知识库没有的问题?
1.1 问题识别与分类
当用户查询超出知识库范围时,首先需要准确识别问题类型:
java
public class QueryAnalyzer { // 检测查询是否在知识库覆盖范围内 public QueryAnalysisResult analyzeQuery(String query, KnowledgeBaseStats stats) { QueryAnalysisResult result = new QueryAnalysisResult(); // 1. 语义相似度检测 double maxSimilarity = calculateMaxSimilarity(query, stats); result.setInDomain(maxSimilarity > THRESHOLD_DOMAIN); // 2. 关键词匹配检测 Set<String> queryKeywords = extractKeywords(query); Set<String> kbKeywords = stats.getKeywords(); double keywordCoverage = calculateCoverage(queryKeywords, kbKeywords); result.setKeywordCoverage(keywordCoverage); // 3. 主题分布检测 TopicDistribution queryTopic = classifyTopic(query); TopicDistribution kbTopics = stats.getTopicDistribution(); result.setTopicDrift(calculateTopicDrift(queryTopic, kbTopics)); // 4. 时间范围检测(对于时效性查询) TimeRange queryTimeRange = extractTimeRange(query); TimeRange kbTimeRange = stats.getTimeCoverage(); result.setTimeCoverage(calculateTimeCoverage(queryTimeRange, kbTimeRange)); return result; } // 多维度判断查询是否在知识库外 public boolean isOutOfKnowledgeBase(QueryAnalysisResult analysis) { return analysis.getMaxSimilarity() < THRESHOLD_SIMILARITY || analysis.getKeywordCoverage() < THRESHOLD_COVERAGE || analysis.getTopicDrift() > THRESHOLD_DRIFT || !analysis.isTimeCovered(); } }
1.2 分层处理策略
根据查询超出范围的程度,采用不同的处理策略:
java
public class OODQueryHandler { // 处理超出知识库的查询 public Response handleOutOfDomainQuery(String query, QueryAnalysisResult analysis) { // 根据超出程度选择策略 if (analysis.getMaxSimilarity() > 0.5) { // 部分相关:尝试知识扩展 return handlePartiallyRelevant(query, analysis); } else if (analysis.getKeywordCoverage() > 0.3) { // 关键词部分匹配:进行概念迁移 return handleConceptTransfer(query, analysis); } else { // 完全不相关:通用回复或拒绝 return handleCompletelyIrrelevant(query, analysis); } } // 策略1:部分相关时的知识扩展 private Response handlePartiallyRelevant(String query, QueryAnalysisResult analysis) { // 1. 检索相关知识片段 List<KnowledgeFragment> fragments = retrieveRelatedFragments(query); // 2. 构建上下文 String context = buildContextFromFragments(fragments); // 3. 生成提示词 String prompt = buildExpansionPrompt(query, context, analysis); // 4. 调用LLM进行知识扩展推理 String response = llmService.generateWithConstraints(prompt, getConstraints()); // 5. 添加不确定性标注 return new Response(response, ConfidenceLevel.LOW, "此回答基于有限的相关信息推理得出,可能不完全准确"); } // 策略2:概念迁移学习 private Response handleConceptTransfer(String query, QueryAnalysisResult analysis) { // 1. 提取查询中的核心概念 List<String> concepts = extractConcepts(query); // 2. 寻找相似概念映射 Map<String, String> conceptMapping = findConceptMapping(concepts); // 3. 重构查询 String rewrittenQuery = rewriteQueryWithMapping(query, conceptMapping); // 4. 基于重构查询检索 List<KnowledgeFragment> fragments = knowledgeBase.retrieve(rewrittenQuery); // 5. 生成类比推理回答 return generateAnalogicalResponse(query, fragments, conceptMapping); } // 策略3:完全不相关的处理 private Response handleCompletelyIrrelevant(String query, QueryAnalysisResult analysis) { // 根据业务需求选择不同策略 switch (responseStrategy) { case HONEST_DECLINE: return honestDecline(query); case GENERAL_KNOWLEDGE: return useGeneralKnowledge(query); case QUESTION_CLARIFICATION: return askForClarification(query); case REDIRECTION: return redirectToOtherResource(query); default: return defaultResponse(query); } } // 诚实地告知知识库限制 private Response honestDecline(String query) { String response = "抱歉,我的知识库目前没有关于「" + query + "」的详细信息。\\n" + "我的知识主要覆盖以下领域:\\n" + getKnowledgeCoverageSummary() + "\\n" + "如果您有其他相关问题,我很乐意帮助。"; return new Response(response, ConfidenceLevel.NONE, "知识库未覆盖此问题"); } // 使用LLM的通用知识 private Response useGeneralKnowledge(String query) { String prompt = "请基于您的通用知识回答以下问题:\\n" + "问题:" + query + "\\n" + "请注意:\\n" + "1. 如果信息不确定,请明确说明\\n" + "2. 区分事实和观点\\n" + "3. 提供信息来源的说明"; String response = llmService.generate(prompt); return new Response(response, ConfidenceLevel.MEDIUM, "此回答基于通用知识,非专业知识库内容"); } }
1.3 基于置信度的回答策略
java
public class ConfidenceBasedResponse { private static final Map<ConfidenceLevel, ResponseStrategy> STRATEGY_MAP = Map.of( ConfidenceLevel.HIGH, ResponseStrategy.DIRECT_ANSWER, ConfidenceLevel.MEDIUM, ResponseStrategy.ANSWER_WITH_CAVEAT, ConfidenceLevel.LOW, ResponseStrategy.CONDITIONAL_ANSWER, ConfidenceLevel.NONE, ResponseStrategy.DECLINE_OR_EXTEND ); // 基于置信度生成回答 public Response generateResponse(String query, RetrievalResult retrievalResult) { ConfidenceLevel confidence = calculateConfidence(query, retrievalResult); ResponseStrategy strategy = STRATEGY_MAP.get(confidence); return switch (strategy) { case DIRECT_ANSWER -> directAnswer(query, retrievalResult); case ANSWER_WITH_CAVEAT -> answerWithCaveat(query, retrievalResult, confidence); case CONDITIONAL_ANSWER -> conditionalAnswer(query, retrievalResult); case DECLINE_OR_EXTEND -> declineOrExtend(query, retrievalResult); }; } // 计算回答置信度 private ConfidenceLevel calculateConfidence(String query, RetrievalResult result) { // 多维度计算置信度分数 double score = 0.0; // 1. 检索结果相关性 score += result.getMaxRelevance() * 0.4; // 2. 结果数量充分性 score += Math.min(result.getDocumentCount() / 10.0, 1.0) * 0.2; // 3. 结果一致性(多个结果是否相互印证) score += calculateConsistency(result.getDocuments()) * 0.2; // 4. 知识库覆盖率 score += calculateCoverage(query, result) * 0.2; // 转换为置信度等级 if (score >= 0.8) return ConfidenceLevel.HIGH; if (score >= 0.5) return ConfidenceLevel.MEDIUM; if (score >= 0.3) return ConfidenceLevel.LOW; return ConfidenceLevel.NONE; } // 条件性回答(低置信度时) private Response conditionalAnswer(String query, RetrievalResult result) { String prompt = """ 基于以下可能相关的信息,请谨慎回答用户的问题。 请注意:这些信息可能不完整或不完全相关,回答时应: 1. 明确说明信息的局限性 2. 区分事实和推断 3. 提供多个可能性(如果有) 4. 建议验证来源 相关信息: %s 用户问题:%s 请按照以下格式回答: [信息局限性说明] [核心回答] [不确定性说明] [建议验证或补充信息来源] """.formatted(formatDocuments(result.getDocuments()), query); String answer = llmService.generate(prompt); return new Response(answer, ConfidenceLevel.LOW, "此回答基于有限且可能不完全相关的信息"); } }
1.4 主动学习和知识缺口识别
java
public class KnowledgeGapDetector { // 定期分析未覆盖查询,识别知识缺口 public List<KnowledgeGap> detectGaps(List<UnansweredQuery> unansweredQueries) { // 1. 聚类分析相似未回答查询 Map<String, List<UnansweredQuery>> clusters = clusterSimilarQueries(unansweredQueries); // 2. 识别高频知识缺口 List<KnowledgeGap> gaps = new ArrayList<>(); for (Map.Entry<String, List<UnansweredQuery>> entry : clusters.entrySet()) { if (entry.getValue().size() >= GAP_THRESHOLD) { KnowledgeGap gap = extractGapInfo(entry.getKey(), entry.getValue()); gaps.add(gap); } } // 3. 计算缺口优先级 gaps.forEach(gap -> gap.setPriority(calculatePriority(gap))); return gaps.stream() .sorted(Comparator.comparing(KnowledgeGap::getPriority).reversed()) .collect(Collectors.toList()); } // 提取知识缺口信息 private KnowledgeGap extractGapInfo(String clusterId, List<UnansweredQuery> queries) { KnowledgeGap gap = new KnowledgeGap(); gap.setId(clusterId); gap.setFrequency(queries.size()); // 提取代表性查询 gap.setRepresentativeQueries(extractRepresentativeQueries(queries)); // 分析主题分布 gap.setTopics(analyzeTopics(queries)); // 计算用户影响度 gap.setUserImpact(calculateUserImpact(queries)); // 分析业务重要性 gap.setBusinessImportance(calculateBusinessImportance(queries)); return gap; } // 生成知识缺口报告 public KnowledgeGapReport generateReport(List<KnowledgeGap> gaps) { KnowledgeGapReport report = new KnowledgeGapReport(); report.setDetectionDate(LocalDate.now()); report.setTotalGaps(gaps.size()); // 按优先级分类 Map<PriorityLevel, List<KnowledgeGap>> gapsByPriority = gaps.stream() .collect(Collectors.groupingBy(gap -> classifyPriority(gap.getPriority()))); report.setCriticalGaps(gapsByPriority.getOrDefault(PriorityLevel.CRITICAL, List.of())); report.setHighGaps(gapsByPriority.getOrDefault(PriorityLevel.HIGH, List.of())); report.setMediumGaps(gapsByPriority.getOrDefault(PriorityLevel.MEDIUM, List.of())); // 分析趋势 report.setTrendAnalysis(analyzeGapTrends(gaps)); // 生成建议 report.setRecommendations(generateRecommendations(gaps)); return report; } }
二、RAG知识库如何更新数据?
2.1 知识库更新架构设计
java
public class KnowledgeBaseUpdateSystem { // 更新系统主控类 public class KnowledgeBaseUpdater { private final DataSourceMonitor sourceMonitor; private final UpdateScheduler scheduler; private final UpdateExecutor executor; private final QualityValidator validator; private final VersionManager versionManager; public void initialize() { // 1. 初始化数据源监听 sourceMonitor.registerDataSources(getDataSources()); sourceMonitor.setChangeListener(this::handleDataSourceChange); // 2. 设置定时任务 scheduler.schedulePeriodicUpdates(getUpdateSchedule()); // 3. 启动监控 startMonitoring(); } // 处理数据源变化 private void handleDataSourceChange(DataSourceChangeEvent event) { switch (event.getChangeType()) { case INCREMENTAL_CHANGE: handleIncrementalUpdate(event); break; case MAJOR_UPDATE: handleMajorUpdate(event); break; case SCHEMA_CHANGE: handleSchemaUpdate(event); break; } } // 增量更新处理 private void handleIncrementalUpdate(DataSourceChangeEvent event) { UpdateTask task = UpdateTask.builder() .type(UpdateType.INCREMENTAL) .source(event.getSource()) .changes(event.getChanges()) .priority(event.getPriority()) .build(); // 异步执行更新 executor.executeAsync(task, this::onUpdateComplete); } // 更新完成回调 private void onUpdateComplete(UpdateResult result) { if (result.isSuccess()) { // 验证更新质量 ValidationResult validation = validator.validateUpdate(result); if (validation.isValid()) { // 创建新版本 versionManager.createVersion(result, validation); // 更新索引 updateIndexes(result); // 触发缓存失效 invalidateCaches(result.getAffectedKeys()); // 记录更新日志 logUpdate(result, validation); } else { // 回滚更新 rollbackUpdate(result, validation); } } else { handleUpdateFailure(result); } } } // 数据源监控器 public class DataSourceMonitor { private final Map<String, DataSource> dataSources = new ConcurrentHashMap<>(); private final List<ChangeListener> listeners = new CopyOnWriteArrayList<>(); // 注册数据源 public void registerDataSource(String sourceId, DataSource source) { dataSources.put(sourceId, source); startMonitoringSource(sourceId, source); } // 开始监控数据源 private void startMonitoringSource(String sourceId, DataSource source) { switch (source.getType()) { case DATABASE: monitorDatabase(sourceId, source); break; case API: monitorApi(sourceId, source); break; case FILE_SYSTEM: monitorFileSystem(sourceId, source); break; case MESSAGE_QUEUE: monitorMessageQueue(sourceId, source); break; } } // 监控数据库变化 private void monitorDatabase(String sourceId, DataSource source) { DatabaseConfig config = (DatabaseConfig) source.getConfig(); // 策略1: 基于CDC(Change Data Capture) if (config.supportsCDC()) { startCDCListening(sourceId, config); } // 策略2: 基于时间戳轮询 else if (config.hasTimestampColumn()) { scheduleTimestampPolling(sourceId, config); } // 策略3: 基于版本号 else if (config.hasVersionColumn()) { scheduleVersionPolling(sourceId, config); } // 策略4: 全量轮询 else { scheduleFullPolling(sourceId, config); } } // 监控API变化 private void monitorApi(String sourceId, DataSource source) { ApiConfig config = (ApiConfig) source.getConfig(); // 根据API类型选择监控策略 if (config.isWebhookSupported()) { registerWebhook(sourceId, config); } else if (config.isPollingSupported()) { scheduleApiPolling(sourceId, config); } else if (config.isEventDriven()) { subscribeToEvents(sourceId, config); } } } }
2.2 增量更新与全量更新策略
java
public class UpdateStrategyManager { // 增量更新实现 public class IncrementalUpdateStrategy implements UpdateStrategy { @Override public UpdateResult execute(UpdateTask task) { try { // 1. 获取变更数据 List<DataChange> changes = fetchIncrementalChanges(task); // 2. 转换数据格式 List<KnowledgeDocument> documents = convertChangesToDocuments(changes); // 3. 应用变更到知识库 return applyIncrementalChanges(documents, task); } catch (Exception e) { return UpdateResult.failed(task.getId(), e); } } private List<DataChange> fetchIncrementalChanges(UpdateTask task) { DataSource source = task.getSource(); // 根据数据源类型采用不同的增量获取方式 switch (source.getType()) { case DATABASE: return fetchDatabaseChanges(source, task.getLastUpdateTime()); case API: return fetchApiChanges(source, task.getLastUpdateTime()); case FILE_SYSTEM: return fetchFileSystemChanges(source, task.getLastUpdateTime()); default: throw new UnsupportedDataSourceException(source.getType()); } } private UpdateResult applyIncrementalChanges(List<KnowledgeDocument> documents, UpdateTask task) { UpdateResult result = new UpdateResult(task.getId()); for (KnowledgeDocument doc : documents) { try { // 根据操作类型处理 switch (doc.getOperation()) { case INSERT: knowledgeBase.insert(doc); result.incrementInserted(); break; case UPDATE: knowledgeBase.update(doc); result.incrementUpdated(); break; case DELETE: knowledgeBase.delete(doc.getId()); result.incrementDeleted(); break; } } catch (Exception e) { result.addError(doc.getId(), e); } } // 更新索引(增量更新) updateIndexesIncrementally(documents); // 更新向量存储 updateVectorStoreIncrementally(documents); return result.success(); } } // 全量更新实现 public class FullUpdateStrategy implements UpdateStrategy { @Override public UpdateResult execute(UpdateTask task) { try { // 1. 创建临时知识库 KnowledgeBase tempKB = createTemporaryKnowledgeBase(); // 2. 分批加载数据 int batchSize = 1000; int totalProcessed = 0; while (hasMoreData(task)) { List<KnowledgeDocument> batch = fetchDataBatch(task, batchSize); // 3. 处理批数据 processBatch(tempKB, batch); totalProcessed += batch.size(); logProgress(totalProcessed); // 4. 检查资源使用 if (shouldPauseForGC()) { System.gc(); Thread.sleep(1000); } } // 5. 构建索引 buildIndexes(tempKB); // 6. 原子切换 return switchKnowledgeBase(tempKB, task); } catch (Exception e) { return UpdateResult.failed(task.getId(), e); } } private UpdateResult switchKnowledgeBase(KnowledgeBase newKB, UpdateTask task) { UpdateResult result = new UpdateResult(task.getId()); // 1. 停止接受新请求 knowledgeBase.setReadOnly(true); // 2. 等待当前请求完成 waitForPendingRequests(); // 3. 备份当前知识库 backupCurrentKnowledgeBase(); try { // 4. 原子替换 KnowledgeBase oldKB = knowledgeBase; knowledgeBase = newKB; // 5. 验证新知识库 ValidationResult validation = validateNewKnowledgeBase(); if (!validation.isValid()) { // 回滚 knowledgeBase = oldKB; throw new ValidationException("新知识库验证失败"); } // 6. 清理旧资源 cleanupOldResources(oldKB); // 7. 预热缓存 warmUpCaches(); result.setStats(collectStatistics(newKB)); return result.success(); } catch (Exception e) { // 恢复备份 restoreFromBackup(); throw e; } } } // 混合更新策略(智能选择) public class HybridUpdateStrategy implements UpdateStrategy { @Override public UpdateResult execute(UpdateTask task) { // 分析更新类型和规模 UpdateAnalysis analysis = analyzeUpdateTask(task); // 根据分析结果选择策略 if (shouldUseIncremental(analysis)) { return incrementalStrategy.execute(task); } else if (shouldUseDelta(analysis)) { return deltaStrategy.execute(task); } else { return fullStrategy.execute(task); } } private boolean shouldUseIncremental(UpdateAnalysis analysis) { // 判断条件:变更比例小,结构不变,时间要求高 return analysis.getChangeRatio() < 0.1 && !analysis.hasSchemaChanges() && analysis.isTimeSensitive(); } private boolean shouldUseDelta(UpdateAnalysis analysis) { // 判断条件:中等变更比例,有结构变化但兼容 return analysis.getChangeRatio() >= 0.1 && analysis.getChangeRatio() < 0.5 && analysis.hasCompatibleSchemaChanges(); } } }
2.3 实时更新与流式处理
java
public class RealTimeUpdateProcessor { // 基于消息队列的实时更新 public class MessageQueueUpdater { private final KafkaConsumer<String, UpdateMessage> consumer; private final UpdatePipeline pipeline; private final ExecutorService executor; public void start() { consumer.subscribe(List.of("knowledge-updates")); while (true) { ConsumerRecords<String, UpdateMessage> records = consumer.poll(Duration.ofMillis(100)); for (ConsumerRecord<String, UpdateMessage> record : record) { // 异步处理每条消息 executor.submit(() -> processUpdateMessage(record.value())); } // 异步提交偏移量 consumer.commitAsync(); } } private void processUpdateMessage(UpdateMessage message) { try { // 1. 验证消息 if (!validateMessage(message)) { log.warn("Invalid update message: {}", message); return; } // 2. 根据消息类型处理 switch (message.getType()) { case DOCUMENT_CREATED: handleDocumentCreate(message); break; case DOCUMENT_UPDATED: handleDocumentUpdate(message); break; case DOCUMENT_DELETED: handleDocumentDelete(message); break; case BATCH_UPDATE: handleBatchUpdate(message); break; } // 3. 发送确认 sendAcknowledgment(message); } catch (Exception e) { log.error("Failed to process update message", e); handleProcessingError(message, e); } } private void handleDocumentCreate(UpdateMessage message) { // 转换消息为文档 KnowledgeDocument doc = convertToDocument(message.getPayload()); // 添加到知识库 knowledgeBase.insert(doc); // 更新向量索引(异步) vectorIndex.updateAsync(doc); // 更新全文索引 fulltextIndex.index(doc); // 更新缓存 cacheManager.invalidate(doc.getKey()); // 触发下游处理 triggerDownstreamProcessing(doc); } } // 流式处理管道 public class UpdatePipeline { private final List<ProcessingStage> stages; public void process(UpdateEvent event) { // 创建处理上下文 ProcessingContext context = new ProcessingContext(event); // 顺序执行处理阶段 for (ProcessingStage stage : stages) { try { stage.process(context); // 检查是否需要终止 if (context.shouldTerminate()) { break; } } catch (Exception e) { context.addError(stage.getName(), e); // 根据错误处理策略决定是否继续 if (!stage.getErrorStrategy().shouldContinue(e)) { throw new PipelineException("Pipeline failed at stage: " + stage.getName(), e); } } } // 处理结果 handlePipelineResult(context); } // 处理阶段定义 public interface ProcessingStage { String getName(); void process(ProcessingContext context); ErrorStrategy getErrorStrategy(); } // 具体处理阶段:数据验证 public class ValidationStage implements ProcessingStage { @Override public void process(ProcessingContext context) { UpdateEvent event = context.getEvent(); // 1. 格式验证 if (!validateFormat(event.getData())) { throw new ValidationException("Invalid data format"); } // 2. 完整性验证 if (!validateCompleteness(event.getData())) { throw new ValidationException("Incomplete data"); } // 3. 一致性验证 if (!validateConsistency(event.getData())) { throw new ValidationException("Data consistency check failed"); } // 4. 业务规则验证 if (!validateBusinessRules(event.getData())) { throw new ValidationException("Business rule violation"); } context.setValidated(true); } } // 具体处理阶段:数据转换 public class TransformationStage implements ProcessingStage { @Override public void process(ProcessingContext context) { if (!context.isValidated()) { throw new IllegalStateException("Data not validated"); } RawData rawData = context.getEvent().getData(); // 1. 标准化处理 StandardizedData standardized = standardize(rawData); // 2. 增强处理 EnhancedData enhanced = enhance(standardized); // 3. 向量化处理 VectorizedData vectorized = vectorize(enhanced); // 4. 元数据提取 Metadata metadata = extractMetadata(enhanced); // 构建知识文档 KnowledgeDocument doc = KnowledgeDocument.builder() .content(enhanced.getContent()) .vector(vectorized.getVector()) .metadata(metadata) .rawData(rawData) .build(); context.setDocument(doc); } } } }
2.4 版本控制与回滚机制
java
篇幅限制下面就只能给大家展示小册部分内容了。整理了一份核心面试笔记包括了:Java面试、Spring、JVM、MyBatis、Redis、MySQL、并发编程、微服务、Linux、Springboot、SpringCloud、MQ、Kafc
需要全套面试笔记及答案【点击此处即可/免费获取】https://docs.qq.com/doc/DQXdYWE9LZ2ZHZ1ho
public class KnowledgeBaseVersionManager { // 版本控制系统 public class VersionControlSystem { private final VersionStore versionStore; private final VersionPolicy versionPolicy; private final RollbackManager rollbackManager; // 创建新版本 public VersionInfo createVersion(UpdateResult updateResult, ValidationResult validation) { // 1. 生成版本信息 VersionInfo version = VersionInfo.builder() .versionId(generateVersionId()) .timestamp(Instant.now()) .updateResult(updateResult) .validationResult(validation) .checksum(calculateChecksum()) .metadata(collectMetadata()) .build(); // 2. 创建版本快照 createSnapshot(version); // 3. 保存版本信息 versionStore.save(version); // 4. 应用版本保留策略 applyRetentionPolicy(); // 5. 记录版本日志 logVersionCreation(version); return version; } // 创建快照 private void createSnapshot(VersionInfo version) { // 1. 导出当前状态 KnowledgeBaseSnapshot snapshot = knowledgeBase.export(); // 2. 压缩快照 CompressedSnapshot compressed = compressSnapshot(snapshot); // 3. 存储快照 snapshotStorage.store(version.getVersionId(), compressed); // 4. 创建索引 createSnapshotIndex(version, snapshot); } // 回滚到指定版本 public RollbackResult rollbackToVersion(String targetVersionId, RollbackOptions options) { try { // 1. 验证目标版本存在 VersionInfo targetVersion = versionStore.get(targetVersionId); if (targetVersion == null) { throw new VersionNotFoundException(targetVersionId); } // 2. 创建当前版本快照(用于可能的恢复) VersionInfo currentVersion = createVersion(null, null); // 3. 停止接受新请求 knowledgeBase.setReadOnly(true); // 4. 等待处理中的请求完成 waitForPendingOperations(); // 5. 加载目标版本快照 KnowledgeBaseSnapshot snapshot = loadSnapshot(targetVersionId); // 6. 恢复知识库状态 restoreFromSnapshot(snapshot); // 7. 验证恢复结果 ValidationResult validation = validateRestoredState(); // 8. 重新启用知识库 knowledgeBase.setReadOnly(false); // 9. 记录回滚日志 logRollback(currentVersion, targetVersion, validation); return RollbackResult.success(currentVersion, targetVersion, validation); } catch (Exception e) { // 尝试恢复之前的状态 try { emergencyRestore(); } catch (Exception restoreEx) { log.error("Emergency restore failed", restoreEx); } return RollbackResult.failed(e); } } } // 增量版本管理(针对频繁更新) public class IncrementalVersionManager { // 基于差异的版本存储 public class DeltaBasedVersioning { public VersionInfo createDeltaVersion(UpdateResult updateResult) { // 1. 计算与上一版本的差异 KnowledgeBaseDelta delta = calculateDelta(updateResult); // 2. 存储差异 deltaStorage.store(delta); // 3. 创建版本链 VersionInfo version = createVersionFromDelta(delta); versionStore.save(version); // 4. 更新版本指针 updateCurrentVersion(version); return version; } // 计算差异 private KnowledgeBaseDelta calculateDelta(UpdateResult updateResult) { KnowledgeBaseDelta delta = new KnowledgeBaseDelta(); // 收集所有变更 delta.setInserts(collectInsertedDocuments()); delta.setUpdates(collectUpdatedDocuments()); delta.setDeletes(collectDeletedDocumentIds()); // 计算元数据差异 delta.setMetadataChanges(calculateMetadataChanges()); // 计算索引差异 delta.setIndexChanges(calculateIndexChanges()); return delta; } // 应用差异 public void applyDelta(KnowledgeBaseDelta delta) { // 1. 应用文档变更 delta.getInserts().forEach(knowledgeBase::insert); delta.getUpdates().forEach(knowledgeBase::update); delta.getDeletes().forEach(knowledgeBase::delete); // 2. 应用元数据变更 applyMetadataChanges(delta.getMetadataChanges()); // 3. 应用索引变更 applyIndexChanges(delta.getIndexChanges()); // 4. 验证应用结果 validateDeltaApplication(delta); } } } }
三、常见RAG问题及解决方案(详细解析)
3.1 检索质量问题及优化方案
问题1:检索结果不相关
根本原因:
- 向量表示不准确
- 查询与文档的语义鸿沟
- 知识库文档质量差
- 索引策略不合理
解决方案:
java
public class RetrievalOptimizer { // 解决方案1:多阶段检索优化 public class MultiStageRetrieval { public List<Document> retrieveWithStages(String query) { // 阶段1:初步召回(高召回率) List<Document> initialResults = stage1Retrieval(query, 100); // 阶段2:重新排序(高精度) List<Document> rerankedResults = stage2Reranking(query, initialResults); // 阶段3:多样性调整 List<Document> diverseResults = stage3Diversification(rerankedResults); // 阶段4:相关性过滤 List<Document> filteredResults = stage4Filtering(query, diverseResults); return filteredResults.subList(0, Math.min(10, filteredResults.size())); } private List<Document> stage1Retrieval(String query, int k) { // 混合检索策略 List<Document> results = new ArrayList<>(); // 1. 向量检索(语义相似度) results.addAll(vectorRetriever.retrieve(query, k/2)); // 2. 关键词检索(BM25) results.addAll(keywordRetriever.retrieve(query, k/4)); // 3. 元数据过滤检索 results.addAll(metadataRetriever.retrieve(query, k/4)); return results; } private List<Document> stage2Reranking(String query, List<Document> candidates) { // 使用交叉编码器进行精排 CrossEncoderReranker reranker = new CrossEncoderReranker(); return candidates.stream() .map(doc -> new ScoredDocument(doc, reranker.score(query, doc.getContent()))) .sorted(Comparator.comparing(ScoredDocument::getScore).reversed()) .map(ScoredDocument::getDocument) .collect(Collectors.toList()); } } // 解决方案2:查询扩展与重构 public class QueryOptimizer { public String optimizeQuery(String originalQuery, QueryContext context) { // 1. 查询解析 ParsedQuery parsed = parseQuery(originalQuery); // 2. 同义词扩展 String expanded = expandSynonyms(parsed); // 3. 语义重构 String rewritten = semanticRewrite(expanded, context); // 4. 添加约束条件 String constrained = addConstraints(rewritten, context); return constrained; } private String semanticRewrite(String query, QueryContext context) { // 使用LLM进行查询重构 String prompt = """ 请将用户查询重构为更适合检索系统理解的版本。 要求: 1. 保持原意不变 2. 明确化模糊概念 3. 补充隐含的上下文 4. 结构化复杂查询 原始查询:%s 上下文:%s 请输出重构后的查询: """.formatted(query, context); return llmService.generate(prompt); } } // 解决方案3:混合检索策略 public class HybridRetrieval { public List<Document> hybridRetrieve(String query, HybridConfig config) { // 并行执行多种检索 CompletableFuture<List<Document>> vectorFuture = CompletableFuture.supplyAsync(() -> vectorRetrieve(query)); CompletableFuture<List<Document>> keywordFuture = CompletableFuture.supplyAsync(() -> keywordRetrieve(query)); CompletableFuture<List<Document>> semanticFuture = CompletableFuture.supplyAsync(() -> semanticRetrieve(query)); // 等待所有结果 CompletableFuture.allOf(vectorFuture, keywordFuture, semanticFuture).join(); // 融合结果 return fuseResults( vectorFuture.join(), keywordFuture.join(), semanticFuture.join(), config ); } private List<Document> fuseResults(List<Document> vectorResults, List<Document> keywordResults, List<Document> semanticResults, HybridConfig config) { // 1. 归一化分数 Map<String, Double> scores = new HashMap<>(); // 加权融合 addScores(scores, vectorResults, config.getVectorWeight()); addScores(scores, keywordResults, config.getKeywordWeight()); addScores(scores, semanticResults, config.getSemanticWeight()); // 2. 排序并去重 return scores.entrySet().stream() .sorted(Map.Entry.<String, Double>comparingByValue().reversed()) .map(entry -> documentMap.get(entry.getKey())) .distinct() .limit(config.getMaxResults()) .collect(Collectors.toList()); } } }
问题2:检索效率低下
根本原因:
- 向量检索复杂度高
- 索引未优化
- 硬件资源不足
- 查询复杂度高
解决方案:
java
public class RetrievalEfficiencyOptimizer { // 解决方案1:索引优化 public class IndexOptimization { public void optimizeIndexes(KnowledgeBase kb) { // 1. 向量索引优化 optimizeVectorIndex(kb); // 2. 倒排索引优化 optimizeInvertedIndex(kb); // 3. 元数据索引优化 optimizeMetadataIndex(kb); // 4. 分层索引策略 createHierarchicalIndexes(kb); } private void optimizeVectorIndex(KnowledgeBase kb) { // 选择合适的ANN算法 switch (vectorIndexType) { case "HNSW": buildHNSWIndex(kb.getVectors()); break; case "IVF": buildIVFIndex(kb.getVectors()); break; case "PQ": buildPQIndex(kb.getVectors()); break; } // 调整参数 tuneIndexParameters(kb.getStatistics()); // 预构建索引 prebuildIndexForCommonQueries(); } private void createHierarchicalIndexes(KnowledgeBase kb) { // 根据文档聚类创建层级索引 List<Cluster> clusters = clusterDocuments(kb.getDocuments()); for (Cluster cluster : clusters) { // 为每个簇创建专门的索引 createClusterIndex(cluster); // 构建簇摘要向量 createClusterSummaryVector(cluster); // 建立簇间索引 createInterClusterIndex(clusters); } } } // 解决方案2:缓存策略优化 public class RetrievalCache { private final Cache<String, List<Document>> queryCache; private final Cache<String, List<Document>> semanticCache; private final Cache<String, byte[]> embeddingCache; public List<Document> retrieveWithCache(String query) { // 1. 查询缓存 String cacheKey = generateCacheKey(query); List<Document> cached = queryCache.getIfPresent(cacheKey); if (cached != null) { cacheStats.hit(); return cached; } cacheStats.miss(); // 2. 语义缓存(相似查询) List<Document> semanticCached = findInSemanticCache(query); if (semanticCached != null) { return semanticCached; } // 3. 执行检索 List<Document> results = doRetrieval(query); // 4. 更新缓存 updateCaches(query, results); return results; } private void updateCaches(String query, List<Document> results) { // 更新查询缓存 queryCache.put(generateCacheKey(query), results); // 更新语义缓存 updateSemanticCache(query, results); // 更新热门文档缓存 updatePopularDocumentCache(results); } private void updateSemanticCache(String query, List<Document> results) { // 生成查询向量 float[] queryVector = embeddingService.embed(query); // 查找语义相似的缓存条目 for (CacheEntry entry : semanticCache.getAll()) { float similarity = cosineSimilarity(queryVector, entry.getQueryVector()); if (similarity > 0.9) { // 合并结果 List<Document> merged = mergeResults(results, entry.getResults()); semanticCache.put(entry.getKey(), merged); return; } } // 添加新条目 semanticCache.put(generateSemanticKey(query), results); } } // 解决方案3:近似最近邻检索优化 public class ANNRetrievalOptimizer { public List<Document> approximateRetrieve(String query, int k, double recallTarget) { // 自适应参数调整 SearchParameters params = adjustParametersByRecallTarget(recallTarget); // 多层检索策略 List<Document> results = new ArrayList<>(); // 第一层:粗粒度检索 results.addAll(coarseGrainedRetrieve(query, k * 2, params)); // 第二层:精粒度检索(在粗粒度结果上) results = fineGrainedRetrieve(query, results, k, params); // 第三层:重排序(如果需要更高精度) if (requiresReranking(results, recallTarget)) { results = rerankWithExactSimilarity(query, results); } return results.subList(0, Math.min(k, results.size())); } private SearchParameters adjustParametersByRecallTarget(double recallTarget) { SearchParameters params = new SearchParameters(); // 根据召回率目标调整搜索参数 if (recallTarget >= 0.95) { params.setEfSearch(1000); // 扩大搜索范围 params.setMaxCandidates(10000); } else if (recallTarget >= 0.85) { params.setEfSearch(500); params.setMaxCandidates(5000); } else { params.setEfSearch(200); // 平衡精度和速度 params.setMaxCandidates(1000); } return params; } } }
3.2 生成质量问题及优化方案
问题1:生成与检索内容不一致(幻觉问题)
根本原因:
- LLM过度依赖自身知识
- 检索内容未充分加权
- 提示工程不完善
- 上下文窗口限制
解决方案:
java
public class GenerationConsistencyEnforcer { // 解决方案1:基于检索内容的约束生成 public class ConstrainedGeneration { public String generateWithConstraints(String query, List<Document> retrievedDocs) { // 1. 提取检索内容的关键信息 Map<String, Object> constraints = extractConstraints(retrievedDocs); // 2. 构建约束提示词 String constrainedPrompt = buildConstrainedPrompt(query, retrievedDocs, constraints); // 3. 执行约束生成 String draftResponse = llmService.generate(constrainedPrompt); // 4. 事实性检查与修正 String verifiedResponse = verifyAndCorrect(draftResponse, retrievedDocs); // 5. 添加引用标记 String finalResponse = addCitations(verifiedResponse, retrievedDocs); return finalResponse; } private String buildConstrainedPrompt(String query, List<Document> docs, Map<String, Object> constraints) { return """ 请基于以下检索到的信息回答问题。必须遵守以下约束: 约束条件: 1. 只使用提供的检索信息,不要添加外部知识 2. 如果信息不足,请明确说明"根据提供的信息,无法完全回答" 3. 关键数据必须来自检索内容 4. 保持回答与检索信息一致 检索到的信息: %s 用户问题:%s 请严格按照以下格式回答: [回答正文] [数据来源说明] [信息完整性说明] """.formatted(formatDocuments(docs), query); } private String verifyAndCorrect(String response, List<Document> docs) { // 1. 提取回答中的关键事实 List<Fact> claimedFacts = extractFacts(response); // 2. 验证每个事实 List<Fact> verifiedFacts = new ArrayList<>(); for (Fact fact : claimedFacts) { VerificationResult result = verifyFact(fact, docs); if (result.isVerified()) { verifiedFacts.add(fact); } else if (result.isContradicted()) { // 修正矛盾事实 Fact corrected = correctFact(fact, result.getCorrectInfo()); verifiedFacts.add(corrected); } else { // 移除未验证事实 log.warn("Removing unverified fact: {}", fact); } } // 3. 重构回答 return reconstructResponse(verifiedFacts, response); } } // 解决方案2:事实性检查与修正管道 public class FactCheckingPipeline { public FactCheckResult checkResponse(String response, List<Document> sources) { FactCheckResult result = new FactCheckResult(); // 1. 事实提取 List<ClaimedFact> claimedFacts = extractClaims(response); // 2. 多维度验证 for (ClaimedFact fact : claimedFacts) { FactVerification verification = verifyFact(fact, sources); result.addVerification(verification); // 统计验证结果 switch (verification.getStatus()) { case SUPPORTED: result.incrementSupported(); break; case CONTRADICTED: result.incrementContradicted(); break; case UNVERIFIED: result.incrementUnverified(); break; } } // 3. 计算整体置信度 result.setConfidenceScore(calculateConfidence(result)); // 4. 生成修正建议 if (result.getContradictedCount() > 0) { result.setCorrectionSuggestions(generateCorrections(result)); } return result; } private FactVerification verifyFact(ClaimedFact fact, List<Document> sources) { // 多证据验证 List<Evidence> supportingEvidences = new ArrayList<>(); List<Evidence> contradictingEvidences = new ArrayList<>(); for (Document doc : sources) { Evidence evidence = checkEvidence(fact, doc); if (evidence.supports()) { supportingEvidences.add(evidence); } else if (evidence.contradicts()) { contradictingEvidences.add(evidence); } } // 判断事实状态 if (!supportingEvidences.isEmpty() && contradictingEvidences.isEmpty()) { return FactVerification.supported(fact, supportingEvidences); } else if (!contradictingEvidences.isEmpty()) { return FactVerification.contradicted(fact, contradictingEvidences); } else { return FactVerification.unverified(fact); } } } // 解决方案3:引用增强生成 public class CitationAwareGeneration { public CitedResponse generateWithCitations(String query, List<Document> retrievedDocs) { // 1. 对检索文档进行段落划分 List<DocumentChunk> chunks = chunkDocuments(retrievedDocs); // 2. 构建带有引用的上下文 String contextWithCitations = buildContextWithCitations(chunks); // 3. 提示模型生成带引用的回答 String prompt = buildCitationPrompt(query, contextWithCitations); // 4. 生成回答 String response = llmService.generate(prompt); // 5. 解析和验证引用 List<Citation> citations = parseCitations(response); validateCitations(citations, chunks); // 6. 构建最终响应 return CitedResponse.builder() .content(removeCitationMarkers(response)) .citations(citations) .sourceDocuments(retrievedDocs) .build(); } private String buildContextWithCitations(List<DocumentChunk> chunks) { StringBuilder context = new StringBuilder(); for (int i = 0; i < chunks.size(); i++) { DocumentChunk chunk = chunks.get(i); context.append(String.format("[%d] %s\\n", i + 1, chunk.getContent())); } return context.toString(); } private String buildCitationPrompt(String query, String context) { return """ 请基于以下带编号的参考资料回答问题。 要求: 1. 回答中的每个重要陈述都必须引用对应的资料编号,格式为[编号] 2. 如果没有相关资料支持,请说明"没有找到相关资料" 3. 如果资料之间存在矛盾,请指出并说明 4. 只使用提供的资料,不要添加外部知识 参考资料: %s 问题:%s 请生成带引用的回答: """.formatted(context, query); } } }
问题2:生成内容冗余或信息不足
根本原因:
- 检索内容重复
- 生成模型过度解释
- 缺乏内容规划
- 未考虑用户背景知识
解决方案:
java
public class GenerationQualityOptimizer { // 解决方案1:内容规划与摘要 public class ContentPlanner { public String generateWithPlanning(String query, List<Document> docs) { // 1. 内容规划阶段 ContentPlan plan = createContentPlan(query, docs); // 2. 信息提取与组织 StructuredInfo structuredInfo = extractAndOrganizeInfo(docs, plan); // 3. 生成草稿 String draft = generateDraft(structuredInfo, plan); // 4. 优化与压缩 String optimized = optimizeAndCompress(draft, plan); return optimized; } private ContentPlan createContentPlan(String query, List<Document> docs) { // 使用小模型或规则生成内容大纲 String planningPrompt = """ 根据用户问题和相关资料,制定回答的内容计划。 要求: 1. 确定核心要点(不超过3个) 2. 为每个要点分配权重 3. 规划回答结构 4. 确定详细程度 5. 识别需要强调的关键信息 用户问题:%s 相关资料摘要:%s 请输出JSON格式的内容计划: """.formatted(query, summarizeDocuments(docs)); String planJson = smallLlm.generate(planningPrompt); return parseContentPlan(planJson); } private String optimizeAndCompress(String draft, ContentPlan plan) { // 1. 去除冗余 String deduplicated = removeDuplicates(draft); // 2. 简化复杂表达 String simplified = simplifyLanguage(deduplicated); // 3. 确保信息完整性 String complete = ensureCompleteness(simplified, plan); // 4. 调整长度 return adjustLength(complete, plan.getTargetLength()); } } // 解决方案2:自适应详细程度控制 public class DetailLevelController { public String generateWithAdaptiveDetail(String query, List<Document> docs, UserProfile user) { // 1. 分析查询复杂度 ComplexityLevel complexity = analyzeQueryComplexity(query); // 2. 分析用户背景知识 KnowledgeLevel userKnowledge = assessUserKnowledge(user, query); // 3. 确定详细程度 DetailLevel detailLevel = determineDetailLevel(complexity, userKnowledge); // 4. 根据详细程度生成回答 return generateWithDetailControl(query, docs, detailLevel); } private DetailLevel determineDetailLevel(ComplexityLevel complexity, KnowledgeLevel userKnowledge) { // 基于规则或学习模型确定详细程度 if (userKnowledge == KnowledgeLevel.EXPERT) { return DetailLevel.CONCISE; // 专家需要简洁 } else if (complexity == ComplexityLevel.HIGH && userKnowledge == KnowledgeLevel.BEGINNER) { return DetailLevel.VERY_DETAILED; // 初学者面对复杂问题需要详细解释 } else if (complexity == ComplexityLevel.LOW) { return DetailLevel.MODERATE; // 简单问题中等详细 } else { return DetailLevel.DETAILED; } } private String generateWithDetailControl(String query, List<Document> docs, DetailLevel detailLevel) { String prompt = """ 请根据指定的详细程度回答用户问题。 详细程度要求:%s 具体要求: %s 参考资料: %s 问题:%s """.formatted( detailLevel.getName(), detailLevel.getGuidelines(), formatDocuments(docs), query ); return llmService.generate(prompt); } } // 解决方案3:信息密度优化 public class InformationDensityOptimizer { public String optimizeDensity(String response, double targetDensity) { // 1. 计算当前信息密度 double currentDensity = calculateInformationDensity(response); // 2. 分析密度问题 DensityAnalysis analysis = analyzeDensity(response); // 3. 根据目标密度调整 if (currentDensity < targetDensity) { // 增加信息密度 return increaseDensity(response, analysis, targetDensity); } else if (currentDensity > targetDensity) { // 降低信息密度(增加解释) return decreaseDensity(response, analysis, targetDensity); } else { return response; } } private String increaseDensity(String response, DensityAnalysis analysis, double targetDensity) { // 1. 移除冗余解释 String compressed = removeRedundantExplanations(response, analysis); // 2. 合并相似信息 String merged = mergeSimilarInformation(compressed); // 3. 使用更精确的表达 String precise = useMorePreciseLanguage(merged); // 4. 添加结构化信息 String structured = addStructure(precise); return structured; } private double calculateInformationDensity(String text) { // 信息密度 = 关键信息单元数量 / 总字数 int keyInfoUnits = extractKeyInformationUnits(text).size(); int totalWords = countWords(text); return totalWords > 0 ? (double) keyInfoUnits / totalWords : 0; } } }
3.3 系统性能问题及优化方案
问题1:检索速度慢
根本原因:
- 向量检索复杂度高
- 索引规模过大
- 硬件限制
- 查询优化不足
解决方案:
java
篇幅限制下面就只能给大家展示小册部分内容了。整理了一份核心面试笔记包括了:Java面试、Spring、JVM、MyBatis、Redis、MySQL、并发编程、微服务、Linux、Springboot、SpringCloud、MQ、Kafc
需要全套面试笔记及答案【点击此处即可/免费获取】https://docs.qq.com/doc/DQXdYWE9LZ2ZHZ1ho
public class RetrievalPerformanceOptimizer { // 解决方案1:分层检索架构 public class HierarchicalRetrieval { public List<Document> hierarchicalRetrieve(String query, int k) { // 第一层:粗粒度聚类检索 List<Cluster> candidateClusters = retrieveClusters(query, 10); // 第二层:簇内细粒度检索 List<Document> results = new ArrayList<>(); for (Cluster cluster : candidateClusters) { List<Document> clusterDocs = retrieveWithinCluster(query, cluster, k/5); results.addAll(clusterDocs); if (results.size() >= k * 2) { break; // 提前终止 } } // 第三层:全局精排 return rerankAndSelect(query, results, k); } private List<Cluster> retrieveClusters(String query, int maxClusters) { // 使用簇中心向量进行快速检索 float[] queryVector = embeddingService.embed(query); // ANN检索簇中心 return clusterIndex.annSearch(queryVector, maxClusters); } private List<Document> retrieveWithinCluster(String query, Cluster cluster, int k) { // 在簇内进行更精确的检索 return cluster.getIndex().search(query, k); } } // 解决方案2:量化与压缩 public class VectorQuantization { public QuantizedIndex buildQuantizedIndex(List<float[]> vectors) { // 1. 选择合适的量化方法 QuantizationMethod method = selectQuantizationMethod(vectors); // 2. 训练量化器 Quantizer quantizer = trainQuantizer(vectors, method); // 3. 量化所有向量 List<QuantizedVector> quantizedVectors = vectors.stream() .map(quantizer::quantize) .collect(Collectors.toList()); // 4. 构建量化索引 return QuantizedIndex.builder() .quantizer(quantizer) .vectors(quantizedVectors) .originalDim(vectors.get(0).length) .compressionRatio(calculateCompressionRatio(vectors, quantizedVectors)) .build(); } private QuantizationMethod selectQuantizationMethod(List<float[]> vectors) { // 基于数据特征选择量化方法 DataCharacteristics chars = analyzeDataCharacteristics(vectors); if (chars.getDistribution() == DistributionType.NORMAL && chars.getDimension() > 128) { return QuantizationMethod.PRODUCT_QUANTIZATION; } else if (chars.getDimension() <= 128) { return QuantizationMethod.SCALAR_QUANTIZATION; } else { return QuantizationMethod.RESIDUAL_QUANTIZATION; } } public List<Document> searchWithQuantization(String query, QuantizedIndex index, int k) { // 1. 量化查询向量 QuantizedVector queryVector = index.getQuantizer().quantize( embeddingService.embed(query) ); // 2. 非对称距离计算(更精确) return index.searchAsymmetric(queryVector, k); } } // 解决方案3:预计算与缓存优化 public class PrecomputationEngine { public void precomputeCommonQueries() { // 1. 分析查询模式 QueryPatternAnalysis analysis = analyzeQueryPatterns(); // 2. 识别高频查询 List<String> frequentQueries = analysis.getFrequentQueries(); // 3. 预计算查询结果 for (String query : frequentQueries) { precomputeAndCache(query); } // 4. 预计算查询变体 for (String query : frequentQueries) { List<String> variants = generateQueryVariants(query); for (String variant : variants) { precomputeAndCache(variant); } } } private void precomputeAndCache(String query) { // 1. 执行检索 List<Document> results = doFullRetrieval(query); // 2. 预计算相似度 Map<String, Float> similarities = precomputeSimilarities(query, results); // 3. 存储到预热缓存 warmCache.put(query, new PrecomputedResult(results, similarities)); // 4. 预构建回答摘要 String summary = precomputeSummary(query, results); summaryCache.put(query, summary); } public CachedResult getWithPrecomputation(String query) { // 1. 检查预热缓存 PrecomputedResult precomputed = warmCache.get(query); if (precomputed != null) { return new CachedResult(precomputed, CacheType.WARM); } // 2. 检查查询变体缓存 CachedResult variantResult = checkQueryVariants(query); if (variantResult != null) { return variantResult; } // 3. 检查语义相似缓存 CachedResult semanticResult = checkSemanticCache(query); if (semanticResult != null) { return semanticResult; } // 4. 执行实时检索 return new CachedResult(doRealTimeRetrieval(query), CacheType.NONE); } } }
问题2:系统可扩展性问题
根本原因:
- 单点瓶颈
- 数据分布不均
- 资源竞争
- 架构限制
解决方案:
java
public class ScalabilityOptimizer { // 解决方案1:分布式检索架构 public class DistributedRetrieval { private final List<RetrievalNode> nodes; private final Router router; private final Merger merger; public List<Document> distributedRetrieve(String query, int k) { // 1. 查询路由 List<RetrievalTask> tasks = router.routeQuery(query, nodes.size()); // 2. 并行检索 List<CompletableFuture<PartialResult>> futures = new ArrayList<>(); for (int i = 0; i < tasks.size(); i++) { RetrievalTask task = tasks.get(i); RetrievalNode node = nodes.get(i % nodes.size()); futures.add(CompletableFuture.supplyAsync( () -> node.retrieve(task), retrievalExecutor )); } // 3. 合并结果 CompletableFuture<List<PartialResult>> allResults = CompletableFuture.allOf(futures.toArray(new CompletableFuture[0])) .thenApply(v -> futures.stream() .map(CompletableFuture::join) .collect(Collectors.toList())); // 4. 全局重排序 return allResults.thenApply(partialResults -> merger.mergeAndRerank(partialResults, k) ).join(); } // 智能查询路由 public class SmartRouter { public List<RetrievalTask> routeQuery(String query, int nodeCount) { // 1. 分析查询特征 QueryFeatures features = extractQueryFeatures(query); // 2. 基于内容的路由 if (features.isSemanticQuery()) { return routeBySemanticHash(query, nodeCount); } // 3. 基于负载的路由 else if (features.isComplexQuery()) { return routeByLoadBalancing(query, nodeCount); } // 4. 基于数据分布的路由 else { return routeByDataDistribution(query, nodeCount); } } private List<RetrievalTask> routeBySemanticHash(String query, int nodeCount) { // 基于语义哈希将查询分配到特定节点 int hash = semanticHash(query); int nodeIndex = hash % nodeCount; // 创建路由任务 RetrievalTask task = RetrievalTask.builder() .query(query) .targetNodes(Set.of(nodeIndex)) .strategy(RetrievalStrategy.SEMANTIC) .build(); return List.of(task); } } } // 解决方案2:弹性伸缩机制 public class ElasticScaling { private final ScalingMonitor monitor; private final ScalingController controller; private final ResourcePool resourcePool; public void manageScaling() { while (true) { // 1. 监控系统指标 SystemMetrics metrics = monitor.collectMetrics(); // 2. 分析负载模式 LoadPattern pattern = analyzeLoadPattern(metrics); // 3. 预测未来负载 LoadPrediction prediction = predictFutureLoad(pattern); // 4. 决定伸缩操作 ScalingDecision decision = makeScalingDecision(metrics, prediction); // 5. 执行伸缩操作 executeScaling(decision); // 等待下一个监控周期 Thread.sleep(SCALING_INTERVAL_MS); } } private ScalingDecision makeScalingDecision(SystemMetrics metrics, LoadPrediction prediction) { ScalingDecision decision = new ScalingDecision(); // 基于规则的决策 if (metrics.getCpuUsage() > SCALE_OUT_CPU_THRESHOLD) { decision.setAction(ScalingAction.SCALE_OUT); decision.setNodeCount(calculateScaleOutCount(metrics)); } else if (metrics.getCpuUsage() < SCALE_IN_CPU_THRESHOLD && metrics.getActiveNodes() > MIN_NODES) { decision.setAction(ScalingAction.SCALE_IN); decision.setNodeCount(calculateScaleInCount(metrics)); } // 基于预测的预伸缩 if (prediction.getExpectedLoad() > metrics.getCurrentLoad() * 1.5) { decision.setPreemptiveScaleOut(true); decision.setAdditionalNodes(prediction.getAdditionalNodesNeeded()); } return decision; } private void executeScaling(ScalingDecision decision) { switch (decision.getAction()) { case SCALE_OUT: scaleOut(decision.getNodeCount()); break; case SCALE_IN: scaleIn(decision.getNodeCount()); break; case PREEMPTIVE_SCALE: preemptiveScale(decision); break; } // 重新平衡数据 rebalanceData(); // 更新路由表 updateRoutingTable(); } } // 解决方案3:异步与流式处理 public class AsyncProcessingPipeline { private final ExecutorService retrievalExecutor; private final ExecutorService generationExecutor; private final ResultStreamer resultStreamer; public CompletableFuture<StreamingResponse> processAsync(String query) { CompletableFuture<StreamingResponse> future = new CompletableFuture<>(); // 1. 启动异步检索 CompletableFuture<List<Document>> retrievalFuture = CompletableFuture.supplyAsync(() -> retrieveDocuments(query), retrievalExecutor); // 2. 流式返回部分结果 resultStreamer.startStreaming(future); // 3. 检索完成后异步生成 retrievalFuture.thenAcceptAsync(docs -> { // 流式返回检索结果 resultStreamer.streamRetrievalResults(docs); // 异步生成回答 CompletableFuture.supplyAsync(() -> generateResponse(query, docs), generationExecutor) .thenAccept(response -> { // 流式返回生成结果 resultStreamer.streamGenerationResult(response); resultStreamer.complete(); }) .exceptionally(ex -> { resultStreamer.streamError(ex); return null; }); }).exceptionally(ex -> { resultStreamer.streamError(ex); return null; }); return future; } // 流式结果处理器 public class ResultStreamer { private final SseEmitter emitter; private final List<String> bufferedChunks = new ArrayList<>(); public void startStreaming(CompletableFuture<StreamingResponse> future) { // 立即返回初始响应 StreamingResponse initial = StreamingResponse.builder() .status(StreamingStatus.STARTED) .message("开始处理查询…") .build(); future.complete(initial); // 设置超时和错误处理 emitter.onTimeout(() -> handleTimeout()); emitter.onError(ex -> handleError(ex)); } public void streamRetrievalResults(List<Document> docs) { // 流式返回检索进度 streamChunk("已检索到 " + docs.size() + " 个相关文档"); // 流式返回文档摘要 docs.stream() .limit(5) // 限制数量避免过多数据 .forEach(doc -> streamChunk("文档摘要: " + doc.getSummary())); } public void streamGenerationResult(String response) { // 流式返回生成结果(分块) chunkText(response, 100).forEach(this::streamChunk); } private void streamChunk(String chunk) { try { emitter.send(SseEmitter.event() .name("chunk") .data(chunk)); bufferedChunks.add(chunk); } catch (IOException e) { log.error("Failed to stream chunk", e); } } } } }
3.4 知识库更新问题及优化方案
问题1:更新延迟与实时性差
根本原因:
- 批量更新周期长
- 索引重建耗时
- 数据同步延迟
- 资源竞争
解决方案:
java
public class RealTimeUpdateOptimizer { // 解决方案1:增量索引更新 public class IncrementalIndexUpdater { private final IndexWriter indexWriter; private final BufferManager bufferManager; private final MergeScheduler mergeScheduler; public void updateIncrementally(List<DocumentUpdate> updates) { // 1. 缓冲更新 UpdateBuffer buffer = bufferManager.bufferUpdates(updates); // 2. 应用更新到内存索引 MemoryIndex memoryIndex = applyToMemoryIndex(buffer); // 3. 异步写入磁盘 CompletableFuture.runAsync(() -> writeToDiskIndex(memoryIndex, buffer) ); // 4. 合并小段(后台) if (shouldMergeSegments()) { mergeScheduler.scheduleMerge(); } } private MemoryIndex applyToMemoryIndex(UpdateBuffer buffer) { MemoryIndex index = new MemoryIndex(); for (DocumentUpdate update : buffer.getUpdates()) { switch (update.getType()) { case INSERT: index.addDocument(update.getDocument()); break; case UPDATE: index.updateDocument(update.getDocumentId(), update.getDocument()); break; case DELETE: index.deleteDocument(update.getDocumentId()); break; } } // 更新内存中的向量索引 updateVectorIndexInMemory(index); return index; } // 实时查询:结合内存和磁盘索引 public List<Document> realTimeRetrieve(String query) { // 1. 查询内存索引(最新数据) List<Document> memoryResults = memoryIndex.search(query); // 2. 查询磁盘索引(历史数据) List<Document> diskResults = diskIndex.search(query); // 3. 合并结果(内存结果优先级更高) return mergeResults(memoryResults, diskResults); } } // 解决方案2:基于CDC的实时同步 public class CDCBasedSync { private final ChangeCapture changeCapture; private final ChangeProcessor changeProcessor; private final ReplicationManager replicationManager; public void startRealTimeSync() { // 1. 捕获数据源变化 changeCapture.startCapturing(changeEvent -> { // 2. 实时处理变化 CompletableFuture.runAsync(() -> processChangeEvent(changeEvent) ); }); // 3. 启动复制监听 replicationManager.startReplication(); } private void processChangeEvent(ChangeEvent event) { try { // 1. 转换变化为知识库更新 KnowledgeUpdate update = convertChangeEvent(event); // 2. 验证更新 if (!validateUpdate(update)) { log.warn("Invalid update from change event: {}", event); return; } // 3. 应用更新(原子操作) applyUpdateAtomically(update); // 4. 触发下游更新 triggerDownstreamUpdates(update); // 5. 记录更新日志 logUpdate(update); } catch (Exception e) { log.error("Failed to process change event", e); handleProcessingError(event, e); } } private void applyUpdateAtomically(KnowledgeUpdate update) { // 使用事务保证原子性 Transaction tx = knowledgeBase.beginTransaction(); try { // 应用文档更新 applyDocumentUpdate(update, tx); // 更新索引 updateIndexes(update, tx); // 更新向量存储 updateVectors(update, tx); // 提交事务 tx.commit(); // 更新缓存 updateCaches(update); } catch (Exception e) { tx.rollback(); throw e; } } } // 解决方案3:流式处理管道 public class StreamingUpdatePipeline { private final KafkaStreams streams; private final UpdateProcessor processor; public void buildStreamingPipeline() { // 构建Kafka Streams处理拓扑 StreamsBuilder builder = new StreamsBuilder(); // 1. 源流:原始更新事件 KStream<String, UpdateEvent> sourceStream = builder.stream("update-events"); // 2. 转换流:转换为标准格式 KStream<String, StandardizedUpdate> transformedStream = sourceStream .mapValues(this::standardizeUpdate); // 3. 过滤流:过滤无效更新 KStream<String, StandardizedUpdate> filteredStream = transformedStream .filter((key, value) -> isValidUpdate(value)); // 4. 处理流:应用更新 filteredStream.foreach((key, update) -> processor.processUpdate(update) ); // 5. 分支流:根据类型分别处理 Map<String, KStream<String, StandardizedUpdate>> branchedStreams = filteredStream.split(Named.as("branch-")) .branch((key, update) -> update.getType() == UpdateType.INSERT, Branched.as("inserts")) .branch((key, update) -> update.getType() == UpdateType.UPDATE, Branched.as("updates")) .branch((key, update) -> update.getType() == UpdateType.DELETE, Branched.as("deletes")) .noDefaultBranch(); // 分别处理不同类型 processInserts(branchedStreams.get("branch-inserts")); processUpdates(branchedStreams.get("branch-updates")); processDeletes(branchedStreams.get("branch-deletes")); // 启动流处理 streams = new KafkaStreams(builder.build(), getStreamsConfig()); streams.start(); } private void processInserts(KStream<String, StandardizedUpdate> insertStream) { insertStream // 分批处理(窗口化) .groupByKey() .windowedBy(TimeWindows.of(Duration.ofSeconds(5))) .aggregate( () -> new BatchAccumulator(), (key, update, accumulator) -> accumulator.add(update), Materialized.with(Serdes.String(), new JsonSerde<>()) ) .toStream() // 批量应用插入 .foreach((windowedKey, batch) -> processor.batchInsert(batch.getUpdates()) ); } } }
问题2:更新一致性保证
篇幅限制下面就只能给大家展示小册部分内容了。整理了一份核心面试笔记包括了:Java面试、Spring、JVM、MyBatis、Redis、MySQL、并发编程、微服务、Linux、Springboot、SpringCloud、MQ、Kafc
需要全套面试笔记及答案【点击此处即可/免费获取】https://docs.qq.com/doc/DQXdYWE9LZ2ZHZ1ho
根本原因:
- 并发更新冲突
- 分布式系统一致性难题
- 网络分区
- 故障恢复
解决方案:
java
public class ConsistencyManager { // 解决方案1:基于版本的一致性控制 public class VersionBasedConsistency { private final VersionStore versionStore; private final ConflictResolver conflictResolver; public UpdateResult applyUpdateWithVersion(KnowledgeUpdate update, long expectedVersion) { // 获取当前版本 long currentVersion = knowledgeBase.getCurrentVersion(); // 检查版本一致性 if (expectedVersion != currentVersion) { // 版本冲突,需要解决 ConflictResolution resolution = resolveConflict(update, expectedVersion, currentVersion); return applyResolvedUpdate(resolution); } // 版本一致,应用更新 return applyUpdate(update, currentVersion + 1); } private ConflictResolution resolveConflict(KnowledgeUpdate update, long expectedVersion, long currentVersion) { // 1. 获取冲突版本之间的变更 List<KnowledgeUpdate> conflictingUpdates = versionStore.getUpdatesBetween(expectedVersion, currentVersion); // 2. 分析冲突类型 ConflictAnalysis analysis = analyzeConflicts(update, conflictingUpdates); // 3. 自动或手动解决冲突 if (analysis.isAutoResolvable()) { return conflictResolver.autoResolve(update, conflictingUpdates, analysis); } else { return conflictResolver.manualResolve(update, conflictingUpdates, analysis); } } private UpdateResult applyResolvedUpdate(ConflictResolution resolution) { // 创建合并后的更新 KnowledgeUpdate mergedUpdate = mergeUpdates( resolution.getOriginalUpdate(), resolution.getConflictingUpdates(), resolution.getResolutionStrategy() ); // 应用合并后的更新 return applyUpdate(mergedUpdate, resolution.getNewVersion()); } } // 解决方案2:基于事务的一致性保证 public class TransactionalUpdate { private final TransactionManager txManager; private final LockManager lockManager; public UpdateResult updateWithTransaction(KnowledgeUpdate update) { // 开始事务 Transaction tx = txManager.beginTransaction(); try { // 1. 获取必要的锁 List<Lock> locks = acquireLocks(update, tx); // 2. 验证前置条件 validatePreconditions(update, tx); // 3. 执行更新操作 executeUpdateOperations(update, tx); // 4. 后置条件检查 validatePostconditions(tx); // 5. 提交事务 tx.commit(); // 6. 释放锁 releaseLocks(locks); return UpdateResult.success(update.getId()); } catch (Exception e) { // 回滚事务 tx.rollback(); // 释放锁 releaseAllLocks(); return UpdateResult.failed(update.getId(), e); } } private List<Lock> acquireLocks(KnowledgeUpdate update, Transaction tx) { List<Lock> locks = new ArrayList<>(); // 根据更新类型获取不同的锁 switch (update.getScope()) { case DOCUMENT_LEVEL: // 文档级锁 locks.add(lockManager.acquireDocumentLock(update.getDocumentId(), tx)); break; case COLLECTION_LEVEL: // 集合级锁 locks.add(lockManager.acquireCollectionLock(update.getCollection(), tx)); break; case GLOBAL: // 全局锁(谨慎使用) locks.add(lockManager.acquireGlobalLock(tx)); break; } // 获取索引锁 if (update.affectsIndex()) { locks.addAll(lockManager.acquireIndexLocks(update.getAffectedIndexes(), tx)); } return locks; } } // 解决方案3:最终一致性保证 public class EventualConsistency { private final ReplicationLog replicationLog; private final ConsistencyChecker consistencyChecker; private final RepairManager repairManager; public void ensureEventualConsistency() { // 定期检查一致性 ScheduledExecutorService scheduler = Executors.newScheduledThreadPool(1); scheduler.scheduleAtFixedRate(() -> { try { // 1. 检查副本一致性 ConsistencyReport report = consistencyChecker.checkConsistency(); // 2. 识别不一致 List<Inconsistency> inconsistencies = report.getInconsistencies(); if (!inconsistencies.isEmpty()) { // 3. 启动修复流程 repairManager.repairInconsistencies(inconsistencies); // 4. 记录修复日志 logRepairActions(inconsistencies); } } catch (Exception e) { log.error("Consistency check failed", e); } }, 0, CONSISTENCY_CHECK_INTERVAL, TimeUnit.MINUTES); } // 读修复机制 public Document readWithRepair(String documentId) { // 1. 从主副本读取 Document primaryDoc = readFromPrimary(documentId); // 2. 从从副本读取(快速返回) CompletableFuture<Document> replicaFuture = CompletableFuture.supplyAsync( () -> readFromReplica(documentId) ); // 3. 比较一致性 Document replicaDoc = replicaFuture.join(); if (!documentsEqual(primaryDoc, replicaDoc)) { // 4. 检测到不一致,启动异步修复 CompletableFuture.runAsync(() -> repairInconsistency(documentId, primaryDoc, replicaDoc) ); } // 5. 返回主副本数据 return primaryDoc; } // 写传播机制 public void propagateUpdate(KnowledgeUpdate update) { // 1. 写入主副本 applyToPrimary(update); // 2. 异步传播到从副本 CompletableFuture.runAsync(() -> { for (ReplicaNode replica : replicaNodes) { try { replica.applyUpdate(update); } catch (Exception e) { log.error("Failed to propagate update to replica", e); // 记录失败,稍后重试 scheduleRetry(update, replica); } } }); // 3. 更新复制日志 replicationLog.append(update); } } }
四、总结与最佳实践
通过以上详细分析,我们可以总结出RAG系统的关键问题和解决方案:
4.1 处理知识库未覆盖问题的最佳实践
4.2 知识库更新的最佳实践
4.3 系统设计原则
4.4 未来发展趋势
RAG系统作为连接大语言模型和专业知识库的关键桥梁,其优化是一个持续的过程。随着技术的不断发展,我们期待看到更加智能、高效、可靠的RAG系统在更多领域得到应用。



评论前必须登录!
注册