 网硕互联帮助中心
网硕互联帮助中心文章目录
- 前言
- 一、缓存添加
- 二、缓存更新策略
-
- 1.内存淘汰
- 2.超时剔除
- 3.主动更新
- 4.小结
- 三、缓存穿透
-
- 1.空值缓存
- 2.布隆过滤
- 3.小结
- 四、总结
前言
redis学的有点快了。今天从原理角度来复习一下缓存穿透的来龙去脉。由于学的是redis数据库,所以很多原理都是基于redis的机制和操作。
一、缓存添加
由于每次网络向后端发出请求,后端去数据库查询,返回给前端。这个过程中,由于数据库性能问题,导致请求大量增加的同时,会出现用户功能体验延迟的情况。所以为了避免这个情况,考虑到缓存的高性能,后端接收请求后首先访问缓存,命中则直接返回查询内容;反之则去数据库查询数据,并将查询到的数据存放进缓存中,提高下次操作性能。下面是缓存添加的示意图。 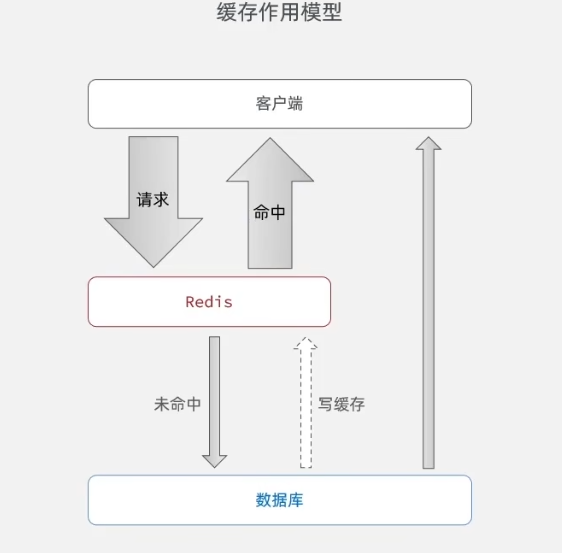
二、缓存更新策略
数据一致性要求缓存和数据库中的数据要保持一致。所以数据库每次增删改操作都需要对缓存进行更新,避免数据不一致的情况。这里从数据一致性结果的高低介绍三种方法。
1.内存淘汰
内存淘汰是基于redis自身机制,从而实现无需手动维护的更新方式。
Redis 内存淘汰机制是当内存使用达到配置的maxmemory阈值时,自动筛选并删除部分键值对以释放内存的核心策略,用于防止内存溢出,保证服务稳定运行。并且淘汰过程中保证高性能且不阻塞正常请求。但前提需要去conf文件中配置maxmemory的值。这里简要介绍一下redis怎么执行内存淘汰。
从这个过程中,可以了解到内存淘汰机制的随机性,使得最后的数据一致性也会较低。该方法维护成本也低。
2.超时剔除
超时剔除方法基于redis中TTL字段值实现的一种方法。数据存放进缓存时给它添加一个字段TTL,表示过期时间。当过期时间到了,自动删除该数据。就相当于自动重置到未添加缓存的状态。该方法需要手动添加字段,并且由于额外存放一个字段,内存消耗增大。相比于内存淘汰而言,维护成本变高,但是由于指向性,数据一致性也变高。
3.主动更新
主动更新理解起来很容易,手动编写业务逻辑,在增删改数据库时同时更新缓存。这个方法关键在于对于不同业务的理解。这里就不再赘述,只能以后到项目中慢慢领会。
4.小结

三、缓存穿透
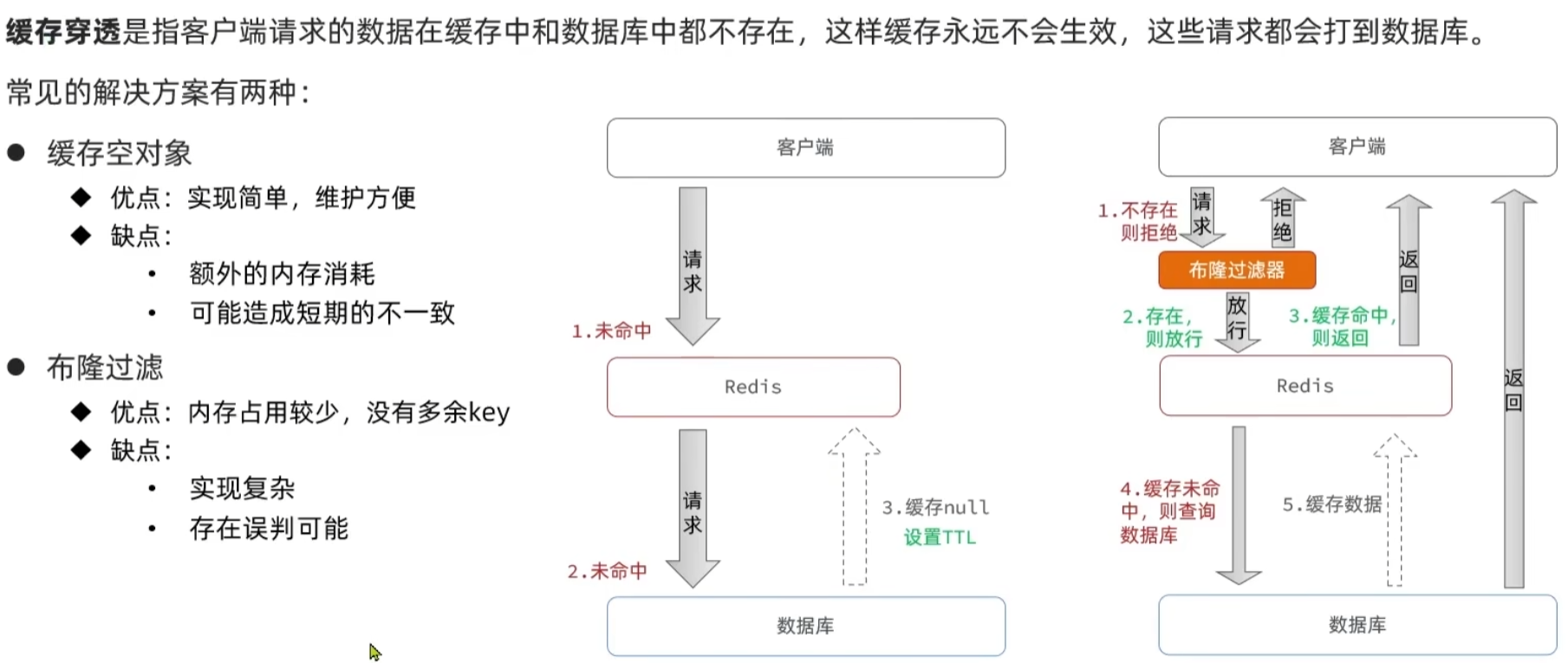
缓存穿透是指客户端请求的数据在缓存中和数据库中都不存在,这样缓存永远不会生效,这些请求都会打到数据库。大量发出这种恶意请求会给数据库带来巨大压力,甚至打垮数据库。这里提供两种常见的解决思路:空值缓存和布隆过滤。
1.空值缓存
这种是直接从定义本身出发。既然都不存在该数据,那我就给你返回一个空数据,并且给空值设置一个过期时间,让它自动剔除。
Object cacheValue = redisTemplate.opsForValue().get(cacheKey);
if (cacheValue != null) {
if (NULL_VALUE.equals(cacheValue)) {
return null;
}
}
2.布隆过滤
布隆过滤器是一种空间效率极高的概率型数据结构,能快速判断一个元素 “一定不存在” 或 “可能存在”。我们可以先把数据库中所有有效的 key 提前加载到布隆过滤器中,当请求过来时,先通过布隆过滤器判断 key 是否存在:
3.小结
四、总结
从为什么使用缓存,到如何更新缓存,全都是为缓存穿透的出现作铺垫。因为要使用缓存,所以需要解决出现的一系列问题。后续再复习缓存雪崩和缓存击穿



评论前必须登录!
注册